

让 Amazon 商品数据流水线在你的笔记本上跑起来是一回事;让它在生产环境稳定运行(包含代理、CAPTCHA、页面布局变化与 IP 封锁)则是另一回事。即便你解决了爬虫本身,你仍然需要调度、重试、错误处理,以及一个真正能看见你采集了什么的方式。
我们会在这里把这些都搭起来。我们将使用 Bright Data 的 Web Scraping API 与 Mage AI 串起一条流水线:采集 Amazon 商品与评论,运行 Gemini 情感分析,并将所有数据写入 PostgreSQL 与 Streamlit 仪表盘。整条流水线使用 Docker 运行,只需要一个 API key(另外可选配一个 Gemini key 用于 AI 分析)
TL;DR:无需搭建爬虫基础设施,即可获得 Amazon 商品情报。
- 你将得到什么:一条可按关键词发现商品、用 Gemini AI 分析评论,并提供实时 Streamlit 仪表盘的流水线
- 成本如何:按需付费,按记录计费(见定价页),端到端 5–8 分钟
- 它如何工作:Bright Data 负责代理、CAPTCHA 与解析;Mage AI 负责调度、重试与分支
- 如何开始:
docker compose up—— 代码在 GitHub 仓库
我们要构建的内容:Bright Data + Mage AI 集成流水线
Bright Data 的 Web Scraping API 负责抓取层。你发送关键词或商品 URL,即可得到结构化 JSON(标题、价格、评分、评论、卖家信息),并且已完成解析。无需维护代理基础设施,无需解析 HTML。当 Amazon 更改网站时,Bright Data 通常会更新解析器,你的代码保持不变。
如果你以前没用过 Mage AI:它是一个免费、开源的数据流水线工具,类似 Airflow 但不需要大量样板代码。你可以在类似 Notebook 的编辑器里写 Python,每个 block 都是可复用单元,并且带有自己的测试与输出预览。这里的关键点是:Mage AI 支持分支流水线,本质上就是带并行路径的 DAG(有向无环图)。它还支持按 block 的内置重试逻辑,以及可在 UI 中修改的流水线变量,无需改代码。
这条流水线共有 6 个 block,分成两条并行分支:
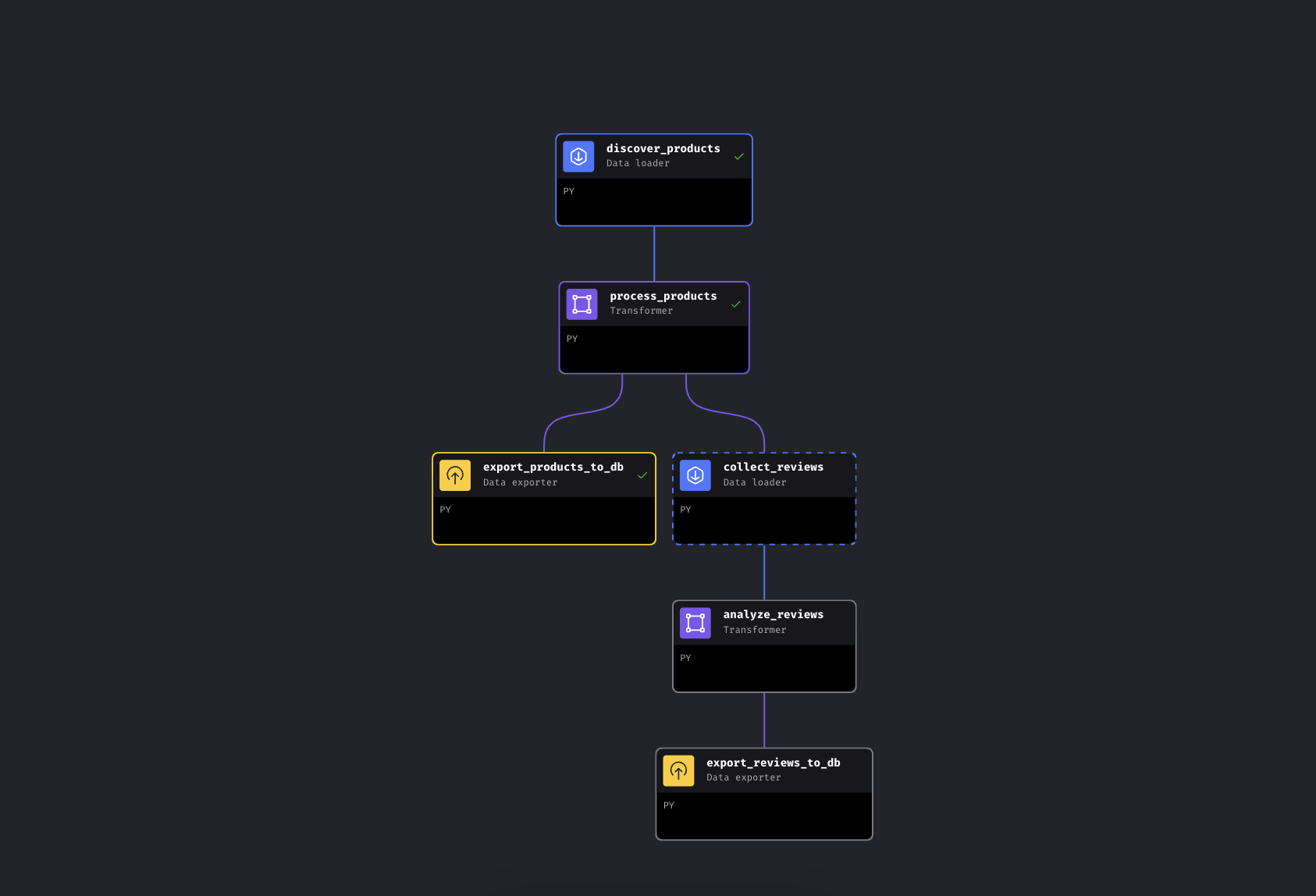
Mage AI 中的分支流水线。左分支立即导出商品,右分支采集并分析评论
流水线先通过 Bright Data 按关键词发现商品,用价格档位与评分对其增强,然后进入分支:一条路径立即把商品导出到 PostgreSQL;另一条路径为 Top 商品采集评论,交给 Gemini 做情感分析,并同样导出。
我们在这里选择 Mage AI,是因为流水线包含分支(它是 DAG,而不是线性脚本——即使评论采集失败,你的商品数据也已经安全落库),但 Bright Data 的 API 调用本质只是 HTTP 请求。在 Airflow、Prefect、Dagster 或纯 Python 脚本里用法都一样。
快速开始
克隆仓库、添加 API keys,然后运行即可。所有内容都在 Docker 里运行,因此你无需在本机安装 Python。
前置条件
你需要:
- Docker 与 Docker Compose(获取 Docker)
- 一个带 API token 的 Bright Data 账号
