

在本指南中,你将了解:
- Bright Data CLI 是什么、它如何工作、它提供的功能以及它暴露的命令。
- 如何在 Linux、macOS、WSL 和 Windows 上安装并开始使用它。
- 如何以简单、引导式的方式使用 CLI 的第一步。
- 它支持的用例和场景,并通过真实世界示例进行演示。
让我们开始吧!
Bright Data CLI 简介
在看到它实际运行之前,先了解 Bright Data CLI 带来了什么以及它如何工作。
什么是 Bright Data CLI?
Bright Data CLI 是一款一体化终端工具,可为完整的 Bright Data API 表面提供简化访问。换句话说,它通过暴露直接的终端命令来使用、控制并集成 Bright Data 产品与服务,从而简化集成。
从高层来看,它提供的命令可以:
- 通过 网络解锁器 API 在绕过 CAPTCHA 和反机器人保护的同时抓取任何网站。
- 使用 搜索引擎 API 在 Google、Bing、Yandex 等主流引擎上执行结构化搜索。
- 通过 Web 爬虫 API 从 40+ 个平台(例如 Amazon、LinkedIn、Instagram)提取数据。
- 通过 Browser API 使用不可封锁的远程浏览器以编程方式与网页交互。
- 使用 Bright Data Web MCP 简化设置与编排。
- 以及更多…
进一步阅读:
它如何工作
@brightdata/cli 是 Bright Data CLI 的官方 npm 包。安装后,它会让你可以使用 brightdata 命令(bdata 作为简写),从而直接在终端中与完整的 Bright Data API 表面交互。
brightdata CLI 工具封装了整个 Bright Data 网页数据平台,并通过简单、对开发者友好的命令将其暴露出来。在底层,它会:
- 通过 OAuth、设备流程或 API key 进行一次性认证,将凭据存储在本地,这样你无需重新输入。之后,每个命令都可开箱即用——无需管理 token、创建 区域 或配置代理!
- 在首次登录时自动在你的 Bright Data 账户中配置所需的 区域(
cli_unlocker和cli_browser),让你可以立即开始。 - 通过 Bright Data 的基础设施路由请求,处理 CAPTCHA、机器人检测、IP 轮换、JavaScript 渲染以及所有其他 网页抓取挑战。
- 返回干净、可用的输出,包括终端中的格式化表格或结构化的 JSON、CSV 或 Markdown(非常适合用于下游分析与处理的数据格式,包括 AI 工作流)。
功能与能力
下面是 Bright Data CLI 提供的核心功能列表:
- 基础设施与成本管理:从单一的基于 CLI 的界面监控代理使用情况、检查配置,并跟踪账户余额、带宽以及按 区域 计费的成本。
- 通用网页抓取:从任何网站访问数据,内置处理反机器人保护,交付干净、可直接使用的输出。
- 搜索引擎数据访问:在主流搜索引擎上运行查询并接收结构化结果,包括自然结果、广告等。
- 结构化数据提取:从数十个平台拉取网页数据源,随时可用于分析。
- 远程浏览器自动化:通过托管浏览器以编程方式与实时网页交互,执行导航、点击、输入并处理动态内容。
- 自动化友好工作流:将命令集成到 Bash 脚本和管道中,支持串联与大规模数据处理。
- AI agent 集成:以简化方式为 AI 编码助手添加预构建技能或 MCP 连接。
- 简单的设置与配置:通过引导式设置和集中式配置快速初始化 CLI,并管理凭据与默认值的环境设置。
主要命令
Bright Data CLI 可通过 brightdata 命令(或 bdata 别名)使用。你可以这样使用它:
brightdata <COMMAND> <ARGUMENTS>支持的命令包括:
