
使用代理进行 IP 轮换对于网页抓取至关重要,尤其是面对可能施加限制的现代网站。将请求分发到多个 IP 地址对于避免被封锁或避免受制于速率限制十分重要。轮换 IP 地址使网站更难跟踪、限制您的抓取活动。这有助于提高网页抓取的效率和可靠性,使您能够更有效地提取数据。在网页抓取过程中使用代理和 IP 地址轮换可以避免基于 IP 的封禁和处罚、克服速率限制并访问受地域限制的内容。
本文介绍如何在网页抓取工作流程中通过代理来轮换所使用的 IP 地址。您可以了解从何处获得有效的代理、IP 轮换的技巧以及如何避免被目标网站屏蔽 。
使用 Python 轮换 IP
使用 Python 的常规抓取过程往往通过 Requests 或 Scrapy 等 Python 库来访问网站并解析其内容。然后,您可以筛选网站内容以获取想要提取的信息。以下是典型抓取过程的示例:
import requests
url = 'http://example.com'
# Make requests
response = requests.get(url)
print(response.text)
此过程可帮助您获取所需的信息,适用于一次性使用或只需要提取一次数据的情况。但是,它使用您的系统 IP 来发出请求,可能会在网站随着时间推移限制访问时遇到重复请求或连续请求的问题。
抓取流程示例的结果如下所示:
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans",
…
大多数旨在抓取或发出 web 请求的 Python 库,例如 Requests 或 Scrapy,都有切换发出这些请求的 IP 地址的途径。但是,要利用这一点,您需要有效 IP 地址的列表或来源。这些来源可能是免费或商用的,例如 Bright Data 代理。
商用代理可保证 IP 地址的有效性,并提供有效的工具来管理、轮换代理,从而确保网页抓取过程不会中断。例如,Bright Data 提供多种类型的代理产品,其价格各不相同,具体取决于其用例、扩展能力以及保障顺畅访问所请求数据的能力:
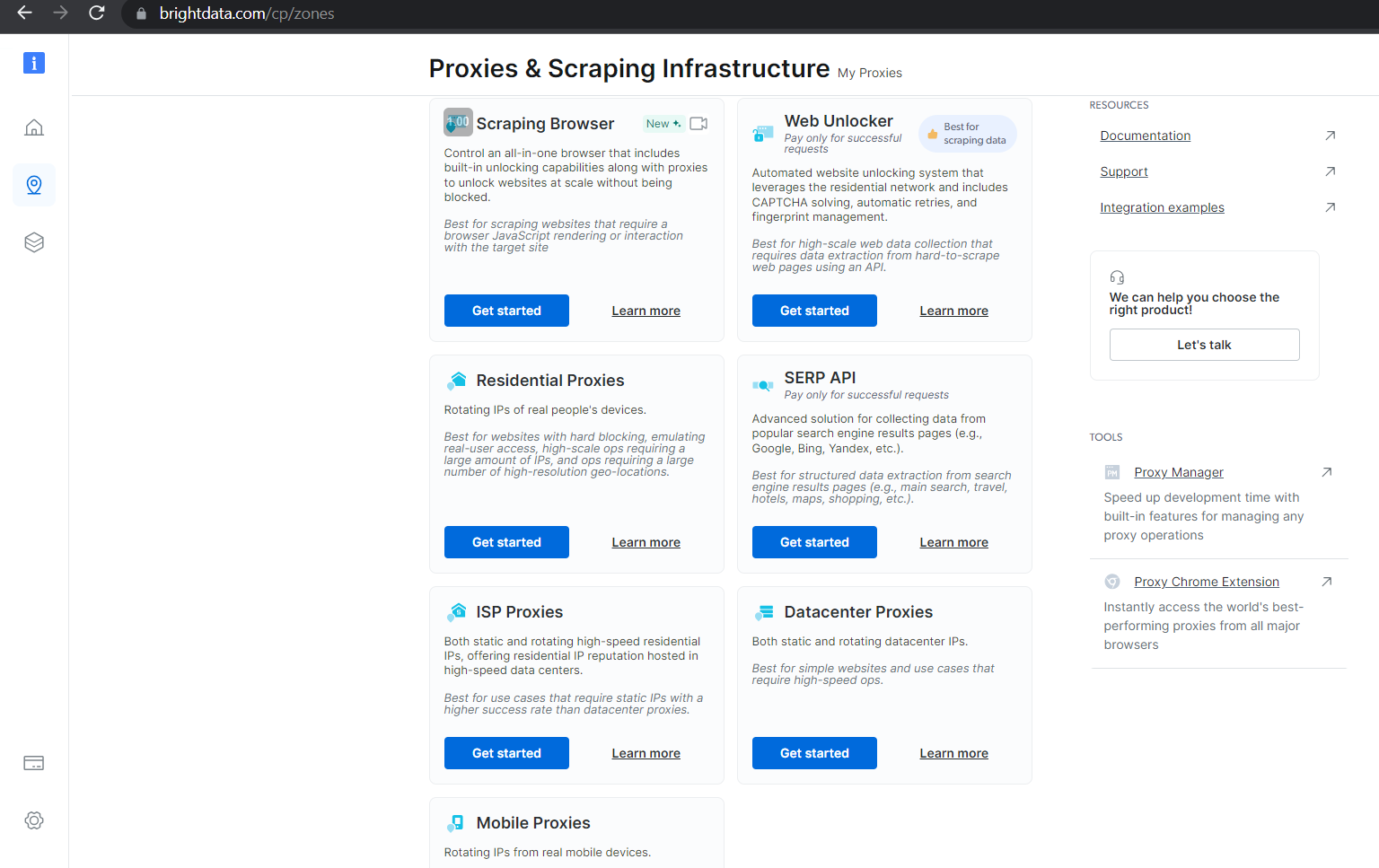
您可使用免费代理在 Python 中创建一个包含有效代理的列表,以便在整个抓取过程中轮换这些代理:
proxies = ["103.155.217.1:41317", "47.91.56.120:8080", "103.141.143.102:41516", "167.114.96.13:9300", "103.83.232.122:80"]
有了该列表后,您只需一个轮换机制在您发起多个请求后,从列表中选择不同的 IP 地址。在 Python 中,这类似于下列功能:
import random
import requests
def scraping_request(url):
ip = random.randrange(0, len(proxies))
ips = {"http": proxies[ip], "https": proxies[ip]}
response = requests.get(url, proxies=ips)
print(f"Proxy currently being used: {ips['https']}")
return response.text
每次调用该代码后,它都会从列表中随机选择一个代理。此代理用于发出抓取请求。
在处理无效代理时添加出错用例则会出现完整的抓取代码,如下所示:
import random
import requests
proxies = ["103.155.217.1:41317", "47.91.56.120:8080", "103.141.143.102:41516", "167.114.96.13:9300", "103.83.232.122:80"]
def scraping_request(url):
ip = random.choice(proxies)
try:
response = requests.get(url, proxies={"http": ip, "https": ip})
if response.status_code == 200:
print(f"Proxy currently being used: {ip}")
ip = random.randrange(0, len(proxies))
ips = {"http": proxies[ip], "https": proxies[ip]}
response = requests.get(url, proxies=ips)
try:
if response.status_code == 200:
print(f"Proxy currently being used: {ips['https']}")
print(response.text)
elif response.status_code == 403:
print("Forbidden client")
elif response.status_code == 429:
print("Too many requests")
except Exception as e:
print(f"An unexpected error occurred: {e}")
scraping_request("http://example.com")
您也可以使用此代理轮换列表,通过 Scrapy 等任何其他抓取框架来执行请求。
使用 Scrapy 抓取
使用 Scrapy 时,您需要先安装库并创建必要的项目工件,然后才能成功爬取网页。
您可在支持 Python 的环境中使用 pip 包管理器安装 Scrapy:
pip install Scrapy
安装完毕后,您可通过以下命令,使用当前目录中的一些模板文件生成 Scrapy 项目:
scrapy startproject sampleproject
cd sampleproject
scrapy genspider samplebot example.com
这些命令还会生成一个基础代码文件,您可通过 IP 轮换机制来完善此文件。
打开 sampleproject/spiders/samplebot.pysamplebot.py 文件并使用以下代码对其进行更新:
import scrapy
import random
proxies = ["103.155.217.1:41317", "47.91.56.120:8080", "103.141.143.102:41516", "167.114.96.13:9300", "103.83.232.122:80"]
ip = random.randrange(0, len(proxies))
class SampleSpider(scrapy.Spider):
name = "samplebot"
allowed_domains = ["example.com"]
