本文将涵盖:
- 当从网站抓取的数据不可靠或过时时,开发者面临的挑战
- 识别抓取结果不佳的原因
- 获取确保数据更干净、更可信的建议
我们开始吧!
导致网页抓取数据不准确的一些原因
在学习如何提升抓取数据的准确性之前,先了解这些问题的成因。在本节中,你将看到抓取过程中可能遇到的一些问题,例如动态内容、频繁的 DOM 变更等。
JavaScript 渲染内容导致的数据缺口
高度依赖 JavaScript 的网站会在初始 HTML 响应后异步加载内容,导致传统的 HTTP 抓取器得到的页面结构不完整。请求页面时,你只会先收到在 JavaScript 执行之前的 HTML 框架。电商站点的商品列表、社交平台的用户评论以及无限滚动的内容通常通过页面加载后数毫秒到数秒内的 AJAX 调用加载。
这种时序不匹配会让抓取器提取到占位元素、加载动画或空容器,而不是实际数据。例如,抓取到的 HTML 可能包含 <div class="product-list" data-loading="true"></div> 而不是填充了商品信息的内容。
DOM 结构不断演变导致不一致

网站经常修改其 HTML 结构,而不会为自动化工具保留向后兼容性。曾经可靠的 CSS 选择器可能在开发者修改类名、重构布局或改变父子层级后突然返回空结果。你的抓取器可能仍然定位 .product-price,而网站改版后该选择器被重命名为 .item-cost。
反爬系统干扰数据采集
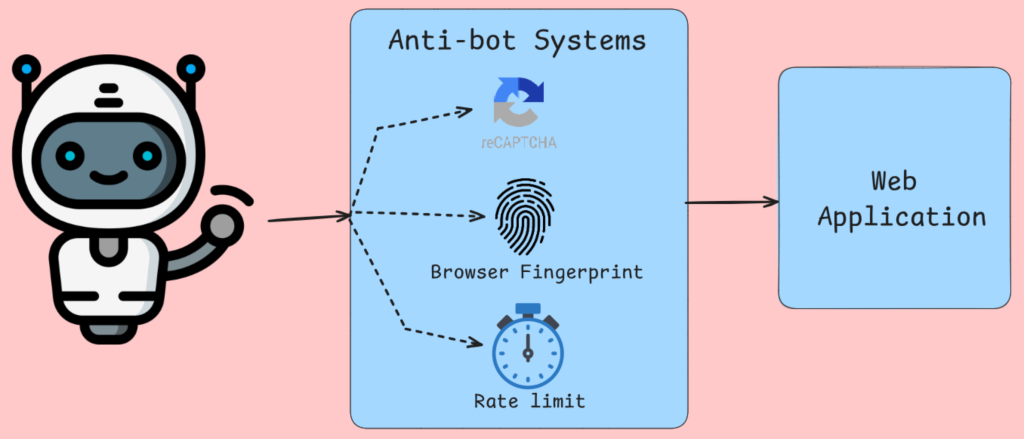
机器人检测不仅仅做 IP 封锁,还会分析浏览器指纹、鼠标移动以及其他常见检查。Cloudflare 等工具会注入需要浏览器执行才能完成的 JavaScript 挑战。通过浏览器检查后,未通过测试的请求将被返回替代内容或错误页面。你的抓取器会收到验证码页面、拒绝访问提示,甚至是有意误导的数据,而非真实内容。
限流算法会跟踪每个 IP、User-Agent 等的请求频率。如果流量看起来不像人类行为,就会被限速或阻断。
服务端渲染(SSR)问题
使用 Next.js 等框架在服务器端渲染,会基于不同条件生成不同的 HTML 输出。同一 URL 可能根据你的抓取器无法控制或准确模拟的因素返回完全不同的内容结构。个性化内容、地理围栏信息和用户特定定价会导致抓取器看到的与实际用户看到的数据不同。
出现在抓取器与源站之间的缓存层会引入时间上的不一致,最新更新的内容需要时间在 CDN 节点间传播。你的抓取器可能抓到过期的商品价格、陈旧的库存水平,或并不反映网站当前状态的缓存错误页。不同地理区域的边缘节点可能返回不同的缓存版本,使数据一致性取决于响应你请求的具体服务器。
网络层面的数据损坏
不稳定的网络连接、代理服务器问题以及 DNS 解析故障会引入难以通过常规错误处理发现的细微数据损坏。部分内容下载会生成被截断的 HTML 响应,这些响应可能能成功解析,但缺失页面关键部分。你的抓取器可能只收到商品列表页面前 80% 的内容,看似正常工作,却系统性遗漏长页面底部加载的条目。
在使用不同压缩设置的旋转代理时,压缩算法偶尔也会在传输过程中造成数据损坏。
不准确的数据对应用有何影响?
