

本文将介绍:
- 什么是 Playwright MCP 服务器,以及它如何用于网页抓取
- Playwright MCP 服务器中可用的不同工具
- Bright Data Web MCP 服务器如何为网页抓取提供更简单的替代方案
开始吧!
Playwright MCP 服务器
Playwright 以浏览器自动化工具闻名,常用于测试与自动化浏览器任务。Playwright MCP 服务器在此基础上构建,不过这一次它并非面向人类直接使用,而是为 AI 智能体而设计。
通过运行该服务器,您可以连接任意 MCP 宿主,并为 AI 智能体授予对 Playwright 全套自动化工具的访问权限。
这意味着您的 AI 智能体可以像人类一样与浏览器交互,执行诸如在线购物、获取最新新闻、回复电子邮件等操作。
本文将重点关注网页抓取。借助 Playwright MCP 服务器,您不仅能完成浏览器自动化,还能让大语言模型(LLM)直接从网络抓取与提取数据。
Playwright MCP 服务器
与所有 MCP 服务器一样,Playwright MCP 服务器带有一组可暴露给 AI 智能体的工具。这些工具与开发者熟悉并使用的 Playwright API 一一对应。下面是一些重要工具:
- Browser_click:允许 AI 智能体像鼠标点击一样点击元素。
- Browser_drag:启用拖拽交互。
- Browser_close:关闭浏览器实例。
- Browser_evaluate:让 AI 智能体在页面中直接执行 JavaScript 代码。
- Browser_file_upload:通过浏览器处理文件上传。
- Browser_fill_form:在网页上填写表单。
- Browser_hover:将鼠标指针悬停在元素上。
- Browser_navigate:导航到任意 URL。
- Browser_press_key:模拟按键输入,为智能体提供完整的键盘输入能力。
