HtmlUnit是无头浏览器。借助HtmlUnit,用户可对 HTML 页面进行建模。以编程方式完成建模后,用户可以通过执行诸如完成表单、提交表单和页面间导航等任务来与页面交互。HtmlUnit可用于网页抓取,提取数据以供后续操作;也可创建自动化测试以验证程序是否根据预设创建网页。
使用 HtmlUnit 进行网页抓取
要使用 HtmlUnit 和Gradle进行网页抓取,就需要使用IntelliJ IDEA IDE;当然,您也可以使用其他更青睐的 IDE 或代码编辑器。
IntelliJ 支持与 Gradle 全功能集成,您可以在 JetBrains 网站下载 IntelliJ 。 Gradle 是一种自动化构建工具,支持用户构建和创建应用包。用户也可使用Gradle无缝地添加和管理依赖。最新的 IntelliJ IDEA 版本中默认安装和启用 Gradle 和 Gradle 扩展。
本教程的所有代码都可在此 GitHub 存储库中找到。
创建 Gradle 项目
想在IntelliJ 集成开发环境中创建新的Gradle 项目,从菜单选项中选择文件 > 新建 > 项目,就会打开一个新项目向导。输入项目名称并选择新建位置:
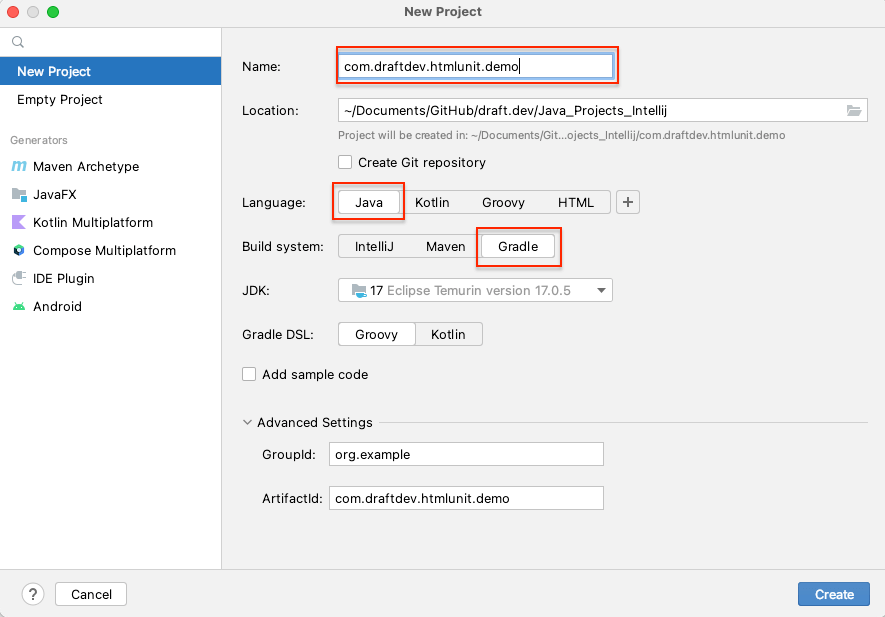
因为要使用 HtmlUnit 在 Java 中创建网页抓取应用程序,所以需要选择Java语言。此外,还需选择Gradle构建系统;然后点击创建。这样就会创建一个具有默认结构和所有必要文件的 Gradle 项目。例如, build.gradle文件包含构建此项目需要的所有依赖项:
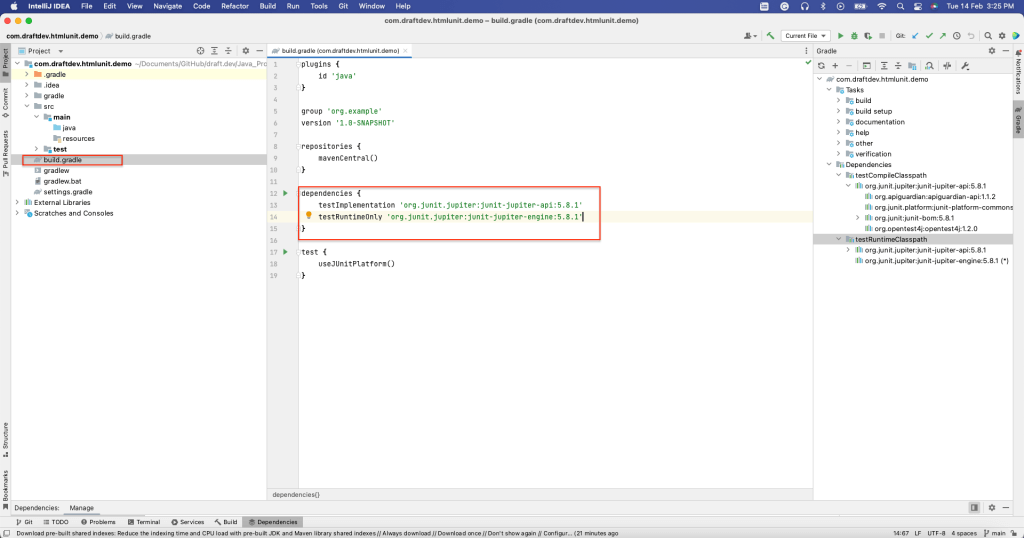
安装 HtmlUnit
