

在本文中,你将学到:
- 什么是 LibreChat,以及它的独特之处。
- 为什么将 Bright Data 的 Web MCP 集成到 LibreChat 能带来显著提升。
- 如何将 Web MCP 连接到 LibreChat,并与任意受支持的 AI 模型配合使用。
让我们开始吧!
什么是 LibreChat?
LibreChat 是一款开源的 Web 聊天应用,GitHub Star 超过 3 万(且仍在增长),由 Danny Aviles 开发。
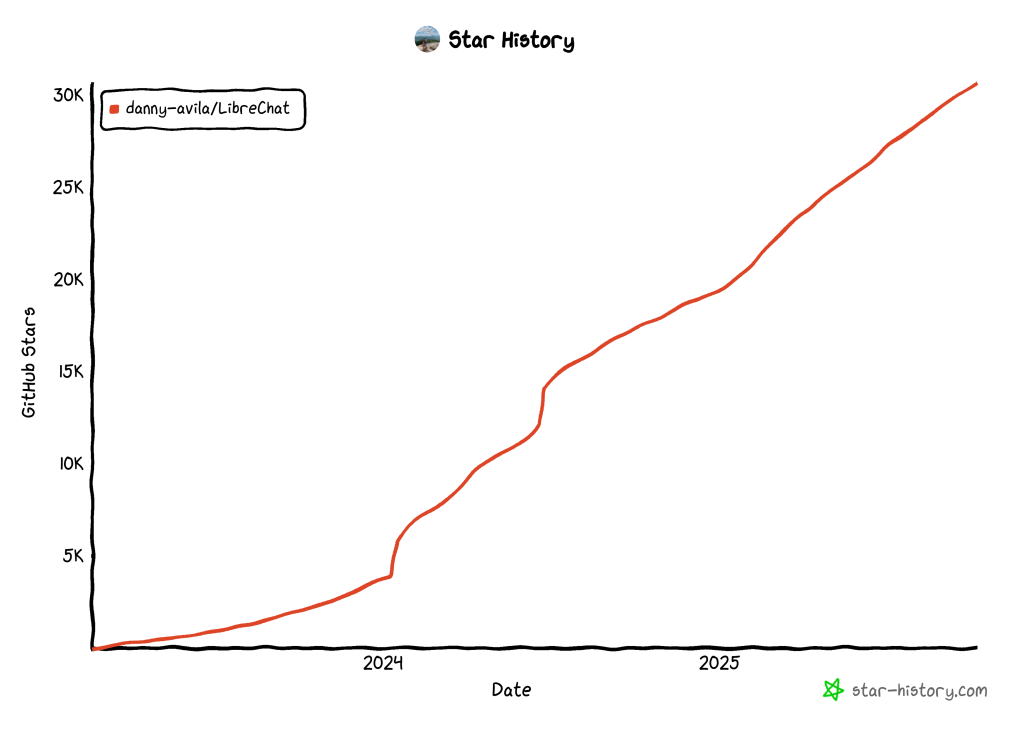
该应用为与多个 AI 模型交互提供了集中式界面,充当一体化开源 AI 枢纽。
LibreChat 的亮点在于其受 ChatGPT 启发的界面设计。它几乎支持所有主流 AI 提供商,从 OpenAI、Anthropic 到 Google、Ollama,以及任何自定义端点。通过同一界面,它支持多模态对话、AI Agent 构建,并提供认证与内容审核等安全功能。
为何用 Bright Data 的 Web MCP 在 LibreChat 中扩展 AI 模型
LibreChat 允许你将 MCP 服务器连接到应用,并将其工具提供给 AI 模型使用。配置在应用层面完成一次后,任何已配置的 LLM 都可访问这些工具,使 MCP 工具的使用真正无缝。
假设你对某个 LLM 的输出不满意,你只需点击几下即可切换到另一个,它仍然可以访问你的 MCP 服务器,无需额外设置。这就是 LibreChat 的强大之处!
那么,应该优先考虑哪些 MCP 服务器?答案很简单:那些能帮助 AI 模型克服其最大局限的——过时的知识,以及无法搜索或浏览网页。
这正是 Web MCP(Bright Data 的 Web MCP 服务器)的用途。它既提供开源软件包,也提供远程服务器,让 AI 模型能够获取实时网页数据并像人类一样与网页交互。
更具体地说,Web MCP 提供了60 多种即用型 AI 工具,由 Bright Data 的网页交互与数据采集基础设施驱动。
即使在免费层,你也能使用两款颠覆性的工具:
| 工具 | 说明 |
|---|---|
search_engine |
从 Google、Bing 或 Yandex 获取搜索结果,返回 JSON 或 Markdown。 |
scrape_as_markdown |
将任意网页抓取为干净的 Markdown 格式,可绕过机器人检测和验证码。 |
除此之外,Web MCP 还包含用于云端浏览器自动化,以及从 YouTube、Amazon、LinkedIn、TikTok、Google 地图、Yahoo Finance 等平台提取结构化数据的工具。
通过 LibreChat 实际体验 Web MCP!
