

一份分步指南,教你如何在 Google Cloud 上使用 Cloud Run、Firestore、BigQuery、Workflows 和 Cloud Scheduler 构建无服务器抓取流水线。
在本文中,你将学习:
- 为什么无服务器架构非常适合网页抓取流水线。
- 如何从零开始搭建所需的 Google Cloud 基础设施。
- 如何在 Cloud Run 上部署一个私有的抓取服务(scraper service)和一个公开的 API 服务。
- 如何使用 Cloud Workflows 编排抓取任务,并使用 Cloud Scheduler 将其自动化。
- 如何使用 Firestore 与 BigQuery 存储并查询抓取数据。
- 如何验证你的整条流水线端到端正常工作。
让我们开始吧!
为什么要构建无服务器抓取流水线?
大多数抓取教程止步于脚本层面:你拿到一些 HTML,可能解析几个字段,然后就结束了。但当你要在生产环境运行抓取器时,你需要回答更难的问题:数据要存到哪里?如何按计划运行?之后如何查询结果?当抓取器不运行时,如何保持低成本?
这就是无服务器的价值所在。Google Cloud Run 只在你的服务处理请求时计费。无需管理服务器,也不会有闲置算力在夜里持续烧钱。把它与用于任务追踪的 Firestore、用于分析的 BigQuery,以及用于编排的 Cloud Workflows 组合起来,你就能得到一个数据流水线架构:空闲时可扩展到零,按需启动。
在本指南结束时,你将拥有:
- 一个在 Cloud Run 上运行的私有
scraper-service,负责实际抓取。 - 一个在 Cloud Run 上运行的公开
api-service,用于对外提供数据。 - 用于追踪任务状态与结果的 Firestore collections。
- 一个可用于分析查询的 BigQuery table。
- 一个编排整次抓取运行的 Cloud Workflow。
- 一个按 cron 定时触发的 Cloud Scheduler 任务。
理解整体架构
在开始执行命令之前,先理解各个组件如何连接会更有帮助。我们在首次搭建时花了不少时间来确定正确的架构,因此下面带你快速过一遍。
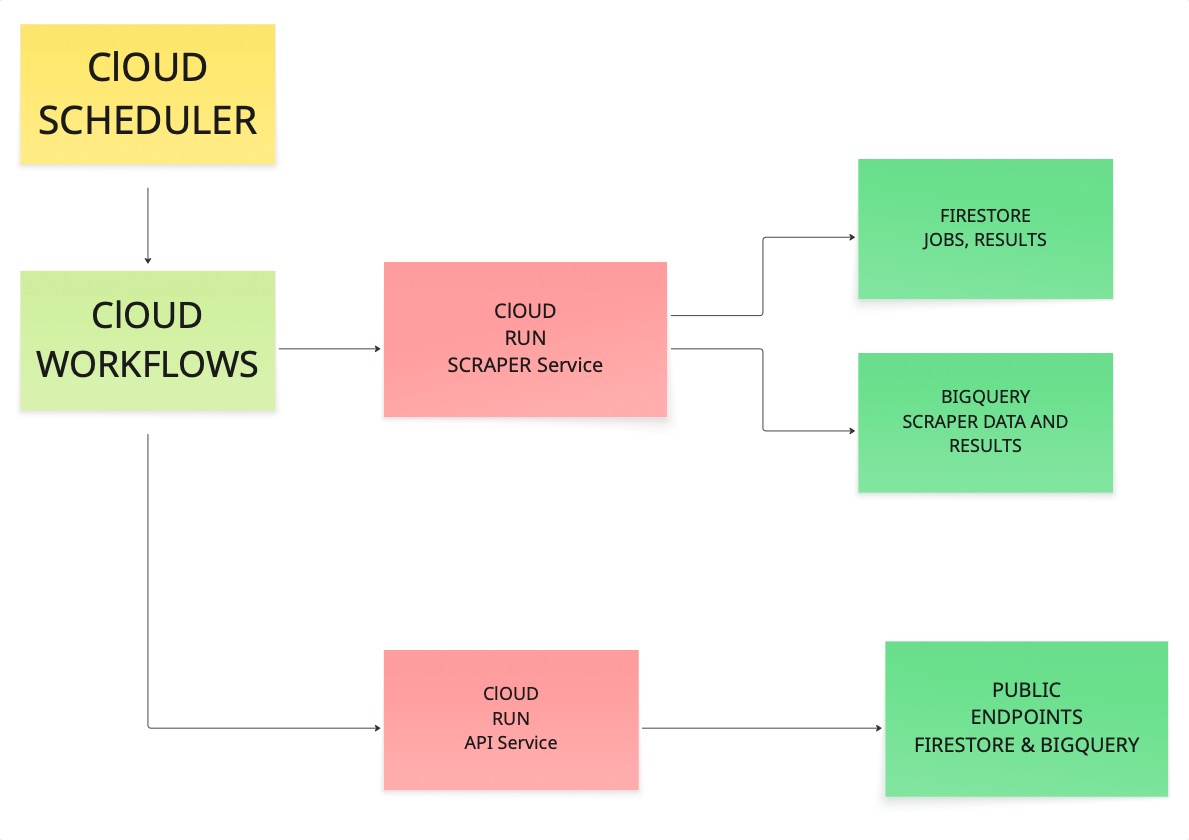
调度器触发工作流;工作流调用抓取器;抓取器访问 URL、拉取内容,并将结果写入 Firestore 与 BigQuery;随后 API 服务从这些存储中读取数据,并通过公开端点对外提供。
如果链路中的每个环节都能正常工作,你就拥有了一个可在生产环境依赖的系统。
前置条件
在开始之前,请确保你具备以下条件:
- 一个 Google 账号。
