
当你直接访问互联网时,网站可以轻松地将你的请求追踪到你的 IP 地址。这种暴露可能导致定向广告和在线跟踪,并可能危及你的数字身份。
这就是代理发挥作用的地方。它们充当你的计算机与互联网之间的中介,并帮助你保护数字身份。当你使用代理服务器时,它会代表你使用代理自己的 IP 地址向网站发送请求。
在网页爬虫方面,代理可以帮助你绕过 IP 封禁、避免地理封锁,并保护你的身份。在本文中,你将学习如何在 C# 中为你的所有网页爬虫项目实现代理。
前提条件
在开始本教程之前,请确保你具备以下内容:
- Visual Studio 2022
- .NET 7 或更新版本
- HtmlAgilityPack
本文中的示例使用单独的 .NET 控制台应用程序。要创建你自己的应用程序,可以使用以下指南之一:
要开始,你需要创建两个控制台应用程序, WebScrapApp 和 WebScrapBrightData:
对于网页爬虫,尤其是在处理 HTML 内容时,你需要像 HtmlAgilityPack 这样的特定工具。这个库简化了 HTML 解析和操作,使从网页中提取数据更容易。
在两个项目中(即 WebScrapApp 和 WebScrapBrightData),通过右键单击 NuGet 文件夹,然后单击 Manage NuGet Packages,添加 NuGet 包 HtmlAgilityPack。当弹出窗口出现时,搜索 “HtmlAgilityPack” 并为两个项目安装它:

要运行以下任一项目,你需要在命令提示符中导航到项目目录,并使用 cd pathtoyourproject 然后执行 dotnet run。或者,你可以按 F5 在 Visual Studio 中构建并运行项目。两种方法都会编译并执行你的应用程序,并相应地显示输出。
注意: 如果你没有 Visual Studio 2022,可以使用任何支持 .NET 7 的替代 IDE。只需注意,本指南中的某些步骤可能会有所不同。
如何设置本地代理
在网页抓取方面,你需要做的第一件事是使用代理服务器。本教程使用开源代理 mitmproxy。
首先,导航到 mitmproxy 下载,下载 10.1.6 版本,并为你的操作系统选择正确的版本。如需更多帮助,请查看官方 mitmproxy 安装指南。
安装 mitmproxy 后,打开你的终端并使用以下命令启动 mitmproxy:
mitmproxy你应该会在 shell 或终端中看到一个像这样的窗口:
要测试代理,打开另一个终端或 shell 并运行以下 curl 请求:
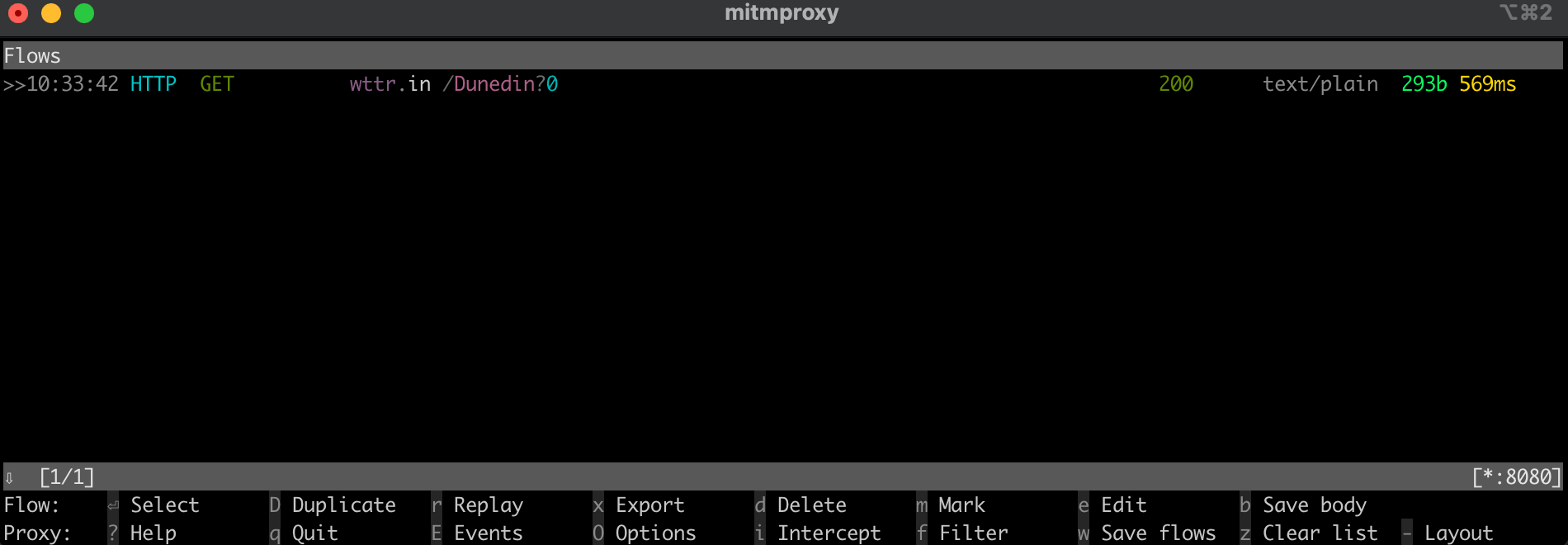
curl --proxy http://localhost:8080 "http://wttr.in/Dunedin?0"你的输出应该如下所示:
Weather report: Dunedin
Cloudy
.--. +11(9) °C
.-( ). ↙ 15 km/h
(___.__)__) 10 km
0.0 mm在 mitmproxy 窗口中,你应该会看到它通过本地代理拦截了该调用:
C# 中的网页爬虫
在以下部分中,你将为网页爬虫设置 C# 控制台应用程序 WebScrapApp。此应用程序利用代理服务器,并包含代理轮换以提高效率。
创建 HttpClient
ProxyHttpClient 类旨在配置一个 HttpClient 实例,以便通过指定的代理服务器路由请求。
在你的 WebScrapApp 项目下,创建一个名为 ProxyHttpClient.cs 的新类文件,并添加以下代码:
namespace WebScrapApp
{
public class ProxyHttpClient
{
public static HttpClient CreateClient(string proxyUrl)
{
var httpClientHandler = new HttpClientHandler()
{
Proxy = new WebProxy(proxyUrl),
UseProxy = true
};
return new HttpClient(httpClientHandler);
}
}
}实现代理轮换
要实现代理轮换,请在你的 WebScrapApp 解决方案下创建一个 ProxyRotator.cs 类文件:
namespace WebScrapApp
{
public class ProxyRotator
