

在本指南中,你将学到:
- Pipedream 是什么,以及为何要使用它。
- 为什么应将其与内置的爬取插件集成。
- 将 Pipedream 与 Bright Data 爬取架构集成的优势。
- 如何通过分步教程在 Pipedream 中创建一个网页爬取工作流。
让我们开始吧!
快速了解 Pipedream:轻松自动化与集成
Pipedream 是一个用于构建和运行工作流的平台,可连接各类应用和第三方服务。它同时提供无代码与低代码能力。借助这些能力,你可以通过预构建组件或自定义代码来实现流程自动化与系统集成。
其主要特性如下:
- 可视化工作流构建器:通过可视化界面定义工作流,并连接热门应用的预构建组件。目前已提供2700+ 应用集成。
- 无代码/低代码:无需技术背景即可上手。对于复杂需求,Pipedream 的应用还可加入自定义代码节点。支持的编程语言包括 Node.js、Python、Go 和 Bash。
- 事件驱动架构:工作流由诸如HTTP/Webhook、定时任务、来邮等事件触发。因此,在特定触发事件发生前,工作流处于休眠状态且不消耗资源。
- 无服务器执行:Pipedream 的核心是其无服务器运行时。这意味着你无需预置或管理服务器。Pipedream 在可扩展的按需环境中执行工作流。
- AI 构建工作流:可使用 String,一款专注于编写自定义智能体的 AI,只需提供提示词即可。即使你不熟悉 Pipedream,也能通过提示词让 AI 为你构建工作流。
为何不直接写代码?现成爬取集成的优势
Pipedream 支持代码操作。这允许你用偏好的语言(在支持范围内)从零编写完整脚本。从技术上讲,你可以在 Pipedream 中使用这些节点构建一个爬虫。
但这样做并不一定能简化构建爬取工作流的过程。你仍会遇到与反爬机制相关的常见挑战与阻碍。
因此,更实用、高效且快捷的方式,是依赖一个内置的爬取插件来为你处理这些复杂性。这正是Pipedream 中的 Bright Data 集成所带来的体验。
以下是选择 Bright Data 现成爬取插件的主要理由:
- 简单认证:Pipedream 安全存储你的 Bright Data API 密钥(认证所需),并提供易用性。你无需为认证编写任何自定义代码,也不必担心密钥泄露。
- 突破反爬系统:在幕后,Bright Data 的 API 处理所有网页爬取难题,从代理轮换与 IP 管理,到解决验证码与数据解析。从而确保你的 Pipedream 工作流持续获得高质量网页数据。
- 结构化数据:爬取完成后,你无需写任何代码即可获得结构化、规整的数据。插件会替你完成数据结构化。
将 Pipedream 与 Bright Data 插件结合的关键优势
当你将 Pipedream 的自动化能力与 Bright Data 相结合时,你可以:
- 获取新鲜数据:网页爬取的目的在于从网络获取数据,Bright Data 可为你提供帮助。但数据会随时间变化。若不希望分析结果过时,就需要持续获取新数据。这正是 Pipedream 的强项(例如通过定时触发器)。
