摘要:让我们了解如何构建雅虎财经爬虫,来提取股票数据,以执行交易和投资的财务分析。
本教程将涵盖:
- 为什么要从网络抓取金融数据?
- 金融抓取库和工具
- 使用Selenium从雅虎财经抓取股票数据
为什么要从网络抓取金融数据?
从网络上抓取金融数据可以提供有价值的见解,在多种场景中发挥作用,包括:
- 自动交易:通过采集实时或历史市场数据,如股票价格和交易量,开发人员可以构建自动交易策略。
- 技术分析:历史市场数据和指标对于技术分析师极其重要。分析师能利用这些数据识别模式和趋势,辅助投资决策。
- 财务建模:研究人员和分析师可以采集财务报表和经济指标等相关数据,以构建复杂的模型来评估公司业绩、预测收益和评估投资机会。
- 市场研究:金融数据提供了大量股票、市场指数和商品的相关信息。分析这些数据有助于研究人员了解市场趋势、消费者情绪和行业状况,从而做出明智的投资决策。
在监控市场方面,雅虎财经是最受欢迎的财经网站之一。它为投资者和交易者提供大量信息和关于工具,如股票、债券、共同基金、商品、货币和市场指数的实时和历史数据。此外,它还提供新闻文章、财务报表、分析师预估、图表等有价值的资源。
通过抓取雅虎财经,您可以访问大量信息来支持您的财务分析、研究和决策过程。
金融数据抓取库和工具
Python语法简单,易于使用,并且拥有丰富的库生态系统,因此被认为是最适合抓取数据的编程语言之一。请查看指南:如何使用 Python 抓取网页。
要从众多可用的数据抓取库中选择正确的工具,请在浏览器中探索雅虎财经。您会注意到该网站上的大部分数据都会实时更新,或在交互后发生变化。这意味着该网站大量依赖AJAX技术,在不重新加载页面的情况下动态加载和更新数据。也就是说,您需要一个能够运行JavaScript的工具。
借助Selenium,我们可以在 Python 中抓取动态网站。即使网站使用JavaScript来渲染或检索数据,Selenium能通过网页浏览器渲染网站,并以编程方式执行操作。
有了Selenium,您就能够使用Python来抓取目标网站。让我们来了解一下具体操作!
使用Selenium,从雅虎财经抓取股票数据
按照此分步教程,了解如何创建Python脚本来抓取雅虎财经网页。
第1步:设置
在深入抓取网页之前,请确保满足以下先决条件:
- 在您的计算机上安装Python 3+:下载安装程序,双击运行,并按照安装向导的步骤完成操作。
- 选择一个Python IDE:PyCharm Community Edition或带有Python扩展的Visual Studio Code均可。
接下来,使用以下命令来设置一个带有虚拟环境的Python 项目:
mkdir yahoo-finance-scraper
cd yahoo-finance-scraper
python -m venv env这将初始化yahoo-finance-scraper项目文件夹。在项目文件夹内,添加一个scraper.py文件,如下所示:
print('Hello, World!')您将在此处添加抓取雅虎财经数据的逻辑。目前,它是一个仅打印“Hello, World!”的示例脚本。
运行程序以验证它是否有效:
python scraper.py在终端中,您会看到:
Hello, World!很好!现在您已经为雅虎财经爬虫创建了一个Python项目,接下来只需要添加项目的依赖项即可。请使用以下终端命令安装Selenium和Webdriver管理器:
pip install selenium webdriver-manager这一步可能需要些时间,请耐心等待。
虽然没有严格要求,但我们强烈建议您使用webdriver管理器,因为这能让您更容易在Selenium中管理网络驱动程序。有了该管理器,您无需再手动下载、配置和导入网络驱动程序。
更新scraper.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
# initialize a web driver instance to control a Chrome window
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# scraping logic...
