

在本指南中,您将了解到
- 什么是零镜头分类及其工作原理
- 使用它的优点和缺点
- 这种做法与网络抓取的相关性
- 在网络抓取场景中实施零镜头分类的分步教程
让我们深入了解一下!
什么是零点射击分类?
零点分类(ZSC)是指预测机器学习模型在训练阶段从未见过的类别的能力。类是模型分配给数据的特定类别或标签。例如,它可以为电子邮件文本指定 “垃圾邮件 “类别,或为图像指定 “猫 “类别。
ZSC 可以归类为迁移学习的一个实例。迁移学习是一种机器学习技术,通过应用从解决一个问题中获得的知识来帮助解决一个不同但相关的问题。
ZSC 的核心思想已在多种类型的神经网络和机器学习模型中探索和实施了一段时间。它可以应用于不同的模式,包括:
- 正文想象一下,您有一个经过训练的模型,可以广泛地理解语言,但您从未向它展示过 “可持续包装产品评论 “的例子。有了 ZSC,您就可以要求它从一堆文本中识别出此类评论。它可以理解您所需类别(标签)的含义,并将其与输入文本进行匹配,而不是依赖于预先学习的每个特定标签的示例。
- 图像:在一组动物图像(如猫、狗、马)上训练出来的模型,可能在训练过程中从未见过斑马,却能将斑马图像分类为 “动物”,甚至是 “有条纹的类马动物”。
- 音频:可以训练一个模型识别 “汽车喇叭声”、”警笛声 “和 “狗叫声 “等常见的城市声音。有了 ZSC,模型就能通过了解声音特性并将其与已知声音联系起来,识别出一种从未经过明确训练的声音,如 “手锤声”。
- 多模态数据:ZSC 可以处理不同类型的数据,例如根据它从未见过的一类数据的文字描述对图像进行分类,反之亦然。
ZSC 如何工作?
由于预训练 LLM 的流行,零镜头分类法越来越受到关注。这些模型是在大量面向人工智能的数据上训练出来的,使它们能够深入理解语言、语义和上下文。
对于 ZSC,预训练的模型通常会在一项名为 NLI(自然语言推理)的任务中进行微调。NLI 包括确定两段文本之间的关系:”前提 “和 “假设”。模型会判断假设是蕴涵(前提为真)、矛盾(前提为假)还是中性(无关)。
在零镜头分类设置中,输入文本是前提。候选类别标签被视为假设。模型会计算 “前提”(输入文本)最有可能包含哪个 “假设”(标签)。蕴涵得分最高的标签被选为分类标签。
使用零镜头分类的优势和局限性
是时候探讨 ZSC 的利弊了。
优势
ZSC 在运行方面具有多种优势,包括
- 对新类别的适应性:ZSC 为将数据分类为未知类别打开了大门。它通过定义新标签来实现这一点,而不需要对模型进行重新训练,也不需要为新类别收集特定的训练示例。
- 减少对标注数据的要求:该方法减少了对目标类大量标注数据集的依赖。这减轻了数据标注–机器学习项目时间和成本的常见瓶颈。
- 高效的分类器实施:可以快速配置和评估新的分类方案。这有助于加快迭代周期,以应对不断变化的需求。
局限性
零镜头分类虽然功能强大,但也有其局限性,例如
- 性能差异:与在固定类别集上广泛训练的监督模型相比,ZSC 驱动的模型可能会表现出较低的准确率。这是因为 ZSC 依赖于语义推理,而不是直接在目标类示例上进行训练。
- 取决于模型质量:ZSC 的性能取决于基础预训练语言模型的质量和能力。一个强大的基础模型通常会带来更好的 ZSC 结果。
- 标签的模糊性和措辞:候选标签的清晰度和独特性会影响准确性。模糊或定义不清的标签会导致性能不理想。
网络抓取中零镜头分类的相关性
网络上不断涌现出新的信息、产品和主题,这就需要有适应性强的数据处理方法。这一切都始于网络扫描–从网页中自动检索数据的过程。
传统的机器学习方法需要手动分类或频繁地重新训练,以处理抓取数据中的新类别,这在大规模使用时效率很低。相反,零点分类法通过实现以下功能来应对网络内容的动态特性所带来的挑战:
- 对异构数据进行动态分类:可使用用户定义的与当前分析目标相关的标签集对从不同来源获取的数据进行实时分类。
- 适应不断变化的信息环境:新的类别或主题可以立即纳入分类模式,而不需要大量的模型重新开发周期。
因此,ZSC 在网络抓取中的典型用例是
- 动态内容分类:在从多个域中抓取新闻文章或产品列表等内容时,ZSC 可自动将项目分配到预定义或新的类别中。
- 针对新主题的情感分析:对于新产品的客户评论或与新兴品牌相关的社交媒体数据,ZSC 可以进行情感分析,而无需特定于该产品或品牌的情感训练数据。这有助于及时进行品牌认知监测和客户反馈评估。
- 识别新兴趋势和主题:通过定义代表潜在新趋势的假设标签,ZSC 可用于分析从论坛、博客或社交媒体中抓取的文本,以识别这些主题的日益流行。
