

在本文中,你将学到:
- 什么是 Langfuse,它能提供什么能力。
- 为什么企业和用户需要它来监控和追踪 AI Agent。
- 如何将它集成到一个真实、复杂、基于 LangChain 构建的 AI Agent 中,并通过 Bright Data 获取网页搜索和爬取能力。
我们开始吧!
什么是 Langfuse?
Langfuse 是一个开源且提供云托管的 LLM 工程平台,用于帮助你调试、监控和优化大语言模型应用。它提供可观测性、链路追踪、提示词管理和评估工具,覆盖整个 AI 开发工作流。
其主要特性包括:
- 可观测性与链路追踪:通过 trace、会话概览以及成本、延迟、错误率等指标,深入洞察你的 LLM 应用。这对理解性能、定位问题至关重要。
- 提示词管理:提供一个带版本控制的系统,让团队可以协作创建、管理和迭代提示词,而无需修改代码。
- 评估:用于评估应用行为的工具,包括人工反馈收集、基于模型的打分以及基于数据集的自动化测试。
- 协作:通过注释、评论和共享洞察支持团队协作流程。
- 可扩展性:完全开源,可灵活集成到不同技术栈中。
- 部署选项:可作为托管云服务(包含免费层),也可以自托管,满足对数据与基础设施有完全控制需求的团队。
为什么要在你的 AI Agent 中集成 Langfuse
对于企业级应用来说,用 Langfuse 监控 AI Agent 是基础能力。只有这样,才能达到生产环境所需的可观测性、可控性和可靠性。
在真实场景中,AI Agent 会与敏感数据、复杂业务逻辑以及外部 API 交互。因此,你需要一种方式来追踪并理解 Agent 的具体行为、成本以及可靠性。
Langfuse 提供端到端链路追踪、详细指标及调试工具,使得即使是非技术团队也可以从提示词输入到模型决策和工具调用,全程监控 AI 工作流的每个步骤。
对企业而言,这意味着更少的盲区、更快的事故响应,以及更强的内部治理和外部合规能力。此外,Langfuse 还支持提示词管理和评估,让团队可以在大规模场景下对提示词进行版本化、测试和优化。
如何使用 Langfuse 追踪一个基于 LangChain 和 Bright Data 构建的合规追踪 AI Agent
为了展示 Langfuse 的追踪和监控能力,我们首先需要一个可被“埋点”的 AI Agent。因此,我们将使用 LangChain 构建一个真实世界的 AI Agent,并通过Bright Data 的网页搜索与爬取解决方案为其提供能力支持。
注意:Langfuse 和 Bright Data 支持多种 AI Agent 框架,这里选择 LangChain 只是为了演示和简化。
这个面向企业的 AI Agent 将负责处理合规相关任务,包括:
- 加载一份描述企业流程(如数据处理流程)的内部 PDF 文档。
- 使用 LLM 分析文档,识别关键隐私与合规要点。
- 通过 Bright Data SERP API 执行相关主题的网页搜索。
- 使用 Bright Data Web Unlocker API 以 Markdown 格式获取搜索结果中靠前的网页(优先政府网站)。
- 处理收集到的信息并给出更新后的洞察,帮助避免潜在合规风险。
随后,我们会将该 Agent 接入 Langfuse,以追踪运行时信息、指标以及其他相关数据。
该项目的高层架构如下图所示: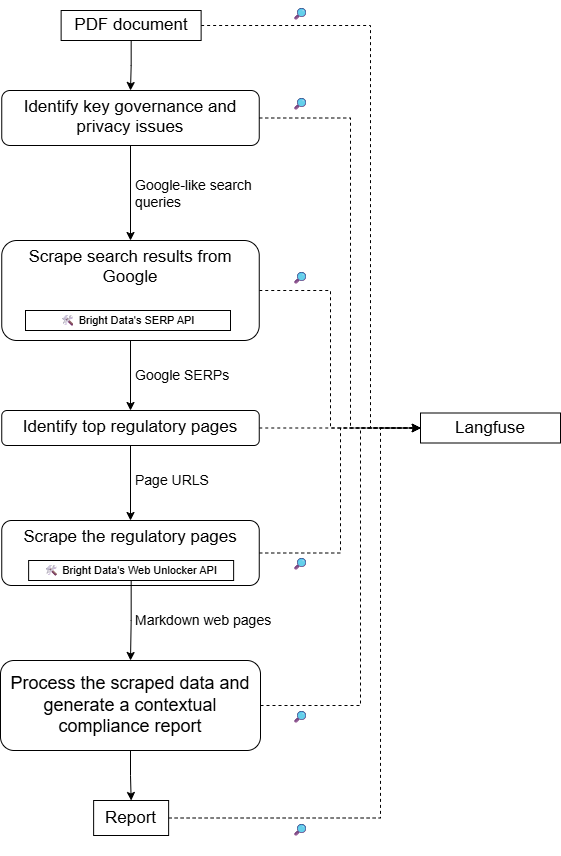
按照下方步骤进行配置即可!
前置条件
在开始之前,请确保你已经具备以下条件:
- 本机已安装Python 3.10 或更高版本。
- 一个OpenAI API Key。
- 一个Bright Data 账号,已创建 SERP API 和 Web Unlocker API 的 Zone,并获取 API Key。
- 一个Langfuse 账号,并已配置公开密钥和私密密钥。
暂时无需急于完成 Bright Data 和 Langfuse 的账号配置,下面的步骤会逐步引导你完成。同时,如果你对 AI Agent 的埋点与监控有基本了解,将更容易理解 Langfuse 如何追踪和管理运行数据。
步骤一:创建 LangChain AI Agent 项目
在终端中运行以下命令,为你的 LangChain AI Agent 创建一个新文件夹:
mkdir compliance-tracking-ai-agentcompliance-tracking-ai-agent/ 目录即为你的 AI Agent 项目文件夹,之后将通过 Langfuse 对其进行埋点。
进入该目录并在其中创建 Python 虚拟环境:
cd compliance-tracking-ai-agent
python -m venv .venv使用你喜欢的 Python IDE 打开该项目文件夹,例如安装了 Python 插件的 VS Code 或 PyCharm。
在项目根目录下创建 agent.py 脚本:
compliance-tracking-ai-agent/
├─── .venv/
└─── agent.py # <------------当前 agent.py 还是空文件,稍后我们会在这里通过 LangChain 定义 AI Agent。
接下来,激活虚拟环境。在 Linux 或 macOS 中运行:
source venv/bin/activate在 Windows 中,则执行:
venv/Scripts/activate虚拟环境激活后,通过以下命令安装项目依赖:
pip install langchain langchain-openai langgraph langchain-brightdata langchain-community pypdf python-dotenv langfuse这些库分别用于:
langchain、langchain-openai和langgraph:用于构建和管理基于 OpenAI 模型的 AI Agent。langchain-brightdata:通过官方工具将 LangChain 与 Bright Data 服务集成。langchain-community与pypdf:基于pypdf提供读取和处理 PDF 的能力。python-dotenv:从.env文件中加载应用密钥(如第三方服务的 API Key)。langfuse:为你的 AI Agent 添加埋点,收集 trace 和遥测数据(可在云端或本地使用)。
至此,你已经完成了用于构建 AI Agent 的 Python 开发环境搭建。
