

在本教程中,你将了解:
- IBM watsonx 如何支持 AI Agent 开发。
- 为什么集成 Bright Data 的 SERP API 能增强 IBM watsonx Orchestrate 代理的能力。
- 在 IBM watsonx Orchestrate 中利用 Bright Data SERP API 构建 AI Agent 的完整步骤。
让我们开始吧!
什么是 IBM watsonx 中的 AI Agent 构建功能?
IBM watsonx Orchestrate 是一套面向企业的生成式 AI 与自动化系统,它提供 AI Agent 构建能力。该解决方案为你提供设计、部署和管理自主 AI Agent 所需的一切,这些 Agent 能执行任务、做出决策并与关键业务系统交互。
在 IBM watsonx 中,你既可以通过低代码 Web 界面构建 Agent,也可以通过 Agent Development Kit (ADK) Python 库进行代码式开发。本文将重点介绍使用 Web 应用进行的低代码工作流集成方式。
Orchestrate 服务中的 Agent 可以通过多 Agent 协同进行编排、连接多种外部工具、利用 RAG(检索增强生成)实现基于知识的回答,以及更多功能。
该平台还包含治理与可观测性功能,以确保合规性、透明度和性能监控。构建完成后,Agent 可以在 Web 聊天、Slack、Microsoft Teams 等多个渠道中部署。
为什么 IBM watsonx Agents 需要访问 Bright Data 的 SERP API
大语言模型(包括 IBM watsonx 中可用的模型)受限于其训练数据。简单来说,它们的知识只更新到某个时间点。
因此,LLM 往往会产生过时或不准确的回答。当 AI Agent 需要负责决策或生成支持决策的报告时,这个问题会更加严重……
解决方案是为你的 Agent 配备可以获取并处理可靠数据的工具。例如,Agent 可以查询搜索引擎以收集经过验证、最新的信息,并从这些数据中学习,从而减少幻觉。这样得到的结果是更准确的决策,以及对 Agent 回答基于真实世界知识的更高信心。
