

在本指南中,你将了解:
- NVIDIA NeMo 框架提供了什么,特别是如何使用 NVIDIA NeMo Agent Toolkit 构建 AI 智能体。
- 如何通过 LangChain 自定义工具,将 Bright Data 集成到 NAT AI 智能体中。
- 如何将 NVIDIA NeMo Agent Toolkit 工作流连接到 Bright Data Web MCP。
让我们开始吧!
NVIDIA NeMo 框架简介
NVIDIA NeMo 框架是一套完整的云原生 AI 开发平台,用于构建、定制和部署生成式 AI 模型,包括大语言模型(LLM)和多模态模型。
它为整个 AI 生命周期提供端到端工具——从训练、微调到评估和部署。NeMo 还支持大规模分布式训练,并内置用于数据整理、模型评估以及安全防护规则(guardrails)等任务的组件。
该框架由开源的Python 库(GitHub Star 数超过 16k)和专用 Docker 镜像提供支持。
NVIDIA NeMo Agent Toolkit
作为 NVIDIA NeMo 框架的一部分,NVIDIA NeMo Agent Toolkit(简称 “NAT”)是一个开源框架,用于构建、优化和管理复杂的 AI 智能体系统。
它帮助你将不同的智能体和工具连接成统一的工作流,并具备深度可观测性、性能分析和成本分析能力,充当多智能体操作的“指挥家”,帮助 AI 应用扩展规模。
NAT 强调可组合性,将智能体和工具视作模块化函数调用。同时,它还提供识别瓶颈、自动化评估以及管理企业级智能体 AI 系统的能力。
更多信息可参考:
使用 Bright Data 工具打通 LLM 与实时数据
NVIDIA NeMo Agent Toolkit 提供了构建和管理企业级 AI 项目所需的灵活性、定制性、可观测性和可扩展性。它使组织能够编排复杂的 AI 工作流、连接多个智能体,并监控性能和成本。
然而,即便是最先进的 NAT 应用也要面对 LLM 的固有限制,包括由于静态训练数据导致的知识陈旧,以及缺乏对实时网页信息的访问能力。
解决方案是将你的 NVIDIA NeMo Agent Toolkit 工作流与面向 AI 的网页数据提供方(如 Bright Data)集成。
Bright Data 提供网页抓取、搜索、浏览器自动化等工具。这些解决方案能够让你的 AI 系统获取实时、可执行的数据,为企业级应用释放全部潜力!
如何将 Bright Data 连接到 NVIDIA NeMo AI 智能体
利用 Bright Data 能力的一个方式,是在 NVIDIA NeMo AI 智能体中通过 NeMo Agent Toolkit 创建自定义工具。
这些工具将通过 LangChain(或其他任意已支持的 AI 智能体构建库集成方案)驱动的自定义函数连接 Bright Data 产品。
按如下步骤操作!
前提条件
要跟随本教程,你需要:
- 本地安装 Python 3.11、3.12 或 3.13。
- 一个用于集成官方 LangChain 工具的Bright Data 账户。
- 一个已配置 API 密钥的 NVIDIA NIM 账户。
暂时不必着急配置 Bright Data 和 NVIDIA NIM 账户,后续章节会有专门说明。
注意:如果在安装或运行工具包时遇到问题,请确认你使用的是受支持的平台之一。
步骤 1:获取你的 NVIDIA NIM API 密钥
大多数 NVIDIA NeMo Agent 工作流需要 NVIDIA_API_KEY 环境变量。它用于为工作流背后的 NVIDIA NIM LLM 连接进行身份验证。
要获取 API 密钥,首先创建一个NVIDIA NIM 账户(如果你尚未注册)。登录后,点击右上角的账户头像,选择 “API Keys” 选项:
你将进入 API Keys 页面。点击 “Generate API Key” 按钮创建新的密钥:
为你的 API 密钥命名,然后点击 “Generate Key”:
弹窗将显示你的 API 密钥。点击 “Copy API Key” 按钮并将密钥安全保存,你很快就会用到它。
完成!接下来你就可以安装 NVIDIA NeMo Agent Toolkit 并开始使用。
步骤 2:创建 NVIDIA NeMo 项目
要安装最新稳定版 NeMo Agent Toolkit,运行:
pip install nvidia-natNeMo Agent Toolkit 有许多可选依赖,可与核心包一起安装,这些依赖按不同框架分组。
安装完成后,你应该可以使用 nat 命令。通过运行以下命令进行验证:
nat --version你应看到类似输出:
nat, version 1.3.1接着,为你的 NVIDIA NeMo 应用创建一个根目录,例如命名为 “bright_data_nvidia_nemo”:
mkdir bright_data_nvidia_nemo在该目录下,通过以下命令创建名为 “web_data_workflow” 的 NeMo Agent 工作流:
nat workflow create --workflow-dir bright_data_nvidia_nemo web_data_workflow 注意:如果遇到 “A required privilege is not held by the client” 错误,请以管理员身份运行命令。
如果成功,你会看到类似日志:
Installing workflow 'web_data_workflow'...
Workflow 'web_data_workflow' installed successfully.
