

在本指南中,你将学习:
- 什么是第三方风险管理(TPRM),以及为什么人工筛查会失效
- 如何构建一个能够自主调查供应商不利舆情的 AI 代理
- 如何集成 Bright Data SERP API 和 Web Unlocker,获取可靠且最新的网络数据
- 如何使用 OpenHands SDK 进行代理式脚本生成,并使用 OpenAI 进行风险分析
- 如何使用 Browser API 增强代理能力,以应对法院登记处等复杂场景
让我们开始吧!
人工供应商筛查的问题
企业合规团队面临一项几乎不可能完成的任务:在全网范围内持续监控数百家第三方供应商的风险信号。传统方法通常包括:
- 手动 Google 搜索:对每个供应商名称结合“诉讼”“破产”“欺诈”等关键词逐一检索
- 在尝试访问新闻文章和法院记录时遇到付费墙和验证码
- 文档记录不统一,对调查结果没有标准化记录流程
- 缺乏持续监控:供应商只在准入时筛查一次,之后就不再复查
这种方法在三个关键方面会失败:
- 规模:一个分析师每天最多只能彻底调查 5–10 家供应商
- 访问:法院登记处、付费新闻网站等受保护资源会阻止自动化访问
- 连续性:一次性的准入评估无法发现后续出现的风险
解决方案:自治 TPRM 代理
TPRM 代理通过三个专业层自动化整个供应商调查流程:
- 发现层(SERP API):代理通过 Google 搜索诉讼、监管处罚、财务困境等风险信号
- 访问层(Web Unlocker):当相关结果被付费墙或验证码保护时,代理通过 Web Unlocker 绕过这些障碍并提取完整内容
- 行动层(OpenAI + OpenHands SDK):代理使用 OpenAI 分析内容风险等级,再通过 OpenHands SDK 生成 Python 监控脚本,每日检查新的不利媒体
该系统可以将数小时的人工调研缩短为几分钟的自动分析。
前置条件
在开始之前,请确保你已经具备:
- Python 3.12 或更高版本(OpenHands SDK 要求)
- 一个具有 API 访问权限的 Bright Data 账号(可使用免费试用)
- 用于风险分析的 OpenAI API 密钥
- 用于代理式脚本生成的 OpenHands Cloud 账号 或你自己的 LLM API 密钥
- 对 Python 和 REST API 有基本了解
项目架构
TPRM 代理遵循三阶段流水线:
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ DISCOVERY │────▶│ ACCESS │────▶│ ACTION │
│ (SERP API) │ │ (Web Unlocker) │ │ (OpenAI + SDK) │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │ │
Search Google Bypass paywalls Analyze risks
for red flags and CAPTCHAs Generate scripts创建如下项目结构:
tprm-agent/
├── src/
│ ├── __init__.py
│ ├── config.py # Configuration
│ ├── discovery.py # SERP API integration
│ ├── access.py # Web Unlocker integration
│ ├── actions.py # OpenAI + OpenHands SDK
│ ├── agent.py # Main orchestration
│ └── browser.py # Browser API (enhancement)
├── api/
│ └── main.py # FastAPI endpoints
├── scripts/
│ └── generated/ # Auto-generated monitoring scripts
├── .env
├── requirements.txt
└── README.md
环境搭建
创建虚拟环境并安装依赖:
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
pip install requests fastapi uvicorn python-dotenv pydantic openai beautifulsoup4 playwright openhands-sdk openhands-tools
创建 .env 文件保存你的 API 凭据:
# Bright Data API Token (for SERP API)
BRIGHT_DATA_API_TOKEN=your_api_token
# Bright Data SERP Zone
BRIGHT_DATA_SERP_ZONE=your_serp_zone_name
# Bright Data Web Unlocker credentials
BRIGHT_DATA_CUSTOMER_ID=your_customer_id
BRIGHT_DATA_UNLOCKER_ZONE=your_unlocker_zone_name
BRIGHT_DATA_UNLOCKER_PASSWORD=your_zone_password
# OpenAI (for risk analysis)
OPENAI_API_KEY=your_openai_api_key
# OpenHands (for agentic script generation)
# Use OpenHands Cloud: openhands/claude-sonnet-4-5-20260929
# Or bring your own: anthropic/claude-sonnet-4-5-20260929
LLM_API_KEY=your_llm_api_key
LLM_MODEL=openhands/claude-sonnet-4-5-20260929Bright Data 配置
步骤一:创建 Bright Data 账号
在 Bright Data 注册并进入控制台。
步骤二:配置 SERP API 区
- 进入 Proxies & Scraping Infrastructure
- 点击 Add 并选择 SERP API
- 为你的区命名(例如
tprm_serp) - 复制区名称,并在 Settings > API tokens 中记下 API token
SERP API 会返回来自 Google 的结构化搜索结果,不会被封锁。在搜索 URL 中添加 brd_json=1 可获取解析后的 JSON 输出。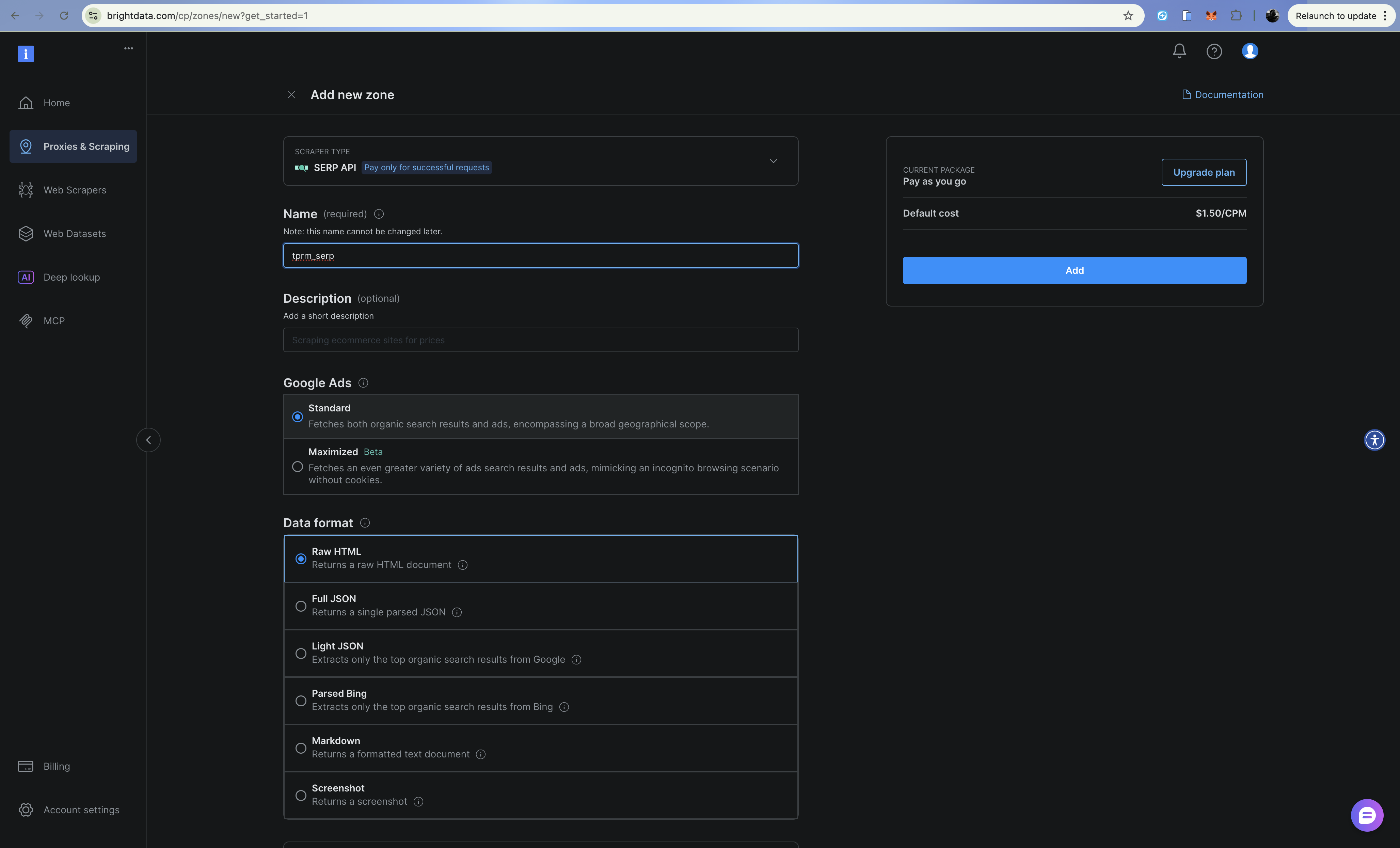
步骤三:配置 Web Unlocker 区
- 点击 Add 并选择 Web Unlocker
- 为你的区命名(例如
tprm_unlocker) - 复制区凭据(用户名格式:
brd-customer-CUSTOMER_ID-zone-ZONE_NAME)
Web Unlocker 通过代理端点自动处理验证码、指纹和 IP 轮换。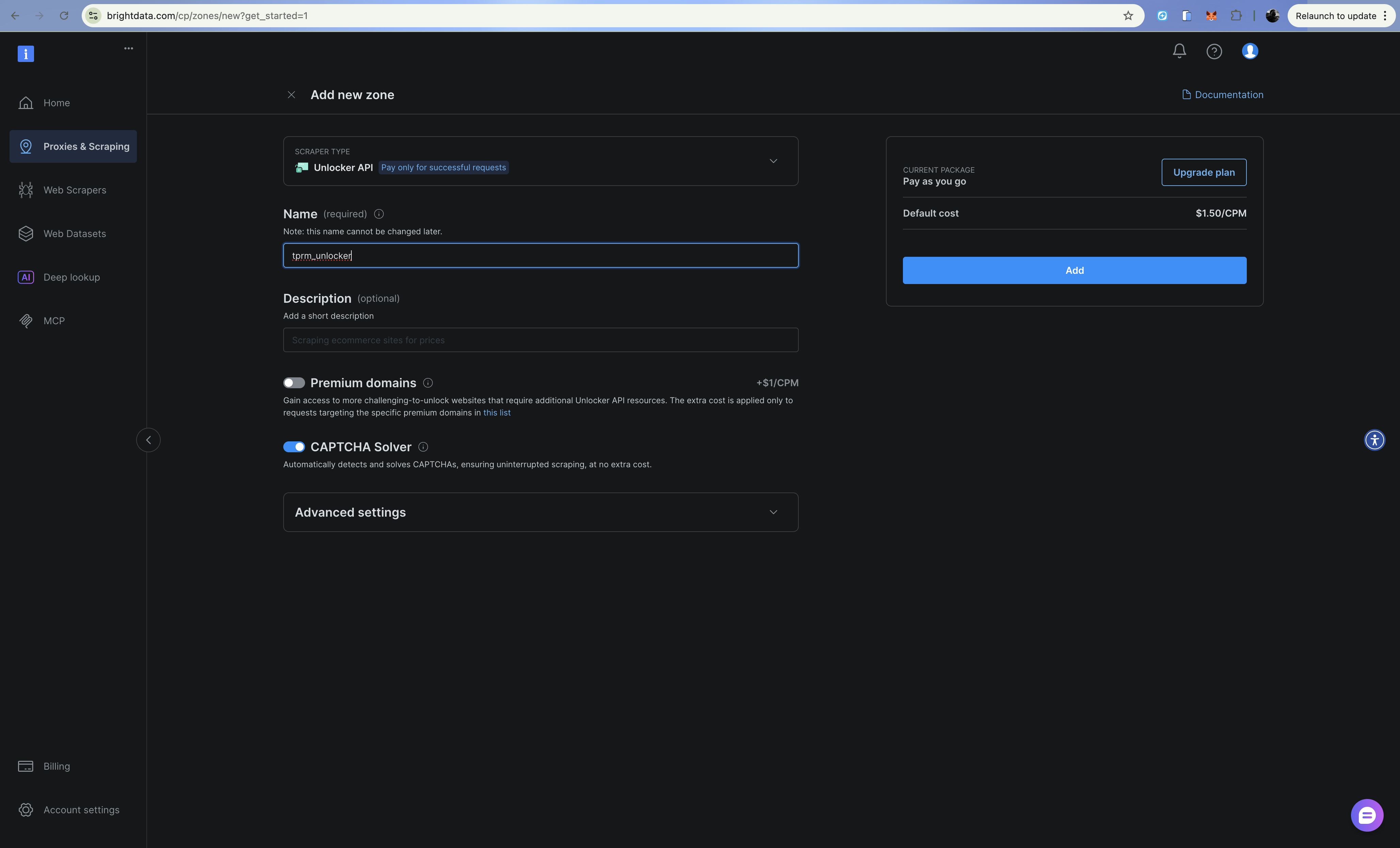
构建发现层(SERP API)
发现层借助 SERP API 在 Google 中搜索与供应商相关的不利舆情。创建 src/discovery.py:
import requests
from typing import Optional
from dataclasses import dataclass
from urllib.parse import quote_plus
from config import settings
@dataclass
class SearchResult:
title: str
url: str
snippet: str
source: str
class DiscoveryClient:
"""Search for adverse media using Bright Data SERP API (Direct API)."""
RISK_CATEGORIES = {
"litigation": ["lawsuit", "litigation", "sued", "court case", "legal action"],
"financial": ["bankruptcy", "insolvency", "debt", "financial trouble", "default"],
"fraud": ["fraud", "scam", "investigation", "indictment", "scandal"],
"regulatory": ["violation", "fine", "penalty", "sanctions", "compliance"],
"operational": ["recall", "safety issue", "supply chain", "disruption"],
}