实现这一点最简单的方式,就是使用 SERP API 或网页搜索工具,例如 Bright Data 的 SERP API。这是一款企业级的搜索引擎数据采集 API,它为你处理代理、解封以及数据格式化等工作。换句话说,你无需再为在 AI Agent 中采集搜索引擎数据时通常会遇到的各种挑战操心。
Bright Data 的 SERP API 可以直接集成到 IBM watsonx Orchestrate(以及许多其他 AI Agent 构建平台)中,使你的 AI Agent 能访问搜索结果,从而生成更具上下文、更可信、且可验证的输出。
在 IBM watsonx.ai 中开发集成 SERP API 的 AI Agent:分步指南
在本节中,你将学习如何在 IBM watsonx Orchestrate 中将 Bright Data SERP API 作为工具集成到 AI Agent 中。
在众多可能的使用场景中,本教程以构建“内容推荐 Agent”为例。它的目标是根据给定主题的最新趋势提供内容创意(例如,发掘值得撰写文章或制作 YouTube 视频进行营销的最新热门新闻)。
注意:这只是一个示例,你可以基于同样的 SERP API 集成来支持许多其他AI 驱动的使用场景。
按照下面的步骤进行操作!
前置条件
要顺利跟随本教程,请确保你已有:
- 用于登录 IBM watsonx Orchestrate 的 IBMid(免费试用版即可)。
- 一个带有效 API 密钥的 Bright Data 账号。
暂时不必担心如何配置 Bright Data 账号,文中稍后会一步步带你完成。
如果你已经大致了解 Bright Data SERP API 的工作方式、AI Agent 如何调用工具,以及用 OpenAPI 规范定义工具的基础知识,将会更有帮助。
步骤一:创建一个新的 IBM watsonx AI Agent
使用 IBM 账号登录 IBM watsonx Orchestrate。你将进入如下页面:
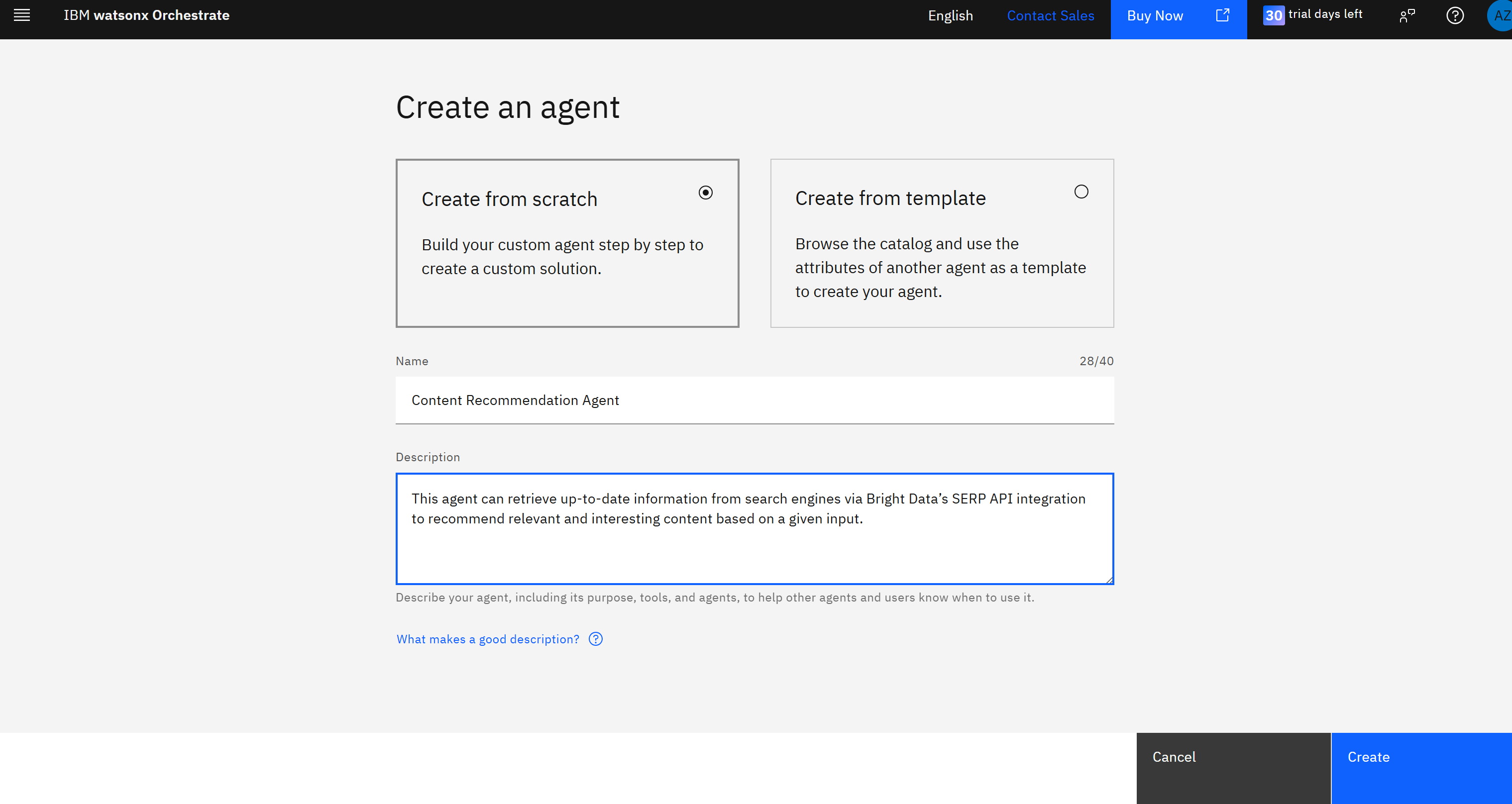
在这里,点击左侧的 “Create new agent” 按钮来打开创建新 Agent 的表单。按如下方式填写 “Create an agent” 表单:
- 选择 “Create from scratch” 选项。
- 给你的 Agent 起一个名字,比如 “Content Recommendation Agent”(内容推荐 Agent)。
- 添加如下描述:“This agent can retrieve up-to-date information from search engines via Bright Data’s SERP API integration to recommend relevant and interesting content based on a given input.”(该 Agent 可通过集成 Bright Data 的 SERP API,从搜索引擎获取最新信息,并基于给定输入推荐相关且有趣的内容。)
完成后,点击左下角的 “Create” 按钮继续。系统会将你带到 Agent 管理页面:
很好!你刚刚在 IBM watsonx Orchestrate 中初始化了一个内容推荐 AI Agent。接下来,你将很快把它与 Bright Data 的 SERP API 集成,以便获取最新搜索结果。
步骤二:自定义你的 Agent
在 Agent 管理页面中,你可以自定义多个选项,例如 Agent 的语音、AI 模型、起始提示语、欢迎消息等等。
如需更换模型,在 “AI model” 部分右侧打开下拉菜单:
在 IBM watsonx 试用版中,你可以使用以下两个模型:
llama-3-2-90b-vision-instruct:针对视觉识别、图像推理、图像描述与图像问答进行了优化。这是默认模型。llama-3-405b-instruct:面向合成数据生成、蒸馏以及聊天机器人、编程与特定领域任务推理的高级 LLM,由 Meta 开发。
选择最符合你 Agent 目标的模型即可。
接着,可以更新欢迎消息,使其更贴合 Agent 的功能。例如写成:“你想获取哪些内容推荐方面的建议?”
同时,更新快速开始提示(Quick start prompts),以给用户提供示例交互:
- “推荐一些我最近一定要看的热门电影。”
- “给我展示最近关于 IBM watsonx 的新闻报道。”