- 一个已启用计费的 GCP 项目(成本很低,但必须启用计费)。
- Node.js 18 或更高版本。
- 在本机安装
gcloudCLI。
运行一个快速检查:
node --version
npm --version
gcloud --version如果这三个命令都能输出版本号,就说明你已准备就绪。
设置你的 Google Cloud 项目
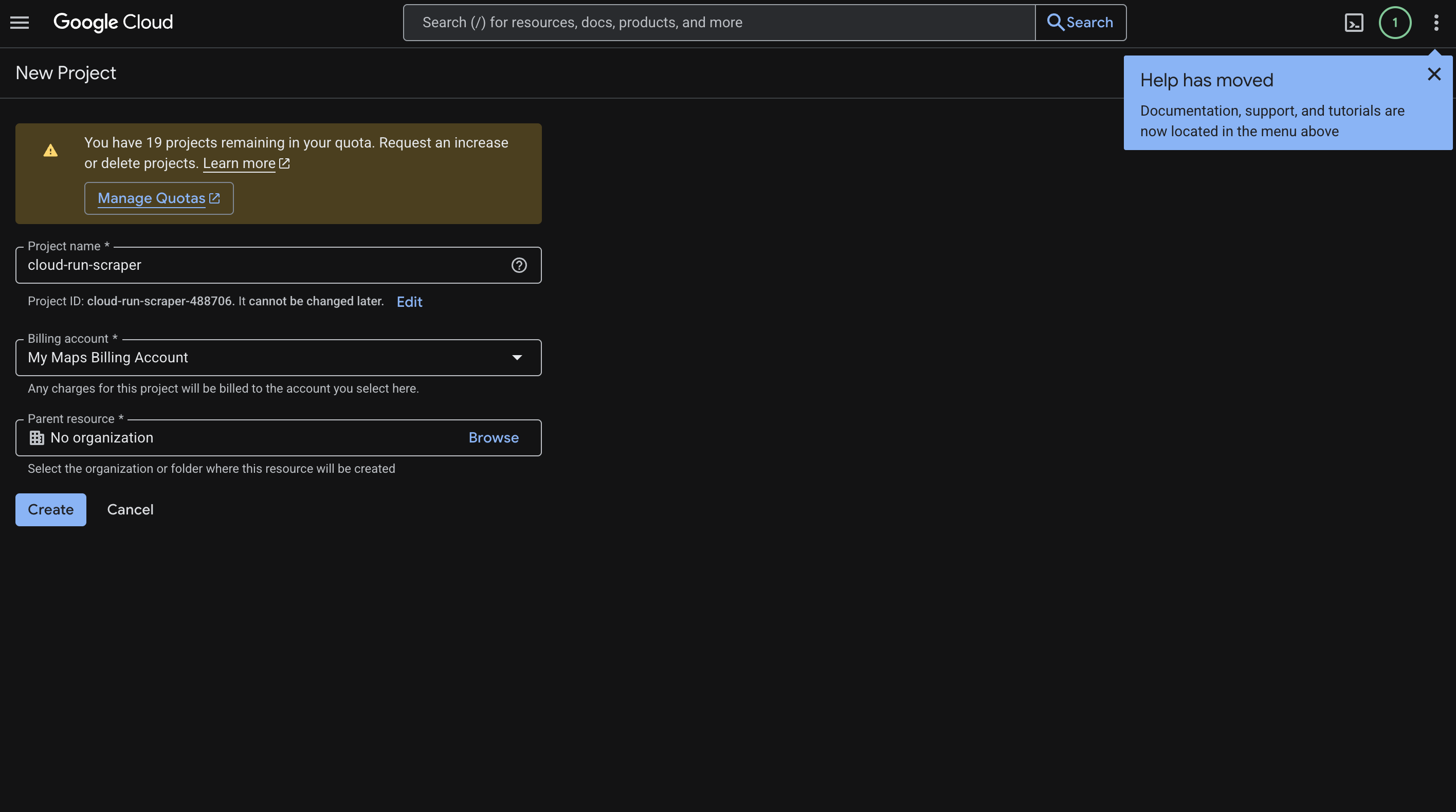
前往 Cloud Console 并创建一个新项目。我们将其命名为 cloud-run-scraper,但你可以根据自己的用例取任何合适的名字。
具体操作如下:
- 输入项目名称。
- 点击 Create。
- 复制生成的 Project ID(类似
cloud-run-scraper-123456)。本指南中会反复用到它。 - 前往 Billing 并将一个计费账号关联到该项目。
该页面大致如下所示:
配置你的 Shell
我们建议先设置一些环境变量,以免到处复制粘贴项目 ID。这样命令更干净也更易复用:
export PROJECT_ID="YOUR_PROJECT_ID"
export REGION="us-central1"
export REPO_NAME="cloud-run-scraper-repo"
export BQ_DATASET="scraper_data"
export BQ_TABLE="scraped_results"然后让 gcloud 指向你的项目:
gcloud config set project "$PROJECT_ID"
gcloud config set run/region "$REGION"并进行认证(会打开浏览器):
gcloud auth login
gcloud auth application-default login启用所需的 API
Google Cloud 有一点容易让人踩坑:在你显式启用所需 API 之前,很多东西都无法工作。可以把这理解为打开断路器。运行一次即可:
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
workflows.googleapis.com \
artifactregistry.googleapis.com \
cloudscheduler.googleapis.com \
bigquery.googleapis.com \
firestore.googleapis.com \
secretmanager.googleapis.com你可以用下面的命令验证它们都已启用:
gcloud services list --enabled | rg "run.googleapis.com|cloudbuild.googleapis.com|workflows.googleapis.com|artifactregistry.googleapis.com|cloudscheduler.googleapis.com|bigquery.googleapis.com|firestore.googleapis.com"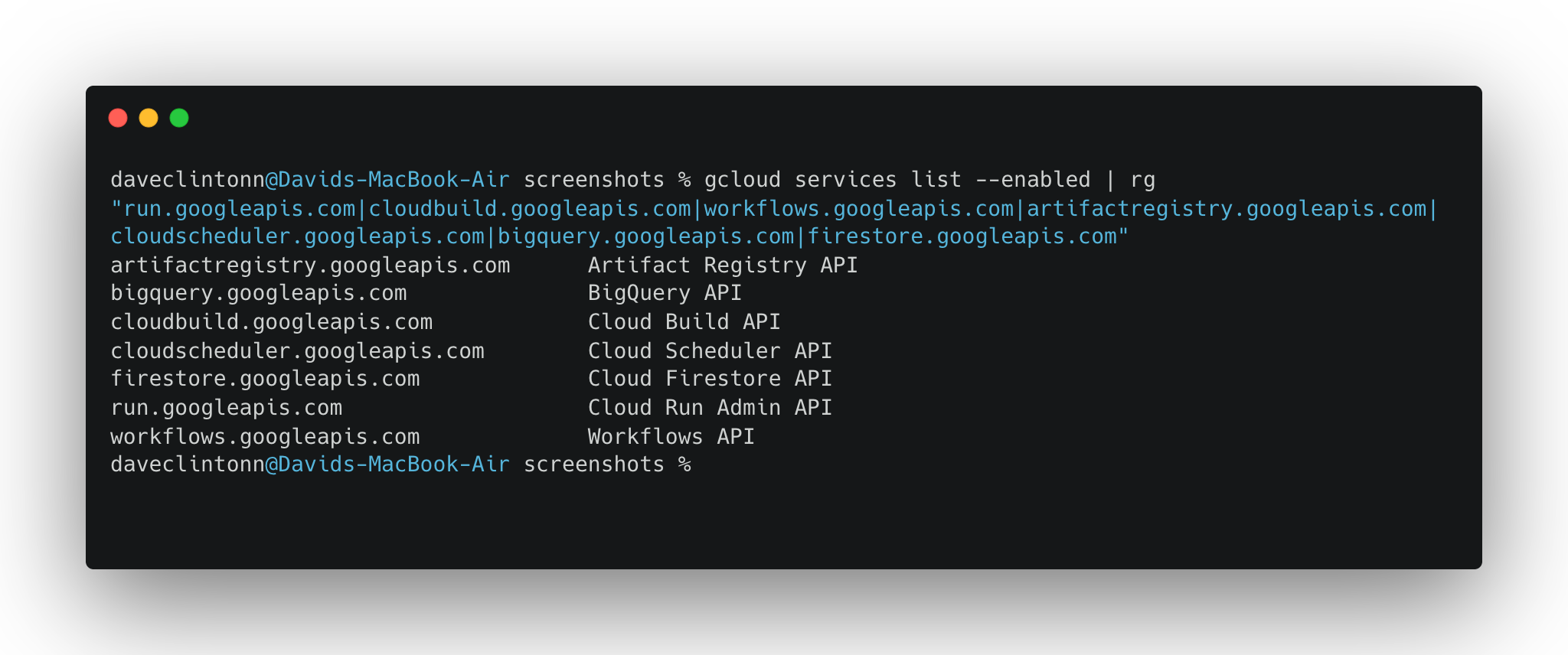
设置 Firestore
我们需要以 Native mode 启用 Firestore,用于存储任务追踪数据与抓取结果:
gcloud firestore databases create --location="$REGION" --type=firestore-native如果你在该项目中已经设置过 Firestore,可以跳过此步骤。它会报错提示数据库已存在。
创建 Artifact Registry
Artifact Registry 用于存放你的 Docker 镜像。可以把它理解为 GCP 上的私有容器仓库:
gcloud artifacts repositories create "$REPO_NAME" \
--repository-format=docker \
--location="$REGION" \
--description="Docker images for cloud-run-scraper"然后让 Docker 知道如何对其进行认证:
gcloud auth configure-docker "$REGION-docker.pkg.dev"设置 BigQuery
现在我们将创建 BigQuery dataset 与 table,用于接收抓取数据。这正是让整条流水线真正有用的关键——一个结构良好的 ETL 流水线能让你对全部抓取数据运行 SQL 查询,从而发现趋势、按来源过滤或构建仪表盘。
创建 dataset:
bq --location="$REGION" mk -d "$PROJECT_ID:$BQ_DATASET"然后用抓取器使用的 schema 创建 table:
bq mk --table \
"$PROJECT_ID:$BQ_DATASET.$BQ_TABLE" \
url:STRING,title:STRING,content:STRING,scraped_at:TIMESTAMP,job_id:STRING,source:STRING,metadata:STRING快速检查是否成功:
bq show "$PROJECT_ID:$BQ_DATASET.$BQ_TABLE"配置正确的 IAM 权限
