

学习如何将 Zed 的 AI 原生编辑器连接到 Bright Data 的 Web MCP,在开发环境中直接实现实时网页访问、干净的数据抽取以及具备网页上下文感知能力的 AI 工作流。
在本教程中,你将学到:
- 什么是 Zed,以及它基于 AI、具备 Agent 能力的编辑模型在现代代码编辑器中的工作方式。
- 为什么需要为 Zed 扩展实时网页交互和数据采集能力,以提升 AI 辅助开发的准确性。
- 如何将 Zed 连接到 Bright Data 的 Web MCP,使 AI Agent 能在编辑器内直接获取并使用实时公网数据。
下面开始!
什么是 Zed?
Zed 是一款现代、高性能的代码编辑器,专注于速度、协作和 AI 辅助开发。从底层设计上就强调响应速度和低延迟,目标是在大型代码库中也能让编码体验保持即时、流畅。
Zed 完全使用 Rust 编写,架构上充分利用多核 CPU 和 GPU 加速。这种设计使 Zed 拥有快速启动、流畅的界面交互和极低的输入延迟,这些都是其开发者体验的核心。
Zed 支持在 macOS、Linux 和 Windows 上运行,并在各平台上提供一致的原生体验。
Zed 默认内置了一系列核心开发功能,包括:
- 原生 Git 支持,可进行暂存、提交、拉取、推送以及查看 diff。
- 基于 Debug Adapter Protocol(DAP)的调试支持。
- 对多种编程语言的 Language Server Protocol(LSP)支持。
- 多缓冲区编辑,可在同一视图中组合和编辑来自不同文件的内容。
- 内置协作功能,如共享编辑、聊天和屏幕共享。