零镜头分类的实际应用
本教程将指导您对从网络上获取的数据进行零点分类。目标网站是 “曲棍球队”:表格、搜索和分页“:
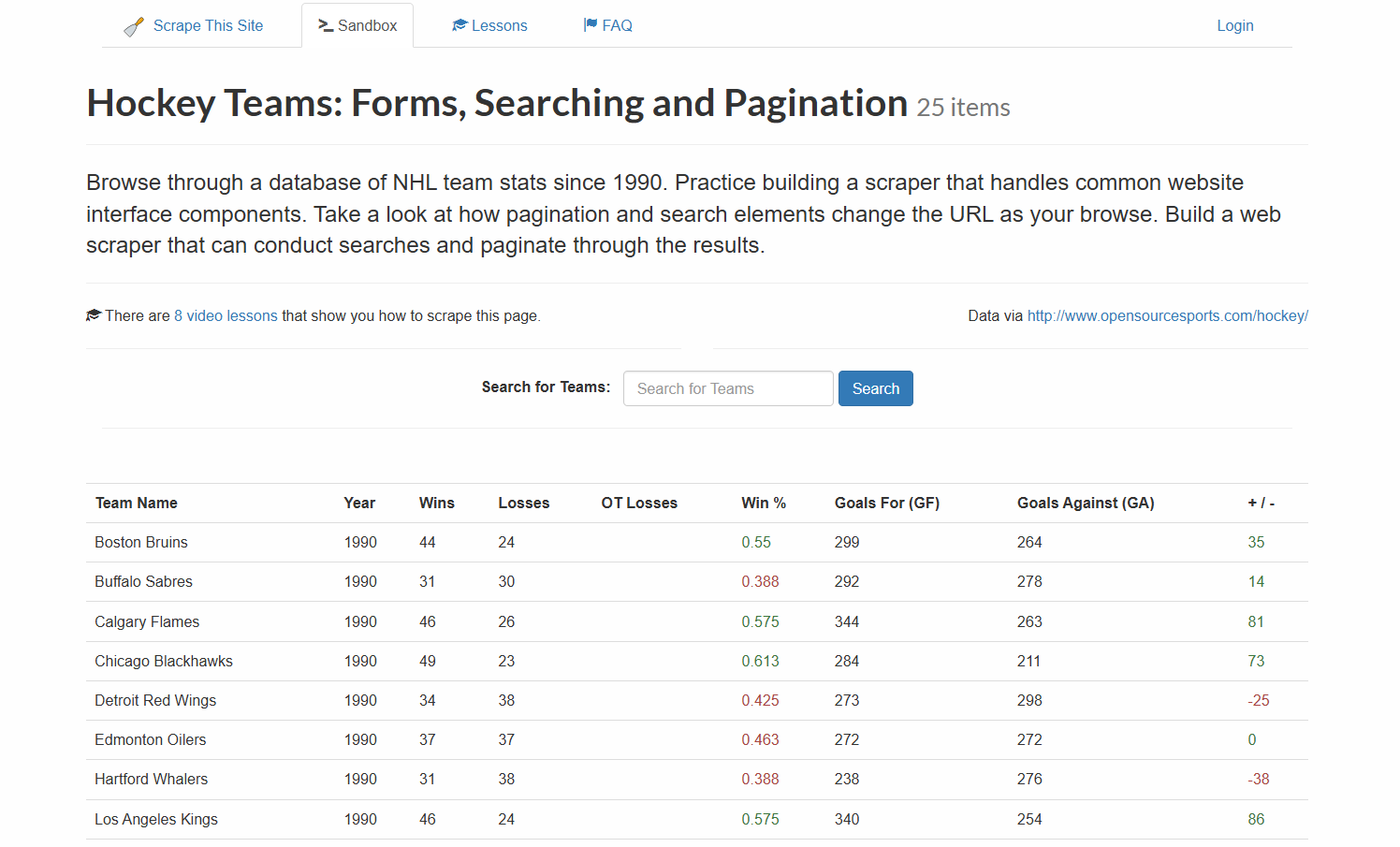
首先,网络抓取器将从上表中提取数据。然后,LLM 将使用 ZSC 对其进行分类。本教程将使用来自 Hugging Face 的DistilBart-MNLI:BART 系列的轻量级 LLM。
请按照以下步骤操作,看看如何实现理想的 ZSC 目标!
先决条件和依赖性
要复制本教程,您的计算机必须安装Python 3.10.1 或更高版本。
假设您将项目的主文件夹命名为zsc_project/。该步骤结束后,文件夹的结构如下:
zsc_project/
├── zsc_scraper.py
└── venv/在哪里?
zsc_scraper.py是包含编码逻辑的 Python 文件。venv/包含虚拟环境。
您可以像这样创建venv/ 虚拟环境目录:
python -m venv venv要激活它,在 Windows 上运行
venvScriptsactivate同样,在 macOS 和 Linux 上,执行
source venv/bin/activate在激活的虚拟环境中,用以下命令安装依赖项:
pip install requests beautifulsoup4 transformers torch这些依赖项是
请求:用于提出 HTTP 网络请求的库。beautifulssoup4: 用于解析 HTML 和 XML 文档并从中提取数据的库。更多信息,请参阅我们的BeautifulSoup 网页搜索指南。transformers:Hugging Face 的一个库,提供数千个预训练模型。火炬PyTorch 是一个开源机器学习框架。
太棒了现在,您已经拥有了从目标网站提取数据和执行 ZSC 所需的一切。
步骤 #1:初始设置和配置
通过导入所需的库和设置一些变量来初始化zsc_scraper.py文件:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from transformers import pipeline
# The starting URL for scraping
BASE_URL = "https://www.scrapethissite.com/pages/forms/"
# Predefined categories for the zero-shot classification
CANDIDATE_LABELS = [
"NHL team season performance summary",
"Player biography and career stats",
"Sports news and game commentary",
"Hockey league rules and regulations",
"Fan discussions and forums",
"Historical sports data record"
]
MAX_PAGES_TO_SCRAPE = 2 # Maximum number of pages to scrape
MAX_TEAMS_PER_PAGE_FOR_ZSC = 2 # Maximum number of teams to process 上述代码的作用如下
- 用
BASE_URL定义要扫描的目标网站。 CANDIDATES_LABELS保存了一个字符串列表,它定义了零点分类模型用来对抓取数据进行分类的类别。该模型将尝试确定这些标签中哪一个能最好地描述每条团队数据。- 定义要抓取的最大页面数和最大团队数据数。
完美!你已经具备了在 Python 中开始零点分类的条件。
步骤 #2:获取页面 URL
首先检查目标页面上的分页元素:
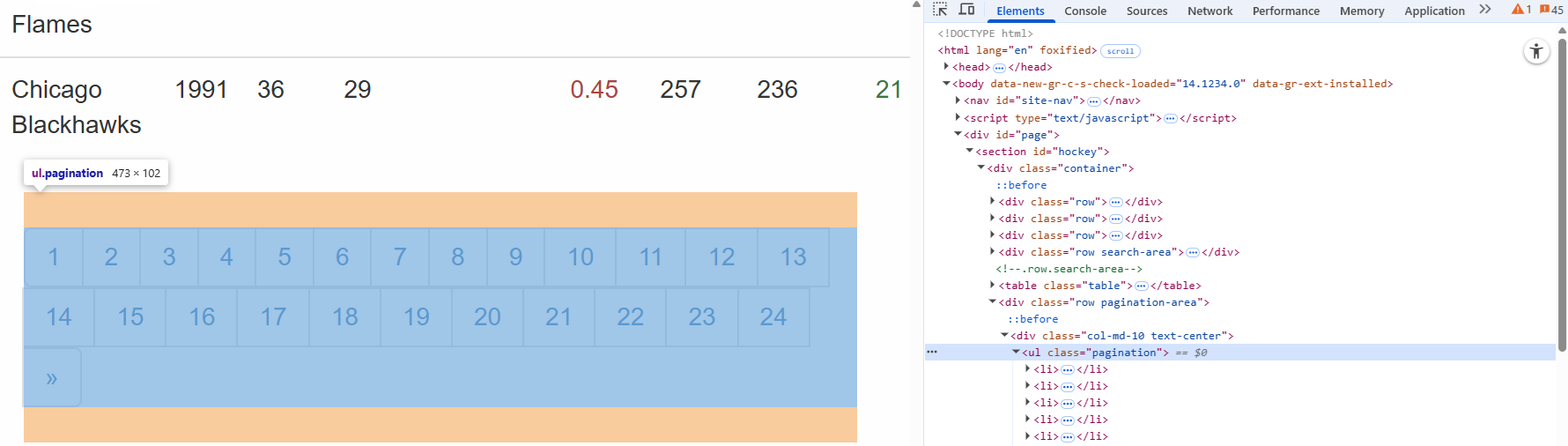
在这里,您可以看到分页 URL 包含在一个.paginationHTML 节点中。
定义一个函数,用于从网站的分页部分查找所有唯一的页面 URL:
def get_all_page_urls(base_url_to_scrape):
page_urls = [base_url_to_scrape] # Initialize with the base URL
response = requests.get(base_url_to_scrape) # Fetch content of base URL