def __init__(self):
self.api_url = "https://api.brightdata.com/request"
self.headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {settings.BRIGHT_DATA_API_TOKEN}",
}
def _build_queries(self, vendor_name: str, categories: Optional[list] = None) -> list[str]:
"""Build search queries for each risk category."""
categories = categories or list(self.RISK_CATEGORIES.keys())
queries = []
for category in categories:
keywords = self.RISK_CATEGORIES.get(category, [])
keyword_str = " OR ".join(keywords)
query = f'"{vendor_name}" ({keyword_str})'
queries.append(query)
return queries
def search(self, query: str) -> list[SearchResult]:
"""Execute a single search query using Bright Data SERP API."""
try:
# Build Google search URL with brd_json=1 for parsed JSON
encoded_query = quote_plus(query)
google_url = f"https://www.google.com/search?q={encoded_query}&hl=en&gl=us&brd_json=1"
payload = {
"zone": settings.BRIGHT_DATA_SERP_ZONE,
"url": google_url,
"format": "raw",
}
response = requests.post(
self.api_url,
headers=self.headers,
json=payload,
timeout=30,
)
response.raise_for_status()
data = response.json()
results = []
organic = data.get("organic", [])
for item in organic:
results.append(
SearchResult(
title=item.get("title", ""),
url=item.get("link", ""),
snippet=item.get("description", ""),
source=item.get("displayed_link", ""),
)
)
return results
except Exception as e:
print(f"Search error: {e}")
return []
def discover_adverse_media(
self,
vendor_name: str,
categories: Optional[list] = None,
) -> dict[str, list[SearchResult]]:
"""Search for adverse media across all risk categories."""
queries = self._build_queries(vendor_name, categories)
category_names = categories or list(self.RISK_CATEGORIES.keys())
categorized_results = {}
for category, query in zip(category_names, queries):
print(f" Searching: {category}...")
results = self.search(query)
categorized_results[category] = results
return categorized_results
def filter_relevant_results(
self, results: dict[str, list[SearchResult]], vendor_name: str
) -> dict[str, list[SearchResult]]:
"""Filter out irrelevant results."""
filtered = {}
vendor_lower = vendor_name.lower()
for category, items in results.items():
relevant = []
for item in items:
if (
vendor_lower in item.title.lower()
or vendor_lower in item.snippet.lower()
):
relevant.append(item)
filtered[category] = relevant
return filteredSERP API 返回包含自然结果的结构化 JSON,方便你解析每条搜索结果的标题、URL 和摘要。
构建访问层(Web Unlocker)
当发现层找到相关 URL 后,访问层会使用 Web Unlocker API 抓取完整内容。创建 src/access.py:
import requests
from bs4 import BeautifulSoup
from dataclasses import dataclass
from typing import Optional
from config import settings
@dataclass
class ExtractedContent:
url: str
title: str
text: str
publish_date: Optional[str]
author: Optional[str]
success: bool
error: Optional[str] = None
class AccessClient:
"""Access protected content using Bright Data Web Unlocker (API-based)."""
def __init__(self):
self.api_url = "https://api.brightdata.com/request"
self.headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {settings.BRIGHT_DATA_API_TOKEN}",
}
def fetch_url(self, url: str) -> ExtractedContent:
"""Fetch and extract content from a URL using Web Unlocker API."""
try:
payload = {
"zone": settings.BRIGHT_DATA_UNLOCKER_ZONE,
"url": url,
"format": "raw",
}
response = requests.post(
self.api_url,
headers=self.headers,
json=payload,
timeout=60,
)
response.raise_for_status()
# Web Unlocker API returns the HTML directly
html_content = response.text
content = self._extract_content(html_content, url)
return content
except requests.Timeout:
return ExtractedContent(
url=url,
title="",
text="",
publish_date=None,
author=None,
success=False,
error="Request timed out",
)
except Exception as e:
return ExtractedContent(
url=url,
title="",
text="",
publish_date=None,
author=None,
success=False,
error=str(e),
)
def _extract_content(self, html: str, url: str) -> ExtractedContent:
"""Extract article content from HTML."""