- Vim 风格的模式化编辑,适合偏好模式工作流的开发者。
为什么要用 Bright Data Web MCP 为 Zed 增强能力
无论你在 Zed 中使用哪一种 AI 模型,它都有一个关键限制:LLM 本身无法实时访问互联网。其回答基于训练数据,这些数据只是某一时间点的快照,很容易过时。
在处理不断更新的文档、工具或框架时,这个限制尤为明显。编辑器中的 AI 助手无法自行验证最新信息、浏览网站或抽取真实内容。
现在,设想一下如果为 Zed 的 AI Agent 增加如下能力:
- 读取实时在线文档页面
- 拉取最新的指南和参考资料
- 浏览并从真实网站中抽取内容
通过将 Zed 连接到 Bright Data Web MCP,这些能力都可以解锁。Bright Data 的 Web MCP 提供 60+ 个适配 AI 的工具,由 Bright Data 的 AI 基础设施 提供支持,使 AI Agent 能够进行实时网页交互和数据检索。
最常用、并且在免费套餐中也可用的两个工具是:
| 工具 | 描述 |
|---|---|
scrape_as_markdown |
从网页中抽取内容并返回干净的 Markdown,自动处理反爬和 CAPTCHA。 |
search_engine |
从 Google、Bing 或 Yandex 获取搜索结果,支持 JSON 或 Markdown 格式。 |
除了核心工具之外,Web MCP 还包含许多用于浏览器交互和结构化数据抽取的高级选项。免费套餐提供基础工具的访问;启用 Pro 模式后可以解锁完整工具集,以支持更高级的用例。