这部分可能没那么有趣,但至关重要。你的 Cloud Run 服务需要权限来访问 Firestore、BigQuery,并彼此调用。没有这些 IAM 绑定,你会遇到莫名其妙的 403 错误,而且往往很难定位原因。
首先,获取你的 compute service account:
PROJECT_NUMBER=$(gcloud projects describe "$PROJECT_ID" --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}[email protected]"
echo "$COMPUTE_SA"然后授予所需角色:
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/datastore.user"
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.dataEditor"
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.jobUser"
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/run.invoker"
gcloud projects add-iam-policy-binding "$PROJECT_ID" \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/workflows.invoker"这五个角色绑定分别允许该 service account 执行特定操作:读写 Firestore、写入 BigQuery、调用 Cloud Run 服务,以及触发工作流。
安装依赖
在仓库根目录下,为两个服务安装依赖:
npm --prefix scraper-service install
npm --prefix api-service install部署抓取服务(Scraper Service)
这是整条流水线的主力服务:它会访问 URL、拉取内容,并将结果写入 Firestore 和 BigQuery。如果你希望在抓取器中处理更复杂的反爬场景,像 Bright Data 的 Scraping Browser 这类工具值得考虑,可用于在云端进行可规模化的浏览器自动化。
我们将其部署为私有服务。注意 --no-allow-unauthenticated 这个参数。只有经过认证的请求(例如来自工作流的请求)才能调用它:
gcloud run deploy scraper-service \