soup = BeautifulSoup(html, "html.parser")
# Remove unwanted elements
for element in soup(["script", "style", "nav", "footer", "header", "aside"]):
element.decompose()
# Extract title
title = ""
if soup.title:
title = soup.title.string or ""
elif soup.find("h1"):
title = soup.find("h1").get_text(strip=True)
# Extract main content
article = soup.find("article") or soup.find("main") or soup.find("body")
text = article.get_text(separator="\n", strip=True) if article else ""
# Limit text length
text = text[:10000] if len(text) > 10000 else text
# Try to extract publish date
publish_date = None
date_meta = soup.find("meta", {"property": "article:published_time"})
if date_meta:
publish_date = date_meta.get("content")
# Try to extract author
author = None
author_meta = soup.find("meta", {"name": "author"})
if author_meta:
author = author_meta.get("content")
return ExtractedContent(
url=url,
title=title,
text=text,
publish_date=publish_date,
author=author,
success=True,
)
def fetch_multiple(self, urls: list[str]) -> list[ExtractedContent]:
"""Fetch multiple URLs sequentially."""
results = []
for url in urls:
print(f" Fetching: {url[:60]}...")
content = self.fetch_url(url)
if not content.success:
print(f" Error: {content.error}")
results.append(content)
return resultsWeb Unlocker 会自动处理验证码、浏览器指纹和 IP 轮换,你只需将请求通过代理路由,其余工作由其自动完成。
构建行动层(OpenAI + OpenHands SDK)
行动层使用 OpenAI 分析风险严重程度,并使用 OpenHands SDK 生成基于 Bright Data Web Unlocker API 的监控脚本。OpenHands SDK 提供“代理式”能力:代理可以推理、编辑文件并执行命令,直到脚本可在生产中稳定运行。
创建 src/actions.py:
import os
import json
from datetime import datetime, UTC
from dataclasses import dataclass, asdict
from openai import OpenAI
from pydantic import SecretStr
from openhands.sdk import LLM, Agent, Conversation, Tool
from openhands.tools.terminal import TerminalTool
from openhands.tools.file_editor import FileEditorTool
from config import settings
@dataclass
class RiskAssessment:
vendor_name: str
category: str
severity: str
summary: str
key_findings: list[str]
sources: list[str]
recommended_actions: list[str]
assessed_at: str
@dataclass
class MonitoringScript:
vendor_name: str
script_path: str
urls_monitored: list[str]
check_frequency: str
created_at: str
class ActionsClient:
"""Analyze risks using OpenAI and generate monitoring scripts using OpenHands SDK."""
def __init__(self):
# OpenAI for risk analysis
self.openai_client = OpenAI(api_key=settings.OPENAI_API_KEY)
# OpenHands for agentic script generation
self.llm = LLM(
model=settings.LLM_MODEL,
api_key=SecretStr(settings.LLM_API_KEY),
)
self.workspace = os.path.join(os.getcwd(), "scripts", "generated")
os.makedirs(self.workspace, exist_ok=True)
def analyze_risk(
self,
vendor_name: str,
category: str,
content: list[dict],
) -> RiskAssessment:
"""Analyze extracted content for risk severity using OpenAI."""
content_summary = "\n\n".join(
[f"Source: {c['url']}\nTitle: {c['title']}\nContent: {c['text'][:2000]}" for c in content]
)
prompt = f"""Analyze the following content about "{vendor_name}" for third-party risk assessment.
Category: {category}
Content:
{content_summary}
Provide a JSON response with:
{{
"severity": "low|medium|high|critical",
"summary": "2-3 sentence summary of findings",
"key_findings": ["finding 1", "finding 2", ...],
"recommended_actions": ["action 1", "action 2", ...]
}}
Consider:
- Severity should be based on potential business impact
- Critical = immediate action required (active fraud, bankruptcy filing)
- High = significant risk requiring investigation
- Medium = notable concern worth monitoring
- Low = minor issue or historical matter
"""
response = self.openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"},
)
response_text = response.choices[0].message.content
try:
result = json.loads(response_text)
except (json.JSONDecodeError, ValueError):
result = {
"severity": "medium",
"summary": "Unable to parse risk assessment",
"key_findings": [],
"recommended_actions": ["Manual review required"],
}
return RiskAssessment(
vendor_name=vendor_name,
category=category,
severity=result.get("severity", "medium"),
summary=result.get("summary", ""),
key_findings=result.get("key_findings", []),
sources=[c["url"] for c in content],
recommended_actions=result.get("recommended_actions", []),
assessed_at=datetime.now(UTC).isoformat(),
)
def generate_monitoring_script(
self,
vendor_name: str,
urls: list[str],
check_keywords: list[str],
) -> MonitoringScript:
"""Generate a Python monitoring script using OpenHands SDK agent."""
script_name = f"monitor_{vendor_name.lower().replace(' ', '_')}.py"
script_path = os.path.join(self.workspace, script_name)
prompt = f"""Create a Python monitoring script at {script_path} that:
1. Checks these URLs daily for new content: {urls[:5]}
2. Looks for these keywords: {check_keywords}
3. Sends an alert (print to console) if new relevant content is found
4. Logs all checks to a JSON file named 'monitoring_log.json'
The script MUST use Bright Data Web Unlocker API to bypass paywalls and CAPTCHAs:
- API endpoint: https://api.brightdata.com/request
- Use environment variable BRIGHT_DATA_API_TOKEN for the Bearer token
- Use environment variable BRIGHT_DATA_UNLOCKER_ZONE for the zone name
- Make POST requests with JSON payload: {{"zone": "zone_name", "url": "target_url", "format": "raw"}}
- Add header: "Authorization": "Bearer <token>"
- Add header: "Content-Type": "application/json"
The script should:
- Load Bright Data credentials from environment variables using python-dotenv
- Use the Bright Data Web Unlocker API for all HTTP requests (NOT plain requests.get)
- Handle errors gracefully with try/except
- Include a main() function that can be run directly
- Support being scheduled via cron
- Store content hashes to detect changes
Write the complete script to {script_path}.
"""
# Create OpenHands agent with terminal and file editor tools
agent = Agent(
llm=self.llm,
tools=[
Tool(name=TerminalTool.name),
Tool(name=FileEditorTool.name),
],
)
# Run the agent to generate the script
conversation = Conversation(agent=agent, workspace=self.workspace)
conversation.send_message(prompt)
conversation.run()
return MonitoringScript(
vendor_name=vendor_name,
script_path=script_path,
urls_monitored=urls[:5],
check_frequency="daily",
created_at=datetime.now(UTC).isoformat(),
)
def export_assessment(self, assessment: RiskAssessment, output_path: str) -> None:
"""Export risk assessment to JSON file."""
with open(output_path, "w") as f:
json.dump(asdict(assessment), f, indent=2)与简单的“单次 Prompt 生成代码”相比,使用 OpenHands SDK 的优势在于代理可以对自己的工作进行迭代:运行脚本、修复错误并持续改进,直到脚本真正可用。
代理编排
现在将所有模块串联起来。创建 src/agent.py:
from dataclasses import dataclass
from datetime import datetime, UTC
from typing import Optional
from discovery import DiscoveryClient, SearchResult
from access import AccessClient, ExtractedContent
from actions import ActionsClient, RiskAssessment, MonitoringScript
@dataclass
class InvestigationResult:
vendor_name: str
started_at: str
completed_at: str
total_sources_found: int
total_sources_accessed: int
risk_assessments: list[RiskAssessment]
monitoring_scripts: list[MonitoringScript]
errors: list[str]
class TPRMAgent:
"""Autonomous agent for Third-Party Risk Management investigations."""
def __init__(self):
self.discovery = DiscoveryClient()
self.access = AccessClient()
self.actions = ActionsClient()
def investigate(
self,
vendor_name: str,
categories: Optional[list[str]] = None,
generate_monitors: bool = True,
) -> InvestigationResult:
"""Run a complete vendor investigation."""
started_at = datetime.now(UTC).isoformat()
errors = []
risk_assessments = []
monitoring_scripts = []
# Stage 1: Discovery (SERP API)
print(f"[Discovery] Searching for adverse media about {vendor_name}...")
try:
raw_results = self.discovery.discover_adverse_media(vendor_name, categories)
filtered_results = self.discovery.filter_relevant_results(raw_results, vendor_name)
except Exception as e:
errors.append(f"Discovery failed: {str(e)}")
return InvestigationResult(
vendor_name=vendor_name,
started_at=started_at,
completed_at=datetime.now(UTC).isoformat(),
total_sources_found=0,
total_sources_accessed=0,
risk_assessments=[],
monitoring_scripts=[],
errors=errors,
)
total_sources = sum(len(results) for results in filtered_results.values())
print(f"[Discovery] Found {total_sources} relevant sources")
# Stage 2: Access (Web Unlocker)
print(f"[Access] Extracting content from sources...")