不准确的网页抓取数据会从根本上破坏系统的业务逻辑与用户体验。理解这些失败模式有助于开发者构建更具韧性的数据管道和验证层。
分析管道退化
数据质量问题在分析系统中尤为明显,因为聚合会放大底层错误。例如,抓取到的电商价格数据如果在解析时因货币符号处理失败把“$29.99”变成了“2999”,那么计算出来的平均价格就毫无意义。
当抓取的商品标识符包含不可见的 Unicode 字符或尾随空格时,数据库联接可能在不知不觉中失败。一个商品追踪系统可能把同一条目显示为多条记录,导致库存统计膨胀,进而扭曲需求预测模型。这类标准化失败会遍布整个 ETL 流程,并导致下游报表把营收计算成两倍。
决策系统失效
构建在抓取数据之上的自动化决策系统,一旦输入质量下降,就可能做出灾难性的错误选择。依赖从动态网站抓取的竞品数据的价格监控应用,常会抓到“Loading…”之类的占位值或 JavaScript 错误信息,而不是实际价格。当这些非数值字符串绕过验证进入系统时,定价算法可能回退为零值。
如果你在构建推荐引擎,当某些商品品类因分页问题或鉴权障碍而系统性抓取不全时,不完整的数据集会让推荐引擎表现受损。结果是推荐系统偏向那些成功抓取的品类,形成“回音室”,降低用户发现多样化产品的机会,最终限制营收增长与客户满意度。
应用性能下降
当数据质量问题导致低效的数据库操作时,消费抓取数据的应用会出现性能问题。包含未转义 HTML 标签的抓取文本字段会破坏搜索索引,使查询从优化的索引查找退化为全表扫描。当这些性能惩罚在多并发查询中累积,面向用户的搜索功能会变得迟缓。
当抓取数据的格式不一致,且导致无法进行重复检测时,缓存失效策略会失败。同一产品信息在不同时间被抓取下来,可能因为空白符处理不同而被视为不同的缓存条目,增加内存占用并降低缓存命中率。这种“缓存污染”会迫使应用反复执行代价高昂的数据库调用,从而降低整体响应速度。
数据集成问题
抓取数据很少是孤立存在的。它通常需要与内部数据库和第三方 API 联合,形成完整的数据集。当网站改版导致抓取字段结构意外变化时,模式不匹配会变得常见。若抓取逻辑未能适配新的 HTML 布局,商品目录系统可能丢失关键规格信息,令下游应用获取到的不完整商品信息影响搜索结果与客户购买决策。
数据新鲜度不一致会造成抓取数据与内部数据反映不同时间点的状况。金融应用若将抓取的市场数据与内部交易记录合并,当抓取延迟导致价格信息落后于交易时间戳时,投资组合估值就会不准确。这些时间上的不一致也使得建立准确的审计路径变得困难。
提升数据准确性的多种方法
网页抓取中的数据准确性依赖多种技术协同工作,以应对提取流水线中的不同失败点。
用无头浏览器处理动态内容
传统的基于 HTTP 的抓取器会错过大量数据,因为许多网站在初始页面加载后严重依赖 JavaScript 来渲染内容。无头浏览器(如 Puppeteer 或 Playwright)可像常规浏览器一样执行 JavaScript,确保捕获所有动态生成的内容。
Puppeteer 通过 Chrome DevTools Protocol 提供对页面渲染的精细控制。你可以等待特定网络请求完成、监控 DOM 变化,甚至拦截用于填充内容的 API 调用。此方法对那些在初始渲染后通过 AJAX 请求加载数据的单页应用尤为有效。
使用无头浏览器时,禁用图片、CSS 和不必要的插件以降低内存消耗并提升加载速度。合理配置视口尺寸,因为有些网站会根据屏幕尺寸渲染不同内容。
快速适应网站结构变化
网站结构频繁变化,会破坏依赖固定 CSS 选择器或 XPath 表达式的抓取器。构建可适配的抓取器需要采用回退策略,并建立监控系统以在结构变化导致数据丢失之前就检测到变化。
为同一数据元素创建选择器层级,尝试多种定位方式。先用最具体的选择器,再逐步回退到更通用的选择器。
class AdaptiveSelector:
def __init__(self, selectors_list, element_name):
self.selectors = selectors_list
self.element_name = element_name
self.successful_index = 0
def extract_data(self, soup):
for i, selector in enumerate(self.selectors[self.successful_index:], self.successful_index):
elements = soup.select(selector)
if elements:
self.successful_index = i
return [elem.get_text(strip=True) for elem in elements]
raise ValueError(f"No selector found for {self.element_name}")
# Usage
price_selector = AdaptiveSelector([
'div.price-current .price-value', # Most specific
'.price-current', # Intermediate
'[class*="price"]' # Broad fallback
], 'product_price')实现变更检测系统,以随时间比较页面结构的“指纹”。
验证并清洗抓取数据
原始抓取数据常包含影响准确性的各种不一致。为此需要构建全面的验证与清洗流水线,将凌乱的网页数据转化为适合下游处理的可靠数据集。
数据验证从类型检查和格式校验开始。价格应匹配货币模式,日期应能正确解析,数值字段应包含有效数字。
import re
from datetime import datetime
from typing import Optional, Dict, Any
class DataValidator:
def __init__(self):