- “查找 2026 年 AI 领域的热门博客话题,并给出我可以写的 5 个内容创意。”
由于该 Agent 将主要依赖工具(特别是 Bright Data SERP API),很有必要将其定义为一个 ReAct Agent。如果你对这种架构还不熟悉,ReAct Agent 大致遵循以下流程:
- Thought(思考):LLM 规划下一步要做什么。
- Action(行动):通过工具执行操作。
- Observation(观察):观察结果并调整策略。
这个持续循环使 Agent 能够处理复杂查询、交叉验证信息,并在给出最终回答前验证中间结果。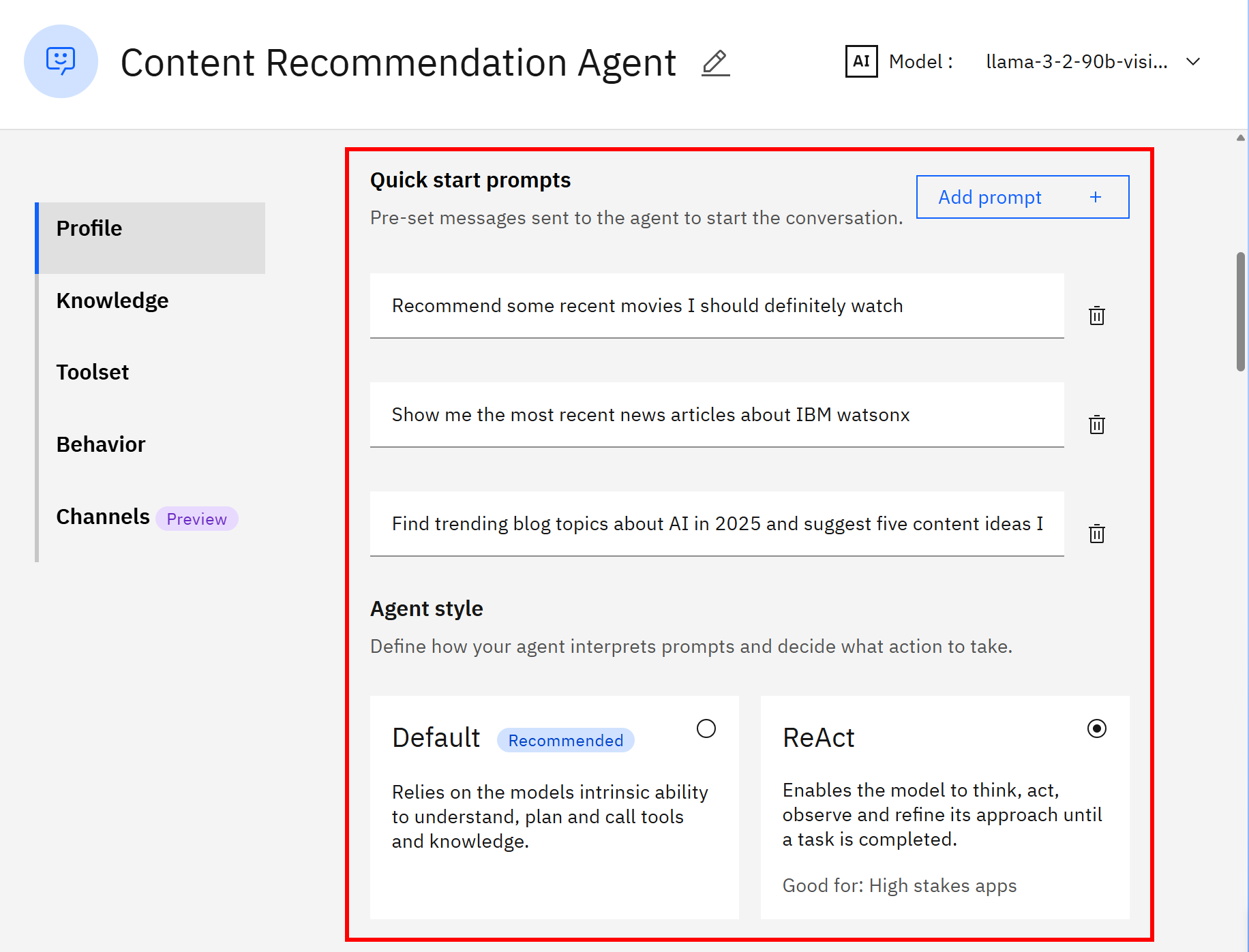
完成所有配置后,在右侧的 “Preview” 区域中点击 “Reset chat” 按钮,重新加载 Agent 预览:
此时,你将看到已经应用所有自定义设置后的 Agent:
步骤三:开始使用 Bright Data 的 SERP API
在继续定义 AI Agent 之前,你需要先准备好 Bright Data 账号并配置 SERP API 服务。为此,你可以参考官方 Bright Data 文档或按照下文步骤操作。
如果你之前还没有账号,请先注册 Bright Data 账号。如果已有账号,只需登录控制台。登录后,前往 “Proxies & Scraping” 页面,在 “My Zones” 区域的表格中查找名为 “SERP API” 的一行: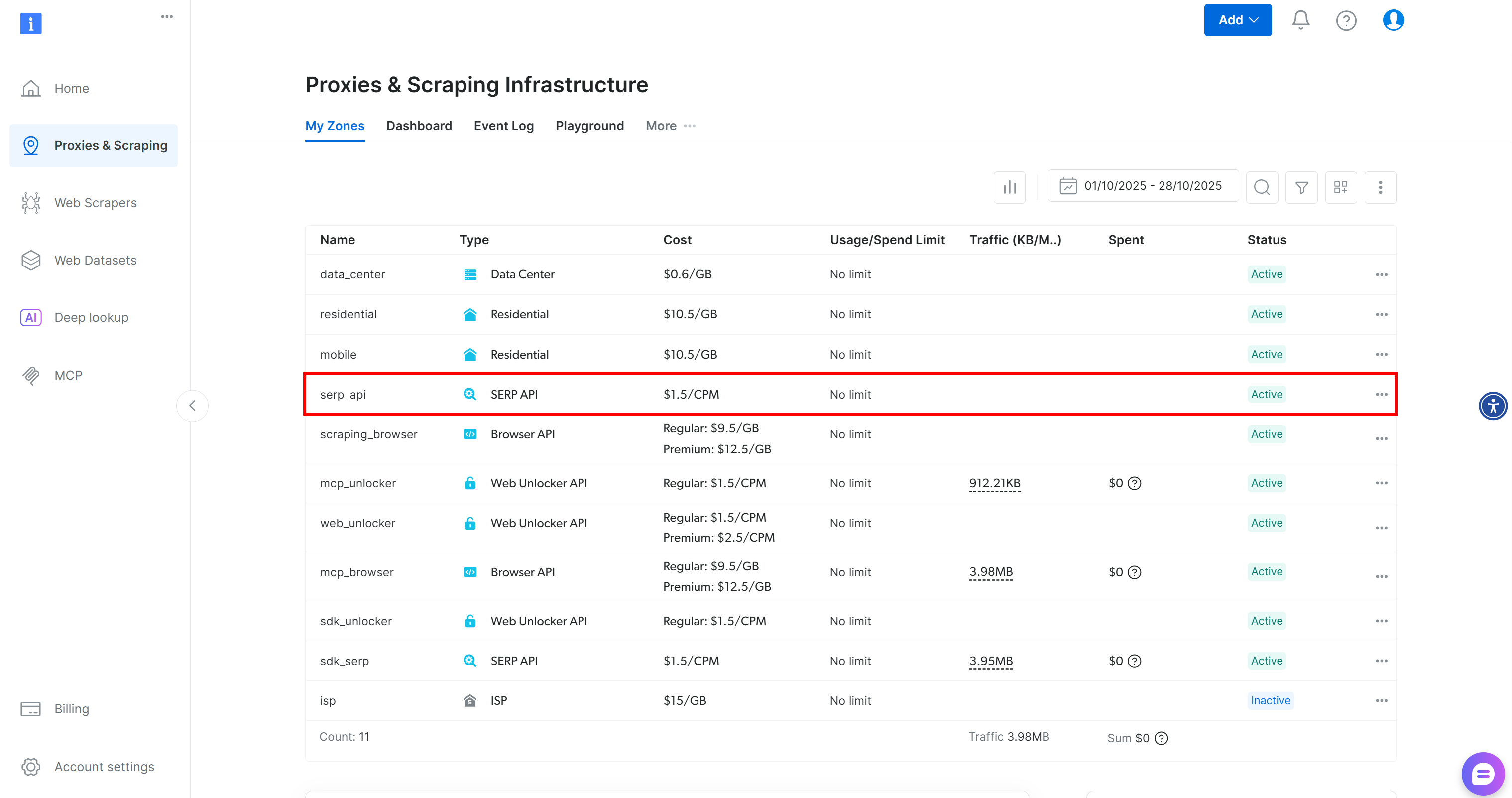
如果你没有看到 “SERP API” 这一行,说明还没有创建对应的 Zone。向下滚动到 “SERP API” 区域,并点击 “Create zone” 新建一个 Zone: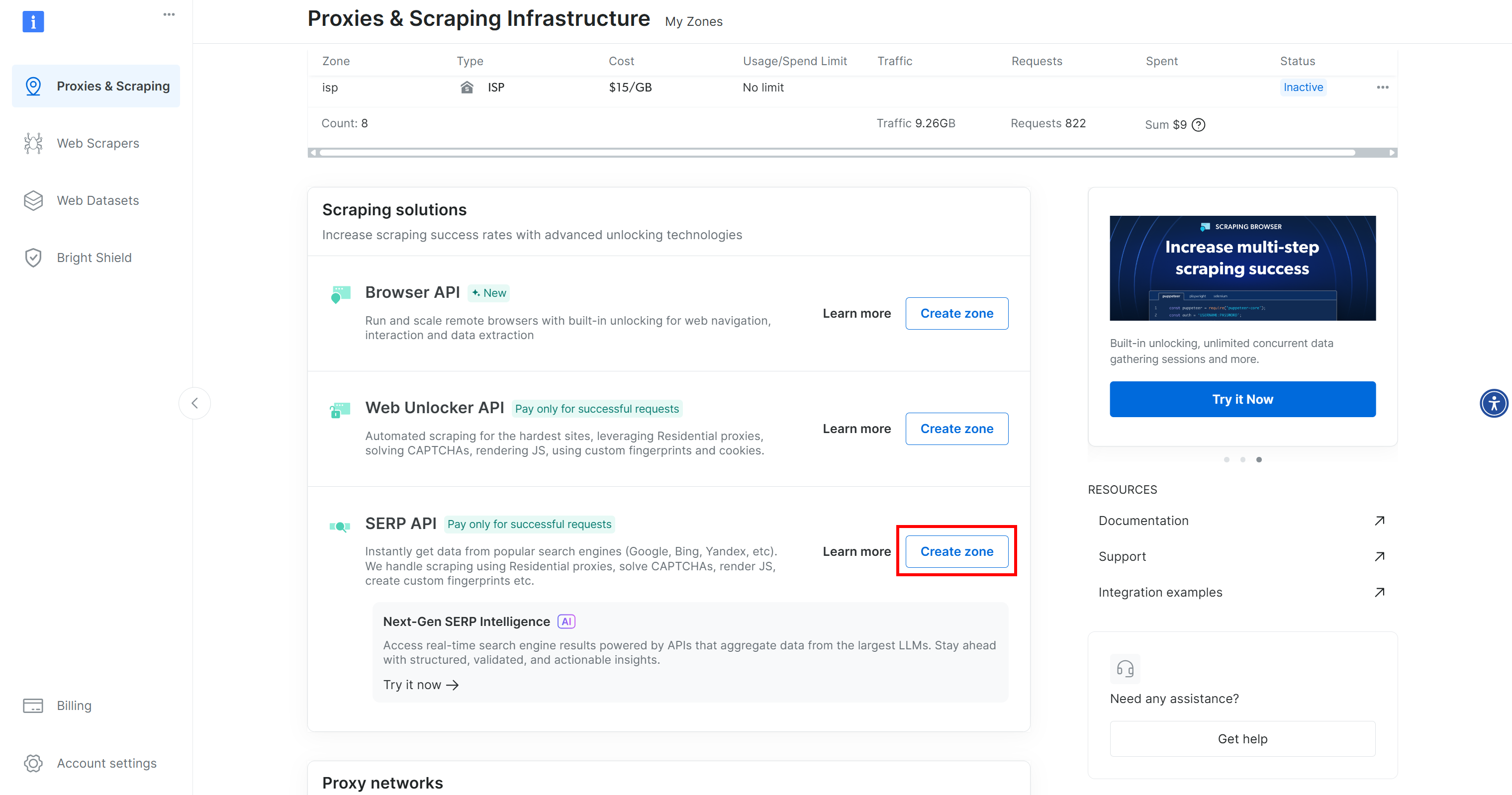
创建一个 SERP API Zone,并为其设置名称,例如 serp_api(或者任意你喜欢的名字)。请务必记住该 Zone 名称,因为你稍后在 IBM watsonx 中访问该服务时需要用到它。