| 命令 | 作用 |
|---|---|
scrape <url> |
抓取任何网站,同时处理 CAPTCHA、JavaScript 渲染以及其他反抓取保护。 |
search <query> |
在 Google、Bing 或 Yandex 上运行结构化搜索并接收整理后的 JSON 结果。 |
pipelines <type> [params...] [options] |
从 40+ 个平台(如 Amazon、LinkedIn、TikTok 等)提取结构化数据。 |
browser |
远程控制真实浏览器,以编程方式导航、点击、输入并与网页交互。 |
add mcp |
将 Bright Data Web MCP 服务器连接到 Claude Code、Cursor 或 Codex 等 AI 编码 agent。 |
skill |
将预构建的 Bright Data AI agent 技能安装到编码助手中,以增强自动化能力。 |
zones |
列出并检查你的 Bright Data 代理 区域 及其当前配置。 |
budget |
一目了然地查看账户余额、按 区域 成本以及带宽使用情况。 |
如需完整命令列表以及其支持的选项与参数,请参阅文档。
Bright Data CLI 入门:分步指南
在接下来的教程章节中,你将被引导完成在本地机器上设置 Bright Data CLI 的过程。
安装流程取决于你的环境:
- 在 Linux 或 macOS 上,你可以使用专用的 CLI 安装器快速开始。
- 在 Windows 上,或在 Linux/macOS 上使用 Node.js 时,你需要全局安装 npm 包,并通过特定命令完成配置。
两种情况下,初始设置都只需几分钟!
接下来的两章将介绍这两种方法,并从通用的先决条件开始。
先决条件
要在你的机器上运行 Bright Data CLI(无论环境如何),你需要:
- 本地安装 Node.js 版本 20+(推荐 LTS 版本)。
- 一个 Bright Data 账户(你可以免费创建一个新账户)。
在 Linux/macOS/WSL 上设置 Bright Data CLI
在 macOS、Linux 和其他基于 Unix 的系统(包括 WSL)上,使用以下命令安装 Bright Data CLI:
curl -fsSL https://cli.brightdata.com/install.sh | sh该命令会下载 Bright Data CLI 安装器并运行它。这将安装 并设置 CLI。
你应该会得到如下输出: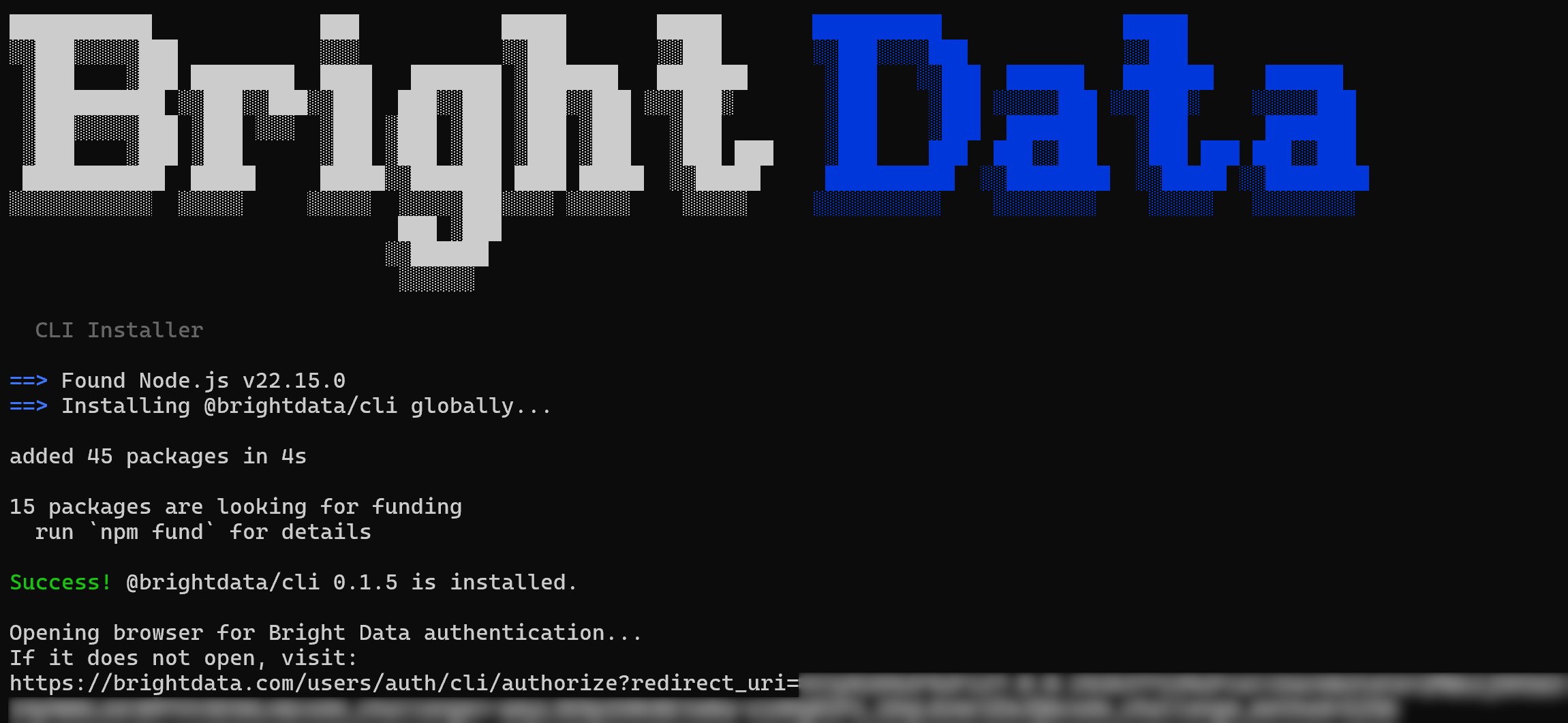
注意 @brightdata/cli npm 包已被全局安装。随后会显示一个 URL,用于使用你的 Bright Data 账户进行认证。浏览器页面应会自动打开 Bright Data 登录页。如果没有,请复制该 URL 并手动打开。
登录后,你应该会看到以下确认信息: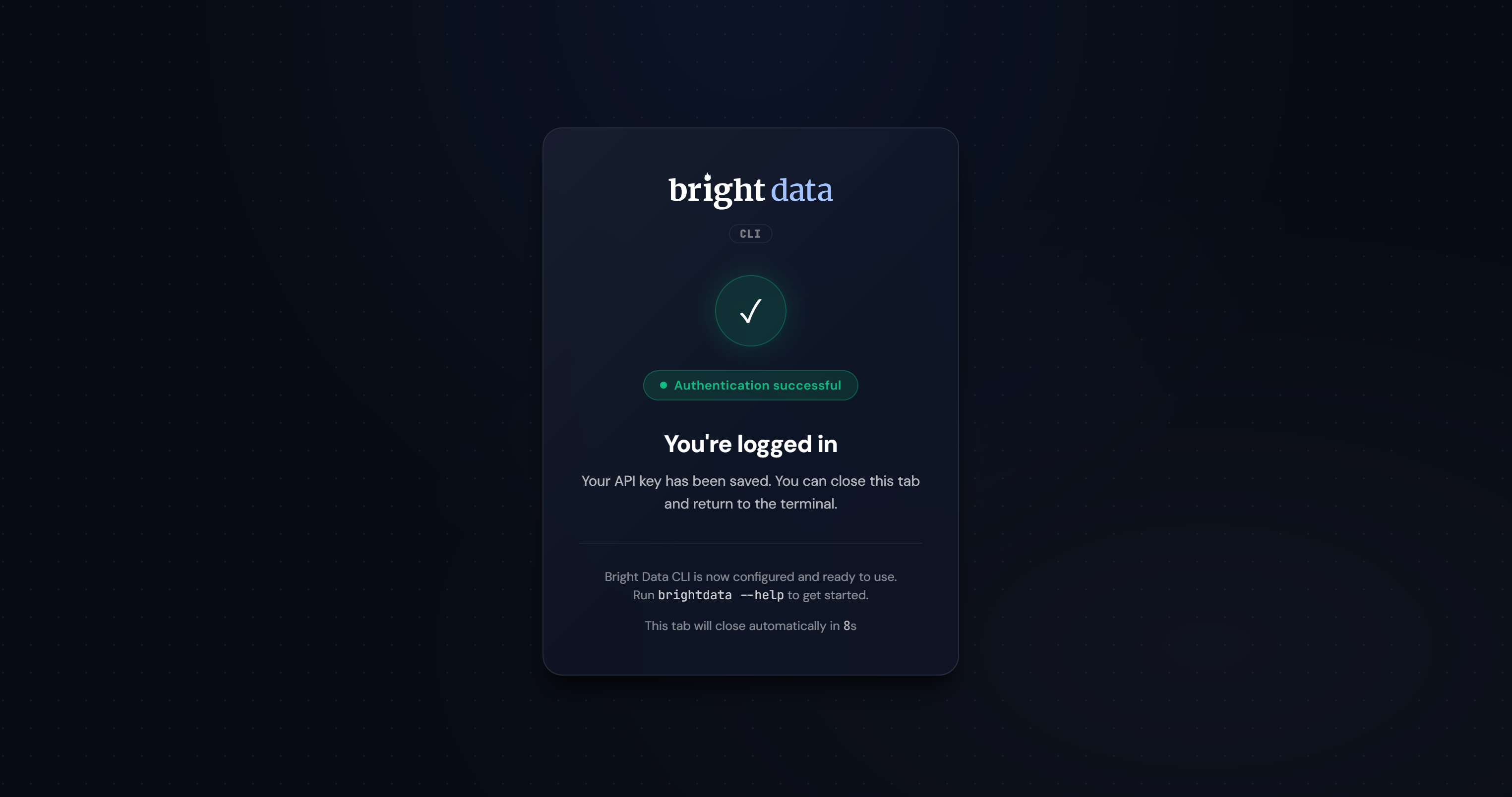
如果认证成功,Bright Data CLI 将创建所需的 区域,并在你的系统上完全可用:
使用以下命令检查设置是否成功完成:
brightdata --version或使用等效别名:
bdata --version两种情况下,结果应类似如下:
0.1.5在此示例中,0.1.5 是本地安装的 Bright Data CLI 版本。
Bright Data CLI 已在本地安装,你的 Bright Data 账户已配置,且 CLI 已认证。任务完成!
通过 Node.js 在 Windows 或任何其他 OS 上设置 Bright Data CLI
按照以下步骤在 Windows 上开始使用 Bright Data CLI,或在任何其他操作系统上通过 Node.js 手动设置。