如何将 LibreChat 连接到 Web MCP
在本教程部分,你将学习如何在 LibreChat 中使用 Web MCP。无论你配置哪种 LLM,此设置都能带来增强的 AI 体验。
接下来你将看到,已配置的 AI 模型会利用 MCP 服务器公开的工具执行股票分析。这只是该集成所支持的众多用例之一。
注意:相同流程也适用于在 LibreChat AI agents 中启用 Web MCP 工具。
请按以下步骤操作!
先决条件
要跟随本教程,请确保你已具备:
- 本地已安装 Git。
- 本地已安装 Docker。
- 来自任一受支持提供商的 LLM API 密钥(本文示例使用 Gemini,因此需要 Google API key)。
- 带有 API key 的 Bright Data 账户。
不必现在就设置 Bright Data 账户,稍后步骤会引导你完成。了解MCP 的工作原理以及Bright Data Web MCP 可用工具也会有所帮助。
步骤一:开始使用 LibreChat
本地搭建 LibreChat 最简单的方法是通过 Docker 启动。先克隆项目仓库:
git clone https://github.com/danny-avila/LibreChat.git现在,在你偏好的 IDE(如 Visual Studio Code 或 IntelliJ IDEA)中打开 LibreChat/ 目录。
在克隆的仓库中,你会发现一个 .env.example 文件。这是 LibreChat 所需环境配置文件的示例。复制并重命名为 .env:
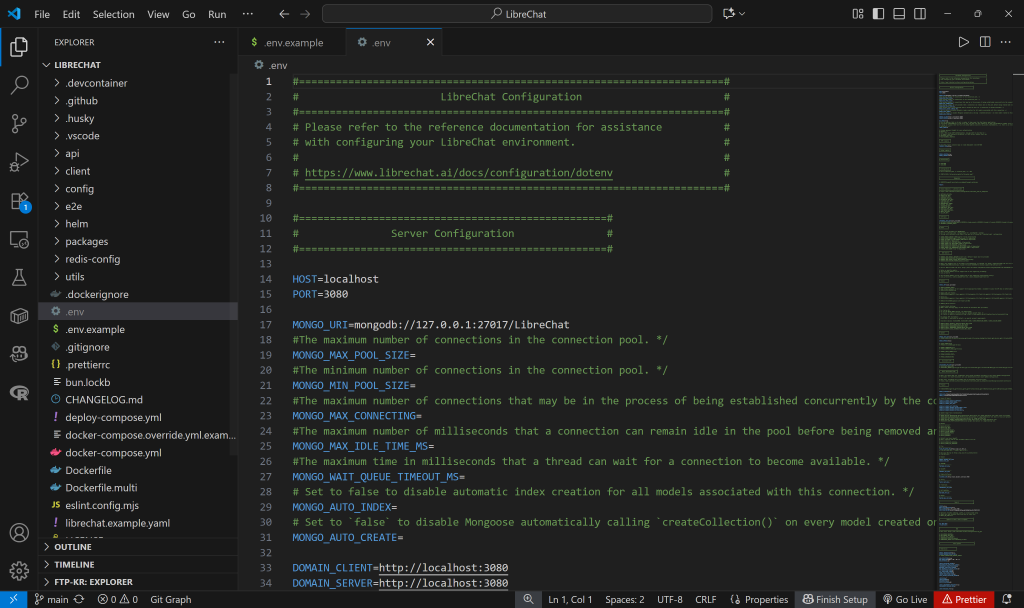
直接复制 .env.example 即可。如需更多信息,请参考官方 .env 配置指南。
注意项目中包含 docker-compose.yml 文件,这允许你通过 Docker 运行应用。使用以下命令启动应用:
docker compose up -d终端应看到类似如下的输出:

可以看到所有所需镜像均已拉取并启动。LibreChat 现在会在 http://localhost:3080 监听(在 .env 中配置)。在浏览器中打开该地址。
LibreChat 内置本地认证系统,你应看到如下页面:

点击“Sign up”创建本地账户。然后登录,你将看到如下聊天界面:

完成!你已成功运行 LibreChat。
步骤二:配置 LLM
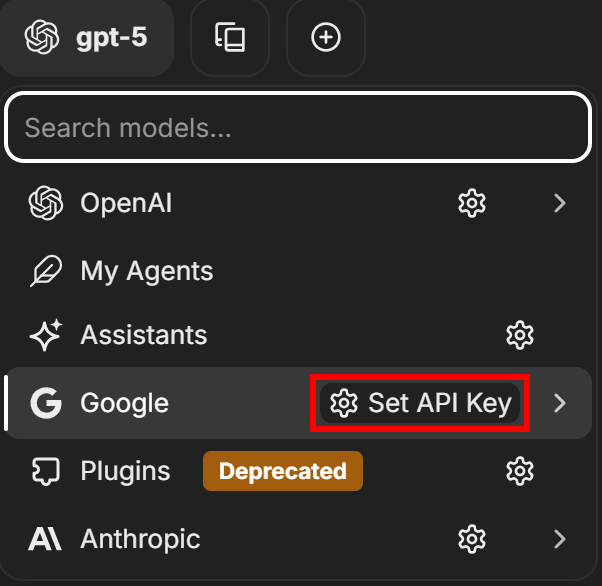
截至撰写时,LibreChat 默认使用 GPT-5 作为 LLM。要更改,点击左上角的“gpt-5”标签,选择一个 LLM 提供商(此处选择“Google”),然后点击“Set API Key”按钮:
随后会出现如下用于输入 Google API key 的模态框:
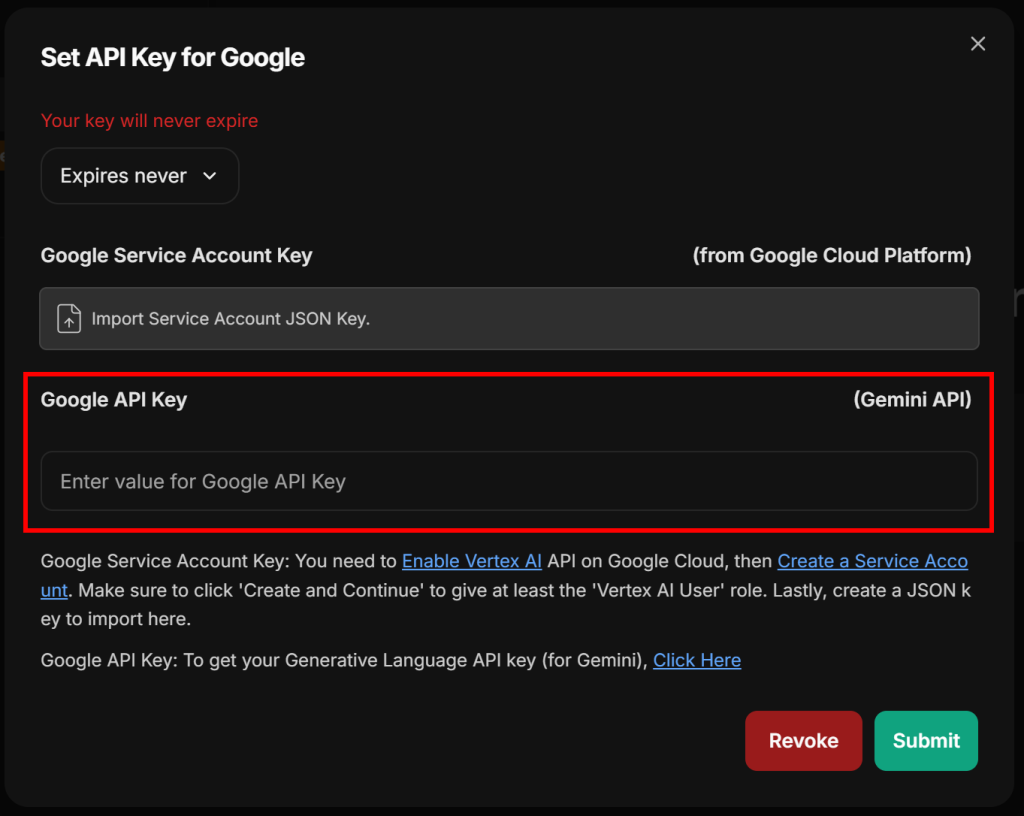
粘贴你的Google/Gemini API key,点击“Submit”确认。现在你可以选择一个可用的 Google AI 模型,例如 gemini-2.5-pro:
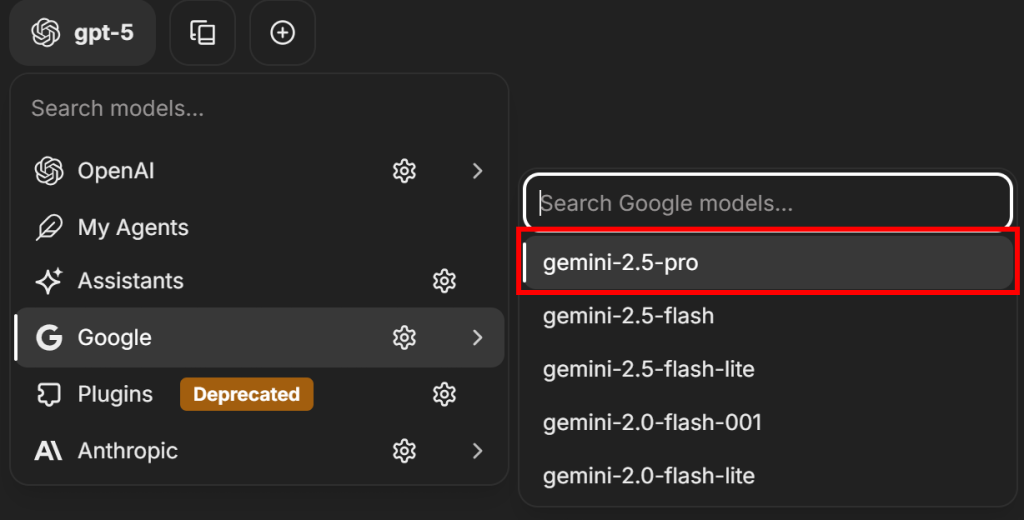
请注意,Gemini 2.5 Pro 每日包含 10,000 次 grounded prompts,且无需额外费用。
注意:你也可以通过相同流程配置其他受支持的 AI 模型。
很好!你已在 LibreChat 中准备好可用的 LLM。
步骤三:在本地测试 Bright Data 的 Web MCP
在将 LM Studio 连接到 Bright Data 的 Web MCP 之前,先确保你的本机能够运行 MCP 服务器。这很重要,因为我们将演示在本地连接 Web MCP。如果你选择通过 SSE 使用远程服务器,也可采用类似设置。
现在,先创建一个 Bright Data 账户。如果你已有账户,直接登录即可。为快速设置,请按照你账户中的“MCP”部分的指引操作:
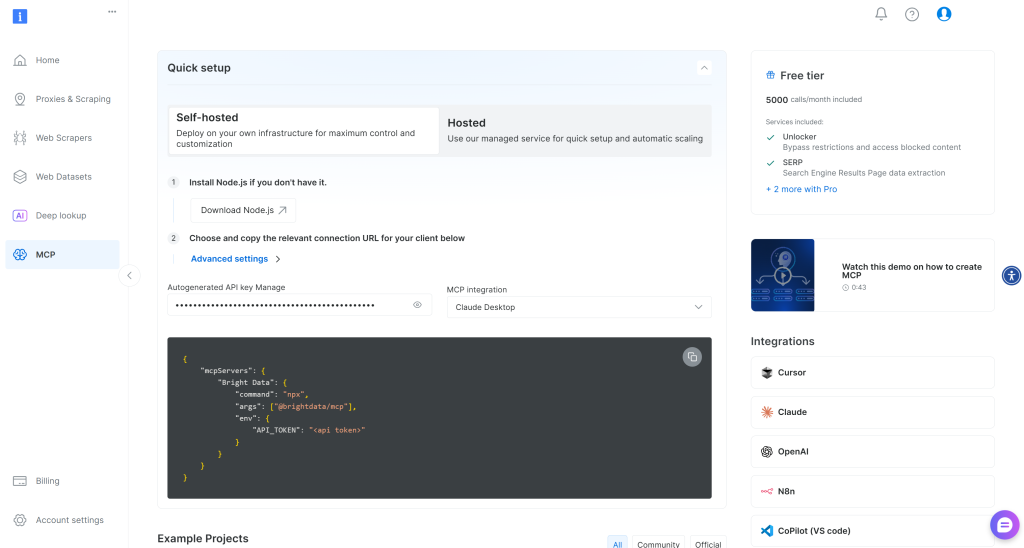
