

构建可靠的网页数据提取方案需要从正确的基础设施开始。在本指南中,你将创建一个单页应用,接受任意公开网页 URL 和自然语言提示,然后进行抓取、解析,并返回干净、结构化的 JSON,实现端到端自动化的提取流程。
该技术栈将 Bright Data 的反机器人抓取基础设施、Supabase 的安全后端,以及 Lovable 的快速开发工具整合为一个无缝工作流。
你将构建什么
以下是你将构建的完整数据管道——从用户输入到结构化 JSON 输出与存储:
用户输入
↓
认证
↓
数据库日志记录
↓
Edge Function
↓
Bright Data Web Unlocker(绕过反机器人防护)
↓
原始 HTML
↓
Turndown(HTML → Markdown)
↓
干净的结构化文本
↓
Google Gemini AI(自然语言处理)
↓
结构化 JSON
↓
数据库存储
↓
前端展示
↓
用户导出下面是完成后的应用快速预览:
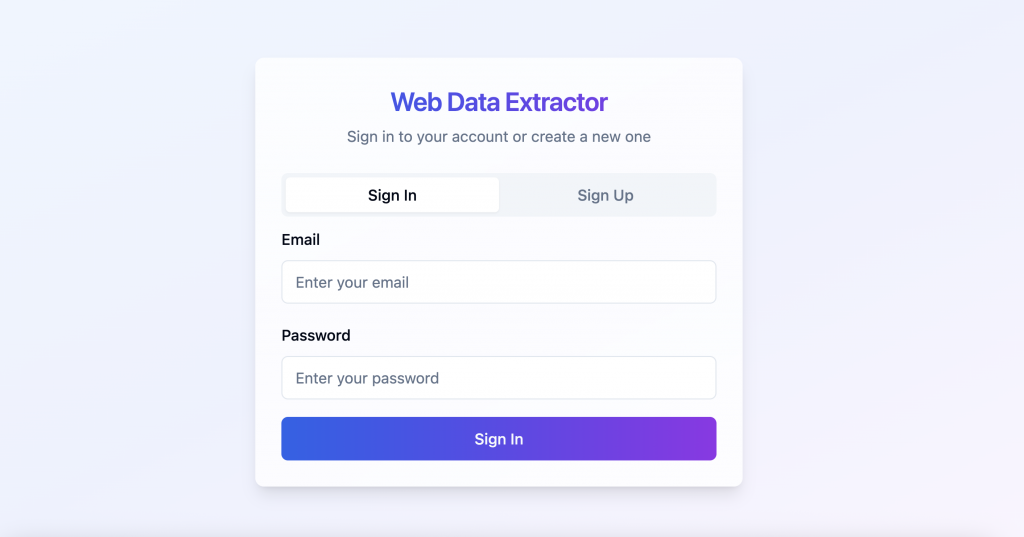
用户认证:用户可以通过 Supabase 提供的认证界面安全注册或登录。
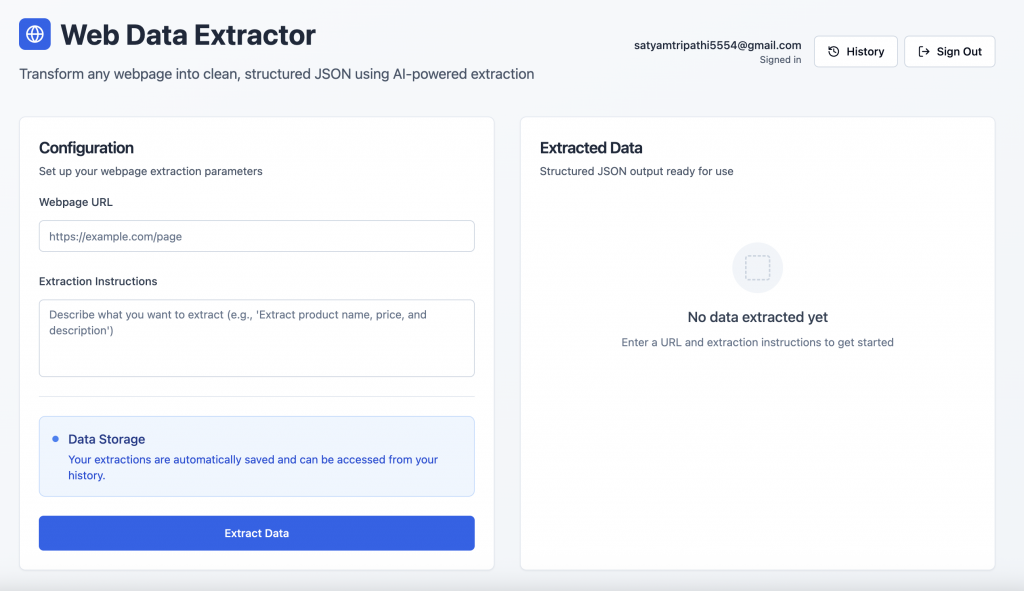
数据提取界面:登录后,用户可以输入网页 URL 和自然语言提示以获取结构化数据。
技术栈概览
以下是我们所用技术栈及其各自带来的战略优势。
- Bright Data:网页抓取常会遭遇封禁、验证码以及高级机器人检测。Bright Data 专为应对这些挑战而生,提供:
- 自动代理轮换
- 验证码求解与反机器人防护
- 全球基础设施,确保访问稳定
- 对动态内容进行 JavaScript 渲染
- 自动速率限制处理
在本指南中,我们将使用Bright Data 的 Web Unlocker—一款专为从高度受保护页面可靠抓取完整 HTML 而打造的工具。
- Supabase:Supabase 为现代应用提供安全的后端基础,包括:
- 内置认证与会话管理
- 支持实时的 PostgreSQL 数据库
- 用于无服务器逻辑的 Edge Functions
- 安全的密钥存储与访问控制
- Lovable:Lovable 通过 AI 驱动工具与原生 Supabase 集成简化开发,提供:
- AI 驱动的代码生成
- 无缝的前后端脚手架
- 开箱即用的 React + Tailwind UI
- 快速原型,面向生产就绪
- Google Gemini AI:Gemini 利用自然语言提示将原始 HTML 转换为结构化 JSON,支持:
- 准确的内容理解与解析
- 对整页内容的大输入支持
- 可扩展、具性价比的数据提取
前提条件与设置
在开始开发前,请确保你具备以下条件:
- Bright Data 账户
- 在 brightdata.com 注册
- 创建一个 Web Unlocker 区域(zone)
- 在账户设置中获取你的 API 密钥
- Google AI Studio 账户
- 访问 Google AI Studio
- 创建一个新的 API 密钥
- Supabase 项目
- 在 supabase.com 注册
- 创建一个新组织,然后新建项目
- 在项目面板中,进入 Edge Functions → Secrets → Add New Secret。添加
BRIGHT_DATA_API_KEY与GEMINI_API_KEY等密钥及其值
- Lovable 账户
- 在 lovable.dev 注册
- 进入你的个人资料 → Settings → Integrations
- 在 Supabase 下点击 Connect Supabase
- 授权 API 访问,并将其关联到你刚创建的 Supabase 组织
使用 Lovable 提示逐步构建应用
下面是一套结构化、基于提示的开发流程,涵盖前端、后端、数据库与智能解析。
步骤一 – 前端搭建
先设计一个简洁直观的用户界面。
Build a modern web data extraction app using React and Tailwind CSS. The UI should include:
- A gradient background with card-style layout
- An input field for the webpage URL
- A textarea for the extraction prompt (e.g., "Extract product title, price, and ratings")
- A display area to render structured JSON output
- Responsive styling with hover effects and proper spacing步骤二 – 连接 Supabase 并添加认证
将你的 Supabase 项目连接到应用:
- 点击 Lovable 右上角的 Supabase 图标
- 选择 Connect Supabase
- 选择你之前创建的组织和项目
Lovable 会自动集成你的 Supabase 项目。连接完成后,使用如下提示启用认证:
Set up complete Supabase authentication:
- Sign up and login forms using email/password
- Session management and auto-persistence
- Route protection for unauthenticated users
- Sign out functionality
- Create user profile on signup
- Handle all auth-related errorsLovable 会生成所需的 SQL 模式与触发器——审阅并批准它们以完成认证流程。
步骤三 – 定义 Supabase 数据库模式
设置所需数据表以记录并存储提取活动:
Create Supabase tables for storing extractions and results:
- extractions: stores URL, prompt, user_id, status, processing_time, error_message
- extraction_results: stores parsed JSON output
Apply RLS policies to ensure each user can only access their own data步骤四 – 创建 Supabase Edge Function
该函数负责核心的抓取、转换与提取逻辑:
Create an Edge Function called 'extract-web-data' that:
- Fetches the target page using Bright Data's Web Unlocker
- Converts raw HTML to Markdown using Turndown
- Sends the Markdown and prompt to Google Gemini AI (gemini-2.0-flash-001)
- Returns clean structured JSON
- Handles CORS, errors, and response formatting
- Requires GEMINI_API_KEY and BRIGHT_DATA_API_KEY as Edge Function secrets
Below is a reference implementation that handles HTML fetching using Bright Data, markdown conversion with Turndown, and AI-driven extraction with Gemini:
import { GoogleGenerativeAI } from '@google/generative-ai';
import TurndownService from 'turndown';
interface BrightDataConfig {
apiKey: string;
zone: string;
}
// Constants
const GEMINI_MODEL = 'gemini-2.0-flash-001';
const WEB_UNLOCKER_ZONE = 'YOUR_WEB_UNLOCKER_ZONE';
export class WebContentExtractor {
private geminiClient: GoogleGenerativeAI;
private modelName: string;
private htmlToMarkdownConverter: TurndownService;
private brightDataConfig: BrightDataConfig;
constructor() {
const geminiApiKey: string = 'GEMINI_API_KEY';
const brightDataApiKey: string = 'BRIGHT_DATA_API_KEY';
try {
this.geminiClient = new GoogleGenerativeAI(geminiApiKey);
this.modelName = GEMINI_MODEL;
this.htmlToMarkdownConverter = new TurndownService();
this.brightDataConfig = {
apiKey: brightDataApiKey,
zone: WEB_UNLOCKER_ZONE
};
} catch (error) {
console.error('Failed to initialize WebContentExtractor:', error);
throw error;
}
}
/**
* Fetches webpage content using Bright Data Web Unlocker service
*/
