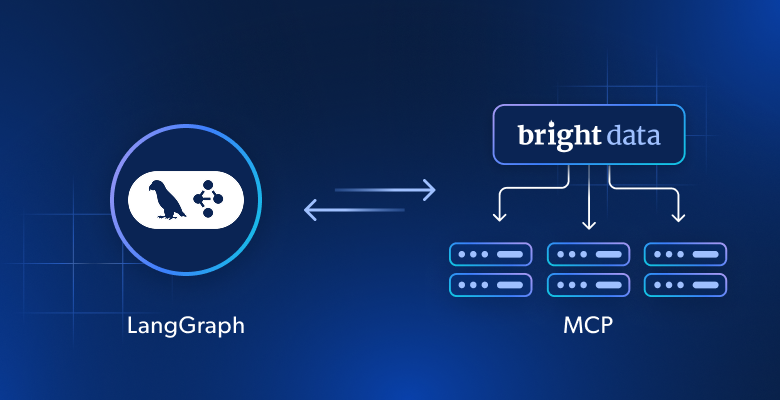
本指南将向你展示如何将 Bright Data Web MCP 与 LangGraph 连接,构建一个能够搜索、抓取并基于实时网页数据进行推理的 AI 研究智能体。
在本指南中,你将学到如何:
- 构建一个可控制自身推理循环的 LangGraph 智能体
- 通过 Bright Data Web MCP 免费层为该智能体提供实时网页访问能力
- 将搜索与数据提取工具接入一个可运行的智能体
- 使用 Web MCP 付费工具,为同一个智能体升级浏览器自动化能力
LangGraph 简介
LangGraph 让你可以构建 LLM 应用,其中的控制流是显式且易于检查的,而不是隐藏在提示词或重试逻辑里。每一步都是一个节点,每一次跳转都由你定义。
智能体以循环方式运行。LLM 模型读取当前状态,选择直接回应或请求调用工具。如果它调用了某个工具(例如网页搜索),结果会被加入回状态中,然后模型再次做出决策。当它收集到足够信息时,循环结束。
这就是工作流与智能体的关键区别。工作流遵循固定步骤;智能体则循环:决策、行动、观察,再次决策。这个循环也是 Agentic RAG 系统的基础,在这种系统中,检索是动态发生的,而不是在固定节点执行。
LangGraph 为你提供一种结构化方式来构建这个循环,包含记忆、工具调用,以及明确的停止条件。你可以看到智能体做出的每一个决策,并控制它何时停止。
为什么要在 LangGraph 中使用 Bright Data Web MCP
LLM 具备很强的推理能力,但它们无法看到当下网页上正在发生的内容。它们的知识停留在训练时间点。因此,当智能体需要最新数据时,模型往往会通过猜测来填补空白。
Bright Data Web MCP 通过搜索和提取工具,为你的智能体提供对实时网页数据的直接访问。模型不再需要猜测,而是可以基于真实、最新的来源来支撑回答。
LangGraph 则让这种访问方式在“智能体”场景中变得可用。智能体必须决定自己什么时候信息足够,什么时候需要再去获取更多数据。
借助 Web MCP,当智能体回答问题时,它可以指向实际使用过的来源,而不是依赖“记忆”。这使输出更容易被信任,也更容易调试。
如何将 Bright Data Web MCP 连接到 LangGraph 智能体
LangGraph 负责控制智能体循环。Bright Data Web MCP 为智能体提供实时网页数据访问能力。剩下的就是把它们连接起来,同时不引入额外复杂度。
在本节中,你将搭建一个最小化的 Python 项目,连接到 Web MCP 服务器,并把它的工具暴露给 LangGraph 智能体使用。
前置条件
要跟随本教程,你需要:
- Python 3.11+ 版本
- Bright Data 账号
- OpenAI Platform 账号
步骤 #1:生成 OpenAI API Key
智能体需要一个 LLM API Key 来进行推理并决定何时使用工具。在该配置中,这个 Key 来自 OpenAI。
在 OpenAI Platform 控制台创建一个 API Key。打开 “API keys” 页面并点击 “Create new secret key”。
这会打开一个新窗口,你可以在其中设置你的 Key。
保持默认设置(可选为 Key 命名),然后点击 “Create secret key”。
复制该 Key 并安全存储。你将在后续步骤中把它加入到 OPENAI_API_KEY 环境变量中。
该 Key 允许 LangGraph 调用 LLM 模型,由模型决定何时调用 Web MCP 工具。
步骤 #2:生成 Bright Data API Token
接下来,你需要从 Bright Data 获取一个 API Token。该 Token 用于让你的智能体在 Web MCP 服务器上完成认证,并允许它调用搜索与抓取工具。
在 Bright Data 控制台生成 Token。打开 “Account settings”,进入 “Users and API keys”,然后点击 “+ Add key”。
本指南中保持默认设置并点击 “Save”:
复制该 Key 并安全存储。你将在后续步骤中把它加入到 BRIGHTDATA_TOKEN 环境变量中。
该 Token 赋予你的智能体通过 Web MCP 访问实时网页数据的权限。
步骤 #3:搭建一个简单的 Python 项目
创建一个新的项目目录和虚拟环境:
mkdir webmcp-langgraph-demo
cd webmcp-langgraph-demo
python3 -m venv webmcp-langgraph-venv激活虚拟环境:
source webmcp-langgraph-venv/bin/activate这能隔离依赖并避免与其他项目冲突。在环境激活后,只安装所需依赖。这些依赖与 Bright Data 的 LangChain 与 LangGraph 集成中使用的 MCP 适配器一致,因此随着智能体扩展,配置也能保持一致:
pip install \
langgraph \
langchain \
langchain-openai \