- 一个 Google Gemini API key(有免费档但有限制;见下方 Gemini 部分)
- 对 Python 与 Docker 有基本了解。无需抓取经验——这正是重点
第 1 步:克隆并配置
克隆仓库并创建配置文件:
git clone https://github.com/triposat/mage-brightdata-demo.git
cd mage-brightdata-demo
cp .env.example .env然后将你的 API keys 写入 .env:
BRIGHT_DATA_API_TOKEN=your_api_token_here
GEMINI_API_KEY=your_gemini_api_key_here获取 Bright Data API token:在 [Bright Data]() 注册(免费试用,无需信用卡),然后进入 账户设置 创建 API key。该流水线使用两个 Web Scraping API 采集器(一个用于商品发现,一个用于评论),按记录计费、按需付费。当前费率请查看 定价页。
获取 Gemini API key:前往 Google AI Studio,登录后点击 Create API key。免费档无需信用卡。本流水线没有它也能跑;会退化为基于评分的情感判断。
第 2 步:启动服务
docker compose up -d如果你想确认 keys 是否已正确加载:
docker compose exec mage python -c "import os; t=os.getenv('BRIGHT_DATA_API_TOKEN',''); assert t and t!='your_api_token_here', 'Token not set'; print('OK')"这会启动三个容器:
| 服务 | URL | 用途 |
|---|---|---|
| Mage AI | http://localhost:6789 |
流水线编辑器与调度器 |
| Streamlit 仪表盘 | http://localhost:8501 |
实时数据可视化 + 聊天 |
| PostgreSQL | localhost:5432 |
数据存储 |
第一次运行会拉取镜像并安装依赖,大约 3–5 分钟(取决于网络)。使用 docker compose stop/start 重启只需几秒;docker compose down/up 会重新安装 pip 包,大约需要一分钟。
三个服务全部运行中
第 3 步:运行流水线
打开 http://localhost:6789,进入 Pipelines,点击 amazon_product_intelligence,然后在左侧边栏点击 Triggers 并选择 Run@once。
Mage AI 仪表盘
整条流水线端到端约 5–8 分钟。大部分时间花在 Bright Data API 从 Amazon 采集数据上;增强与数据库导出只需几秒;Gemini 分析时间取决于批量大小与限流。当 6 个 block 都变绿后,打开 http://localhost:8501 查看仪表盘。
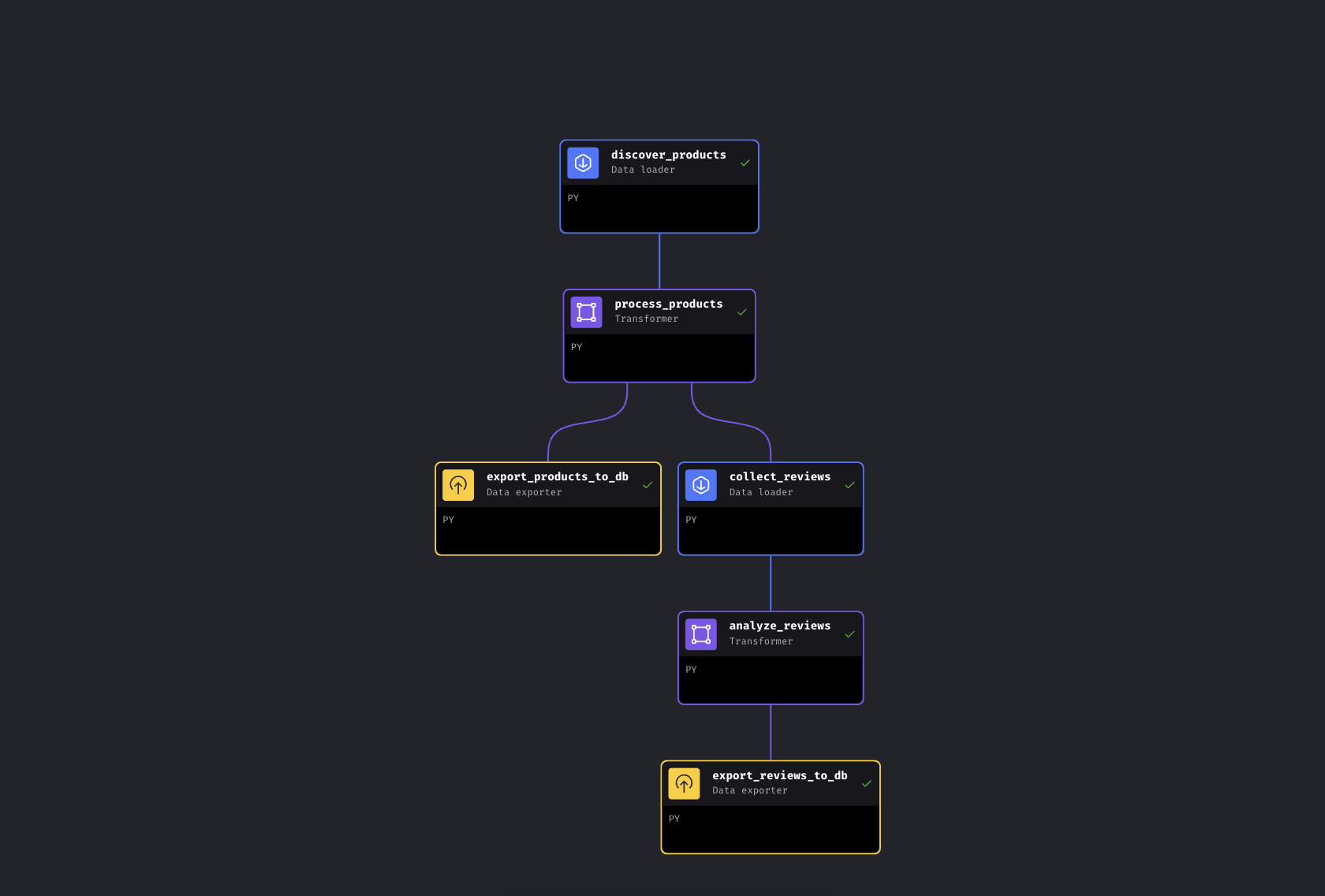
6 个 block 全部变绿。流水线完成
Mage AI 数据流水线如何工作
