

分布式网络爬虫是一种在多台机器上扩展网络爬虫的策略,从而克服了单节点爬虫的局限性。本文将探讨
- 分布式网络爬行与单节点网络爬行
- 分布式网络爬虫的核心架构
- 分布式网络抓取的真实案例
- 实施战略和最佳做法
- 常见陷阱及解决方法
简要说明: 分布式网络爬虫利用机器集群并行抓取网站,解决了单节点爬虫无法应对的可扩展性和速度难题。它提供了更高的吞吐量和可靠性(无单一瓶颈),但代价是增加了架构的复杂性和开销。
分布式抓取与单节点抓取
大多数爬虫项目并不需要分布式系统,但团队通常会浪费数月时间来构建复杂的分布式架构,而单台服务器就足够了。
在单节点爬虫中,一台机器可以处理所有的获取、解析和存储工作。这种系统更易于开发和维护,也更省钱。它非常适合每分钟抓取 60-500 页内容,但随着抓取需求的增加,单节点就会成为瓶颈,因为你会受到 CPU、内存和网络限制的制约。
相比之下,分布式爬虫会将工作分散到多个节点上,从而实现大规模、高速、高容错性的并发获取。如果一个工作站崩溃,其他工作站会继续运行,从而提高了可靠性。代价是,分布式系统需要消息队列、URL 边界同步和精心设计,以避免重复或压倒目标网站。
全面对比
| 对比维度 | 单节点模式(Single-Node) | 分布式模式(Distributed) |
|---|---|---|
| 性能表现 | 平均每页4秒,约每分钟60-120个页面 | 快约30倍,每秒50,000+个请求 |
| 扩展能力 | 受限于单机资源 | 节点数线性扩展 |
| 容错能力 | 存在单点故障风险 | 自动故障切换、自愈能力强 |
| 地理分布 | 固定位置 | 多区域部署支持 |
| 资源利用 | 仅支持纵向扩展(增加单机性能) | 优化的横向扩展(增加机器数量) |
| 复杂性 | 设置简便,维护负担低 | 复杂的协调管理,运维成本较高 |
| 成本投入 | 初始投入低 | 基础设施成本更高,大规模运营时投资回报率(ROI)更优 |
| 维护成本 | 日常运维负担低 | 需要分布式系统的专业维护经验 |
| 数据处理 | 仅支持本地处理 | 节点间并行处理 |
| 反检测能力 | 有限的IP代理轮换 | 高级代理管理、防指纹技术 |
您是否应该采用分布式系统?(决策树)
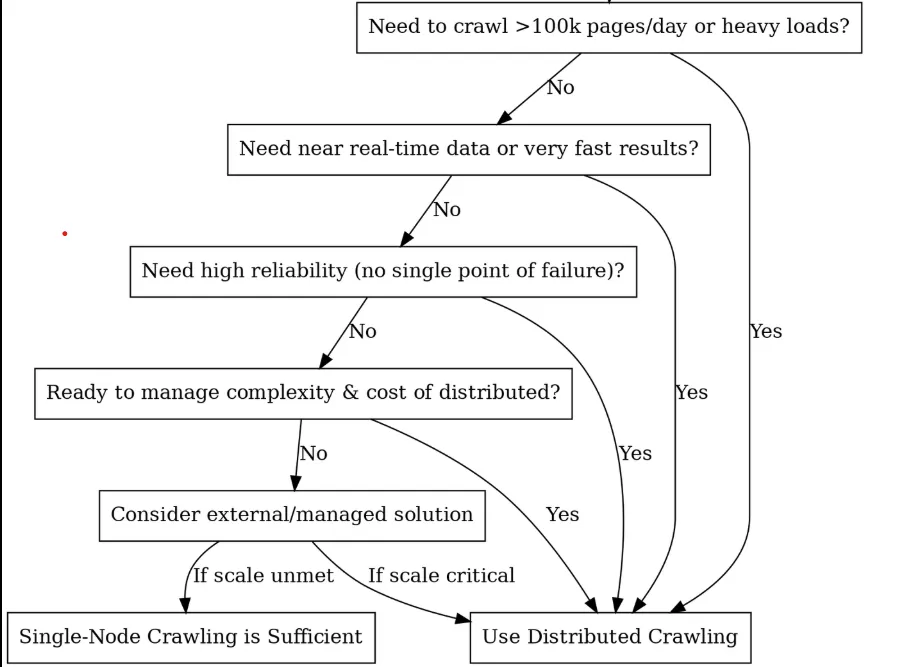
核心构件与架构
一旦您决定采用分布式爬行,下一步就是分解您实际要构建的东西。把它想象成组建一支高性能的赛车队,每个组件都有特定的工作,而且都需要无缝协作。以下是构建分布式爬虫系统所需的关键组件:
调度器/队列(大脑)
分布式爬虫的核心是一个调度器或任务队列,用于协调各节点之间的工作。调度器组件还可以处理礼貌(定时)和重试。例如,您可以实施特定域的队列,以确保一个网站不会同时被所有工人抓取。
对于调度程序,你有三种主要选择,每种都有自己的个性:
- 卡夫卡它是重量级冠军。它专为高吞吐量而设计,每秒处理数百万条信息也不费吹灰之力。它的优点在于基于日志的设计,非常适合管理 URL 边界。您可以按域进行分区,以保持抓取的有序性。
- RabbitMQ:这就像一把瑞士军刀。路由比 Kafka 更灵活,具有优先队列等功能。RabbitMQ 具有内存存储功能,因此对于较小的工作负载来说速度更快。当你需要对不同类型的内容采用不同的抓取策略时,它就非常适合。
- Celery:Python 开发者的好朋友。该选项不如其他选项高效,但易于使用。Celery 非常适合原型开发或中等规模的爬行,当你需要快速完成一些工作时。
URL前沿与重复数据删除:爬虫的记忆
是否曾不小心将同一个页面抓取 1000 次?重复数据删除功能就能帮你解决这个问题。你需要跟踪你所看到的内容,同时尊重服务器的礼貌,这样你就不会重复抓取同一个域。
Redis Sets 可以提供完美的准确性,但会占用大量内存。Bloom Filters 占用的内存少 90%(1.2GB,而十亿个 URL 则需要 12GB 以上),但偶尔也会出现误报(它们可能会说你没见过某个 URL,但其实你已经见过了),所以你可能会选择这种 Redis 实现:
class DistributedURLFrontier:
def __init__(self, redis_client):
self.redis = redis_client
def add_url(self, url, priority=0):
domain = urlparse(url).netloc
# Skip if already seen
if self.redis.sismember("seen_urls", url):
return
# Mark as seen and queue by domain
self.redis.sadd("seen_urls", url)