async fetchContentViaBrightData(targetUrl: string): Promise<string | null> {
try {
// Append Web Unlocker parameters to the target URL
const urlSeparator: string = targetUrl.includes('?') ? '&' : '?';
const requestUrl: string = `${targetUrl}${urlSeparator}product=unlocker&method=api`;
const apiResponse = await fetch('https://api.brightdata.com/request', {
method: 'POST',
headers: {
'Authorization': `Bearer ${this.brightDataConfig.apiKey}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
zone: this.brightDataConfig.zone,
url: requestUrl,
format: 'raw'
})
});
if (!apiResponse.ok) {
throw new Error(`Web Unlocker request failed with status: ${apiResponse.status}`);
}
const htmlContent: string = await apiResponse.text();
return htmlContent && htmlContent.length > 0 ? htmlContent : null;
} catch (error) {
console.error('Failed to fetch webpage content:', error);
return null;
}
}
/**
* Converts HTML to clean Markdown format for better AI processing
*/
async convertToMarkdown(htmlContent: string): Promise<string | null> {
try {
const markdownContent: string = this.htmlToMarkdownConverter.turndown(htmlContent);
return markdownContent;
} catch (error) {
console.error('Failed to convert HTML to Markdown:', error);
return null;
}
}
/**
* Uses Gemini AI to extract specific information from markdown content
* Uses low temperature for more consistent, factual responses
*/
async extractInformationWithAI(markdownContent: string, userQuery: string): Promise<string | null> {
try {
const aiPrompt: string = this.buildAIPrompt(userQuery, markdownContent);
const aiModel = this.geminiClient.getGenerativeModel({ model: this.modelName });
const aiResult = await aiModel.generateContent({
contents: [{ role: 'user', parts: [{ text: aiPrompt }] }],
generationConfig: {
maxOutputTokens: 2048,
temperature: 0.1,
}
});
const response = await aiResult.response;
return response.text();
} catch (error) {
console.error('Failed to extract information with AI:', error);
return null;
}
}
private buildAIPrompt(userQuery: string, markdownContent: string): string {
return `You are a data extraction assistant. Below is some content in markdown format extracted from a webpage.
Please analyze this content and extract the information requested by the user.
