这份详尽的指南中,我们将讨论
顶级C#网页抓取库
只要使用了正确的工具,网络数据抓取并不难。让我们来看看C#的最佳 NuGet 抓取库有哪些:
- HtmlAgilityPack:是最流行的C#爬虫库:使您能够下载网页、解析其HTML 内容、选择 HTML 元素并从中抓取数据。
HttpClient: 最受欢迎的 C# HTTP 客户端:在网络爬取方面特别有用,因为它允许您轻松地异步执行 HTTP 请求。Selenium WebDriver是一个支持多种编程语言的库,允许您为网页应用程序编写自动化测试,您也可以将其用于网页抓取目的。Puppeteer Sharp是 Puppeteer 的 C# 端口:提供无头浏览器功能并允许抓取动态内容页面。
在本教程中,您将会学到如何使用带有 HtmlAgilityPack和 Selenium 的 C# 执行网页抓取。
使用C#进行网页抓取的先决条件
在编写 C# 网络爬虫的第一行代码之前,您需要满足一些先决条件:
- Visual Studio: 使用2022的免费社区版就可以了。
- .NET 6+:任何大于或等于6的LTS版本都行。
如果你还没有这些工具,请单击上面的链接下载工具并按照安装向导进行设置。
有了这些之后,就可以在Visual Studio 中创建 C#网页抓取项目了。
开始在Visual Studio中设置项目