借助上述工具,AI 智能体可以轻松在网页间穿梭并抓取数据。下面看看如何实现。
使用 Playwright MCP 服务器进行网页抓取
本节我们将使用 Playwright MCP 服务器执行一次网页抓取任务。我们的 AI 智能体将收集 iPhone 16 各型号的最新价格信息。为简化演示,我们将数据来源限定为 Best Buy。
服务器配置
要运行 Playwright MCP 服务器,我们需要一个 MCP 宿主。您可以选择任意宿主,例如 Claude Desktop、Cursor 或 Gemini CLI。本文将使用 VS Code。
Playwright MCP 服务器是一个基于 Node.js 实现的本地 MCP 服务器,因此在继续之前,请确保已安装 Node。
要完成服务器设置,我们需要在 MCP 宿主中添加如下配置:
{
"servers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest"
]
}
}
}该配置适用于在 VS Code 中设置 MCP 服务器的方式,其他 MCP 宿主可能略有不同。完成设置后,我们的 AI 智能体就可以访问服务器提供的工具。准备就绪后,我们即可开始抓取。
使用 MCP 服务器进行抓取
第一步是访问 Best Buy 网站。我们只需指示 AI 智能体打开该站点,它会使用 Browser_navigate 工具到达目标页面。
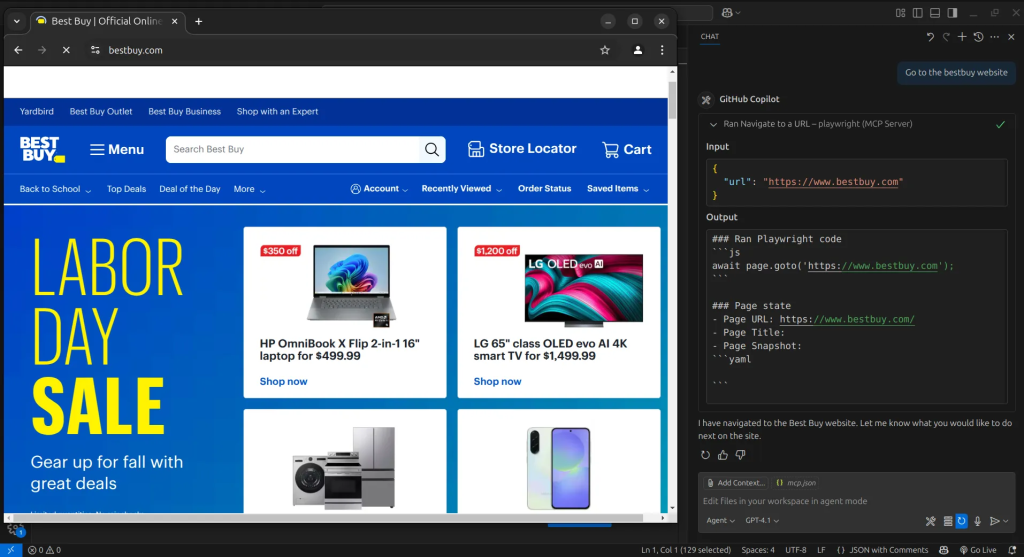
接着,我们指示 AI 智能体搜索 iPhone 16。它将使用 Browser_press_key 工具输入搜索关键词。
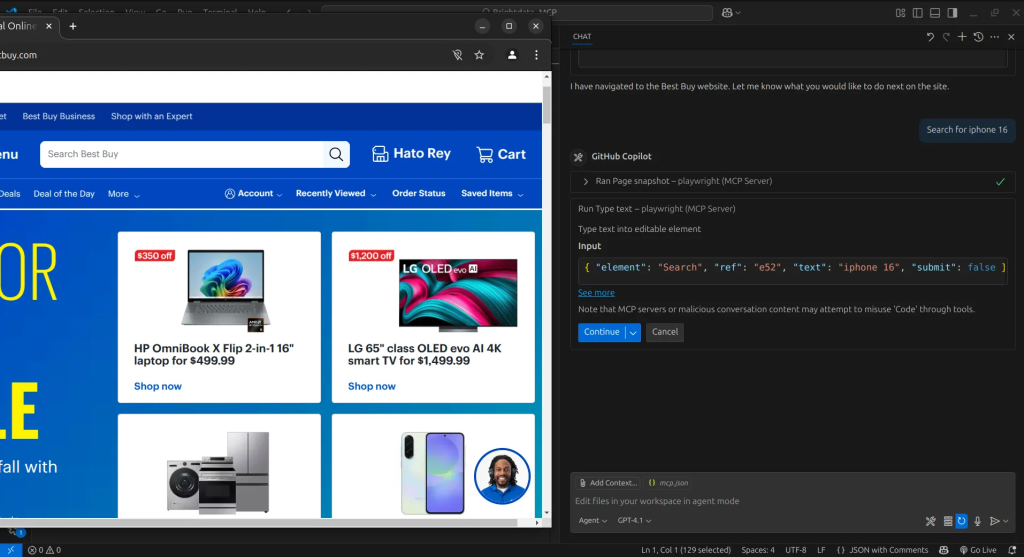
随后,AI 智能体会使用 Browser_click 工具点击搜索按钮。