通过将 Bright Data Web MCP 连接到 Zed,AI Agent 可以使用实时网页内容,而不是静态知识,在编辑器中提供更准确、更可靠的辅助。
如何将 Bright Data Web MCP 集成到 Zed
在本节中,你将:
- 在 Zed 中将 Bright Data Web MCP 配置为 MCP 服务器
- 使用 Bright Data API Token 为 MCP 服务器做身份验证
- 让 Zed 的 AI Agent 通过 MCP 访问实时网页内容
- 验证集成是否正常工作
按照下面的步骤开始操作!
前置条件
在开始之前,请确认你已经具备:
- 受支持的操作系统(macOS、Linux 或 Windows)
- 已安装并可运行的 Zed
- 已安装 Node.js(推荐最新 LTS 版本)
- 一个带 API Token 的Bright Data 账号
你无需提前完成 Bright Data 的复杂配置。所需的设置会在后续章节中一步步讲解。
虽然不是必需,但以下背景知识会有所帮助:
- 对 Model Context Protocol(MCP) 的基本概念
- 对 Bright Data Web MCP 及其可用工具有大致了解
步骤一:安装并启动 Zed
从官网下载安装 Zed,并根据你的操作系统(macOS、Linux 或 Windows)完成安装。
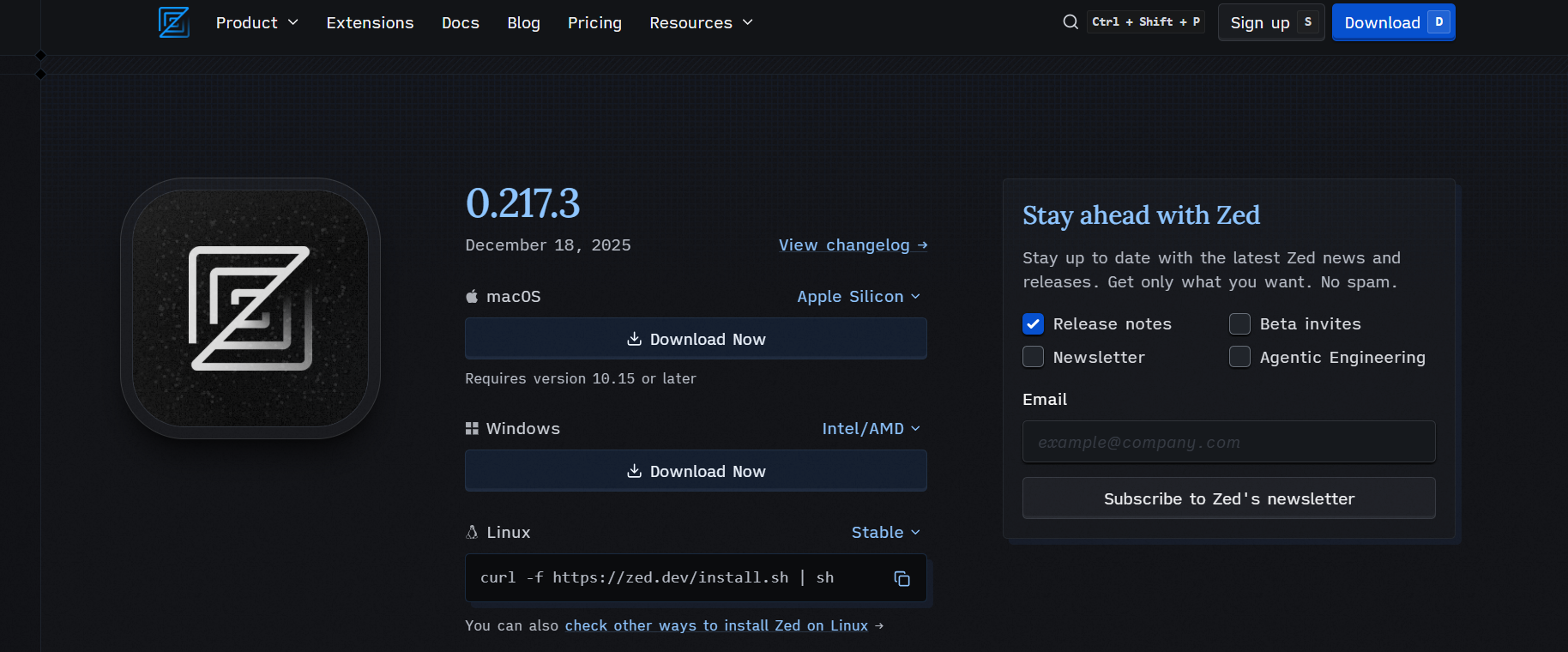
安装完成后,从应用菜单中打开 Zed,确保编辑器能正常启动且无报错。
你应该可以看到主编辑器界面,并能打开 Settings(设置)面板。如果 Zed 能顺利启动,就可以继续下一步。
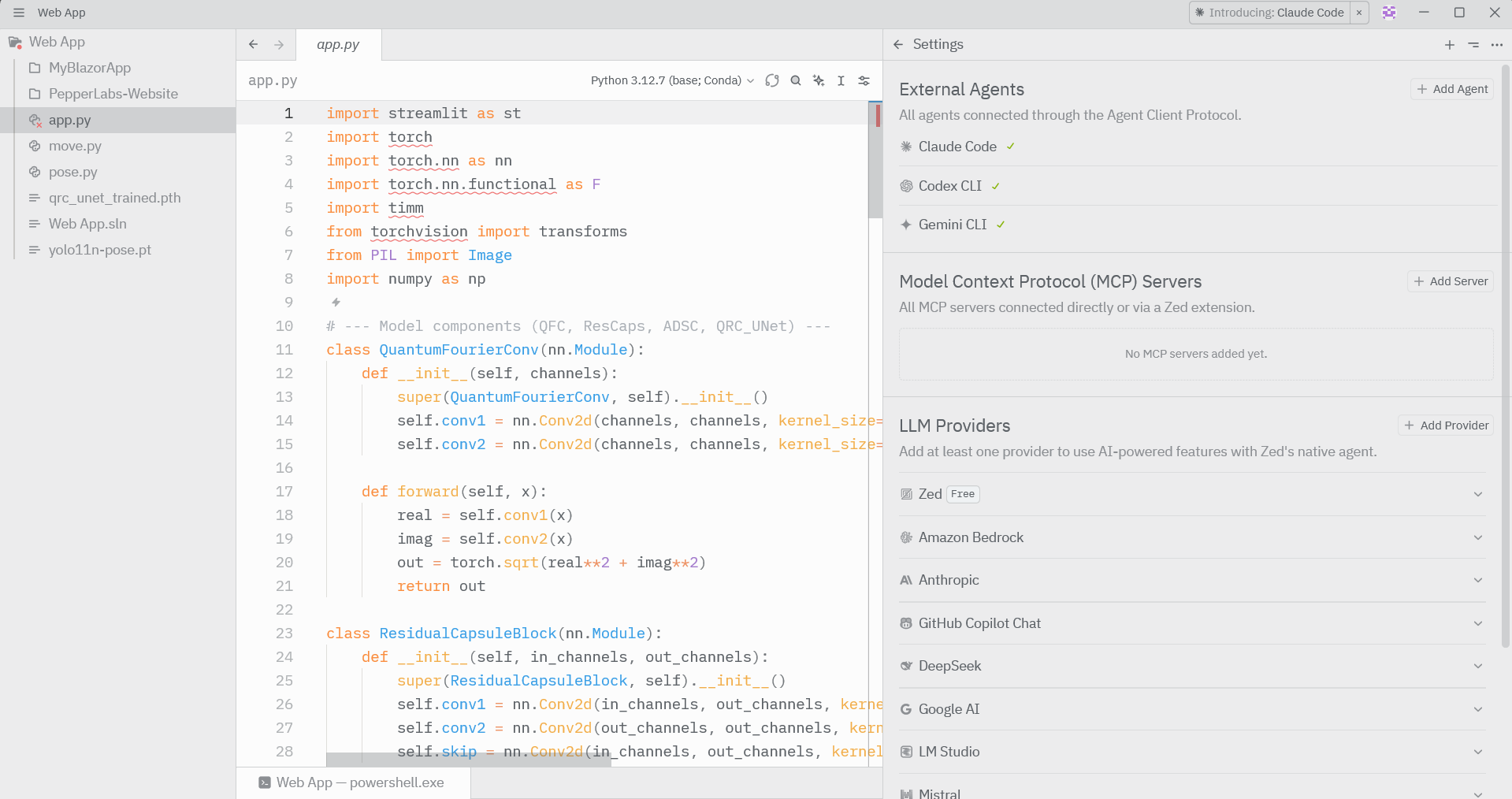