步骤二:配置环境变量读取
你的 AI Agent 将会连接 OpenAI、Bright Data 和 Langfuse 等第三方服务。为避免在代码中硬编码凭据,并让脚本具备企业级生产可用性,我们会使用 .env 文件来统一管理这些密钥,这也是我们安装 python-dotenv 的原因。
在 agent.py 中,先添加如下导入:
from dotenv import load_dotenv然后在项目根目录中创建 .env 文件:
compliance-tracking-ai-agent/
├─── .venv/
├─── agent.py
└─── .env # <------------该文件将存放所有的凭据、API Key 和密钥。
在 agent.py 中,通过如下代码加载 .env 中的环境变量:
load_dotenv()这样,脚本就可以安全地从 .env 文件中读取配置值。
步骤三:准备 Bright Data 账号
LangChain 的 Bright Data 工具会连接到你账号中已配置好的 Bright Data 服务。本项目需要的两个工具是:
BrightDataSERP:用于检索搜索引擎结果,查找相关法规网页。该工具连接到 Bright Data 的 SERP API。BrightDataUnblocker:访问任意公共网站,即便存在地理限制或反爬虫保护。Agent 可以使用它抓取网页内容并进行分析。该工具连接到 Bright Data 的 Web Unlocker API。
也就是说,你需要在 Bright Data 账号中创建一个 SERP API Zone 和一个 Web Unlocker API Zone。下面是具体配置方法。
如果你还没有 Bright Data 账号,请先注册账号;否则直接登录。进入控制台后,打开“Proxies & Scraping”页面,查看“My Zones”表格: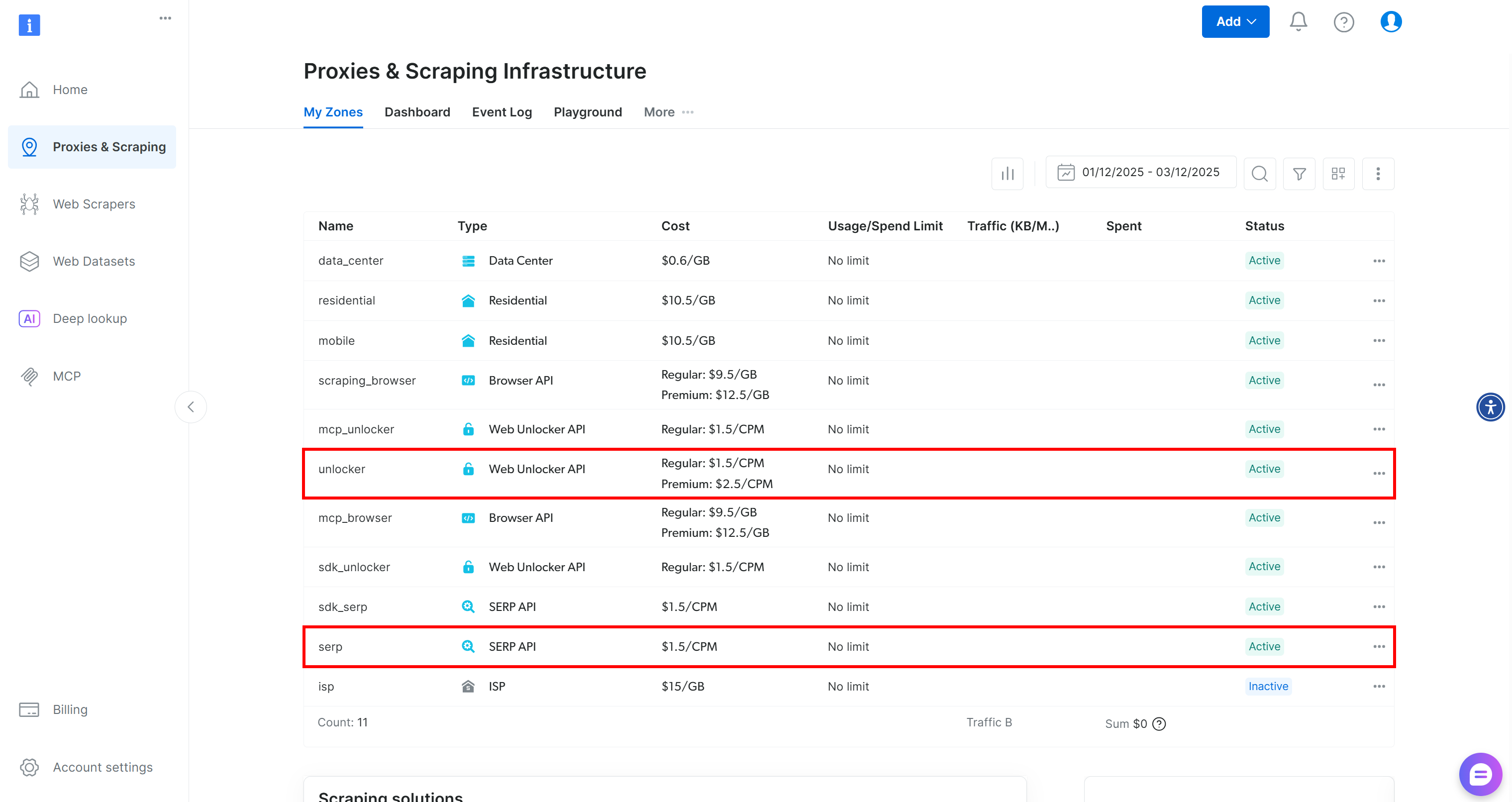
如果表中已经存在名为 unlocker 的 Web Unlocker API Zone 和名为 serp 的 SERP API Zone,则可以直接使用,因为:
BrightDataSERP工具会自动连接名为serp的 SERP API Zone。BrightDataUnblocker工具会自动连接名为web_unlocker的 Web Unlocker API Zone。
更多详情可参考 Bright Data x LangChain 文档。
如果你还没有上述两个 Zone,可以很容易地创建它们。在“Unblocker API”和“SERP API”卡片下方点击“Create zone”按钮,并按照向导创建具有上述名称的两个 Zone: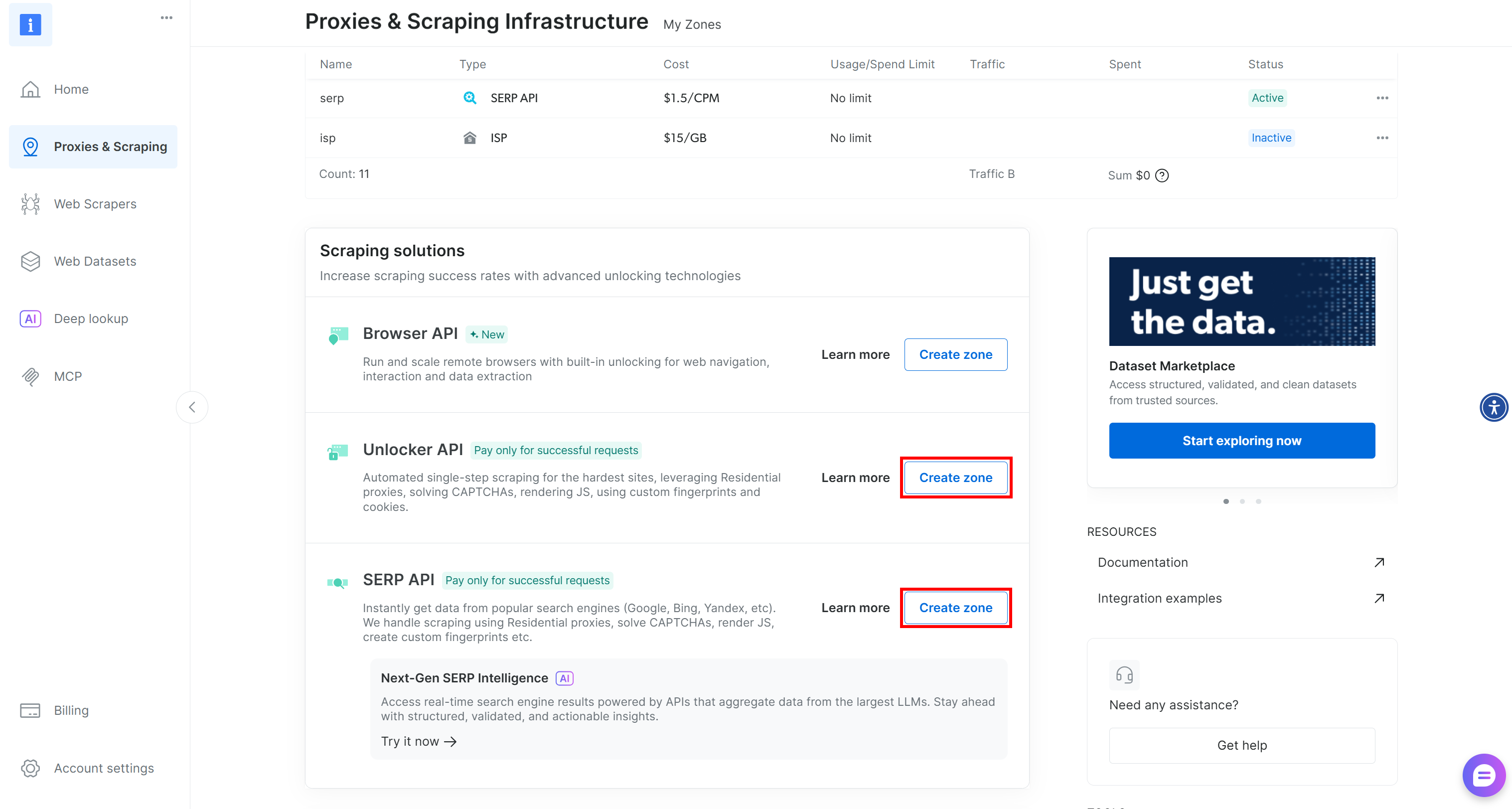
如果需要更详细的操作步骤,可以参考以下文档:
最后,你需要告诉 LangChain 的 Bright Data 工具如何连接到你的账号。这通过 Bright Data API Key 实现,该 Key 用于身份验证。
生成你的 Bright Data API Key,并在 .env 文件中添加:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"至此,你已经具备将 LangChain 脚本通过官方工具连接到 Bright Data 解决方案所需的一切前提条件。
步骤四:配置 LangChain 的 Bright Data 工具
在 agent.py 中按如下方式初始化 LangChain 的 Bright Data 工具:
from langchain_brightdata import BrightDataUnlocker, BrightDataSERP
bright_data_serp_api_tool = BrightDataSERP()
bright_data_web_unlocker_api_tool = BrightDataUnlocker()注意:你无需在此处手动指定 Bright Data API Key,这两个工具会自动从你之前在 .env 中设置的 BRIGHT_DATA_API_KEY 环境变量中进行读取。
步骤五:集成 LLM
你的合规追踪 AI Agent 需要一个“大脑”——即 LLM 模型。这里我们选择 OpenAI 作为 LLM 提供方。首先,在 .env 文件中添加你的 OpenAI API Key:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"接着,在 agent.py 中按如下方式初始化 LLM:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="gpt-5-mini",
)注意:这里使用的是 GPT-5 Mini 模型,你也可以选择任意其他 OpenAI 模型。
如果不想使用 OpenAI,可参考 LangChain 官方文档 将 LLM 替换为其他模型提供方。
到这里,你已经具备定义 LangChain AI Agent 所需的全部基础组件。
步骤六:定义 AI Agent
一个 LangChain Agent 需要 LLM、可选的工具列表,以及一个用于定义 Agent 行为的系统提示词(System Prompt)。
将这些组件整合为一个 LangChain Agent 如下:
from langchain.agents import create_agent
# Define system prompt that instructs the agent on its compliance and privacy-focused task
system_prompt = """
You are a compliance-tracking expert. Your role is to analyze documents for potential regulatory and privacy issues.
Your analysis is supported by researching updated rules and authoritative sources online using Bright Data's tools, including the SERP API and Web Unlocker.