Workflow 'web_data_workflow' created successfully in <your_path>此时项目目录 bright_data_nvidia_nemo/web_data_workflow 将具有如下结构:
bright_data_nvidia_nemo/web_data_workflow/
├── configs -> src/web_data_workflow/configs
├── data -> src/text_file_ingest/data
├── pyproject.toml
└── src/
├── web_data_workflow.egg-info/
└── web_data_workflow/
├── __init__.py
├── configs/
│ └── config.yml
├── data/
├── __init__.py
├── register.py
└── web_data_workflow.py各文件与文件夹含义如下:
configs/→src/web_data_workflow/configs:工作流配置的符号链接,便于访问。data/→src/text_file_ingest/data:用于存放示例数据或输入文件的符号链接。pyproject.toml:项目元数据与依赖文件。src/:源代码目录。web_data_workflow.egg-info/:由 Python 打包工具创建的元数据文件夹。web_data_workflow/:主工作流模块。__init__.py:模块初始化文件。configs/config.yml:工作流配置文件,用于定义运行时行为(LLM 配置、函数/工具定义、智能体类型和参数、工作流编排等)。
data/:用于存放工作流专用数据、示例输入或测试文件。register.py:用于将自定义函数注册到 NAT 的模块。web_data_workflow.py:定义自定义工具的样例文件。
用你喜欢的 Python IDE 打开该项目,并花点时间熟悉这些自动生成的文件。
你会看到,工作流定义位于以下文件中:
bright_data_nvidia_nemo/web_data_workflow/web_data_workflow/configs/config.yml打开后,你会看到如下 YAML 配置:
functions:
current_datetime:
_type: current_datetime
web_data_workflow:
_type: web_data_workflow
prefix: "Hello:"
llms:
nim_llm:
_type: nim
model_name: meta/llama-3.1-70b-instruct
temperature: 0.0
workflow:
_type: react_agent
llm_name: nim_llm
tool_names: [current_datetime, web_data_workflow]这定义了一个由 meta/llama-3.1-70b-instruct NVIDIA NIM 模型驱动的ReAct 智能体工作流,该模型拥有访问以下工具的能力:
- 内置工具
current_datetime。 - 自定义工具
web_data_workflow。
其中,web_data_workflow 工具本身定义在:
bright_data_nvidia_nemo/web_data_workflow/web_data_workflow/web_data_workflow.py示例工具接收文本输入,并返回加上预定义前缀字符串(如 "Hello:")后的结果。
很好!你已经使用 NAT 创建好了一个工作流。
步骤 3:测试当前工作流
在定制自动生成的工作流之前,建议先花点时间熟悉它的运行方式。这样在后续集成 Bright Data 时会更加顺畅。
首先在终端中进入工作流目录:
cd ./bright_data_nvidia_nemo/web_data_workflow运行工作流前,需要设置 NVIDIA_API_KEY 环境变量。在 Linux/macOS 上,运行:
export NVIDIA_API_KEY="<YOUR_NVIDIA_API_KEY>"在 Windows PowerShell 中等效命令为:
$Env:NVIDIA_API_KEY="<YOUR_NVIDIA_API_KEY>"将 <YOUR_NVIDIA_API_KEY> 替换为之前获取的 NVIDIA NIM API 密钥。
现在,通过以下命令测试工作流:
nat run --config_file configs/config.yml --input "Hey! How's it going?"该命令会加载 config.yml 文件(通过 configs/ 符号链接)并发送提示词 "Hey! How's it going?"。
你应该看到类似如下输出: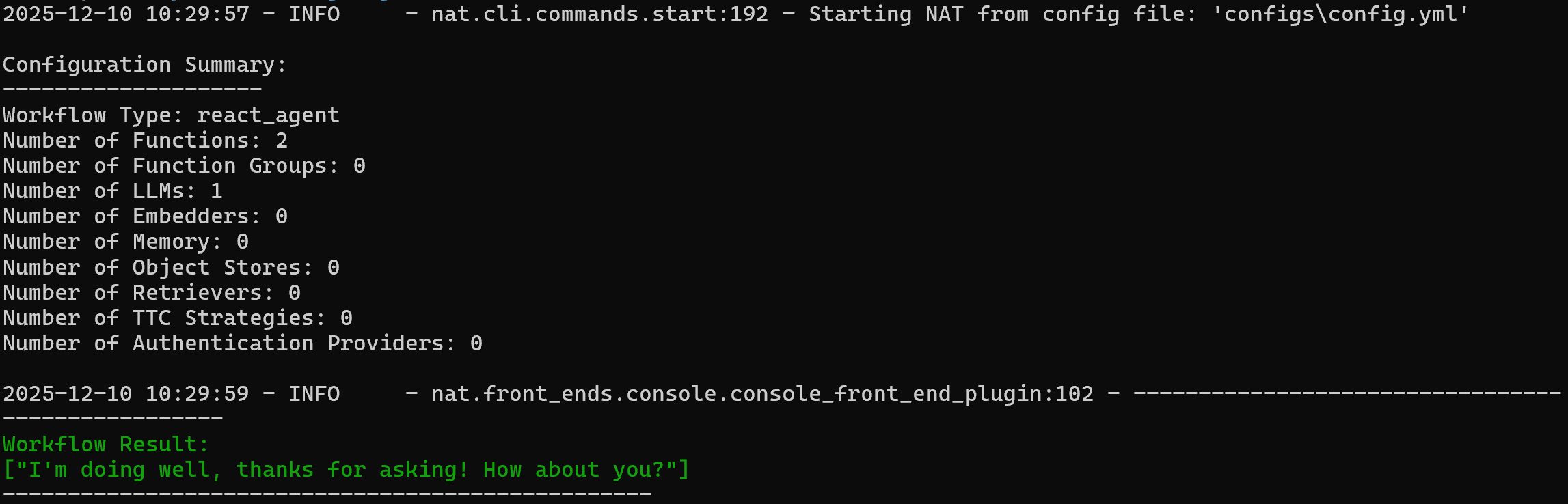
注意智能体的回复为:
I'm doing well, thanks for asking! How about you?要验证自定义 web_data_workflow 工具是否工作,尝试如下命令:
nat run --config_file configs/config.yml --input "Use the web_data_workflow tool on 'World!'"由于 web_data_workflow 工具配置了 "Hello:" 作为前缀,预期输出为:
Workflow Result:
['Hello: World!']可以看到结果与预期行为一致: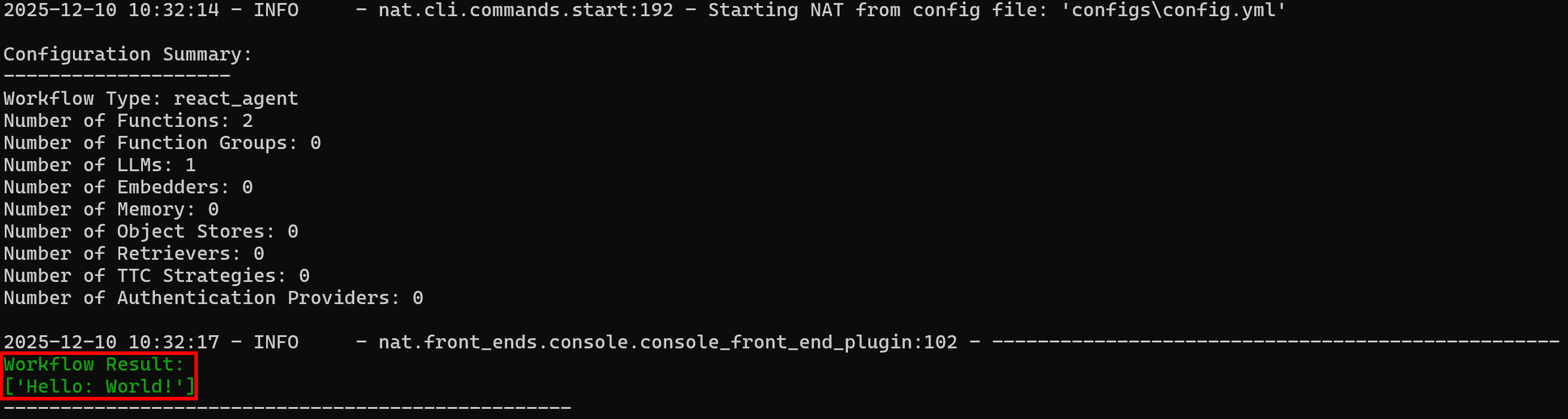
非常好!你的 NAT 工作流运行正常,现已具备与 Bright Data 集成的基础。
步骤 4:安装 LangChain Bright Data 工具
NVIDIA NeMo Agent Toolkit 的一个重要特点是它可以与其他 AI 库协同工作,包括 LangChain、LlamaIndex、CrewAI、Agno、Microsoft Semantic Kernel、Google ADK,以及许多其它框架。
为了简化与 Bright Data 的集成,我们不会重复造轮子,而是直接使用官方的 Bright Data LangChain 工具。
关于这些工具的更多说明,可参考官方文档或以下博客文章:
为在 NVIDIA NeMo Agent Toolkit 中使用 LangChain,安装以下库:
pip install "nvidia-nat[langchain]" langchain-brightdata所需包包括:
"nvidia-nat[langchain]":用于将 LangChain(或 LangGraph)集成进 NeMo Agent Toolkit 的子包。langchain-brightdata:为 Bright Data 的网页数据采集工具套件提供 LangChain 集成,使 AI 智能体能够采集搜索引擎结果、访问地理受限或有反爬虫保护的网站,并从 Amazon、LinkedIn 等热门平台提取结构化数据。
为避免部署时出现依赖问题,请确保项目 pyproject.toml 文件包含:
dependencies = [
"nvidia-nat[langchain]~=1.3",
"langchain-brightdata~=0.1.3",
]注意:可根据你的项目需求适当调整这些包的版本。
很好!你的 NVIDIA NeMo Agent 工作流现已可以与 LangChain 工具集成,从而更方便地连接 Bright Data。
步骤 5:准备 Bright Data 集成
LangChain Bright Data 工具通过连接你账户中配置好的 Bright Data 服务来工作。本文展示的两个工具为:
BrightDataSERP:抓取搜索引擎结果,用于定位相关的法规网页。该工具连接到 Bright Data 的 SERP API。BrightDataUnblocker:访问任何公共网站,即便存在地理限制或反爬虫保护。帮助智能体从页面中抓取内容并进行学习,它连接到 Bright Data 的 Web Unblocker API。
要使用这些工具,你需要一个 Bright Data 账户,并配置好 SERP API 区(zone)和 Web Unblocker API 区。下面进行设置。
如果你还没有 Bright Data 账户,请创建新账户。否则登录并进入仪表盘。然后前往 “Proxies & Scraping” 页面,查看 “My Zones” 表格: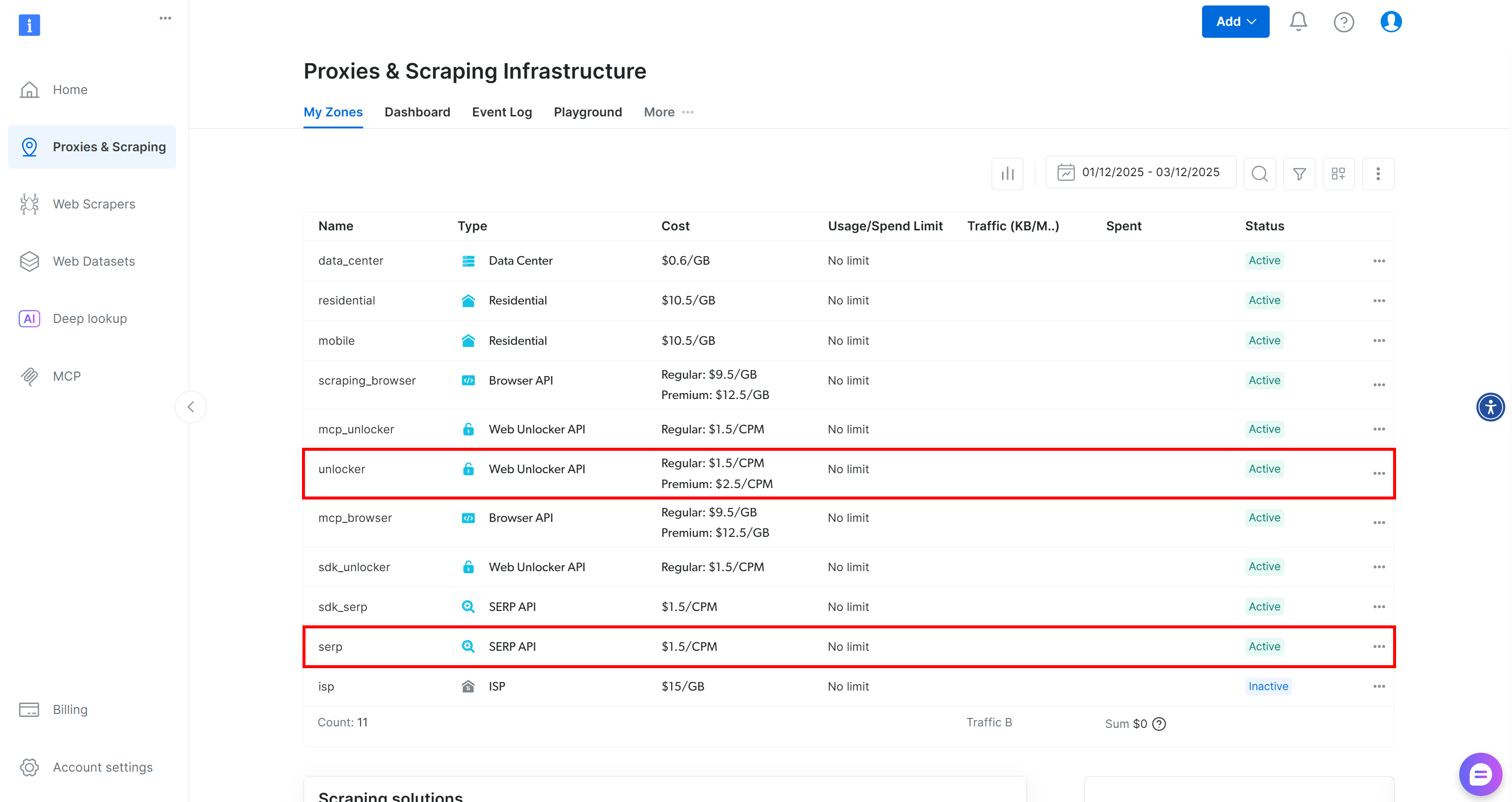
如果表格中已存在名为 unlocker 的 Web Unblocker API 区以及名为 serp 的 SERP API 区,则你已准备就绪。原因如下:
- LangChain 工具
BrightDataSERP会自动连接名为serp的 SERP API 区。 - LangChain 工具
BrightDataUnblocker会自动连接名为web_unlocker的 Web Unblocker API 区。
如果缺少这些区域,你需要创建它们。向下滚动到 “Unblocker API” 和 “SERP API” 卡片,点击 “Create zone” 按钮,并根据向导创建具备所需名称的两个区域: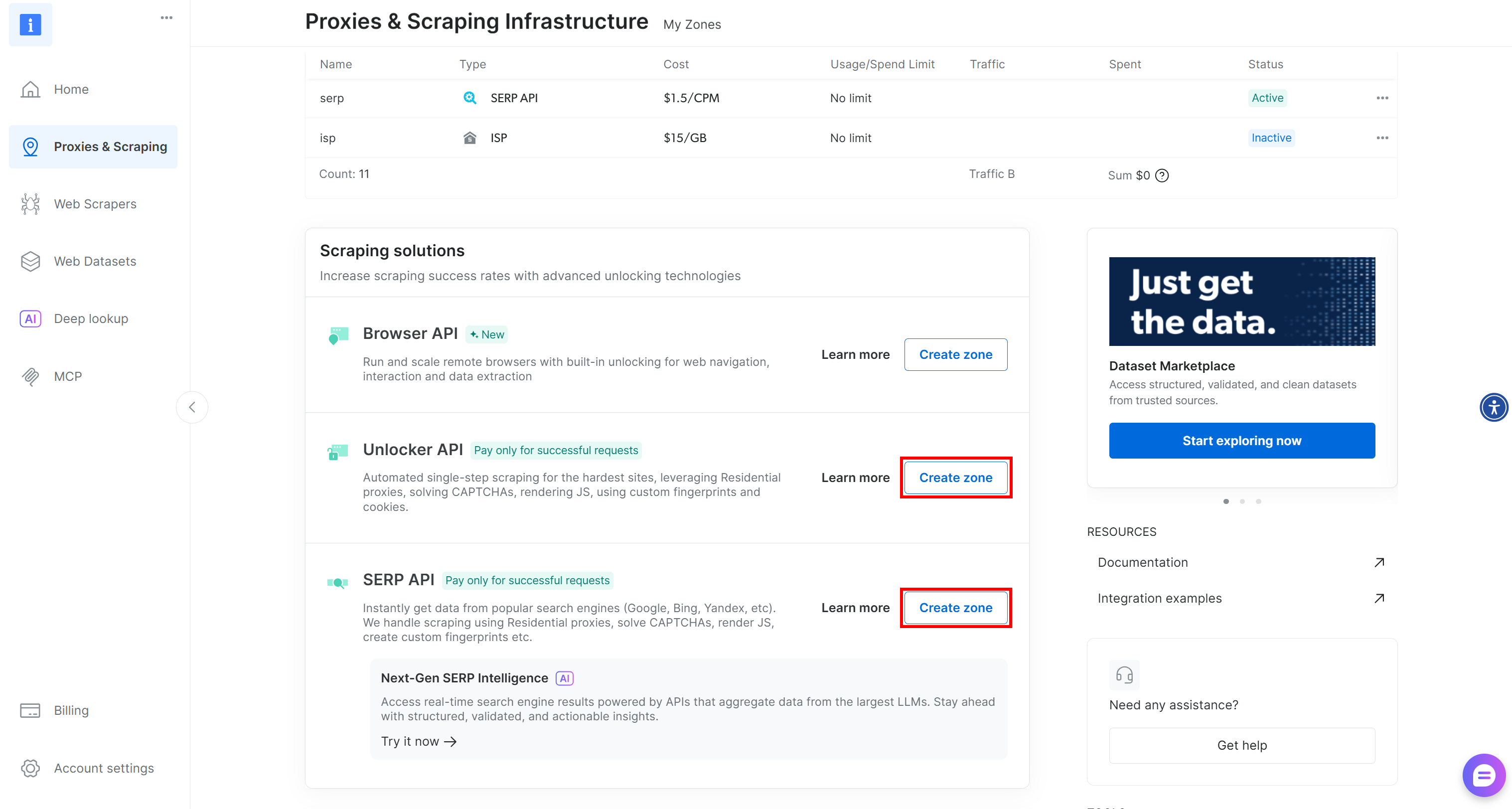
详细步骤可以参考以下文档:
最后,你需要告诉 LangChain Bright Data 工具如何使用你的账户进行身份验证。生成 Bright Data API 密钥并将其设置为环境变量:
export BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"在 PowerShell 中:
$Env:BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"现在一切就绪,你已经具备了通过 LangChain 工具将 NVIDIA NeMo 智能体连接到 Bright Data 的全部前提条件。
步骤 6:定义自定义 Bright Data 工具
到目前为止,你已经具备了在 NVIDIA NeMo Agent Toolkit 工作流中创建新工具的所有基础。这些工具将让智能体与 Bright Data 的 SERP API 和 Web Unblocker API 交互,从而实现网页搜索和任意公开网页的数据抓取。
首先,在项目的 src/ 文件夹下添加一个 bright_data.py 文件:
按如下方式定义一个与 SERP API 交互的自定义工具:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/bright_data.py
from pydantic import Field
from typing import Optional
from nat.builder.builder import Builder
from nat.builder.function_info import FunctionInfo
from nat.cli.register_workflow import register_function
from nat.data_models.function import FunctionBaseConfig
import json
class BrightDataSERPAPIToolConfig(FunctionBaseConfig, name="bright_data_serp_api"):
"""
Configuration for Bright Data SERP API tool.