步骤二:在 Zed 中启用 AI 和 Agent 式编辑
打开 Zed 的 Settings,进入 LLM Providers(LLM 提供方)部分。
登录 Zed AI,或者配置任一受支持的提供方,如 Anthropic、Google AI 或 Amazon Bedrock,以启用 AI 功能。
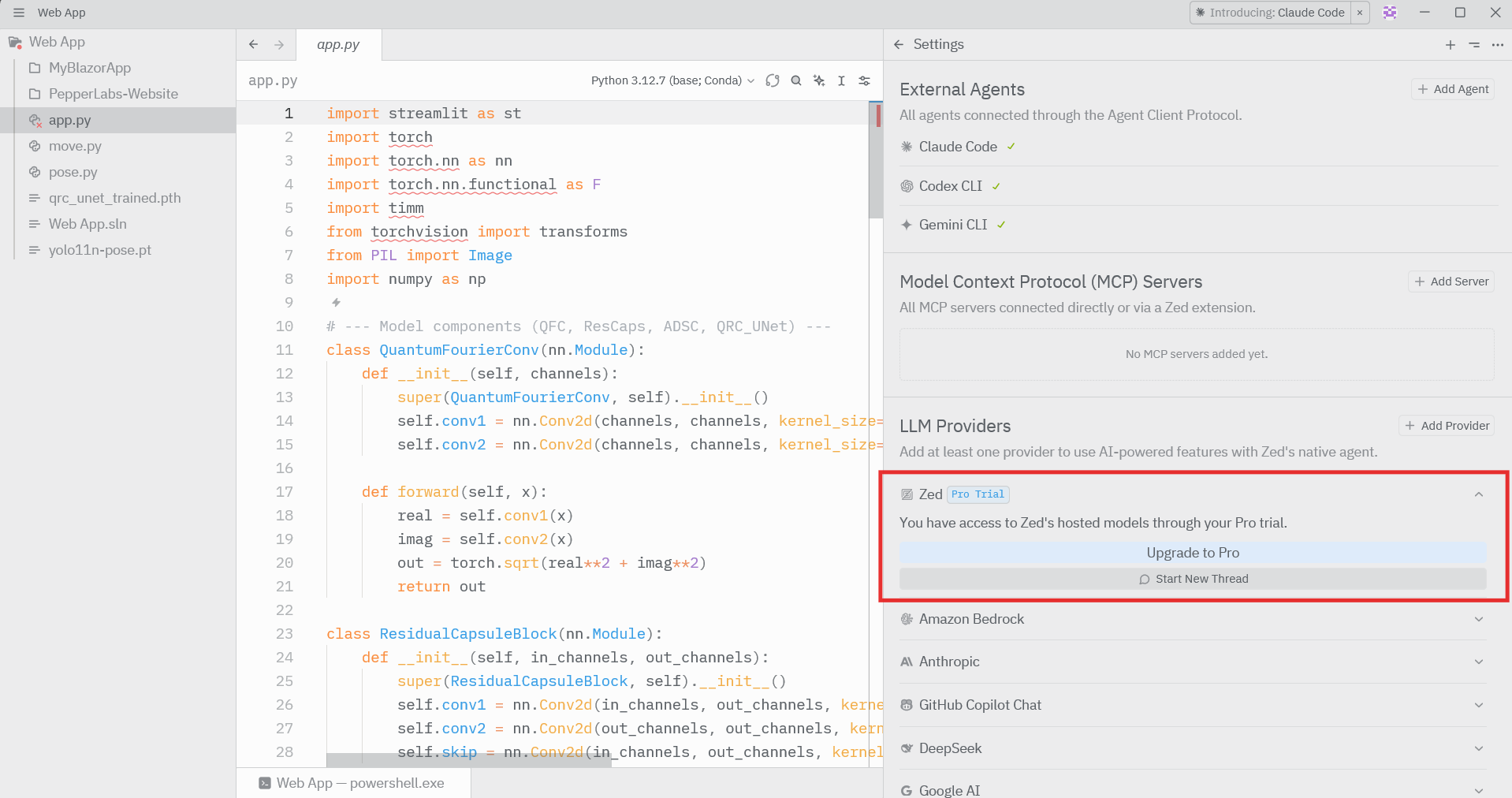
当某个提供方激活后,回到编辑器,打开 AI 或 Chat 面板,确认可以发送提示(prompt)并收到回复。如果 AI 能在编辑器中正常应答,则说明 Agent 式编辑已成功启用。
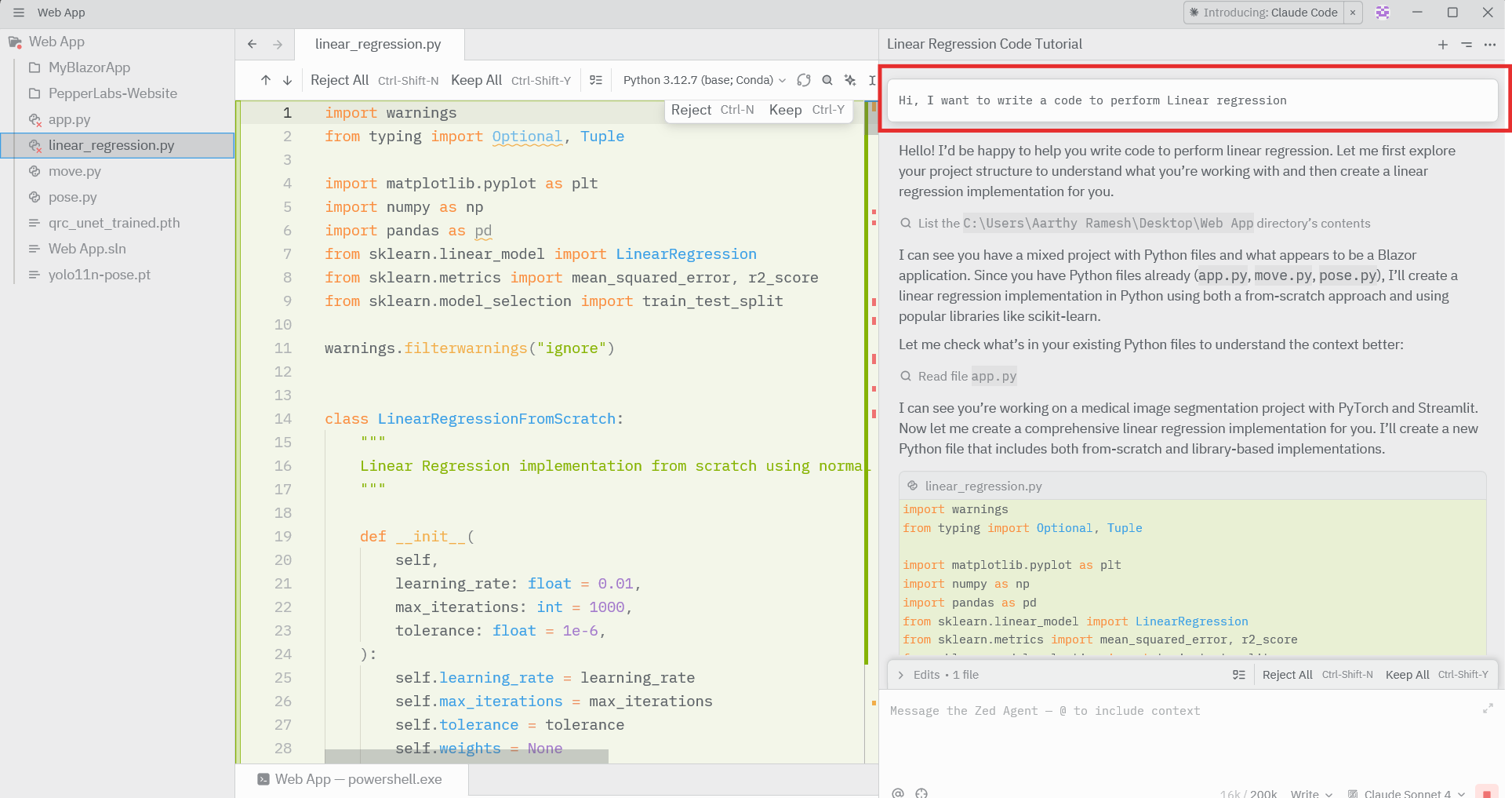
步骤三:在本地搭建 Bright Data Web MCP
要让 Zed 的 AI Agent 具备实时访问网页的能力,需要在本地机器上运行 Bright Data Web MCP。这个 MCP 服务器是 AI Agent 与实时网页数据之间的桥梁。
首先从 Bright Data 仪表盘 创建一个 Bright Data 账号。如果你已有账号,直接登录即可。
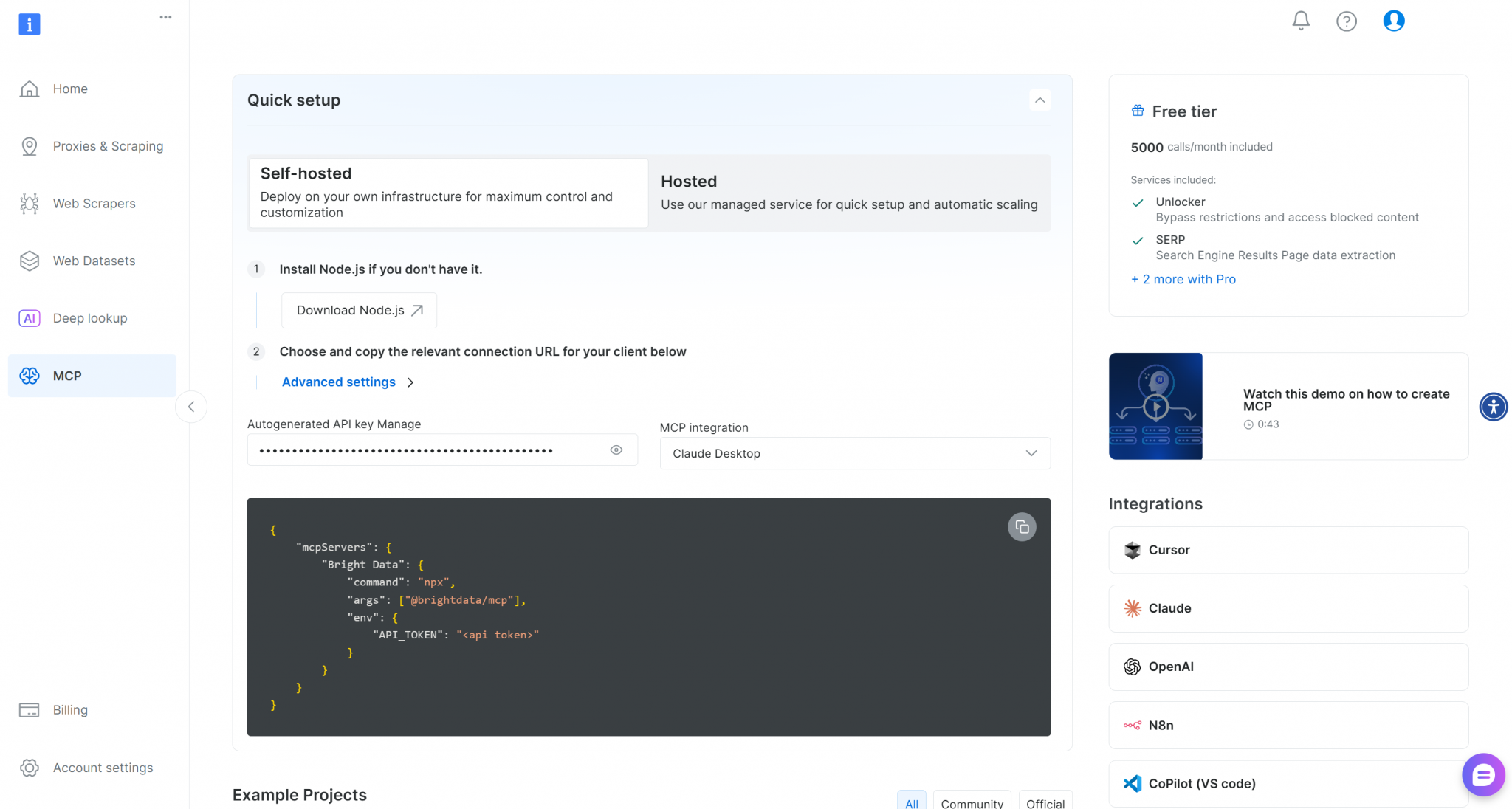
若想快速上手,可以在账号中打开 “MCP” 页面并按照页面中的指引操作:
或者,也可以按下面步骤操作:
在 Bright Data 仪表盘中,生成一个 API Token 并妥善保存。Web MCP 服务器会用这个 Token 来验证请求并访问 Bright Data 的 Web 工具。
在本教程中,你只需要这个 API Token 一项凭据。