这样,我们就获得了搜索结果。智能体在页面导航的每一步都会捕获当前状态的快照。我们可以利用这些快照来指示智能体提取所需信息,并将其整理为结构化格式。
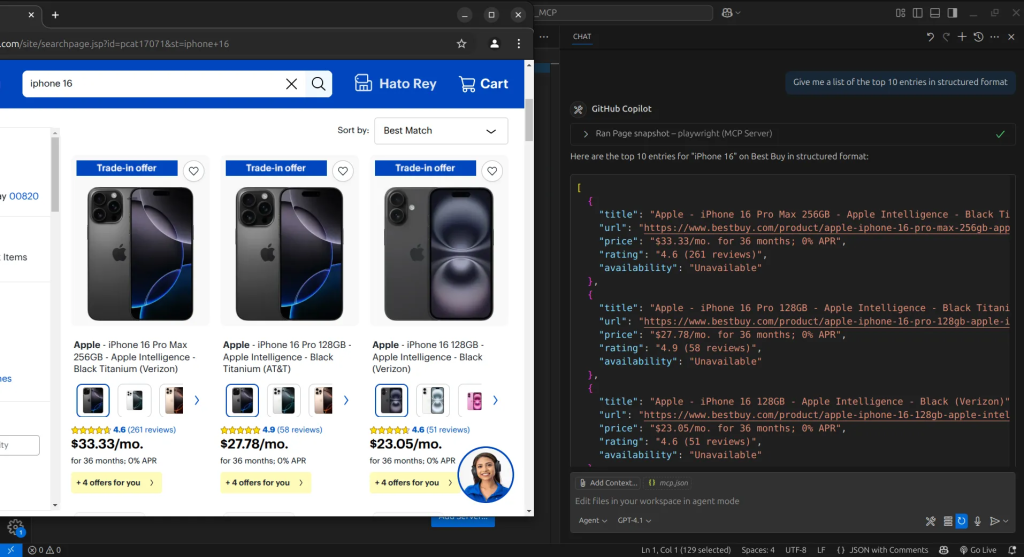
通过这种方式,我们成功完成了站点抓取。不过,尽管这种方法让我们几乎能完全掌控一切操作,它仍属于较低层级。如果我们的目标只是抓取数据,可能并不需要如此全面的浏览器自动化能力。
接下来,让我们看看 Bright Data Web MCP 服务器如何以更高层级的方式完成同样的任务。
Bright Data Web MCP 服务器:高层级的网页抓取 MCP 服务器
Bright Data Web MCP 服务器内置了为网页抓取而生的一系列高层级工具。这些工具包括从 Amazon 等平台提取数据、获取个人与公司资料,甚至收集 Instagram 的资料、帖子与 Reels 等。
不同于处于较低层级的 Playwright MCP,Bright Data Web MCP 服务器简化了智能体的抓取流程。它还能处理受机器人检测或 CAPTCHA 保护的网页,使您的智能体在传统方法可能失效的场景中也能可靠访问。
在本次演示中,我们将使用Bright Data Web MCP 服务器来完成与此前 Playwright MCP 相同的任务。它开箱即用地提供两个核心工具:
- 搜索引擎工具
- 将数据抓取为 Markdown 的工具
启用专业模式(Pro Mode)后可解锁更多工具,但此处我们仅使用这两个。更多细节可参阅这篇文章。
服务器配置
不同于本地运行的 Playwright MCP 服务器,Bright Data Web MCP 服务器是一个远程 MCP 服务器。因此配置方式略有不同。以下是在 VS Code 中的设置方法:
"BrightData": {
"url": "https://mcp.brightdata.com/mcp?token=YOUR_API_KEY",
}连接时您需要提供Bright Data API Key。配置完成后,智能体即可开始抓取。