如需更多指导,你可以参考下述说明。
首先,获取你的 Bright Data API key。请妥善保存,下一步会用到。我们假设你的 API key 具有 Admin 权限,这将简化 Web MCP 的集成流程。
现在,通过下述 npm 命令在你的机器上全局安装 Web MCP:
npm install -g @brightdata/mcp通过运行以下命令验证 MCP 服务器能否在本地工作:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcp或者在 PowerShell 中:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp将 <YOUR_BRIGHT_DATA_API> 占位符替换为你的 Bright Data API token。上述两条(等效)命令会设置必需的 API_TOKEN 环境变量,并通过运行 @brightdata/mcp 包在本地启动 Web MCP。
如果成功,你应看到如下输出:

如你所见,首次启动时,Web MCP 会在你的 Bright Data 账户中自动创建两个默认 Zone:
mcp_unlocker:用于 Web Unlocker 的 Zone。mcp_browser:用于 Browser API 的 Zone。
为了驱动其 60 多个工具,Web MCP 依赖上述两项 Bright Data 服务。
若要验证这些 Zone 已创建,请前往 Bright Data 控制台中的“Proxies & Scraping Infrastructure”页面。你应能在表格中看到这两个 Zone:
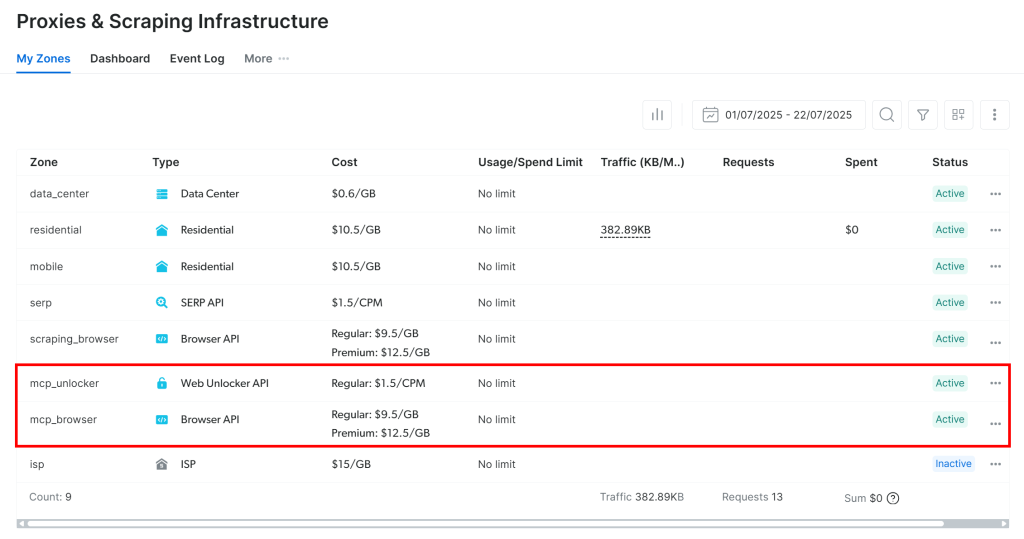
注意:如果你的 API token 不具备 Admin 权限,这两个 Zone 将不会被自动设置。此时你必须手动创建,并通过环境变量进行配置,具体参见GitHub 上的说明。