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML content
# Tags for pagination
pagination_links = soup.select("ul.pagination li a")
discovered_urls = set() # Store unique relative URLs to avoid duplicates
for link_tag in pagination_links:
href = link_tag.get("href")
# Ensure the link is a pagination link for this site
if href and href.startswith("?page_num="):
discovered_urls.add(href)
# Sort for consistent order and construct full URLs
for relative_url in sorted(list(discovered_urls)):
full_url = urljoin(base_url_to_scrape, relative_url) # Create absolute URL
# If you want to add paginated URLs, uncomment the next line:
page_urls.append(full_url)
return page_urls此功能:
- 使用
get()方法向目标网站发送 HTTP 请求。 - 使用 BeautifulSoup 中的
select()方法管理分页。 - 使用
for循环遍历每个页面,确保顺序一致。 - 返回所有唯一的整页 URL 列表。
酷!您创建了一个函数来获取网页的 URL,以便从这些 URL 抓取数据。
步骤 #3:搜索数据
首先检查目标页面上的分页元素:

在这里,您可以看到要抓取的球队数据包含在一个.tableHTML 节点中。
创建一个函数,获取单个页面的 URL、内容并提取团队统计数据:
def scrape_page(url):
page_data = [] # List to store data scraped from this page
response = requests.get(url) # Fetch the content of the page
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML
# Select all table rows with class "team" inside a table with class "table"
table_rows = soup.select("table.table tr.team")
for row in table_rows:
# Extract text from each row (name, year, wins, losses)
team_stats = {
"name": row.select_one("td.name").get_text(strip=True),
"year": row.select_one("td.year").get_text(strip=True),
"wins": row.select_one("td.wins").get_text(strip=True),
"losses": row.select_one("td.losses").get_text(strip=True),
}
page_data.append(team_stats) # Add the scraped team data to the list
return page_data此功能:
- 使用
select()方法从表格行中读取数据。 - 使用
for row in table_rows:循环处理每一行。 - 以列表形式返回获取的数据。
干得好!您创建了一个函数,用于从目标网站检索数据。
步骤 #4:协调流程
按以下步骤协调整个工作流程:
- 加载分类模型
- 获取要抓取的页面的 URL
- 从每个页面抓取数据
- 使用 ZSC 对抓取到的文本进行分类
使用以下代码即可实现这一目标:
# Initialize the zero-shot classification pipeline
classifier = pipeline("zero-shot-classification", model="valhalla/distilbart-mnli-12-3")
