

在本教程中,我们将学习如何抓取现代招聘网站 JOBKOREA 的职位列表。
我们将涵盖:
- 通过提取内嵌 Next.js 数据的纯 Python 手工爬取
- 使用 Bright Data Web MCP 实现更稳定、可扩展的抓取
- 使用 Bright Data AI Scraper Studio 的零代码抓取
每种技术都基于本仓库提供的工程代码实现,从底层爬取逐步过渡到完全由 AI 驱动的智能数据抽取。
前置条件
开始本教程前,请确认你已经准备好以下环境:
- Python 3.9 及以上版本
- 具备 Python 与 JSON 的基础知识
- 一个已开通 MCP 权限的 Bright Data 账号
- 已安装 Claude Desktop(在零代码方案中作为 AI Agent 使用)
项目初始化
克隆 项目仓库 并安装依赖:
python -m venv venv
source venv/bin/activate # macOS / Linux
venv\Scripts\activate # Windows
pip install -r requirements.txt项目结构
仓库结构经过组织,便于分别学习每一种抓取技术:
jobkorea_scraper/
│
├── manual_scraper.py # Manual Python scraping
├── mcp_scraper.py # Bright Data Web MCP scraping
├── parsers/
│ └── jobkorea.py # Shared parsing logic
├── schemas.py # Job data schema
├── requirements.txt
├── README.md每个脚本都可以独立运行,取决于你想要体验哪一种方法。
技术一:纯 Python 手工爬取
我们先从最基础的方法开始:仅使用 Python 抓取 JOBKOREA,不依赖浏览器、MCP 或 AI Agent。
这种方式有助于理解 JOBKOREA 的数据返回方式,也适合在使用更高级方案前快速做原型。
抓取页面
打开 manual_scraper.py。
爬虫首先使用 requests 发送一个标准 HTTP 请求。为了避免立刻被封锁,我们会添加类似浏览器的请求头:
headers = {
"User-Agent": "Mozilla/5.0 (...)",
"Accept": "text/html,application/xhtml+xml,*/*",
"Accept-Language": "en-US,en;q=0.9,ko;q=0.8",
"Referer": "https://www.jobkorea.co.kr/"
}目标只是让请求看起来像正常的网页访问。随后我们抓取页面,并强制使用 UTF-8 编码,以避免韩文文本出现乱码:
response = requests.get(url, headers=headers, timeout=20)
response.raise_for_status()
response.encoding = "utf-8"
html = response.text为了调试,我们将原始 HTML 保存到本地:
with open("debug.html", "w", encoding="utf-8") as f:
f.write(html)当站点结构变更导致解析失败时,这个文件会非常有用。
解析响应