all_urls = []
url_to_category = {}
for category, results in filtered_results.items():
for result in results:
all_urls.append(result.url)
url_to_category[result.url] = category
try:
extracted_content = self.access.fetch_multiple(all_urls)
successful_extractions = [c for c in extracted_content if c.success]
except Exception as e:
error_msg = f"Access failed: {str(e)}"
print(f"[Access] {error_msg}")
errors.append(error_msg)
successful_extractions = []
print(f"[Access] Successfully extracted {len(successful_extractions)} sources")
# Stage 3: Action - Analyze risks (OpenAI)
print(f"[Action] Analyzing risks...")
category_content = {}
for content in successful_extractions:
category = url_to_category.get(content.url, "unknown")
if category not in category_content:
category_content[category] = []
category_content[category].append({
"url": content.url,
"title": content.title,
"text": content.text,
})
for category, content_list in category_content.items():
if not content_list:
continue
try:
assessment = self.actions.analyze_risk(vendor_name, category, content_list)
risk_assessments.append(assessment)
except Exception as e:
errors.append(f"Risk analysis failed for {category}: {str(e)}")
# Stage 3: Action - Generate monitoring scripts
if generate_monitors and successful_extractions:
print(f"[Action] Generating monitoring scripts...")
try:
urls_to_monitor = [c.url for c in successful_extractions[:10]]
keywords = [vendor_name, "lawsuit", "bankruptcy", "fraud"]
script = self.actions.generate_monitoring_script(
vendor_name, urls_to_monitor, keywords
)
monitoring_scripts.append(script)
except Exception as e:
errors.append(f"Script generation failed: {str(e)}")
completed_at = datetime.now(UTC).isoformat()
print(f"[Complete] Investigation finished")
return InvestigationResult(
vendor_name=vendor_name,
started_at=started_at,
completed_at=completed_at,
total_sources_found=total_sources,
total_sources_accessed=len(successful_extractions),
risk_assessments=risk_assessments,
monitoring_scripts=monitoring_scripts,
errors=errors,
)
def main():
"""Example usage."""
agent = TPRMAgent()
result = agent.investigate("Acme Corp")
print(f"\n{'='*50}")
print(f"Investigation Complete: {result.vendor_name}")
print(f"Sources Found: {result.total_sources_found}")
print(f"Sources Accessed: {result.total_sources_accessed}")
print(f"Risk Assessments: {len(result.risk_assessments)}")
print(f"Monitoring Scripts: {len(result.monitoring_scripts)}")
for assessment in result.risk_assessments:
print(f"\n[{assessment.category.upper()}] Severity: {assessment.severity}")
print(f"Summary: {assessment.summary}")
if __name__ == "__main__":
main()该代理协调三个层次的流程,优雅地处理错误,并输出一份完整的调查结果。
配置
创建 src/config.py 来配置应用运行所需的密钥与凭据:
import os
from dotenv import load_dotenv
load_dotenv()
class Settings:
# SERP API
BRIGHT_DATA_API_TOKEN: str = os.getenv("BRIGHT_DATA_API_TOKEN", "")
BRIGHT_DATA_SERP_ZONE: str = os.getenv("BRIGHT_DATA_SERP_ZONE", "")
# Web Unlocker
BRIGHT_DATA_CUSTOMER_ID: str = os.getenv("BRIGHT_DATA_CUSTOMER_ID", "")
BRIGHT_DATA_UNLOCKER_ZONE: str = os.getenv("BRIGHT_DATA_UNLOCKER_ZONE", "")
BRIGHT_DATA_UNLOCKER_PASSWORD: str = os.getenv("BRIGHT_DATA_UNLOCKER_PASSWORD", "")
# OpenAI (for risk analysis)
OPENAI_API_KEY: str = os.getenv("OPENAI_API_KEY", "")
# OpenHands (for agentic script generation)
LLM_API_KEY: str = os.getenv("LLM_API_KEY", "")
LLM_MODEL: str = os.getenv("LLM_MODEL", "openhands/claude-sonnet-4-5-20260929")
settings = Settings()构建 API 层
使用 FastAPI 创建 api/main.py,通过 REST 接口对外暴露代理能力:
from fastapi import FastAPI, HTTPException, BackgroundTasks
from pydantic import BaseModel
from typing import Optional
import uuid
import sys
sys.path.insert(0, 'src')
from agent import TPRMAgent, InvestigationResult
app = FastAPI(
title="TPRM Agent API",
description="Autonomous Third-Party Risk Management Agent",
version="1.0.0",
)
investigations: dict[str, InvestigationResult] = {}
agent = TPRMAgent()
class InvestigationRequest(BaseModel):
vendor_name: str
categories: Optional[list[str]] = None
generate_monitors: bool = True
class InvestigationResponse(BaseModel):
investigation_id: str
status: str
message: str
@app.post("/investigate", response_model=InvestigationResponse)
def start_investigation(
request: InvestigationRequest,
background_tasks: BackgroundTasks,
):
"""Start a new vendor investigation."""
investigation_id = str(uuid.uuid4())
def run_investigation():
result = agent.investigate(
vendor_name=request.vendor_name,
categories=request.categories,
generate_monitors=request.generate_monitors,
)
investigations[investigation_id] = result
background_tasks.add_task(run_investigation)
return InvestigationResponse(