打开Visual Studio并点击“Create a new project/创建新项目 ”。
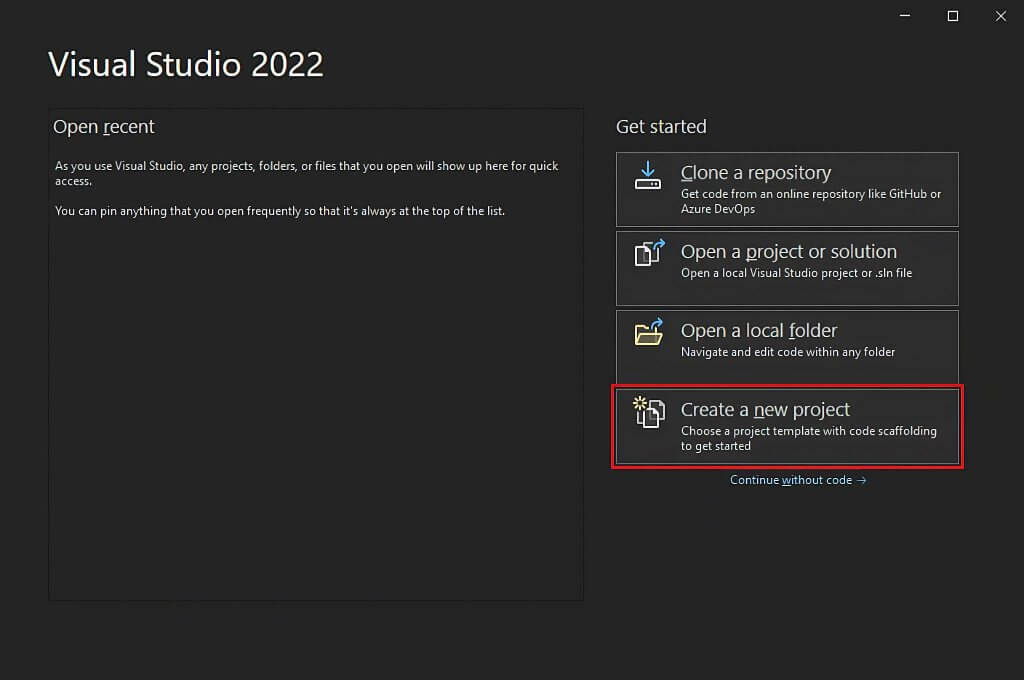
在“创建新项目”窗口中,从下拉列表中选择“C#”选项。 指定编程语言后,选择“Console App”模板,点击“Next/下一步”。
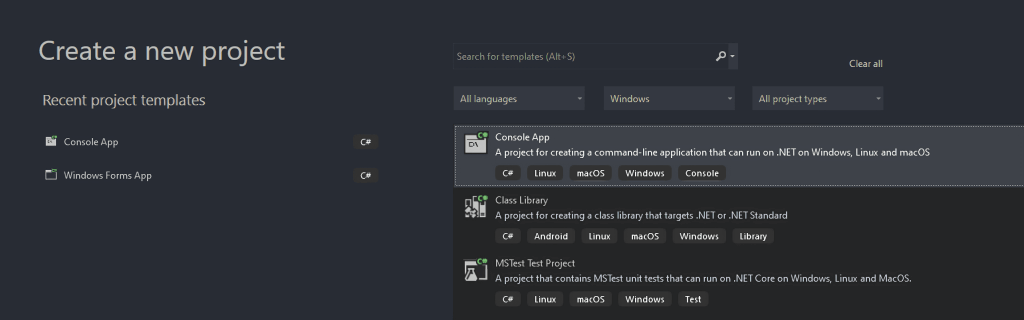
然后,你将你的项目明名为StaticWebScraping,, 单击Select/选择”,再选择NET 版本。 如果您安装了 .NET 6.0,Visual Studio 应该已经为您选择了它。
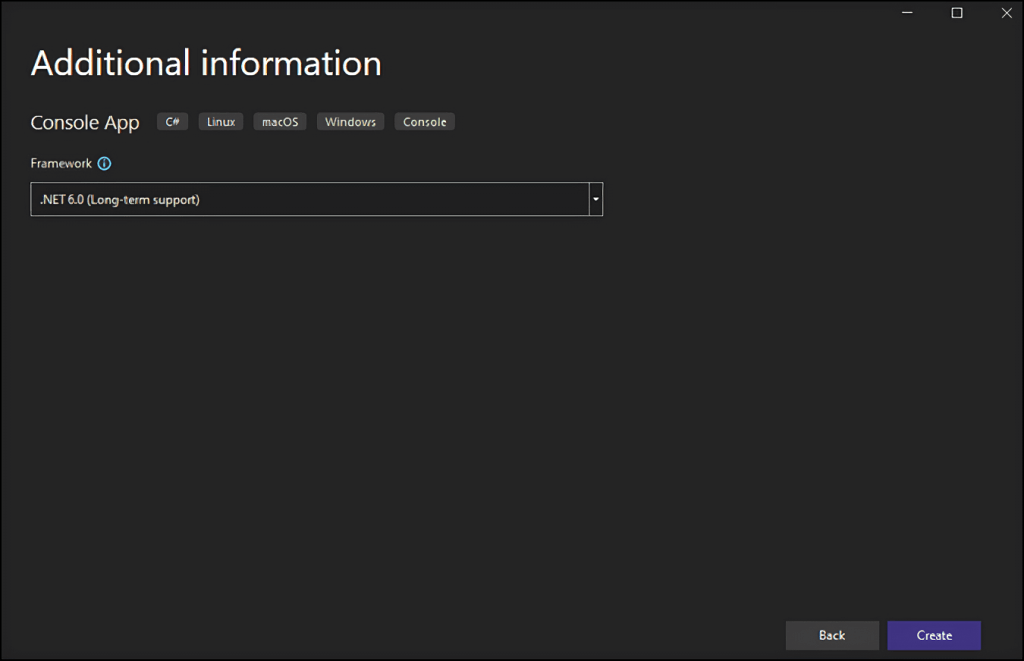
单击“Create/创建”按钮以初始化 C# 网络抓取项目。 Visual Studio 将为您初始化一个包含 App.cs 文件的StaticWebScraping文件夹。 此文件将在 C# 中存储您的网络抓取逻辑:
namespace WebScraping {
public class Program {
public static void Main() {
// scraping logic...
}
}
}
现在可以了解如何在 C# 中构建网络抓取工具了!