# close the browser and free up the resources
driver.quit()此脚本创建了一个Chrome WebDriver的对象。接下来,您会用它来实现数据提取逻辑。
第2步:连接到目标网页
这是雅虎财经股票页面的URL:
https://finance.yahoo.com/quote/AMZN正如您所看到的,这是一个根据股票代码变化的动态URL。股票代码是一个字符串缩写,是在股市中交易的股票的唯一标识。例如,“AMZN”是亚马逊股票的股票代码。
接下来,我们来修改脚本,从命令行参数中读取股票代码。
import sys
# if there are no CLI parameters
if len(sys.argv) <= 1:
print('Ticker symbol CLI argument missing!')
sys.exit(2)
# read the ticker from the CLI argument
ticker_symbol = sys.argv[1]
# build the URL of the target page
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'sys是一个Python标准库,能够访问命令行参数。不要忘记,索引为0的参数是您的脚本名称。因此,请针对索引为1的参数进行操作。
从命令行页面(CLI)读取代码后,代码会被用于f 字符串中,生成要抓取的目标URL。
例如,假设要启动带有特斯拉股票代码“TSLA”的爬虫:
python scraper.py TSLA
url会包含:
https://finance.yahoo.com/quote/TSLA如果您忘记在命令行页面中输入股票代码,程序会运行失败并显示以下错误:
Ticker symbol CLI argument missing!我们建议您在Selenium中打开任何页面之前,先设置窗口大小,以确保能看到每个元素:
driver.set_window_size(1920, 1080)现在,您可以使用Selenium连接到目标页面:
driver.get(url)get ()函数会指示浏览器访问所需页面。
到这一步,您的雅虎财经抓取脚本将如下所示:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
import sys
# if there are no CLI parameters
if len(sys.argv) <= 1:
print('Ticker symbol CLI argument missing!')
sys.exit(2)
# read the ticker from the CLI argument
ticker_symbol = sys.argv[1]
# build the URL of the target page
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'
# initialize a web driver instance to control a Chrome window
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# set up the window size of the controlled browser
driver.set_window_size(1920, 1080)
# visit the target page
driver.get(url)
# scraping logic...
# close the browser and free up the resources
driver.quit()如果运行脚本,它会在终止前短暂打开此窗口:
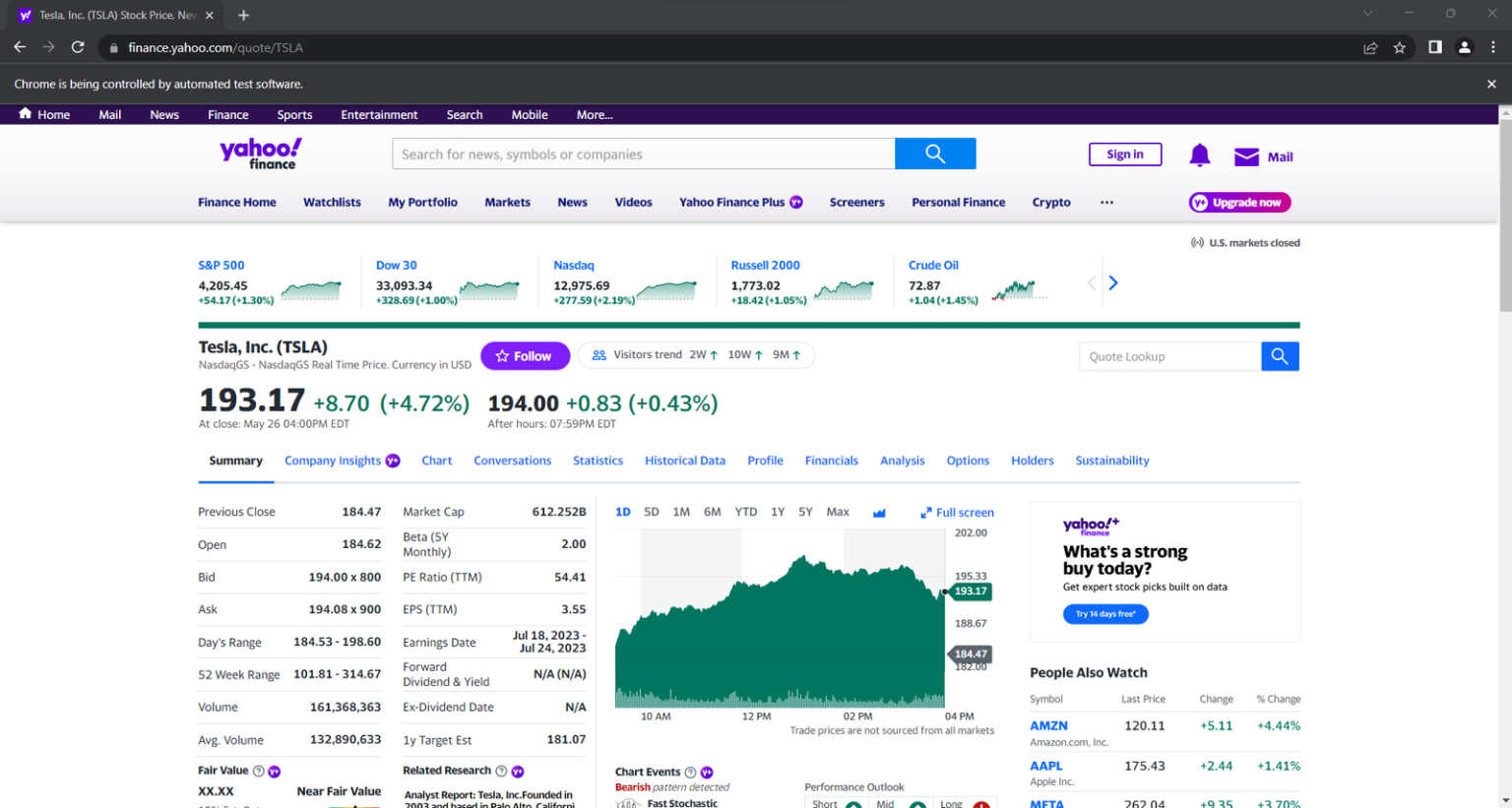
启动带有用户界面(UI)的浏览器,有助于通过监控爬虫在网页上执行的操作来进行调试。不过,以这种方式启动浏览器会占用大量资源。为避免此类情况,请将 Chrome 配置为在无头模式下运行:
from selenium.webdriver.chrome.options import Options
# ...
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)无头模式下,控制的浏览器会在后台启动,没有用户界面。
第3步:检查目标页面
如果您想构建有效的数据挖掘策略,首先必须分析目标网页。打开浏览器,访问雅虎股票页面。
如果您位于欧洲,您会首先看到一个模态框,要求您接受Cookies:
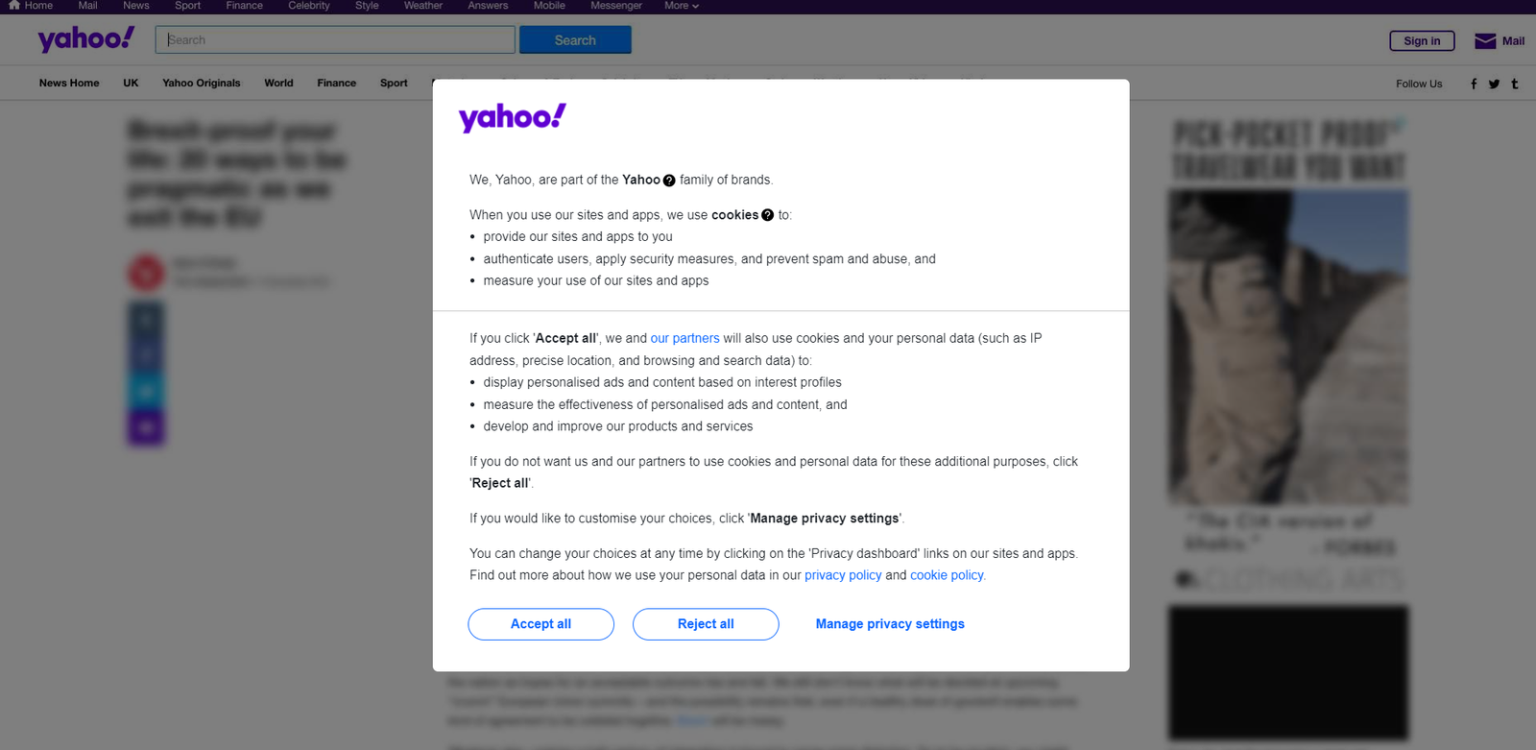
要关闭该模态框并继续访问所需页面,您必须单击“全部接受”或“全部拒绝”。右键单击第一个按钮,选择“检查/Inspect”选项以打开浏览器的开发者工具/DevTools:
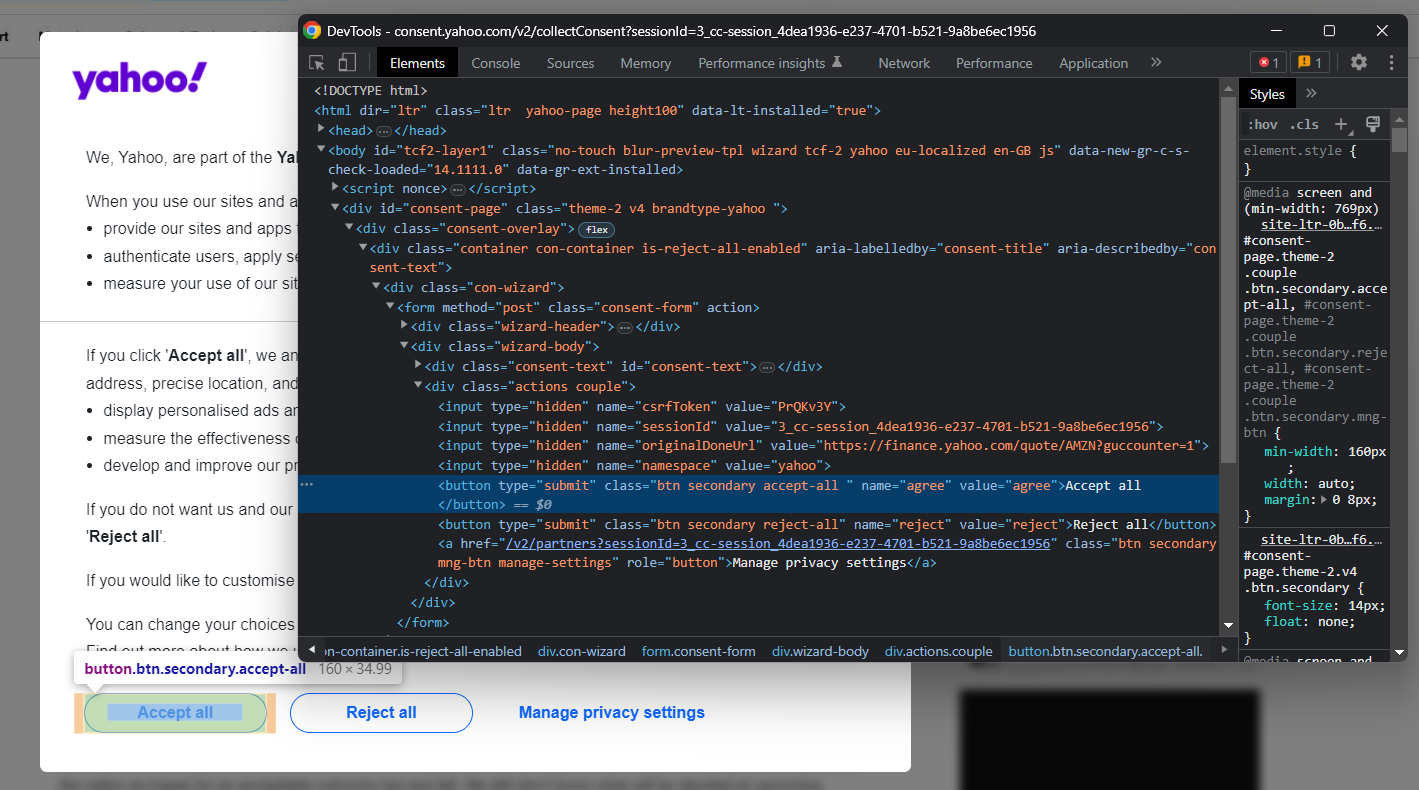
在这里您会注意到:您可以使用以下CSS 选择器选择该按钮:
.consent-overlay .accept-all使用这些代码行来处理Selenium中的同意模态框:
try:
# wait up to 3 seconds for the consent modal to show up
consent_overlay = WebDriverWait(driver, 3).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.consent-overlay')))
# click the "Accept all" button
accept_all_button = consent_overlay.find_element(By.CSS_SELECTOR, '.accept-all')
accept_all_button.click()
except TimeoutException:
print('Cookie consent overlay missing')WebDriverWait允许您等待页面上发生的预期条件。如果在指定的超时时间内没有任何反应,则会引发超时异常/TimeoutException 。只有当您的出口IP为欧洲时才会出现Cookies弹窗,因此您可以使用try-catch指令处理异常。这样,当同意模态框不存在时,脚本将继续运行。
为了使脚本正常工作,您需要添加以下导入语句:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutException现在,继续在开发者工具/DevTools 中检查目标站点,并熟悉其DOM(文档对象模型)结构。
第4步:提取股票数据
您在上一步可能已经注意到,本节有一些最有趣的信息:
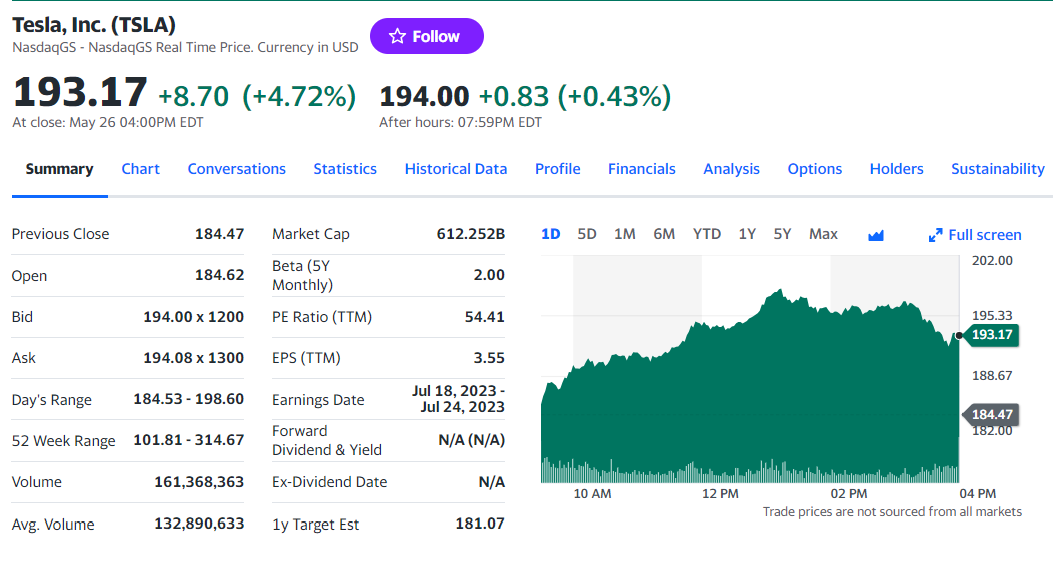
检查HTML价格指示器元素:
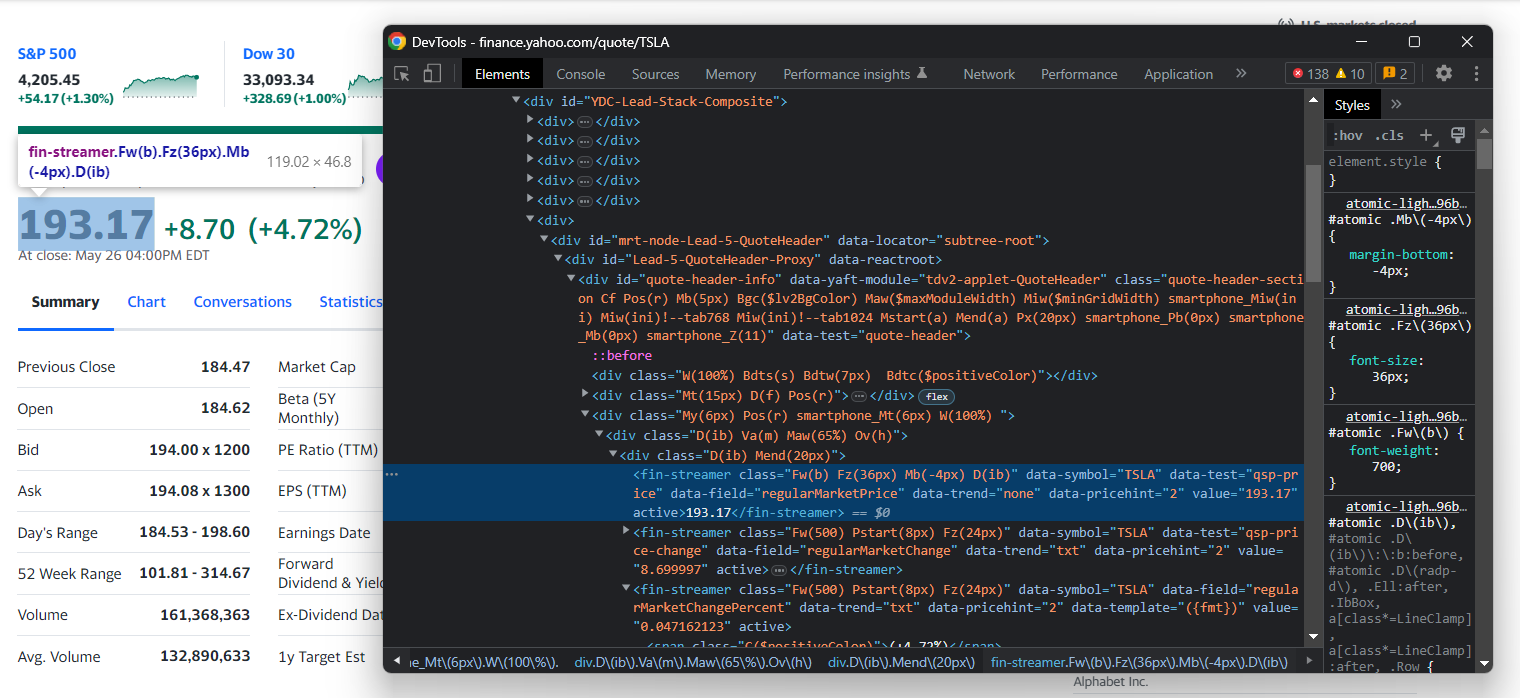
请注意,在雅虎财经中,无法使用CSS类来有效定义合适的选择器,因为它们的样式框架遵循特殊语法。因此,您应该关注其他HTML属性。例如,您可以使用以下CSS选择器获取股票价格:
[data-symbol="TSLA"][data-field="regularMarketPrice"]您可以按照类似方法,使用以下代码从价格指标中提取所有股票数据:
regular_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketPrice"]')
.text
regular_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChange"]')
.text
regular_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChangePercent"]')
.text
.replace('(', '').replace(')', '')
post_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketPrice"]')
.text
post_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChange"]')
.text
post_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChangePercent"]')
.text
.replace('(', '').replace(')', '')
通过特定的CSS选择器策略选择HTML元素后,您可以使用文本/text字段提取其内容。由于百分比字段涉及圆括号,因此可以使用Replace()将其删除。
将数据添加到股票字典中并打印,以验证抓取财经数据的过程是否符合预期:
# initialize the dictionary
stock = {}
# stock price scraping logic omitted for brevity...
# add the scraped data to the dictionary
stock['regular_market_price'] = regular_market_price
stock['regular_market_change'] = regular_market_change
stock['regular_market_change_percent'] = regular_market_change_percent
stock['post_market_price'] = post_market_price
stock['post_market_change'] = post_market_change
stock['post_market_change_percent'] = post_market_change_percent
print(stock)在想要抓取的证券上运行脚本,您应该看到与以下内容类似的信息:
{'regular_market_price': '193.17', 'regular_market_change': '+8.70', 'regular_market_change_percent': '+4.72%', 'post_market_price': '194.00', 'post_market_change': '+0.83', 'post_market_change_percent': '+0.43%'}您可以在#quote-summary表中找到其他有用的信息:
在这种情况下,您可以借助data-test属性提取每个数据字段,如以下CSS选择器所示:
#quote-summary [data-test="PREV_CLOSE-value"]使用以下代码抓取全部信息:
previous_close = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PREV_CLOSE-value"]').text
open_value = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="OPEN-value"]').text
bid = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BID-value"]').text
ask = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="ASK-value"]').text
days_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DAYS_RANGE-value"]').text
week_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="FIFTY_TWO_WK_RANGE-value"]').text
volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="TD_VOLUME-value"]').text
avg_volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="AVERAGE_VOLUME_3MONTH-value"]').text
market_cap = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="MARKET_CAP-value"]').text
beta = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BETA_5Y-value"]').text
pe_ratio = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PE_RATIO-value"]').text
eps = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EPS_RATIO-value"]').text
earnings_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EARNINGS_DATE-value"]').text
dividend_yield = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DIVIDEND_AND_YIELD-value"]').text
ex_dividend_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EX_DIVIDEND_DATE-value"]').text
year_target_est = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="ONE_YEAR_TARGET_PRICE-value"]').text然后,将数据添加到股票中:
stock['previous_close'] = previous_close
stock['open_value'] = open_value
stock['bid'] = bid
stock['ask'] = ask
stock['days_range'] = days_range
stock['week_range'] = week_range
stock['volume'] = volume
stock['avg_volume'] = avg_volume
stock['market_cap'] = market_cap
stock['beta'] = beta
stock['pe_ratio'] = pe_ratio
stock['eps'] = eps
stock['earnings_date'] = earnings_date
stock['dividend_yield'] = dividend_yield
stock['ex_dividend_date'] = ex_dividend_date
stock['year_target_est'] = year_target_est很好!您刚刚使用Python抓取了财经网页!
第5步:抓取股票信息
多元化投资组合包含不止一种证券。要检索所有投资组合数据,您需要扩展脚本来抓取多个股票代码。
首先,将抓取逻辑封装在一个函数中:
def scrape_stock(driver, ticker_symbol):
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'
driver.get(url)
# deal with the consent modal...
# initialize the stock dictionary with the
# ticker symbol
stock = { 'ticker': ticker_symbol }
# scraping the desired data and populate
# the stock dictionary...
return stock然后,迭代CLI股票代码参数并应用抓取函数:
if len(sys.argv) <= 1:
print('Ticker symbol CLI arguments missing!')
sys.exit(2)
# initialize a Chrome instance with the right
# configs
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
driver.set_window_size(1150, 1000)
# the array containing all scraped data
stocks = []
# scraping all market securities
for ticker_symbol in sys.argv[1:]:
stocks.append(scrape_stock(driver, ticker_symbol))在for循环结束时,Python字典中的股票列表会包含所有股市数据。
第6步:将抓取的数据导出为CSV文件
您可以输入几行代码将采集的数据以CSV格式导出:
import csv
# ...
# extract the name of the dictionary fields
# to use it as the header of the output CSV file
csv_header = stocks[0].keys()
# export the scraped data to CSV
with open('stocks.csv', 'w', newline='') as output_file:
dict_writer = csv.DictWriter(output_file, csv_header)
dict_writer.writeheader()
dict_writer.writerows(stocks)这段代码使用open()创建了一个名为stocks.csv的文件,以标题行初始化文件并填充数据。具体而言,DictWriter.writerows()将每个字典转换为CSV记录并将其附加到输出文件。
由于csv来自Python标准库,您甚至无需安装额外的依赖项即可实现所需的目标。
您从网页中包含的原始数据开始,现在有了存储在CSV文件中的半结构化数据。是时候查看整个雅虎财经爬虫了。
第7步:整合所有内容
以下是完整的scraper.py文件:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutException
import sys
import csv
def scrape_stock(driver, ticker_symbol):
# build the URL of the target page
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'
# visit the target page
driver.get(url)
try:
# wait up to 3 seconds for the consent modal to show up
consent_overlay = WebDriverWait(driver, 3).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.consent-overlay')))
# click the 'Accept all' button
accept_all_button = consent_overlay.find_element(By.CSS_SELECTOR, '.accept-all')
accept_all_button.click()
except TimeoutException:
print('Cookie consent overlay missing')
# initialize the dictionary that will contain
# the data collected from the target page
stock = { 'ticker': ticker_symbol }
# scraping the stock data from the price indicators
regular_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketPrice"]')
.text
regular_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChange"]')
.text
regular_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChangePercent"]')
.text
.replace('(', '').replace(')', '')
post_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketPrice"]')
.text
post_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChange"]')
.text
post_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChangePercent"]')
.text
.replace('(', '').replace(')', '')
stock['regular_market_price'] = regular_market_price
stock['regular_market_change'] = regular_market_change
stock['regular_market_change_percent'] = regular_market_change_percent
stock['post_market_price'] = post_market_price
stock['post_market_change'] = post_market_change
stock['post_market_change_percent'] = post_market_change_percent
# scraping the stock data from the "Summary" table
previous_close = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PREV_CLOSE-value"]').text
open_value = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="OPEN-value"]').text
bid = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BID-value"]').text
ask = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="ASK-value"]').text
days_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DAYS_RANGE-value"]').text
week_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="FIFTY_TWO_WK_RANGE-value"]').text
volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="TD_VOLUME-value"]').text
avg_volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="AVERAGE_VOLUME_3MONTH-value"]').text
market_cap = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="MARKET_CAP-value"]').text
beta = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BETA_5Y-value"]').text
pe_ratio = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PE_RATIO-value"]').text
eps = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EPS_RATIO-value"]').text
earnings_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EARNINGS_DATE-value"]').text
dividend_yield = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DIVIDEND_AND_YIELD-value"]').text
ex_dividend_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EX_DIVIDEND_DATE-value"]').text
year_target_est = driver.find_element(By.CSS_SELECTOR,
'#quote-summary [data-test="ONE_YEAR_TARGET_PRICE-value"]').text
stock['previous_close'] = previous_close
stock['open_value'] = open_value
stock['bid'] = bid
stock['ask'] = ask
stock['days_range'] = days_range
stock['week_range'] = week_range
stock['volume'] = volume
stock['avg_volume'] = avg_volume
stock['market_cap'] = market_cap
stock['beta'] = beta
stock['pe_ratio'] = pe_ratio
stock['eps'] = eps
stock['earnings_date'] = earnings_date
stock['dividend_yield'] = dividend_yield
stock['ex_dividend_date'] = ex_dividend_date
stock['year_target_est'] = year_target_est
return stock
# if there are no CLI parameters
if len(sys.argv) <= 1:
print('Ticker symbol CLI argument missing!')
sys.exit(2)
options = Options()
options.add_argument('--headless=new')
# initialize a web driver instance to control a Chrome window
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# set up the window size of the controlled browser
driver.set_window_size(1150, 1000)
# the array containing all scraped data
stocks = []
# scraping all market securities
for ticker_symbol in sys.argv[1:]:
stocks.append(scrape_stock(driver, ticker_symbol))
# close the browser and free up the resources
driver.quit()
# extract the name of the dictionary fields
# to use it as the header of the output CSV file
csv_header = stocks[0].keys()
# export the scraped data to CSV
with open('stocks.csv', 'w', newline='') as output_file:
dict_writer = csv.DictWriter(output_file, csv_header)
dict_writer.writeheader()
dict_writer.writerows(stocks)您用不到150行代码构建了一个功能齐全的爬虫来从雅虎财经中检索数据。
针对您的目标股票启动爬虫,如下所示:
python scraper.py TSLA AMZN AAPL META NFLX GOOG在抓取过程结束时,此stocks.csv文件将出现在项目的根文件夹中:

结论
在本教程中,您了解了为什么雅虎财经是最好的金融门户之一,以及如何从中提取数据。特别是,您了解了如何构建一个可以从中检索股票数据的Python爬虫。正如本文所示所示,这并不复杂,只需要几行代码。
同时,雅虎财经是一个严重依赖JavaScript的动态网站。在处理此类网站时,采取基于HTTP库和HTML解析器的传统方法是不够的。最重要的是,这些热门网站往往会实施高级的数据保护技术。因此,想要抓取数据,您需要一个可控制的浏览器,它能够自动为您解决验证码、指纹识别、自动重试等。这正是我们全新的亮数据浏览器解决方案所关注的!
完全不想处理网络抓取,但又对财务数据感兴趣?探索我们的数据集市场。