步骤 #1:通过 npm 安装 CLI
在 Windows 或任何平台上,使用 npm 全局安装 Bright Data CLI:
npm install -g @brightdata/cli这会设置 brightdata 命令,使其可在你的机器上的任何位置使用。
注意:你也可以在不安装的情况下运行 CLI:
npx --yes --package @brightdata/cli brightdata <command>使用以下命令检查 brightdata 命令(或其别名 bdata)是否在全局可用:
brightdata --version结果将显示已安装的包版本,例如:
0.1.5很好!Bright Data CLI 现在已在本地安装,并可作为全局命令访问。
步骤 #2:连接到你的 Bright Data 账户
运行以下命令以将 CLI 与你的 Bright Data 账户关联:
brightdata login你应该会看到如下输出:
浏览器页面将自动打开 Bright Data 登录页。如果没有,请复制提供的 URL 并手动打开。这将允许你通过 OAuth 使用你的 Bright Data 账户进行认证。
登录后,你应该会看到类似这样的确认页面:
一个新的 Bright Data Agent API key 会被创建并存储在你的机器本地用于认证。一旦成功,CLI 会自动设置所需的 区域,并可立即使用:
总结来说,login 命令会:
- 在本地验证并存储你的 API key
- 自动创建所需的代理 区域(
cli_unlocker、cli_browser) - 配置合理的默认值,让你可以立即开始
注意:要退出登录并重置认证,请运行:
brightdata logout非常好!Bright Data CLI 现在已安装、已认证,并可随时使用。
设置后概览与第一步(可选)
设置 Bright Data CLI 后,你的 Bright Data 账户中将包含两个新的 区域( cli_unlocker 和 cli_browser):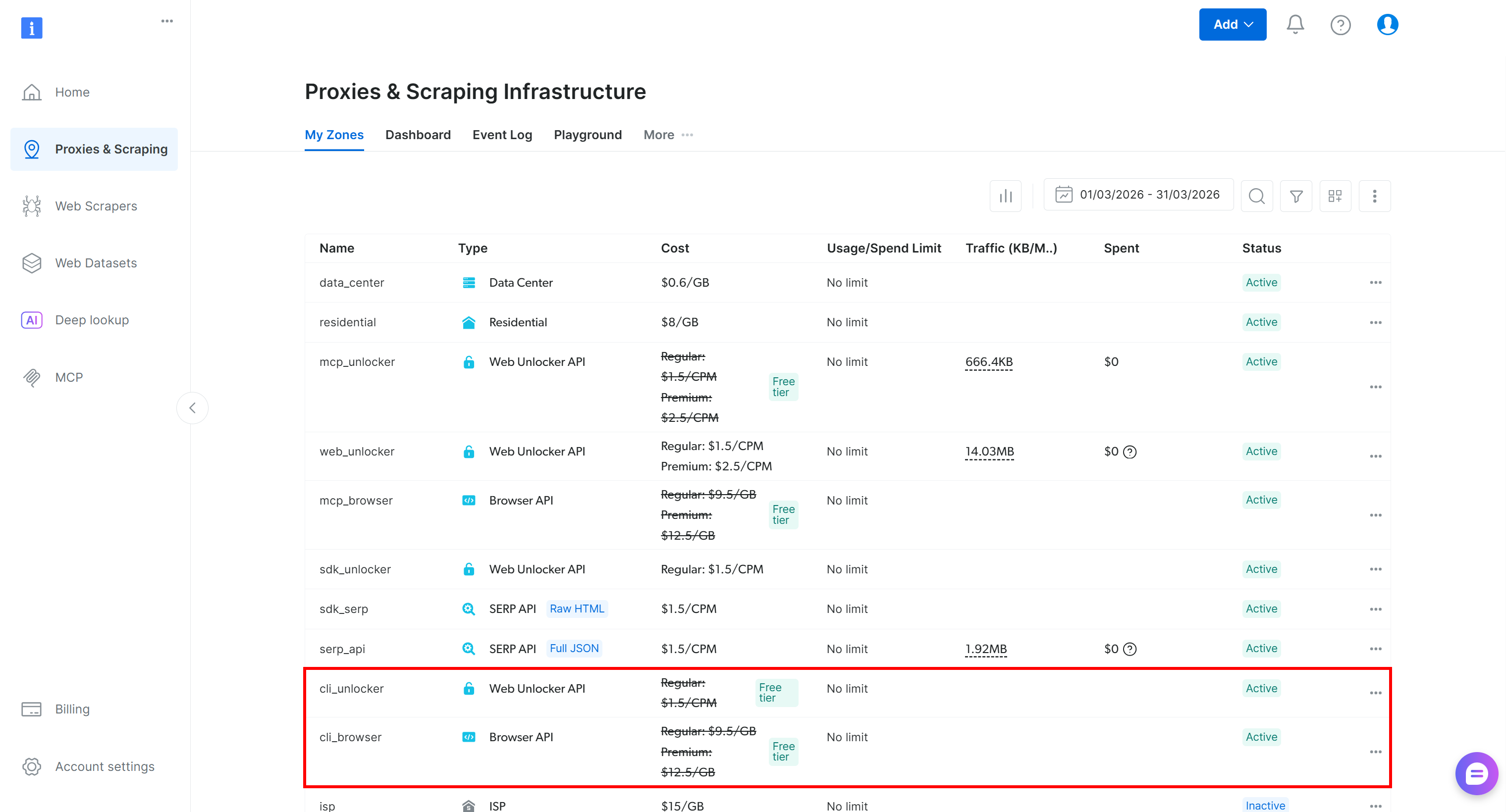
你还将拥有一个新的 Agent API key,这是通过 OAuth 创建的特殊 Bright Data API key,可管理 区域、发送请求、检索预算信息等: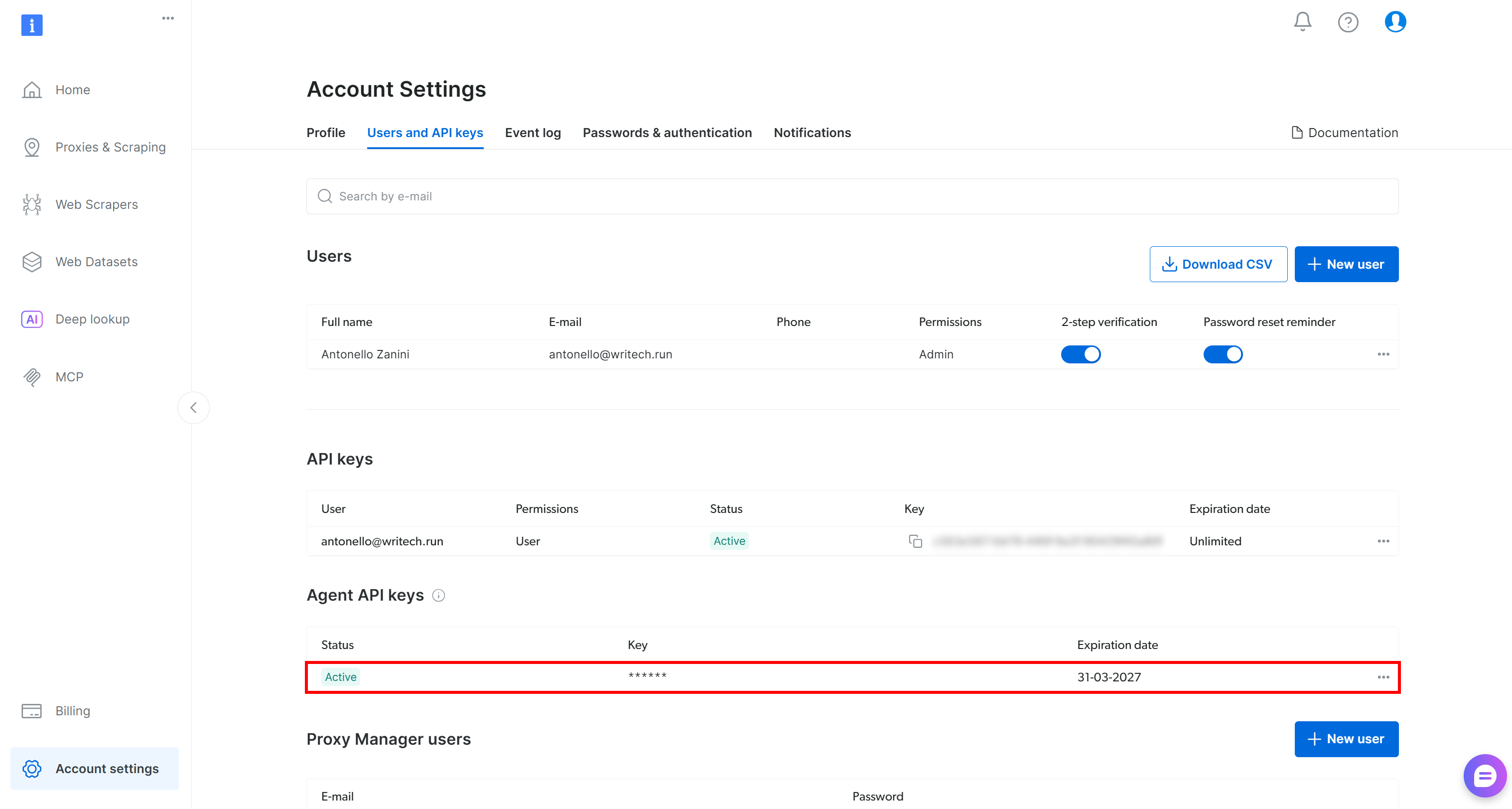
如果这是你第一次运行 CLI,请从 init 命令开始:
brightdata init这会启动一个交互式向导来配置 Bright Data CLI,并提供一些用于测试的示例。
在设置过程中,你将被要求:
- 确认已配置的 Bright Data Agent API key 或更新它。
- 选择默认的 网络解锁器 区域(默认:
cli_unlocker)。 - 选择是否将同一 区域 用作 搜索引擎 API 的默认值。
- 选择默认输出格式(Markdown 或 JSON)。
完成后,你将看到简洁的设置摘要,随后是用于测试和验证安装的示例 Bright Data CLI 命令。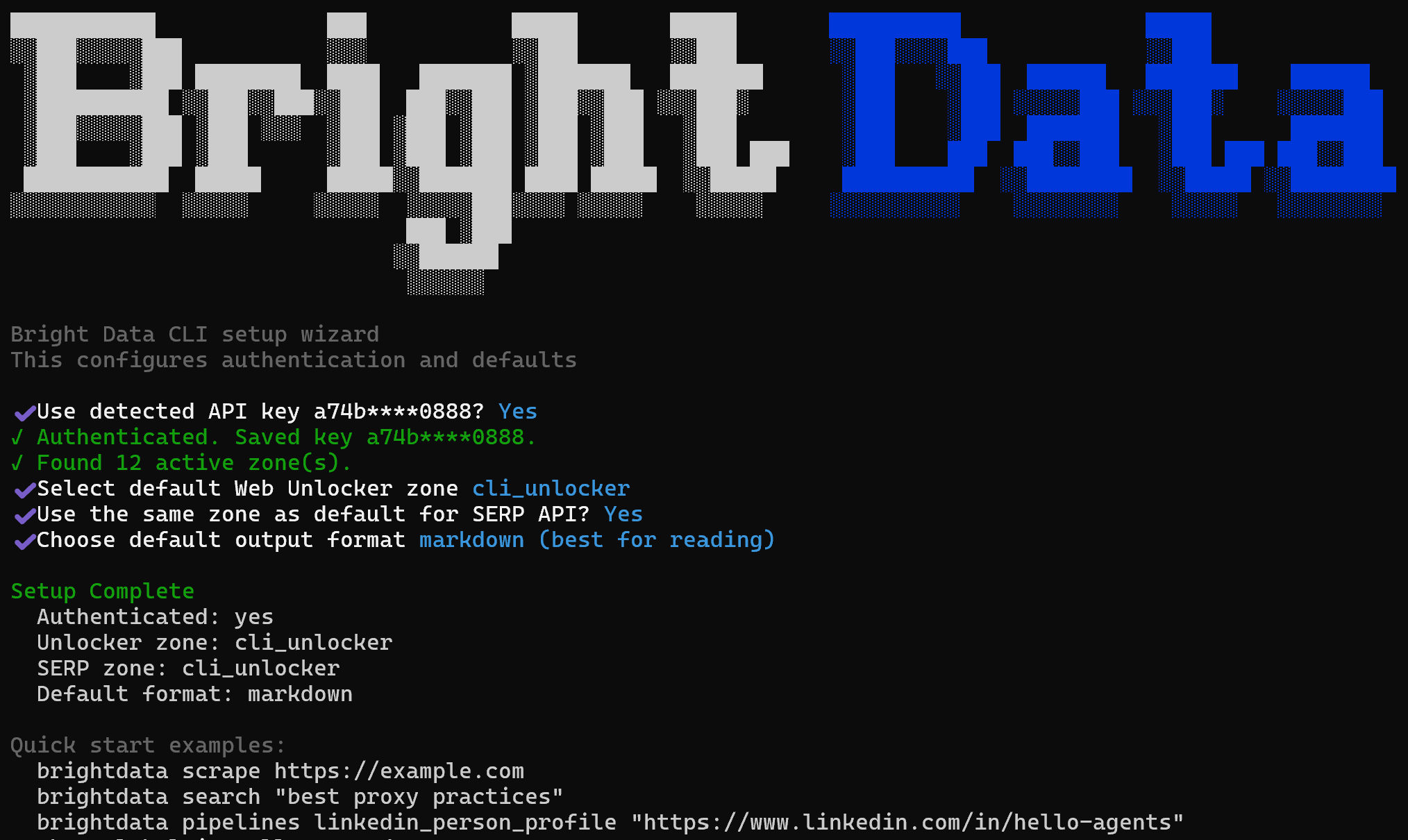
注意:要查看当前配置,请使用 brightdata config 命令。要更新某个设置,请运行:
brightdata config set <CONFIG_NAME> <CONFIG_VALUE>否则,使用全局环境变量覆盖它们。
Bright Data CLI 实战:真实世界示例
Bright Data CLI 支持多个命令,每个命令都有许多选项。在这里,我们将探索其中一些最相关的命令。如需完整示例列表,请查阅文档。
注意:Bright Data CLI 的使用每月可免费进行最多 5,000 次请求,并可按月循环续用。因此,你可以免费开始!