self.redis.lpush(f"queue:{domain}", url)
self.redis.zadd("priority_queue", {url: priority})
def get_next_url(self):
# Get highest priority URL
result = self.redis.zrevrange("priority_queue", 0, 0)
if not result:
return None
url = result[0]
domain = urlparse(url).netloc
# Respect crawl delay (1 second between requests per domain)
last_crawl = self.redis.get(f"last_crawl:{domain}")
if last_crawl and time.time() - float(last_crawl) < 1.0:
return None
# Remove from queues and update last crawl time
self.redis.zrem("priority_queue", url)
self.redis.rpop(f"queue:{domain}")
self.redis.set(f"last_crawl:{domain}", time.time())
return url
工作节点(肌肉)
工作节点是抓取工作的主力军。它们是实际执行抓取工作(如获取 URL 和处理内容)的进程或机器。每个工作节点运行相同的抓取逻辑(如相同的 Python 脚本或应用程序),但它们会并行处理队列中的不同 URL。
要想充分发挥 Worker 的作用,就需要让它们保持无状态,这样任何状态(访问过的 URL、结果等)都会存储在共享存储中或通过消息传递。这样,任何 Worker 都可以执行任何任务,当其中一个 Worker 死亡时,其他 Worker 会立即接替,不会有任何闪失。
class DistributedWorker:
def __init__(self, worker_id, max_concurrent=50):
self.worker_id = worker_id
self.semaphore = asyncio.Semaphore(max_concurrent)
self.session = aiohttp.ClientSession(
timeout=aiohttp.ClientTimeout(total=30),
connector=aiohttp.TCPConnector(limit=100)
)
async def crawl_batch(self, urls):
tasks = [self.crawl_url(url) for url in urls]
return await asyncio.gather(*tasks, return_exceptions=True)
async def crawl_url(self, url):
async with self.semaphore:
try:
async with self.session.get(url) as response:
content = await response.text()
return {'url': url, 'content': content, 'status': response.status}
except Exception as e:
return {'url': url, 'error': str(e)}
专业提示:对于 Worker,重要的是不要什么都用大锤。你应该对静态 HTML 使用轻量级 HTTP Worker,对 JavaScript 渲染的页面使用重型 Puppeteer Worker。不同的工具,不同的 Worker 池。通过我们全面的代理选择指南,你可以轻松为你的 Worker 团队选择合适的代理类型。
存储层(仓库)
存储层是保存抓取数据和元数据的地方,通常由两部分组成:
- 内容存储可处理大量原始 HTML、JSON 响应、图像和 PDF。将其视为数字仓库。S3、Google 云存储或 HDFS 等对象存储在这方面表现出色,因为它们可以无限扩展,处理来自多个工作站的并发写入而不会出错。
- 元数据存储保存您提取的结构化黄金–解析字段、实体关系、抓取时间戳和成功/失败状态。这些数据将被纳入数据库,并针对查询和更新进行优化,而不仅仅是存储容量。
分布式爬虫需要能处理大量并发写入而不窒息的存储。像 S3 或 Google Cloud Storage 这样的对象存储擅长处理原始内容,因为它们可以无限扩展,而 NoSQL 数据库(MongoDB、Cassandra)或 SQL 则能有效处理结构化元数据。