--source ./scraper-service \
--region "$REGION" \
--memory 2Gi \
--cpu 2 \
--timeout 300 \
--no-allow-unauthenticated \
--set-env-vars NODE_ENV=production部署完成后获取它的 URL:
SCRAPER_URL=$(gcloud run services describe scraper-service --region "$REGION" --format='value(status.url)')
echo "$SCRAPER_URL"把这个 URL 保存好,后面配置工作流会用到。
部署 API 服务
API 服务是流水线对外公开的一侧。它从 Firestore 与 BigQuery 读取数据并暴露端点,以便你或前端应用访问抓取数据:
gcloud run deploy api-service \
--source ./api-service \
--region "$REGION" \
--memory 512Mi \
--cpu 1 \
--timeout 60 \
--allow-unauthenticated \
--set-env-vars NODE_ENV=production获取 URL:
API_URL=$(gcloud run services describe api-service --region "$REGION" --format='value(status.url)')
echo "$API_URL"测试已部署的服务
现在进入最有趣的部分:实际请求你的线上服务并确认一切正常。请记住,即使在无服务器架构下,常见的网页抓取挑战(例如 IP 封锁与限流)仍然可能影响抓取器,因此从一开始就规划应对策略是值得的。
先对 API 服务试试这些请求:
curl -s "$API_URL/"
curl -s "$API_URL/jobs?limit=10"
curl -s "$API_URL/analytics/summary"对于抓取服务,由于它是私有服务,你需要传入 auth token:
curl -s -X POST \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{"url":"http://books.toscrape.com"}' \
"$SCRAPER_URL/scrape"如果你想定位页面中的特定元素,也可以传入自定义 CSS selector:
curl -s -X POST \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{"url":"http://books.toscrape.com","selectors":{"title":"h1, h2","content":"p, article"}}' \
"$SCRAPER_URL/scrape"设置工作流(Workflow)
工作流负责把抓取器和定时运行连接起来。它是一个 YAML 文件,用于告诉 Cloud Workflows:对列表中的每个 URL 调用抓取器。
打开 workflows/scrape-pipeline.yaml,把 scraper_url 设置为你在部署抓取服务步骤中拿到的 URL。
然后部署:
gcloud workflows deploy scrape-pipeline \
--location "$REGION" \
--source workflows/scrape-pipeline.yaml \
--service-account "$COMPUTE_SA"创建 Scheduler 任务
到这里,这条流水线就实现了完全自动化。我们将创建一个 cron 任务,在每天 UTC 时间 06:00 运行工作流:
gcloud scheduler jobs create http scrape-pipeline-daily \
--location "$REGION" \
--schedule "0 6 * * *" \
--uri "https://workflowexecutions.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}/workflows/scrape-pipeline/executions" \
--http-method POST \
--oauth-service-account-email "$COMPUTE_SA" \
--oauth-token-scope "https://www.googleapis.com/auth/cloud-platform" \
--message-body '{"argument":"{\"urls\":[\"http://books.toscrape.com\",\"http://quotes.toscrape.com\"]}"}'如果任务已存在,而你只是想更新它:
gcloud scheduler jobs update http scrape-pipeline-daily \
--location "$REGION" \
--schedule "0 6 * * *" \