self.patterns = {
'price': re.compile(r'[$€£¥]?[d,]+.?d*'),
'email': re.compile(r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}$'),
'phone': re.compile(r'^+?[ds-()]{10,}$'),
'date': re.compile(r'd{4}-d{2}-d{2}|d{2}/d{2}/d{4}')
}
def validate_record(self, record: Dict[str, Any]) -> Dict[str, Any]:
cleaned_record = {}
for field, value in record.items():
if value is None or str(value).strip() == '':
cleaned_record[field] = None
continue
cleaned_value = self._clean_field(field, str(value))
if self._is_valid_field(field, cleaned_value):
cleaned_record[field] = cleaned_value
else:
cleaned_record[field] = None
return cleaned_record
def _clean_field(self, field_name: str, value: str) -> str:
# Remove extra whitespace
cleaned = re.sub(r's+', ' ', value.strip())
# cleadning logic
return cleaned
def _is_valid_field(self, field_name: str, value: str) -> bool:
if 'price' in field_name.lower():
return bool(self.patterns['price'].match(value))
elif 'email' in field_name.lower():
return bool(self.patterns['email'].match(value))
# Add more field-specific validations
return len(value) > 0实现离群点检测,以识别可能表示抓取错误的可疑数据点。可使用四分位距等统计方法标记落在期望范围之外的价格、数量或其他数值。字符串相似度算法也能检测损坏的文本字段或提取错误。
实现错误处理与重试机制
网络故障、服务器错误和解析异常在抓取操作中不可避免。为抓取器构建全面的错误处理可防止单点失败蔓延为整体崩溃,而重试机制可自动应对临时问题。
指数退避是应对限流和服务器临时过载的有效策略。先使用较短延迟,随后在重试中逐步增加等待时间。这样既给服务器恢复时间,也能避免过于激进的重试模式触发反爬措施。
import asyncio
import aiohttp
from typing import Optional, Callable
class ResilientScraper:
def __init__(self, max_attempts=3, base_delay=1.0):
self.max_attempts = max_attempts
self.base_delay = base_delay
self.session = None
async def fetch_with_retry(self, url: str, parse_func: Callable) -> Optional[Any]:
for attempt in range(self.max_attempts):
try:
if attempt > 0:
delay = self.base_delay * (2 ** attempt)
await asyncio.sleep(delay)
async with self.session.get(url) as response:
if response.status == 200:
content = await response.text()
return parse_func(content)
elif response.status == 429: # Rate limited
continue
elif response.status >= 500: # Server error
continue
else: # Client error
return None
except (aiohttp.ClientError, asyncio.TimeoutError):
continue
return None断路器模式可防止抓取器在服务异常时持续施压。跟踪各域名的错误率,当失败率超过阈值时临时停止请求。在宕机期间,这能同时保护抓取器与目标站点免受不必要负载影响。
使用旋转代理和用户代理
IP 封锁是大规模抓取中最常见的障碍之一。轮换代理与用户代理可将请求分散到不同的来源,在保持抓取速度的同时显著降低被检测概率。
代理轮换需要精心管理连接池与请求分配。避免同一域名的连续请求使用同一代理,这种模式很容易被检测。应采用轮询或随机选择算法,确保在代理池中均匀分布。
import random
from typing import List, Dict, Optional
class ProxyRotator:
def __init__(self, proxies: List[str], user_agents: List[str]):
self.proxies = proxies
self.user_agents = user_agents