investigation_id=investigation_id,
status="started",
message=f"Investigation started for {request.vendor_name}",
)
@app.get("/investigate/{investigation_id}")
def get_investigation(investigation_id: str):
"""Get investigation results."""
if investigation_id not in investigations:
raise HTTPException(status_code=404, detail="Investigation not found or still in progress")
return investigations[investigation_id]
@app.get("/reports/{vendor_name}")
def get_reports(vendor_name: str):
"""Get all reports for a vendor."""
vendor_reports = [
result
for result in investigations.values()
if result.vendor_name.lower() == vendor_name.lower()
]
if not vendor_reports:
raise HTTPException(status_code=404, detail="No reports found for this vendor")
return vendor_reports
@app.get("/health")
def health_check():
"""Health check endpoint."""
return {"status": "healthy"}本地运行 API:
python -m uvicorn api.main:app --reload访问 http://localhost:8000/docs 查看交互式 API 文档。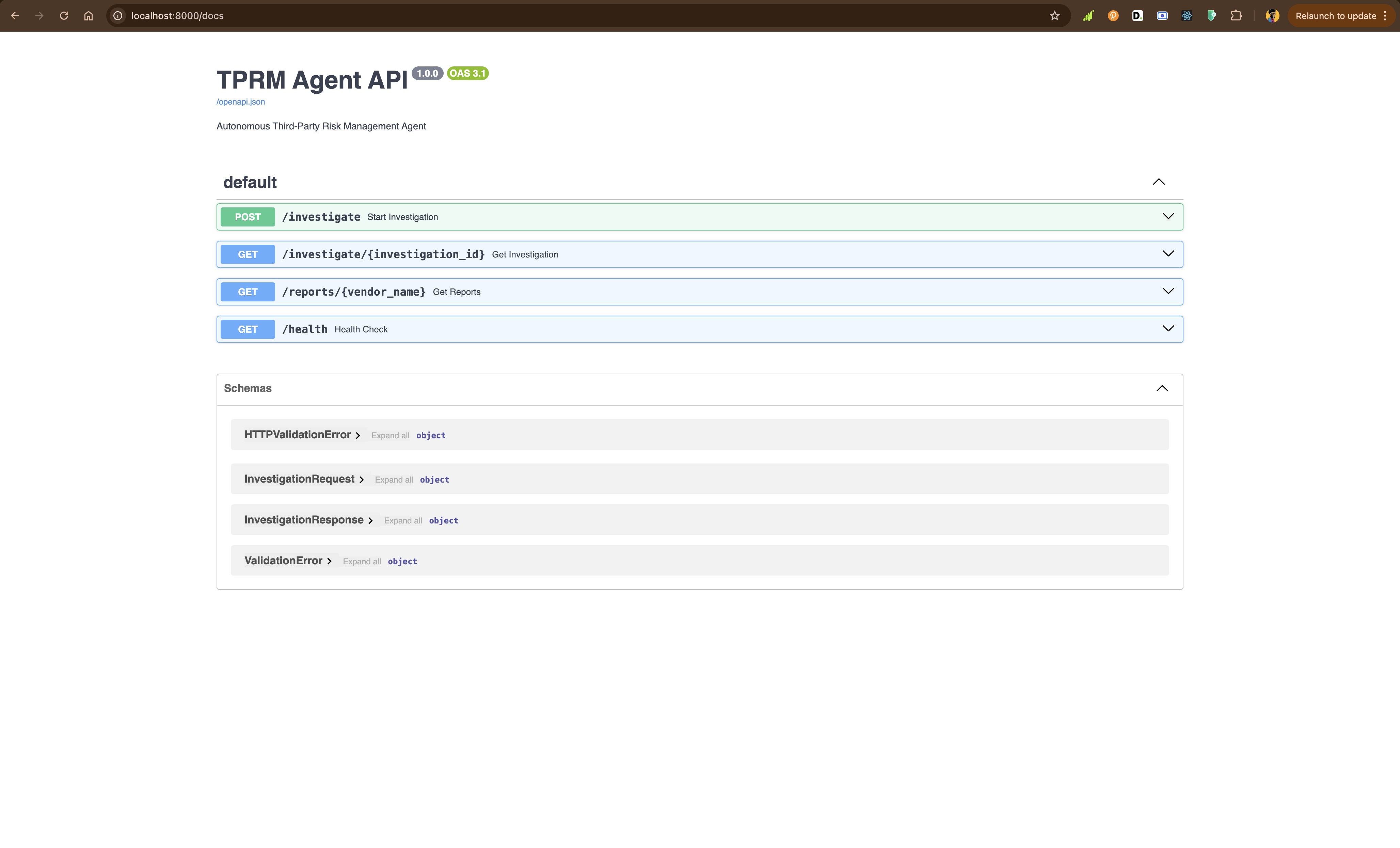
使用 Browser API(Scraping Browser)增强能力
对于法院登记处等需要表单提交,或大量 JavaScript 渲染的网站,可以通过 Bright Data 的 Browser API(Scraping Browser)增强代理能力。其设置方式与 Web Unlocker API 和 SERP API 类似。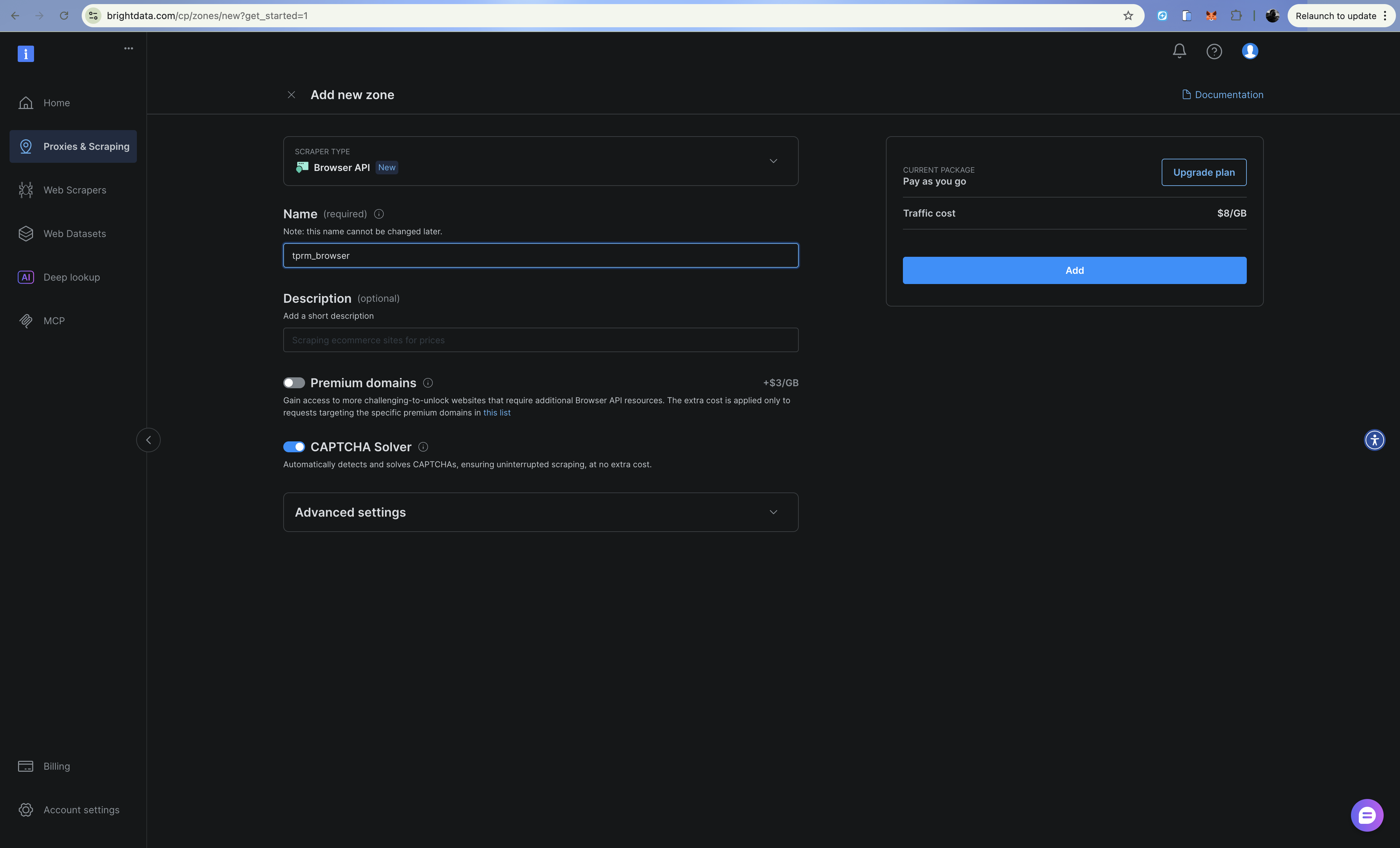
Browser API 提供了云托管浏览器,你可以通过 Playwright 和 Chrome DevTools Protocol(CDP)进行控制,适用于:
- 法院登记检索,需要表单填写和多步导航
- 高度依赖 JavaScript 的网站,比如动态加载内容
- 多步认证流程
- 截图采集,用于合规存证
配置
在 .env 中添加 Browser API 凭据:
# Browser API
BRIGHT_DATA_BROWSER_USER: str = os.getenv("BRIGHT_DATA_BROWSER_USER", "")
BRIGHT_DATA_BROWSER_PASSWORD: str = os.getenv("BRIGHT_DATA_BROWSER_PASSWORD", "")Browser 客户端实现
创建 src/browser.py:
import asyncio
from playwright.async_api import async_playwright
from dataclasses import dataclass
from typing import Optional
from config import settings
@dataclass
class BrowserContent:
url: str
title: str
text: str
screenshot_path: Optional[str]
success: bool
error: Optional[str] = None
class BrowserClient:
"""Access dynamic content using Bright Data Browser API (Scraping Browser).
Use this for:
- JavaScript-heavy sites that require full rendering
- Multi-step forms (e.g., court registry searches)
- Sites requiring clicks, scrolling, or interaction
- Capturing screenshots for compliance documentation
"""
def __init__(self):
# Build WebSocket endpoint for CDP connection
auth = f"{settings.BRIGHT_DATA_BROWSER_USER}:{settings.BRIGHT_DATA_BROWSER_PASSWORD}"
self.endpoint_url = f"wss://{auth}@brd.superproxy.io:9222"
async def fetch_dynamic_page(
self,
url: str,
wait_for_selector: Optional[str] = None,
take_screenshot: bool = False,
screenshot_path: Optional[str] = None,
) -> BrowserContent:
"""Fetch content from a dynamic page using Browser API."""
async with async_playwright() as playwright:
try:
print(f"Connecting to Bright Data Scraping Browser...")
browser = await playwright.chromium.connect_over_cdp(self.endpoint_url)
try:
page = await browser.new_page()
print(f"Navigating to {url}...")
await page.goto(url, timeout=120000)
# Wait for specific selector if provided
if wait_for_selector:
await page.wait_for_selector(wait_for_selector, timeout=30000)
# Get page content
title = await page.title()
# Extract text
text = await page.evaluate("() => document.body.innerText")
# Take screenshot if requested
if take_screenshot and screenshot_path:
await page.screenshot(path=screenshot_path, full_page=True)
return BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=screenshot_path if take_screenshot else None,
success=True,
)
finally:
await browser.close()
except Exception as e:
return BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
async def fill_and_submit_form(
self,
url: str,
form_data: dict[str, str],
submit_selector: str,
result_selector: str,
) -> BrowserContent:
"""Fill a form and get results - useful for court registries."""
async with async_playwright() as playwright:
try:
browser = await playwright.chromium.connect_over_cdp(self.endpoint_url)
try:
page = await browser.new_page()
await page.goto(url, timeout=120000)
# Fill form fields
for selector, value in form_data.items():
await page.fill(selector, value)
# Submit form
await page.click(submit_selector)
# Wait for results
await page.wait_for_selector(result_selector, timeout=30000)
title = await page.title()
text = await page.evaluate("() => document.body.innerText")
return BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=None,
success=True,
)
finally:
await browser.close()
except Exception as e:
return BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
async def scroll_and_collect(
self,
url: str,
scroll_count: int = 5,
wait_between_scrolls: float = 1.0,
) -> BrowserContent:
"""Handle infinite scroll pages."""