Bright Data Web MCP 使用 Node.js 在本地以服务器形式运行。通过以下命令全局安装:
npm install -g @brightdata/mcp该命令会安装之后 Zed 将要连接的 Web MCP 包。
通过以下命令启动 Web MCP 服务器:
API_TOKEN="YOUR_BRIGHT_DATA_API_TOKEN" npx -y @brightdata/mcp将 YOUR_BRIGHT_DATA_API_TOKEN 替换为你的实际 API Token。

如果服务器启动成功,你会在终端看到日志输出,表明 MCP 服务器已启动并准备好接收请求。
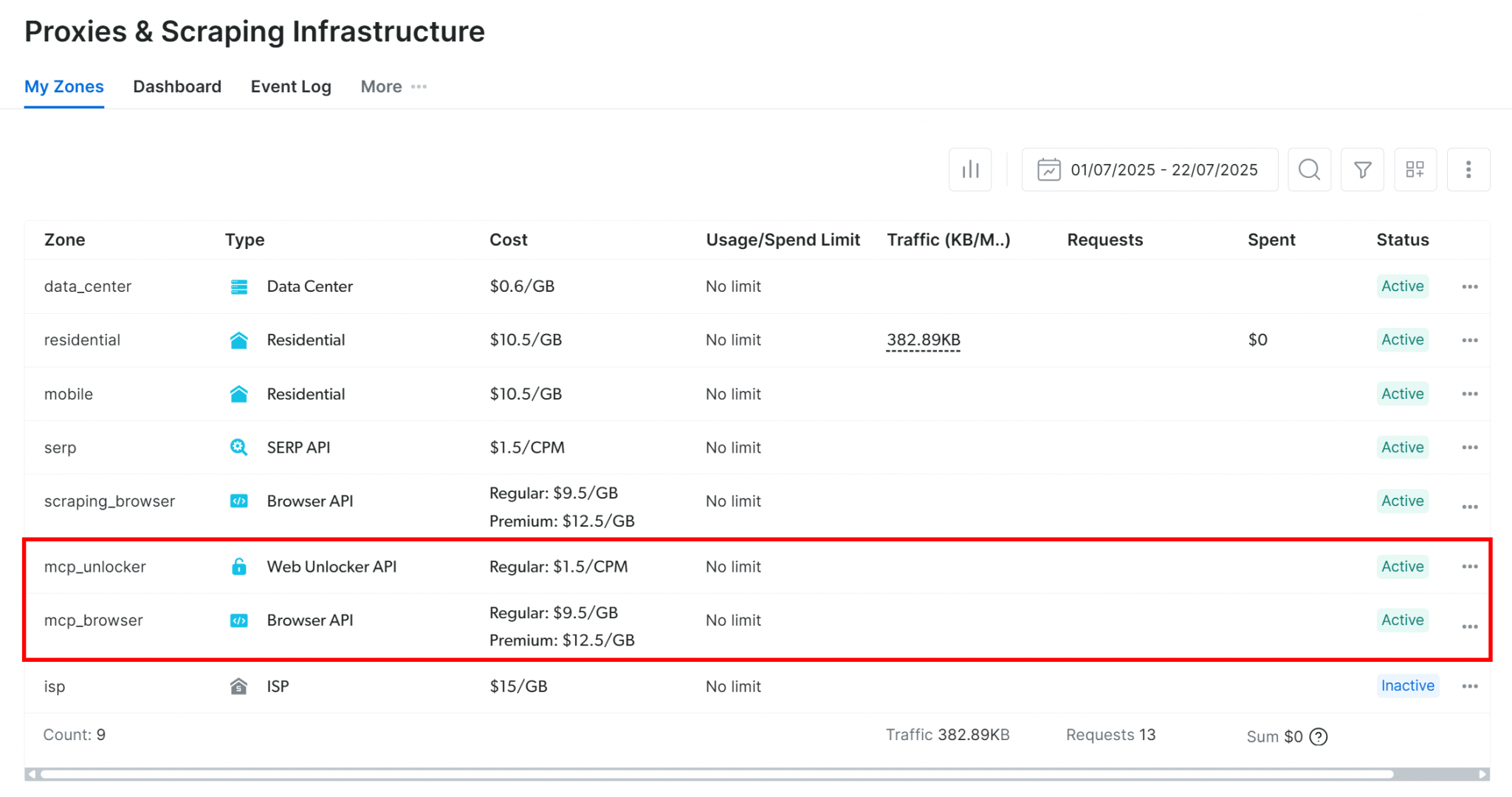
首次运行时,Bright Data Web MCP 会在你的 Bright Data 账号中自动创建两个必要的 Zone:一个用于 Web Unlocker,一个用于 Browser API。这些 Zone 会被 Web MCP 内部使用,以支撑可用工具。
你可以前往 Bright Data 仪表盘的 Proxies & Scraping Infrastructure 页面来验证这些 Zone 是否创建成功。如果你的 API Token 没有管理员权限,可能需要手动创建这些 Zone,并通过环境变量进行引用。
默认情况下,Web MCP 只暴露 search_engine 和 scrape_as_markdown 工具,这两个工具在免费套餐中可用。启用 Pro 模式后可以解锁完整工具集(包括高级浏览器自动化能力),可能会产生额外费用。