Requires BRIGHT_DATA_API_KEY.
"""
api_key: str = Field(
default="",
description="Your Bright Data API key used for SERP requests."
)
# Default SERP parameters (optional overrides)
search_engine: str = Field(
default="google",
description="Search engine to query (default: google)."
)
country: str = Field(
default="us",
description="Two-letter country code for localized results (default: us)."
)
language: str = Field(
default="en",
description="Two-letter language code (default: en)."
)
search_type: Optional[str] = Field(
default=None,
description="Type of search: None, 'shop', 'isch', 'nws', 'jobs'."
)
device_type: Optional[str] = Field(
default=None,
description="Device type: None, 'mobile', 'ios', 'android'."
)
parse_results: Optional[bool] = Field(
default=None,
description="Whether to return structured JSON instead of raw HTML."
)
@register_function(config_type=BrightDataSERPAPIToolConfig)
async def bright_data_serp_api_function(tool_config: BrightDataSERPAPIToolConfig, builder: Builder):
import os
from langchain_brightdata import BrightDataSERP
# Set API key if missing
if not os.environ.get("BRIGHT_DATA_API_KEY"):
if tool_config.api_key:
os.environ["BRIGHT_DATA_API_KEY"] = tool_config.api_key
async def _bright_data_serp_api(
query: str,
search_engine: Optional[str] = None,
country: Optional[str] = None,
language: Optional[str] = None,
search_type: Optional[str] = None,
device_type: Optional[str] = None,
parse_results: Optional[bool] = None,
) -> str:
"""
Perform a real-time search query using Bright Data SERP API.
Args:
query (str): The search query text.
search_engine (str, optional): Search engine to use (default: google).
country (str, optional): Country code for localized results.
language (str, optional): Language code for localized results.
search_type (str, optional): Search type (e.g., None, 'isch', 'shop', 'nws').
device_type (str, optional): Device type (e.g., None, 'mobile', 'ios').
parse_results (bool, optional): Whether to return structured JSON.
Returns:
str: JSON-formatted search results.
"""
serp_client = BrightDataSERP(
bright_data_api_key=os.environ["BRIGHT_DATA_API_KEY"]
)
payload = {
"query": query,
"search_engine": search_engine or tool_config.search_engine,
"country": country or tool_config.country,
"language": language or tool_config.language,
"search_type": search_type or tool_config.search_type,
"device_type": device_type or tool_config.device_type,
"parse_results": (
parse_results
if parse_results is not None
else tool_config.parse_results
),
}
# Remove parameters explicitly set to None
payload = {k: v for k, v in payload.items() if v is not None}
results = serp_client.invoke(payload)
return json.dumps(results)
yield FunctionInfo.from_fn(
_bright_data_serp_api,
description=_bright_data_serp_api.__doc__,
)上述代码定义了一个名为 bright_data_serp_api 的自定义 NVIDIA NeMo Agent 工具。首先定义 BrightDataSERPAPIToolConfig 类,用于指定 Google SERP API 所支持的必填参数和可配置参数(例如 API 密钥、搜索引擎、国家、语言、设备类型、搜索类型、是否将结果解析为 JSON 等)。
然后注册自定义函数 bright_data_serp_api_function() 作为 NeMo 工作流函数。该函数会检查是否已在环境变量中设置 Bright Data API 密钥,然后定义一个异步函数 _bright_data_serp_api()。
_bright_data_serp_api() 使用 LangChain 的 BrightDataSERP 客户端构造搜索请求,调用后将结果以 JSON 格式返回。最后通过 FunctionInfo 将该函数暴露给 NeMo Agent 框架,其中包含智能体调用该函数所需的所有元数据。
注意:以 JSON 字符串形式返回结果是一种标准化输出的做法,这在 SERP API 可能返回多种数据形式(解析后的 JSON、原始 HTML 等)时尤其实用。
类似地,你可以在同一文件中定义 bright_data_web_unlocker_api 工具:
class BrightDataWebUnlockerAPIToolConfig(FunctionBaseConfig, name="bright_data_web_unlocker_api"):
"""
Configuration for Bright Data Web Unlocker Tool.
Allows accessing geo-restricted or anti-bot-protected pages using
Bright Data Web Unlocker.
Requires BRIGHT_DATA_API_KEY.
"""
api_key: str = Field(
default="",
description="Bright Data API key for the Web Unlocker."
)
country: str = Field(
default="us",
description="Two-letter country code simulated for the request (default: us)."
)
data_format: str = Field(
default="html",
description="Output content format: 'html', 'markdown', or 'screenshot'."
)
zone: str = Field(
default="unblocker",
description='Bright Data zone to use (default: "unblocker").'
)
@register_function(config_type=BrightDataWebUnlockerAPIToolConfig)
async def bright_data_web_unlocker_api_function(tool_config: BrightDataWebUnlockerAPIToolConfig, builder: Builder):
import os
import json
from typing import Optional
from langchain_brightdata import BrightDataUnlocker
# Set environment variable if needed
if not os.environ.get("BRIGHT_DATA_API_KEY") and tool_config.api_key:
os.environ["BRIGHT_DATA_API_KEY"] = tool_config.api_key
async def _bright_data_web_unlocker_api(
url: str,
country: Optional[str] = None,
data_format: Optional[str] = None,
) -> str:
"""
Access a geo-restricted or anti-bot-protected URL using Bright Data Web Unlocker.
Args:
url (str): Target URL to fetch.
country (str, optional): Override the simulated country.
data_format (str, optional): Output content format ('html', 'markdown', 'screenshot').
Returns:
str: The fetched content from the target website.