langchain-mcp-adapters \
python-dotenv创建一个 .env 文件用于存储 API Key:
touch .env将 OpenAI API Key 与 Bright Data Key 粘贴到 .env 文件中:
OPENAI_API_KEY="your-openai-api-key"
BRIGHTDATA_TOKEN="your-brightdata-api-key"请保持 OPENAI_API_KEY 的名称不变。LangChain 会自动读取它,因此你不需要在代码中传入 Key。
最后,创建一个 Python 文件,并定义系统提示词(system prompt),用于规定智能体的角色、边界以及工具使用规则:
# webmcp-langgraph-demo.py file
SYSTEM_PROMPT = """You are a web research assistant.
Task:
- Research the user's topic using Google search results and a few sources.
- Return 6–10 simple bullet points.
- Add a short "Sources:" list with only the URLs you used.
How to use tools:
- First call the search tool to get Google results.
- Select 3–5 reputable results and scrape them.
- If scraping fails, try a different result.
Constraints:
- Use at most 5 sources.
- Prefer official docs or primary sources.
- Keep it quick: no deep crawling.
"""步骤 #4:设置 LangGraph 节点
这是智能体的核心。一旦你理解了这个循环,其余内容都只是实现细节。
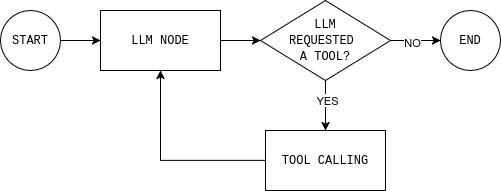
在写代码之前,先理解你将要构建的智能体循环会很有帮助。该图展示了一个简单的 LangGraph 智能体循环:模型读取当前状态,判断是否需要外部数据,必要时调用工具,观察结果,并重复直到可以回答。

“
要实现这个循环,你需要两个节点(一个 LLM 节点和一个工具执行节点),以及一个路由函数,用于决定继续循环还是结束并给出最终响应。
LLM 节点会将当前对话状态与系统规则发送给模型,并返回模型回复或工具调用。关键细节是:每次模型回复都会追加到 MessagesState 中,这样后续步骤就能看到模型做了什么决策以及原因。
def make_llm_call_node(llm_with_tools):
async def llm_call(state: MessagesState):
messages = [SystemMessage(content=SYSTEM_PROMPT)] + state["messages"]
ai_message = await llm_with_tools.ainvoke(messages)
return {"messages": [ai_message]}
return llm_call工具执行节点负责执行模型请求的工具,并把输出记录为观察结果(observations)。这种分离能让推理留在模型中、执行留在代码中。
def make_tool_node(tools_by_name: dict):
async def tool_node(state: MessagesState):
last_ai_msg = state["messages"][-1]
tool_results = []
for tool_call in last_ai_msg.tool_calls:
tool = tools_by_name.get(tool_call["name"])
if not tool:
tool_results.append(
ToolMessage(
content=f"Tool not found: {tool_call['name']}",
tool_call_id=tool_call["id"],
)
)
continue
# MCP tools are typically async
observation = (
await tool.ainvoke(tool_call["args"])
if hasattr(tool, "ainvoke")
else tool.invoke(tool_call["args"])
)
tool_results.append(
ToolMessage(
content=str(observation),
tool_call_id=tool_call["id"],
)
)
return {"messages": tool_results}
return tool_node最后,路由规则决定图是否继续循环还是停止。实际就是回答一个问题:模型是否请求了工具?