{
private List<string> _validProxies = new List<string>();
private readonly Random _random = new();
public ProxyRotator(string[] proxies, bool isLocal)
{
if (isLocal)
{
_validProxies.Add("http://localhost:8080/");
}
else
{
_validProxies = ProxyChecker.GetWorkingProxies(proxies.ToList()).Result;
}
if (_validProxies.Count == 0)
throw new InvalidOperationException();
}
public HttpClient ScrapeDataWithRandomProxy(string url)
{
if (_validProxies.Count == 0)
throw new InvalidOperationException();
var proxyUrl = _validProxies[_random.Next(_validProxies.Count)];
return ProxyHttpClient.CreateClient(proxyUrl);
}
}
}此类管理一个代理列表,提供一种方法为每个网页请求随机选择一个代理。这种随机化是降低网页爬虫期间被检测和潜在 IP 封禁风险的关键。
当 isLocal 设置为 True 时,它会从 mitmproxy 获取本地代理。如果设置为 False,它会获取代理的公共 IP。
ProxyChecker 用于验证代理服务器列表。
接下来,创建一个名为 ProxyChecker.cs 的新类文件,并添加以下代码:
using WebScrapApp;
namespace WebScrapApp
{
public class ProxyChecker
{
private static SemaphoreSlim consoleSemaphore = new SemaphoreSlim(1, 1);
private static int currentProxyNumber = 0;
public static async Task<List<string>> GetWorkingProxies(List<string> proxies)
{
var tasks = new List<Task<Tuple<string, bool>>>();
foreach (var proxyUrl in proxies)
{
tasks.Add(CheckProxy(proxyUrl, proxies.Count));
}
var results = await Task.WhenAll(tasks);
var workingProxies = new List<string>();
foreach (var result in results)
{
if (result.Item2)
{
workingProxies.Add(result.Item1);
}
}
return workingProxies;
}
private static async Task<Tuple<string, bool>> CheckProxy(string proxyUrl, int totalProxies)
{
var client = ProxyHttpClient.CreateClient(proxyUrl);
bool isWorking = await IsProxyWorking(client);
await consoleSemaphore.WaitAsync();
try
{
currentProxyNumber++;
Console.WriteLine($"Proxy: {currentProxyNumber} de {totalProxies}");
}
finally
{
consoleSemaphore.Release();
}
return new Tuple<string, bool>(proxyUrl, isWorking);
}
private static async Task<bool> IsProxyWorking(HttpClient client)