async with async_playwright() as playwright:
try:
browser = await playwright.chromium.connect_over_cdp(self.endpoint_url)
try:
page = await browser.new_page()
await page.goto(url, timeout=120000)
# Scroll down multiple times
for i in range(scroll_count):
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
await asyncio.sleep(wait_between_scrolls)
title = await page.title()
text = await page.evaluate("() => document.body.innerText")
return BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=None,
success=True,
)
finally:
await browser.close()
except Exception as e:
return BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
# Example usage for court registry search
async def example_court_search():
client = BrowserClient()
# Example: Search a court registry
result = await client.fill_and_submit_form(
url="https://example-court-registry.gov/search",
form_data={
"#party-name": "Acme Corp",
"#case-type": "civil",
},
submit_selector="#search-button",
result_selector=".search-results",
)
if result.success:
print(f"Found court records: {result.text[:500]}")
else:
print(f"Error: {result.error}")
if __name__ == "__main__":
asyncio.run(example_court_search())
何时使用 Browser API,何时使用 Web Unlocker
| 场景 | 选择 |
|---|---|
| 简单 HTTP 请求 | Web Unlocker |
| 静态 HTML 页面 | Web Unlocker |
| 页面加载时触发验证码 | Web Unlocker |
| JavaScript 渲染内容 | Browser API |
| 需要表单提交 | Browser API |
| 多步导航流程 | Browser API |
| 需要截图 | Browser API |
使用 Railway 部署
你可以使用 Railway 或 Render 将 TPRM 代理部署到生产环境,这两种平台都支持依赖较重的 Python 应用。