我们来过一遍代码。重点看 Bright Data 集成与 Gemini 分析。
将 Bright Data 的 Web Scraping API 连接到 Mage AI
我们把关键词发送到 Amazon Products API,并获得结构化数据。Bright Data 将其称为 “Discovery” 采集器——它可按关键词或类目发现商品。后续的评论 block 会使用另一个独立的 Reviews 采集器,以商品 URL 作为输入。API 采用异步模式:触发采集后拿到 snapshot ID,然后轮询直到结果就绪。
DATASET_ID = "gd_l7q7dkf244hwjntr0" # Amazon Products (check repo for current IDs)
API_BASE = "https://api.brightdata.com/datasets/v3"
# Trigger the collection (uses /scrape – auto-switches to async if >1 min; for production, consider /trigger)
response = requests.post(
f"{API_BASE}/scrape",
headers={"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json"},
params={"dataset_id": DATASET_ID,
"type": "discover_new",
"discover_by": "keyword",
"limit_per_input": kwargs.get('limit_per_keyword', 5)},
json={"input": [{"keyword": kw} for kw in keywords]}
)
snapshot_id = response.json()["snapshot_id"]
# Poll until results are ready
data = requests.get(
f"{API_BASE}/snapshot/{snapshot_id}",
headers={"Authorization": f"Bearer {api_token}"},
params={"format": "json"}
).json()以下是 Bright Data 返回的内容示例:
{
"title": "BESIGN LS03 Aluminum Laptop Stand",
"asin": "B07YFY5MM8", // Amazon's unique product ID
"url": "https://www.amazon.com/dp/B07YFY5MM8",
"initial_price": 19.99,
"final_price": 16.99,
"currency": "USD",
"rating": 4.8,
"reviews_count": 22776,
"seller_name": "BESIGN",
"categories": ["Office Products", "Office & School Supplies"],
"image_url": "https://m.media-amazon.com/images/I/..."