HTML 下载完成后,会被传入共享的解析函数:
jobs = parse_job_list(html)该函数位于 parsers/jobkorea.py 中,包含所有与 JOBKOREA 相关的解析逻辑。
尝试传统 HTML 解析
在 parse_job_list 内部,我们首先尝试像处理传统服务端渲染网站一样,使用 BeautifulSoup 提取职位列表:
soup = BeautifulSoup(html, "html.parser")
job_lists = soup.find_all("div", class_="list-default")如果没有找到任何列表,则会使用备选选择器:
job_lists = soup.find_all("ul", class_="clear")在这种方法有效时,爬虫会抽取以下字段:
- 职位标题
- 公司名称
- 工作地点
- 发布时间
- 职位链接
不过,这一方式只在 JOBKOREA 暴露出有意义的 HTML 结构时有效,而实际情况并非总是如此。
回退方案:提取 Next.js Hydration 数据
如果通过 HTML 解析没有找到职位数据,爬虫会切换到回退策略——针对页面中内嵌的 Next.js Hydration 数据。
nextjs_jobs = parse_nextjs_data(html)该函数会在页面中扫描注入的 JSON 字符串,这些字符串由客户端渲染阶段写入。匹配逻辑的简化版本如下:
pattern = r'\\"id\\":\\"(?P<id>\d+)\\",\\"title\\":\\"(?P<title>.*?)\\",\\"postingCompanyName\\":\\"(?P<company>.*?)\\"'基于这些数据,我们重建职位详情页 URL:
link = f"https://www.jobkorea.co.kr/Recruit/GI_Read/{job_id}"借助这一回退方案,我们无需运行浏览器也能完成抓取。
保存结果
每条职位数据都会通过共享 Schema 校验,并写入磁盘:
with open("jobs.json", "w", encoding="utf-8") as f:
json.dump(
[job.model_dump() for job in jobs],
f,
ensure_ascii=False,
indent=2
)运行方式如下:
python manual_scraper.py "https://www.jobkorea.co.kr/Search/?stext=python"此时你应当能在项目根目录看到包含职位列表的 jobs.json 文件。
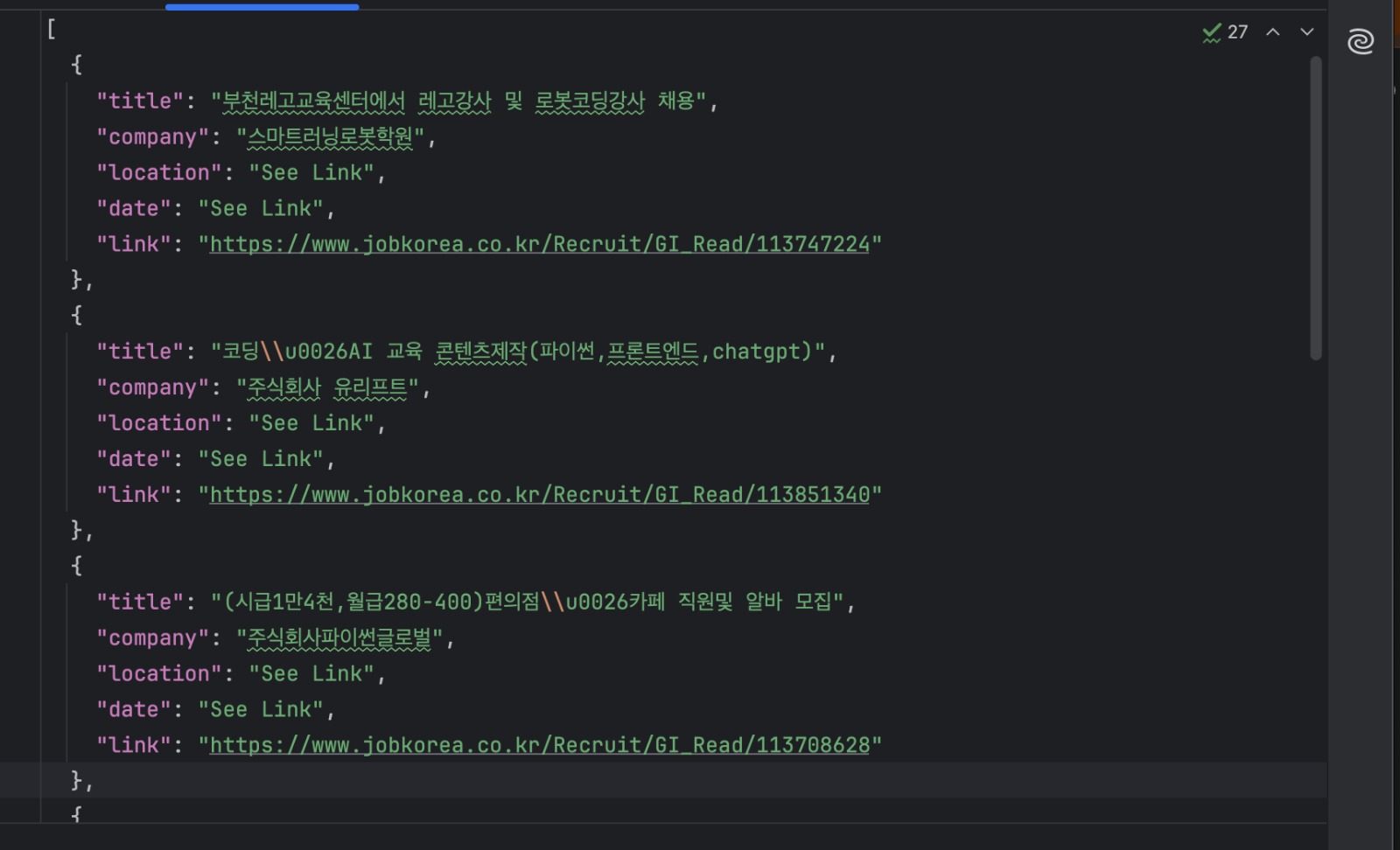
何时适合使用这种方法
手工爬取非常适合用于探索网站工作原理或快速搭建原型。它简单、速度快,也不依赖外部服务。
但这种方法与 JOBKOREA 当前的页面结构高度绑定:依赖特定的 HTML 布局和 Hydration 模式,一旦网站改版,就容易失效。
对于更稳定、长期的抓取,更推荐使用能够处理渲染和页面变更的工具,这正是我们在下一节中使用 Bright Data Web MCP 要解决的问题。
技术二:使用 Bright Data Web MCP 抓取
在上一节中,我们通过手工下载 HTML 并提取内嵌数据来抓取 JOBKOREA。虽然可行,但与现有页面结构高度耦合。
在这一节中,我们将使用 Bright Data Web MCP 来负责页面抓取与渲染,我们只需专注于将返回内容转成结构化职位数据。