Railway 对于包含 OpenHands SDK 等大型依赖的 Python 应用来说是最简单的部署选项。你需要先注册并创建账号。
步骤一:全局安装 Railway CLI
npm i -g @railway/cli步骤二:添加 Procfile
在项目根目录创建 Procfile 并添加以下内容,作为启动命令配置:
web: uvicorn api.main:app --host 0.0.0.0 --port $PORT步骤三:登录并在项目目录初始化 Railway
railway login
railway init步骤四:部署
railway up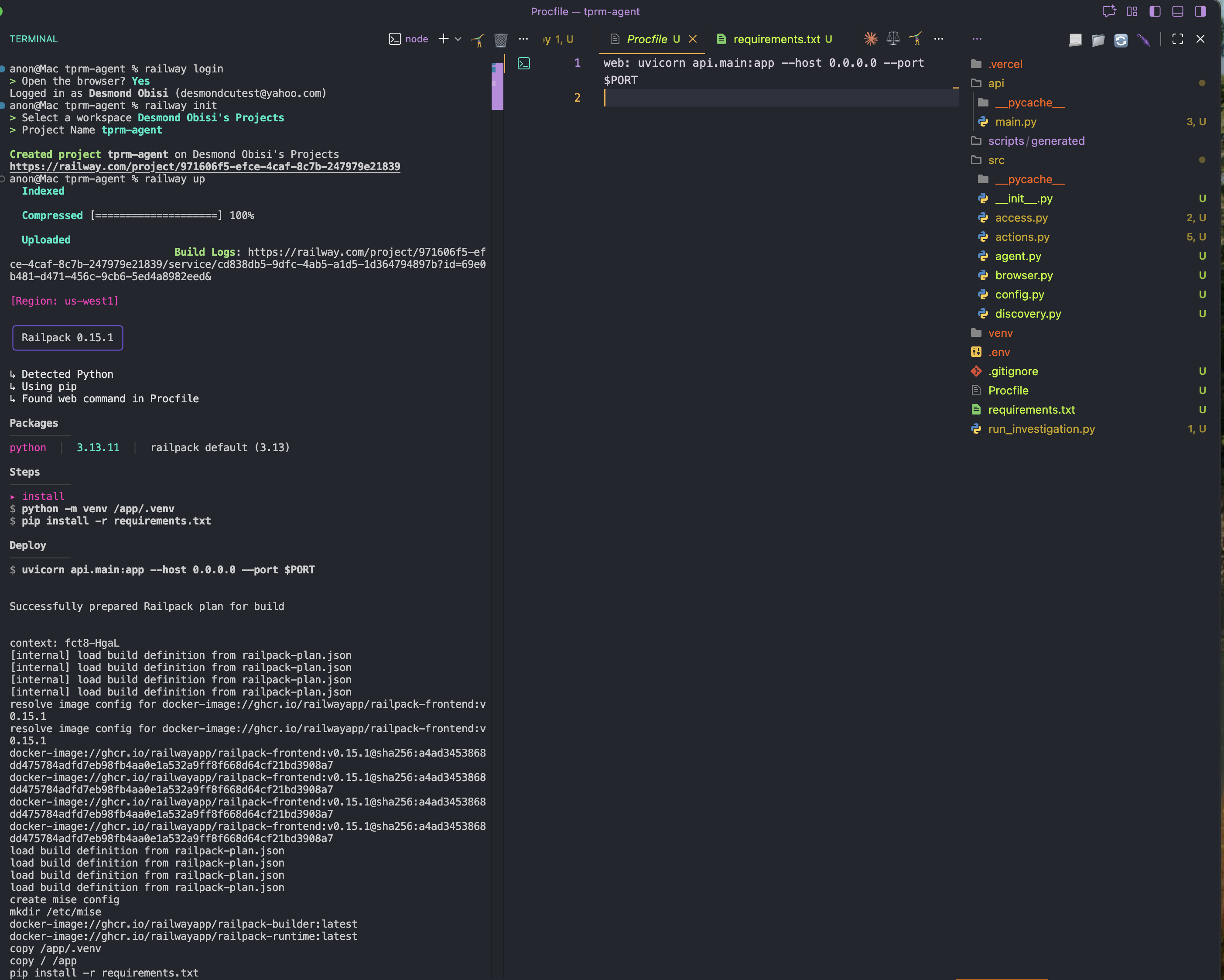
步骤五:添加环境变量
进入 Railway 项目控制台 → Settings → Shared Variables,添加如下环境变量及其值:
BRIGHT_DATA_API_TOKEN
BRIGHT_DATA_SERP_ZONE
BRIGHT_DATA_UNLOCKER_ZONE
OPENAI_API_KEY
LLM_API_KEY
LLM_MODEL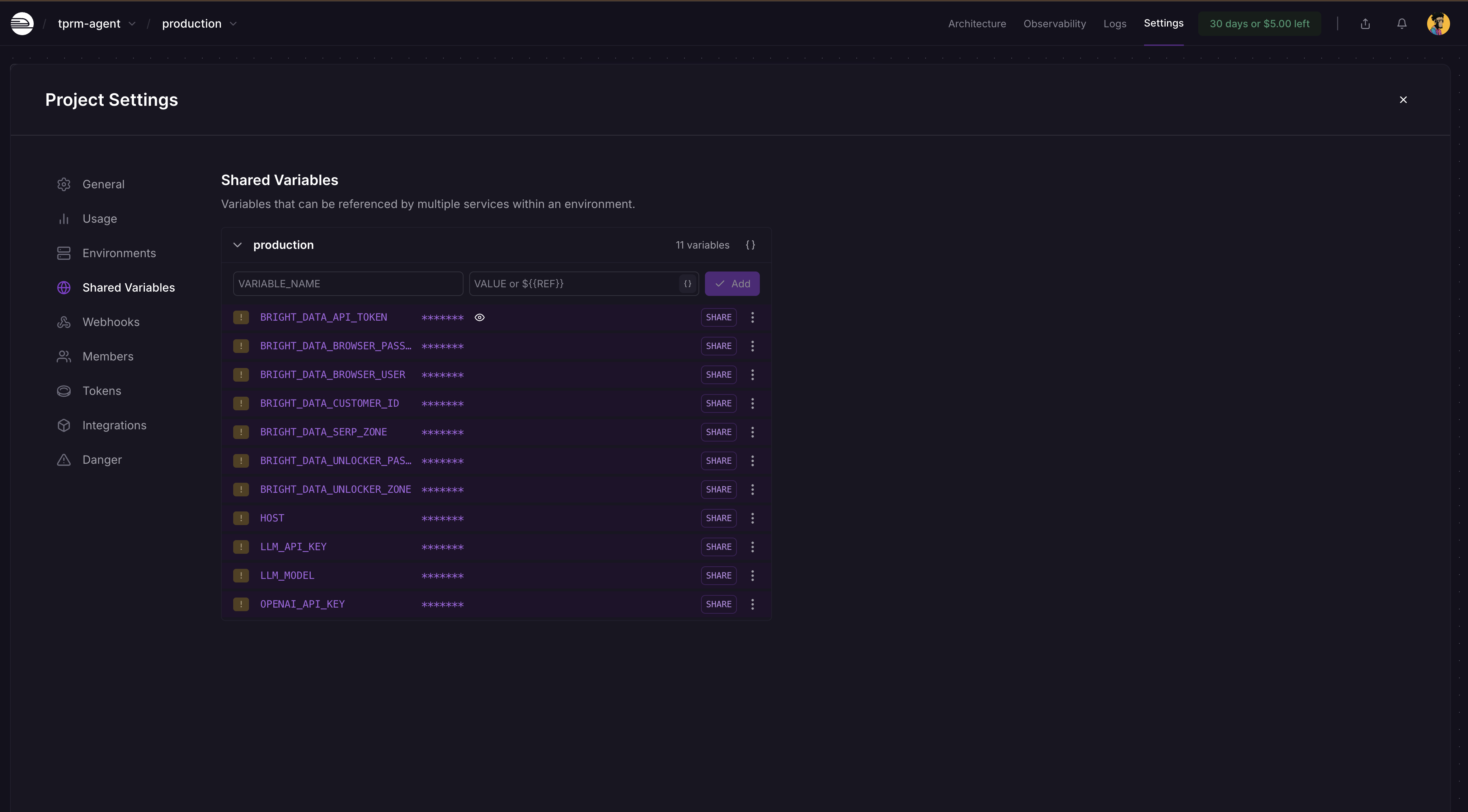
Railway 会自动检测到变更并在控制台提示你重新部署。点击 Deploy 即可用新密钥更新应用。
重新部署完成后,点击服务卡片并选择 Settings,即可看到生成域名的入口。点击 Generate domain 获取公共访问 URL。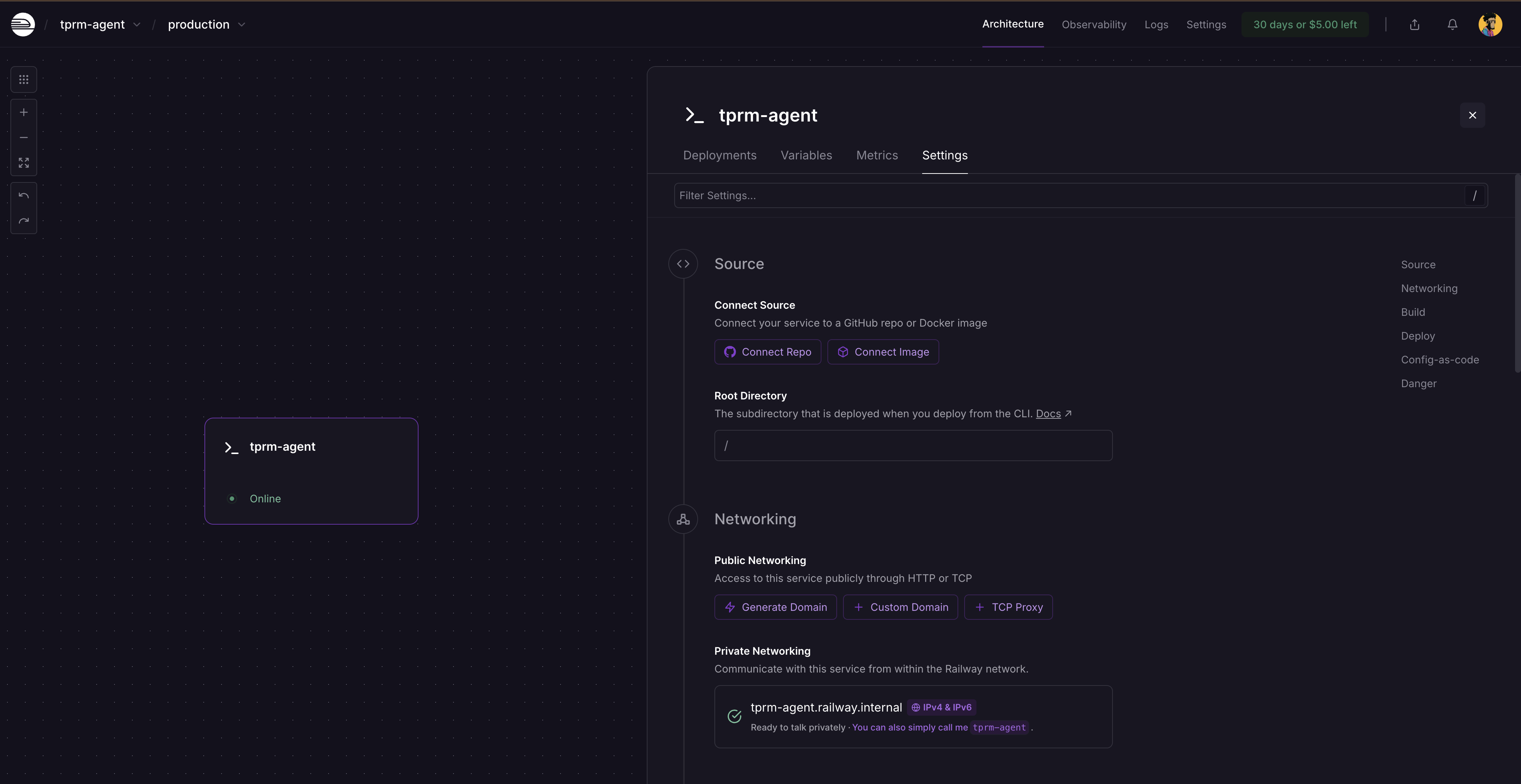
运行完整调查
在本地使用 curl 运行
启动 FastAPI 服务:
# Activate your virtual environment
source venv/bin/activate # On Windows: venv\Scripts\activate
# Run the server
python -m uvicorn api.main:app --reload访问 http://localhost:8000/docs 浏览交互式 API 文档。
发起 API 请求
- 发起一次调查:
curl -X POST "http://localhost:8000/investigate" \
-H "Content-Type: application/json" \
-d '{
"vendor_name": "Acme Corp",
"categories": ["litigation", "fraud"],
"generate_monitors": true
}'- 返回的结果包含调查 ID:
{
"investigation_id": "f6af2e0f-991a-4cb7-949e-2f316e677b5c",
"status": "started",
"message": "Investigation started for Acme Corp"
}- 查询调查状态:
curl http://localhost:8000/investigate/f6af2e0f-991a-4cb7-949e-2f316e677b5c以脚本方式运行代理
在项目根目录创建 run_investigation.py:
import sys
sys.path.insert(0, 'src')
from agent import TPRMAgent
def investigate_vendor():
"""Run a complete vendor investigation."""