抓取任意网站
要从网页检索内容,请像这样使用 scrape 命令:
brightdata scrape https://nodejs.org/en结果会以 Markdown 格式输出到 STDOUT(默认数据格式):
这对应于命令中指定页面的 Markdown 版本(非常适合 LLM 摄取):
如果你想将请求地理定位到特定国家(例如美国),请使用 --country 参数:
brightdata scrape amazon.com/Apple-Cellular-Multisport-Smartwatch-Titanium/dp/B0FQF9TJ86 --country us你将获得仿佛从美国访问该页面的结果(可用于绕过地理限制或查看基于位置变化的内容)。
要将结果导出到文件,请使用 -o 参数:
brightdata scrape https://www.w3schools.com/sql/sql_where.asp -o tutorial.md将创建一个 tutorial.md 文件,并以 Markdown 格式填充抓取到的内容: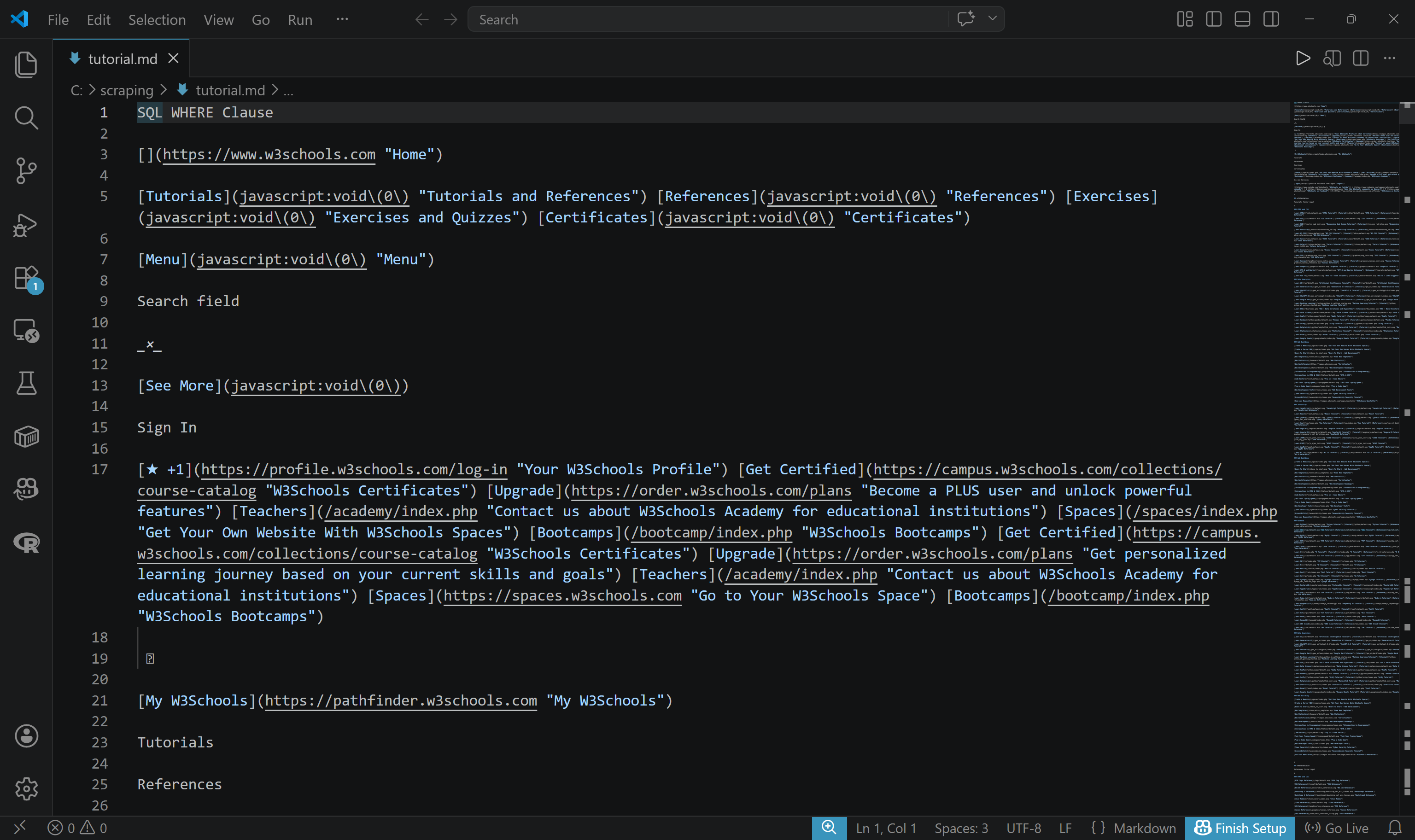
要获取原始 HTML,请使用 -f 参数指定格式。同时,建议将输出写入文件:
brightdata scrape https://developer.mozilla.org/en-US/ -f html -o index.html输出将是一个名为 index.html 的文件,包含抓取页面的原始 HTML: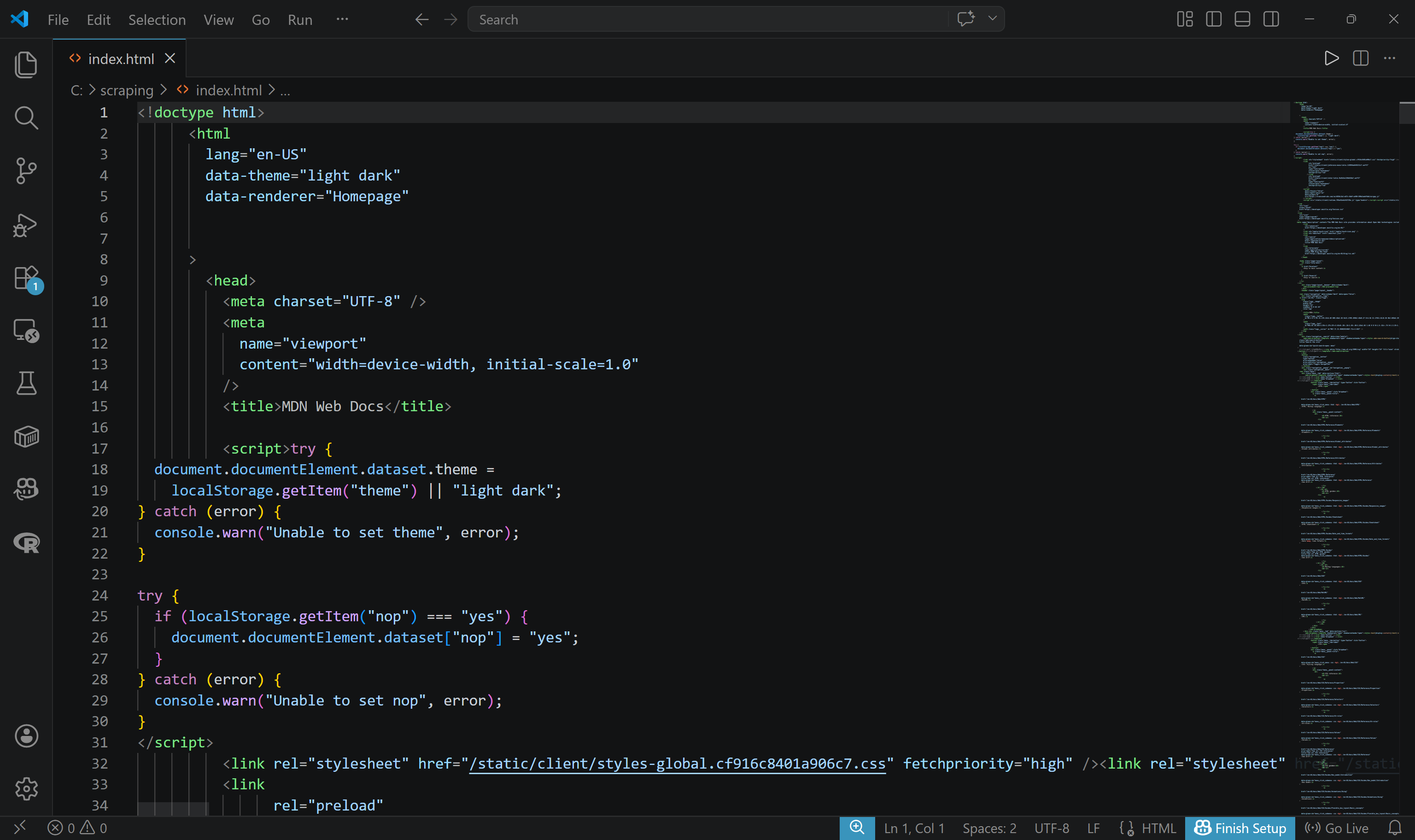
使用类似机制,你还可以对指定页面进行截图:
brightdata scrape https://www.amazon.com/Apple-2026-MacBook-13-inch-Laptop/dp/B0GR6BVYS5?th=1 -f screenshot -o page.pngpage.png 将包含: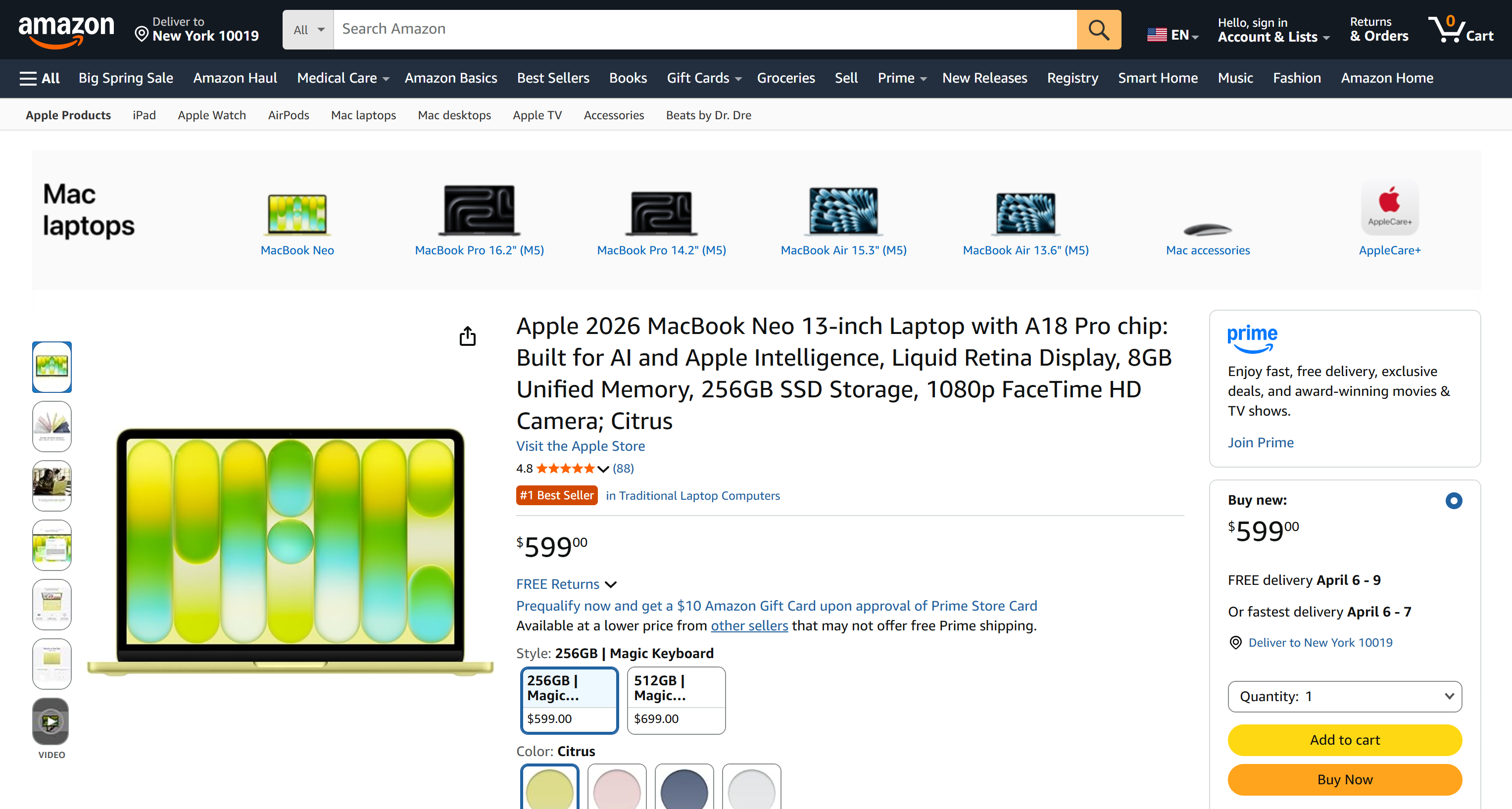
搜索 Web
使用 search 命令直接从 CLI 执行网页搜索:
brightdata search "best chatgpt scrapers"结果会以格式化表格返回,便于阅读和检查:
该结果表格对应于 “best cheap 爬虫工具” 查询的 Google SERP: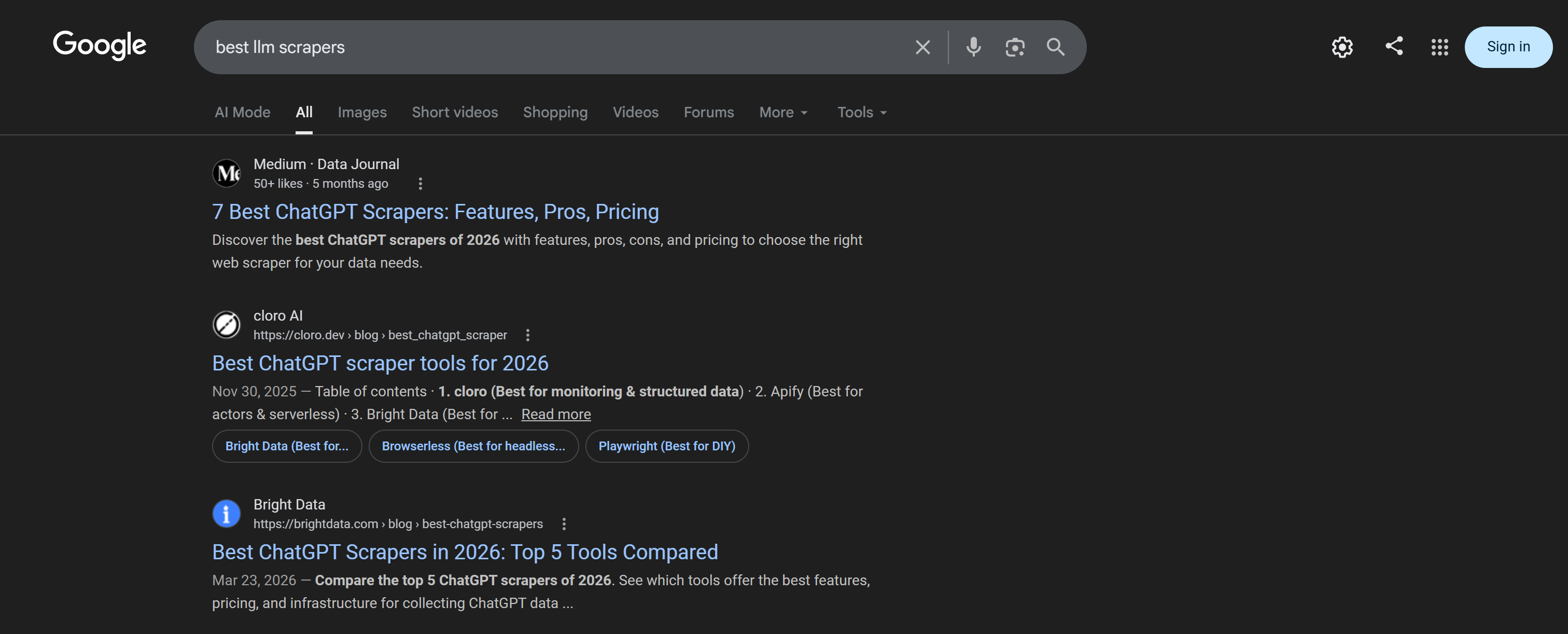
要控制 Google 结果页,请指定 --page 参数:
brightdata search "best llms" --page 2
如果你需要用于进一步处理的结构化数据,请使用 --json 标志获取原始 JSON 输出:
brightdata search "node.js security best practices" --json这非常适合将结果通过管道传入脚本或与其他工具集成:
要获得更易读的原始输出版本,请设置 --pretty 标志:
brightdata search "best llm scrapers" --pretty上述命令会以良好格式化的方式生成结果,这在调试或探索时很有帮助:
你还可以自定义搜索上下文。例如,要在特定国家和语言中运行本地化查询:
brightdata search "mejores restaurantes italianos en Madrid" --country es --language es该命令返回的结果就像搜索是在西班牙、以西班牙语执行的一样:
最后,你可以专门指定你想要的结果类型。例如,仅检索新闻结果:
brightdata search "barcelona beaches" --type images其他支持的类型包括 shopping 和 news,具体取决于你的用例。
获取结构化数据源
除了原始抓取之外,你还可以使用 pipelines 命令从热门平台提取结构化数据。这会为特定应用返回干净、可直接使用的数据集。
例如,要从 Amazon 产品页面收集结构化详情,请运行:
brightdata pipelines amazon_product "https://www.amazon.com/Apple-2025-MacBook-Laptop-10%E2%80%91core/dp/B0FWD726XF/"这将触发 Bright Data Amazon Web 爬虫工具 上的异步任务,并自动轮询直到响应就绪: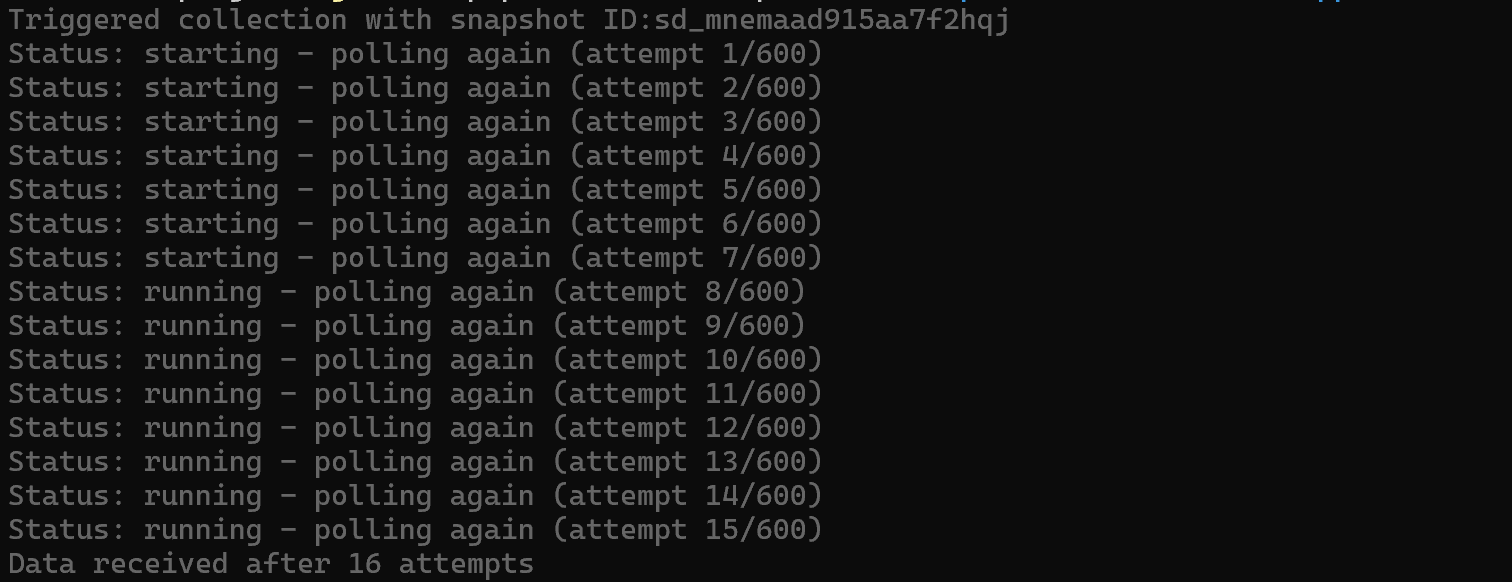
当目标数据集就绪后,它将打印在终端中(JSON,默认格式):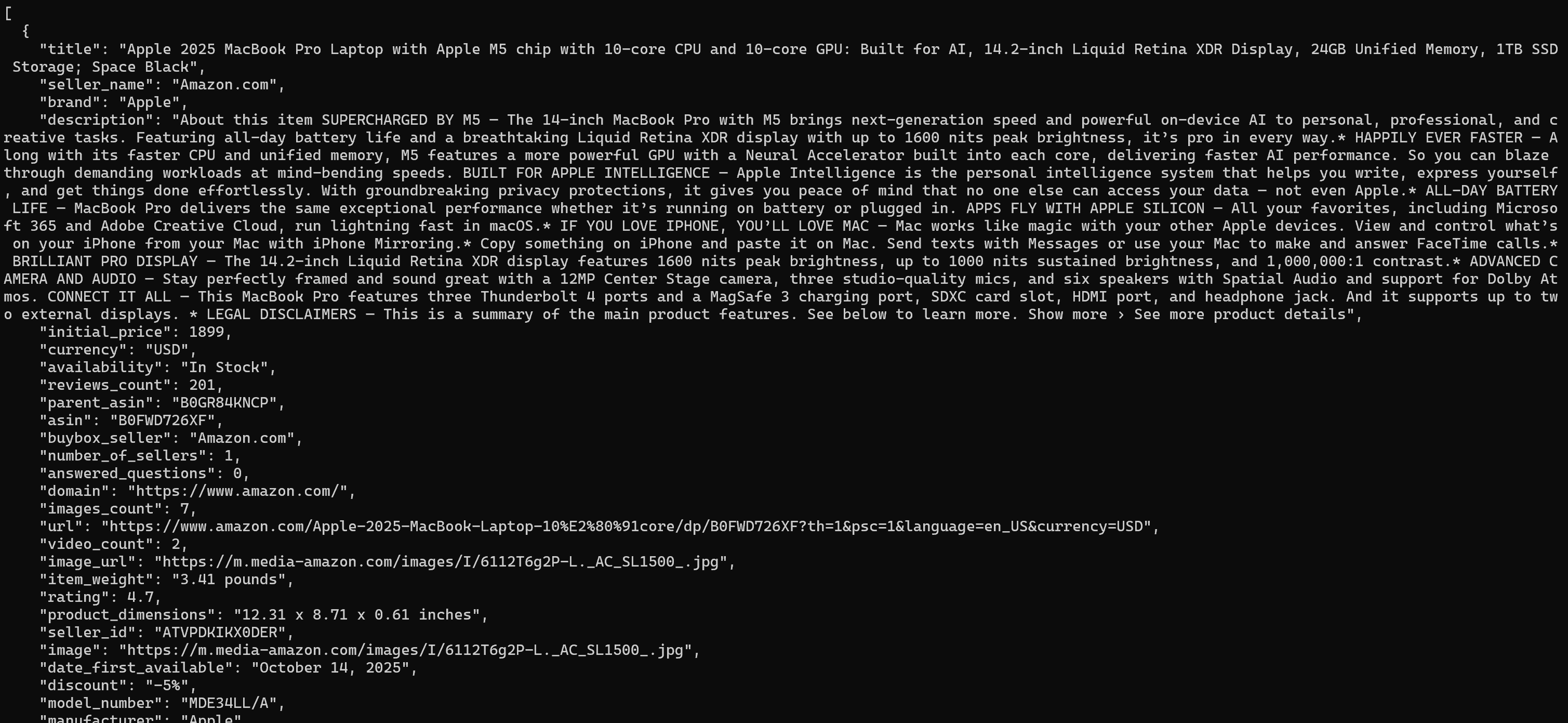
输出以结构化格式包含产品标题、价格、评分、规格等信息。
类似地,对于公司级洞察,你可以使用面向 Crunchbase 等商业智能来源 的 pipelines:
brightdata pipelines crunchbase_company "https://www.crunchbase.com/organization/brightdata"上述 pipelines 命令会收集融资、行业、公司概览等关键详情: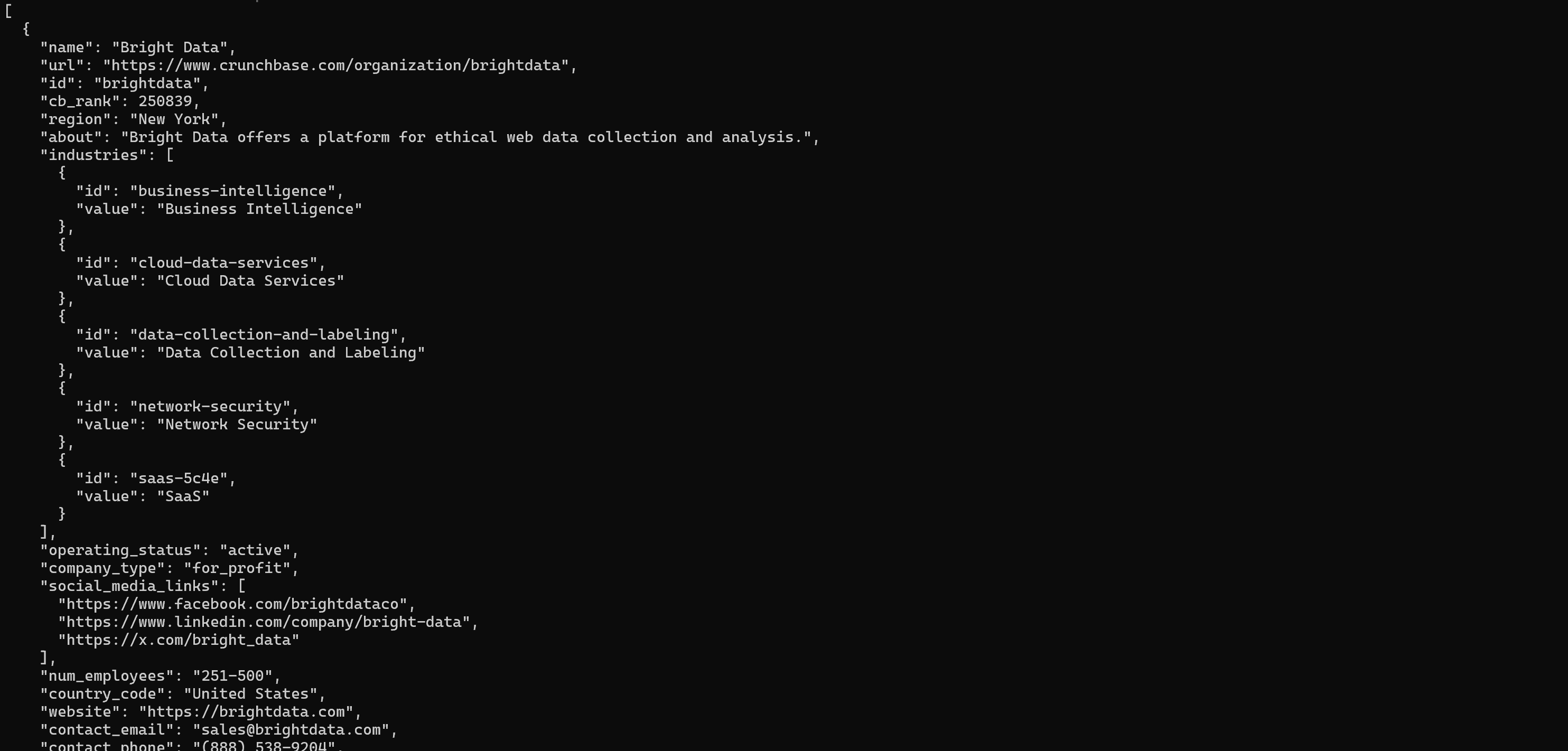