在 C# 中抓取静态内容网站
静态内容网站意味着网页的内容已经存储在服务器返回的 HTML 文档中了,静态内容网页不执行XHR 请求来检索数据或需要呈现 JavaScript。
抓取静态网站非常简单,你只需:
- 安装网页抓取 C# 库
- 下载目标网页并解析其 HTML 文档
- 使用网络抓取库选择感兴趣的 HTML元素
- 取数据
让我们在维基百科的“SpongeBob SquarePanta剧集列表” 页面操作以下这些步骤:
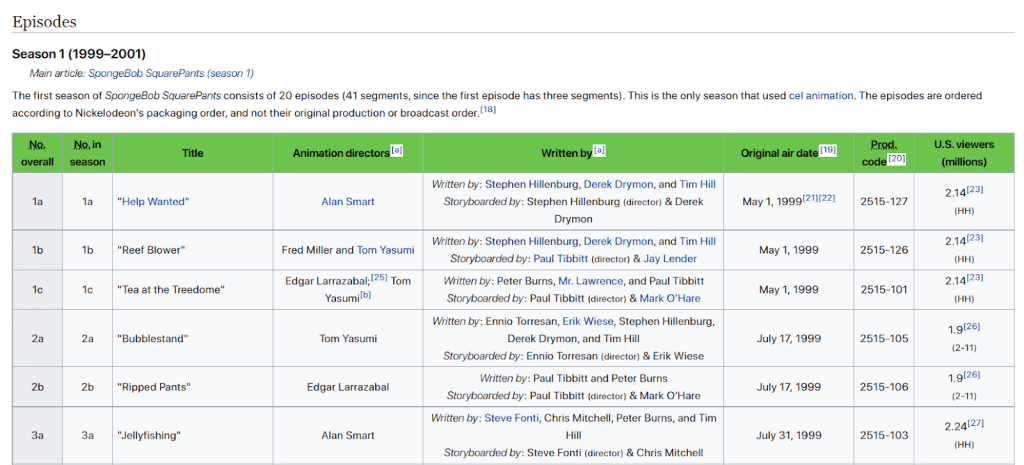
构建的 C# 网络抓取工具的目标是自动从该静态内容维基百科页面检索所有剧集数据。
让我们开始吧!
第 1 步:安装 HtmlAgilityPack
HtmlAgilityPack 是一个开源的C#库,它允许你解析HTML文档,从公DOM中选择元素并提取数据。该工具基本上提供了抓取静态内容网站所需要的一切。
要安装它,请在“Solution Explorer/解决方案资源管理器”中右键单击项目名称下的“Dependencies/依赖项”选项。 然后,选择“Manage NuGet Packages/NuGet 管理包”。 在NuGet 包管理器窗口中,搜索“HtmlAgilityPack”,并单击屏幕右侧的“Install/安装”按钮。
这时,会有弹出窗口将询问您是否同意对您的项目进行更改。 单击“确定”安装 HtmlAgilityPack。 一切就绪,可以使用 C# 在静态网站上执行网页抓取。
在App.cs文件顶部添加以下行以导入 HtmlAgilityPack
using HtmlAgilityPack;第 2 步:加载 HTML 网页
您可以使用 HtmlAgilityPack 连接到目标网页,如下所示:
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
var web = new HtmlWeb();
// downloading to the target page
// and parsing its HTML content
var document = web.Load(url);
HtmlWeb 类的实例允许您通过其 Load() 方法加载网页。 在后台,此方法执行 HTTP GET 请求以检索与作为参数传递的 URL 关联的 HTML 文档。 然后, Load() 返回一个 HtmlAgilityPack的 HtmlDocument 实例,您可以使用它从页面中选择 HTML 元素。
第 3 步:选择 HTML 元素
您可以使用XPath selectors从网页中选择 HTML 元素。详细地说,XPath 允许您选择一个或多个特定的 DOM 元素。要获取与 HTML 元素相关的 XPath 选择器,右键单击它,在浏览器中打开检查工具,确保它选择了感兴趣的 DOM 元素,右键单击 DOM 元素,然后选择“ Copy XPath复制 XPath” 。
该C# 网络抓取工具的目标是提取与每一集相关的数据。 因此,通过将上述过程应用于 <tr> 剧集元素来提取 “XPath selector /XPath 选择器”。
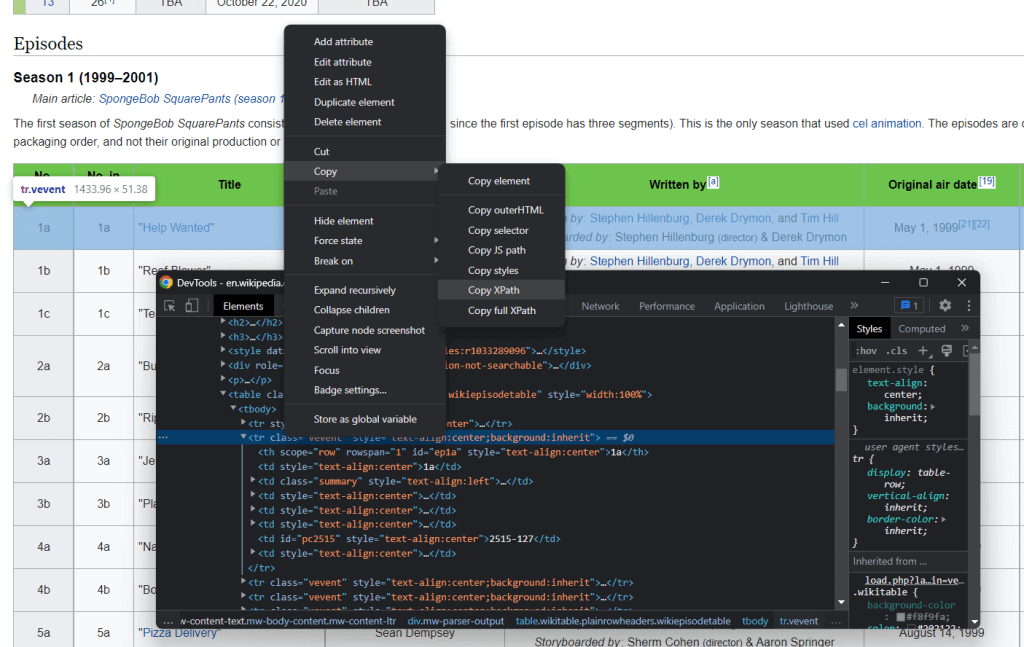
返回:
//*[@id="mw-content-text"]/div[1]/table[2]/tbody/tr[2]
记住,你需要选择所有的 <tr> 元素. 因此,您必须更改与选择行元素关联的索引。 这意味着,您不需要抓取表格的第一行,因为它只包含表格标题。 在 XPath 中,索引从 1 开始,因此您可以通过添加position()>1 语法来选择页面上第一集表的所有 <tr> 元素。
此外,您还需要从该剧的所有季中抓取数据。 在维基百科页面中,包含剧集数据的表格是 HTML 文档中包含的第二个到第十五个 HTML 表格。 所以,这就是最终的 XPath 字符串的样子:
//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]
那么,可以使用 HtmlAgilityPack 提供的 SelectNodes() 来选择感兴趣的 HTML 元素,如下所示:
var nodes = document.DocumentNode.SelectNodes("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]");请注意,您必须在SelectNodes() 实例上调用 SelectNodes() 方法。 因此,您需要使用 DocumentNode 属性获取 HTML 文档的 HTML 根节点。
对了, XPath 选择器只是您从网页中选择 HTML 元素的众多方法之一。 你也可以使用大受欢迎的 CSS selectors。
第 4 步:从 HTML 元素中提取数据
首先,需要一个自定义类来存储抓取的数据。 在 WebScraping 文件夹下创建Episode.cs 文件,初始化如下:
namespace StaticWebScraping {
public class Episode {
public string OverallNumber { get; set; }
public string Title { get; set; }
public string Directors { get; set; }
public string WrittenBy { get; set; }
public string Released { get; set; }
}
}
你可以看到,这个类有四个属性来储存抓取一个聚集所需的重要信息,请注意, OverallNumber 是一个字串符,因为SpongeBob 中的剧集编号始终包含一个字符。
现在你可以按照以下方法来在 App.cs文档中实现网页抓取C#逻辑:
using HtmlAgilityPack;
using System;
using System.Collections.Generic;
namespace StaticWebScraping {
public class Program {
public static void Main() {
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
var web = new HtmlWeb();
// downloading to the target page
// and parsing its HTML content
var document = web.Load(url);
// selecting the HTML nodes of interest
var nodes = document.DocumentNode.SelectNodes("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]");
// initializing the list of objects that will
// store the scraped data
List<Episode> episodes = new List<Episode>();
// looping over the nodes
// and extract data from them
foreach (var node in nodes) {
// add a new Episode instance to
// to the list of scraped data
episodes.Add(new Episode() {
OverallNumber = HtmlEntity.DeEntitize(node.SelectSingleNode("th[1]").InnerText),
Title = HtmlEntity.DeEntitize(node.SelectSingleNode("td[2]").InnerText),
Directors = HtmlEntity.DeEntitize(node.SelectSingleNode("td[3]").InnerText),
WrittenBy = HtmlEntity.DeEntitize(node.SelectSingleNode("td[4]").InnerText),
Released = HtmlEntity.DeEntitize(node.SelectSingleNode("td[5]").InnerText)
});
}
// converting the scraped data to CSV...
// storing this data in a db...
// calling an API with this data...