如需使用浏览器自动化和结构化数据抽取等高级能力,可在启动 Web MCP 服务器前设置 PRO_MODE=true 来启用 Pro 模式:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcp在确认服务器运行正常后,可以先停止它。接下来会在 Zed 中配置,让其自动启动并连接 Web MCP 服务器。
步骤四:在 Zed 中配置 Bright Data Web MCP
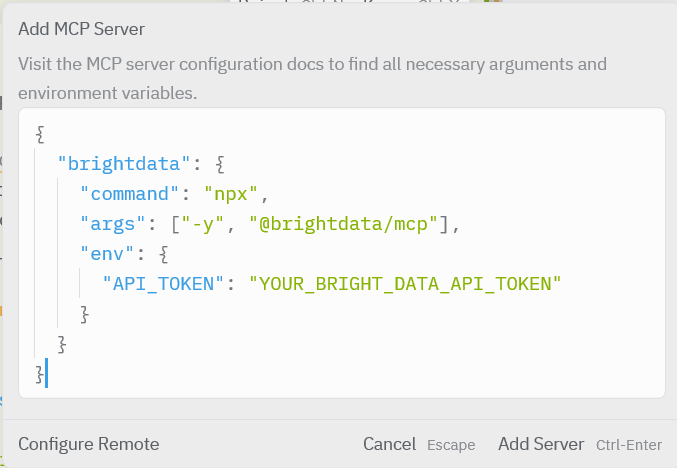
在 Zed 中打开 Settings,进入 Model Context Protocol(MCP)Servers 部分。点击 “Add Server” 来注册一个新的本地 MCP 服务器。

在弹出的配置界面中,将 Bright Data MCP 服务器的 command 设置为运行 Web MCP 包(例如:npx @brightdata/mcp),并添加用于身份验证的环境变量(API_TOKEN)。保存配置后,该 MCP 服务器就可以被 Zed 的 AI Agent 使用。
添加成功后,你会在 MCP Servers 列表中看到 Bright Data,说明 Zed 已准备好在 AI 工作流中连接 Web MCP。
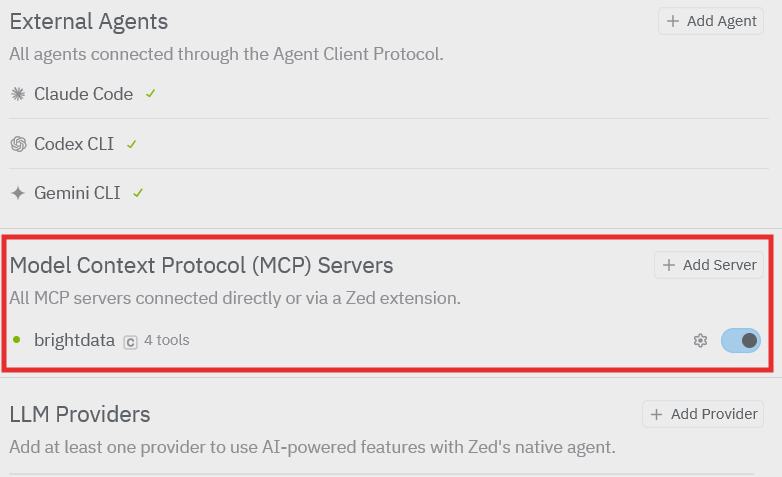
启用 MCP 服务器后,Zed 的 AI Agent 就可以在编辑器中的 AI 工作流里调用 Bright Data 的 Web 工具。
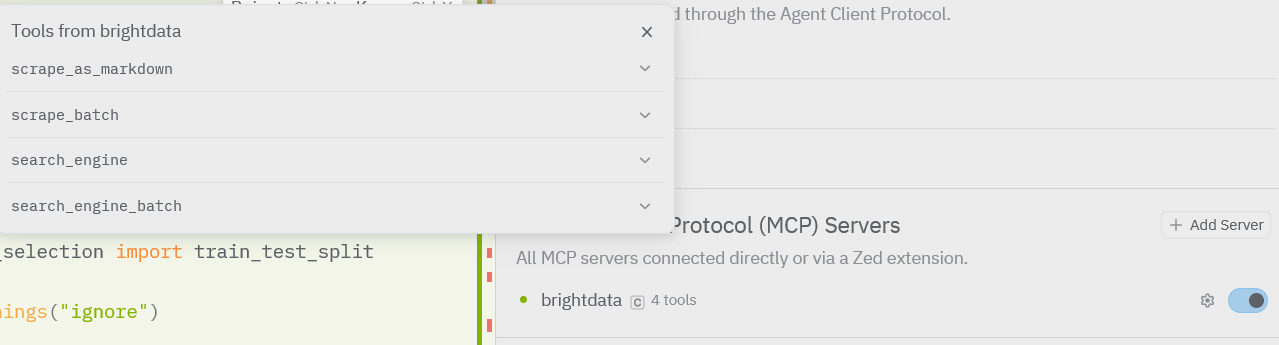