监控和警报
运行分布式爬虫需要了解系统的性能。您可以使用 Prometheus 和 Grafana 创建全面的监控仪表板,跟踪抓取率、成功率、响应时间和队列深度。关键指标包括按域划分的每秒请求数、第 95 百分位响应时间和队列大小趋势。
反僵尸和规避层
规模化的网页抓取意味着需要持续不断地与各类反爬虫系统展开“猫鼠游戏”。为此,您需要搭建三重防护机制:在数以千计的住宅型和数据中心型代理间进行 IP 轮换、对用户代理和浏览器特征指纹随机化,以及模仿真实用户行为模式以规避被检测模式。
Bright Data Web Unlocker 为企业级应用提供卓越的反检测能力,成功率高达 99% 以上。这一成绩通过自动化验证码求解、IP 轮换以及浏览器指纹混淆实现。其基于 API 的集成方式简化了操作过程,有效处理复杂的反爬虫挑战。
class BrightDataWebUnlocker:
def crawl_url(self, url: str, options: Dict = None) -> Dict:
payload = {
"url": url,
"zone": self.zone,
"format": "raw",
"country": "US",
"render_js": True,
"wait_for_selector": ".content"
}
response = requests.post(
self.base_url,
headers={"Authorization": f"Bearer {self.api_key}"},
json=payload,
timeout=60
)
先进的代理轮换功能可跨住宅、数据中心和移动代理池实施健康检查、地理优化和故障恢复。成功的代理管理需要 1000 多个具有智能轮换算法的 IP。
避免指纹识别会随机化用户代理、浏览器指纹和网络特征,以防止被复杂的反僵尸系统检测到。这包括 TLS 指纹旋转、canvas 指纹欺骗和行为模式模拟。
带代码示例的真实世界使用案例
让我们来探讨分布式爬虫的两种常见用例,并概述如何通过代码片段来实现它们。为简单起见,我们将在示例中使用 Python 和 Celery,但其原理普遍适用。
使用案例 1:电子商务价格监控
想象一下,您每天要对 50,000 个产品页面上的竞争对手价格进行跟踪。如果您尝试用一台机器来访问所有这些 URL,那么在不出错的前提下,您将需要花费 12 个多小时来爬行。此外,大多数电子商务网站会在同一 IP 发出几千次快速请求后开始阻止您。
这就是分布式抓取的优势所在。你可以将这 50,000 个 URL 分散到几十个工人手中,每个工人使用不同的 IP 地址,而不是一台不堪重负的机器。过去需要半天时间的工作现在只需 2-3 个小时就能完成,而且不会被反僵尸系统发现。
设置简单明了。您需要维护竞争对手的 URL 列表(从网站地图或搜索抓取中获取),然后使用 Celery 和 Redis 等工具来分配工作。每天早上,您将所有 50,000 个 URL 排成队列,然后您的工人大军开始工作。工人 1 负责耐克的跑鞋,工人 2 负责阿迪达斯的运动鞋,工人 3 负责彪马的定价。所有工作同时进行,且来自不同的 IP。
from celery import Celery
import requests
from bs4 import BeautifulSoup
import random
import time
import re
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
# Initialize Celery app with Redis as broker
app = Celery('price_monitor', broker='redis://localhost:6379/0')
# Realistic user agents for rotation
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15"
]
# Proxy pool (replace with your actual proxy service)
PROXY_POOL = [
"<http://proxy1:8080>",
"<http://proxy2:8080>",
"<http://proxy3:8080>",
# Add your proxy endpoints here
]
def get_session_with_retries():
"""Create a session with retry strategy and random proxy."""