}
}
}
此 C# 网络抓取器循环选定的 HTML 节点,为每个节点创建 Episode 类的实例,并将其存储在 Episode 列表中。请记住, HTML 节点的重点是表格的行,因此,您需要使用 SelectSingleNode() 方法选择一些元素。 然后,使用 InnerText 属性提取所需的数据以从中抓取。 请注意使用HtmlEntity.DeEntitize() 静态函数将特殊的 HTML 字符替换为自然代表。
第 5 步:将抓取的数据导出为 CSV
现在,你已经了解了如何在C#中进行网页抓取,你可以自由使用你抓取到的数据。我们通常将抓取的数据转换为人类可读的格式,例如 CSV。 这样,团队中的任何人都可以直接在 Excel 中使用抓取的数据了。
如何使用 C# 将抓取的数据导出到 CSV
简单起见,我们使用一个库。CSVHelper 是一个快而易于使用,且功能强大的 .NET 库,用于读取和写入 CSV 文件。 要添加 CSVHelper 依赖项,请在 Visual Studio 中打开“Manage NuGet Packages/管理 NuGet 包”部分,查找“CSVHelper”并安装它。
使用 CSVHelper 将我们抓取的数据转换为 CSV:
using CsvHelper;
using System.IO;
using System.Text;
using System.Globalization;
// scraping logic…
// initializing the CSV file
using (var writer = new StreamWriter("output.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
// populating the CSV file
csv.WriteRecords(episodes);
}
using关键字定义了一个范围,在该范围内的对象将被释放。 换句话说, using 非常适合处理文件资源。 然后,WriteRecords()CSVHelper 函数负责自动将抓取的数据转换为 CSV, 并将其写入 output.csv文件。
一旦您的 C# 语言网络爬虫完成运行,就会看到一个output.csv 文件出现在项目根文件夹中。 用Excel打开,可以看到如下数据:
web-scraping-with-c-sharp
就这么简单!你已经学会了如何使用C#在静态内容网站上执行网页抓取!
使用C#抓取动态网站内容
动态内容网站使用 JavaScript 通过AJAX 技术动态检索数据。 与动态内容页面关联的 HTML 文档基本上可以是空的。 同时,它包含负责在渲染时动态检索和渲染数据的 JavaScript 脚本。 这意味着如果你想从这些网站提取数据,就需要一个浏览器来呈现其页面,因为只有浏览器才能运行 JavaScript。
通常情况下,抓取动态网站可能很棘手,肯定比抓取静态网站更难。这意味着,您需要一个无头浏览器来抓取此类网站的数据。 无头浏览器就是没有 GUI 的浏览器。 换句话说,如果你想用 C# 抓取动态内容网站,就需要一个提供无头浏览器功能的库,比如Selenium.
和文章开头介绍设置新的C#项目一样,建立一个项目,这次我们叫它叫 DynamicWebScraping
第1步:安装Selenium
Selenium 是一个用于自动化测试的开源框架,支持多种编程语言,提供无头浏览器功能,并允许您向网页浏览器发送特定操作指示。
要将 Selenium 添加到项目的依赖项中,请再次转到“Manage NuGet Packages/管理 NuGet 包”部分,搜索“Selenium.WebDriver”并安装它。
通过在 App.cs文件的顶部添加以下两行来导入 Selenium:
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
第2步:连接到目标网站
Selenium会在浏览器中打开目标网站,因此您不必手动执行 HTTP GET 请求。 只需要使用 Selenium Web 驱动程序,如下所示:
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
// to initialize the Chrome Web Driver in headless mode
var chromeOptions = new ChromeOptions();
chromeOptions.AddArguments("headless");
var driver = new ChromeDriver();
// connecting to the target web page
driver.Navigate().GoToUrl(url);
在这里,您创建了一个 Chrome 网络驱动程序实例。 如果您使用的是其它浏览器,请使用正确的浏览器驱动程序并相应地调整代码。 然后,受惠于 driver变量上的 Navigate() 方法,您可以通过调用GoToUrl()方法连接到目标网页。 具体地说,这个函数接受一个 URL 参数,并使用它在无头浏览器中访问与该 URL 关联的网页。
第 3 步:从 HTML 元素中抓取数据
如前所述,您可以使用以下 “XPath selector /XPath选择器”来选择感兴趣的 HTML 元素:
//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]
在 Selenium 中使用 XPath 选择器:
var nodes = driver.FindElements(By.XPath("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]"));
确切地说,Selenium By.XPath() 方法允许您应用 XPath 字符串从页面的 DOM 中选择 HTML 元素。
现在,假设您已经像以前一样在 DynamicWebScraping 命名空间下定义了一个 Episode.cs 类。 之后就可以使用 Selenium 构建一个 C# 网络爬虫,如下所示:
using System;
using System.Collections.Generic;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
namespace DynamicWebScraping {
public class Program {
public static void Main() {
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
// to initialize the Chrome Web Driver in headless mode
var chromeOptions = new ChromeOptions();
chromeOptions.AddArguments("headless");
var driver = new ChromeDriver();
// connecting to the target web page
driver.Navigate().GoToUrl(url);
// selecting the HTML nodes of interest
var nodes = driver.FindElements(By.XPath("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]"));
// initializing the list of objects that will
// store the scraped data
List<Episode> episodes = new();
// looping over the nodes
// and extract data from them
foreach (var node in nodes) {
// add a new Episode instance to
// to the list of scraped data
episodes.Add(new Episode() {
OverallNumber = node.FindElement(By.XPath("th[1]")).Text,
Title = node.FindElement(By.XPath("td[2]")).Text,
Directors = node.FindElement(By.XPath("td[3]")).Text,
WrittenBy = node.FindElement(By.XPath("td[4]")).Text,
Released = node.FindElement(By.XPath("td[5]")).Text
});
}
// converting the scraped data to CSV...
