

在本指南中,您将学习:
- Selenium Wire 是什么
- 为什么在网页抓取中要使用 Selenium Wire
- Selenium Wire 的主要功能
- 使用 Selenium Wire 进行网页抓取并切换代理的用例
- 如何在 Selenium Wire 中集成 Bright Data 代理
让我们开始吧!
Selenium Wire 是什么?
Selenium Wire 是 Selenium Python 绑定的一个扩展,可对浏览器请求进行控制。具体来说,它允许您在运行 Selenium 的同时,直接通过 Python 代码实时拦截和修改请求与响应。
注意:虽然该库已不再维护,但仍有许多抓取技术和脚本依赖它。
为什么在网页抓取中使用 Selenium Wire?
Selenium 是一个用于浏览器自动化的流行框架,人们常用它在网页抓取时像普通用户一样与网站交互。查看更多内容,请访问我们的 Selenium 网页抓取指南。
问题在于,浏览器本身存在一些限制,导致网页抓取面临挑战。例如,不支持动态设置带有授权的代理 URL 或 实时切换代理。Selenium Wire 可以帮助您克服这些限制。
以下是您应该在网页抓取场景中使用 Selenium Wire 的三个理由:
- 访问网络层:解释、检查并修改 AJAX 网络流量,从而实现更高级的数据提取。
- 绕过反爬机制:
ChromeDriver会暴露大量信息,反爬系统可利用这些信息识别您是爬虫。Selenium Wire 被undetected-chromedriver等技术所使用,以避免被识别并帮助绕过大多数反爬解决方案。 - 突破浏览器的限制:现代浏览器使用启动参数(flags)来在启动时配置行为,但这些设置是静态的,需要重新启动后方能改变。Selenium Wire 通过支持动态修改来克服这一限制。这样,您可以在同一次浏览器会话中更新请求头或代理,非常适合网页抓取。
Selenium Wire 的主要功能
现在您已经了解了 Selenium Wire 是什么以及为什么要在网页抓取中使用它。接下来让我们深入了解它的重要功能!
访问请求与响应
Selenium Wire 可以捕获浏览器发出的 HTTP/HTTPS 流量,让您访问下列属性:
| 属性 | 描述 |
|---|---|
driver.requests |
它会按时间顺序列出捕获的请求 |
driver.last_request |
它表示最近捕获的请求 (这比使用 driver.requests[-1] 更高效) |
driver.wait_for_request(pat, timeout=10) |
此方法会等待(等待时长由 timeout 参数定义),直到出现与 pat(可为子字符串或正则表达式)匹配的请求 |
driver.har |
呈现 HTTP 事务的 JSON 格式HAR 文件 |
driver.iter_requests() |
返回一个对捕获的请求进行迭代的迭代器 |
更具体地说,Selenium Wire 中的 Request 对象包含以下属性:
| 属性 | 描述 |
|---|---|
body |
请求体以 bytes 的形式呈现。如果请求体为空,则 body 值为空(例如:b'')。 |
cert |
以字典形式报告服务器 SSL 证书信息(对于非 HTTPS 请求,该值为空)。 |
date |
显示发出该请求的时间。 |
headers |
以类字典对象形式报告请求头(需要注意的是,在 Selenium Wire 中,头的大小写不敏感,并且允许重复)。 |
host |
报告请求主机(例如,/)。 |