}kwargs.get('limit_per_keyword', 5) 会读取 Mage AI 的流水线变量,因此你可以在 UI 中直接调整。
添加第二个 API 调用:采集 Amazon 评论
评论采集器会接收上游 block 处理后的商品数据,并按评论数排序,选出 Top N,然后将其 Amazon URL 发送到第二个 Bright Data API:
REVIEWS_DATASET_ID = "gd_le8e811kzy4ggddlq" # Amazon Reviews
# Top products from upstream (passed automatically by Mage AI)
top_products = data.sort_values('reviews_count', ascending=False).head(top_n)
product_urls = top_products['url'].dropna().tolist()
# Feed URLs into the Reviews API (same /scrape pattern)
response = requests.post(
f"{API_BASE}/scrape",
headers={"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json"},
params={"dataset_id": REVIEWS_DATASET_ID},
json={"input": [{"url": url} for url in product_urls]}
)
# Same async poll pattern as products...在该 demo 的 metadata.yaml 中,这两个 API block 都配置了重试:如果调用失败,流水线会以 30 秒间隔重试 3 次。该 demo 中每个 block 还包含一个在执行后运行的 @test 函数;如果测试失败,下游 block 不会运行,从而避免脏数据写入数据库。
添加 AI 分析:Gemini 情感分析 block
我们不使用关键词匹配(它会因为出现“cheap”而把 “not cheap, great quality!” 误判为负面),而是使用 Gemini 理解上下文。该 block 以三模型轮换分批处理评论,以保持在免费档限制内:
GEMINI_MODELS = ["gemini-2.5-flash-lite", "gemini-2.5-flash", "gemini-2.5-pro"] # check repo for current models
prompt = f"""Analyze these reviews. For EACH, return JSON with:
- "sentiment": "Positive", "Neutral", or "Negative"
- "issues": specific product issues mentioned
- "themes": 1-3 topic tags