- 将 AI 融入爬取工作流:Pipedream 可集成多种大模型,如 ChatGPT 与 Gemini。这使你能自动化许多需要大量手工工作的任务。例如,你可以构建一个 RAG 工作流来监控电商网站上的竞品列表。
- 简化技术细节:网站采用复杂的反爬阻断技术,几乎每周都会更新。Bright Data 集成会为你绕过这些阻断,因为它负责所有反机器人方案。
现在,让我们在 Pipedream 的爬取工作流中,看看 Bright Data 集成的实际表现!
构建 AI 驱动的爬取工作流:Pipedream + Bright Data 分步教程
在这一引导部分,你将学习如何构建一个使用 Bright Data 获取数据的 Pipedream 工作流,目标数据来自亚马逊商品页面。具体目标页如下:
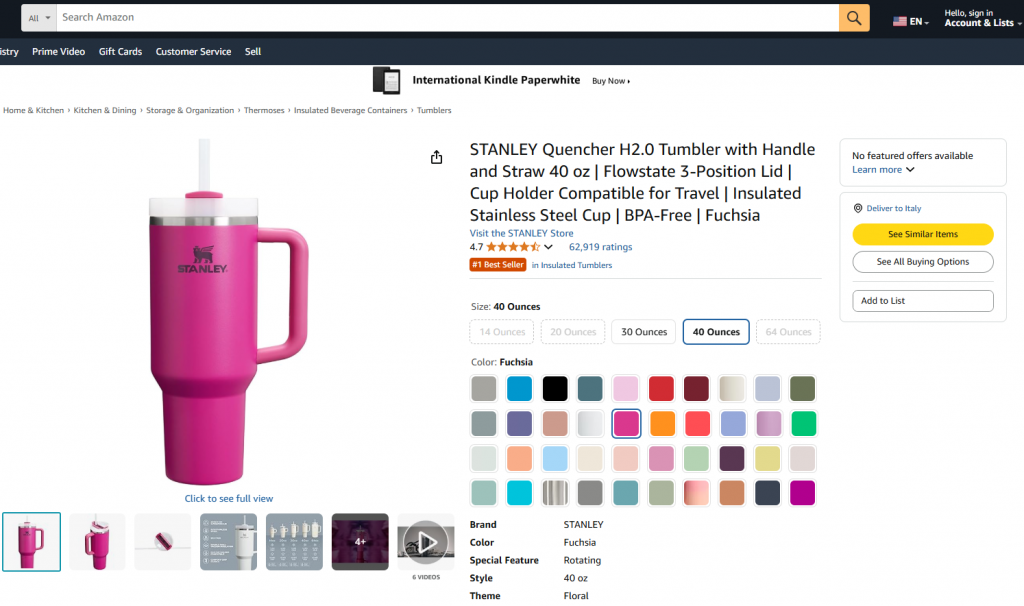
目标是向你展示如何创建一个 Pipedream 工作流,其将执行以下操作:
- 使用 Bright Data 集成从目标网页检索数据。
- 将数据送入一个大语言模型(LLM)。
- 让 LLM 分析数据并基于此生成产品摘要。
按照以下步骤学习如何在 Pipedream 中创建、测试并部署该工作流。
前置条件
要复现本教程,你需要:
- 一个Pipedream 账号(免费账号即可)。
- 一个Bright Data API 密钥。
- 一个OpenAI API 密钥。
如果你还没有,请通过上述链接并按指引完成设置。
另外,具备如下知识将有助于你更好地跟进教程:
- 熟悉 Bright Data 的基础设施与产品(尤其是Web Scraper API)。
- 对 AI 处理有基本理解(如 LLM)。
- 了解触发器与基于 Webhook 的 API 调用如何运作。
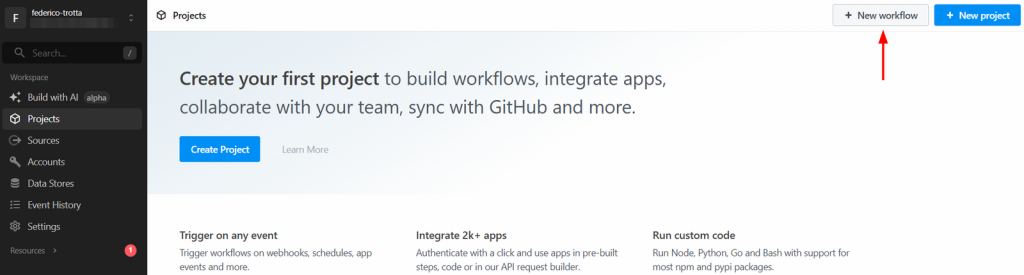
步骤一:创建新的 Pipedream 工作流
登录你的 Pipedream 账号并进入控制台。点击“New workflow”按钮创建新工作流:
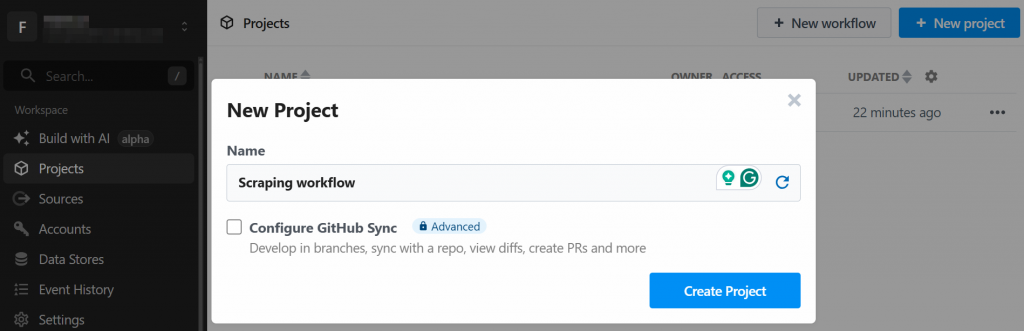
系统会要求你创建一个新项目。为其命名并点击“Create Project”:
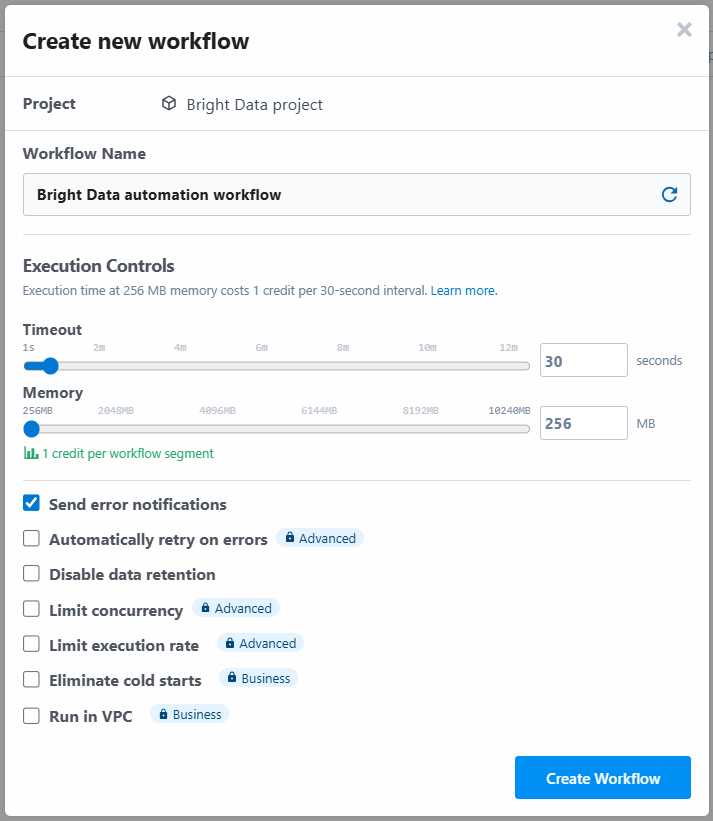
接着需要为工作流命名并配置设置。可保持默认设置,最后点击“Create Workflow”:
你的新工作流界面如下所示:
很好!你已在 Pipedream 中创建了新工作流。现在可以为其添加插件集成。
步骤二:添加触发器
在 Pipedream 中,每个工作流都以触发器开始。点击“Add trigger”将显示可选触发器:
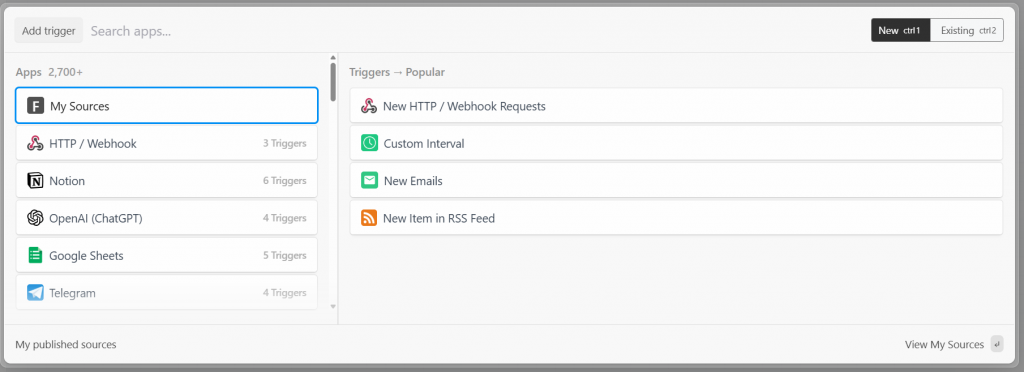