步骤六:在 Zed 中运行一个真实任务
在本步骤中,你将使用 Zed 的 AI Agent 和 Bright Data Web MCP 获取实时网页内容,将其保存到本地,并基于真实数据生成一个小脚本。
打开 Zed 的 AI 或 Chat 面板(即之前用来测试 AI 回答的面板):
- 你将在这里输入 Prompt
- 此时你是在与 Zed 的 AI Agent 对话,而不是在写代码。
将以下 Prompt 原样复制到 Zed 中:
Fetch the live documentation page at
https://nodejs.org/en/docs
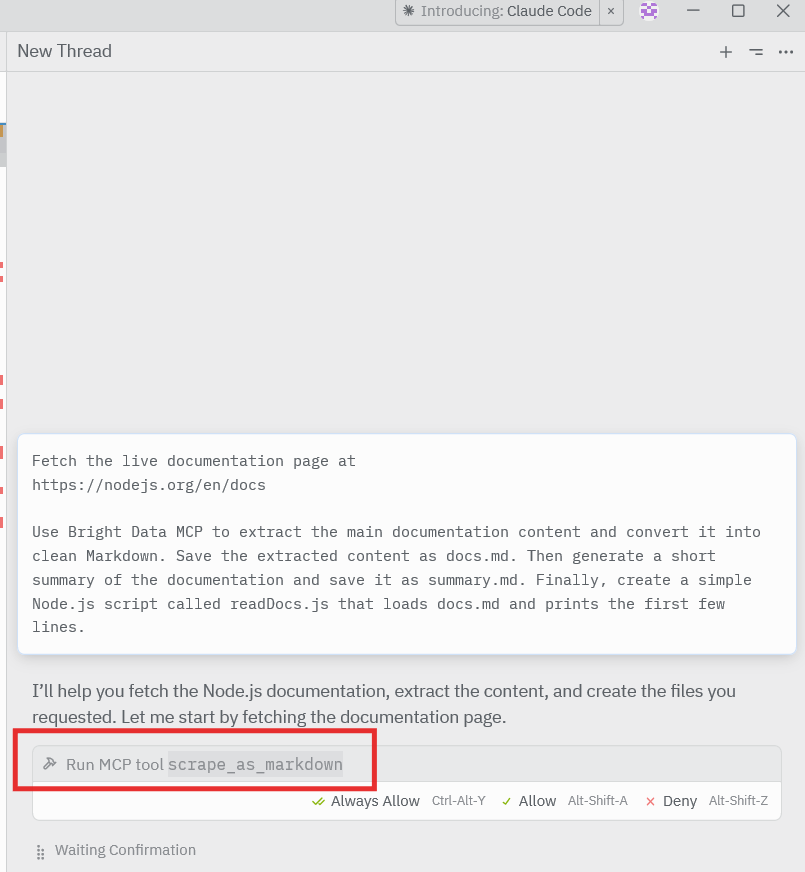
Use Bright Data MCP to extract the main documentation content and convert it into clean Markdown. Save the extracted content as docs.md. Then generate a short summary of the documentation and save it as summary.md. Finally, create a simple Node.js script called readDocs.js that loads docs.md and prints the first few lines.提交 Prompt 后,观察接下来的过程:
- AI Agent 会说明或规划它将执行的步骤
- 它会识别到本次任务需要访问网页