{
try
{
var testUrl = "http://www.google.com";
var response = await client.GetAsync(testUrl);
return response.IsSuccessStatusCode;
}
catch
{
return false;
}
}
}
}此代码定义了用于验证代理服务器列表的 ProxyChecker。当你使用带有代理 URL 列表的 GetWorkingProxies 方法时,它会通过 CheckProxy 方法异步检查每个代理的状态,并在 workingProxies 列表中收集可运行的代理。在 CheckProxy 中,你使用代理 URL 建立一个 HttpClient,向 http://www.google.com 发出测试请求,并使用信号量安全地记录进度。
IsProxyWorking 方法通过检查响应状态码来确认代理的功能,对可运行的代理返回 true。此类有助于从给定列表中识别可用代理。
爬虫网页数据
要爬虫数据,请在你的 WebScrapApp 解决方案下创建一个新的 WebScraper.cs 类文件,并添加以下代码:
using HtmlAgilityPack;
namespace WebScrapApp
{
public class WebScraper
{
public static async Task ScrapeData(ProxyRotator proxyRotator, string url)
{
try
{
var client = proxyRotator.ScrapeDataWithRandomProxy(url);
// Use HttpClient to make an asynchronous GET request
var response = await client.GetAsync(url);
var content = await response.Content.ReadAsStringAsync();
// Load the HTML content into an HtmlDocument
HtmlDocument doc = new();
doc.LoadHtml(content);
// Use XPath to find all <a> tags that are direct children of <li>, <p>, or <td>
var nodes = doc.DocumentNode.SelectNodes("//li/a[@href] | //p/a[@href] | //td/a[@href]");
if (nodes != null)
{
foreach (var node in nodes)
{
string hrefValue = node.GetAttributeValue("href", string.Empty);
string title = node.InnerText; // This gets the text content of the <a> tag, which is usually the title
// Since Wikipedia URLs are relative, we need to convert them to absolute
Uri baseUri = new(url);
Uri fullUri = new(baseUri, hrefValue);
Console.WriteLine($"Title: {title}, Link: {fullUri.AbsoluteUri}");
// You can process each title and link as required
}
}
else
{
Console.WriteLine("No article links found on the page.");
}
// Add additional logic for other data extraction as needed
}
catch (Exception ex)
{
throw ex;
}
}
}