这与在 Crunchbase 公司页面上可以找到的公开信息相匹配:
如果你想从 LinkedIn 个人资料获取结构化数据,请运行:
brightdata pipelines linkedin_person_profile "https://es.linkedin.com/in/antonello-zanini"返回的信息包括姓名、职位、经历和教育背景: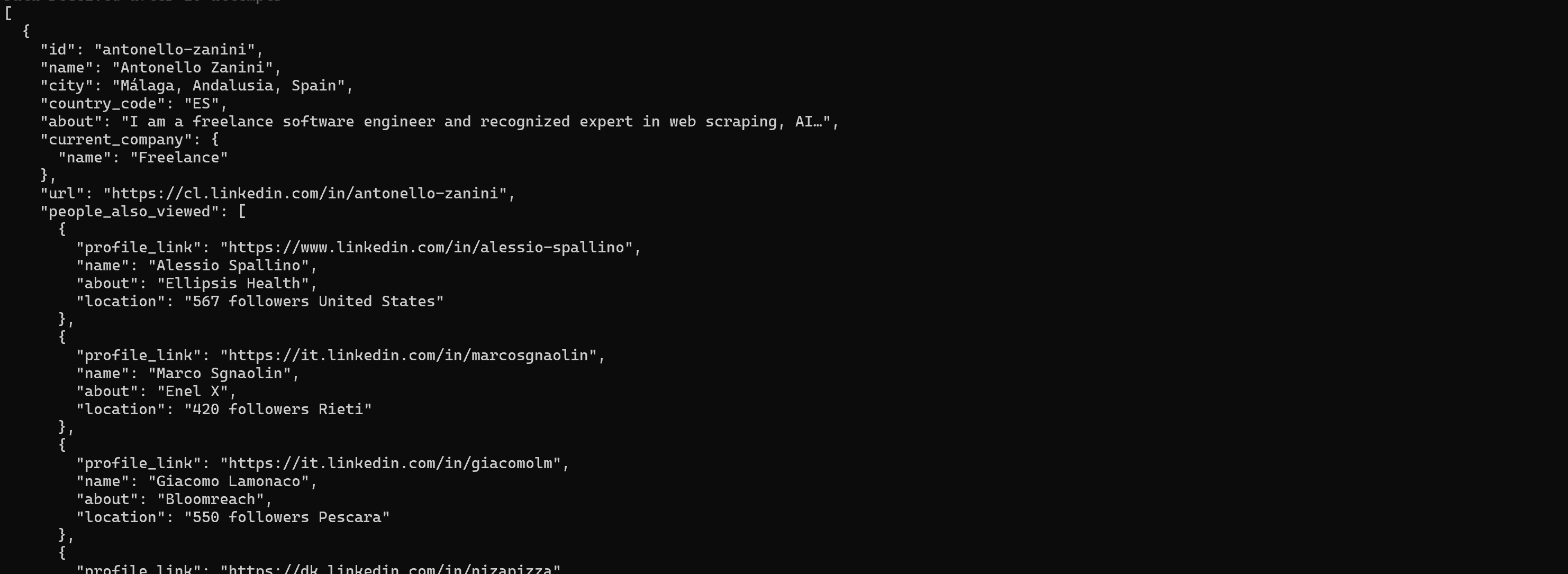
与抓取一样,你可以将结构化结果导出到文件:
brightdata pipelines crunchbase_company "https://www.crunchbase.com/organization/brightdata" --format csv -o company.csv这会创建一个 company.csv 文件,其中包含结构化公司数据,可用于下游分析与处理:
控制真实浏览器会话
browser 命令让你控制由 Bright Data 的 抓取浏览器 API 驱动的真实远程浏览器。它会保持持久会话,因此你可以逐步与页面交互,而无需每个命令都重新连接。
要启动会话并导航到页面,请运行:
brightdata browser open https://example.com这会自动启动浏览器会话并加载目标页面:

要以结构化且更节省 token 的方式读取页面内容,请输入:
brightdata browser snapshot --compact这会返回页面的无障碍树,其中每个可交互元素都会被分配一个引用 ID(例如 e1、e2),你可以用它进行后续操作: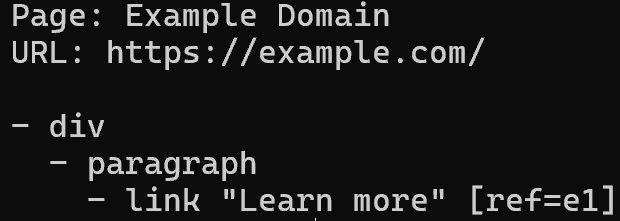
注意返回的树如何与目标网页匹配:
你现在可以与页面交互,例如点击某个元素:
brightdata browser click e1或者在输入框中输入、截图以及许多其他操作。
最后,当你完成后,关闭会话:
brightdata browser close这会停止远程浏览器:
使用 Unix 管道串联命令
Bright Data CLI 被设计为对管道友好。当 STDOUT 不是 TTY 时,颜色和旋转指示器会自动禁用,使其非常适合脚本与自动化。
该机制有助于你将命令串联起来构建简单的数据管道。以下展示如何在一个流程中从搜索到抓取:
brightdata search "best python scraping libraries" --json \
| jq -r ".organic[0].link" \
| xargs brightdata scrape上述管道执行一次 Google 搜索,提取第一个结果 URL(此处为 Reddit 页面),并立即对其进行抓取(以 Markdown 返回其内容):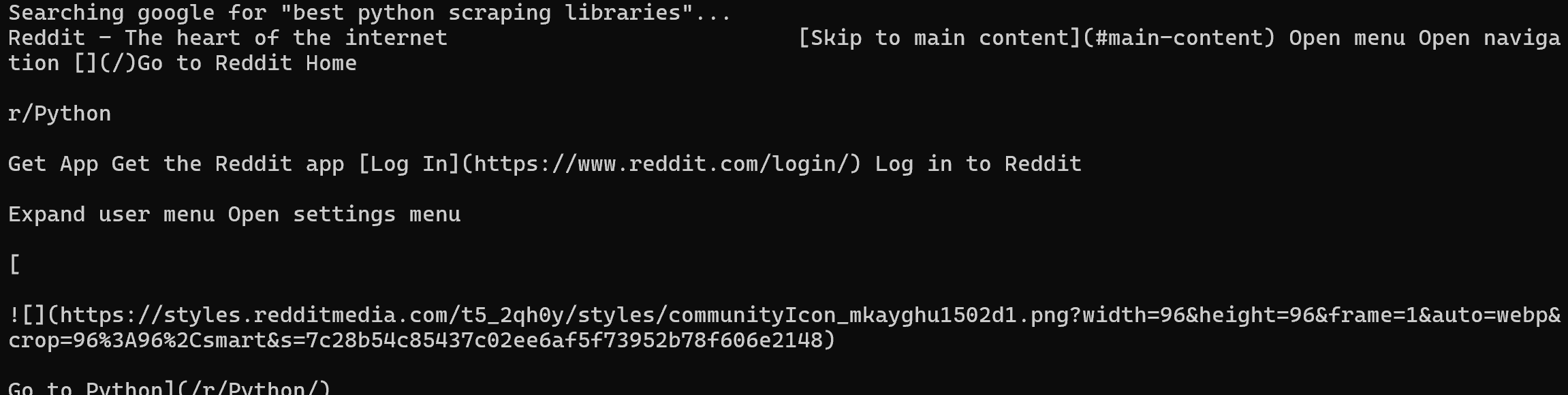
当将 Bright Data 集成到 shell 脚本、cron 作业或更大的数据工作流中时,这种模式尤其强大。要运行它,你必须在本地安装 jq:
sudo apt-get install jq使用技能扩展你的编码 agent
通过直接从 CLI 安装 Bright Data 技能 来增强你的 AI 编码 agent。
要以交互方式选择并安装技能,请运行:
brightdata skill add这会打开一个交互式选择器,你可以选择要安装哪些技能,以及要面向哪种 agentic 解决方案(Claude Code、Amp、Cline、Codex 等):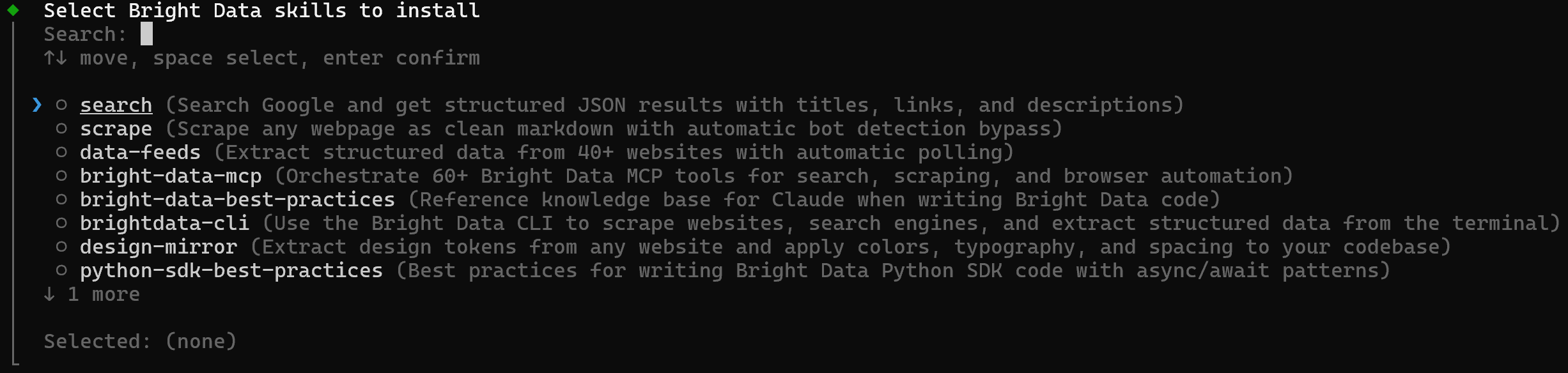
或者,你可以通过 Web MCP 将 Bright Data 直接连接到你的 agentic 解决方案:
brightdata mcp add这会将 Bright Data MCP 服务器链接到 Claude Code、Cursor 或 Codex,使它们能够将抓取、搜索和数据管道作为原生工具访问: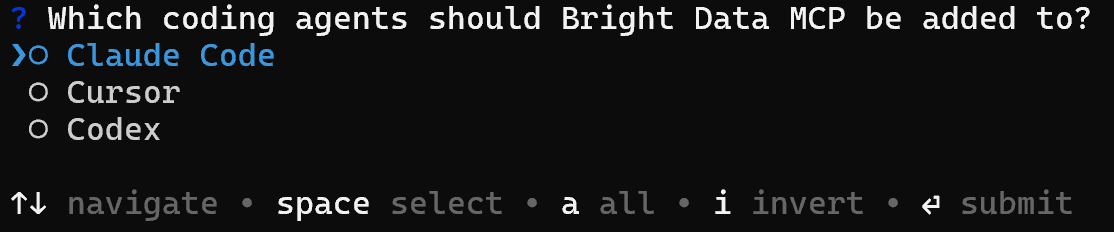
账户管理与监控
利用 CLI 监控你的 Bright Data 账户,实时跟踪使用情况、余额和成本。
要查看所有可用 区域,请使用:
brightdata zones可能的输出如下: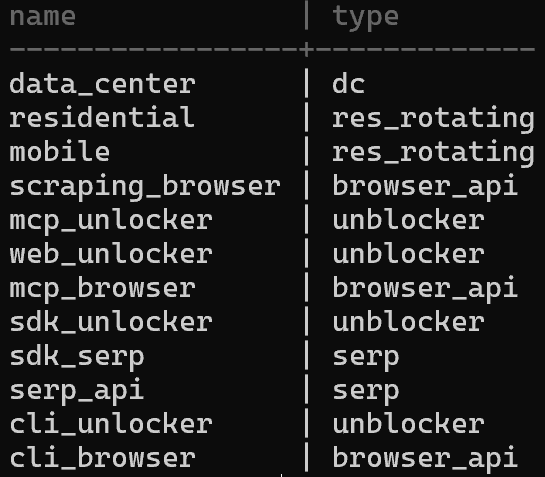
这与 Bright Data 控制面板中的 “My Zones” 表格相匹配: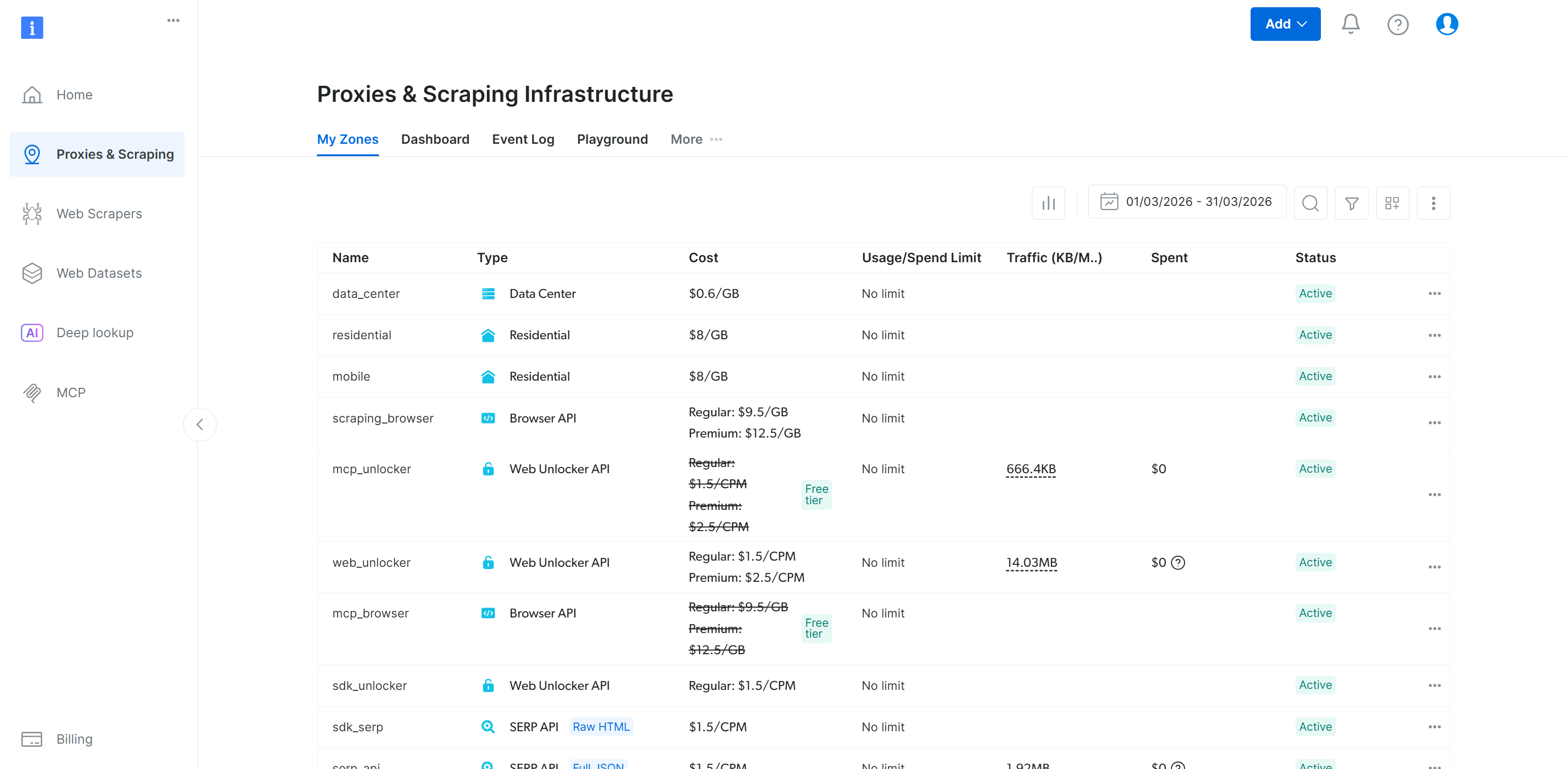
要快速检查剩余余额,请运行:
brightdata budget这会返回当前额度的高层概览: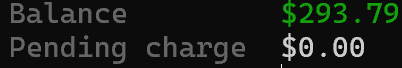
如果你想分析不同 区域 的支出情况,请使用以下命令检查成本分布:
brightdata budget zones这会显示你的使用情况如何按 区域 拆分,从而更容易识别你的额度消耗在哪里: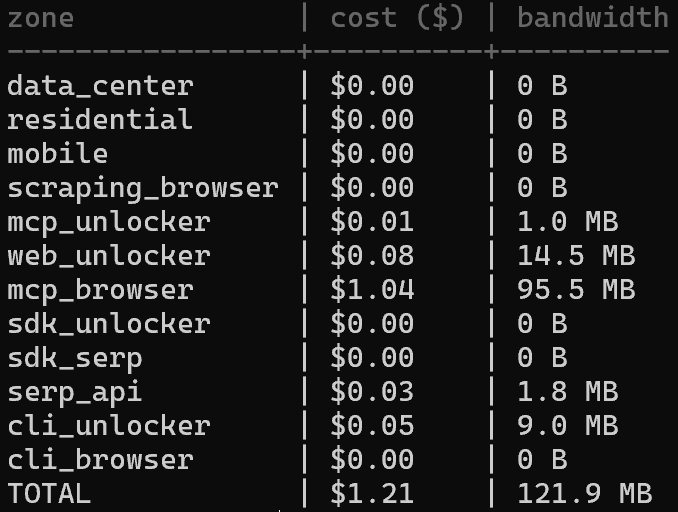