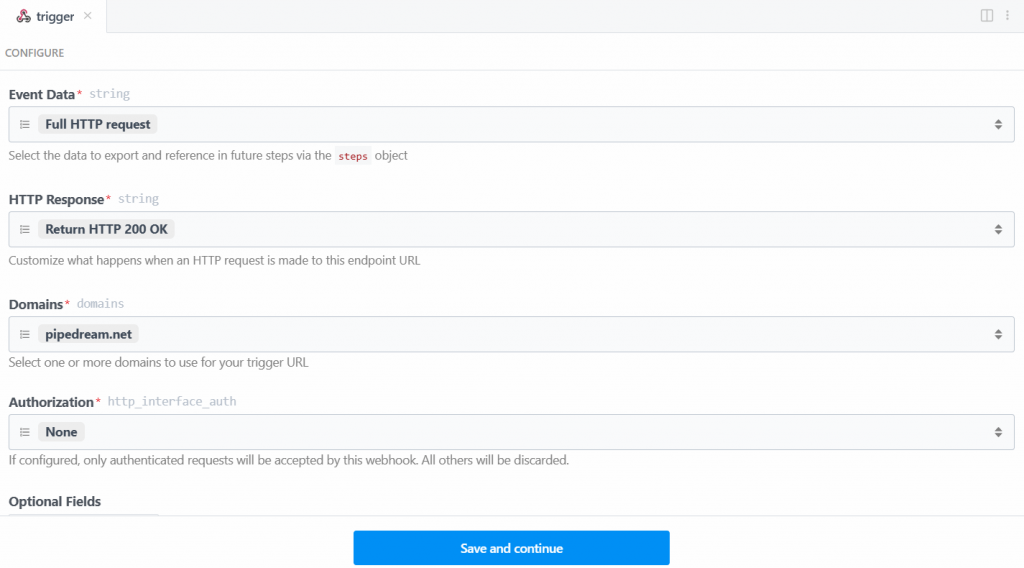
这里选择“New HTTP/Webhook Requests”触发器,它是连接 Bright Data 所需的。保持占位数据不变,然后点击“Save and continue”:
要让触发器生效,需要生成一个事件。点击“Generate Test Event”:
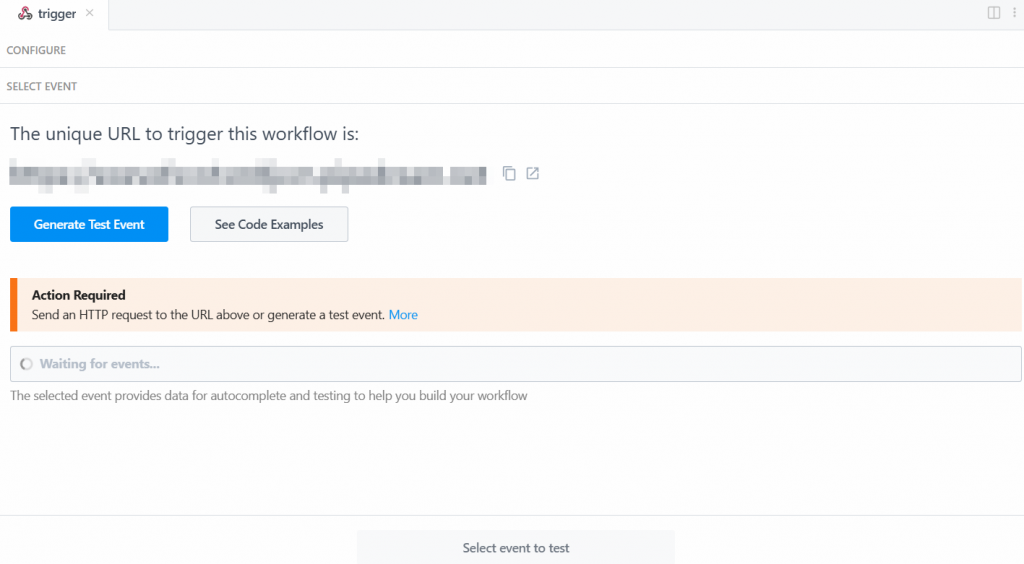
系统会提供如下预设测试事件值:
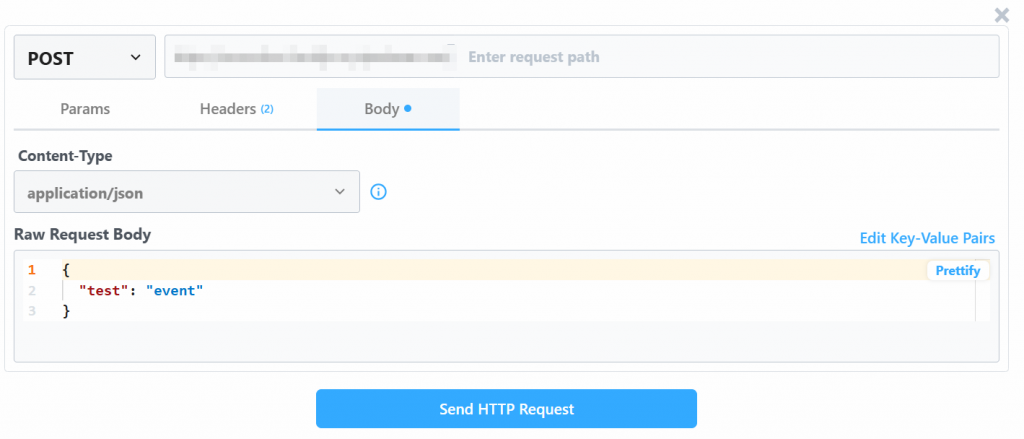
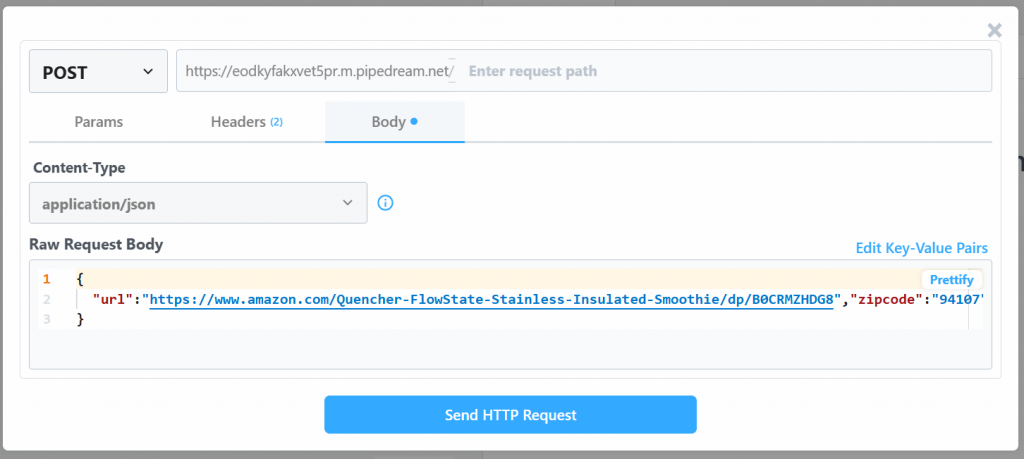
将“Raw Request Body”值替换为:
{
"url": "https://www.amazon.com/Quencher-FlowState-Stainless-Insulated-Smoothie/dp/B0CRMZHDG8",
"zipcode": "94107",
"language": ""
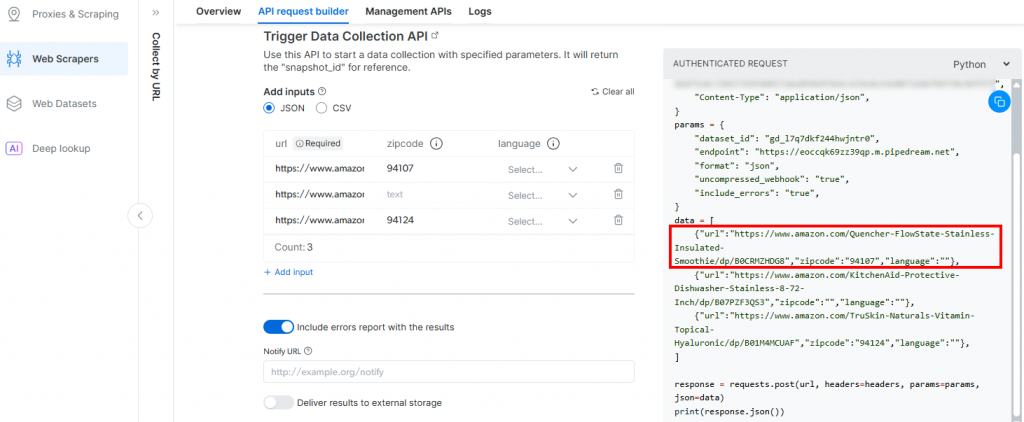
}原因是,Pipedream 生成的触发器将发起对Bright Data 的 Amazon 抓取 API的调用。该端点(稍后将配置)需要以上述特定负载格式提供输入数据。你可以在 Bright Data 的 Amazon Web Scrapers 中“按 URL 采集”爬虫的“API Request Builder”部分进行验证:
回到 Pipedream 窗口,完成后点击“Send HTTP Request”。若一切正常,你将在结果区域看到成功消息,触发器也会变为绿色:
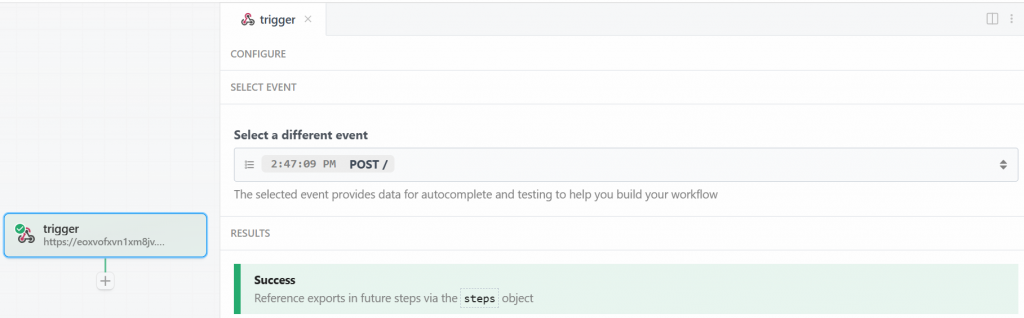
很好!用于在 Pipedream 爬取工作流中启动 Bright Data 集成的触发器已正确设置。现在可以添加一个动作步骤。
步骤三:添加 Bright Data 动作步骤
在触发器之后,你可以在 Pipedream 工作流中添加一个动作步骤。此处你需要将 Bright Data 步骤与触发器连接。为此,点击触发器下方的“+”,搜索“bright data”:
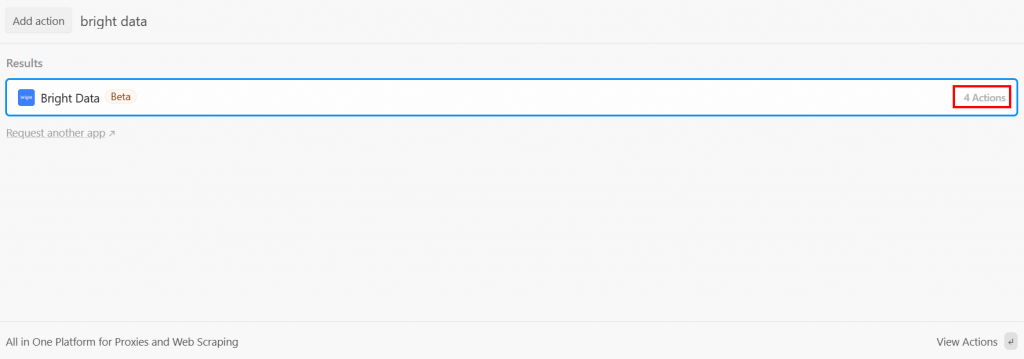
Pipedream 提供来自 Bright Data 插件的多个动作。选中以查看全部:
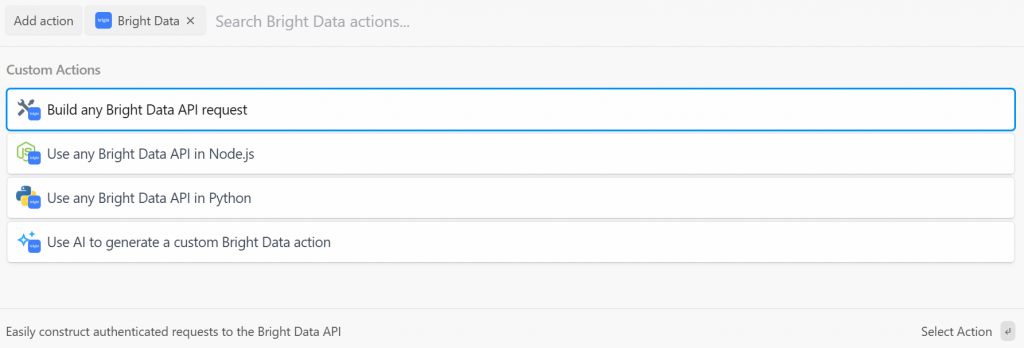
可选项包括:
- Build any Bright Data API request:创建到 Bright Data API 的已认证请求。
- Use any Bright Data API in Node.js/Python:将你的 Bright Data 账号连接到 Pipedream,并在 Node.js/Python 中自定义请求。