method |
指定 HTTP 方法(GET、POST 等)。 |
params |
以字典形式报告请求参数(注意如果在请求中同名参数出现多次,该字典中的值会是一个列表)。 |
path |
报告请求路径。 |
querystring |
报告查询字符串。 |
response |
报告与该请求关联的响应对象(如果请求没有响应则值为 None)。 |
url |
报告完整请求 URL,包括 host、path 和 querystring。 |
ws_messages |
如果该请求是 WebSocket(此时 URL 通常以 wss:// 开头),ws_messages 将包含客户端与服务器间收发的 WebSocket 消息。 |
相应地,Response 对象具有以下属性:
| 属性 | 描述 |
|---|---|
body |
响应体以 bytes 的形式呈现。如果响应没有主体,则值为空(例如:b'')。 |
date |
显示接收该响应的时间。 |
headers |
以类字典对象形式报告响应头(需要注意的是,在 Selenium Wire 中,头的大小写不敏感,并且允许重复)。 |
reason |
报告响应的原因短语,例如 OK、Not Found 等。 |
status_code |
报告响应状态码,例如 200、404 等。 |
您可以创建如下 Python 脚本来测试此功能:
from seleniumwire import webdriver
# Initialize the WebDriver with Selenium Wire
driver = webdriver.Chrome()
try:
# Open the target website
driver.get("https://brightdata.com/")
# Access and print all captured requests
for request in driver.requests:
print(f"URL: {request.url}")
print(f"Method: {request.method}")
print(f"Headers: {request.headers}")
print(f"Response Status Code: {request.response.status_code if request.response else 'No Response'}")
print("-" * 50)
finally:
# Close the browser
driver.quit()以上代码通过 driver.requests 获取目标网站的请求,然后通过 for 循环来拦截并打印各个请求的一些属性(比如 url、method 和 headers)。
预期结果如下所示:
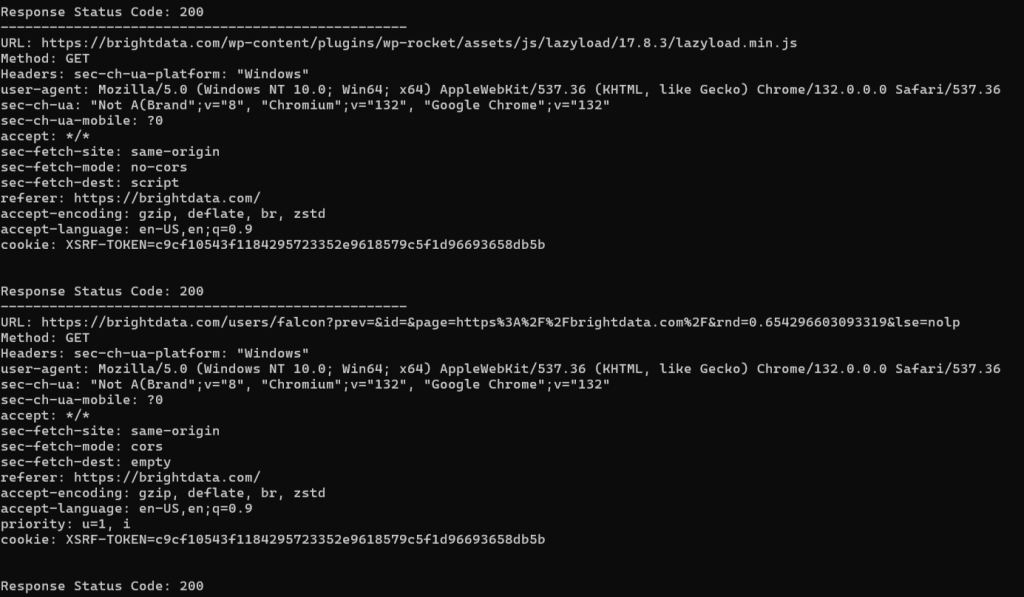
目标网页会发出多个请求,脚本会跟踪这些请求。
拦截请求与响应
Selenium Wire 可以通过拦截器来拦截并修改请求和响应。拦截器是在请求与响应通过浏览器时被调用的函数。
它有两种拦截器:
driver.request_interceptor:拦截请求,只接受一个参数。driver.response_interceptor:拦截响应,接受两个参数:一个是源请求,一个是响应对象。
下面是一个使用请求拦截器的示例:
from seleniumwire import webdriver
# Define the request interceptor function
def interceptor(request):