在Web MCP 免费层中,MCP 服务器仅开放 search_engine 与 scrape_as_markdown(及其批量版本)工具。要解锁所有工具,你必须启用 Pro 模式 **方法是设置 PRO_MODE="true" 环境变量:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcp或在 Windows 上:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpPro 模式可解锁全部 60+ 工具,但不包含在免费层中,会产生额外费用。
太棒了!你已验证 Web MCP 服务器在本机正常工作。停止 MCP 进程,准备配置 LibreChat 连接它。
步骤四:将 Web MCP 集成到 LibreChat
LibreChat 中的 MCP 集成通过 librechat.yaml 配置文件实现。与 .env 文件类似,该文件不随克隆的仓库提供,需要你自行创建;你可以参考 librechat.example.yaml 中的示例:
默认的 librechat.example.yaml 包含许多配置。本示例不需要大多数配置。为简化,创建如下 librechat.yaml:
version: "1.3.0"
mcpServers:
bright-data:
type: stdio
command: npx
args:
- -y
- "@brightdata/mcp"
env:
API_TOKEN: "<YOUR_BRIGHT_DATA_API_KEY>"
PRO_MODE: "true" # Optional
timeout: 300000 # 5 mins此配置与之前测试的 npx 命令一致,使用环境变量作为凭据与设置:
API_TOKEN为必填。将其设置为你之前获取的 Bright Data API key。PRO_MODE为可选。如果不想启用 Pro 模式,可移除此项。
注意,工具运行的超时设置为 300000 毫秒(5 分钟)。对于耗时较长的工具,如遇超时错误,可能需要增大该值。