def should_continue(state: MessagesState) -> Literal["tool_node", END]:
last_message = state["messages"][-1]
if getattr(last_message, "tool_calls", None):
return "tool_node"
return END步骤 #5:把所有内容连接起来
本步骤的所有内容都放在 main() 函数中。在这里你将配置凭据、连接 Web MCP、绑定工具、构建图,并运行一次查询。
首先加载环境变量并读取 BRIGHTDATA_TOKEN。这可以避免把凭据写进源代码,并在缺少 token 时快速失败。
# Load environment variables from .env
load_dotenv()
# Read Bright Data token
bd_token = os.getenv("BRIGHTDATA_TOKEN")
if not bd_token:
raise ValueError("Missing BRIGHTDATA_TOKEN")接着创建 MultiServerMCPClient 并指向 Web MCP 端点。该客户端将智能体连接到实时网页数据。
# Connect to Bright Data Web MCP server
client = MultiServerMCPClient({
"bright_data": {
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}",
"transport": "streamable_http",
}
})注意:Web MCP 默认使用 Streamable HTTP 作为传输方式,与较旧的 SSE 方案相比,它简化了工具的流式返回与重试。因此,大多数较新的 MCP 集成都会统一使用这种传输方式。
然后获取可用的 MCP 工具并按名称建立索引。工具执行节点会使用这个映射来路由调用。
# Fetch all available MCP tools (search, scrape, etc.)
tools = await client.get_tools()
tools_by_name = {tool.name: tool for tool in tools}初始化 LLM 并把 MCP 工具绑定到模型上,从而启用工具调用。
# Initialize the LLM and allow it to call MCP tools
llm = ChatOpenAI(model="gpt-4.1-mini", temperature=0)
llm_with_tools = llm.bind_tools(tools)现在构建前面展示的 LangGraph 智能体。创建 StateGraph(MessagesState),添加 LLM 与工具节点,并连接边以匹配循环逻辑。
# Build the LangGraph agent
graph = StateGraph(MessagesState)
graph.add_node("llm_call", make_llm_call_node(llm_with_tools))
graph.add_node("tool_node", make_tool_node(tools_by_name))
# Graph flow:
# START → LLM → (tools?) → LLM → END
graph.add_edge(START, "llm_call")
graph.add_conditional_edges("llm_call", should_continue, ["tool_node", END])
graph.add_edge("tool_node", "llm_call")
agent = graph.compile()最后,用一个真实提示运行智能体。设置 recursion_limit 以防止无限循环。
# Example research query
topic = "What is Bright Data Web MCP?"
# Run the agent
result = await agent.ainvoke(
{
"messages": [
HumanMessage(content=f"Research this topic:\n{topic}")
]
},
# Prevent infinite loops
config={"recursion_limit": 12}
)
# Print the final response
print(result["messages"][-1].content)下面是 main() 中的完整样子:
async def main():
# Load environment variables from .env
load_dotenv()
# Read Bright Data token
bd_token = os.getenv("BRIGHTDATA_TOKEN")
if not bd_token:
raise ValueError("Missing BRIGHTDATA_TOKEN")
# Connect to Bright Data Web MCP server
client = MultiServerMCPClient({
"bright_data": {
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}",
"transport": "streamable_http",
}
})