# Add a custom header to all requests
request.headers["X-Test-Header"] = "MyCustomHeaderValue"
# Block requests to a specific domain
if "example.com" in request.url:
print(f"Blocking request to: {request.url}")
request.abort() # Abort the request
# Initialize the WebDriver with Selenium Wire
driver = webdriver.Chrome()
# Assign the interceptor function to the driver
driver.request_interceptor = interceptor
try:
# Open a website that makes multiple requests
driver.get("https://brightdata.com/")
# Print all captured requests
for request in driver.requests:
print(f"URL: {request.url}")
print(f"Headers: {request.headers}")
print("-" * 50)
finally:
# Close the browser
driver.quit()这个示例所做的事情:
- 拦截器函数:为每一个传出的请求调用该拦截器函数。此函数使用
request.headers[]为所有请求添加一个自定义请求头。同时,它会阻止浏览器对example.com域名发出的加载请求。 - 捕获请求:页面加载后,脚本打印所有捕获的请求,包括修改过的请求头。
注意:阻止请求对于那些会加载广告、分析脚本或第三方小部件(与您的目标无关)的网页资源很有用。阻止这些请求能够显著提升抓取速度、减少浏览器带宽消耗。
预期结果示例:
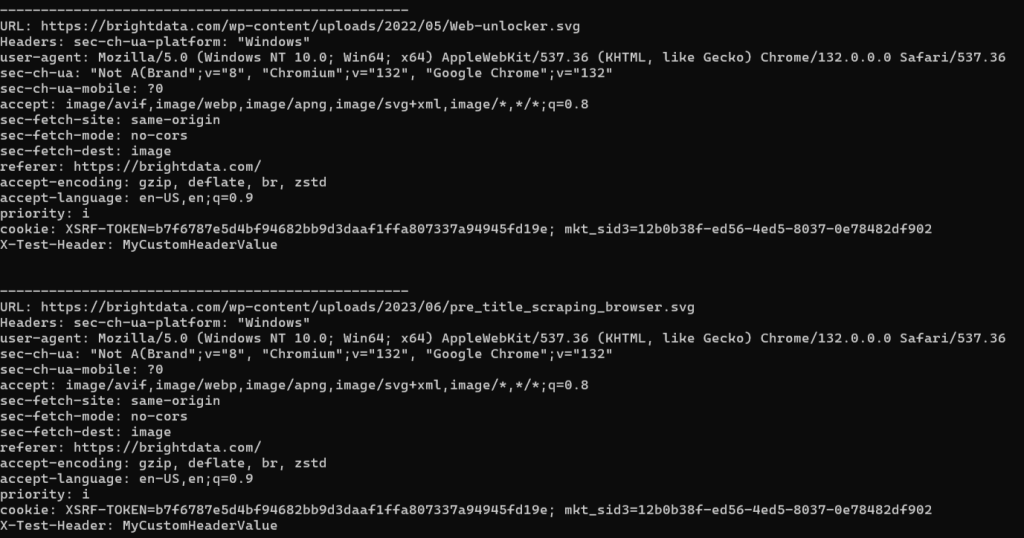
可以看到,浏览器发出的请求被拦截,并添加了自定义的请求头。
WebSocket 监听
许多现代网页使用 WebSockets 来实现与服务器的实时通信。WebSockets 在浏览器与服务器间建立一个持久连接,从而可以持续地交换数据,而无需传统的 HTTP 请求开销。
很多关键数据都可能经由这种通道传输,直接访问这些数据对于数据获取来说非常有价值。通过拦截 WebSocket 通信,您可以提取服务器直接发送的原始数据,而不需要等待浏览器的处理或页面的渲染。
正如前面所述,Request 对象拥有 ws_messages 属性来管理 WebSocket。Selenium Wire 中的 WebSocket 对象中包含以下属性:
| 属性 | 描述 |
|---|---|
content |
报告消息的内容,可以是 str 或 bytes。 |
date |
显示消息的发送或接收时间。 |
headers |
以类字典形式报告响应头(在 Selenium Wire 中,头的大小写不敏感并允许重复)。 |
from_client |
一个布尔值,如果该消息由客户端发送,则为 True;若由服务器发送,则为 False。 |
管理代理
代理服务器充当您设备与目标站点间的中间人,同时隐藏您的 IP 地址。它们在网页抓取场景尤为重要,原因在于:
- 帮助绕过基于 IP 的限制
- 在遇到速率限制时防止被封锁