- Use AI to generate a custom Bright Data action:让 AI 生成 Bright Data 的自定义代码。
本教程中,选择“Use any Bright Data API in Python”。你将看到:
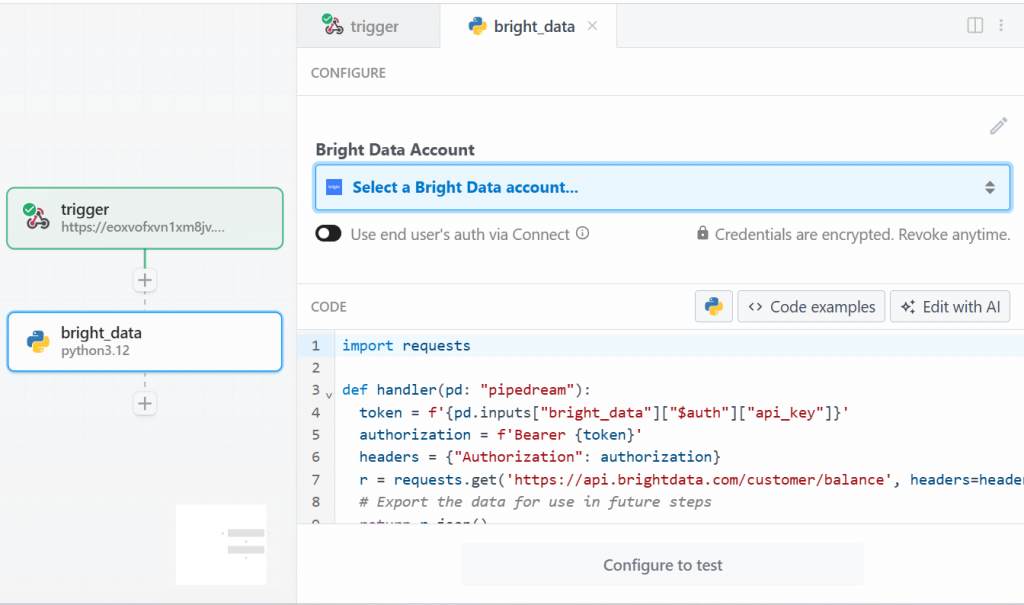
首先,在“Bright Data Account”的“Select a Bright Data account”处添加你的 Bright Data API 密钥。若尚未创建,请参照官方指南配置 Bright Data API 密钥。
然后,删除“CODE”区域中的代码,改为如下内容:
import requests
import json
import time
def handler(pd: "pipedream"):
# Retrieve the Bright Data API key from Pipedream's authenticated accounts
api_key = pd.inputs["bright_data"]["$auth"]["api_key"]
# Get the target Amazon product URL from the trigger data
amazon_product_url = pd.steps["trigger"]["event"]["body"]["url"]
# Configure the Bright Data API request
brightdata_api_endpoint = "https://api.brightdata.com/datasets/v3/trigger"
params = { "dataset_id": "gd_l7q7dkf244hwjntr0", "include_errors": "true" }
payload_data = [{"url": amazon_product_url}]
headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" }
# Initiate the data collection job
print(f"Triggering Bright Data dataset with URL: {amazon_product_url}")
trigger_response = requests.post(brightdata_api_endpoint, headers=headers, params=params, json=payload_data)
# Check if the trigger request was successful
if trigger_response.status_code == 200:
response_json = trigger_response.json()
# Extract the snapshot ID, which is needed to poll for results.
snapshot_id = response_json.get("snapshot_id")
# Handle cases where the trigger is successful but no snapshot ID is provided
if not snapshot_id:
print("Trigger successful, but no snapshot_id was returned.")
return {"error": "Trigger successful, but no snapshot_id was returned.", "response": response_json}
# Begin polling for the completed snapshot using its ID
print(f"Successfully triggered. Snapshot ID is {snapshot_id}. Now starting to poll for results.")
final_scraped_data = poll_and_retrieve_snapshot(api_key, snapshot_id)
# Return the final scraped data from the workflow
return final_scraped_data
else:
# If the trigger failed, log the error and exit the Pipedream workflow
print(f"Failed to trigger. Error: {trigger_response.status_code} - {trigger_response.text}")
pd.flow.exit(f"Error: Failed to trigger Bright Data scrape. Status: {trigger_response.status_code}")
def poll_and_retrieve_snapshot(api_key, snapshot_id, polling_timeout=20):
# Construct the URL for the specific snapshot
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
# Set the authorization header for the API request
headers = { "Authorization": f"Bearer {api_key}" }
print(f"Polling snapshot for ID: {snapshot_id}...")