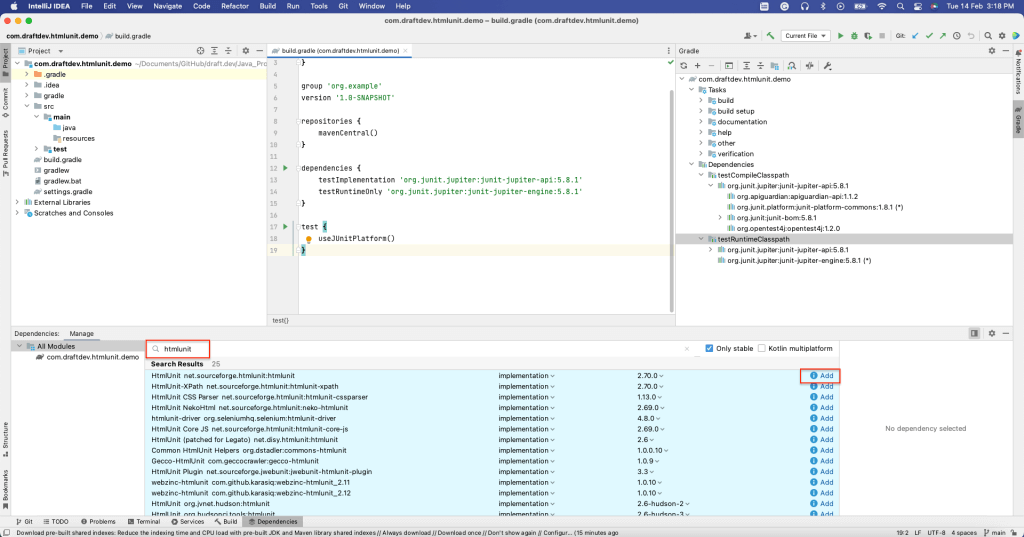
要安装HtmlUnit为依赖项,请选择View > Tool Windows > Dependencies,打开依赖项窗口。
然后搜索“htmlunit”,并选择添加:
您会看到 HtmlUnit 被安装在build.gradle文件的依赖项部分:
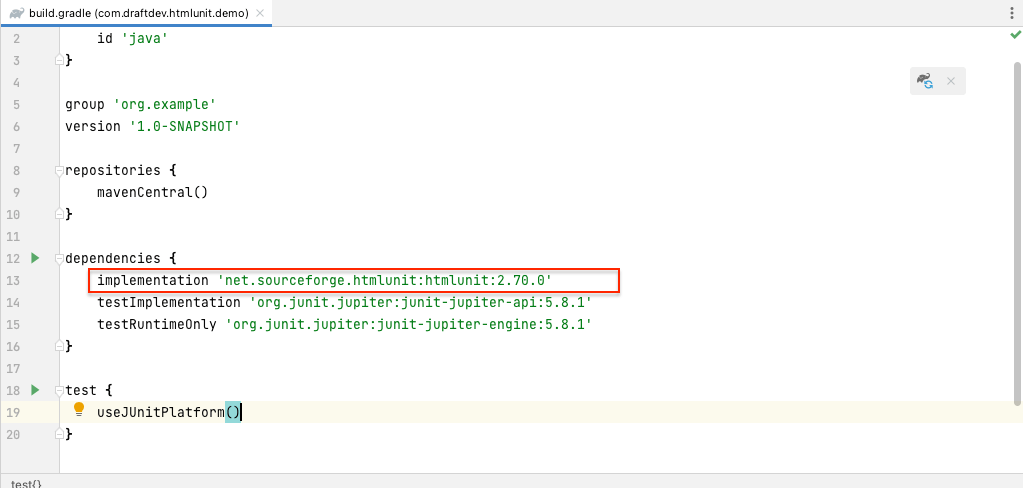
到这一步,您已经成功安装 HtmlUnit,可以从静态和动态网页中抓取数据了。
抓取静态页面
在这个部分,您会知道如何抓取静态网页HtmlUnit Wiki 。该网页包含标题、目录、子标题列表和子标题内容等元素。
HTML 网页中的每个元素都有属性。例如,一个完整的 HTML 文档中,ID属性识别元素具有唯一性, 名称Name属性识别元素不具备唯一性,HTML 文档中的多个元素可以具有相同的名称。用户可以使用任意属性识别网页中的元素。
或者,您也可以使用XPath来识别元素。 XPath 使用类似路径的语法来识别、浏览和查找网页 HTML 中的元素。
在以下示例中,您将使用以上两种方法来识别 HTML 页面中的元素。
进行抓取网页需要用户创建 HtmlUnit WebClient 。 WebClient 代表 Java 应用程序中的浏览器。初始化 WebClient 类似于启动浏览器来查看网页。
如需初始化 WebClient,请使用以下代码:
WebClient webClient = new WebClient(BrowserVersion.CHROME);此代码可用于初始化Chrome谷歌浏览器及其他浏览器。