session = requests.Session()
# Retry strategy for resilience
retry_strategy = Retry(
total=3,
backoff_factor=1,
status_forcelist=[429, 500, 502, 503, 504],
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("http://", adapter)
session.mount("https://", adapter)
# Random proxy rotation
if PROXY_POOL:
proxy = random.choice(PROXY_POOL)
session.proxies = {"http": proxy, "https": proxy}
return session
@app.task(bind=True, max_retries=3)
def fetch_product_price(self, url, site_config=None):
"""Fetches product price with full anti-detection measures."""
# Human-like delay before starting
time.sleep(random.uniform(2, 8))
# Randomized headers to avoid fingerprinting
headers = {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Cache-Control": "max-age=0"
}
try:
session = get_session_with_retries()
resp = session.get(url, headers=headers, timeout=30)
resp.raise_for_status()
# Parse the page for price
soup = BeautifulSoup(resp.text, 'html.parser')
price_value = extract_price(soup, url, site_config)
if price_value:
# Store in database (implement your storage logic here)
store_price_data(url, price_value, resp.status_code)
return {"url": url, "price": price_value, "status": "success"}
else:
return {"url": url, "error": "Price not found", "status": "failed"}
except requests.exceptions.RequestException as e:
print(f"Request failed for {url}: {e}")
# Retry with exponential backoff
if self.request.retries < self.max_retries:
raise self.retry(countdown=60 * (2 ** self.request.retries))
return {"url": url, "error": str(e), "status": "failed"}
def extract_price(soup, url, site_config=None):
"""Extract price using multiple strategies."""
# Site-specific selectors (customize for each competitor)
price_selectors = [
".price", ".product-price", ".current-price", ".sale-price",
"[data-price]", ".price-current", ".price-now", ".offer-price"
]
# Try configured selectors first
if site_config and site_config.get('price_selector'):
price_selectors.insert(0, site_config['price_selector'])
price_text = None
for selector in price_selectors:
price_elem = soup.select_one(selector)
if price_elem:
price_text = price_elem.get_text(strip=True)
break
# Try data attributes as fallback
if not price_text:
price_elem = soup.find(attrs={"data-price": True})
if price_elem:
price_text = price_elem.get("data-price")
if not price_text:
return None
# Clean and parse price
return parse_price(price_text)
def parse_price(price_text):
"""Parse price from various formats."""
# Remove common currency symbols and whitespace
cleaned = re.sub(r'[^\d.,]', '', price_text)
# Handle formats like "1,299.99" or "1299.99"
try:
# Remove commas and convert to float
if ',' in cleaned and '.' in cleaned:
# Format: 1,299.99
price_value = float(cleaned.replace(',', ''))
elif ',' in cleaned:
# Could be European format: 1299,99
if cleaned.count(',') == 1 and len(cleaned.split(',')[1]) == 2:
price_value = float(cleaned.replace(',', '.'))
else:
# Format: 1,299 (no cents)
price_value = float(cleaned.replace(',', ''))
else:
price_value = float(cleaned)
return price_value
except ValueError:
print(f"Could not parse price from: {price_text}")
return None
def store_price_data(url, price, status_code):
"""Store price data in your database."""
# Implement your storage logic here
# Could be PostgreSQL, MongoDB, or any other database
print(f"Storing: {url} -> ${price} (Status: {status_code})")
# Site-specific configurations for better accuracy
SITE_CONFIGS = {
"competitor1.com": {"price_selector": ".price-box .price"},
"competitor2.com": {"price_selector": "[data-testid='price']"},
"competitor3.com": {"price_selector": ".product-price-value"},
}
def get_site_config(url):
"""Get site-specific configuration."""
for domain, config in SITE_CONFIGS.items():
if domain in url:
return config
return None
# Load your 50k product URLs (from database, file, or API)
def load_product_urls():
"""Load URLs from your data source."""
# Replace with your actual data loading logic
urls = [
"<https://competitor1.com/product/123>",
"<https://competitor2.com/product/456>",
# ... 49,998 more URLs
]
return urls
# Main execution: dispatch all crawling tasks
def start_daily_price_monitoring():
"""Start the daily price monitoring job."""
product_urls = load_product_urls()
print(f"Starting crawl for {len(product_urls)} URLs...")
for url in product_urls:
site_config = get_site_config(url)
fetch_product_price.delay(url, site_config)
print("All tasks queued successfully!")