现在,用以下命令重新加载 Docker 设置:
docker compose -f ./deploy-compose.yml down然后再次运行项目:
docker compose -f ./deploy-compose.yml up应用重载后,在浏览器访问 http://localhost:3080。在聊天输入框区域,你现在应能看到一个 “MCP Servers” 下拉框。展开后,你应看到上面配置的 “bright-data” MCP 选项。点击它,即可在 LibreChat 中加载 Web MCP 工具:
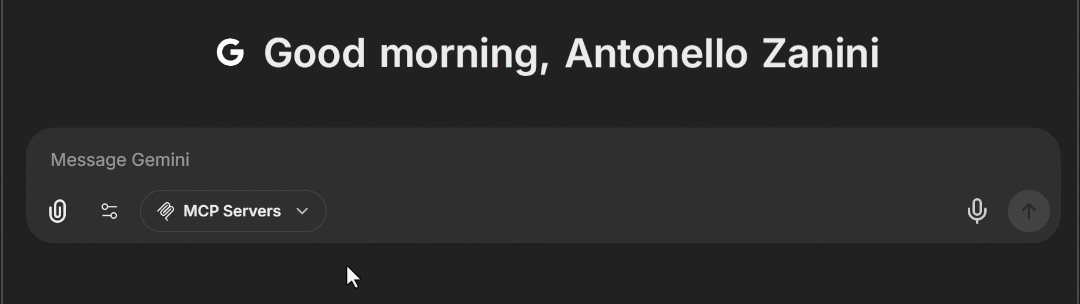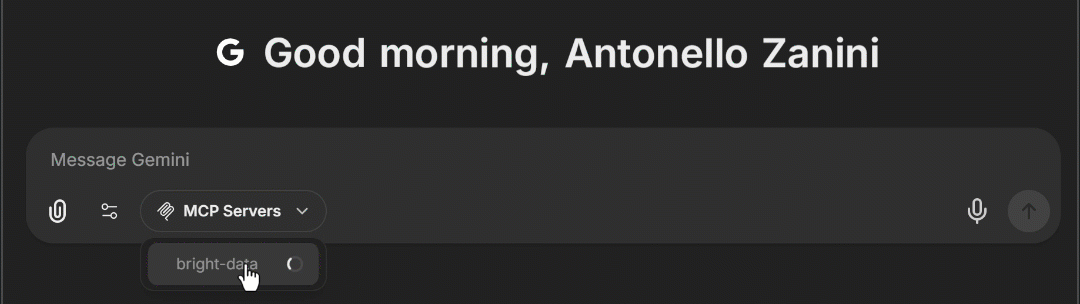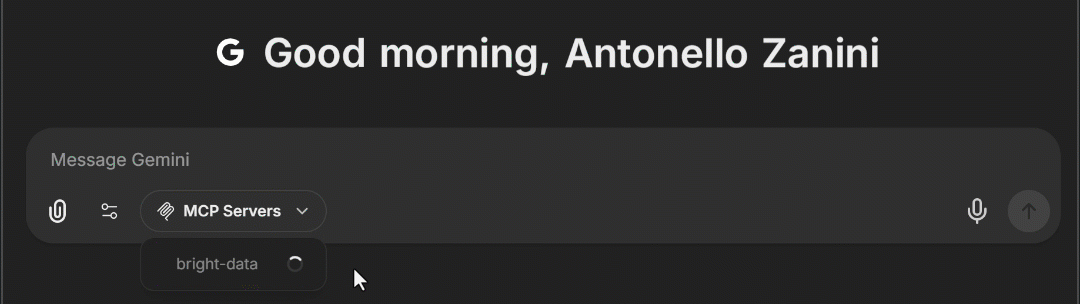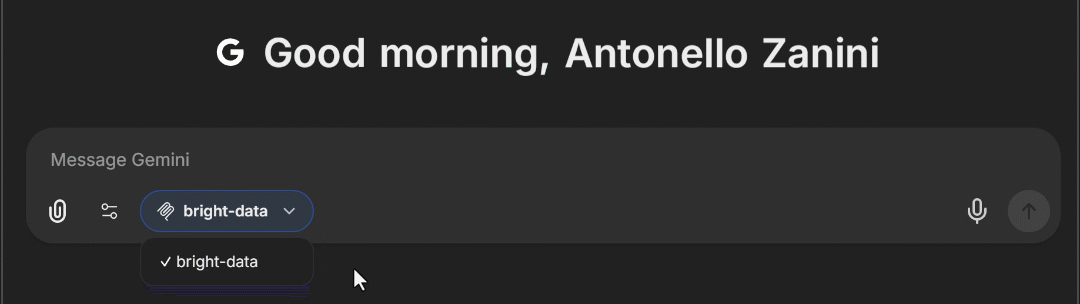
太好了!Bright Data 的 Web MCP 已成功集成进 LibreChat。
注意:LibreChat 还支持通过 Smithery 添加 MCP 服务器。可在文档中了解更多,并查看 Smithery 上的 Web MCP 服务器。
步骤五:验证 MCP 工具可用性
在 LibreChat 中启用 Web MCP 并等待其加载后,你配置的 AI 模型应可访问所有公开的工具。为验证,可运行如下提示:
Which tools from Bright Data’s Web MCP do you have access to?如果处于 Pro 模式,结果应为全部 60+ 工具的列表;若非 Pro 模式,则为 4/5 个免费工具:

输出应与 Web MCP 基于你所选模式(是否 Pro)所公开的工具列表一致,如上图所示。
步骤六:测试 MCP 服务器暴露的网页能力
LibreChat 中配置的 AI 模型现已可使用 Web MCP 提供的所有网页数据获取与交互能力。