Provide accurate, enterprise-ready insights, ensuring all findings are supported by quotes from both the original document and authoritative external sources.
"""
# List of tools available to the agent
tools=[bright_data_serp_api_tool, bright_data_web_unlocker_api_tool]
# Define the AI agent
agent = create_agent(
llm=llm,
tools=tools,
system_prompt=system_prompt,
)create_agent() 函数会基于 LangGraph 构建一个图结构的 Agent 运行时。图由节点(步骤)和边(连接)组成,用于定义你的 Agent 如何处理信息。Agent 会在这张图中移动并依次执行不同类型的节点。更多详情请参考官方文档。
简单来说,agent 变量现在就代表了你的 AI Agent,它已经完成与 Bright Data 的集成,可用于合规追踪和分析。非常棒!
步骤七:启动 Agent
在启动 Agent 之前,你需要准备描述合规分析任务及待分析文档的提示词。
先读取输入 PDF 文档:
from langchain_community.document_loaders import PyPDFDirectoryLoader
# Load all PDF documents from the input folder
input_folder = "./input"
loader = PyPDFDirectoryLoader(input_folder)
# Load all pages from all PDFs in the input folder
docs = loader.load()
# Combine all pages from the PDFs into a single string for analysis
internal_document_to_analyze = "\n\n".join([doc.page_content for doc in docs])上述代码使用了LangChain 的 pypdf 社区文档加载器,从 input/ 文件夹中读取所有 PDF 文件,并将各页文本合并为一个字符串。
在项目根目录下添加 input/ 文件夹:
compliance-tracking-ai-agent/
├─── .venv/
├─── input/ # <------------
├─── agent.py
└─── .env该文件夹将存放由 Agent 分析的 PDF 文件,用于隐私、法规和合规问题检测。
假设 input/ 文件夹中只有一个文档,internal_document_to_analyze 将包含其全部文本。接下来我们将其嵌入到一个引导 Agent 完成任务的提示词中:
from langchain_core.prompts import PromptTemplate
# Define a prompt template to guide the agent through the workflow
prompt_template = PromptTemplate.from_template("""
Given the following PDF content:
1. Have the LLM analyze it to identify the main key aspects worth exploring in terms of privacy.
2. Translate those aspects into up to 3 very short (no more than 5 words), concise, specific search queries suitable for Google.