使用 MCP 服务器进行抓取
首先,我们指示智能体进行一次关于 iPhone 16 价格的网络搜索。
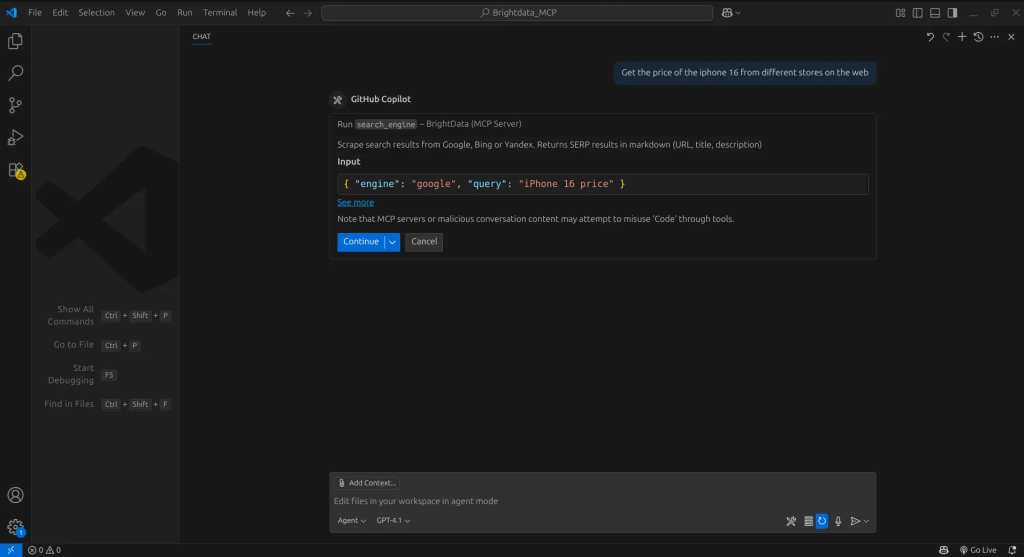
智能体随后使用服务器的搜索引擎工具来执行该请求。
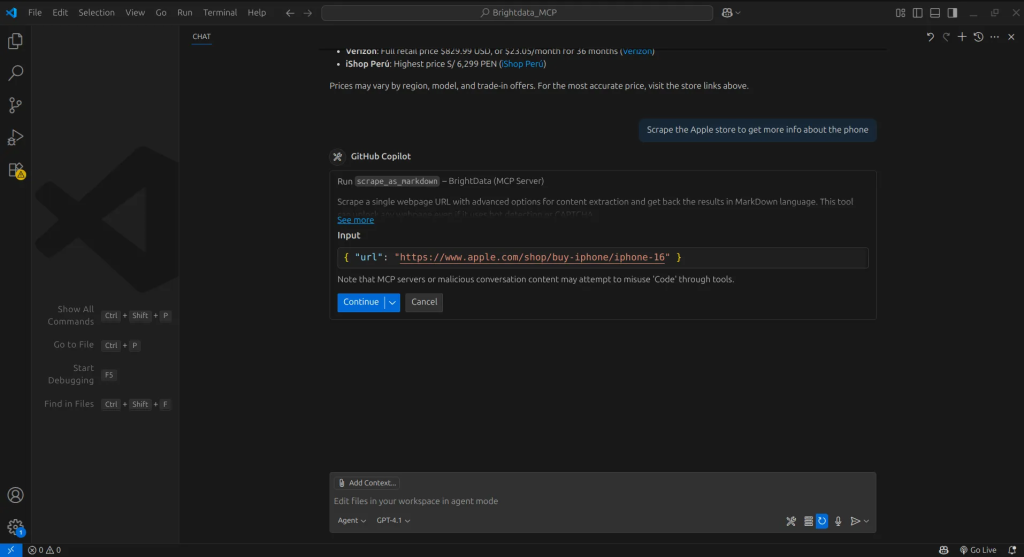
获取搜索结果后,我们指示智能体从指定站点(此处为 Apple Store)提取信息。智能体使用将数据抓取为 Markdown的工具来拉取内容,并以 Markdown 格式返回,便于智能体处理与理解。
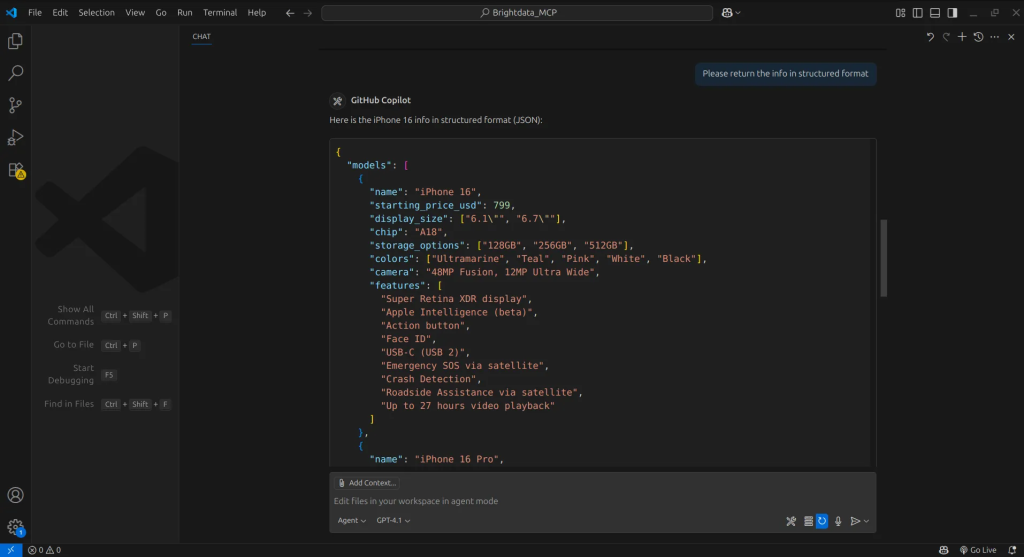
有了提取的信息,我们可以指示智能体将其整理为结构化格式,如此便获得了所需数据。
在这个示例中,我们仅使用了两个工具就完成了抓取任务。不过,Bright Data Web MCP 服务器在专业模式下还提供更多工具,适用于更高级的用例。您可以在这篇详细的文章中找到进一步的示例。
结论
本文探讨了如何借助 AI 智能体使用 MCP 服务器进行网页抓取。我们首先了解了Playwright MCP 服务器,它提供对浏览器自动化的低层级访问,使智能体能充分掌控每一个交互。随后我们又介绍了Bright Data 的 Web MCP 服务器,它以更高层级的方式运行,为智能体配备专门面向网页抓取的工具,即使在受机器人检测保护的网站上也同样有效。
两种方式各有优势:当您需要对浏览器进行精细控制时,Playwright 更为理想;而 Bright Data 则简化了流程,让您可以将精力聚焦于提取所需信息本身。
现在轮到您亲自尝试这两种 MCP 服务器,并选择更契合下一个项目需求的方案了。



技术写作者
Amitesh Anand 是一位开发者倡导者和技术写作者,分享有关 AI、软件和开发工具的内容,拥有 1 万粉丝和超过 40 万次观看。