"""
unlocker = BrightDataUnlocker()
result = unlocker.invoke({
"url": url,
"country": country or tool_config.country,
"data_format": data_format or tool_config.data_format,
"zone": tool_config.zone,
})
return json.dumps(result)
yield FunctionInfo.from_fn(
_bright_data_web_unlocker_api,
description=_bright_data_web_unlocker_api.__doc__,
)可以根据需要调整这两个工具的默认参数值。
请记住,BrightDataSERP 和 BrightDataUnlocker 会尝试从环境变量 BRIGHT_DATA_API_KEY 中读取 API 密钥(你已在前面步骤中完成设置,因此可以直接使用)。
接下来,在 register.py 中导入这两个工具,在文件中添加如下行:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/register.py
# ...
from .bright_data import bright_data_serp_api_function, bright_data_web_unlocker_api_function现在,这两个工具即可在 config.yml 文件中使用。这是因为自动生成的 pyproject.toml 包含:
[project.entry-points.'nat.components']
web_data_workflow = "web_data_workflow.register"这告诉 nat 命令:“在加载 web_data_workflow 工作流时,到 web_data_workflow.register 模块中查找组件。”
注意:同样的方法可以用于为 BrightDataWebScraperAPI 创建工具,从而与 Bright Data 的 Web Scraping APIs 集成,让智能体能从 Amazon、Instagram、LinkedIn、Yahoo Finance 等热门网站获取结构化数据流。
到这里,只需在 config.yml 中做最后的配置,让智能体能够连接到这两个新工具。
步骤 7:配置 Bright Data 工具
在 config.yml 中导入 Bright Data 工具,并将它们传给智能体:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/configs/config.yml
functions:
# Define and customize the custom Bright Data tools
bright_data_serp_api:
_type: bright_data_serp_api
bright_data_web_unlocker_api:
_type: bright_data_web_unlocker_api
data_format: markdown
llms:
nim_llm:
_type: nim
model_name: meta/llama-3.1-70b-instruct # Replace it with an enterprise-ready AI model
temperature: 0.0
workflow:
_type: react_agent
llm_name: nim_llm
tool_names: [bright_data_serp_api, bright_data_web_unlocker_api] # Configure the Bright Data tools要使用前面定义的工具,需要:
- 在
config.yml的functions部分添加它们。你可以通过它们对应的FunctionBaseConfig类所暴露的参数来自定义工具的行为。例如,上述示例中将bright_data_web_unlocker_api工具配置为返回 Markdown 格式数据,而 Markdown 对于 AI 智能体来说是一种极佳的处理格式。 - 在
workflow块的tool_names字段中列出这些工具,让智能体能够调用它们。
现在,你的 ReAct 智能体(由 meta/llama-3.1-70b-instruct 驱动)已可以访问基于 LangChain 的两款自定义工具:
bright_data_serp_apibright_data_web_unlocker_api
注意:在本示例中,LLM 配置为 NVIDIA NIM 模型。你可以根据部署需求切换到更适合企业使用的模型。
步骤 8:测试 NVIDIA NeMo Agent Toolkit 工作流
要验证 NVIDIA NeMo Agent Toolkit 工作流是否已能与 Bright Data 工具交互,你需要一个同时触发网页搜索和网页数据提取的任务。
例如,假设你的公司希望监测竞争对手新品及其定价,以支持商业情报。如果你的竞争对手是 Nike,可以使用如下提示词:
Search the web to discover the latest Nike shoes. From the retrieved search results, select up to three of the most relevant web pages, giving priority to official Nike website pages. Access these pages and retrieve their content in Markdown format. For the discovered shoe model, provide the name, release status, price, key information, and a link to the official Nike page (if available).在运行前,请确认已设置好 NVIDIA_API_KEY 和 BRIGHT_DATA_API_KEY 环境变量,然后用以下命令运行智能体:
nat run --config_file configs/config.yml --input "Search the web to discover the latest Nike shoes. From the retrieved search results, select up to three of the most relevant web pages, giving priority to official Nike website pages. Access these pages and retrieve their content in Markdown format. For the discovered shoe models, provide the name, release status, price, key information, and a link to the official Nike page (if available)."初始输出可能类似如下: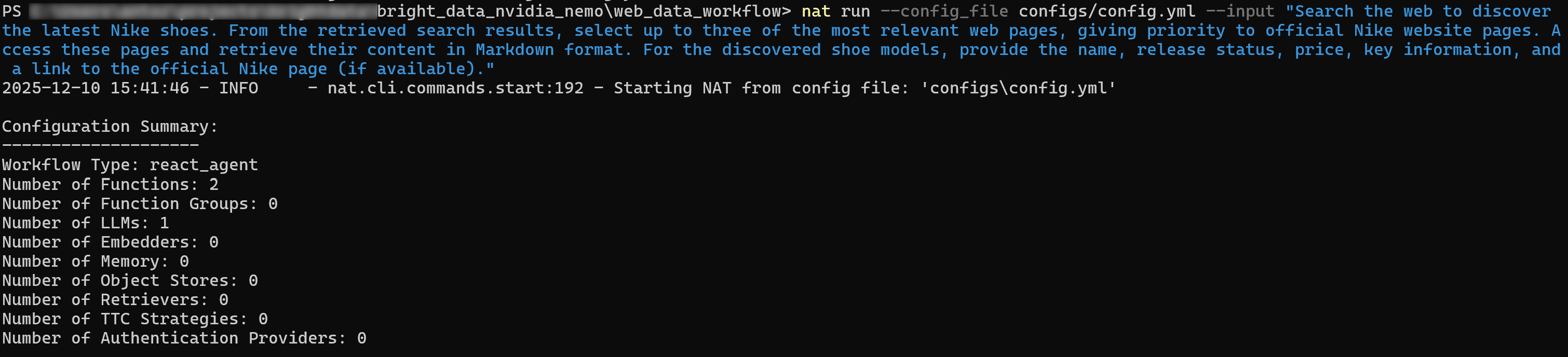
如果开启 verbose 模式(在 workflow 块中设置 verbose: true),你可以看到智能体执行了以下步骤:
- 使用类似 “latest Nike shoes” 和 “new Nike shoes” 的查询调用 SERP API。
- 筛选出最相关页面,优先选择 Nike 官方 “New Shoes” 页面。
- 使用 Web Unlocker API 工具访问选定页面,并以 Markdown 格式抓取页面内容。
- 对抓取的数据进行处理,并生成结构化结果列表:
[Air Jordan 11 Retro "Gamma" - Men's Shoes](https://www.nike.com/t/air-jordan-11-retro-gamma-mens-shoes-DYkD1oXL/CT8012-047)
Release Status: Coming Soon
Colors: 1
Price: $235
[Air Jordan 11 Retro "Gamma" - Big Kids' Shoes](https://www.nike.com/t/air-jordan-11-retro-gamma-big-kids-shoes-LJyljnZt/378038-047)
Release Status: Coming Soon
Colors: 1
Price: $190
# Omitted for brevity...这些结果与 Nike 官方 “New Shoes” 页面上的内容完全一致: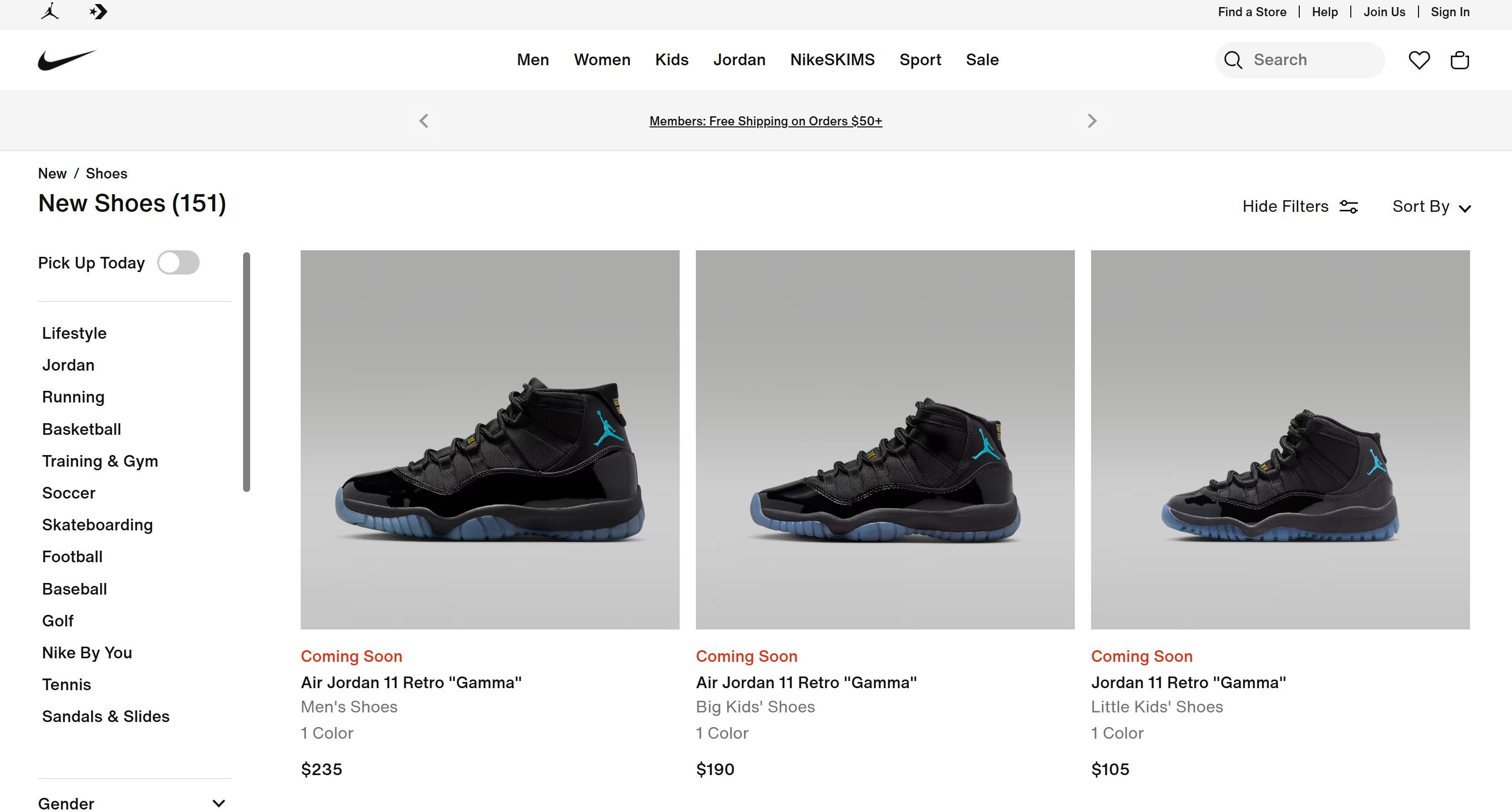
任务完成!AI 智能体已经可以自主搜索网页、选择合适页面、抓取数据,并提取结构化产品洞察。如果没有在 NAT 工作流中集成 Bright Data 工具,这一切将无法实现。
请记住,智能体驱动的商业情报只是 Bright Data 解决方案与 NVIDIA NeMo Agent Toolkit 结合后所支持的众多用例之一。尝试调整工具配置、集成更多工具或修改输入提示词,探索更多场景!
通过 Web MCP 将 NVIDIA NeMo Agent Toolkit 连接 Bright Data
另一种将 NVIDIA NeMo Agent Toolkit 与 Bright Data 产品集成的方式,是将其连接到 Web MCP。详情请参考官方文档。
Web MCP 提供对60+ 工具的访问,这些工具构建在 Bright Data 的网页自动化和数据采集平台之上。即使在免费套餐中,你也可以使用两款强大的工具:
| Tool | Description |
|---|---|
search_engine |
以 JSON 或 Markdown 格式获取 Google、Bing 或 Yandex 搜索结果。 |
scrape_as_markdown |
抓取任意网页并转换为干净的 Markdown,同时绕过反爬虫机制。 |
不过 Web MCP 的真正实力体现在Pro 模式。该付费高级版本可以解锁针对 Amazon、Zillow、LinkedIn、YouTube、TikTok、Google Maps 等主流平台的结构化数据抽取工具,以及更多用于自动化浏览器操作的工具。
注意:关于项目搭建和前提条件,请参考上一章节。
下面介绍如何在 NVIDIA NeMo Agent Toolkit 中使用 Bright Data 的 Web MCP!