您可以使用webClient对象中的getPage()方法发送网页请求。获取网页后,可以使用多种方法抓取网页数据。
要获取页面标题,请使用getTitleText()方法,如以下代码所示:
String webPageURl = "https://en.wikipedia.org/wiki/HtmlUnit";
try {
HtmlPage page = webClient.getPage(webPageURl);
System.out.println(page.getTitleText());
} catch (FailingHttpStatusCodeException | IOException e) {
e.printStackTrace();
}页面标题会呈现如下:
HtmlUnit - Wikipedia要更进一步,我们可以获取网页上所有可用的 H2 元素。在这种情况下,H2 在页面的两个部分中可用:
- 在内容显示的左侧边栏: 如您所见,内容部分的标题是一个 H2 元素。
- 在网页正文中:所有的副标题都是H2元素。
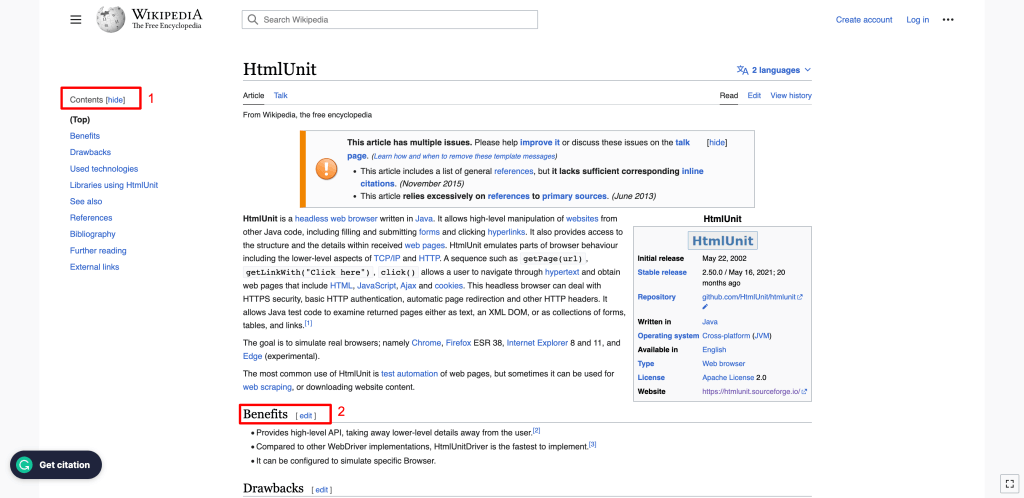
要获取内容正文中的所有 H2,您可以使用 H2 元素的 XPath。您可以右键单击任意 H2 元素并选择Inspect(检查) 查找 XPath。接着右键点击高亮的元素并选择Copy > Copy full XPath :
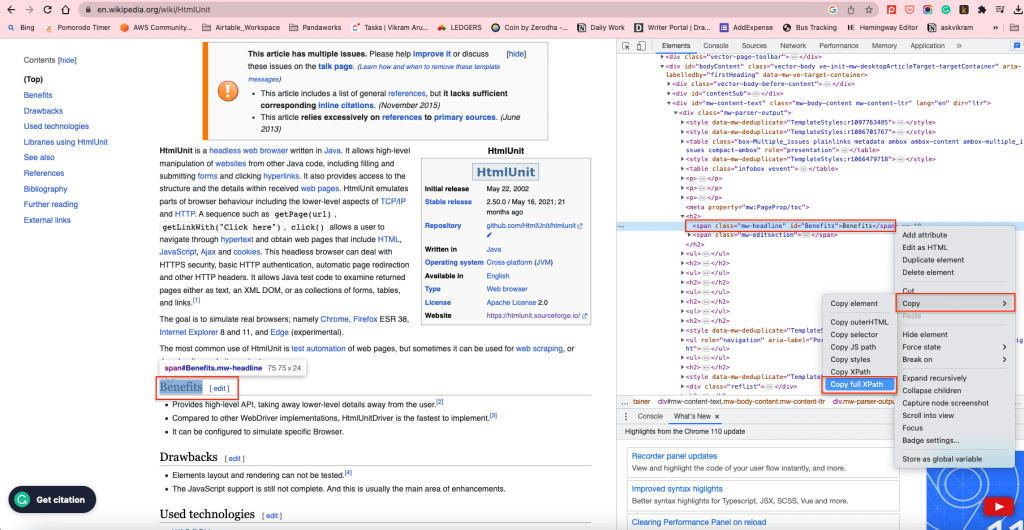
这一步会将 XPath 复制到剪贴板。例如,内容正文中 H2的 XPath 元素是 /html/body/div[1]/div/div[3]/main/div[2]/div[3]/div[1]/h2.