- 允许从受地域限制的网站中抓取内容
以下是如何在 Selenium Wire 中配置代理的示例:
# Set up Selenium Wire options
options = {
"proxy": {
"http": "<YOUR_HTTP_PROXY_URL>",
"https": "<YOUR_HTTPS_PROXY_URL>"
}
}
# Initialize the WebDriver with Selenium Wire
driver = webdriver.Chrome(seleniumwire_options=options)这个配置与在原生 Selenium 中配置代理的方式不同,后者需要依赖 Chrome 的 --proxy-server 启动标志。这意味着在原生 Selenium 中,代理配置是静态的。
一旦您设置了代理,它就会应用于整个浏览器会话里,若要修改代理就必须重启浏览器。在需要动态切换代理的场景下,这种限制往往难以接受。
相比之下,Selenium Wire 允许在同一个浏览器实例内动态修改代理,这得益于它对 proxy 属性的支持:
# Dynamically change the proxy
driver.proxy = {
"http": "<NEW_HTTP_PROXY_URL>",
"https": "<NEW_HTTPS_PROXY_URL>"
}此外,Chrome 的 --proxy-server 标志并不支持在 URL 中携带认证信息:
protocol://username:password@host:port而 Selenium Wire 完全支持带认证的代理,这对于网页抓取来说更佳。
由于代理配置是 Selenium Wire 最显著的优势之一,我们将在下一章深化探讨这个主题。
网页抓取用例:Selenium Wire 的代理切换
如前所述,使用 Selenium Wire 的主要原因之一是其高级别的代理管理能力。
在本指导部分,您将了解如何在 Selenium Wire 中配置代理切换,以便让您的出口 IP 每次请求都能够改变。
前提条件
要复现本教程,您的系统需要满足以下要求:
- Python 3.7 或更高版本:高于 3.7 的 Python 版本皆可。我们将通过 pip 安装依赖,pip 在 Python 3.4 之后版本中默认为自带。
- 支持的网络浏览器:Selenium Wire 是对 Selenium 的扩展,因此需要一个受支持的浏览器。
在安装 Selenium Wire 之前,您可以先创建一个虚拟环境目录:
python -m venv venv然后在 Windows 上激活:
venvScriptsactivate在 macOS/Linux 上激活:
source venv/bin/activate接着,安装 Selenium Wire:
pip install selenium-wire注意:您无需单独安装 Selenium。它会和 Selenium Wire 一起被安装,因为 Selenium Wire 的依赖中已经包含了它。
假设您将主文件夹命名为 selenium_wire/。完成该步骤后,文件夹结构形如:
selenium_wire/
├── selenium_wire.py
└── venv/其中 selenium_wire.py 将包含您在下一步要实现的逻辑。
步骤 1:随机化代理
首先,您需要一个有效的代理列表。如果不清楚从哪里获取,可以参考我们的 免费代理列表。将它们添加到列表中,并使用 random.choice() 随机选择一个:
def get_random_proxy():