}在此代码中,你定义了 WebScraper,它封装了网页爬虫功能。当你调用 ScrapeData 方法时,你向它提供一个 ProxyRotator 实例和一个目标 URL。在此方法内部,你使用 HttpClient 向该 URL 发出异步 GET 请求,检索 HTML 内容,并使用 HtmlAgilityPack 库解析它。然后你使用 XPath 查询从特定 HTML 元素中定位并提取链接和相应的标题。如果找到任何文章链接,你会打印它们的标题和绝对 URL;否则,你会打印一条消息,说明未找到链接。
在配置代理轮换机制并实现网页爬虫功能后,你需要将这些组件无缝集成到应用程序的主要入口点中,该入口点通常位于 Program.cs 中。这种集成使应用程序能够在使用动态代理的同时执行网页爬虫任务,并特别专注于从 Wikipedia 主页爬虫数据:
namespace WebScrapApp {
public class Program
{
static async Task Main(string[] args)
{
string[] proxies = {
"http://162.223.89.84:80",
"http://203.80.189.33:8080",
"http://94.45.74.60:8080",
"http://162.248.225.8:80",
"http://167.71.5.83:3128"
};
var proxyRotator = new ProxyRotator(proxies, false);
string urlToScrape = "https://www.wikipedia.org/";
await WebScraper.ScrapeData(proxyRotator, urlToScrape);
}
}
}在此代码中,应用程序初始化一个代理 URL 列表,创建一个 ProxyRotator 实例,指定要爬虫的目标 URL(在本例中为 https://www.wikipedia.org/),并调用 WebScraper.ScrapeData 方法来启动网页爬虫过程。
该应用程序使用代理数组中指定的免费代理 IP 列表来路由网页爬虫请求,掩盖可信来源并最大限度降低被 Wikipedia 服务器阻止的风险。ScrapeData 方法被设置为爬虫 Wikipedia 主页,以在控制台中提取并显示文章标题和链接。ProxyRotator 类处理这些代理的轮换,从而增强爬虫的隐蔽性。
运行 WebScrapApp
要运行 WebScrapApp,在你的 WebScrapApp 应用程序根目录下打开一个新的终端或 shell,并运行以下命令:
dotnet build
dotnet run 你的输出应该如下所示:
…output omitted…
Title: Latina, Link: https://la.wikipedia.org/
Title: Latviešu, Link: https://lv.wikipedia.org/
Title: Lietuvių, Link: https://lt.wikipedia.org/
Title: Magyar, Link: https://hu.wikipedia.org/
Title: Македонски, Link: https://mk.wikipedia.org/
Title: Bahasa Melayu, Link: https://ms.wikipedia.org/
Title: Bahaso Minangkabau, Link: https://min.wikipedia.org/
Title: bokmål, Link: https://no.wikipedia.org/
Title: nynorsk, Link: https://nn.wikipedia.org/
Title: Oʻzbekcha / Ўзбекча, Link: https://uz.wikipedia.org/
Title: Қазақша / Qazaqşa / قازاقشا, Link: https://kk.wikipedia.org/
Title: Română, Link: https://ro.wikipedia.org/
Title: Simple English, Link: https://simple.wikipedia.org/
Title: Slovenčina, Link: https://sk.wikipedia.org/
Title: Slovenščina, Link: https://sl.wikipedia.org/