# Loop until the snapshot is ready
while True:
response = requests.get(snapshot_url, headers=headers)
# If status is 200, the data is ready
if response.status_code == 200:
print("Snapshot is ready. Returning data...")
return response.json()
# If status is 202, the data is not ready yet. Wait and retry
elif response.status_code == 202:
print(f"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
# If any other status code is received, an error occurred.
else:
print(f"Polling failed! Error: {response.status_code}")
print(response.text)
return {"error": "Polling failed", "status_code": response.status_code, "details": response.text}这段代码实现了以下功能:
handler()函数在 Pipedream 层面管理工作流,具体:- 检索你在 Pipedream 中存储的 Bright Data API 密钥。
- 根据目标 URL、数据集 ID 及相关所需数据配置 Bright Data API 请求。
- 处理响应。若出现问题,你可以在 Pipedream 的日志中看到错误信息。
poll_and_retrieve_snapshot()函数轮询 Bright Data API 的快照直到其就绪。就绪后返回所请求的数据。若出现问题,将进行错误处理并在日志中展示。
准备好后,点击“Test”按钮。你会在“RESULTS”区域看到成功消息,Bright Data 动作步骤也会变为绿色:
在“RESULTS”下的“Exports”区域可以查看到爬取的数据:
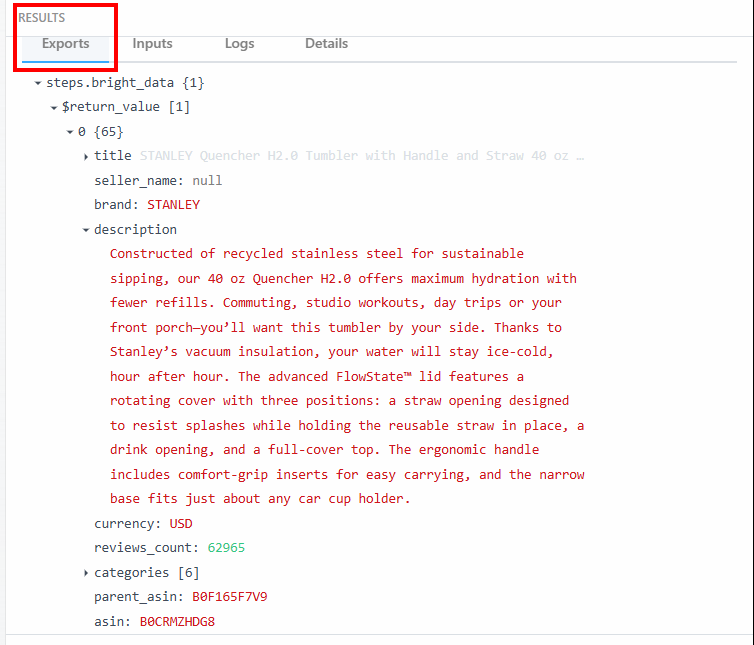
以下为文本形式展示的爬取数据:
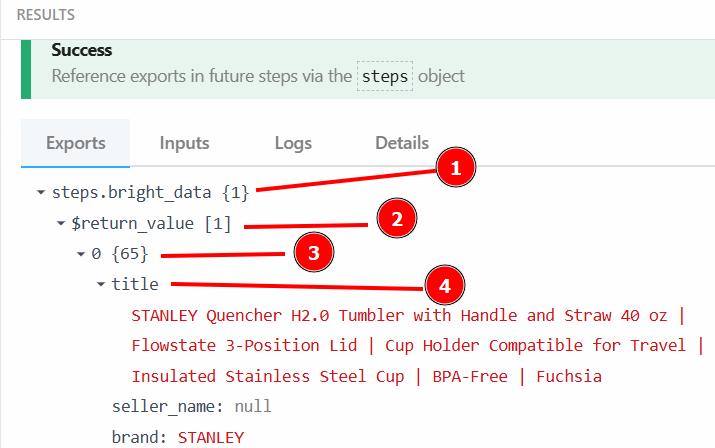
steps.bright_data{
$return_value{
0{
"title":"STANLEY Quencher H2.0 Tumbler with Handle and Straw 40 oz | Flowstate 3-Position Lid | Cup Holder Compatible for Travel | Insulated Stainless Steel Cup | BPA-Free | Fuchsia",
"seller_name":"null",
"brand":"STANLEY",
"description":"Constructed of recycled stainless steel for sustainable sipping, our 40 oz Quencher H2.0 offers maximum hydration with fewer refills. Commuting, studio workouts, day trips or your front porch—you’ll want this tumbler by your side. Thanks to Stanley’s vacuum insulation, your water will stay ice-cold, hour after hour. The advanced FlowState™ lid features a rotating cover with three positions: a straw opening designed to resist splashes while holding the reusable straw in place, a drink opening, and a full-cover top. The ergonomic handle includes comfort-grip inserts for easy carrying, and the narrow base fits just about any car cup holder.",
"currency":"USD",
"reviews_count":"62965",
..OMITTED FOR BREVITY...