3. Perform web searches for those queries using Bright Data's SERP API tool (searching for pages in English, limited to the United States).
4. Access up to the top 5 web, non-PDF pages (giving priority to government websites) in Markdown data format using Bright Data's Web Unlocker tool.
5. Process the collected information and create a final, concise report that includes quotes from the original document and insights from the scraped pages to avoid regulatory issues.
PDF CONTENT:
{pdf}
""")
# Fill the template with the content from the PDFs
prompt = prompt_template.format(pdf=internal_document_to_analyze)最后,将提示词传入 Agent 并执行:
# Stream the agent's response while tracking each step with Langfuse
for step in agent.stream(
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="values",
):
step["messages"][-1].pretty_print()到这里,你的基于 Bright Data 的 LangChain AI Agent 已经可以处理企业级文档分析和法规研究任务。
步骤八:开始使用 Langfuse
现在你的 AI Agent 已开发完成,一般在这个阶段你会引入 Langfuse 来做生产级的追踪与监控——通常是在已有 Agent 的基础上进行埋点。
首先注册一个 Langfuse 账号。系统会将你跳转到“Organizations”页面,需要你创建一个新的组织(Organization)。点击“New Organization”按钮: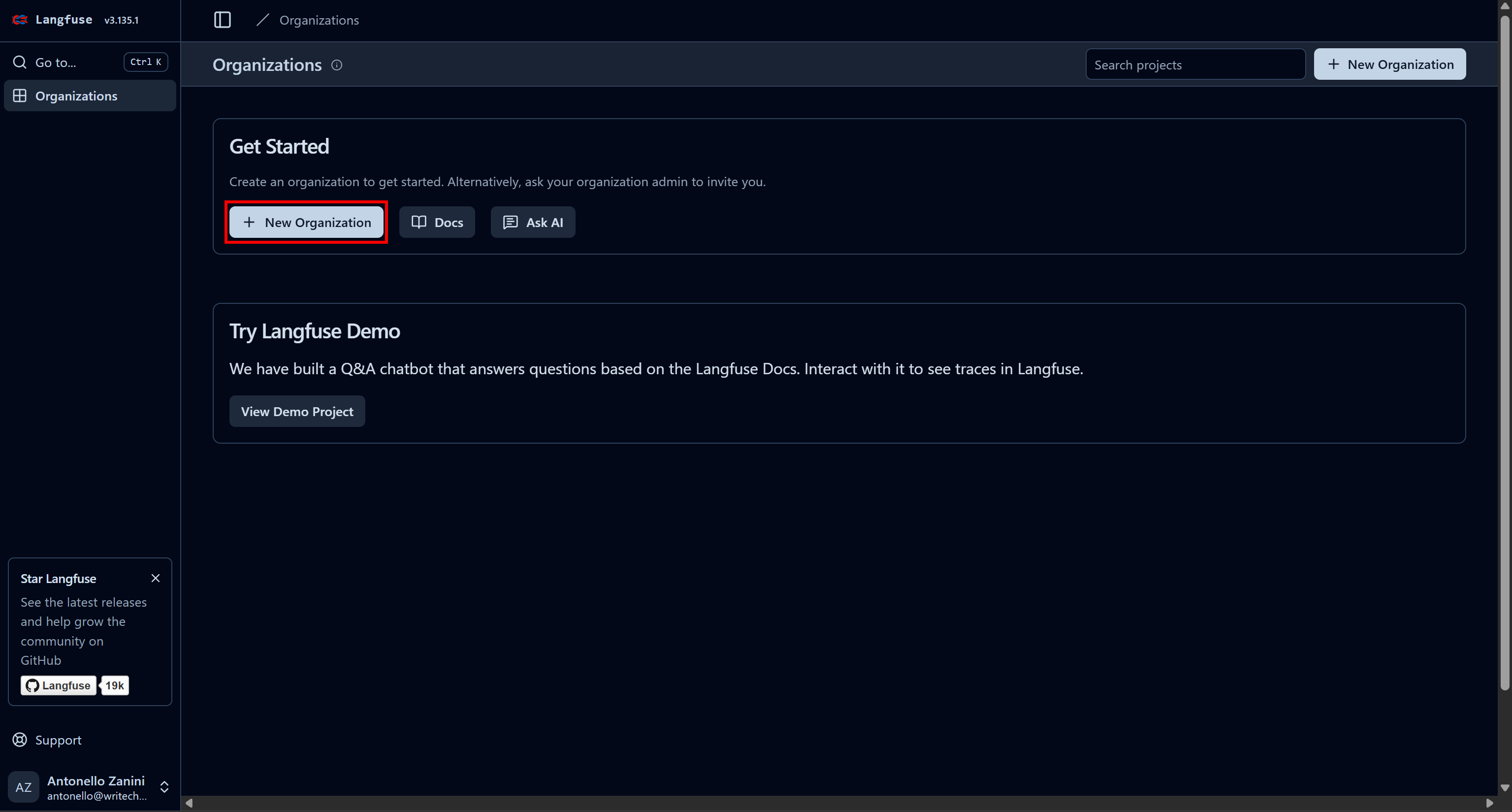
为组织命名,并继续完成向导,直到最后一步“Create Project”: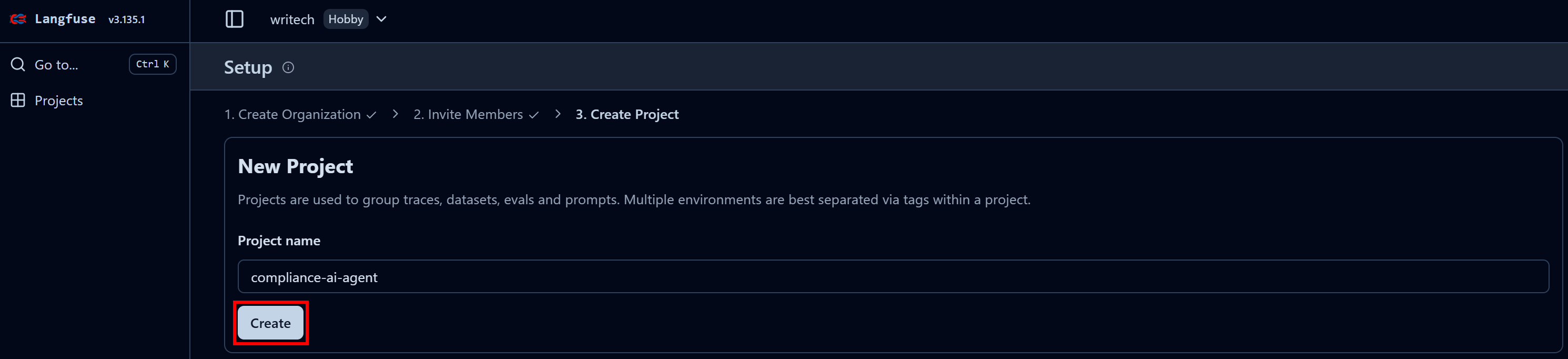
在最后一步中,将项目命名为类似“compliance-tracking-ai-agent”,然后点击“Create”按钮。系统会跳转到“Project Settings”视图,在这里进入“API Keys”页面: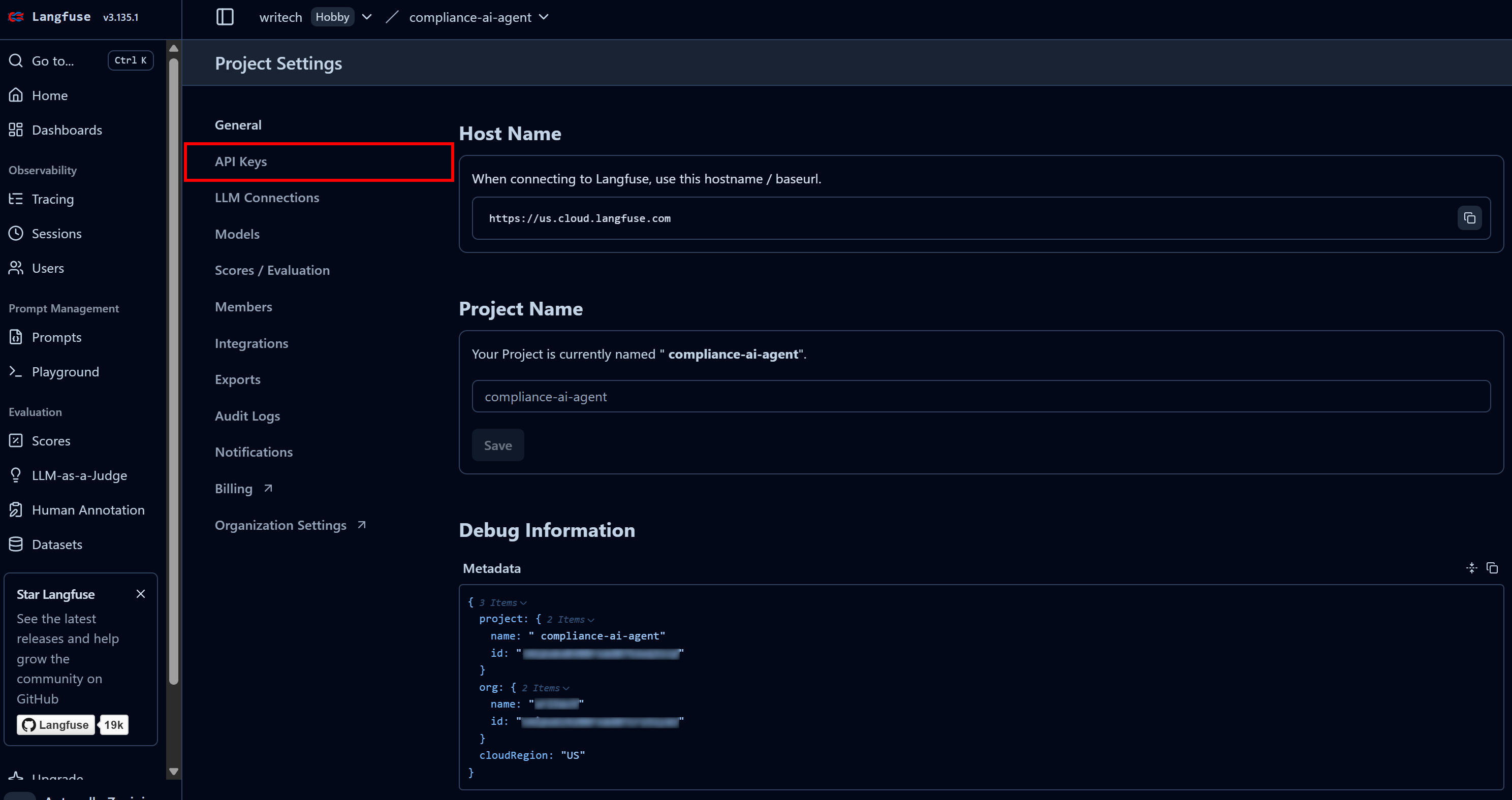
在“Project API Keys”区域点击“Create new API keys”: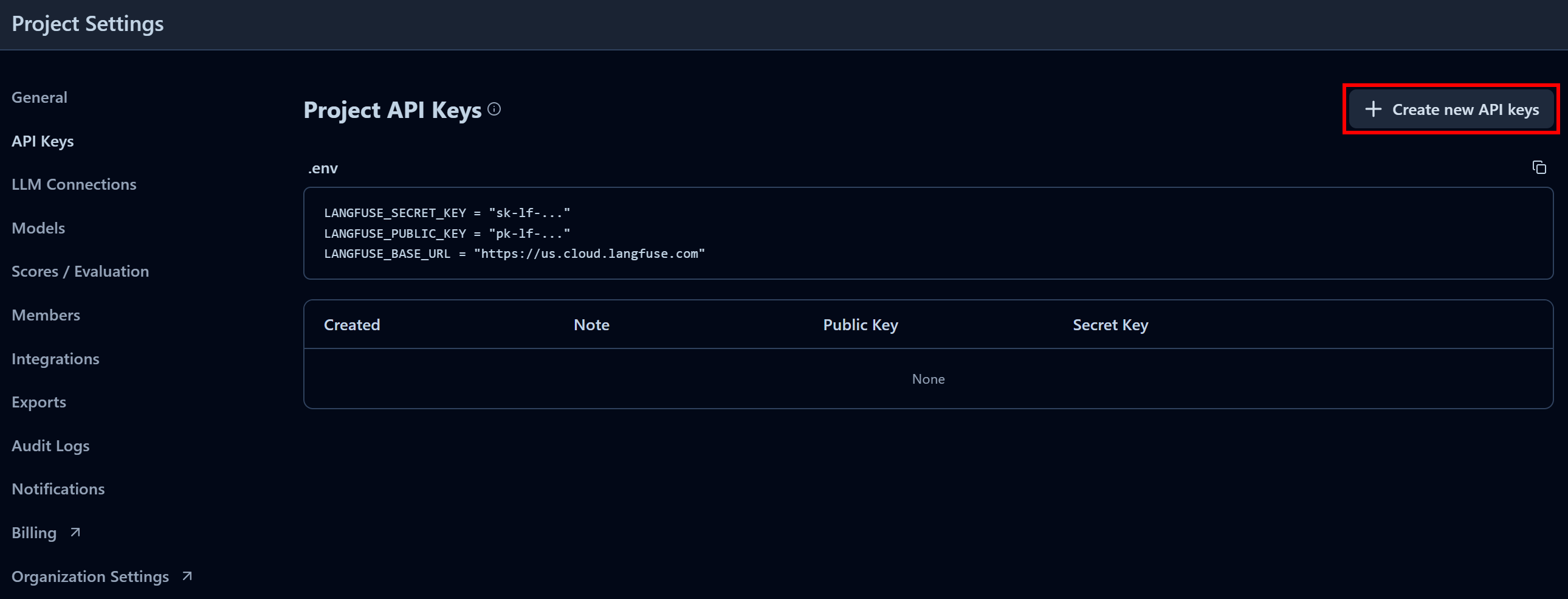
在弹出的窗口中,为 API Key 命名,并点击“Create API keys”: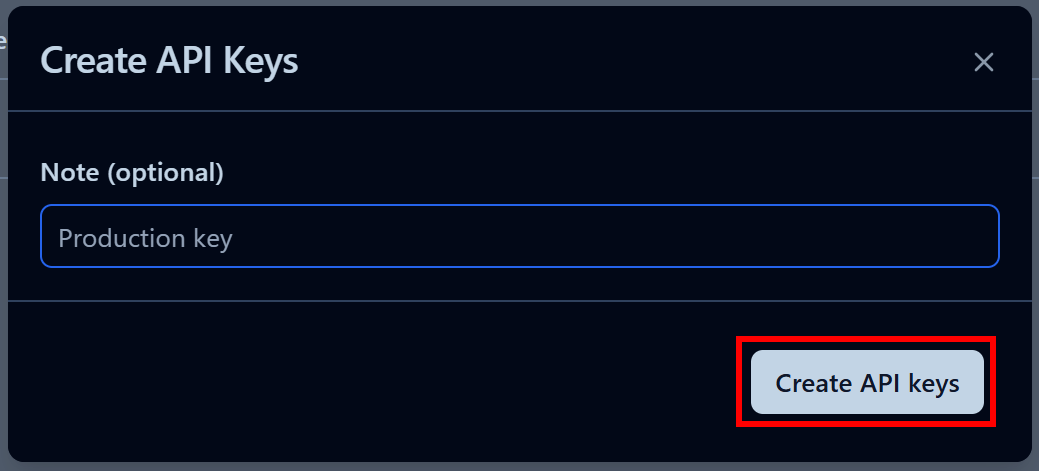
系统会给出一对公开密钥和私密密钥。为便于快速集成,可以点击“.env” 区域中的“Copy to clipboard”按钮: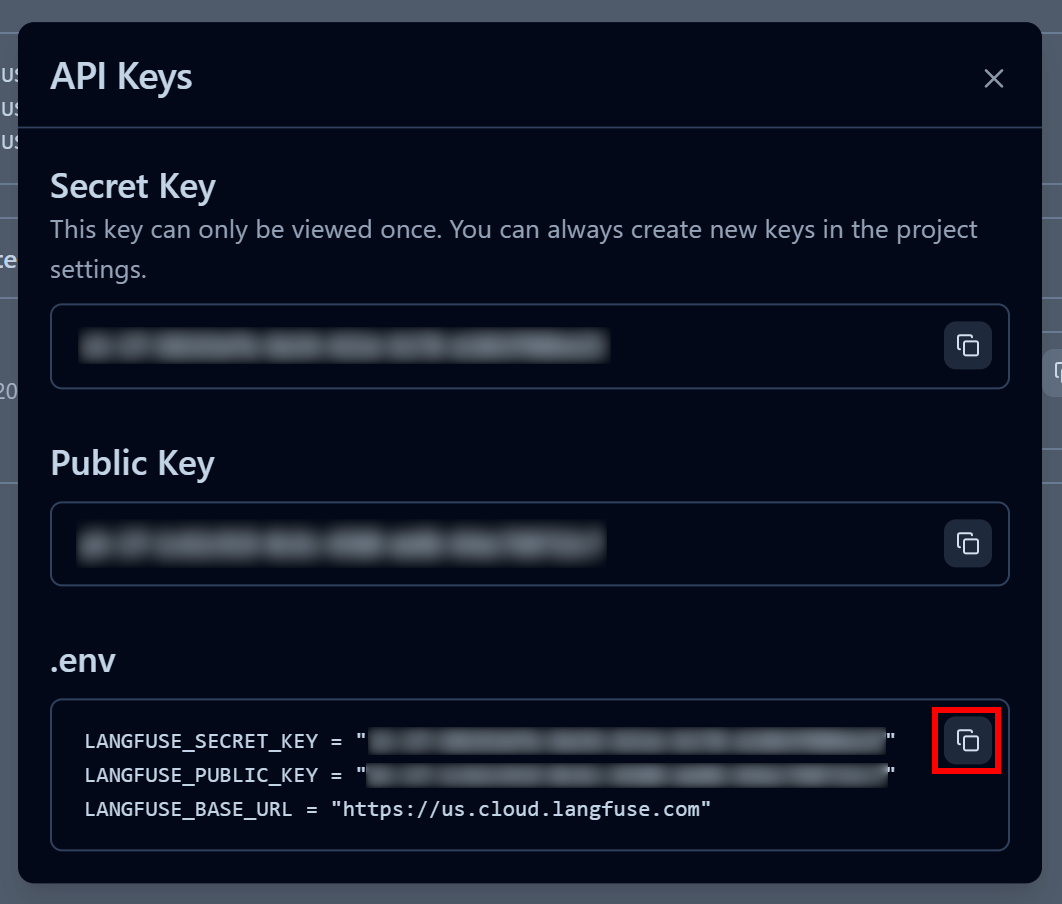
然后将这些环境变量粘贴到项目的 .env 文件中:
LANGFUSE_SECRET_KEY = "<YOUR_LANGFUSE_SECRET_KEY>"
LANGFUSE_PUBLIC_KEY = "<YOUR_LANGFUSE_PUBLIC_KEY>"
LANGFUSE_BASE_URL = "<YOUR_LANGFUSE_BASE_URL>"这样,你的脚本就可以连接到 Langfuse Cloud 账号,并将有价值的 trace 信息发送过去,用于监控和可观测性分析。
步骤九:集成 Langfuse 追踪
Langfuse 对 LangChain 提供了完整支持(同时也支持多种其他 AI Agent 框架),因此无需编写额外的自定义埋点代码。
要将你的 LangChain AI Agent 接入 Langfuse,只需要初始化 Langfuse Client 并创建一个回调处理器(Callback Handler):
from langfuse import get_client
from langfuse.langchain import CallbackHandler
# Load environment variables from .env file
load_dotenv()
# Initialize Langfuse client for tracking and observability
langfuse = get_client()
# Create a Langfuse callback handler to capture Langchain agent interactions
langfuse_handler = CallbackHandler()
Then, pass the Langfuse callback handler when invoking the agent:
for step in agent.stream(
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="values",
config={"callbacks": [langfuse_handler]} # <--- Langfuse integration
):
step["messages"][-1].pretty_print()完成!你的 LangChain AI Agent 现在已经完全接入了 Langfuse。所有运行时信息都会发送到 Langfuse,并可在其 Web 控制台中查看。
步骤十:最终代码
此时你的 agent.py 文件应如下所示:
from dotenv import load_dotenv
from langchain_brightdata import BrightDataUnlocker, BrightDataSERP
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
from langchain_community.document_loaders import PyPDFDirectoryLoader
from langchain_core.prompts import PromptTemplate
from langfuse import get_client
from langfuse.langchain import CallbackHandler
# Load environment variables from .env file
load_dotenv()
# Initialize Langfuse client for tracking and observability
langfuse = get_client()
# Create a Langfuse callback handler to capture Langchain agent interactions
langfuse_handler = CallbackHandler()