# Get all URLs to scrape (base URL + paginated URLs)
all_page_urls = get_all_page_urls(BASE_URL)
all_team_data_for_zsc = [] # List to store team data selected for classification
# Loop through the page URLs
for page_url in all_page_urls[:MAX_PAGES_TO_SCRAPE]:
current_page_team_data = scrape_page(page_url) # Scrape data from the current page
# Maximum teams per page to scrape
all_team_data_for_zsc.extend(current_page_team_data[:MAX_TEAMS_PER_PAGE_FOR_ZSC])
# Start classification
print(f"n--- Classifying {len(all_team_data_for_zsc)} Scraped Hockey Team Snippets ---")
# Loop through the collected team data to classify each one
for i, team_info_dict in enumerate(all_team_data_for_zsc):
name = team_info_dict["name"]
year = team_info_dict["year"]
wins = team_info_dict["wins"]
losses = team_info_dict["losses"]
# Construct a text snippet from the team data for classification
text_snippet = f"Team: {name}, Year: {year}, Wins: {wins}, Losses: {losses}."
print(f"nData Snippet {i+1}: "{text_snippet}"")
# Perform zero-shot classification
result = classifier(text_snippet, CANDIDATE_LABELS, multi_label=False)
# Print the predicted category and its confidence score
print(f"Predicted Category: {result['labels'][0]}")
print(f"Confidence Score: {result['scores'][0]:.4f}")此代码
- 使用
pipeline()方法加载预训练模型,并指定其任务为"零镜头分类"。 - 调用之前的功能并执行实际的 ZSC。
完美!你创建了一个函数,可以协调之前的所有步骤,并执行实际的零镜头分类。
步骤 #5:组合并运行代码
下面是zsc_scraper.py文件现在应该包含的内容:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from transformers import pipeline
# The starting URL for scraping
BASE_URL = "https://www.scrapethissite.com/pages/forms/"
# Predefined categories for the zero-shot classification
CANDIDATE_LABELS = [
"NHL team season performance summary",
"Player biography and career stats",
"Sports news and game commentary",
"Hockey league rules and regulations",
"Fan discussions and forums",
"Historical sports data record"