}
}
}你将在工作流的下一步中使用这些数据及其结构。
很好!你已通过 Pipedream 中的 Bright Data 动作成功爬取了目标数据。
步骤四:添加 OpenAI 动作步骤
亚马逊商品数据已由 Bright Data 集成成功爬取。现在可以将其输入到 LLM。为此,点击“+”添加新动作并搜索“openai”。此处有多种选项:

选择“Build any OpenAI (ChatGPT) API request”,然后选择“Chat”选项:
以下为该动作步骤的配置区域:
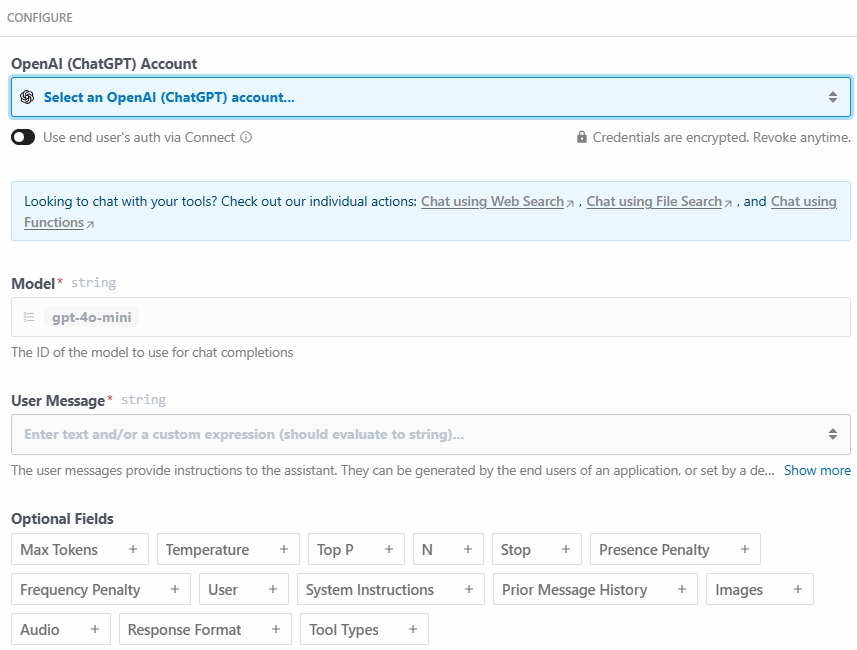
点击“Select an OpenAI (ChatGPT) account…”添加你的 OpenAI 平台 API 密钥。然后在“User Message”区域写入以下提示词:
Act as an expert product analyst. Consider the following data from an Amazon product page:
PRODUCT TITLE:
{{steps.bright_data.$return_value[0].title}}
BRAND:
{{steps.bright_data.$return_value[0].brand}}
DESCRIPTION:
{{steps.bright_data.$return_value[0].description}}
REVIEWS COUNT
{{steps.bright_data.$return_value[0].reviews_count}}
Based on this data, provide a concise summary of the product that should entice potential customers to buy it. The summary should include what the product is, and its most important features.该提示词要求 LLM:
- 扮演资深产品分析师。这能让 LLM 按行业专家的方式思考并输出,更贴合场景。
- 基于 Bright Data 步骤提取的数据(如产品标题与描述),使其聚焦于你需要的具体信息。
- 根据爬取数据生成产品摘要,并明确摘要需包含的内容。这能体现 AI 自动化在产品摘要上的价值:LLM 将基于爬取数据、以专家身份生成摘要。
之所以可以通过 {{steps.bright_data.$return_value[0].title}} 获取产品标题,是因为上一环节中 Bright Data 动作步骤的输出数据结构如下:
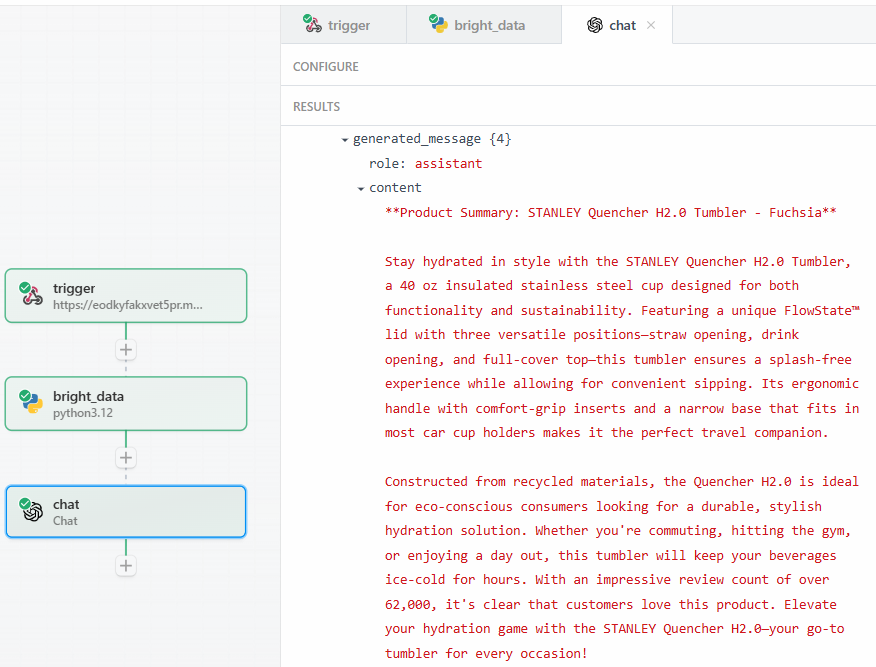
点击“Test”后,在 OpenAI Chat 动作步骤的“RESULTS”区域下“Generated message” > “content”可查看 LLM 的输出:
以下是一个可能的文本结果:
**Product Summary: STANLEY Quencher H2.0 Tumbler - Fuchsia**
Stay hydrated in style with the STANLEY Quencher H2.0 Tumbler, a 40 oz insulated stainless steel cup designed for both functionality and sustainability. Featuring a unique FlowState™ lid with three versatile positions—straw opening, drink opening, and full-cover top—this tumbler ensures a splash-free experience while allowing for convenient sipping. Its ergonomic handle with comfort-grip inserts and a narrow base that fits in most car cup holders makes it the perfect travel companion.