# Initialize Bright Data tools
bright_data_serp_api_tool = BrightDataSERP()
bright_data_web_unlocker_api_tool = BrightDataUnlocker()
# Initialize the large language model
llm = ChatOpenAI(
model="gpt-5-mini",
)
# Define system prompt that instructs the agent on its compliance and privacy-focused task
system_prompt = """
You are a compliance-tracking expert. Your role is to analyze documents for potential regulatory and privacy issues.
Your analysis is supported by researching updated rules and authoritative sources online using Bright Data's tools, including the SERP API and Web Unlocker.
Provide accurate, enterprise-ready insights, ensuring all findings are supported by quotes from both the original document and authoritative external sources.
"""
# List of tools available to the agent
tools=[bright_data_serp_api_tool, bright_data_web_unlocker_api_tool]
# Define the AI agent
agent = create_agent(
llm=llm,
tools=tools,
system_prompt=system_prompt,
)
# Load all PDF documents from the input folder
input_folder = "./input"
loader = PyPDFDirectoryLoader(input_folder)
# Load all pages from all PDFs in the input folder
docs = loader.load()
# Combine all pages from the PDFs into a single string for analysis
internal_document_to_analyze = "\n\n".join([doc.page_content for doc in docs])
# Define a prompt template to guide the agent through the workflow
prompt_template = PromptTemplate.from_template("""
Given the following PDF content:
1. Have the LLM analyze it to identify the main key aspects worth exploring in terms of privacy.
2. Translate those aspects into up to 3 very short (no more than 5 words), concise, specific search queries suitable for Google.