# Fetch all available MCP tools (search, scrape, etc.)
tools = await client.get_tools()
tools_by_name = {tool.name: tool for tool in tools}
# Initialize the LLM and allow it to call MCP tools
llm = ChatOpenAI(model="gpt-4.1-mini", temperature=0)
llm_with_tools = llm.bind_tools(tools)
# Build the LangGraph agent
graph = StateGraph(MessagesState)
graph.add_node("llm_call", make_llm_call_node(llm_with_tools))
graph.add_node("tool_node", make_tool_node(tools_by_name))
# Graph flow:
# START → LLM → (tools?) → LLM → END
graph.add_edge(START, "llm_call")
graph.add_conditional_edges("llm_call", should_continue, ["tool_node", END])
graph.add_edge("tool_node", "llm_call")
agent = graph.compile()
# Example research query
topic = "What is Model Context Protocol (MCP) and how is it used with LangGraph?"
# Run the agent
result = await agent.ainvoke(
{
"messages": [
HumanMessage(content=f"Research this topic:\n{topic}")
]
},
# Prevent infinite loops
config={"recursion_limit": 12}
)
# Print the final response
print(result["messages"][-1].content)注意:你可以在这个 GitHub 仓库中找到一个可完整运行的示例版本。克隆仓库,把 API Key 写入
.env文件,然后运行脚本,即可看到完整的 LangGraph + Web MCP 循环效果。
使用 Web MCP 付费工具:通过浏览器自动化克服抓取挑战
当你从服务端渲染页面走向 JavaScript 重度或交互驱动的网站时,静态抓取就会失效。这正是静态与动态内容的分界线:你何时需要真实浏览器,而不是直接抓 HTML。
对于需要真实用户交互的页面(无限滚动、按钮分页等),静态抓取也会失败,此时 浏览器自动化往往是唯一可靠的选项。
Web MCP 将浏览器自动化与高级抓取能力以 MCP 工具形式提供给智能体。对智能体而言,它们只是当更简单的工具不够用时的额外选择。
在 Web MCP 中启用浏览器自动化工具
由于 Web MCP 的浏览器自动化工具不包含在免费层中,你需要先在 Bright Data 控制台左侧栏的 “Billing” 菜单中为账号充值。
接着,为你的 MCP 配置启用“浏览器自动化”工具组。打开 “MCP” 部分并点击 “Edit”:
然后启用 “Browser Automation”,并点击 “Continue to Configure”:
保持默认设置并点击 “Copy & Close”:
启用后,当智能体调用 client.get_tools() 时,这些工具会与 search、scrape 工具一起出现。
为浏览器自动化工具扩展现有 LangGraph 智能体
这里的关键点很简单:你不需要改变 LangGraph 的架构。
你的智能体已经能够:
- 动态发现工具
- 将工具绑定到模型
- 通过同一个
LLM -> tool -> observation循环来路由执行
添加浏览器自动化工具只会改变可用工具的集合。
实际操作中,唯一需要修改的是 MCP 连接 URL。与其连接基础端点,不如请求高级抓取与浏览器自动化工具组:
# Enable advanced scraping and browser automation
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}&groups=advanced_scraping,browser"当你重新运行脚本时,client.get_tools() 会返回额外的浏览器工具。当静态抓取得到的结果过少或不完整时,模型就可以选择这些工具。
总结
LangGraph 为你提供了清晰、可检查的智能体循环:状态、路由与停止条件都由你控制。Web MCP 则为这个循环提供了可靠的真实网页数据访问能力,无需把抓取逻辑塞进提示词或代码中。
最终得到的是一种清晰的关注点分离:模型决定做什么;LangGraph 决定循环怎么跑;Bright Data 负责搜索、提取以及应对封锁问题。当某个环节失败时,你能清楚看到失败位置与原因。
同样重要的是,这套方案不会把你锁死在某个死胡同里。你可以先用基础 Web MCP 工具快速完成研究,当静态抓取开始失效时再升级到 Web MCP 付费工具。智能体架构保持不变,变化的只是智能体的“触达范围”扩大了。