这一方法在 mcp_scraper.py 中实现。
获取 Bright Data API Key/Token
- 登录 Bright Data 控制台
- 在左侧侧边栏中打开 Settings(设置)
- 进入 Users and API Keys(用户与 API Key)
- 复制你的 API Key
在后续截图中,你会看到该页面的具体位置以及 Token 的展示位置。
在项目根目录创建 .env 文件,并添加:
BRIGHT_DATA_API_TOKEN=your_token_here脚本会在运行时加载该 Token,如果缺失会直接退出。
MCP 的前提条件
Bright Data Web MCP 通过 npx 在本地启动,因此请确保:
- 已安装 Node.js
npx已在系统 PATH 中可用
MCP 服务由 Python 启动:
server_params = StdioServerParameters( command="npx", args=["-y", "@brightdata/mcp"], env={"API_TOKEN": BRIGHT_DATA_API_TOKEN, **os.environ} )运行 MCP 爬虫
使用 JOBKOREA 搜索 URL 运行脚本:
python mcp_scraper.py "https://www.jobkorea.co.kr/Search/?stext=python"脚本会打开一个 MCP 会话并完成初始化:
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()连接建立后,爬虫即可开始获取页面内容。
通过 MCP 抓取页面
在本项目中,爬虫使用 MCP 工具 scrape_as_markdown:
result = await session.call_tool(
"scrape_as_markdown",
arguments={"url": url}
)返回的内容会被收集并保存到本地:
with open("scraped_data.md", "w", encoding="utf-8") as f:
f.write(content_text)这样可以获得 MCP 返回内容的可读快照,方便调试和后续解析。
从 Markdown 中解析职位数据
MCP 返回的 Markdown 内容会被转换为结构化的职位数据。
解析逻辑首先查找 Markdown 链接:
link_pattern = re.compile(r"\[(.*?)\]\((.*?)\)")职位链接根据 URL 中是否包含以下片段来识别:
if "Recruit/GI_Read" in url:找到职位链接后,脚本会结合前后行文本提取公司名称、工作地点和发布时间等信息。
最后,将结果写入磁盘:
with open("jobs_mcp.json", "w", encoding="utf-8") as f:
json.dump(
[job.model_dump() for job in jobs],
f,
ensure_ascii=False,
indent=2
)输出文件
脚本执行结束后,你应当看到:
scraped_data.md
由 Bright Data Web MCP 返回的原始 Markdown 内容
jobs_mcp.json
将职位列表解析后得到的结构化 JSON 数据
何时适合使用这种方法