self.failed_proxies = set()
def get_next_proxy_and_headers(self) -> tuple[Optional[str], Dict[str, str]]:
available_proxies = [p for p in self.proxies if p not in self.failed_proxies]
if not available_proxies:
self.failed_proxies.clear()
available_proxies = self.proxies
proxy = random.choice(available_proxies)
user_agent = random.choice(self.user_agents)
headers = {
'User-Agent': user_agent,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.5',
'Connection': 'keep-alive'
}
return proxy, headers
def mark_proxy_failed(self, proxy: str):
self.failed_proxies.add(proxy)用户代理轮换应模拟真实的浏览器分布(可参考网页分析数据)。按市场份额为列表加权,使 Chrome 等常见浏览器的出现频率更高。对向移动设备提供不同内容的网站,也应包含移动端用户代理。
AI 驱动的代理管理
在数据抓取中,IP 封禁是可能让你的工作彻底停摆的挑战。以抓取机票价格为例,网站很容易检测出来自同一 IP 的高频请求,并据此标记和封禁你的抓取器。
解决方案在于 AI 驱动的代理管理,而不是基础的代理轮换。该方法使用代理池把请求分配到不同 IP 上,有效掩蔽身份。像 Bright Data 这样的专业服务可提供超过 1.5 亿个住宅 IP,覆盖约195 个国家。
智能代理管理带来多项关键收益:确保匿名性,让网站无法将可疑活动直接关联到你;并通过动态限速来调整请求频率,以模拟人类行为。
这些策略协同工作,可让抓取器在多种网络环境中保持数据准确性:无头浏览器捕获完整内容,自适应选择器应对结构变化,验证流水线清洗提取数据,全面的错误处理防止故障蔓延,而 AI 驱动的代理管理优化投递。
可靠抓取的工具与最佳实践
选择合适的抓取工具取决于目标网站的复杂度与可扩展性需求。本节将从四类工具入手,解决网页抓取中的不同技术挑战。
适用于静态内容的 Python 库
Beautiful Soup擅长解析在初始服务器响应中直接加载内容的 HTML 文档。它可以优雅地处理畸形 HTML,并提供直观的方法在嵌套元素中提取数据。Requests 与 Beautiful Soup 自然搭配,便于处理许多站点正确访问所需的站点属性。
Scrapy是一个完整框架,而非简单库。它通过内置调度器管理并发请求,并以其管道架构处理复杂的爬取场景。你可以利用其中间件系统进行自定义请求处理、用户代理轮换以及自动重试机制。
用于动态内容的浏览器自动化
Selenium通过 WebDriver 协议控制真实浏览器,适用于高度依赖 JavaScript 渲染内容的网站。它可处理表单提交、按钮点击、滚动分页等用户交互,这些交互会触发额外内容加载。你需要显式设置等待条件,在特定元素可用或满足条件之前暂停执行。
Playwright提供类似的浏览器自动化能力,但在性能和现代 Web 特性支持上更进一步。其自动等待功能可在元素可交互前自动等待,从而消除大多数时序问题。Playwright 的网络拦截还能监控用于填充页面内容的 API 调用,往往能发现比解析渲染后 HTML 更高效的数据访问方式。
无头浏览器方案
Puppeteer针对 Chromium 系列浏览器,凭借 DevTools Protocol 对浏览器行为进行精细控制。除了数据提取,它还擅长生成截图、PDF 和性能指标。其请求拦截功能可用于屏蔽图片和样式等非必要资源,从而在以内容为中心的场景中加快抓取速度。
Playwright 的跨浏览器特性让它在需要覆盖不同渲染引擎的抓取场景中非常有价值。其 codegen 功能可以记录用户交互并生成对应的自动化脚本。
企业级代理管理平台
Bright Data可在全球范围内提供住宅 IP 轮换,并支持会话持久化,使跨多页面的抓取会话保持一致身份。Web Unlocker可自动处理常见反爬措施,包括验证码解决与浏览器指纹随机化。其 Scraping Browser 将代理轮换与预配置、优化过的浏览器实例结合,帮助规避检测。
请求管理与限流
采用退避策略可在优雅应对临时故障的同时避免压垮目标服务器。例如,urllib3(顶级 Python HTTP 客户端之一)提供可配置延迟的重试机制。采用令牌桶算法的自定义限流确保请求间隔匹配服务器承载能力,而不是使用可能过度或不足的固定延迟。
对于需要鉴权或跨请求保持状态的网站,会话管理尤为重要。持久化的 Cookie 存储与请求头管理可确保在长时间抓取过程中维持对受保护内容的访问。连接池通过重用到同一域的已建立网络连接,降低开销。
数据验证
像 Pydantic 这样的模式验证库可强制数据结构一致性,并在解析错误进入处理流水线之前将其捕获。对抓取内容实施校验和验证可在网站修改结构或内容格式时进行检测,并触发抓取器维护告警。
这些工具的选择取决于你的具体技术需求。比如,面对简单的提取任务,静态内容抓取器提供最佳性能;而浏览器自动化工具虽耗费更多资源,却能处理复杂的交互式场景。
结论
本文首先了解了开发者在网站数据抓取中面临的挑战,并识别了导致不良抓取结果的原因;最后,我们介绍了可帮助你解决这些问题的工具与策略。



AI 内容创作者
Arindam Majumder 是一名开发者推广专员、YouTube博主和技术作家,专注于将大语言模型 (LLM)、智能体工作流及 AI 内容讲解得简单易懂,拥有超过5000名关注者。