Title: Српски / Srpski, Link: https://sr.wikipedia.org/
Title: Srpskohrvatski / Српскохрватски, Link: https://sh.wikipedia.org/
Title: Suomi, Link: https://fi.wikipedia.org/
Title: தமிழ், Link: https://ta.wikipedia.org/
…output omitted…当调用 WebScraper 类的 ScrapeData 方法时,它会从 Wikipedia 执行数据提取,从而在控制台中显示文章标题及其相应链接。此代码使用公开可用的代理,并且每次运行应用程序时,它都会选择列出的 IP 地址之一作为代理。
要使用来自 mitmproxy 的本地代理进行测试,请使用以下内容更新 Program 文件中的 ProxyRotator 方法:
var proxyRotator = new ProxyRotator(proxies, true)
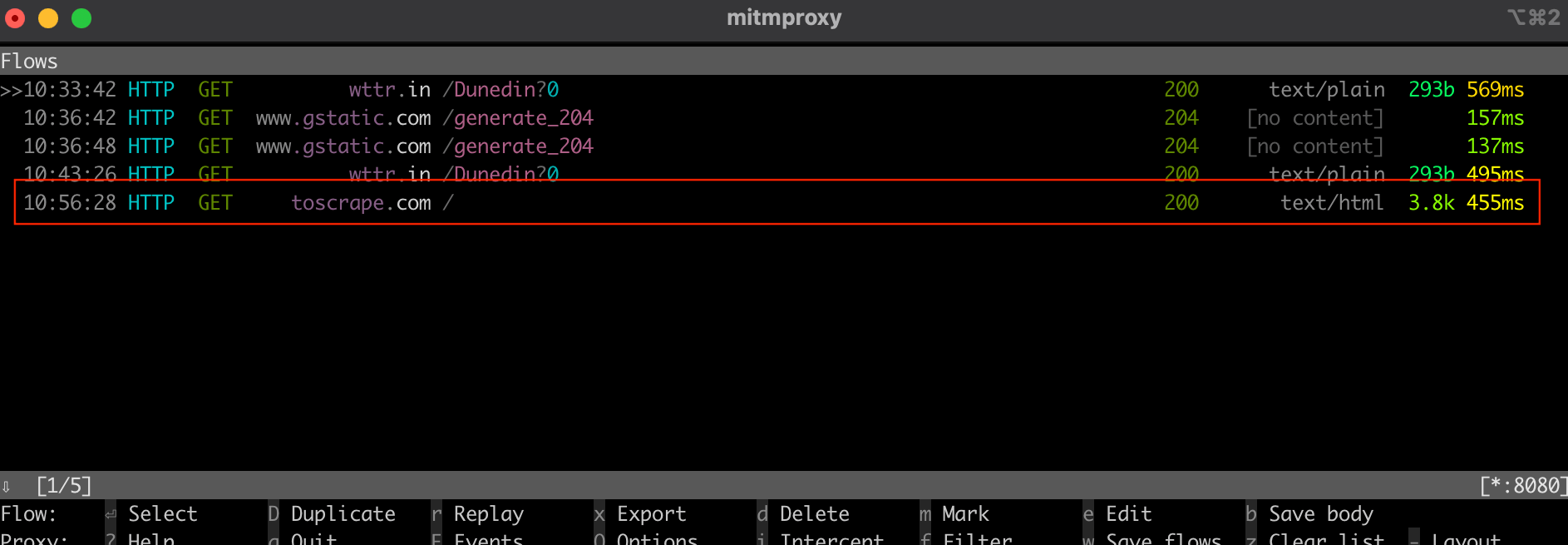
string urlToScrape = "http://toscrape.com/";通过将值设置为 true,它会采用在你的 localhost 端口 8080 上运行的本地代理服务器(即 mitmproxy 服务器)。
为了在你的机器上设置证书时简化配置过程,请将 URL 更改为 http://toscrape.com/。
验证 mitmproxy 服务器正在运行;然后再次运行相同的命令:
dotnet build
dotnet run 你的输出应该如下所示:
…output omitted…
Title: fictional bookstore, Link: http://books.toscrape.com/
Title: books.toscrape.com, Link: http://books.toscrape.com/
Title: A website, Link: http://quotes.toscrape.com/
Title: Default, Link: http://quotes.toscrape.com/
Title: Scroll, Link: http://quotes.toscrape.com/scroll
Title: JavaScript, Link: http://quotes.toscrape.com/js
Title: Delayed, Link: http://quotes.toscrape.com/js-delayed
Title: Tableful, Link: http://quotes.toscrape.com/tableful
Title: Login, Link: http://quotes.toscrape.com/login
Title: ViewState, Link: http://quotes.toscrape.com/search.aspx
Title: Random, Link: http://quotes.toscrape.com/random
…output omitted…如果你从终端或 shell 检查 mitmproxy 窗口,应该会看到它拦截了该调用:
如你所见,设置本地代理或在各种代理之间切换可能是一项复杂且耗时的任务。幸运的是,像 Bright Data 这样的工具可以提供帮助。在以下部分中,你将学习如何使用 Bright Data 代理服务器 来简化爬虫过程。
Bright Data 代理
Bright Data 提供一个 代理服务网络,可在 195 个地点 使用。该网络集成了 Bright Data 代理轮换功能,系统地在服务器之间交替,以增强网页爬虫的有效性和安全性。
使用这种动态代理系统可以降低网页爬虫任务中通常遇到的 IP 封禁或阻止风险。每个请求都使用不同的代理,隐藏爬虫工具的身份,并使网站难以检测和限制访问。这种方法提高了数据收集的可靠性,确保更高的匿名性和安全性。
Bright Data 平台旨在易于使用且设置简单,非常适合 C# 网页爬虫项目,你将在下一部分中看到这一点。
创建住宅代理
在你的项目中使用 Bright Data 代理之前,你需要设置一个账户。为此,请访问 Bright Data 网站 并注册免费试用。