在 SERP API 产品页面中,将 “Activate” 开关切换为开启状态以激活该 Zone: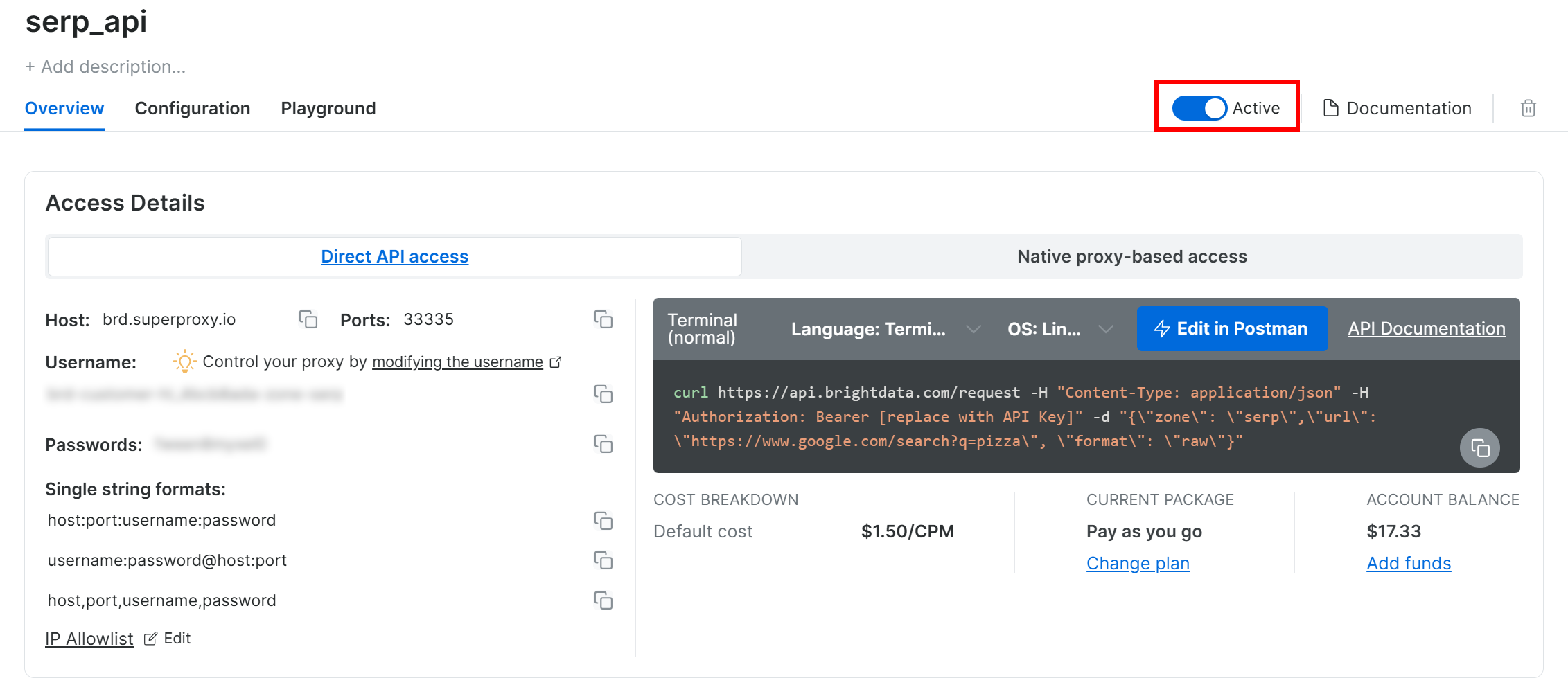
最后,按照官方教程生成 Bright Data API 密钥。请妥善保存该密钥,之后你会用到它。
我们也建议你先浏览 Bright Data SERP API 文档,以熟悉如何调用 API、可用参数以及更多细节。
很好!到这里,你已经完成了在 IBM watsonx AI Agent 中使用 Bright Data SERP API 的所有准备工作。
步骤四:添加 SERP API 工具
在自定义选项中,你还可以为 Agent 添加工具。这正是将 AI Agent 连接到 Bright Data SERP API 的方式。下面我们将通过接下来的三个步骤详细介绍这个自定义工具的定义与集成过程。
要为 Agent 添加新工具,在 “Tools” 区域点击 “Add Tool” 按钮: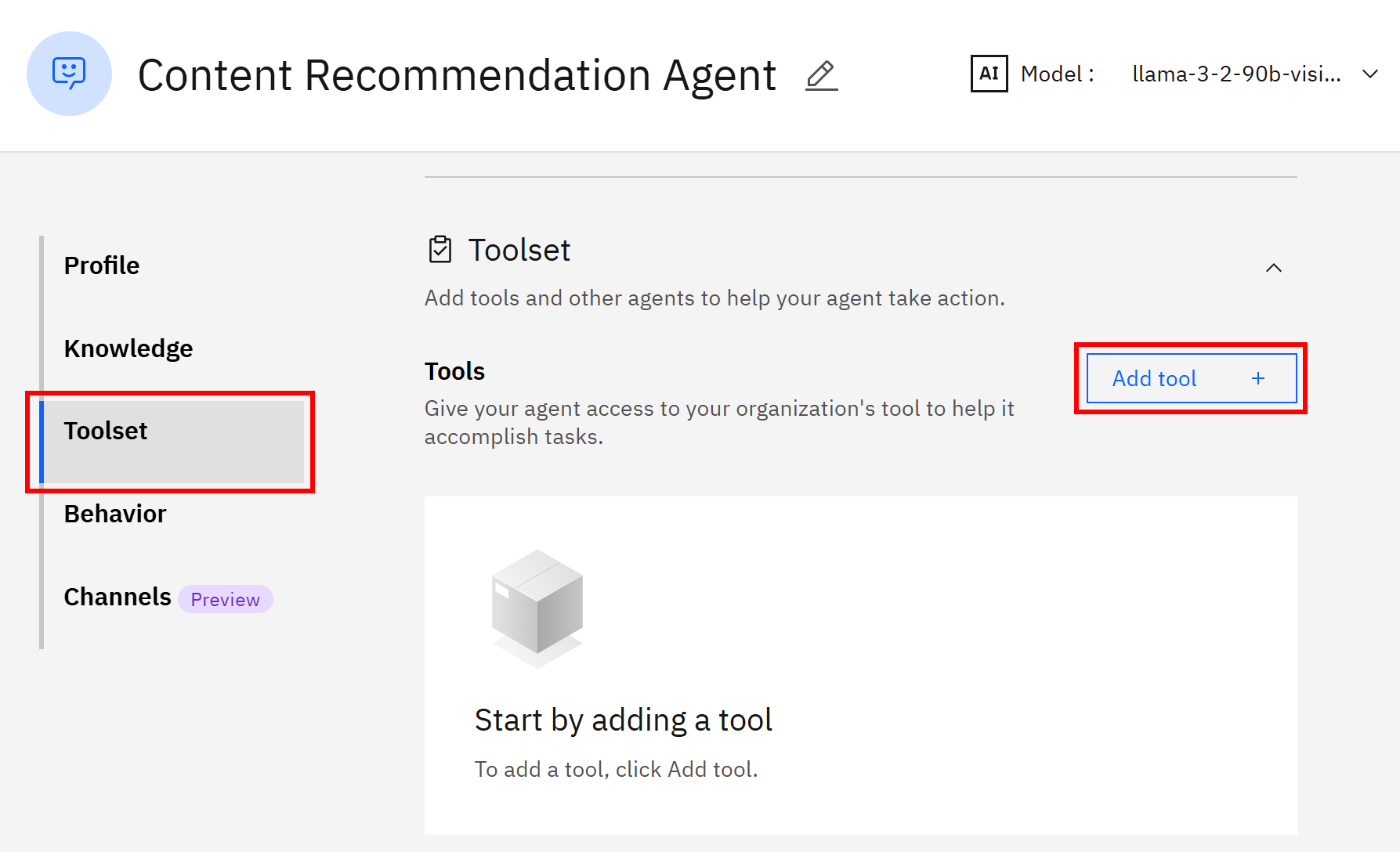
通常,你或许会考虑选择 “Create an agent workflow” 选项,然后通过 Python 代码连接 Bright Data SERP API。然而,在撰写本文时,可在自定义 Python 代码节点中导入和使用的Python 模块列表是固定的,无法扩展。由于常用的Python HTTP 客户端不在其中,自定义代码方式暂时行不通。相反,你可以通过 OpenAPI 规范在工具中集成 SERP API。
更具体地说,你要通过 OpenAPI 定义添加 Bright Data API 工具。为此,在本地机器上创建一个名为 bright-data-serp-api.yml 的文件,并填入如下规范:
openapi: 3.0.3
info:
title: Bright Data SERP API
version: 1.0.0
description: >
Bright Data SERP API provides real user results in high volumes for all the
major search engines. Supports raw and Markdown output formats.