为测试这一点,假设你发现了一只有趣的股票,想进一步了解。这是测试 Web MCP 的网页搜索与 Yahoo Finance 抓取工具的好机会。
例如,尝试如下提示:
Give me all the main information about the following company from Yahoo Finance:
"https://finance.yahoo.com/quote/IONQ/"
Then, search the web for the top 5 recent news articles about it, and return a list with their titles and links.请注意,原生的 Gemini 模型无法完成此任务。原因在于抓取 Yahoo Finance 因其机器人检测而较为棘手。结果是,标准的 Gemini 模型将无法从 Yahoo Finance 获取该公司的数据,并会改用其他方法:
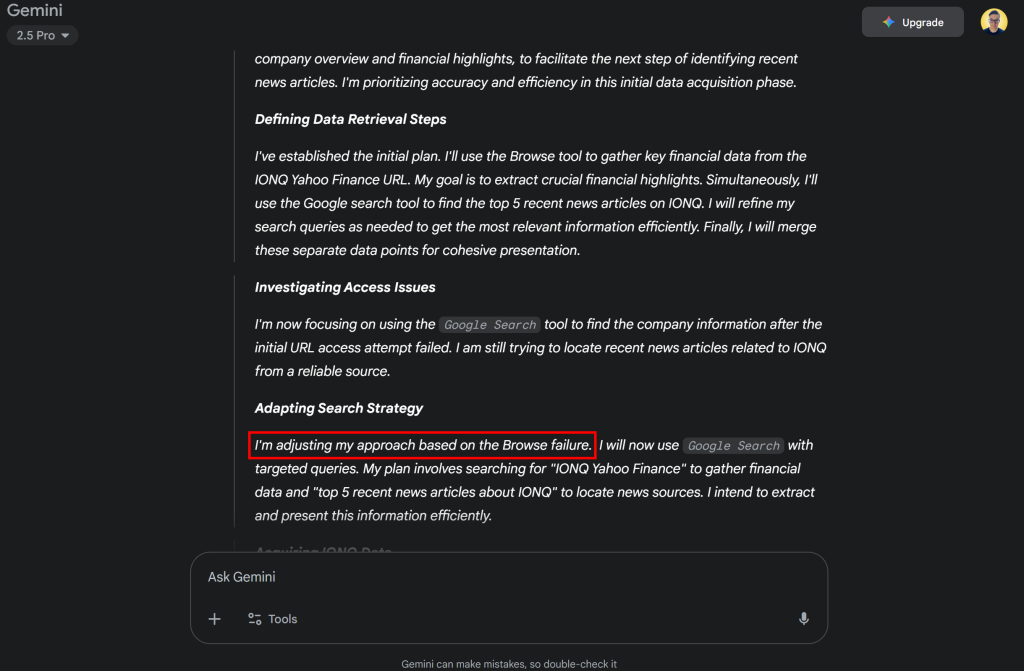
相反,得益于与 Web MCP 的集成,同一模型在 LibreChat 中即可达成目标。将 MCP 服务器配置为 Pro 模式,并在 LibreChat 中运行该提示进行验证。
你会看到 Gemini 模型识别出 web_data_yahoo_finance_business 与 search_engine 是完成任务所需的两个工具,并并行运行。它们的说明如下:
web_data_yahoo_finance_business:快速读取 Yahoo Finance 的结构化企业数据。需要有效的 Yahoo Finance 企业页面 URL。可能走缓存查找,因此比直接抓取更可靠。search_engine:抓取来自 Google、Bing 或 Yandex 的搜索结果。返回 Markdown 格式的 SERP(URL、标题、描述)。
因此,它们非常契合本任务!
展开各自的下拉即可查看返回的数据:
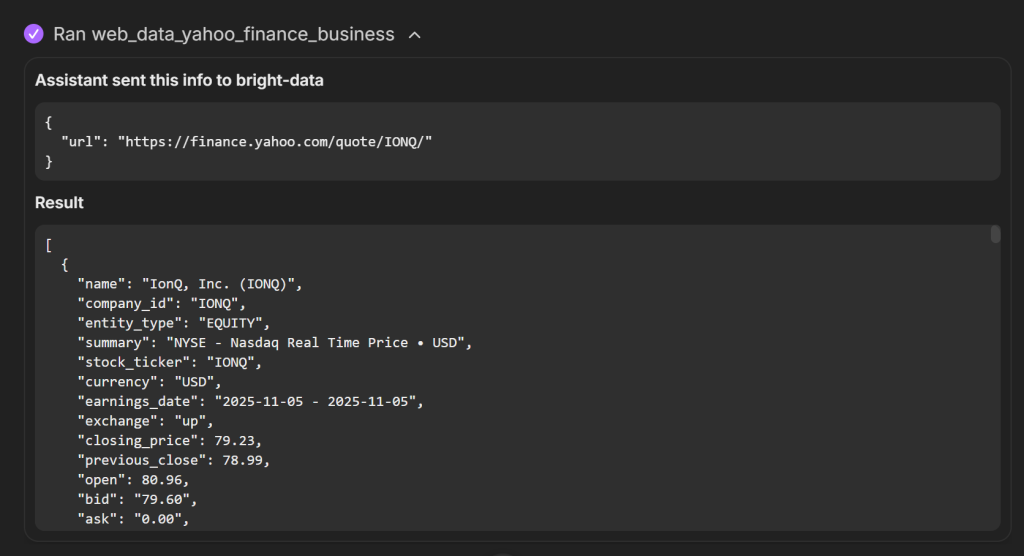