--uri "https://workflowexecutions.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}/workflows/scrape-pipeline/executions" \
--http-method POST \
--oauth-service-account-email "$COMPUTE_SA" \
--oauth-token-scope "https://www.googleapis.com/auth/cloud-platform" \
--message-body '{"argument":"{\"urls\":[\"http://books.toscrape.com\",\"http://quotes.toscrape.com\"]}"}'运行第一次完整测试
不要等调度器。手动触发工作流,观察整条流水线跑起来:
gcloud workflows run scrape-pipeline \
--location "$REGION" \
--data '{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}'你可以用下面的命令监控执行情况:
gcloud workflows executions list scrape-pipeline --location "$REGION"等待一两分钟。当执行状态显示为 SUCCEEDED 后,你的数据应该就会流入 Firestore 与 BigQuery。
验证数据
现在确认数据是否确实落到了正确的位置。
查看 BigQuery 的行数:
bq query --use_legacy_sql=false "SELECT COUNT(*) AS total_rows FROM \`${PROJECT_ID}.${BQ_DATASET}.${BQ_TABLE}\`"查看最新抓取结果:
bq query --use_legacy_sql=false "SELECT source, url, scraped_at, job_id FROM \`${PROJECT_ID}.${BQ_DATASET}.${BQ_TABLE}\` ORDER BY scraped_at DESC LIMIT 10"在 控制台中检查 Firestore。你应该会看到两个 collection:jobs 和 results。
然后请求 API 以确认它能读到全部数据:
curl -s "$API_URL/jobs?limit=1"从响应中取一个 jobId,再深入查询:
curl -s "$API_URL/jobs/YOUR_JOB_ID"
curl -s "$API_URL/results/YOUR_JOB_ID"如果以上都能返回数据,那么你的流水线就实现了端到端可用。