servers:
- url: https://api.brightdata.com
paths:
/request:
post:
summary: Send a SERP request
description: >
Submit a SERP scraping request using your Bright Data SERP API zone.
tags:
- SERP
requestBody:
required: true
content:
application/json:
schema:
type: object
required:
- zone
- url
properties:
zone:
type: string
description: Your SERP API zone name.
default: <YOUR_BRIGHT_DATA_SERP_API_ZONE_NAME>
url:
type: string
description: The search engine URL to query (e.g., https://www.google.com/search?q=<search_query>)
example: https://www.google.com/search?q=pizza&hl=en&gl=us
format:
type: string
description: Response format
default: raw
data_format:
type: string
description: Output data format
default: markdown
responses:
"200":
description: Successful response with search results
content:
text/plain:
schema:
type: string
"400":
description: Invalid request
"401":
description: Unauthorized - invalid API key
"500":
description: Internal server error
security:
- bearerAuth: []
components:
securitySchemes:
bearerAuth:
type: http
scheme: bearer
bearerFormat: API_KEY重要:请将 <YOUR_BRIGHT_DATA_SERP_API_ZONE_NAME> 替换为你之前创建的 SERP API Zone 的真实名称(例如 serp_api)。
上面的 YAML 代码定义了一个用于集成 Bright Data SERP API 的 OpenAPI v3.0.3 规范。需要注意的关键点包括:
- 请求体中定义了如下参数:
zone:你的 SERP API Zone 名称。url:需要查询的搜索引擎页面 URL。format:指定 API 输出数据的方式。"raw"表示 API 会将抓取到的数据直接返回在响应体中,而不是嵌套在结构化对象里。data_format:确定响应格式,例如 HTML、解析后的 JSON 或 Markdown。此处默认设置为"markdown",因为这是一种非常适合AI 消化与理解的数据格式。
securitySchemes下的bearerAuth表示该 API 连接通过用户提供的 API 密钥来认证,在Authorization头中采用 Bearer 机制(这正是使用 Bright Data API 密钥调用 SERP API 的认证方式)。