# Run with: python -m celery worker -A price_monitor --loglevel=info
# Start monitoring with: start_daily_price_monitoring()
在上面的增强代码中,fetch_product_price是一个强大的 Celery 任务,专为企业级价格监控而设计。通过为每个 URL 调用delay(url,site_config),我们将任务排入 Redis 队列,100 多个 Worker 可以立即抓取这些任务。这种分布式方法可将单机爬行 12 小时的任务转变为整个工人团队 2-3 小时即可完成的操作。
主要生产考虑因素:
- 代理管理至关重要: 本示例包含了一个 PROXY_POOL,每次请求都会切换 IP,在抓取超过 50,000 个 URL 时尤其重要。如果不采用代理轮换机制,您的操作可能会成为从同一 IP 发起的拒绝服务攻击(DoS),肯定会被目标站点屏蔽。
- 每个域名的限速(rate limiting): 即使采用分布式抓取,一次性从同一竞争对手的网站抓取 50,000 个 URL 也可能引发警报,尤其是这些请求集中在短短数分钟内完成。我们通过类似人工的延迟(
time.sleep(random.uniform(2, 8)))来降低风险,但您还应考虑为特定域名设置独立的限速机制。 - 定期调度与监控: 使用 Celery Beat 实现每日抓取调度,或通过 Airflow 集成实现更复杂的工作流。函数
start_daily_price_monitoring()可由 cron 任务或其他调度工具平台触发。 - 数据管道集成: 每次抓取完成后,
store_price_data()函数会将结果保存到数据库中。 - 失败处理: 此示例代码包含具备指数退避机制的重试逻辑。但您需提前规划应对部分地址抓取失败的问题。如果 5% 的 URL 持续失败,请深入调查这些产品是否已下架、迁移,或者这些特定网站可能设有更强的反爬机制需要采用不同方法应对。
使用案例 2:搜索引擎优化和市场调研
搜索引擎优化和市场研究需要在两个关键流程中抓取数百万个页面:内容分析和搜索引擎监控。您不仅仅是在抓取,而是在建立竞争情报,这需要速度、隐蔽性和精确性。
如果您想跟踪 100 万个竞争对手页面的关键词提及情况,同时每天监控数百个目标关键词的 SERP 排名,那么单台机器将耗时数周,并在数小时内被屏蔽。这就要求采用分布式架构。
为此,分布式网络爬行方法可分为两个流:
- 内容情报:抓取竞争对手网站、新闻媒体和行业博客,跟踪关键词密度、内容差距和市场趋势
- SERP 监控:监控目标关键词的 Google/Bing 排名,跟踪竞争对手的位置和 SERP 功能变化
from celery import Celery
import requests
from bs4 import BeautifulSoup
import redis
import hashlib
import json
import time
import random
import re
from urllib.parse import urljoin, urlparse
from dataclasses import dataclass
from typing import List, Dict, Optional
import logging
# Initialize Celery and Redis
app = Celery('seo_intelligence', broker='redis://localhost:6379/0')
redis_client = redis.Redis(host='localhost', port=6379, db=1)
# Anti-detection configurations
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 Safari/605.1.15"
]
PROXY_POOL = [
"<http://user:[email protected]:8080>",
"<http://user:[email protected]:8080>",
# Add your proxy endpoints
]
@dataclass
class KeywordData:
keyword: str
frequency: int
context: List[str] # Surrounding text snippets
url: str
domain: str
@dataclass
class SERPResult:
keyword: str
position: int
title: str
url: str
snippet: str
domain: str
class SEOCrawler:
def __init__(self):
self.session = self._create_session()
def _create_session(self):
session = requests.Session()
if PROXY_POOL:
proxy = random.choice(PROXY_POOL)
session.proxies = {"http": proxy, "https": proxy}
return session
def _get_headers(self):
return {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Cache-Control": "max-age=0"
}
# Deduplication utilities
def get_url_hash(url: str) -> str:
"""Generate consistent hash for URL deduplication."""
return hashlib.md5(url.encode()).hexdigest()
def is_url_processed(url: str) -> bool:
"""Check if URL was already processed today."""
url_hash = get_url_hash(url)
today = time.strftime("%Y-%m-%d")
return redis_client.exists(f"processed:{today}:{url_hash}")
def mark_url_processed(url: str):
"""Mark URL as processed with 24h expiry."""
url_hash = get_url_hash(url)
today = time.strftime("%Y-%m-%d")
redis_client.setex(f"processed:{today}:{url_hash}", 86400, 1)
# Stream 1: Content Intelligence Crawling
@app.task(bind=True, max_retries=3)
def crawl_content_for_keywords(self, url: str, target_keywords: List[str]):
"""Crawl a page and extract keyword intelligence."""