]
MAX_PAGES_TO_SCRAPE = 2 # Maximum number of pages to scrape
MAX_TEAMS_PER_PAGE_FOR_ZSC = 2 # Maximum number of teams to process per page
# Fetch page URLs
def get_all_page_urls(base_url_to_scrape):
page_urls = [base_url_to_scrape] # Initialize with the base URL
response = requests.get(base_url_to_scrape) # Fetch content of base URL
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML content
# Tags for pagination
pagination_links = soup.select("ul.pagination li a")
discovered_urls = set() # Store unique relative URLs to avoid duplicates
for link_tag in pagination_links:
href = link_tag.get("href")
# Ensure the link is a pagination link for this site
if href and href.startswith("?page_num="):
discovered_urls.add(href)
# Sort for consistent order and construct full URLs
for relative_url in sorted(list(discovered_urls)):
full_url = urljoin(base_url_to_scrape, relative_url) # Create absolute URL
# If you want to add paginated URLs, uncomment the next line:
page_urls.append(full_url)
return page_urls
def scrape_page(url):
page_data = [] # List to store data scraped from this page
response = requests.get(url) # Fetch the content of the page
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML
# Select all table rows with class "team" inside a table with class "table"
table_rows = soup.select("table.table tr.team")
for row in table_rows:
# Extract text from each row (name, year, wins, losses)
team_stats = {
"name": row.select_one("td.name").get_text(strip=True),
"year": row.select_one("td.year").get_text(strip=True),
"wins": row.select_one("td.wins").get_text(strip=True),
"losses": row.select_one("td.losses").get_text(strip=True),
}
page_data.append(team_stats) # Add the scraped team data to the list
return page_data
# Initialize the zero-shot classification pipeline
classifier = pipeline("zero-shot-classification", model="valhalla/distilbart-mnli-12-3")
# Get all URLs to scrape (base URL + paginated URLs)
all_page_urls = get_all_page_urls(BASE_URL)