- "summary": one-sentence summary
Return ONLY JSON.\n\n{reviews_text}"""
for model in models:
try:
response = client.models.generate_content(model=model, contents=prompt)
return json.loads(response.text.strip())
except Exception as e:
if '429' in str(e):
continue # Rate limited -- rotate to next model轮换从 flash-lite(最便宜最快)开始,回退到 flash,再到 pro。如果三个模型都被耗尽,则评论会改用基于评分的情感。免费档配额会周期性变化,但三模型轮换可自动处理大多数限流情况。Gemini 会返回情感、具体问题(例如“在不平整表面会晃”“铰链久用变松”)、每条评论 1–3 个主题标签,并附带一句话摘要。
其余 block(用于价格档位与折扣计算的 transformer,以及两个带 upsert 逻辑的数据库导出块)都比较直接。如果你想深入了解,它们都在 GitHub 仓库 里。
流水线输出:结果与 Streamlit 仪表盘
下面是使用默认关键词 “laptop stand” 和 “wireless earbuds” 运行一次后生成的结果。你的结果会随 Amazon 当前商品列表而变化。
本次运行:发现 10 个商品,Gemini 分析了 20 条评论。耳机评论中暴露出一些在 4.3 星平均评分里看不到的抱怨——例如 “sound quality”“battery life”“connectivity” 等主题,并附带具体问题。
该流水线在原始数据之上新增了什么:
| 字段 | 示例 | 由谁添加 |
|---|---|---|
best_price |
$16.99 | Transformer(计算) |
discount_percent |
15.0% | Transformer(计算) |
price_tier |
Budget (<$25) | Transformer(增强) |
rating_category |
Excellent (4.5-5) | Transformer(增强) |
sentiment |
Negative | Gemini AI |
issues |
[“Bluetooth drops connection frequently”] | Gemini AI |
themes |
[“connectivity”, “battery life”] | Gemini AI |
ai_summary |
“Battery lasts only 2 hours despite claims of 8” | Gemini AI |
实践效果如下——10 个商品均带有增强字段:
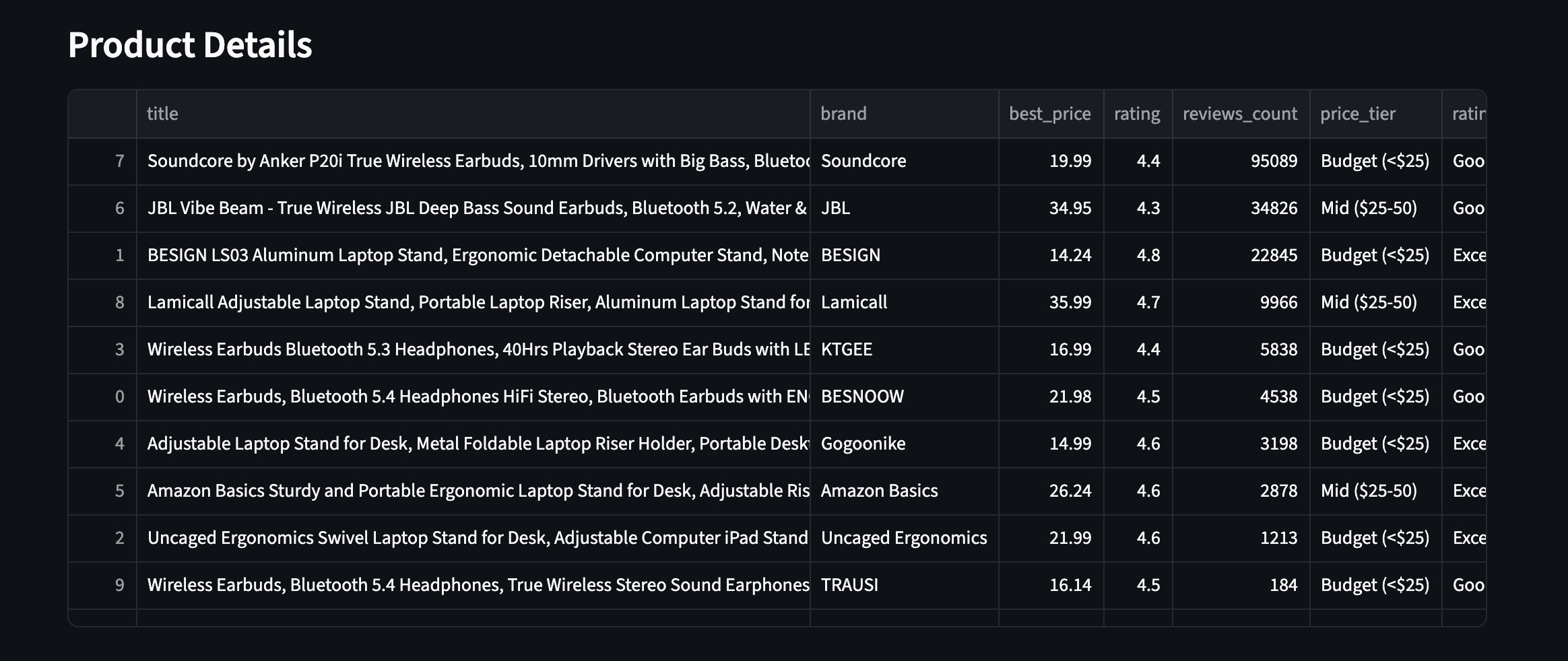
10 个商品全部显示增强字段。来自两类商品的价格档位、评分与评论数