设置好账户后,登录并点击左侧的位置图标,导航到 代理与爬虫基础设施。然后点击 Add 并选择 住宅代理:
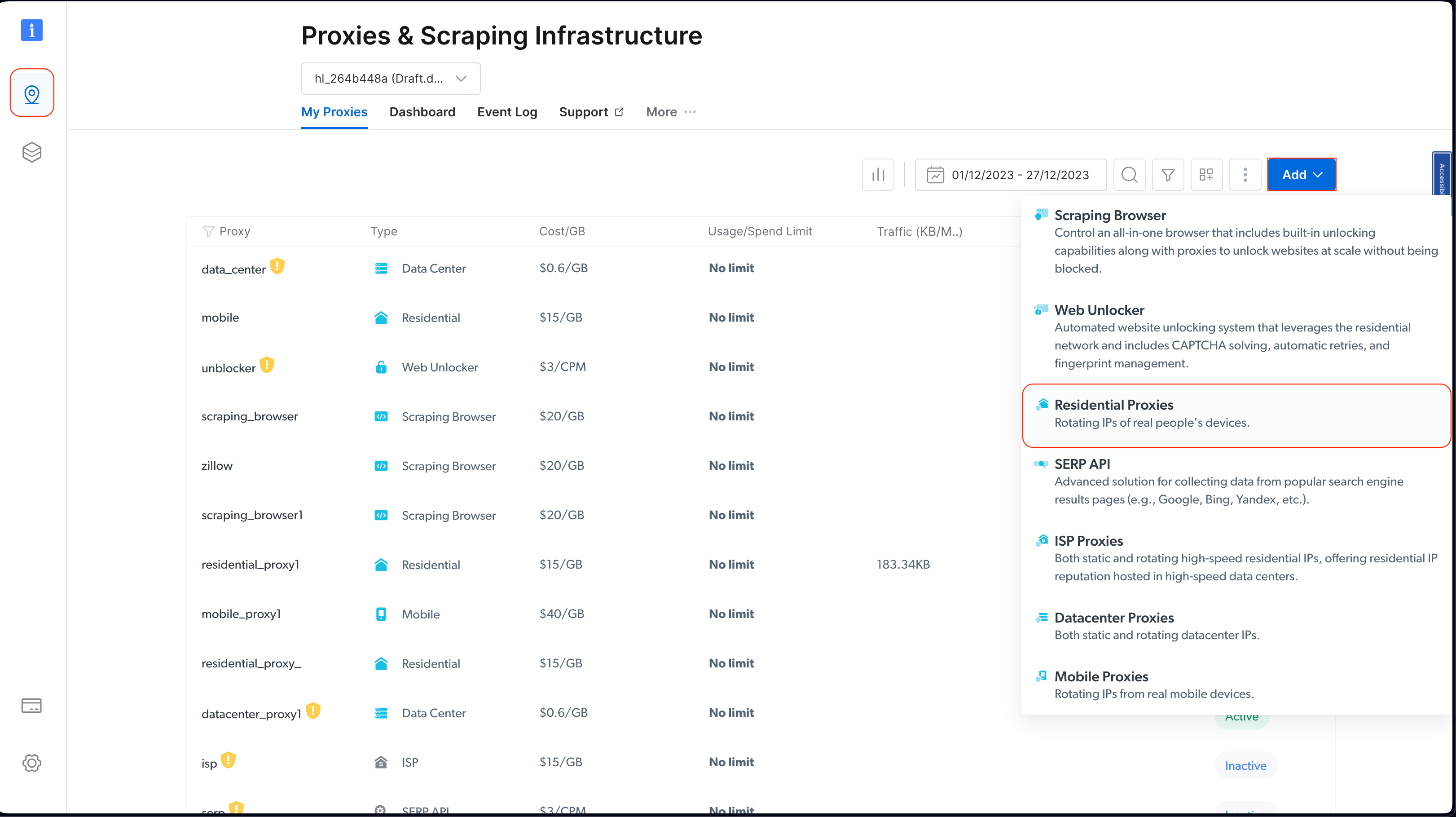
保留默认名称并再次点击 Add 以创建住宅代理:
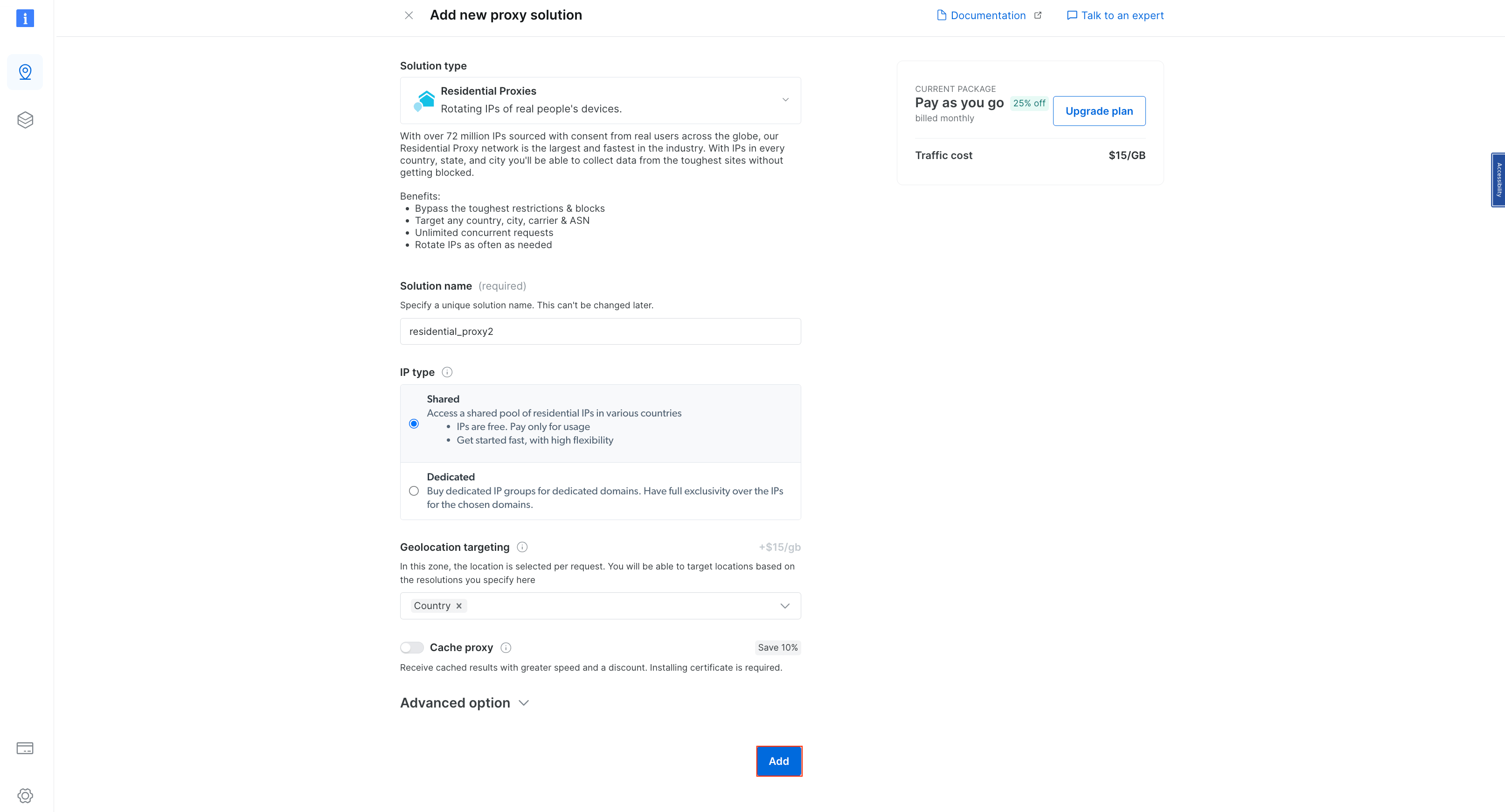
创建代理后,你应该会看到凭据,包括主机、端口、用户名和密码。将这些凭据保存在安全的位置,因为稍后你会需要它们:
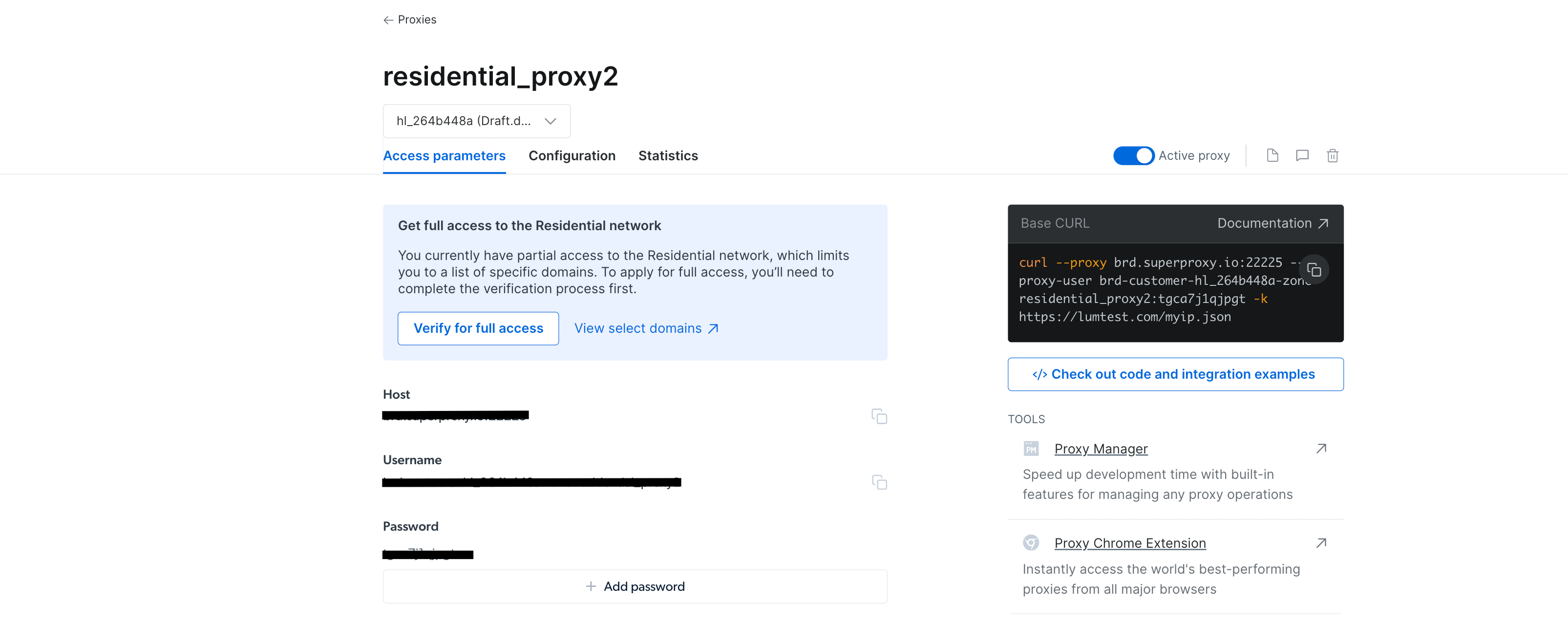
从你的 IDE 或终端/shell 导航到你的 WebScrapingBrightData 项目。然后创建一个 BrightDataProxyConfigurator.cs 类文件,并添加以下代码:
using System.Net;
namespace WebScrapBrightData
{
public class BrightDataProxyConfigurator
{
public static HttpClient ConfigureHttpClient(string proxyHost, string proxyUsername, string proxyPassword)
{
var proxy = new WebProxy(proxyHost) {
Credentials = new NetworkCredential(proxyUsername, proxyPassword)
};
var httpClientHandler = new HttpClientHandler() {
Proxy = proxy,
UseProxy = true
};
var client = new HttpClient(httpClientHandler);
client.DefaultRequestHeaders.Add("User-Agent", "YourUserAgent");
client.DefaultRequestHeaders.Add("Accept", "application/json");
client.DefaultRequestHeaders.TryAddWithoutValidation("Proxy-Authorization", Convert.ToBase64String(System.Text.Encoding.UTF8.GetBytes($"{proxyUsername}:{proxyPassword}")));
return client;
}
}
}在此代码中,你定义了一个 BrightDataProxyConfigurator 类,其中包含 ConfigureHttpClient 方法。调用时,此方法会配置并返回一个设置为使用代理服务器的 HttpClient。你通过使用提供的 username、 password、 host 和 port 创建代理 URL,然后使用此代理配置 HttpClientHandler 来实现这一点。该方法最终返回一个 HttpClient 实例,该实例通过指定代理路由其所有请求。
接下来,在 WebScrapingBrightData 项目下创建 WebContentScraper.cs 类文件,并添加以下代码:
using HtmlAgilityPack;
namespace WebScrapBrightData
{
public class WebContentScraper
{
public static async Task ScrapeContent(string url, HttpClient client)
{
var response = await client.GetAsync(url);
var content = await response.Content.ReadAsStringAsync();
HtmlDocument doc = new();
doc.LoadHtml(content);
var nodes = doc.DocumentNode.SelectNodes("//li/a[@href] | //p/a[@href] | //td/a[@href]");
if (nodes != null)
{
foreach (var node in nodes)
{
string hrefValue = node.GetAttributeValue("href", string.Empty);