在 Python 中直接使用 Bright Data Web MCP,适合希望同时兼顾可靠性与可重复性的爬取场景。
由于 MCP 负责渲染、网络请求与基础站点防御处理,这种方式相比手工爬取对页面布局变化更加不敏感。同时,将逻辑保留在 Python 中又便于自动化、调度以及集成到更大的数据流水线中。
当你需要长期、稳定的抓取结果,或需要抓取多个搜索页/关键词时,这一技术非常适合。另外,它也为从手工爬取升级到 AI 驱动工作流提供了清晰路径,而无需完全重写为纯 AI 方案。
接下来,我们将进入第三种技术:使用连接了 Bright Data Web MCP 的 Claude Desktop 作为 AI Agent,在不编写任何爬虫代码的情况下抓取 JOBKOREA。
技术三:使用 Bright Data IDE 自动生成爬虫代码
在最后一种技术中,我们将在 Web Scraping IDE 中使用 Bright Data 的 AI 辅助爬虫自动生成抓取代码。
你无需从零编写抓取逻辑,只需描述你的目标,IDE 就会协助生成并优化爬虫。
打开 Scraper IDE
在 Bright Data 控制台中:
从左侧侧边栏进入 Data
- 点击 My Scrapers
- 在右上角点击 New
- 选择 Develop your own web scraper
这会打开 JavaScript 集成开发环境(IDE)。
输入目标 URL:”https://www.jobkorea.co.kr/Search/”,然后点击 “Generate Code”。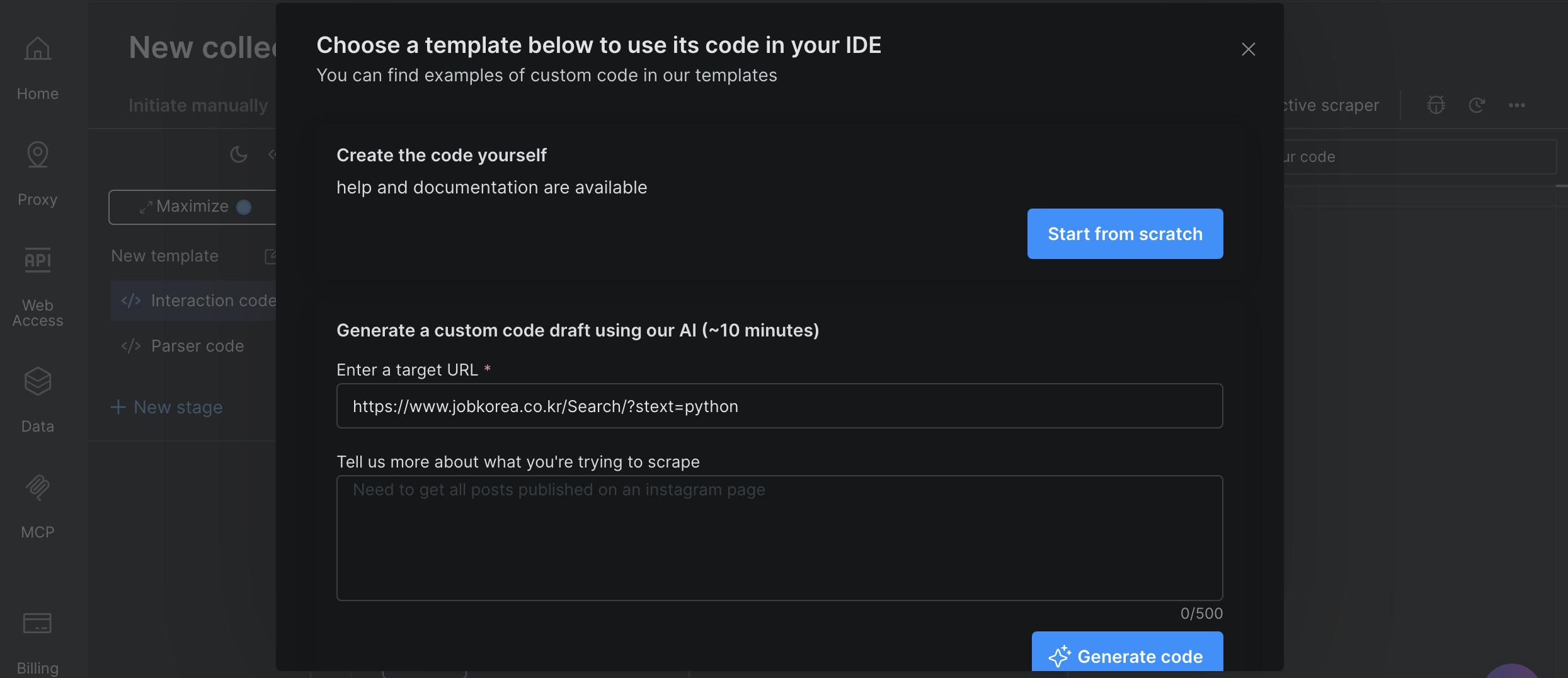
IDE 会处理你的请求并生成一个可直接使用的代码模板。生成完成后,你会收到邮件通知,随后即可按需编辑或直接运行该代码。
三种抓取技术对比
本项目中的三种技术都在解决同一个问题,但适用于不同的工作流。下表概括了它们在实践中的差异:
| 技术方案 | 搭建成本 | 可靠性 | 自动化能力 | 运行位置 | 最佳使用场景 |
|---|---|---|---|---|---|
| 纯 Python 手工爬取 | 低 | 低 ~ 中 | 有限 | 本地机器 | 学习、快速实验 |
| Bright Data MCP(Python) | 中 | 高 | 高 | 本地 + Bright Data | 生产级爬取、定时任务 |
| AI 自动生成爬虫(Bright Data IDE) | 低 | 高 | 高 | Bright Data 平台 | 快速搭建、可复用的托管爬虫 |
总结
在本教程中,我们依次介绍了三种抓取 JOBKOREA 的方式:纯 Python 手工爬取、更稳定的 Bright Data Web MCP 工作流,以及使用 Bright Data AI Scraper Studio 的零代码方案。
三种技术是逐级递进的:手工爬取有助于理解站点工作原理;基于 MCP 的方案提供更高的可靠性和自动化能力;AI Agent 方案则以极小的搭建成本提供最快速的结构化数据获取能力。
如果你正在抓取像 JOBKOREA 这样以客户端渲染为主的现代网站,并希望获得比脆弱的 CSS/DOM 选择器或传统浏览器自动化更可靠的替代方案,Bright Data Web MCP 是一个同时适用于传统脚本和 AI 驱动工作流的坚实基础。



技术写作者
Amitesh Anand 是一位开发者倡导者和技术写作者,分享有关 AI、软件和开发工具的内容,拥有 1 万粉丝和超过 40 万次观看。