仪表盘
打开 http://localhost:8501 进入 Streamlit 仪表盘。在侧边栏点击 Refresh Data 从 PostgreSQL 拉取最新结果。
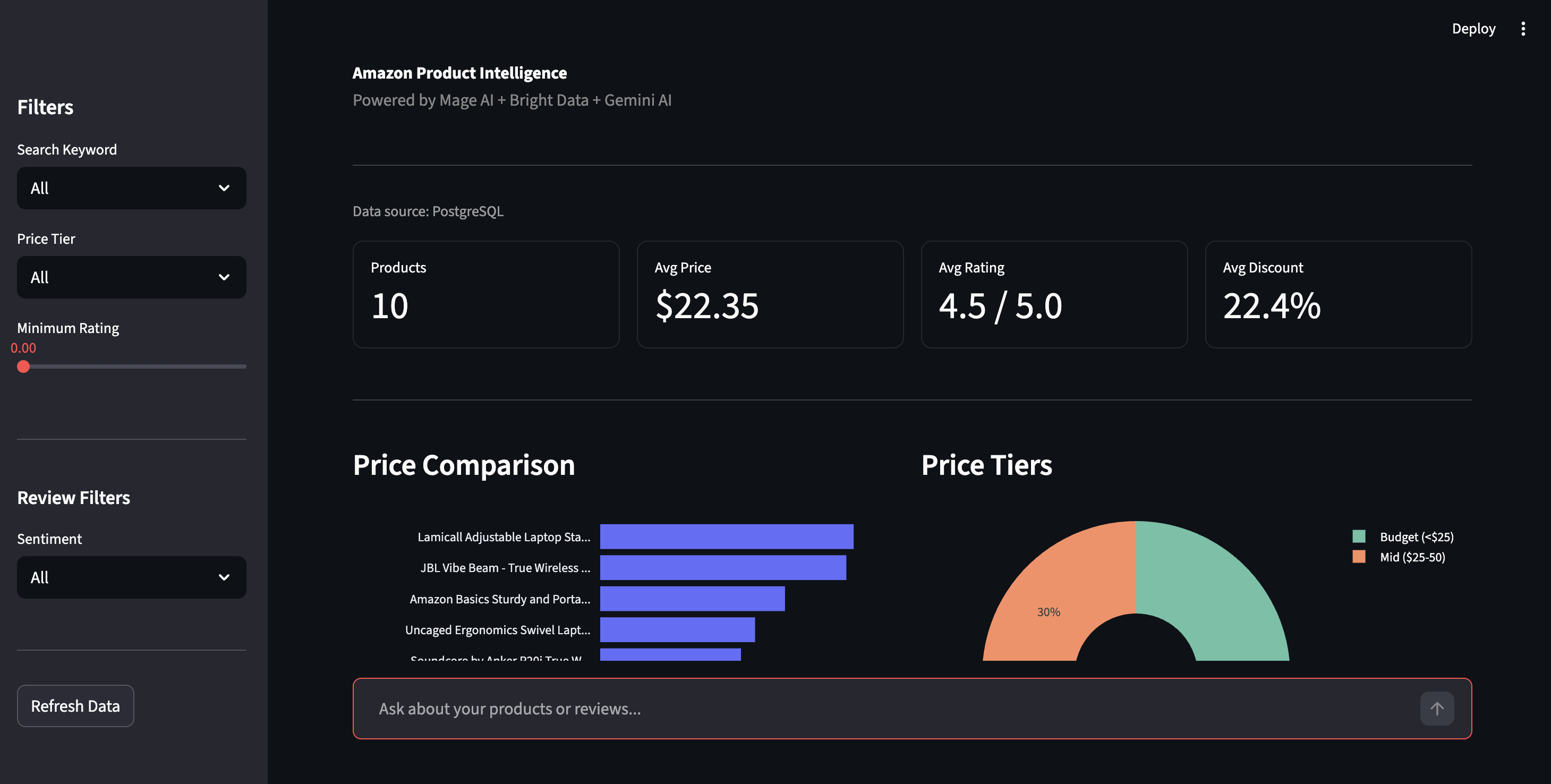
商品情报仪表盘——价格对比、价格档位与筛选控件
侧边栏可按价格档位、评分或情感进行筛选。情感视图显示全部评论的正/负面拆分,并展示 Gemini 抽取的具体问题:“Bluetooth drops connection”“hinge loosens over time”——这些细节往往被星级评分掩盖。

情感拆分与 AI 检测到的商品问题。由 Gemini 提取的真实抱怨,而非关键词匹配
仪表盘还包含 Chat with Your Data 功能。用自然语言提问,Gemini 会以你实际爬虫的数据作为上下文进行回答。下面是一次包含更多商品的独立运行示例:
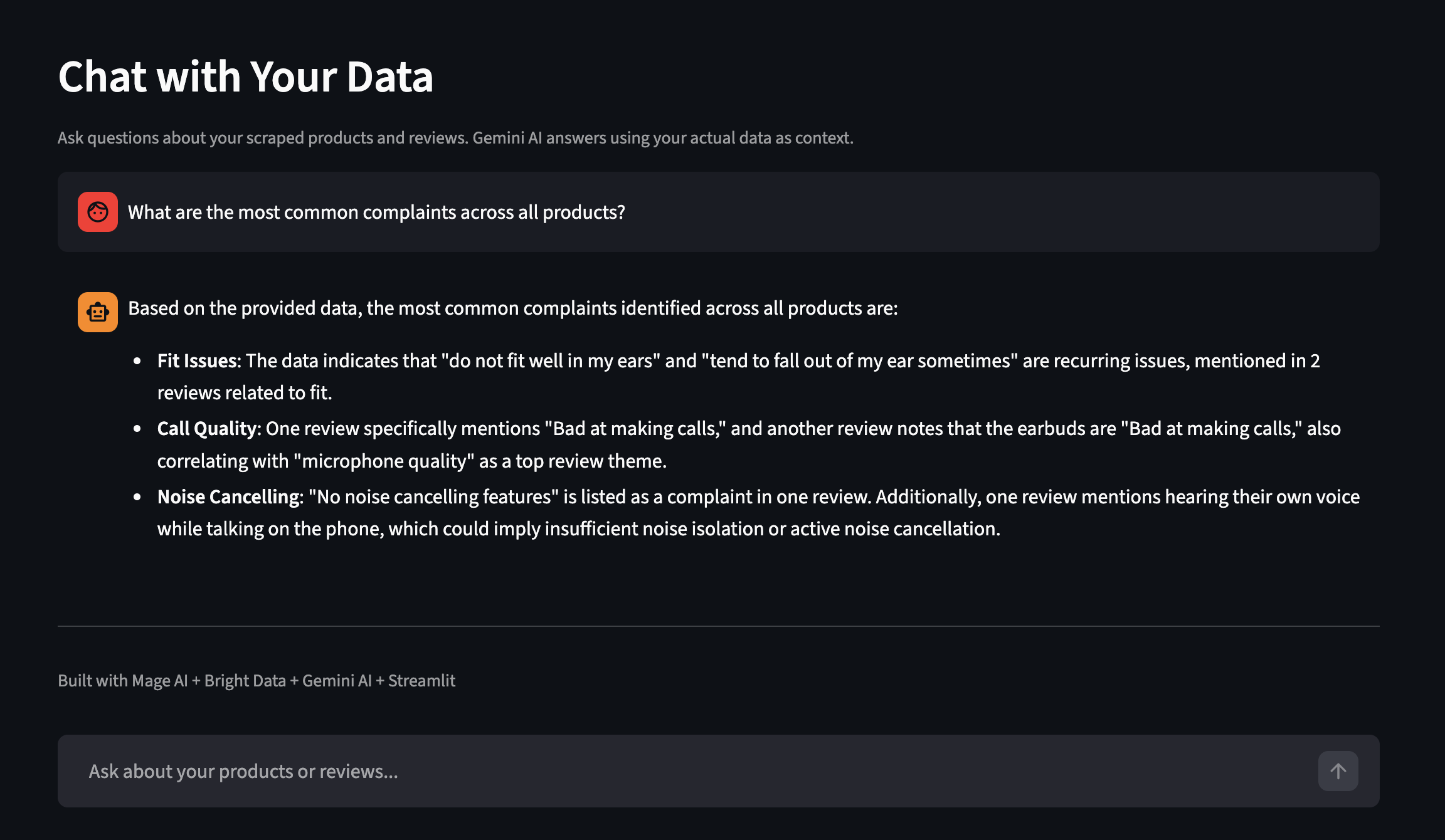
用自然语言就你的爬虫数据提问
扩展流水线
该 demo 默认使用两个关键词并发现 10 个商品。
流水线变量
都可以在 Mage AI UI 或 metadata.yaml 中配置:
| 变量 | 控制内容 | 默认值 |
|---|---|---|
keywords |
Amazon 搜索词 | ["laptop stand", "wireless earbuds"] |
limit_per_keyword |
每个关键词从 Bright Data 获取的商品数 | 5 |
top_n_products |
采集评论的 Top 商品数量 | 2 |
reviews_per_product |
每个商品最多评论数 | 10 |
sort_by |
用于选择评论商品的排序方式 | reviews_count |
把 keywords 改为 ["phone case", "USB-C hub"],你就会得到完全不同的数据集,无需改代码。
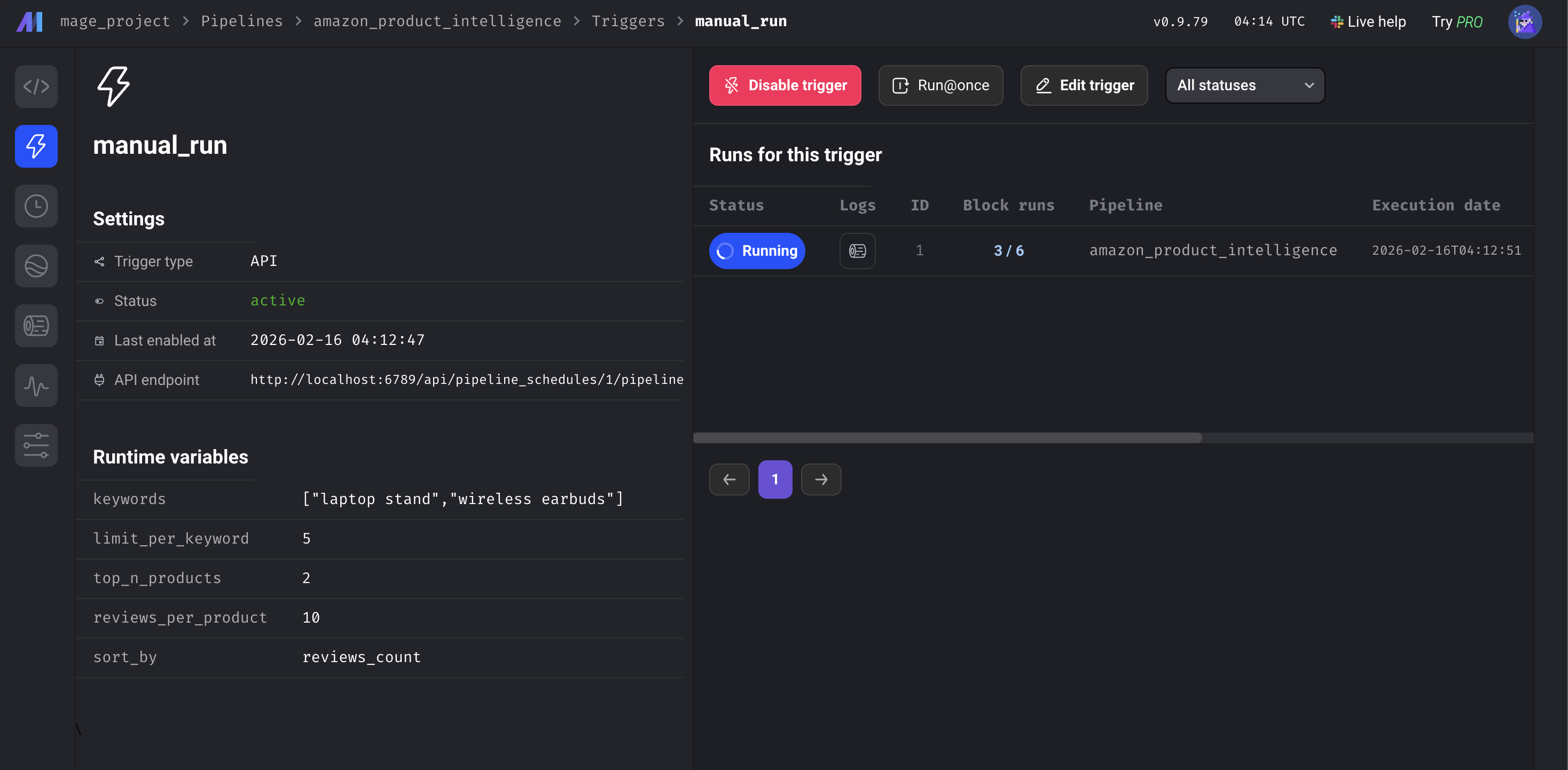
Mage AI UI 中的流水线变量
调度
要按计划运行,请在 Mage AI 侧边栏进入 Triggers,点击 + New trigger,选择 Schedule,然后选择频率(一次、每小时、每天、每周、每月或自定义 cron)。
每次运行都会按 ASIN 进行 upsert——它会替换相同商品的数据,同时保留其他关键词的结果。系统还会保存带时间戳的 CSV 备份,用于历史对比。
当你积累了几次运行数据后,可以直接查询 PostgreSQL,找出星级评分遗漏的抱怨:
-- Find products with high negative sentiment
SELECT asin, product_name,
AVG(CASE WHEN sentiment = 'Negative' THEN 1 ELSE 0 END) as negative_rate
FROM amazon_reviews
GROUP BY asin, product_name