proxies = [
"http://PROXY_1:PORT_NUMBER_X",
"http://PROXY_2:PORT_NUMBER_Y",
"http://PROXY_3:PORT_NUMBER_Z",
# ...
]
# Randomize the list
return random.choice(proxies)每次调用该函数时都会返回列表中的一个随机代理 URL。
记得先导入 random:
import random步骤 2:设置代理
调用 get_random_proxy() 函数得到一个代理 URL:
proxy = get_random_proxy()然后初始化浏览器实例并设置此代理:
# Selenium Wire configuration with the proxy
seleniumwire_options = {
"proxy": {
"http": proxy,
"https": proxy
}
}
# Browser configuration
chrome_options = Options()
chrome_options.add_argument("--headless") # Run the browser in headless mode
# Initialize a browser instance with the given configurations
driver = webdriver.Chrome(service=Service(), options=chrome_options, seleniumwire_options=seleniumwire_options)上述代码需要以下导入:
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options如果您想在浏览器会话中动态切换代理,则可以改用:
driver.proxy = {
"http": proxy,
"https": proxy
}这样一来,受控的 Chrome 实例就会通过指定的代理来进行请求。
步骤 3:访问目标页面
访问目标网站,提取输出,然后关闭浏览器:
try:
# Visit the target page
driver.get("https://httpbin.io/ip")
# Extract the page output
body = driver.find_element(By.TAG_NAME, "body").text
print(body)
except Exception as e:
# Handle any errors that occur with the browser or the proxy
print(f"Error with proxy {proxy}: {e}")
finally:
# Close the browser
driver.quit()务必导入 By:
from selenium.webdriver.common.by import By在本示例中,目标页面是 HTTPBin 项目的 /ip 端点。这样设计是为了让页面返回调用方的 IP 地址。如果一切正常,脚本应在每次运行时都打印出来自代理列表中不同的 IP。
可以开始测试了!
步骤 4:整合以上步骤
以下是完整的 Selenium Wire 代理切换逻辑,放在 selenium_wire.py 文件中:
import random
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
def get_random_proxy():
proxies = [
"http://PROXY_1:PORT_NUMBER_X",
"http://PROXY_2:PORT_NUMBER_Y",
"http://PROXY_3:PORT_NUMBER_Z",
# Add more proxies here...
]
# Randomly pick a proxy
return random.choice(proxies)
# Pick a random proxy URL
proxy = get_random_proxy()
# Selenium Wire configuration with the proxy
seleniumwire_options = {
"proxy": {
"http": proxy,
"https": proxy
}
}
# Browser configuration
chrome_options = Options()
chrome_options.add_argument("--headless") # Run the browser in headless mode
# Initialize a browser instance with the given configurations
driver = webdriver.Chrome(service=Service(), options=chrome_options, seleniumwire_options=seleniumwire_options)
try:
# Visit the target page
driver.get("https://httpbin.io/ip")
# Extract the page output
body = driver.find_element(By.TAG_NAME, "body").text
print(body)
except Exception as e:
# Handle any errors that occur with the browser or the proxy
print(f"Error with proxy {proxy}: {e}")
finally:
# Close the browser
driver.quit()执行:
python3 selenium_wire.py每次执行时,输出类似:
{
"origin": "PROXY_1:XXXX"
}或:
{
"origin": "PROXY_2:YYYY"
}如此往复…
多次执行脚本,您就会看到不同的 IP 地址,说明代理切换已经生效!
更好的代理切换方案:使用 Bright Data 代理
正如我们所见,手动在 Selenium Wire 中进行代理切换不仅涉及大量模板化代码,而且需要维护一个可用代理的列表。
幸运的是,Bright Data 的旋转代理提供了更高效的方案!