3. Perform web searches for those queries using Bright Data's SERP API tool (searching for pages in English, limited to the United States).
4. Access up to the top 5 web, non-PDF pages (giving priority to government websites) in Markdown data format using Bright Data's Web Unlocker tool.
5. Process the collected information and create a final, concise report that includes quotes from the original document and insights from the scraped pages to avoid regulatory issues.
PDF CONTENT:
{pdf}
""")
# Fill the template with the content from the PDFs
prompt = prompt_template.format(pdf=internal_document_to_analyze)
# Stream the agent's response while tracking each step with Langfuse
for step in agent.stream(
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="values",
config={"callbacks": [langfuse_handler]} # <--- Langfuse integration
):
step["messages"][-1].pretty_print()可以看到,仅用大约 75 行 Python 代码,你就构建了一个企业级的法规与合规分析 AI Agent,这离不开 LangChain、Bright Data 和 Langfuse 的配合。
步骤十一:运行 Agent
请记住,你的 AI Agent 需要一个 PDF 文件作为输入。假设你希望对下面这份文档做合规分析:
这是一份示例性质的企业文档,从较高层面对公司处理用户数据的流程进行了说明。
将其保存为 user-data-processing-workflow.pdf,并放置在项目根目录下的 input/ 文件夹中: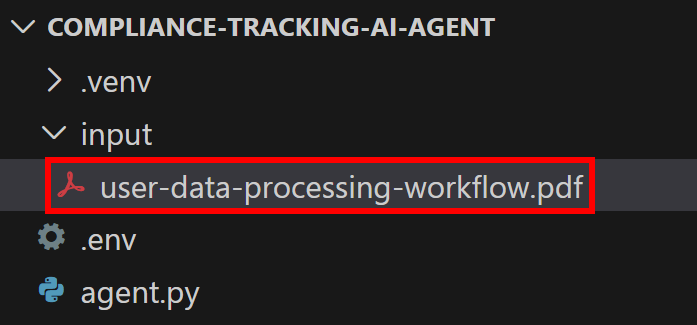
这样脚本就可以访问该文件,并将其内容嵌入到 Agent 的提示词中。
通过以下命令运行 LangChain AI Agent:
python agent.py 在终端中你会看到 Bright Data 工具调用的 trace 输出,例如: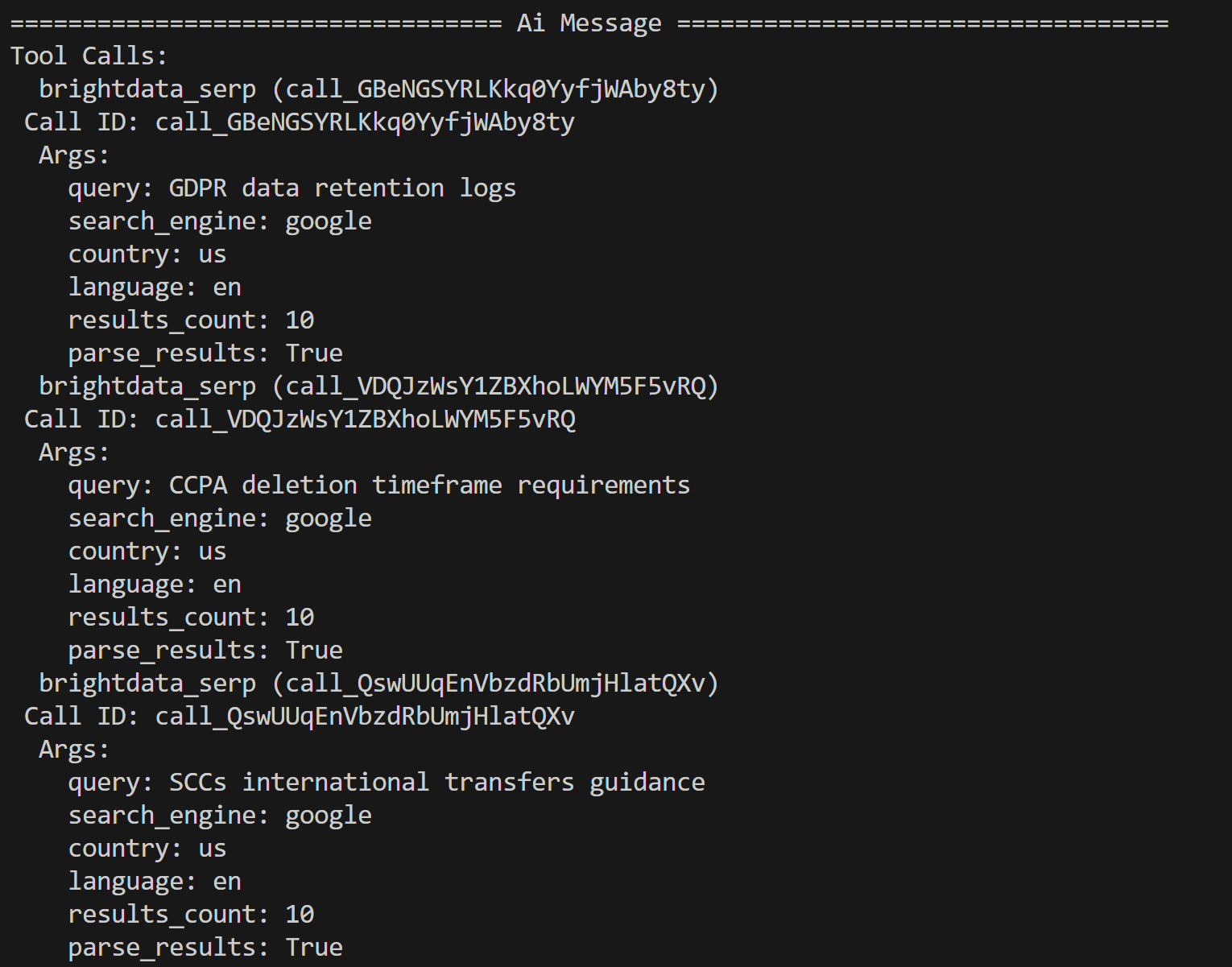
AI Agent 会基于 PDF 内容识别出以下三个搜索查询,用于进一步研究:
- “GDPR data retention logs”
- “CCPA deletion timeframe requirements”
- “SCCs international transfers guidance”
这些查询都和输入文档中提到的潜在法规与隐私问题紧密相关。
Agent 利用 Bright Data SERP API 返回的 Google 搜索结果,从中选取靠前的网页,并通过 Web Unlocker API 工具抓取页面内容: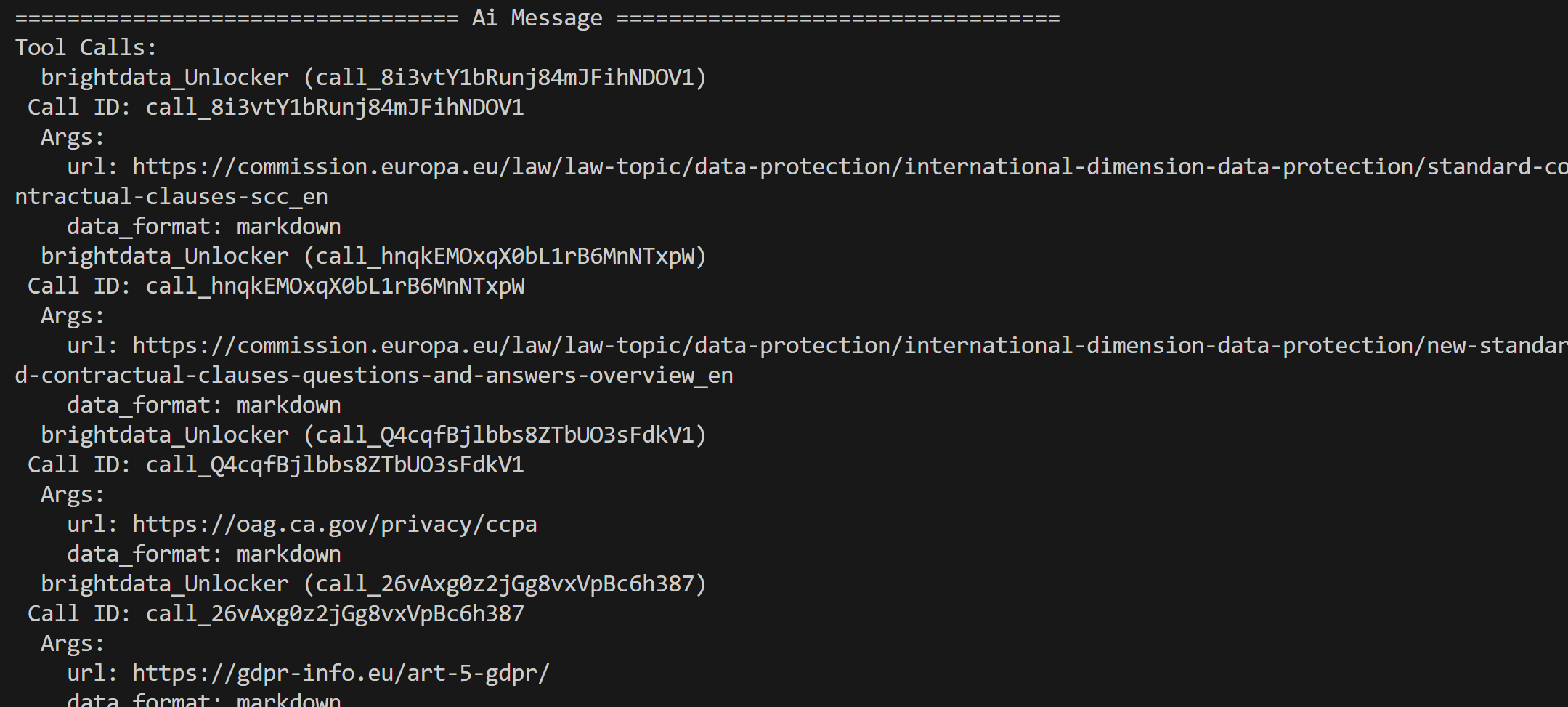
随后 Agent 会对这些页面的内容进行处理并生成一份精简的合规分析报告。
到这里,你的 AI Agent 已经运行良好。接下来看一下集成 Langfuse 后所带来的可观测性效果。
步骤十二:在 Langfuse 中检查 Agent Trace