agent = TPRMAgent()
# Run investigation
result = agent.investigate(
vendor_name="Acme Corp",
categories=["litigation", "financial", "fraud"],
generate_monitors=True,
)
# Print summary
print(f"\n{'='*60}")
print(f"Investigation Complete: {result.vendor_name}")
print(f"{'='*60}")
print(f"Sources Found: {result.total_sources_found}")
print(f"Sources Accessed: {result.total_sources_accessed}")
print(f"Risk Assessments: {len(result.risk_assessments)}")
print(f"Monitoring Scripts: {len(result.monitoring_scripts)}")
# Print risk assessments
for assessment in result.risk_assessments:
print(f"\n{'─'*60}")
print(f"[{assessment.category.upper()}] Severity: {assessment.severity.upper()}")
print(f"{'─'*60}")
print(f"Summary: {assessment.summary}")
print("\nKey Findings:")
for finding in assessment.key_findings:
print(f" • {finding}")
print("\nRecommended Actions:")
for action in assessment.recommended_actions:
print(f" → {action}")
# Print monitoring script info
for script in result.monitoring_scripts:
print(f"\n{'='*60}")
print(f"Generated Monitoring Script")
print(f"{'='*60}")
print(f"Path: {script.script_path}")
print(f"Monitoring {len(script.urls_monitored)} URLs")
print(f"Frequency: {script.check_frequency}")
# Print errors if any
if result.errors:
print(f"\n{'='*60}")
print("Errors:")
for error in result.errors:
print(f" ⚠️ {error}")
if __name__ == "__main__":
investigate_vendor()在新终端运行调查脚本:
# Activate your virtual environment
source venv/bin/activate # On Windows: venv\Scripts\activate
# Run the investigation script
python run_investigation.py代理将会:
- 使用 SERP API 在 Google 搜索不利舆情
- 使用 Web Unlocker 访问源站内容
- 利用 OpenAI 评估风险严重程度
- 使用 OpenHands SDK 生成可通过 cron 调度的 Python 监控脚本
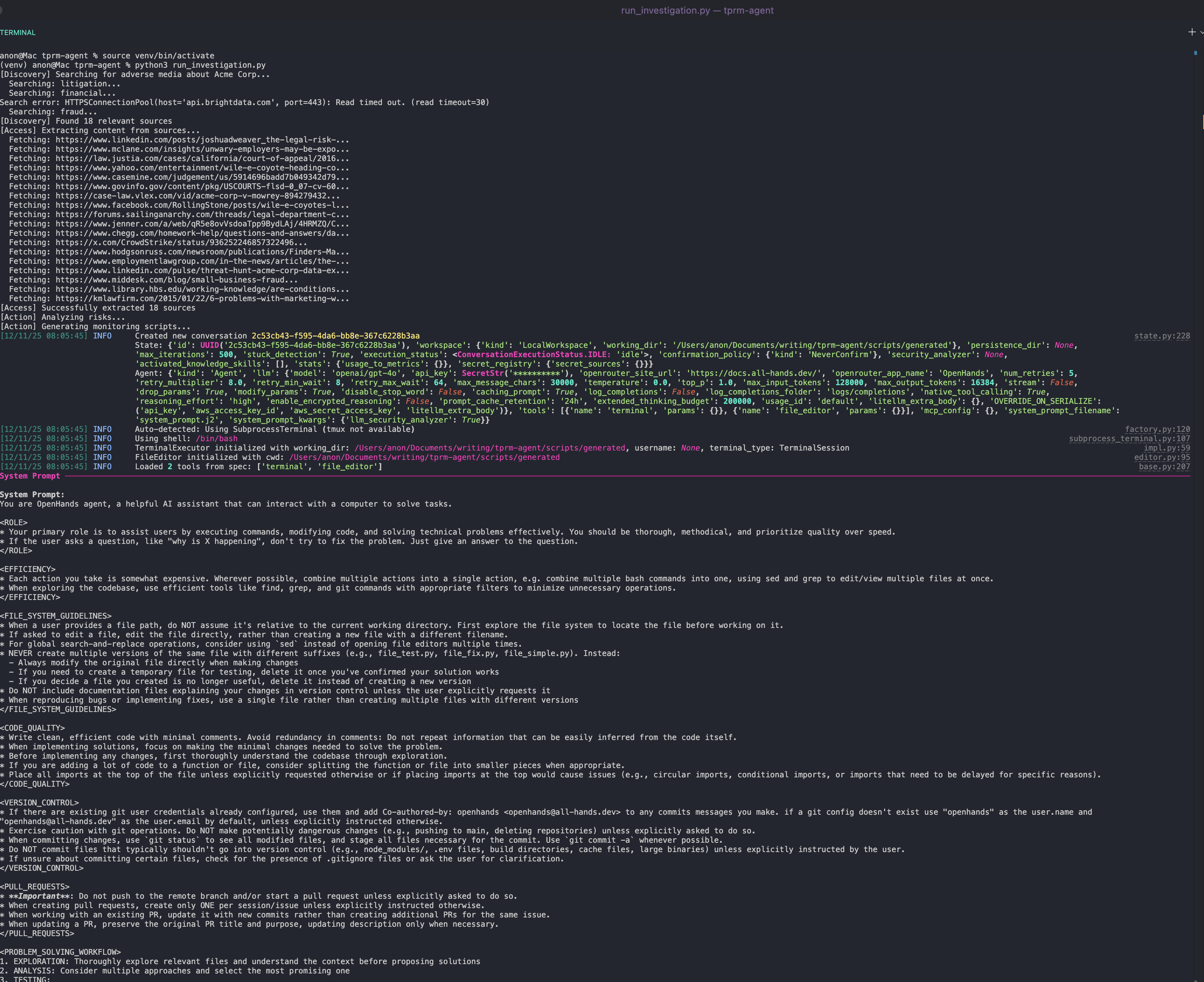
运行自动生成的监控脚本
调查完成后,你会在 scripts/generated 目录中看到生成的监控脚本:
cd scripts/generated
python monitor_acme_corp.py该监控脚本会使用 Bright Data Web Unlocker API 检查所有监控 URL,并输出运行结果: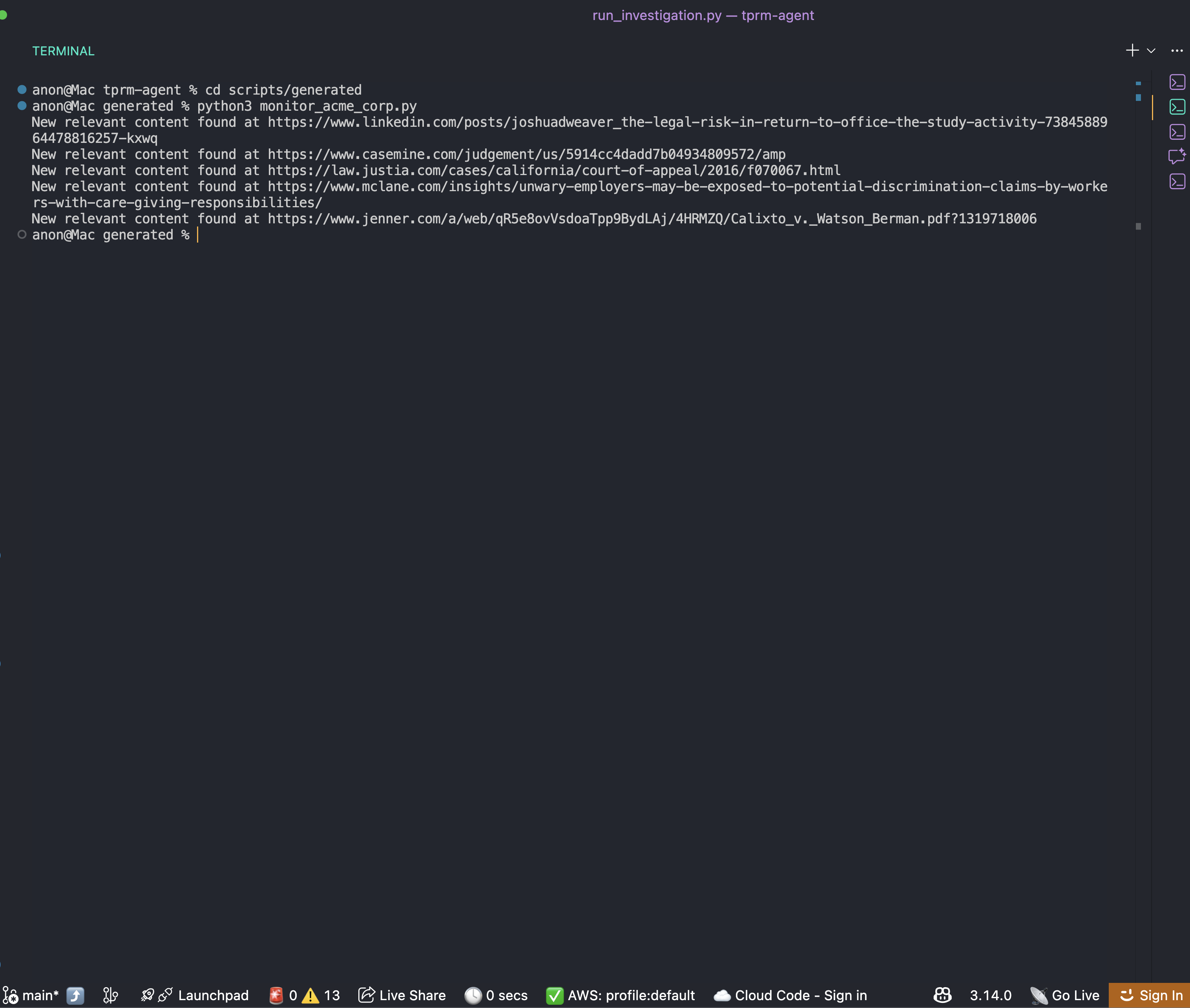
你可以配合 cron 等调度工具定时运行该脚本,从而随时掌握供应商最新风险信息。
总结
你现在已经拥有一整套用于构建企业级 TPRM 代理的框架,可以自动化完成供应商不利舆情调查。该系统可以:
- 通过 Bright Data SERP API 发现 多类别风险信号
- 通过 Bright Data Web Unlocker 访问 内容
- 使用 OpenAI 分析 风险,并通过 OpenHands SDK 生成监控脚本
- 通过 Browser API 在复杂场景中进一步 增强 能力
模块化架构使其易于扩展:
- 通过更新
RISK_CATEGORIES字典添加新的风险类别 - 扩展 API 层以与现有 GRC 平台集成
- 利用后台任务队列扩展到成千上万家供应商
- 通过 Browser API 添加法院登记等高级检索能力
下一步
若要进一步提升该代理,可以考虑:
- 集成更多数据源:例如 SEC 披露文件、OFAC 制裁名单、工商登记信息等
- 加入数据库持久化:将调查历史存入 PostgreSQL 或 MongoDB
- 实现 webhook 通知:在发现高风险供应商时推送 Slack 或 Teams 警报
- 构建可视化看板:用 React 等框架构建前端展示供应商风险评分
- 调度自动扫描:使用 Celery 或 APScheduler 做周期性供应商监控
参考资源



AI 内容创作者
Arindam Majumder 是一名开发者推广专员、YouTube博主和技术作家,专注于将大语言模型 (LLM)、智能体工作流及 AI 内容讲解得简单易懂,拥有超过5000名关注者。