- 它会选择一个 Bright Data MCP 工具(通常是
scrape_as_markdown) - Zed 可能会请求你确认是否允许执行该工具
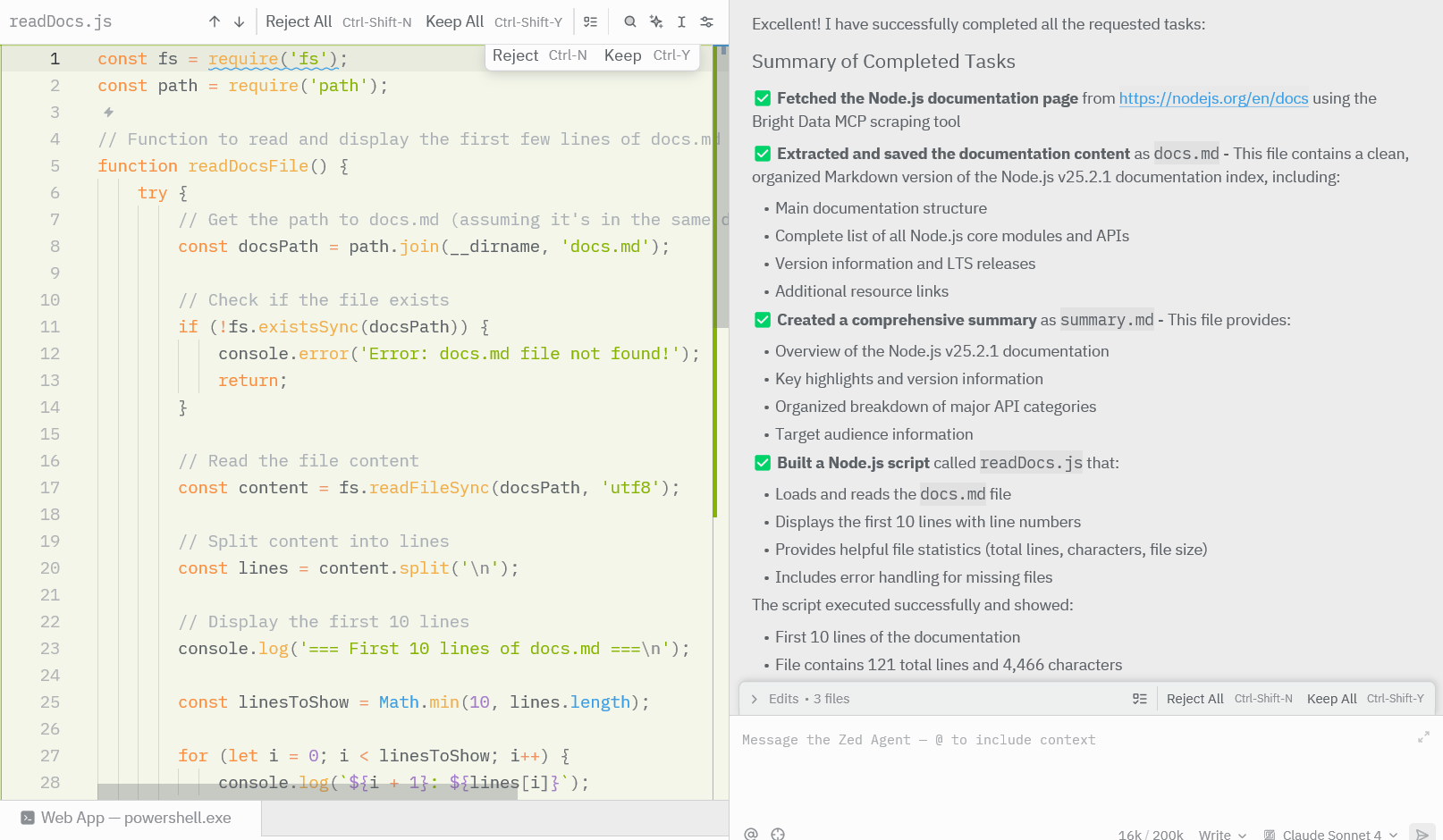
任务完成后,检查项目目录中是否生成了对应文件。打开生成的 Markdown 文件,确认其中包含从在线文档页面抽取到的内容。
运行生成的脚本,应能打印出部分被抓取内容,从而验证整个工作流正常运行。
总结
在本教程中,你学习了如何将 Zed 与 Bright Data Web MCP 集成,从而在一个 AI 原生编辑器中实现实时网页交互。通过把 Zed 的 Agent 式编辑模型与 Bright Data 的 Web 工具结合起来,你构建了一个完整工作流:AI 可以抓取实时内容,将其本地存储,并基于真实数据生成可用的代码和文件。
Bright Data 的 Web MCP 通过提供结构化、最新的网页数据,为构建更加可靠、上下文感知的 AI 辅助开发工作流打开了大门。这种方式减少了对静态知识的依赖,提高了 AI 生成结果的准确性。
如果你希望探索更多高级的 Agent 场景,可以进一步了解更广泛的 Bright Data 平台及其面向 AI 的 Web 数据解决方案。
你可以从一个免费的 Bright Data 账号开始,继续尝试使用 Web MCP 来驱动你自己的 AI 驱动开发工作流。



AI 内容创作者
Arindam Majumder 是一名开发者推广专员、YouTube博主和技术作家,专注于将大语言模型 (LLM)、智能体工作流及 AI 内容讲解得简单易懂,拥有超过5000名关注者。