# Skip if already processed today
if is_url_processed(url):
return {"status": "skipped", "reason": "already_processed", "url": url}
# Human-like delay
time.sleep(random.uniform(3, 7))
try:
crawler = SEOCrawler()
response = crawler.session.get(
url,
headers=crawler._get_headers(),
timeout=30
)
response.raise_for_status()
# Extract content and analyze keywords
soup = BeautifulSoup(response.text, 'html.parser')
content_data = extract_keyword_intelligence(soup, url, target_keywords)
# Store results
store_keyword_data(content_data)
mark_url_processed(url)
return {
"status": "success",
"url": url,
"keywords_found": len(content_data),
"total_mentions": sum(kd.frequency for kd in content_data)
}
except Exception as e:
logging.error(f"Content crawl failed for {url}: {e}")
if self.request.retries < self.max_retries:
raise self.retry(countdown=60 * (2 ** self.request.retries))
return {"status": "failed", "url": url, "error": str(e)}
def extract_keyword_intelligence(soup: BeautifulSoup, url: str, keywords: List[str]) -> List[KeywordData]:
"""Extract keyword data from page content."""
# Remove script and style elements
for script in soup(["script", "style", "nav", "footer", "header"]):
script.decompose()
# Get clean text content
text = soup.get_text()
text = re.sub(r'\s+', ' ', text).strip().lower()
domain = urlparse(url).netloc
keyword_data = []
for keyword in keywords:
keyword_lower = keyword.lower()
# Find all occurrences
pattern = r'\b' + re.escape(keyword_lower) + r'\b'
matches = list(re.finditer(pattern, text))
if matches:
# Extract context around each match
contexts = []
for match in matches[:5]: # Limit to first 5 for performance
start = max(0, match.start() - 100)
end = min(len(text), match.end() + 100)
context = text[start:end].strip()
contexts.append(context)
keyword_data.append(KeywordData(
keyword=keyword,
frequency=len(matches),
context=contexts,
url=url,
domain=domain
))
return keyword_data
# Stream 2: SERP Tracking
@app.task(bind=True, max_retries=3)
def track_serp_rankings(self, keyword: str, search_engine: str = "google"):
"""Track SERP positions for a keyword."""
time.sleep(random.uniform(5, 10)) # Longer delay for search engines
try:
crawler = SEOCrawler()
if search_engine == "google":
search_url = f"<https://www.google.com/search?q={keyword}&num=20>"
else: # Bing
search_url = f"<https://www.bing.com/search?q={keyword}&count=20>"
# Special headers for search engines
headers = crawler._get_headers()
headers.update({
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Referer": "<https://www.google.com/>" if search_engine == "google" else "<https://www.bing.com/>"
})
response = crawler.session.get(search_url, headers=headers, timeout=30)
response.raise_for_status()
# Parse SERP results
soup = BeautifulSoup(response.text, 'html.parser')
serp_data = parse_serp_results(soup, keyword, search_engine)
# Store SERP data
store_serp_data(serp_data)
return {
"status": "success",
"keyword": keyword,
"results_found": len(serp_data),
"search_engine": search_engine
}
except Exception as e:
logging.error(f"SERP tracking failed for '{keyword}': {e}")
if self.request.retries < self.max_retries:
raise self.retry(countdown=120 * (2 ** self.request.retries))
return {"status": "failed", "keyword": keyword, "error": str(e)}
def parse_serp_results(soup: BeautifulSoup, keyword: str, search_engine: str) -> List[SERPResult]:
"""Parse search engine results page."""