步骤 1:安装 NVIDIA NAT MCP 包
前文提到,NVIDIA NeMo Agent Toolkit 是模块化的。核心包提供基础能力,额外功能通过可选扩展添加。
要支持 MCP,需要安装 nvidia-nat[mcp] 包,命令如下:
pip install nvidia-nat[mcp]安装后,NVIDIA NeMo Agent Toolkit 智能体就可以连接 MCP 服务器。为了确保企业级性能和可靠性,你将通过托管的远程服务,使用 Streamable HTTP 远程通信方式连接 Bright Data Web MCP。
步骤 2:配置远程 Web MCP 连接
在 config.yml 中,通过 Streamable HTTP 协议配置与 Bright Data 远程 Web MCP 服务器的连接:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/configs/config.yml
function_groups:
bright_data_web_mcp:
_type: mcp_client
server:
transport: streamable-http
url: "https://mcp.brightdata.com/mcp?token=<YOUR_BRIGHT_DATA_API_KEY>&pro=1" tool_call_timeout: 600
auth_flow_timeout: 300
reconnect_enabled: true
reconnect_max_attempts: 3
llms:
nim_llm:
_type: nim
model_name: meta/llama-3.1-70b-instruct # Replace it with an enterprise-ready AI model
temperature: 0.0
workflow:
_type: react_agent
llm_name: nim_llm
tool_names: [bright_data_web_mcp]此处不是在 functions 块中逐一定义工具,而是使用 function_groups。这会配置与 Web MCP 的连接,并从远程服务器获取整套 MCP 工具集合。然后在 tool_names 字段中将整个分组传递给智能体,方式与单个工具一致。
Web MCP URL 中包含 &pro=1 查询参数。它会启用 Pro 模式,虽为可选项,但强烈建议在企业场景中开启,因为它可以解锁完整的结构化数据抽取工具套件,而不仅是基础工具。
步骤 3:验证 Web MCP 连接
使用新的提示词运行 NVIDIA NeMo Agent。你应该在初始日志中看到智能体正在加载 Web MCP 提供的所有工具: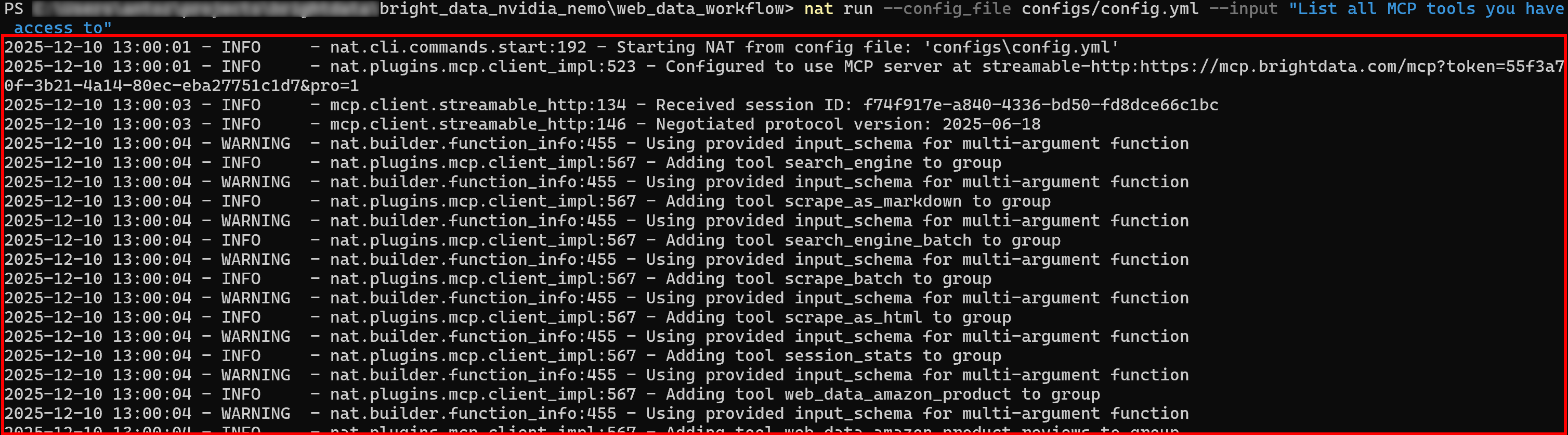
如果启用了 Pro 模式,初次加载时将引入全部 60+ 工具。
随后,配置摘要日志中会显示一个函数组,与预期一致: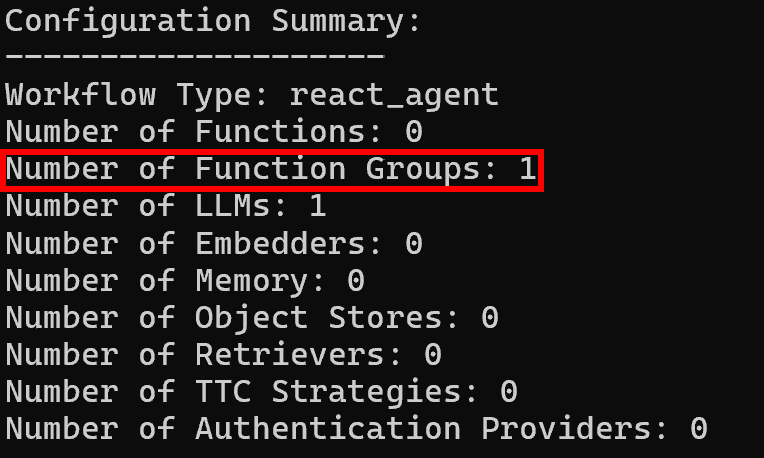
至此,你的 NVIDIA NeMo Agent Toolkit 工作流已经完全接入 Bright Data Web MCP 所提供的全部能力。
总结
在本文中,你学习了如何通过两种方式将 Bright Data 与 NVIDIA NeMo Agent Toolkit 集成:基于 LangChain 的自定义工具,以及通过 Web MCP 集成。
这些集成方式为 NAT 工作流打开了实时网页搜索、结构化数据抽取、实时网页数据流访问以及自动化网页交互的大门。它们充分利用了Bright Data 面向 AI 的完整网页数据服务套件,释放你的 AI 智能体的最大潜力!
立即注册 Bright Data,开始集成我们的 AI 就绪网页数据工具吧!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