HAVING AVG(CASE WHEN sentiment = 'Negative' THEN 1 ELSE 0 END) > 0.2;如果你想监控自家商品而不是按关键词搜索,请移除 type、discover_by 与 limit_per_input 参数,并直接将商品 URL 作为 [{"url": "https://www.amazon.com/dp/YOUR_ASIN"}] 传入。
如果你希望无需自建仪表盘与告警,Bright Insights 可对零售数据做到开箱即用。
扩展规模。该 demo 在单机 Docker 中运行,但 Mage AI 支持用于生产环境的 Kubernetes executor;Bright Data 的 API 会在服务端处理并发(批量请求会有限流)。规模化主要是增加 Mage AI 运行能力,而不是修改采集代码。
集成其他 Bright Data 采集器
同样的流水线模式适用于 Bright Data 的100+ 网站现成采集器。例如可参考 Google Maps Scraper、LinkedIn Scraper 与 Crunchbase Scraper 仓库。若要从 Amazon 切换到其他平台,只需在数据加载 block 中替换 DATASET_ID,并调整输入参数以匹配新采集器的 schema。
要找到正确的 ID 与输入字段,可在控制台浏览 Scraper Library,或调用 /datasets/list 端点——控制台里的 API Request Builder 会精确展示每个采集器的入参要求。Gemini 分析与流水线结构可原样复用;如果新采集器的响应字段与 Amazon 不同,增强与导出 block 可能需要对列名做少量调整。
排障
如果在安装或运行过程中出现问题,以下是最常见的解决办法:
- 端口 6789 或 8501 已被占用。有其他服务占用了端口。停止该服务,或编辑
docker-compose.yml重新映射端口(例如把6789:6789改为6790:6789)。 - Bright Data API 返回 401 Unauthorized。你的 API token 缺失或格式错误。前往 账户设置 复制完整 token,并确保
.env文件末尾没有多余空格。token 是一长串十六进制字符串(64 个字符)。如果你复制的很短或像 UUID 那样带短横线,可能复制错了字段。 - Gemini 在所有模型上都返回 429(限流)。免费档的每分钟限制会周期性变化。流水线会通过三模型轮换来处理;如果三个都耗尽,评论会退化为基于评分的情感。要避免这一点:在流水线变量中降低
reviews_per_product,在 Gemini block 的批次之间增加time.sleep(60),或为 Google AI 项目启用计费以获得更高配额。当前配额请查看 Google 的限流页面。 - 某个流水线 block 变红(失败)。进入该流水线的 Logs 页面(左侧边栏可进入)查看错误。你可以按 block 名称与日志级别过滤。常见原因:API token 过期、Bright Data API 网络超时(在 block 中提高