// storing this data in a db...
// calling an API with this data...
}
}
}
你可以看到,与使用 HtmlAgilityPack 相比,网络抓取逻辑没有太大变化。 详细地说,得益于 FindElements() 和 FindElement() 方法,您可以实现与以前相同的抓取目标。 真正不同的是 Selenium 在浏览器中执行所有这些操作。
请注意,在动态内容网站上,您可能需要等待数据被检索和呈现,WebDriverWait可以帮助你实现此目的。
恭喜! 您现在学会了如何在动态内容网站上执行C#网络抓取。剩下的只是学习如何处理抓取的数据。
如何处理抓取的数据
- 将其存储在数据库中,以便在需要时查询。
- 将其转换为 JSON 并使用它来调用一些 API。
- 将其转换为方便可用的格式,例如 CSV,以便使用 Excel 打开它。
这些只是几个例子。 真正重要的是,一旦你在代码中有了抓取的数据,便可以随心所欲地使用它。 通常情况下,抓取的数据会转换为对您的营销、数据分析或销售团队更有用的格式。
不过,网络数据抓取总会面临各种挑战!
使用代理网络抓取数据是的隐私问题
如果您想避免暴露您的 IP,或避免被屏蔽,并保护您的身份,请考虑采用 网页抓取代理网络。 代理服务器充当您的应用程序和目标网站服务器之间的网关,有隐藏您的 IP的功能。
因此,代理服务可让您克服 IP 封锁、匿名采集数据并抓取所有国家/地区的内容。 代理有各种类型, 它们都有不同的用例和目的,确保您选择了正确的代理提供商。
让我们来深入了解代理IP网络可以为您的网络抓取带来哪些好处。
避免IP被封禁
当您的网络抓取应用程序试图访问万维网上的网站时,发出请求的 IP 地址是能被查看到的, 这意味着网站可以跟踪并阻止发出过多请求的用户I P。 这就是机器人检测的意义所在。 如果您使用代理IP网络,目标服务器将看到轮换的代理IP,而不是您本人的。 因此,使用代理,我们可以 轻松绕过 IP 禁令。
轮换IP地址
高级代理 通常提供 轮动IP 功能。 这意味着每次您联系代理服务器时,都会从大量 IP 中获得一个新的 IP 地址。 这非常有助于避免反抓取系统跟踪您。
地域限制
许多网站根据请求的IP地址来源更改其信息。 此外,其中一些内容提供给某些地区的用户。抓取这些网站以进行全球市场调查 就会出现问题,因为你无法抓取到正确信息,或可能会抓取到错误的信息。 幸运的是,您可以使用 匿名代理 来选择退出 IP 地址的位置,这是从国际化网站收集有关产品的有价值信息的好方法。
结论
现在,您学习了如何使用 C# 构建网络抓取工具。 如您所见,并不需要太多代码行。 然而,当您的目标网页发生变化时,您将不得不相应地更新抓取工具。 一些网站每天都会更改其结构,您应该尝试使用高级 Web Scraper IDE的原因。亮数据Bright Data 的抓取工具是最先端的,让您可以专注于数据,而不需要一遍又一遍地配置您的抓取工具。


在本教程中,您将学习如何在 C# 中构建一个网络爬虫。具体来说,您将了解如何执行 HTTP 请求以下载您想要抓取的网页,从其 DOM 树中选择 HTML 元素,并从中提取数据。