请注意,web_data_yahoo_finance_business 返回了 Yahoo Finance 的结构化数据。这是因为该工具在后台调用了 Yahoo Finance Scraper。这是 Bright Data 基础设施中专为 Yahoo Finance 提供的网页数据抓取器。
与此同时,search_engine 工具在 Google 上执行了类似“IONQ recent news”的查询,并以 Markdown 格式返回 SERP:
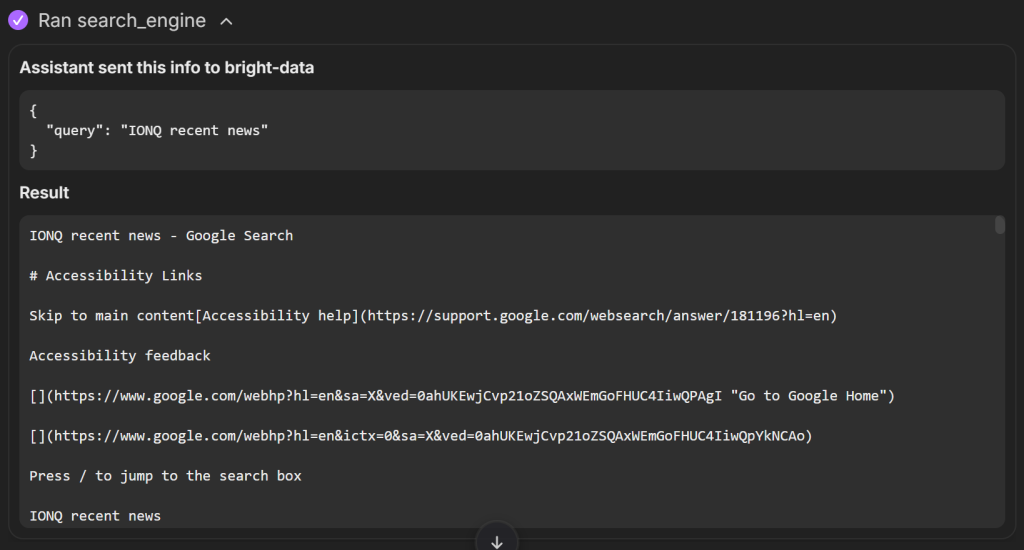
基于工具返回的数据,AI 汇总生成了如下报告,涵盖所有关键信息:

请注意,公司简介与 Yahoo Finance 页面上的信息一致:
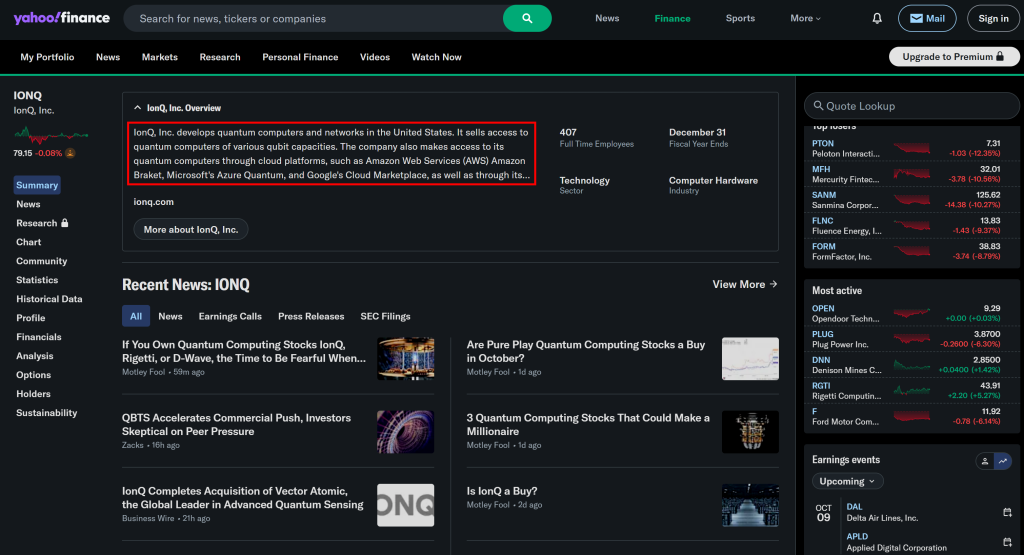
同样,链接指向有关该公司的最新新闻,来自 Google 新闻的提取。很酷!任务完成。
别忘了这只是一个示例。你可以尝试不同的提示。借助 Bright Data Web MCP 的丰富工具,你可以应对许多其他场景。
就这样!你已经体验了将 LibreChat 连接到 Bright Data 的 Web MCP 的强大之处。
结语
在本文中,你学会了如何在 LibreChat 中利用 MCP 集成。具体来说,你看到了如何使用 Bright Data 的 Web MCP 工具来扩展流行的 AI 模型。
正如本文所示,得益于 LibreChat 的灵活性,你选择的任意 LLM 都会自动获得 Web MCP 服务器公开的所有工具访问权限。
该集成为你的模型赋能,包括网页搜索、结构化数据抽取、实时网页数据馈送以及自动化网页交互等高级能力。若要构建复杂的 AI 工作流,欢迎探索Bright Data 的 AI 生态中提供的全套即用型服务。
立即创建免费的 Bright Data 账户,开始探索我们的网页数据工具吧!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