Constructed from recycled materials, the Quencher H2.0 is ideal for eco-conscious consumers looking for a durable, stylish hydration solution. Whether you're commuting, hitting the gym, or enjoying a day out, this tumbler will keep your beverages ice-cold for hours. With an impressive review count of over 62,000, it's clear that customers love this product. Elevate your hydration game with the STANLEY Quencher H2.0—your go-to tumbler for every occasion!如你所见,LLM 以产品专家的身份提供了产品摘要,并准确覆盖了提示词要求的内容:
- 产品是什么。
- 其若干重要特性。
之所以要提取精确的数据(如评分/评价数量),是为了确保 LLM 不会产生幻觉。摘要中称评价数量超过 62,000。若你想查看确切数字,可在结果中的“content”字段下进行核对:
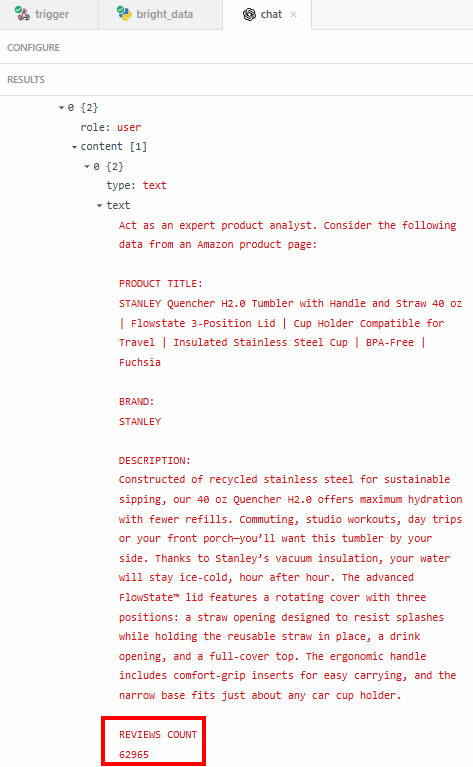
然后再核对该数字是否与亚马逊商品页面上显示的一致。
最后,如果你曾尝试爬取像亚马逊这样的主流电商网站,就会知道自行完成有多难。例如,你可能会遇到臭名昭著的亚马逊验证码,它能阻止大多数爬虫:
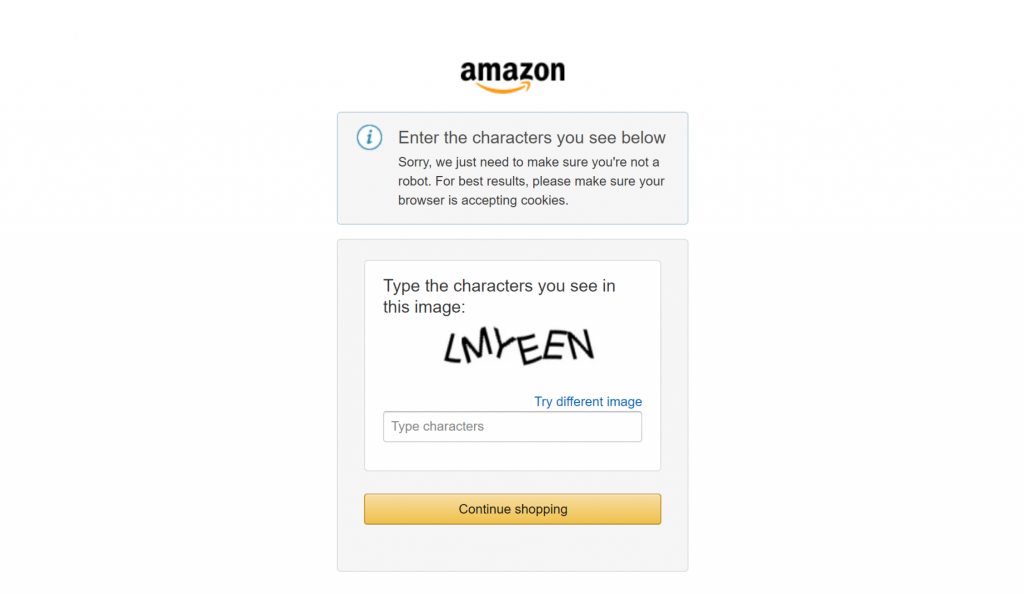
这正是 Bright Data 集成能在你的爬取工作流中发挥关键作用的地方。它在幕后处理所有反爬措施,确保数据获取过程顺畅可靠。
太棒了!你已成功测试 LLM 步骤。现在可以部署该工作流。
步骤五:部署工作流
要部署工作流,点击任意一个“Deploy”按钮:
部署后你将看到如下界面:
要运行整个工作流,点击“Generate Event”:
点击“Send HTTP Request”以触发工作流,随后它将完整运行。要查看已部署工作流的结果,请在首页进入“Events history”。选择感兴趣的工作流,并在“Exports”下查看结果:
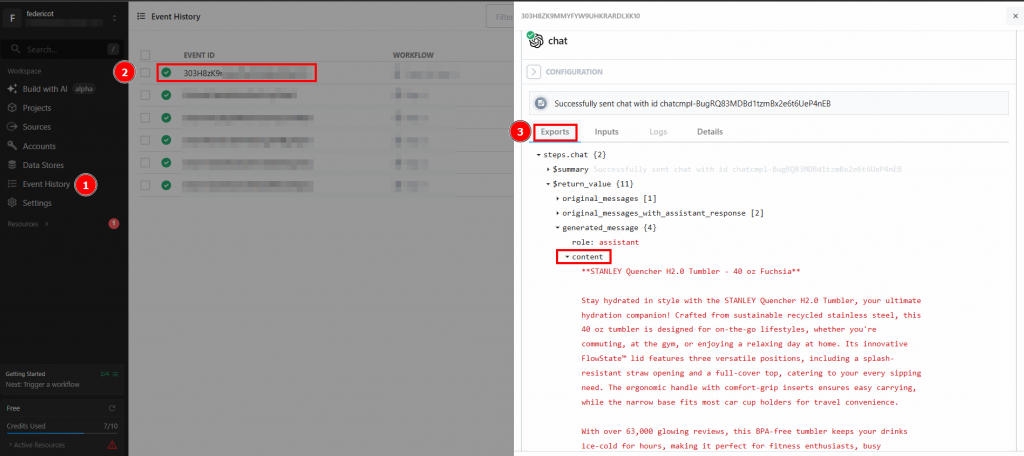
大功告成!你已使用 Bright Data 在 Pipedream 中创建并部署了首个爬取工作流。
结语
通过本指南,你学会了如何使用 Pipedream 构建自动化网页爬取工作流。你亲眼见证了该平台直观的界面如何与 Bright Data 的爬取集成相结合,从而在数分钟内搭建出复杂的爬取流水线。
任何数据驱动自动化的首要挑战都是确保连续不断的、干净可靠的数据流。Pipedream 提供自动化与调度引擎,而Bright Data 的 AI 基础设施处理网页爬取的复杂性并交付可直接使用的数据。二者的协同让你能专注于从数据中创造价值,而不是被获取数据的技术难题所束缚。
创建一个免费的 Bright Data 账号,立即开始体验我们的 AI 就绪数据工具吧!



技术写作者
 3 years experience
3 years experience
Federico Trotta 是一名技术写作者、编辑和数据科学家。擅长技术内容管理、数据分析、机器学习和 Python 开发。