使用 Cloud Build 做 CI/CD
该仓库包含一个 cloudbuild.yaml 文件,可一次性完成构建并部署两个服务。当你需要发布变更时,只需运行:
gcloud builds submit --config cloudbuild.yaml .这一个命令会构建两个 Docker 镜像、推送到 Artifact Registry,并部署两个 Cloud Run 服务。如果你希望扩展到多个流水线,可以阅读这篇关于顶级网页抓取工具的概览,看看不同方案如何与这种云端架构互补。
最终检查清单
在你宣布完成之前,按下面的步骤逐项验证:
gcloud run services list --region us-central1应显示两个服务。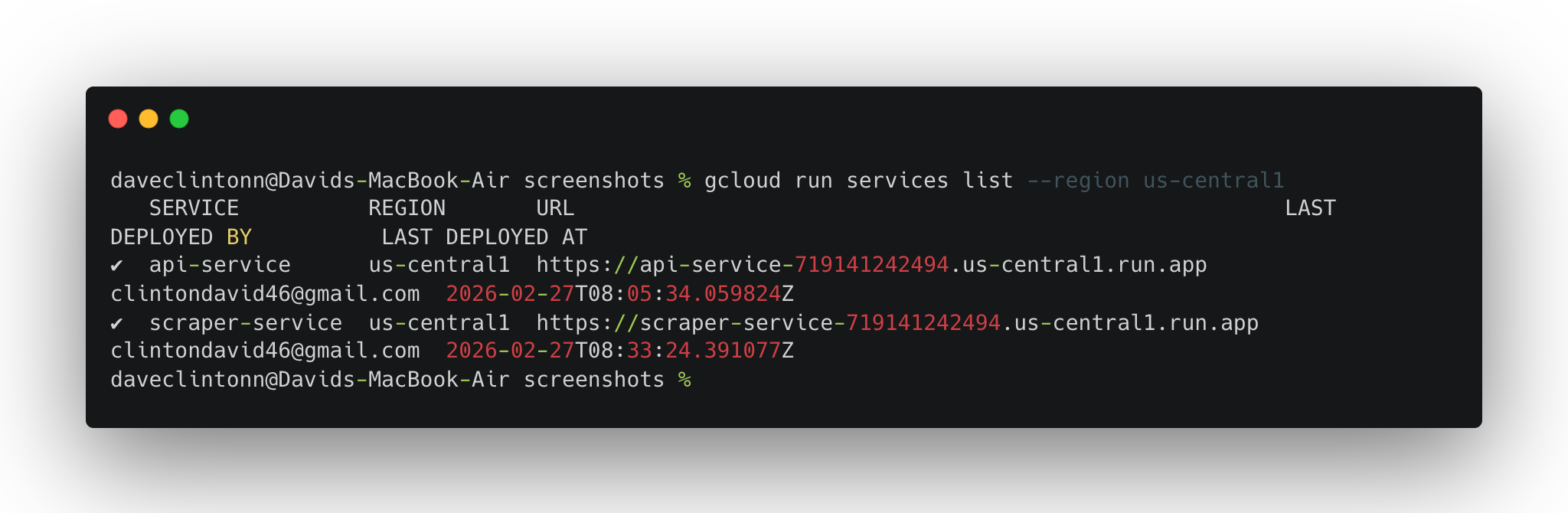
gcloud workflows describe scrape-pipeline --location us-central1应返回工作流详情。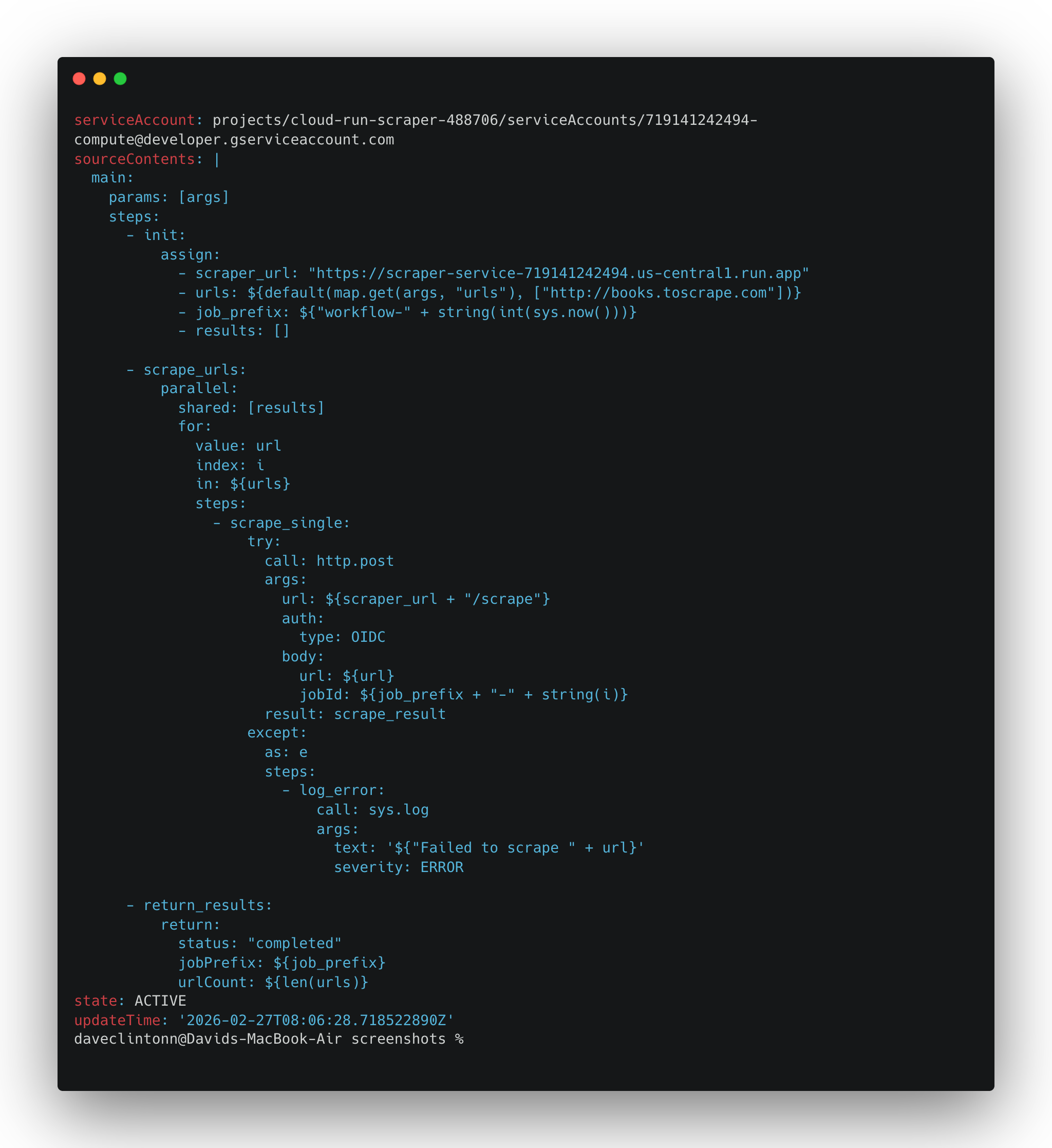
gcloud scheduler jobs list --location us-central1应显示调度任务。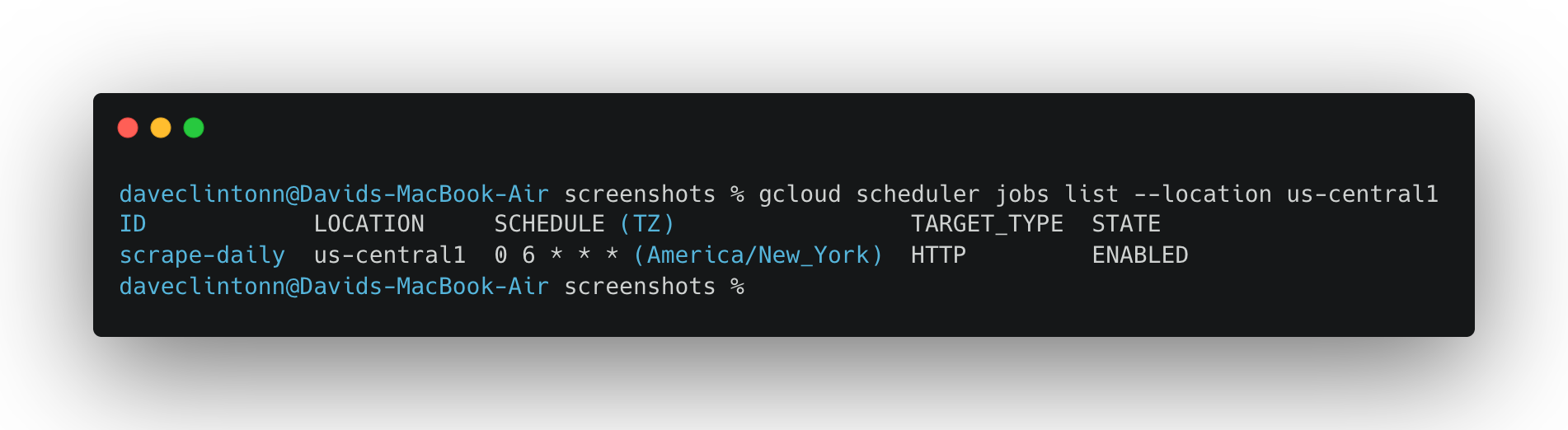
- Firestore 应包含
jobs与resultscollections。 - BigQuery table 应包含数据行。
- API 的
/jobs端点应返回真实记录。
如果以上 6 项都通过,那你不再是在运行一个演示项目,而是拥有了一条真正的流水线:按计划抓取、将数据存到两个位置,并通过公开 API 对外提供。
结论
在本指南中,我们完整演示了如何在 Google Cloud 上搭建一条无服务器网页抓取流水线。内容涵盖基础设施配置、部署两个 Cloud Run 服务、用 Cloud Workflows 编排抓取运行,并用 Cloud Scheduler 实现全面自动化。
如果你更偏好托管式方案,而不是维护自建基础设施,可以探索 Bright Data 的预采集数据集或 Scraper Studio,将任何网站变成开箱即用的数据流水线。你也可以阅读我们关于 使用 Scrapy 与 AWS 进行无服务器抓取 的指南,看看在另一家云服务商上类似架构是什么样的。克隆项目、替换为你自己的目标 URL,你就可以快速把抓取流水线跑起来。



技术写作者
Amitesh Anand 是一位开发者倡导者和技术写作者,分享有关 AI、软件和开发工具的内容,拥有 1 万粉丝和超过 40 万次观看。