要使用XPath 获取所有 H2 元素,您可以使用 getByXpath() 方法:
String xPath = "/html/body/div[1]/div/div[3]/main/div[2]/div[3]/div[1]/h2";
String webPageURL = "https://en.wikipedia.org/wiki/HtmlUnit";
try {
HtmlPage page = webClient.getPage(webPageURL);
//Get all the headings using its XPath+
List<HtmlHeading2> h2 = (List<HtmlHeading2>)(Object) page.getByXPath(xPath);
//print the first heading text content
System.out.println((h2.get(0)).getTextContent());
} catch (FailingHttpStatusCodeException | IOException e) {
e.printStackTrace();
}第一个H2元素的文本内容将呈现如下:
Benefits[edit]同理,您也可以使用getElementById()方法通过ID 获取元素,也可以使用 getElementByName() 方法通过名称获取元素。
下面,我们将教你使用这些方法来抓取动态网页。
使用 HtmlUnit 抓取动态网页
在这个部分,您将通过填写和提交登录表单来了解 HtmlUnit 的表单填写和按钮点击功能;以及如何使用无头浏览器跳转和浏览网页。
为了更好地演示动态网络抓取,我们使用 Hacker News 网站 。登录页面如下所示:
以下代码是上个页面的HTML表单代码。您可以右键点击Login Label /登录标签并点击Inspect检查来获取此代码:
<form action="login" method="post">
<input type="hidden" name="goto" value="news">
<table border="0">
<tbody>
<tr><td>username:</td><td><input type="text" name="acct" size="20" autocorrect="off" spellcheck="false" autocapitalize="off" autofocus="true"></td></tr>
<tr><td>password:</td><td><input type="password" name="pw" size="20"></td></tr></tbody></table><br>
<input type="submit" value="login"></form>要使用HtmlUnit填写表单,需要使用webClient对象获取网页。该页面包含两种表单:Login and Create Account. 您可以使用 getForms().get(0)方法获取登录表单。如果表单具有唯一名称,您也可以使用 getFormByName() method 获取。
接着需要使用 getInputByName() method 和 name 属性获取表单输入(即用户名和密码字段)。
使用 setValueAttribute() 方法在输入字段中设置用户名和密码值,并使用 getInputByValue() method获取提交按钮。 您也可以使用click() method.
点击按钮后,如果登录成功,会返回 HTMLPage页面对象,即提交按钮的目标页面,可用于进一步的操作。
以下代码演示了如何获取表单、填写表单并提交表单:
HtmlPage page = null;
String webPageURl = "https://en.wikipedia.org/wiki/HtmlUnit";
try {
// Get the first page
HtmlPage signUpPage = webClient.getPage(webPageURL);
// Get the form using its index. 0 returns the first form.