结论
在这篇博客文章中,你了解了 Bright Data CLI 提供的内容及其主要优势。你现在知道它允许你直接从终端连接、交互并操作所有基于 Bright Data API 的解决方案。
CLI 完全对管道友好,甚至支持复杂的基于 Bash 的数据工作流。在 Bright Data CLI 文档 中探索所有支持的场景、命令与集成。此外,也可以考虑在 GitHub 仓库点个 star!
今天就免费创建一个 Bright Data 账户并试用他们的网页数据产品——甚至可以通过 CLI!
FAQ
如需更多常见问题与故障排除,请查看官方文档。
我需要 Bright Data 账户才能使用 CLI 吗?
是的!CLI 使用 Bright Data 的基础设施来管理 Web 请求。你可以创建一个免费账户并从免费层开始。
我的 Bright Data CLI 凭据存储在哪里?
凭据存储在你机器的本地,并将权限设置为仅所有者可读/写(0o600):
- macOS:
~/Library/Application Support/brightdata-cli/credentials.json - Linux:
~/.config/brightdata-cli/credentials.json - Windows:
%APPDATA%\brightdata-cli\credentials.json
如何在没有浏览器的远程服务器上登录?
使用带有 device 选项的 login 命令:
brightdata login --device这会打印一个 URL 和验证码。在任何带浏览器的设备上打开该 URL,输入验证码,服务器上的认证将完成。
支持哪些输出格式?
Bright Data CLI 支持的输出数据格式包括:
- 对于
scrape命令:markdown(默认)、html、json和screenshot。 - 对于
search命令:格式化表格(默认)、json(原始 JSON)和pretty(缩进 JSON)。 - 对于
pipelines命令:json(默认)、csv、ndjson和jsonl。
请记住,所有命令都支持-o <path>选项,将抓取输出直接写入文件。



AI Engineer
 5 years experience
5 years experience
Meir 是 Bright Data 的 AI 工程师,使用最前沿的生成式 AI(GenAI)和自动化,构建能将实时网页数据转化为可操作答案的代理。