all_team_data_for_zsc = [] # List to store team data selected for classification
# Loop through the page URLs
for page_url in all_page_urls[:MAX_PAGES_TO_SCRAPE]:
current_page_team_data = scrape_page(page_url) # Scrape data from the current page
# Maximum teams per page to scrape
all_team_data_for_zsc.extend(current_page_team_data[:MAX_TEAMS_PER_PAGE_FOR_ZSC])
# Start classification
print(f"n--- Classifying {len(all_team_data_for_zsc)} Scraped Hockey Team Snippets ---")
# Loop through the collected team data to classify each one
for i, team_info_dict in enumerate(all_team_data_for_zsc):
name = team_info_dict["name"]
year = team_info_dict["year"]
wins = team_info_dict["wins"]
losses = team_info_dict["losses"]
# Construct a text snippet from the team data for classification
text_snippet = f"Team: {name}, Year: {year}, Wins: {wins}, Losses: {losses}."
print(f"nData Snippet {i+1}: "{text_snippet}"")
# Perform zero-shot classification
result = classifier(text_snippet, CANDIDATE_LABELS, multi_label=False)
# Print the predicted category and its confidence score
print(f"Predicted Category: {result['labels'][0]}")
print(f"Confidence Score: {result['scores'][0]:.4f}")非常好!您已经完成了第一个 ZSC 项目。
使用以下命令运行代码
python zsc_scraper.py这是预期的结果:
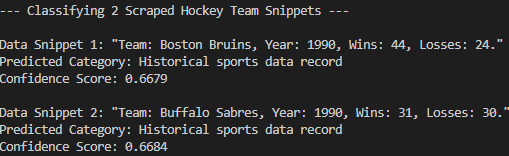
正如您所看到的,该模型已将抓取数据正确分类到 “历史体育数据记录 “中。如果没有零镜头分类,这是不可能实现的。任务完成!
结论
在本文中,您将了解到什么是零镜头分类,以及如何将其应用于网络扫描。网络数据是不断变化的,你不能指望预先训练好的 LLM 事先知道一切。ZSC 无需重新训练即可对新信息进行动态分类,从而弥补了这一差距。
然而,真正的挑战在于如何获取新鲜数据–因为并非所有网站都易于抓取。这正是 Bright Data 的优势所在,它提供了一整套功能强大的工具和服务,旨在克服抓取障碍。这些工具和服务包括
- 网页解锁器:该应用程序接口可绕过反抓取保护,以最小的代价从任何网页中获取干净的 HTML。
- 扫描浏览器:基于云的可控浏览器,具有 JavaScript 渲染功能。它能自动处理验证码、浏览器指纹、重试等。它可与 Panther 或 Selenium PHP 无缝集成。
- Web Scraper API:用于以编程方式访问数十个常用域的结构化网络数据的端点。
如需了解机器学习方案,请访问我们的人工智能中心。
立即注册 Bright Data 并开始免费试用,以测试我们的搜索解决方案!



技术写作者
 3 years experience
3 years experience
Federico Trotta 是一名技术写作者、编辑和数据科学家。擅长技术内容管理、数据分析、机器学习和 Python 开发。