start_urls = ["https://example.com"]
def start_requests(self):
for url in self.start_urls:
proxy = random.choice(proxies)
yield scrapy.Request(url, meta={"proxy": f"http://{proxy}"})
request = scrapy.Request(
"http://www.example.com/index.html",
meta={"proxy": f"http://{ip}"}
)
def parse(self, response):
# Log the proxy being used in the request
proxy_used = response.meta.get("proxy")
self.logger.info(f"Proxy used: {proxy_used}")
print(response.text)
在项目目录的顶部执行以下命令以运行此抓取脚本:
scrapy crawl samplebot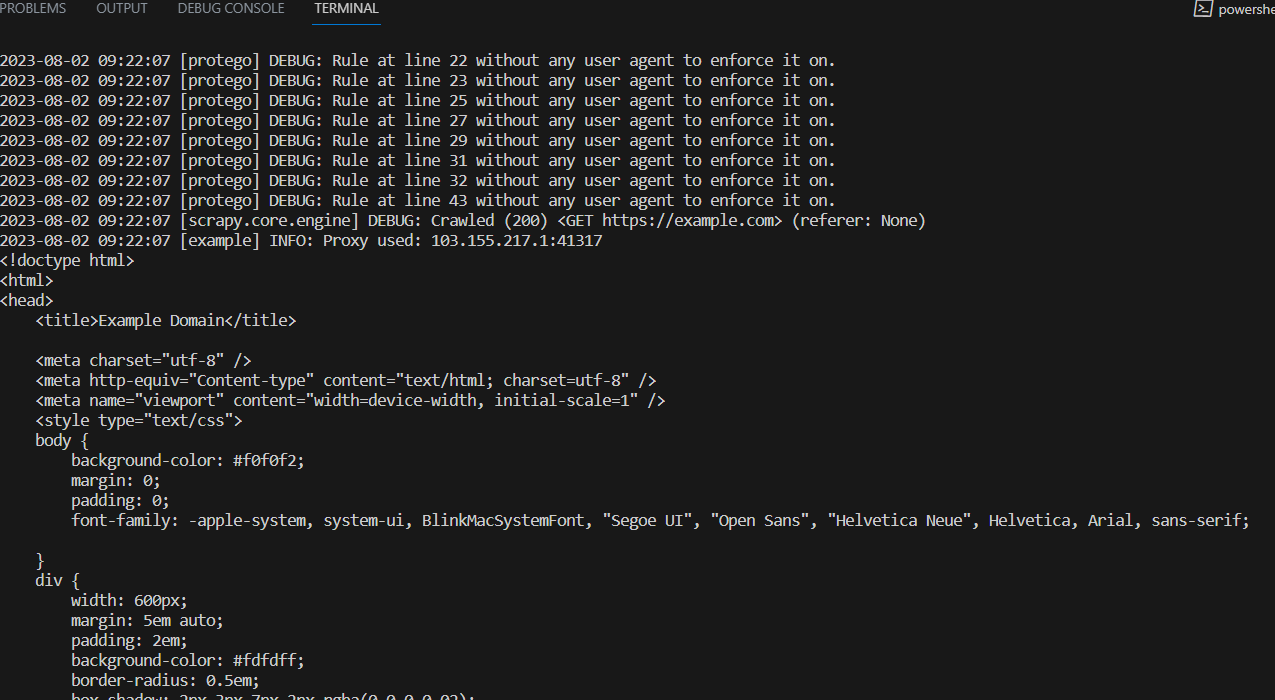
IP 轮换小贴士
网页抓取已演变为网站和抓取工具之间的竞赛,抓取工具不断采用新的方法和技术来获取所需数据,而网站也在寻找新的方法来阻止其访问。
IP 轮换技术旨在避开网站限制。为最大限度提高 IP 轮换的效果,尽可能降低被目标网站屏蔽的几率,请考虑使用以下技巧:
- 保证庞大且多样的代理池: 使用 IP 轮换时,您需要一个具有大量代理和各种 IP 地址的大型代理池。这有助于实现妥当轮换,并降低过度使用代理的风险——过度使用可能会导致速率限制和封禁。考虑使用具有不同 IP 范围和位置的多个代理提供商。另外,可以考虑使用不同的代理来改变请求的时间和间隔,以更好地模拟自然用户行为。
- 具备强大的错误处理机制:在网页抓取过程中,由于暂时的连接问题、代理被封锁或目标网站变更,您可能会遇到许多错误。通过在脚本中实施错误处理,您可以确保顺利执行抓取过程,捕获并处理常见异常,例如连接错误、超时和 HTTP 状态错误。考虑设置断路器,以便在短时间内发生大量错误时暂停抓取过程。
- 在使用前测试代理:在生产中部署抓取脚本之前,使用代理池的示例来测试不同场景下的 IP 轮换功能和错误处理机制。您可以使用示例网站来模拟现实情况,并确保您的脚本可以处理这些情况。
- 监控代理的性能和效率:定期监控代理的性能,以发现任何问题,例如响应慢或频繁故障。您应该追踪每个代理的成功率,以识别效率低下的代理。Bright Data 等代理提供商提供工具来检查其代理的运行状况和性能。通过监控代理性能,您可以快速切换到更可靠的代理,并从轮换池中移除性能不佳的代理。
网页抓取是一个迭代过程,网站可能会改变其结构和响应模式,或者实施新的措施来防止抓取。请定期监控抓取过程并适应任何变化,以保持抓取操作的有效性。
结语
本文探讨了 IP 轮换以及如何在抓取过程中通过 Python 实施 IP 轮换。您还了解了保持 Python 抓取过程有效性的实用技巧。
Bright Data 是网页抓取解决方案的一站式平台,提供合乎伦理道德的优质代理、网页抓取浏览器、用于取爬虫开发和操作的 IDE、即用型数据集以及用于抓取过程中轮换和管理代理的多种工具。
联系 Bright Data 的专家,寻找合适的解决方案,满足您的网页抓取需求。