results = []
position = 1
if search_engine == "google":
# Google result selectors
result_elements = soup.select('div.g')
for element in result_elements:
title_elem = element.select_one('h3')
link_elem = element.select_one('a[href]')
snippet_elem = element.select_one('.VwiC3b, .s3v9rd')
if title_elem and link_elem:
url = link_elem.get('href', '')
if url.startswith('/url?q='):
url = url.split('/url?q=')[1].split('&')[0]
results.append(SERPResult(
keyword=keyword,
position=position,
title=title_elem.get_text(strip=True),
url=url,
snippet=snippet_elem.get_text(strip=True) if snippet_elem else "",
domain=urlparse(url).netloc if url else ""
))
position += 1
if position > 20: # Limit to top 20
break
else: # Bing
result_elements = soup.select('.b_algo')
for element in result_elements:
title_elem = element.select_one('h2 a')
snippet_elem = element.select_one('.b_caption p')
if title_elem:
url = title_elem.get('href', '')
results.append(SERPResult(
keyword=keyword,
position=position,
title=title_elem.get_text(strip=True),
url=url,
snippet=snippet_elem.get_text(strip=True) if snippet_elem else "",
domain=urlparse(url).netloc if url else ""
))
position += 1
if position > 20:
break
return results
# Data storage functions
def store_keyword_data(keyword_data: List[KeywordData]):
"""Store keyword intelligence in database."""
for kd in keyword_data:
data = {
"keyword": kd.keyword,
"frequency": kd.frequency,
"context": kd.context,
"url": kd.url,
"domain": kd.domain,
"crawled_at": time.time()
}
# Store in your preferred database (PostgreSQL, MongoDB, etc.)
redis_client.lpush(f"keyword_data:{kd.keyword}", json.dumps(data))
print(f"Stored: {kd.keyword} found {kd.frequency} times on {kd.domain}")
def store_serp_data(serp_data: List[SERPResult]):
"""Store SERP tracking data."""
for result in serp_data:
data = {
"keyword": result.keyword,
"position": result.position,
"title": result.title,
"url": result.url,
"snippet": result.snippet,
"domain": result.domain,
"tracked_at": time.time()
}
redis_client.lpush(f"serp_data:{result.keyword}", json.dumps(data))
print(f"SERP: '{result.keyword}' -> #{result.position} {result.domain}")
# Orchestration functions
def start_content_intelligence_crawl(urls: List[str], keywords: List[str]):
"""Launch content crawling across 1M+ URLs."""
print(f"Starting content intelligence crawl for {len(urls)} URLs...")
for url in urls:
crawl_content_for_keywords.delay(url, keywords)
print(f"Queued {len(urls)} content crawling tasks")
def start_serp_tracking(keywords: List[str], search_engines: List[str] = ["google", "bing"]):
"""Launch SERP tracking for target keywords."""
print(f"Starting SERP tracking for {len(keywords)} keywords...")
for keyword in keywords:
for engine in search_engines:
track_serp_rankings.delay(keyword, engine)
print(f"Queued {len(keywords) * len(search_engines)} SERP tracking tasks")
# Example usage
if __name__ == "__main__":
# Target keywords for analysis
target_keywords = [