HtmlForm form = signUpPage.getForms().get(0);
//Get the Username and Password field using its name
HtmlTextInput userField = form.getInputByName("acct");
HtmlInput pwField = form.getInputByName("pw");
//Set the User name and Password in the appropriate fields
userField.setValueAttribute("draftdemoacct");
pwField.setValueAttribute("test@12345");
//Get the submit button using its Value
HtmlSubmitInput submitButton = form.getInputByValue("login");
//Click the submit button, and it'll return the target page of the submit button
page = submitButton.click();
} catch (FailingHttpStatusCodeException | IOException e) {
e.printStackTrace();
}以下代码演示了如何获取表单、填写表单并提交表单:
用户名元素的 ID 为 “me”. 您可以按以下代码所示,使用getElementById() method方法获取用户名并传递 ID “me” :
System.out.println(page.getElementById("me").getTextContent());网页用户名会被抓取并显示为输出:
draftdemoacct接下来,您需要单击页面末尾的更多超链接按钮跳转到黑客新闻站点的第二页:

想要获取获取 更多 按钮对象,您可以使用Inspect检查 选项获取更多 按钮的XPath,并使用index 0获取第一个链接对象:
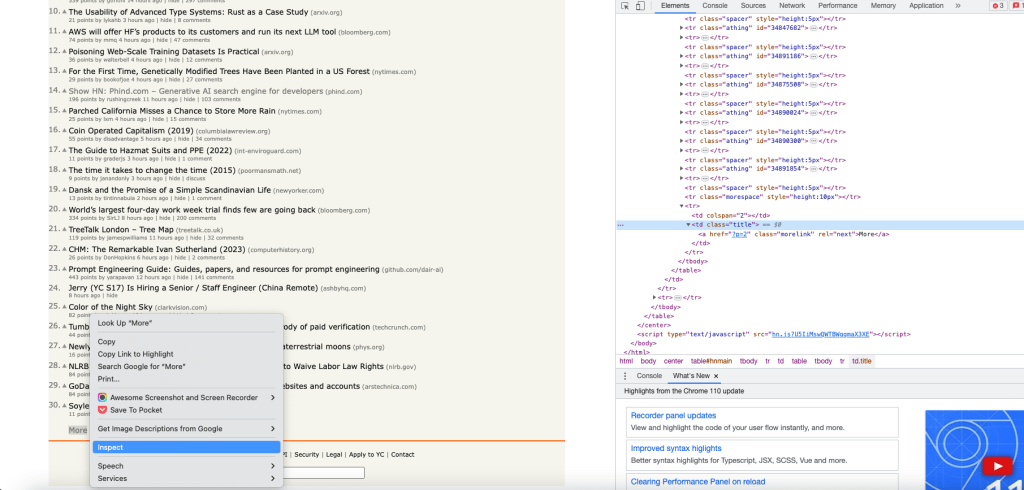
使用 click() method点击更多 link/链接。 link 被点击后,会返回到 HtmlPage对象,即链接的目标页面:
HtmlPage nextPage = null;
try {
List<HtmlAnchor> links = (List<HtmlAnchor>)(Object)page.getByXPath("html/body/center/table/tbody/tr[3]/td/table/tbody/tr[92]/td[2]/a");
HtmlAnchor anchor = links.get(0);
nextPage = anchor.click();
} catch (IOException e) {
throw new RuntimeException(e);
}到这一步,您在 HtmlPage对象中有了第二个页面。
您可以打印 HtmlPage‘s URL以检查是否成功加载第二个页面:
System.out.println(nextPage.getUrl().toString());第二个页面网址如下:
https://news.ycombinator.com/news?p=2黑客新闻站点的每个页面都有 30 个条目。因此第二页的条目以序列号 31 开头。
我们可以检索第二页上第一个条目的 ID,看看它是否等于 31。像前几步一样,使用 Inspect 检查选项获取第一个条目的 XPath。 然后从列表中获取第一个条目并显示其文本内容:
String firstItemId = null;
List<Object> entries = nextPage.getByXPath("/html/body/center/table/tbody/tr[3]/td/table/tbody/tr[1]/td[1]/span");
HtmlSpan span = (HtmlSpan) (entries.get(0));
firstItemId = span.getTextContent();
System.out.println(firstItemId);现在显示第一个条目 ID是:
31.此代码向您展示了如何使用 HtmlUnit 填写表单、点击按钮以及跳转和浏览网页。
结论
通过本篇文章,您了解了如何使用 HtmlUnit 抓取静态和动态网站。您还通过抓取网页并转换为结构化数据了解了 HtmlUnit 的一些高级功能。
使用IntelliJ IDEA等IDE执行此操作时,您需要通过手动检查来找到元素属性,并使用元素属性从头开始编写抓取函数。相比之下, Bright Data 亮数据的Web Scraper IDE提供了强大的网页解锁代理基础架构、灵活实用的抓取功能和热门网站的代码模板。想要摆脱IP屏蔽和速率限制进行网页抓取,需要高效的代理基础架构。代理还能帮助模拟来自不同地域的真实用户。

这个教程教你如何设置一个 Gradle 项目并安装 HtmlUnit 依赖项。在这个过程中,你将学习关于 HtmlUnit 的所有知识,并探索一些它的高级功能。