当你的 AI Agent 开始执行任务时,对应数据会出现在 Langfuse 控制台中。可以看到 “Traces” 计数从 0 增加到 1,同时模型成本也在上升: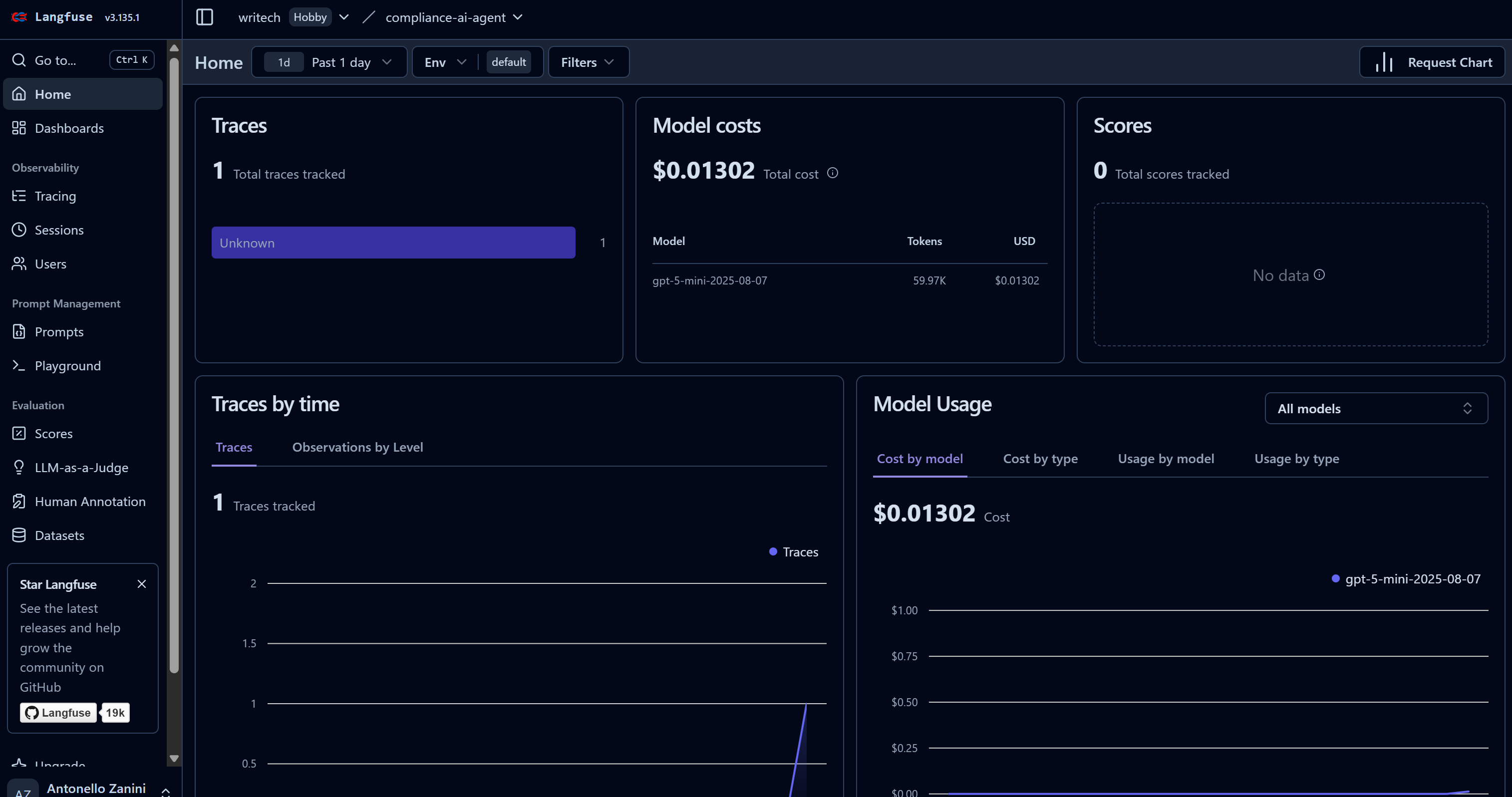
这个 Dashboard 不仅用于监控成本,还可以查看许多其他重要指标。
要查看某次 Agent 运行的全部信息,可进入 “Tracing” 页面,点击对应的 trace 行: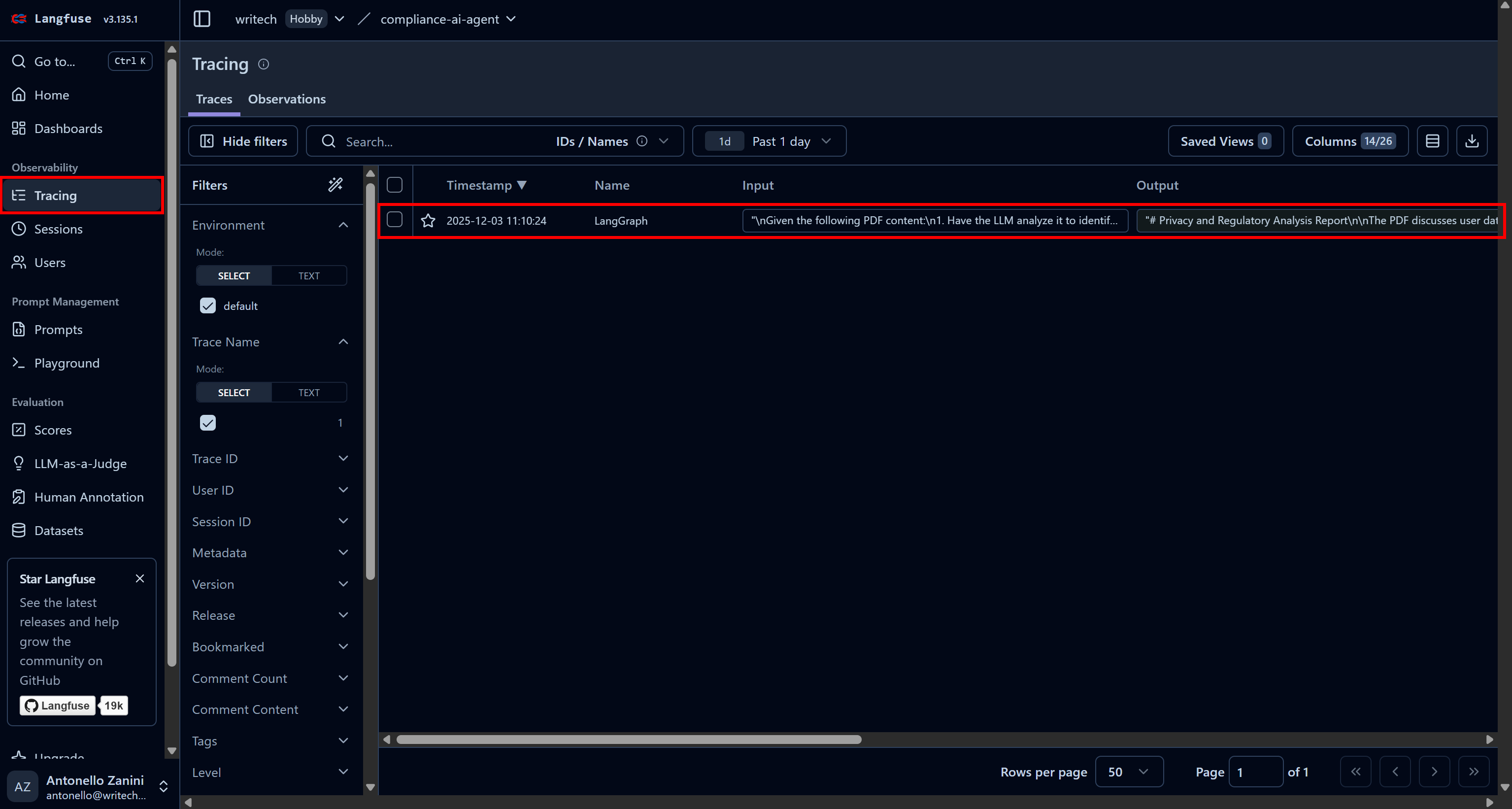
左侧会弹出一个面板,展示此次运行中每个步骤的详细信息。
先关注第一个 “ChatOpenAI” 节点。它显示 Agent 已经调用了三次 Bright Data SERP API,而 Web Unlocker API 还未被调用: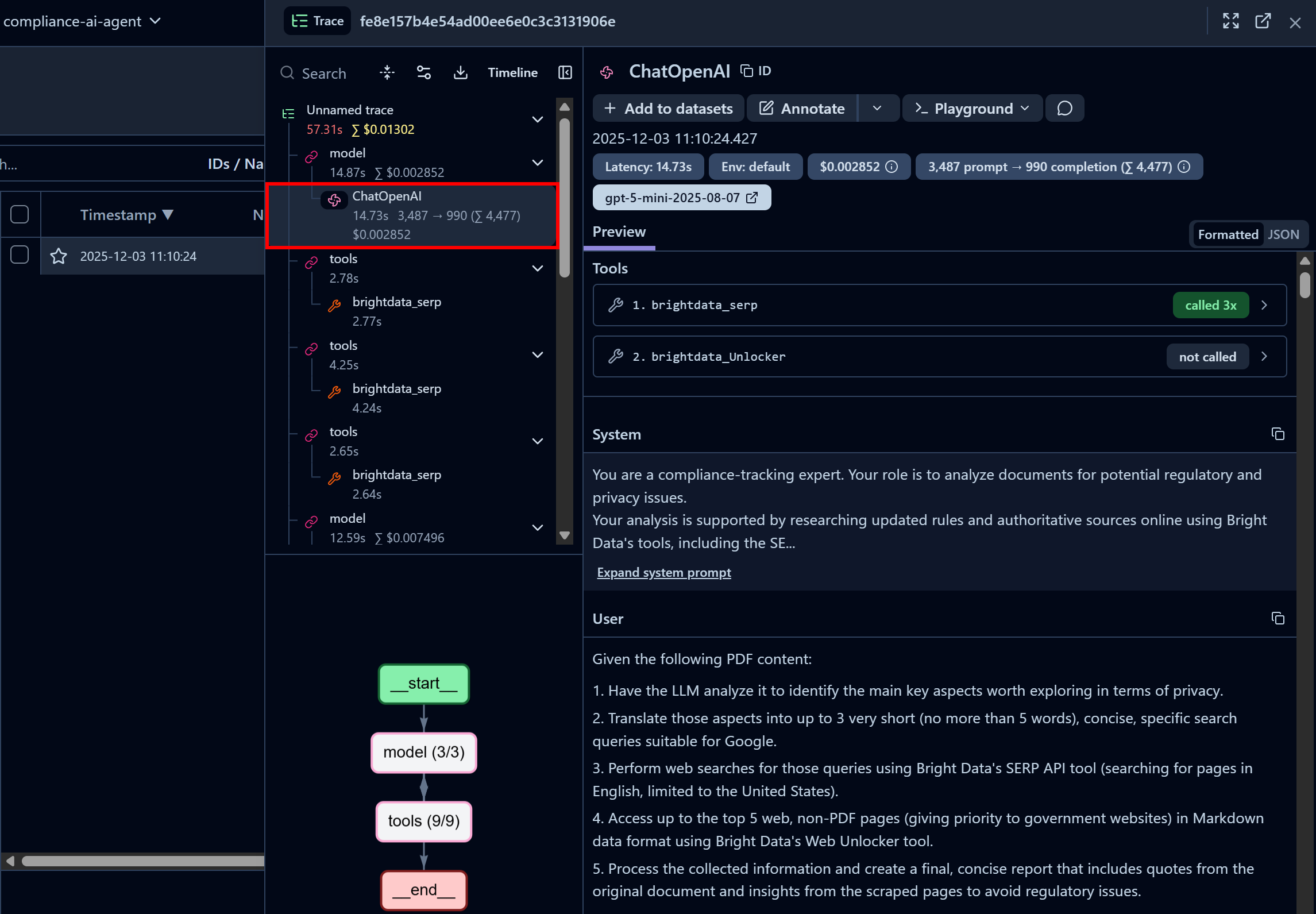
在这里你可以查看代码中配置的系统提示词(System Prompt)与传入的用户提示词(User Prompt),同时还能查看每一步的延迟、成本、时间戳等信息。左下角的交互式流程图则帮助你以可视化方式逐步探索 Agent 的运行。
接着查看一个 Bright Data SERP API 工具调用节点: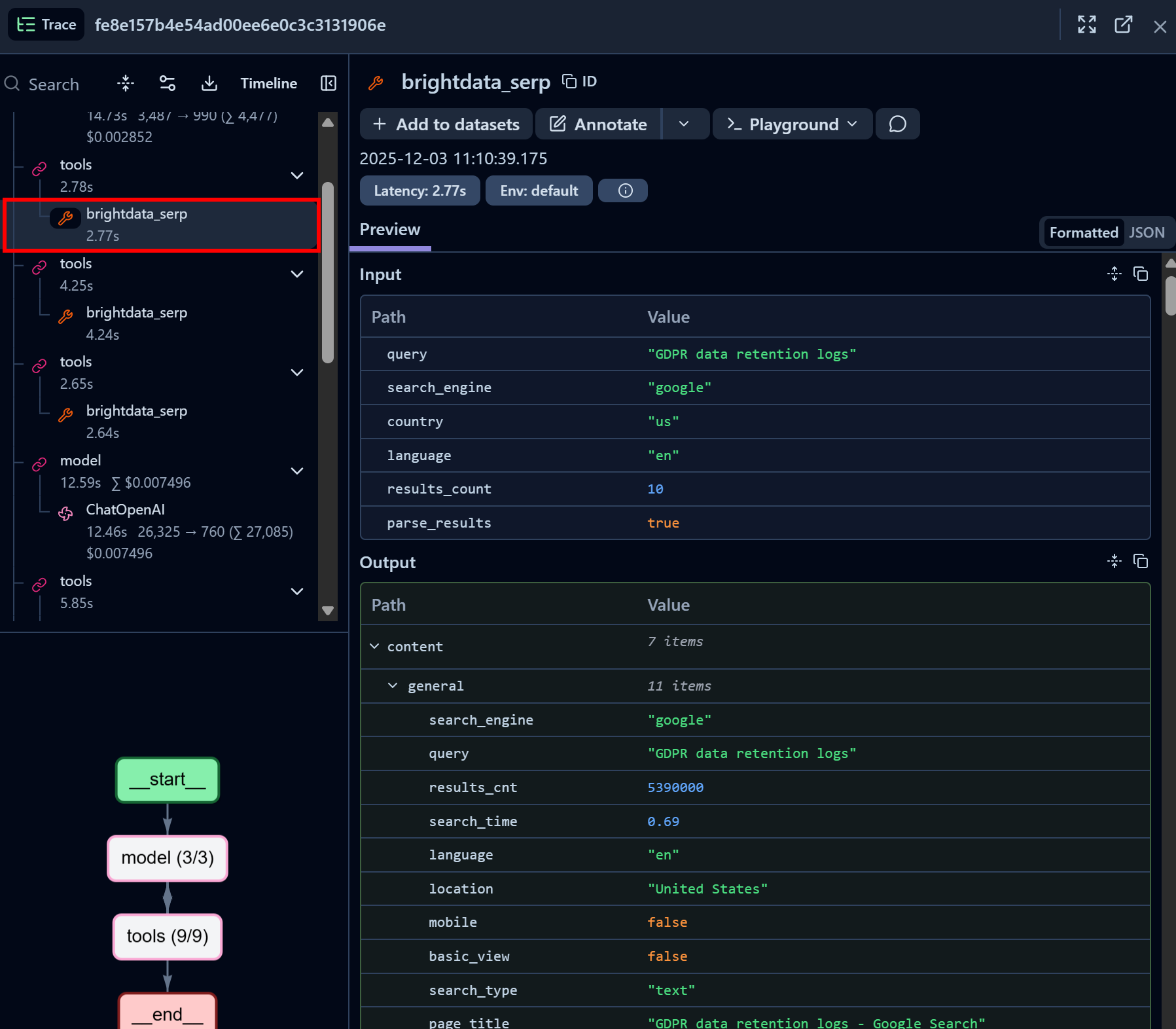
可以看到 Bright Data SERP API LangChain 工具成功返回了某个查询的 SERP 数据,格式为 JSON(非常适合用于AI Agent 中的 LLM 读取)。这表明与 Bright Data SERP API 的集成运行正常。
如果你曾尝试用 Python 抓取 Google 搜索结果,就会知道其中的复杂性。而借助 Bright Data SERP API,整个过程变得直接、快速且完全面向 AI 场景。
类似地,再查看一个 Bright Data Web Unlocker API 工具调用节点: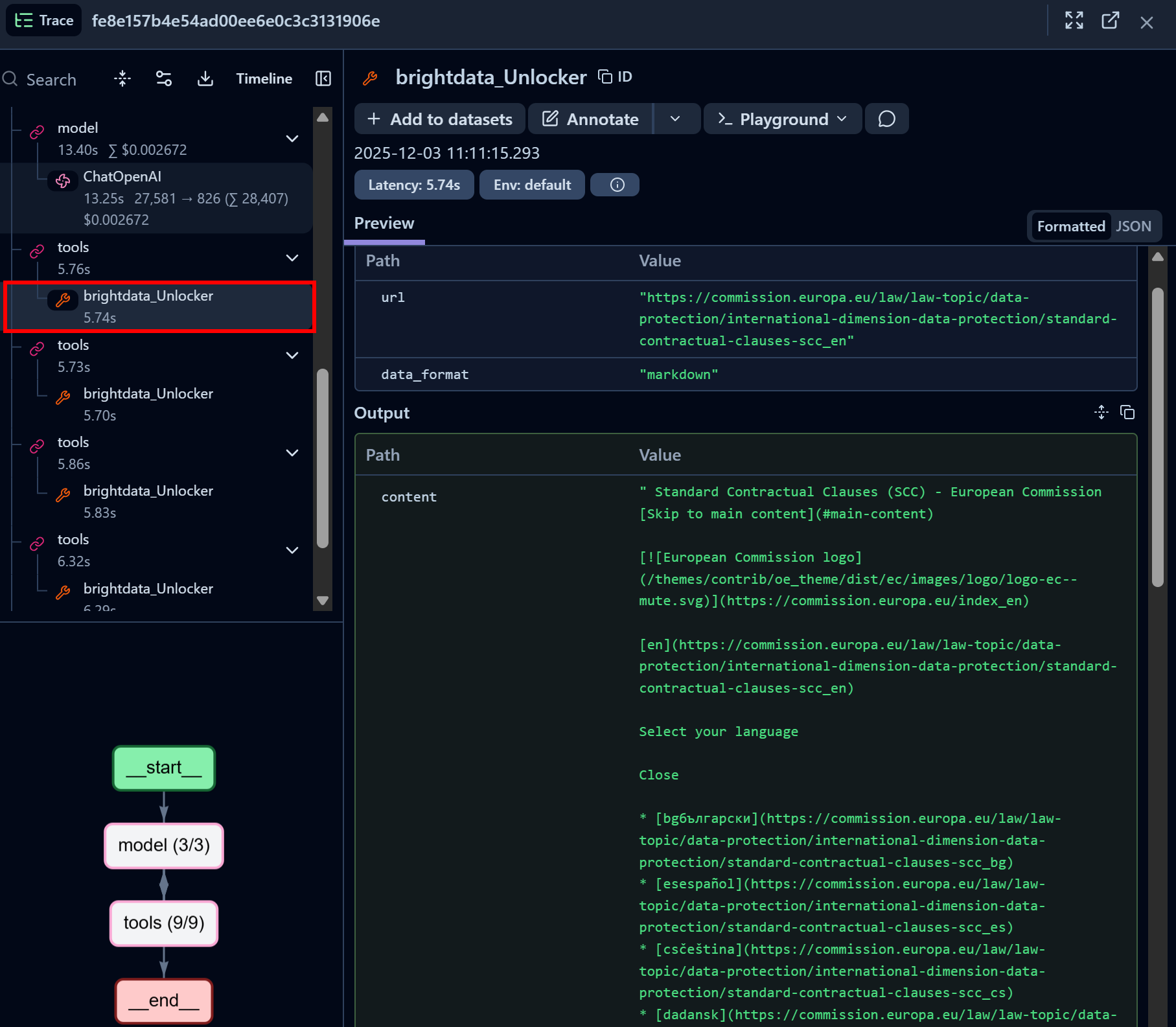
可以看到 Bright Data Web Unlocker LangChain 工具成功访问了目标页面,并以Markdown 格式返回内容。
Web Unlocker API 让你的 AI Agent 可以以编程方式访问任意治理类网站(或其他网页),无需担心封锁问题,并获取适合 LLM 读取的 AI 优化页面内容。
到此为止,Langfuse + LangChain + Bright Data 的集成已经完全打通。Langfuse 还可以集成到许多其他 AI Agent 构建方案中,而这些方案也同样得到了 Bright Data 的支持。
下一步建议
如果希望让这个集成了 Langfuse 的 AI Agent 更具企业级特性,可以考虑以下方向:
- 引入提示词管理:利用 Langfuse 的提示词管理功能,为你的 LLM 应用存储、版本化并动态检索提示词。
- 导出报告:将最终报告导出到磁盘、保存到共享文件夹,或通过邮件发送给相关干系人。
- 自定义 Dashboard:在 Langfuse 中自定义 Dashboard,只展示对你的团队和干系人最重要的指标。
总结
在本教程中,你学习了如何使用 Langfuse 监控和追踪 AI Agent 的运行情况,尤其是如何对一个基于 LangChain、由Bright Data AI 就绪网页访问解决方案驱动的 AI Agent 进行埋点。
正如文中所述,与 Langfuse 类似,Bright Data 也能与多种 AI 解决方案集成,从开源工具到企业级平台。这使你可以为 Agent 提供强大的网页数据检索和浏览能力,并通过 Langfuse 持续监控其性能和行为。
立即免费注册 Bright Data,开始体验我们的 AI 就绪网页数据解决方案吧!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