"artificial intelligence", "machine learning", "data science",
"cloud computing", "cybersecurity", "digital transformation"
]
# URLs to crawl for content intelligence (load from your database)
content_urls = [
"<https://techcrunch.com/ai>",
"<https://venturebeat.com/ai>",
"<https://competitor-blog.com/insights>",
# ... 999,997 more URLs
]
# Keywords to track in SERPs
serp_keywords = [
"best AI tools 2026", "enterprise machine learning",
"data analytics platform", "cloud security solutions"
]
# Launch both crawling streams
start_content_intelligence_crawl(content_urls, target_keywords)
start_serp_tracking(serp_keywords)
主要生产考虑因素:
- 智能重复数据删除:系统使用 24 小时到期的 Redis,避免每天重新抓取相同的内容。对于更深层次的重复数据删除,可考虑使用内容散列技术来检测URL发生变化但内容保持不变的页面。
- 域感知速率限制:SERP 抓取需要格外小心,因为搜索引擎会更积极地进行拦截。我们的示例包括更长的搜索查询延迟(5-10 秒)与内容抓取延迟(3-7 秒)。
- SERP 特征跟踪:解析器可处理谷歌和必应的结果,但您也可以将其扩展到跟踪特色片段、本地包以及影响您的可见性策略的其他 SERP 功能。
- 数据管道集成:将结果存储在您喜欢的数据库中(PostgreSQL 用于关系分析,MongoDB 用于灵活的模式)。
最佳做法
尊重 robots.txt 否则后果自负
在排列 URL 之前先解析 robots.txt,并严格遵守抓取延迟指令。如果忽略这些,你的整个 IP 范围都会被列入黑名单,比你说 “分布式爬虫 “还要快。将 robots.txt 检查直接构建到 URL 边界中,不要让工作节点来负责。
除了符合 robots.txt 合规性要求外,您还应在整个分布式机群中实施全面的检测规避策略。
始终记录 3 AM 调试
当你的爬行在午夜死亡时,你需要元数据:每个请求的 URL、HTTP 状态、延迟、代理 ID、工作者 ID 和时间戳。JSON 结构的日志能让你保持理智。问题不在于是否需要调试生产故障,而在于何时需要。
验证一切,不信任任何事物
分布式网络爬虫的生存需要对提取的数据进行模式验证,因为一个畸形的响应就可能毒害整个数据集。在采集时检查字段类型、必填字段和数据新鲜度。及早捕捉垃圾数据,否则几个月后您就会发现垃圾数据破坏了您的分析。
无情地打击超速债务
分布式系统腐烂得很快。您需要每月安排清理陈旧的 Redis 密钥、失败的任务队列和废弃的工作进程。随着时间的推移,死 URL 会堆积如山,代理池会被阻塞的 IP 污染,工作进程内存泄漏也会加剧。维护工作并不光彩,但它能让爬虫保持健康。爬虫的技术债务会呈指数级增长,因此要在系统崩溃之前解决它。
分布式网页抓取的常见误区与应对方法
在使用分布式网页抓取的时候,有许多容易踩的坑,因此许多工程师更偏向寻找其他替代方案,例如 Bright Data 的数据集。这些容易犯的错误包括:
“单点故障”的误区
将所有逻辑依赖于单一的 Redis 实例或主协调器是一个糟糕的设计。一旦该实例出问题,整个抓取任务都会立即中断。
应对方法: 使用 Redis Cluster 或多个中介实例。应该允许协调器的失效,并设计工人(worker)节点能够优雅地处理中介实例中断并自动重连。
“重试死亡螺旋” 式误区
当失败的 URL 立即重新放回主队列中时,会产生一个无限循环反复访问已经出错的端点,并堵塞整个任务管道。
应对方法: 将失败任务放入单独的重试队列,并采用指数退避机制(exponential backoff)。例如第一次重试等待1分钟,第二次等待5分钟,第三次等待30分钟。如果重试3次仍失败,放入死信队列(dead letter queue)以便人工复核。
“所有工人节点都一模一样”的误区
轮询(Round-robin)式任务分配机制假设每个 worker 都拥有相同的带宽、代理质量及处理能力,但实际情况往往并非如此。
应对方法: 依据 worker 节点的成功率、延迟情况以及吞吐量建立评分系统,将更难的任务分配给性能优异的节点。
“内存泄漏定时炸弹”的误区
不重新启动的 worker 节点容易累积内存泄漏,尤其在处理格式不良的 HTML 文件或处理大型响应数据时。如果任由其发展,分布式抓取的整体性能会不断下降,最终导致节点崩溃。
应对方法: 每处理 1000 个任务或每 4 个小时就重启 worker 节点一次,同时监控内存使用情况,并合理使用熔断机制。
总结
您现在已经掌握了分布式网页抓取扩展到数百万个页面的技术蓝图。如果想进一步加深了解支持分布式系统的相关网页抓取基础知识,请阅读我们完整的网页爬虫概览指南。
架构看起来虽然简单,但一个无情的事实仍然是:90% 的团队在实践中都会失败,往往因为他们严重低估了分布式网页抓取过程中用来避免被检测到的复杂程度。管理数以千计的代理、轮换指纹及处理验证码问题,会严重分散团队的注意力,使团队无法专注于真正有价值的数据提取。
这正是 Bright Data Web Unlocker API 存在的原因。它的出现让您无需花费数月打造容易出问题的代理基础设施,而您的分布式工作节点只需将请求通过 Web Unlocker 支持的成功率高达99%以上的 API 即可。
无需管理代理节点,无需处理指纹轮换,也无需应对 CAPTCHA 验证——直接获得规模化的数据提取稳定性。您的工程团队只需专注于实现业务逻辑,让 Bright Data 帮您应付各类反爬虫系统的追踪对抗。
计算非常简单:自主搭建反检测机制需要耗费数月的工程时间和无尽的日常维护成本,而 Web Unlocker 的成本仅为其一小部分,同时能够提供企业级的可靠性能。不要再重复造轮子了,开始专注挖掘数据价值吧。立即免费获取 Bright Data 账户,将您的分布式网页抓取从维护性的负担转变为竞争优势。



AI 内容创作者
Arindam Majumder 是一名开发者推广专员、YouTube博主和技术作家,专注于将大语言模型 (LLM)、智能体工作流及 AI 内容讲解得简单易懂,拥有超过5000名关注者。