我们的旋转代理会自动处理 IP 地址切换,不再需要手动管理代理。我们在 195 个国家/地区均有覆盖,并提供 99.9% 的网络正常运行时间和成功率。我们的全球代理网络包含:
- 数据中心代理 – 超过 770,000 个数据中心 IP。
- 住宅代理 – 超过 72 百万(7,200 万)个住宅 IP,覆盖 195 多个国家。
- ISP 代理 – 超过 700,000 个 ISP IP。
按照下列步骤,使用 Bright Data 代理与 Selenium Wire 进行集成。
如果已有账户,请登录 Bright Data。否则可以免费创建一个账户。登录后您可看到如下用户面板:
点击 “View proxy products” 按钮:
随后来到 “Proxies & Scraping Infrastructure” 页面:
往下滚动找到 “Residential Proxies” 选项卡,点击 “Get started”:
您会进入住宅代理配置页面,根据向导一步步设置代理服务。如果在配置时有任何疑问,可随时 联系 24/7 技术支持:
进入 “Access parameters” 标签页,获取代理的主机、端口、用户名和密码:
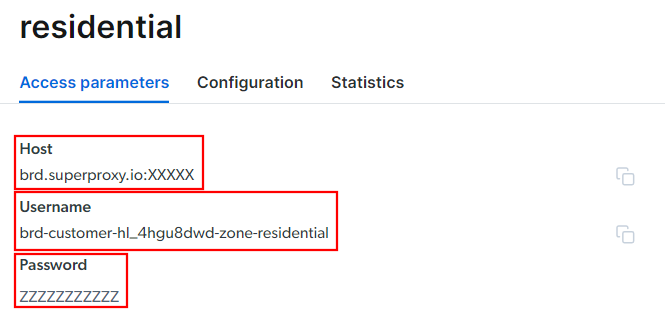
注意,“Host” 字段里已经包含端口。
接下来只需将这些信息组合到代理 URL 中即可,其语法如下:
<username>:<password>@<host>例如,在此示例中可写成:
brd-customer-hl_4hgu8dwd-zone-residential:[email protected]:XXXXX最后切换 “Active proxy” 到开启状态,按照提示完成流程,您就可以直接使用了!

以下是如何在 Selenium Wire 中使用 Bright Data 代理的示例:
# Bright Data proxy URL
proxy = "brd-customer-hl_4hgu8dwd-zone-residential:[email protected]:XXXXX"
# Set up Selenium Wire options
options = {
"proxy": {
"http": proxy,
"https": proxy
}
}
# Initialize the WebDriver with Selenium Wire
driver = webdriver.Chrome(seleniumwire_options=options)使用此方法,代理切换会更加简单!
Selenium 对比 Selenium Wire 在网页抓取中的差异
总结如下,对比下表:
| Selenium | Selenium Wire | |
|---|---|---|
| 定位 | 一款用于自动化网页浏览器的工具,通常用于 UI 测试和网络交互 | 在 Selenium 的基础上扩展,提供检查和修改 HTTP/HTTPS 请求和响应的能力 |
| HTTP/HTTPS 请求处理 | 不支持直接访问 HTTP/HTTPS 请求或响应 | 允许检查、修改并捕获 HTTP/HTTPS 请求与响应 |
| 代理支持 | 有限的代理支持(需手动配置) | 高级代理管理,支持动态设置 |
| 性能 | 轻量且速度快 | 由于捕获和处理网络流量存在开销,速度略慢 |
| 应用场景 | 主要用于 Web 应用功能性测试,也可用于基本的网页抓取 | 适用于测试 API、调试网络流量以及网页抓取 |
结论
在本文中,您学习了 Selenium Wire 是什么,以及如何将其应用到网页抓取当中。我们特别关注了代理集成和代理切换的内容。需要注意的是,Selenium Wire 虽然有用,但并非万能,而且它已经不再积极维护。
更好的方法并不是对 Selenium Wire 进一步扩展,而是直接使用原生的 Selenium 或其他浏览器自动化工具,并结合一个专门的抓取浏览器。
Bright Data 的 Scraping Browser 是一个可伸缩的云端浏览器,可与 Playwright、Puppeteer、Selenium 等工具配合使用。它可在每个请求时自动切换出口 IP,并能应对浏览器指纹识别、重试、验证码识别 等多重挑战。无需再担心被阻拦,大大简化您的抓取流程。
立即注册并开始免费试用吧!



技术写作者
 3 years experience
3 years experience
Federico Trotta 是一名技术写作者、编辑和数据科学家。擅长技术内容管理、数据分析、机器学习和 Python 开发。