USER REQUEST: ${userQuery}
MARKDOWN CONTENT:
${markdownContent}
Please provide a clear, structured response based on the user's request. If the requested information is not available in the content, please indicate that clearly.`;
}
/**
* Main extraction workflow: fetches webpage → converts to markdown → extracts with AI
*/
async extractDataFromUrl(websiteUrl: string, extractionQuery: string): Promise<string | null> {
try {
const htmlContent: string | null = await this.fetchContentViaBrightData(websiteUrl);
if (!htmlContent) {
console.error('Could not retrieve HTML content from URL');
return null;
}
const markdownContent: string | null = await this.convertToMarkdown(htmlContent);
if (!markdownContent) {
console.error('Could not convert HTML to Markdown');
return null;
}
const extractedInformation: string | null = await this.extractInformationWithAI(markdownContent, extractionQuery);
return extractedInformation;
} catch (error) {
console.error('Error in extractDataFromUrl:', error);
return null;
}
}
}
/**
* Example usage of the WebContentExtractor
*/
async function runExtraction(): Promise<void> {
const TARGET_WEBSITE_URL: string = 'https://example.com';
const DATA_EXTRACTION_QUERY: string = 'Extract the product title, all available prices, ...';
try {
const contentExtractor = new WebContentExtractor();
const extractionResult: string | null = await contentExtractor.extractDataFromUrl(TARGET_WEBSITE_URL, DATA_EXTRACTION_QUERY);
if (extractionResult) {
console.log(extractionResult);
} else {
console.log('Failed to extract data from the specified URL');
}
} catch (error) {
console.error(`Application error: ${error}`);
}
}
// Execute the application
runExtraction().catch(console.error);在将原始 HTML 转换为 Markdown后再发送给 Gemini AI 有多项关键优势:它能去除无关的 HTML 噪声,以更干净、结构化的输入提升 AI 表现,并减少 token 使用,从而获得更快且更具成本效益的处理。
重要提示:Lovable 擅长从自然语言构建应用,但并不总能正确集成诸如 Bright Data 或 Gemini 等外部工具。为确保实现准确,请在提示中包含可运行的示例代码。例如,上述提示中的 fetchContentViaBrightData 方法展示了 Bright Data Web Unlocker 的一个简单用法。
Bright Data 提供多种 API——包括 Web Unlocker、SERP API 和 Scraper APIs——每种都有各自的端点、认证方式与参数。当你在 Bright Data 控制台中设置某个产品或区域(zone)后,Overview 选项卡会提供与你配置相匹配的、按语言(Node.js、Python、cURL)定制的代码片段。你可以直接使用这些片段,或根据需要改造以适配 Edge Function 逻辑。
步骤五 – 将前端连接到 Edge Function
准备好 Edge Function 后,将其集成到你的 React 应用中:
Connect the frontend to the Edge Function:
- On form submission, call the Edge Function
- Log the request in the database
- Update status (processing/completed/failed) after the response
- Show processing time, status icons, and toast notifications
- Display the extracted JSON with loading states步骤六 – 添加提取历史
为用户提供回顾先前请求的方式:
Create a history view that:
- Lists all extractions for the logged-in user
- Displays URL, prompt, status, duration, and date
- Includes View and Delete options
- Expands rows to show extracted results
- Uses icons for statuses (completed,failed,processing)
- Handles long text/URLs gracefully with a responsive layout步骤七 – 界面打磨与最终增强
通过贴心的 UI 细节优化体验:
Polish the interface:
- Add toggle between "New Extraction" and "History"
- Create a JsonDisplay component with syntax highlighting and copy button
- Fix responsiveness issues for long prompts and URLs
- Add loading spinners, empty states, and fallback messages
- Include feature cards or tips at the bottom of the page结论
这一整合方案汇集了现代网页自动化的最佳实践:使用 Supabase 实现安全的用户流程,借助 Bright Data 实现可靠的抓取,并通过 Gemini 实现灵活、由 AI 驱动的解析——全部由 Lovable 直观的聊天式构建器驱动,实现零代码、高效率的工作流。
准备好构建你的应用了吗?从 brightdata.com 出发,探索 Bright Data 的数据采集解决方案,以零基础设施负担的方式,扩展至任意网站的可规模化访问。



技术写作者
 5 years experience
5 years experience
Satyam Tripathi 帮助 SaaS 和数据初创公司将复杂技术转化为可执行的内容,提升开发者采用度并增强用户理解。