string title = node.InnerText;
Uri baseUri = new(url);
Uri fullUri = new(baseUri, hrefValue);
Console.WriteLine($"Title: {title}, Link: {fullUri.AbsoluteUri}");
}
}
else
{
Console.WriteLine("No article links found on the page.");
}
}
}
}此代码定义了一个 WebContentScraper 类,其中包含一个静态异步方法 ScrapeContent。此方法接收一个 URL 和一个 HttpClient,获取网页内容,将其解析为 HTML,并从特定 HTML 元素(列表项、段落和表格单元格)中提取链接。然后它将这些链接的标题和绝对 URI 打印到控制台。
Program 类
现在,再次抓取 Wikipedia,并看看 Bright Data 如何改善访问和匿名性。
使用以下代码更新 Program.cs 类文件:
namespace WebScrapBrightData
{
public class Program
{
public static async Task Main(string[] args)
{
// Bright Data Proxy Configuration
string host = "your_brightdata_proxy_host";
string username = "your_brightdata_proxy_username";
string password = "your_brightdata_proxy_password";
var client = BrightDataProxyConfigurator.ConfigureHttpClient(host, username, password);
// Scrape content from the target URL
string urlToScrape = "https://www.wikipedia.org/";
await WebContentScraper.ScrapeContent(urlToScrape, client);
}
}
}注意: 请确保将 Bright Data 代理凭据替换为你之前保存的凭据。
接下来,要测试并运行你的应用程序,请从你的 WebScrapBrightData 项目根目录打开 shell 或终端,并运行以下命令:
dotnet build
dotnet run你应该会获得与之前使用公共代理时相同的输出:
…output omitted…
Title: Latina, Link: https://la.wikipedia.org/
Title: Latviešu, Link: https://lv.wikipedia.org/
Title: Lietuvių, Link: https://lt.wikipedia.org/
Title: Magyar, Link: https://hu.wikipedia.org/
Title: Македонски, Link: https://mk.wikipedia.org/
Title: Bahasa Melayu, Link: https://ms.wikipedia.org/
Title: Bahaso Minangkabau, Link: https://min.wikipedia.org/
Title: bokmål, Link: https://no.wikipedia.org/
Title: nynorsk, Link: https://nn.wikipedia.org/
Title: Oʻzbekcha / Ўзбекча, Link: https://uz.wikipedia.org/
Title: Қазақша / Qazaqşa / قازاقشا, Link: https://kk.wikipedia.org/
Title: Română, Link: https://ro.wikipedia.org/
Title: Simple English, Link: https://simple.wikipedia.org/
Title: Slovenčina, Link: https://sk.wikipedia.org/