max_wait_seconds)、或 Gemini 返回的内容不是合法 JSON(block 的@test会捕获)。 - 在 Apple Silicon 上 Docker Compose 很慢或失败。Mage AI 镜像支持多架构并可在 ARM 上运行,但首次拉取可能更久。如果构建因内存错误失败,请在 Docker Desktop 的 Settings → Resources 中将内存分配提高到至少 4 GB。
下一步
你已经拥有一条可用的流水线:采集 Amazon 商品数据、运行 AI 驱动的评论分析,并把所有内容存入 PostgreSQL——无需代理、无需解析器、也无需你不敢动的 cron。
如果你跟着做完了,就把它变成你的版本。把 metadata.yaml 中的 keywords 列表替换为其他品类——无需改代码。想更深度定制的话,可以指向特定 ASIN,或直接切换到其他 Bright Data 采集器。
第一次接触?[从 Bright Data 免费试用开始]()(无需信用卡),克隆 demo 仓库,然后运行 docker compose up。
FAQ
关于该搭建方式的常见问题:
如何用 Python 爬虫 Amazon 商品数据?
你可以用 requests 与 BeautifulSoup 自己写采集器(Amazon 一改布局就容易失效),也可以使用 Bright Data 的 Amazon 采集器,通过一次 API 调用就返回结构化 JSON。想看独立的 Python 示例,请参考 Amazon Scraper 仓库。想深入了解,请阅读 Bright Data 的 完整 Amazon 爬虫指南
使用 Bright Data 爬虫 Amazon 的成本是多少?
Web Scraping API 采用按需付费模式,按采集的每 1,000 条记录计费。Gemini 免费档可覆盖 AI 分析成本。新账号提供 免费试用。当前费率请查看 定价页面。
这条流水线能爬虫 Walmart、eBay 或其他电商网站吗?
在数据加载 block 中替换 DATASET_ID 并调整输入参数以匹配新采集器的 schema。Gemini 分析与流水线结构可直接复用;增强与导出 block 可能需要对列名做微调。
当 Amazon 更改页面布局会怎样?
你这边无需做任何事。Bright Data 维护解析器,因此当 Amazon 更新 HTML 时,你的 API 调用与响应格式通常会保持不变。
我必须使用 Gemini 吗?能换成其他 LLM 吗?
该流水线不使用 Gemini 也能运行;会退化为基于评分的情感。若要切换到其他 LLM(OpenAI、Claude、Llama),修改 Gemini block 中的 analyze_reviews 函数即可。提示词格式保持不变,你只需要替换 API 调用。



技术写作者
 5 years experience
5 years experience
Satyam Tripathi 帮助 SaaS 和数据初创公司将复杂技术转化为可执行的内容,提升开发者采用度并增强用户理解。