Title: Slovenščina, Link: https://sl.wikipedia.org/
Title: Српски / Srpski, Link: https://sr.wikipedia.org/
Title: Srpskohrvatski / Српскохрватски, Link: https://sh.wikipedia.org/
Title: Suomi, Link: https://fi.wikipedia.org/
Title: தமிழ், Link: https://ta.wikipedia.org/
…output omitted…该程序使用 Bright Data 代理来抓取 Wikipedia 主页,并在控制台中显示提取的标题和链接。这展示了将 Bright Data 代理集成到 C# 网页抓取项目中以进行隐蔽且稳健的数据提取的有效性和简便性。
如果你想可视化使用 Bright Data 代理的效果,可以尝试向 http://lumtest.com/myip.json 发送 GET 请求。该网站会返回当前尝试访问该网站的客户端的位置和其他网络相关详细信息。如果你想自己尝试,请在新的浏览器标签页中打开该链接。你应该会看到你的网络中公开可见的详细信息。
要使用 Bright Data 代理进行尝试,请更新 WebContentScraper.cs 中的代码,使其与以下内容匹配:
using HtmlAgilityPack;
public class WebContentScraper
{
public static async Task ScrapeContent(string url, HttpClient client)
{
var response = await client.GetAsync(url);
var content = await response.Content.ReadAsStringAsync();
HtmlDocument doc = new();
doc.LoadHtml(content);
Console.Write(content);
}
}然后,更新 Program.cs 文件中的 urlToScrape 变量以抓取该网站:
string urlToScrape = "http://lumtest.com/myip.json";现在,尝试再次运行该应用。你应该会在终端中看到类似这样的输出:
{"ip":"79.221.123.68","country":"DE","asn":{"asnum":3320,"org_name":"Deutsche Telekom AG"},"geo":{"city":"Koenigs Wusterhausen","region":"BB","region_name":"Brandenburg","postal_code":"15711","latitude":52.3014,"longitude":13.633,"tz":"Europe/Berlin","lum_city":"koenigswusterhausen","lum_region":"bb"}}这确认了该请求现在正通过 Bright Data 的某个代理服务器进行代理。
结论
在本文中,你学习了如何在 C# 中将代理服务器用于网页抓取。
尽管本地代理服务器在某些场景中可能有用,但它们通常会给网页爬虫项目带来限制。幸运的是,代理服务器 可以提供帮助。凭借其广泛的全球网络和多样化的代理选项,包括 住宅、ISP、数据中心 和 移动代理,Bright Data 保证了高度的灵活性和可靠性。值得注意的是,代理轮换功能对于大规模抓取任务非常宝贵,有助于保持匿名性并降低 IP 封禁风险。
随着你继续进行网页抓取之旅,请考虑使用 Bright Data 解决方案,作为一种强大且可扩展的方式来高效收集数据,同时遵循网页抓取的最佳实践。
本教程的所有代码都可在此 GitHub 存储库 中获得。


我拥有 10 年软件开发经验,专注于后端技术,包括 C#、.NET Core、ASP .NET MVC、SQL Server 和 NoSQL。我是事件驱动和微服务架构方面的专家,并在 AWS 服务方面拥有丰富经验,例如 Lambda、SQS、SNS、DynamoDB、API Gateway 和 RDS。作为所在领域中经过验证的领导者,我始终寻求新的技术挑战和成长机会。