关键是理解:上述 OpenAPI 规范定义了一个会以 Markdown 格式返回数据的 Bright Data SERP API 调用。有关每个参数与选项的含义与更多细节,请参阅官方文档。
要将该 YAML 文件导入 IBM watsonx,在 “Add a new tool” 模态窗口中选择 “Add from file or MCP server”: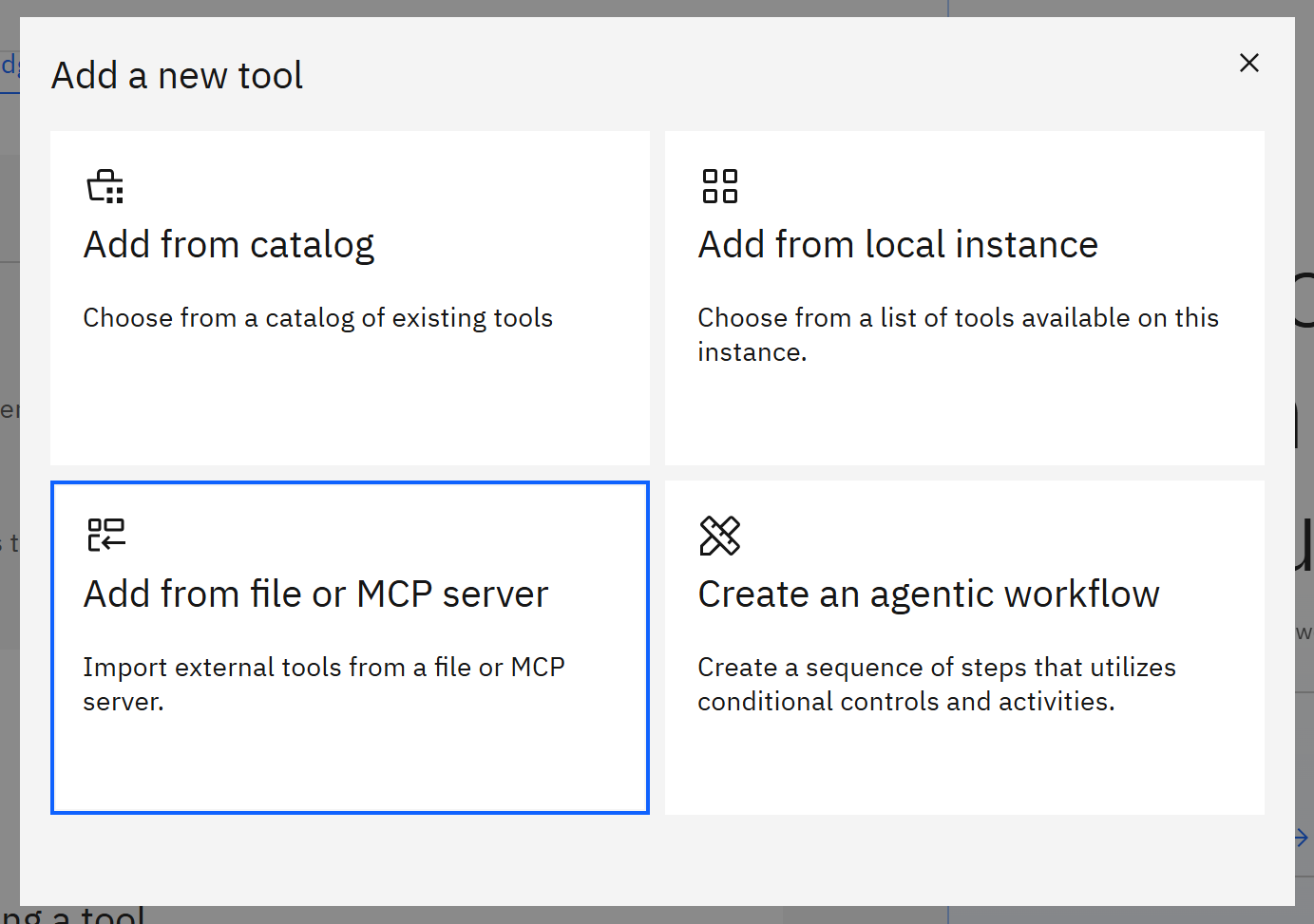
然后选择 “Import from file”: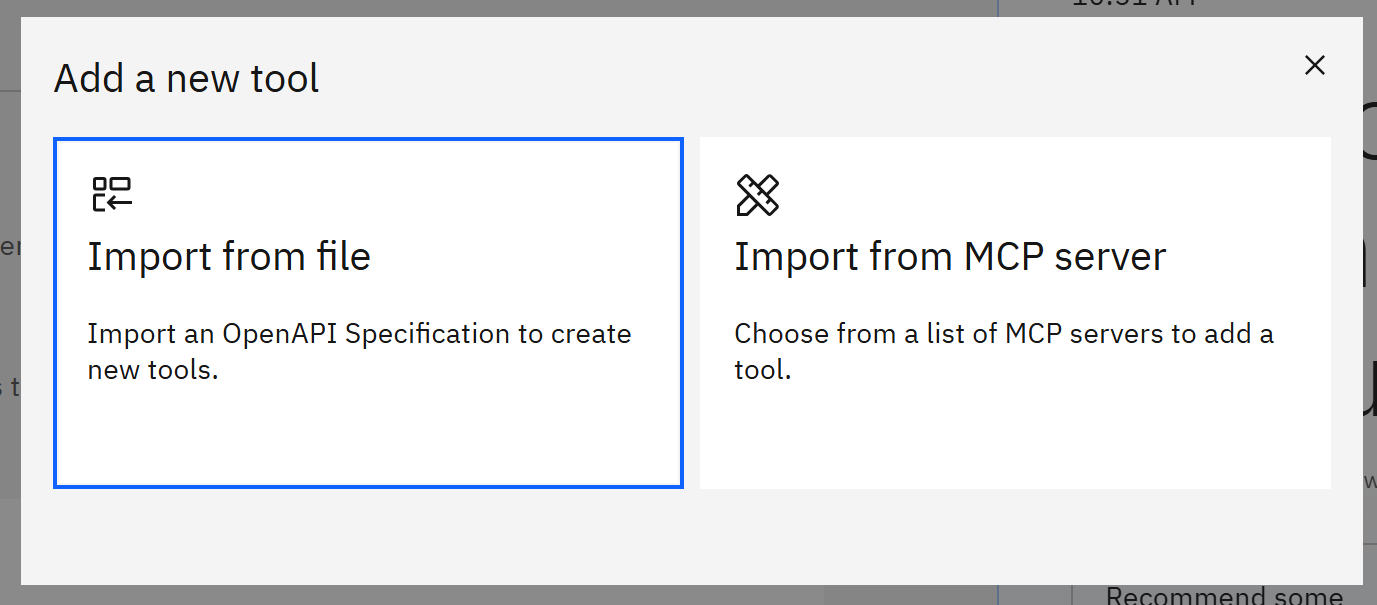
提示:为更方便地访问 AI 就绪的 Bright Data 产品,你也可以选择 “Import from MCP server” 选项,并配置Bright Data 的远程 Web MCP 实例。
在 “Import tool” 模态窗口中,将 bright-data-serp-api.yml 文件拖拽到区域内或者点击上传: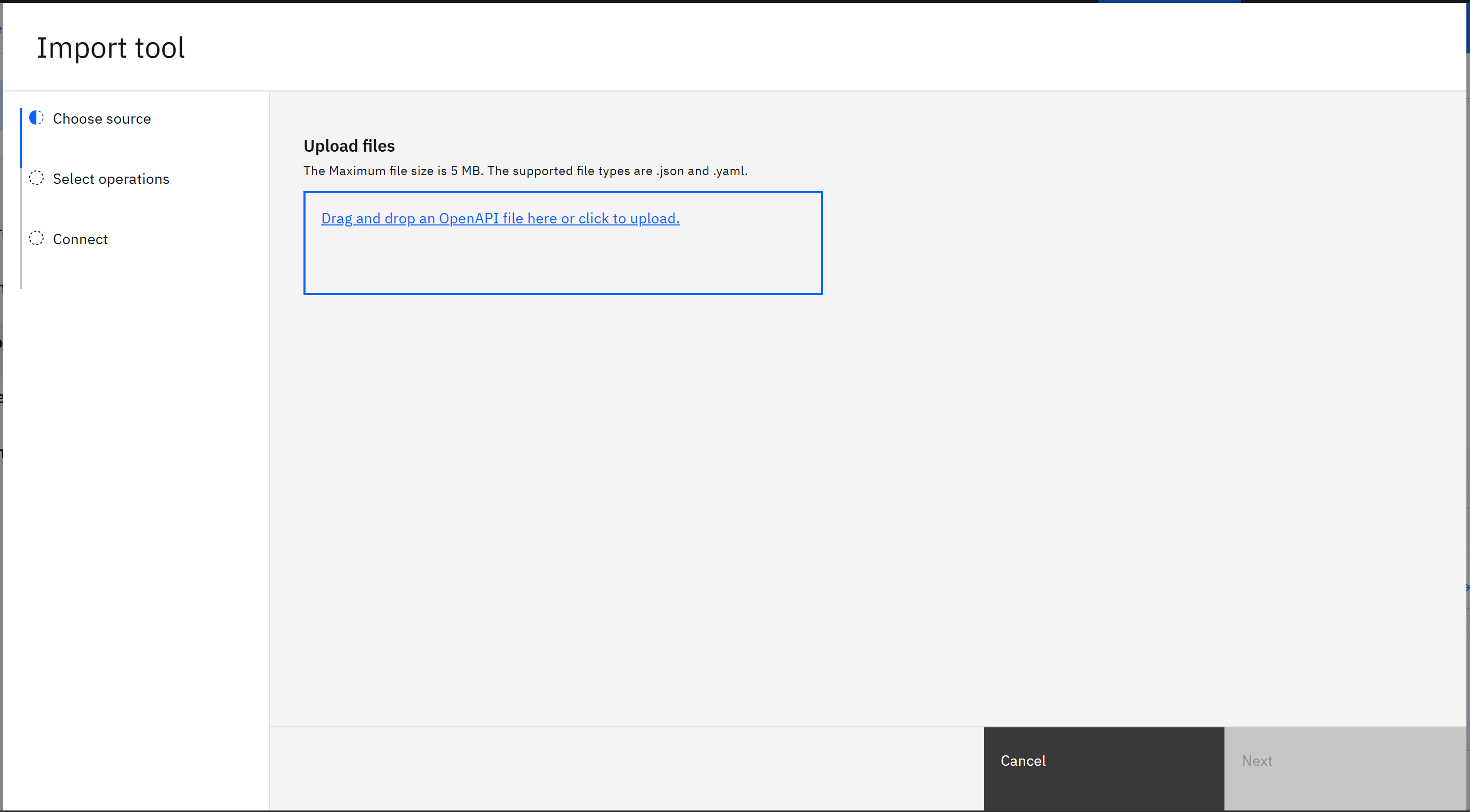
验证完成后,你将看到如下确认消息: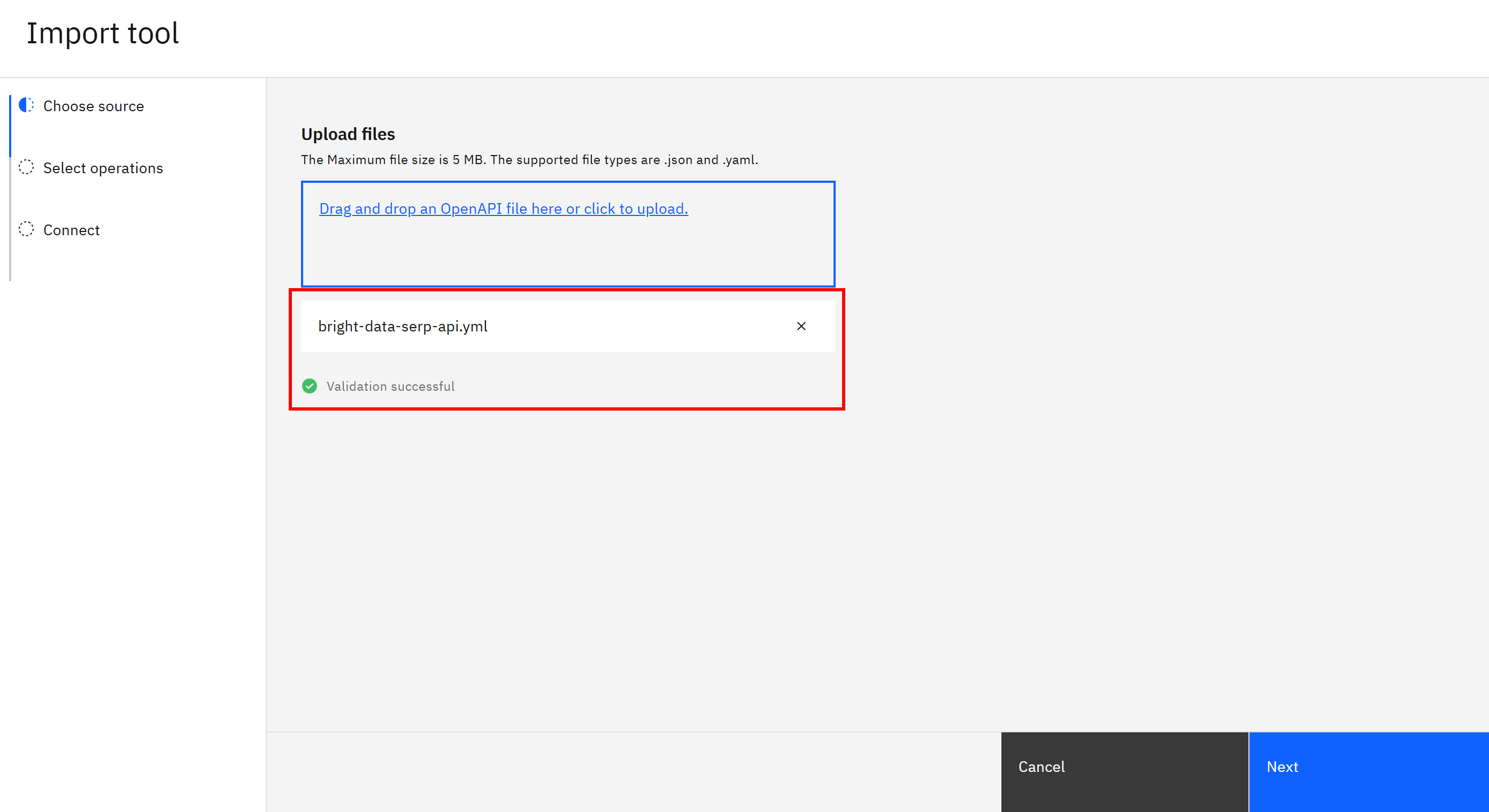
成功!用于集成 Bright Data SERP API 的 OpenAPI 规范已被接受。点击 “Next”,继续在 Agent 中完成该工具的集成。
步骤五:完成 SERP API 工具的认证配置
点击 “Next” 按钮后,你会在 “Operations” 表格中看到 “Send a SERP request” 这一行: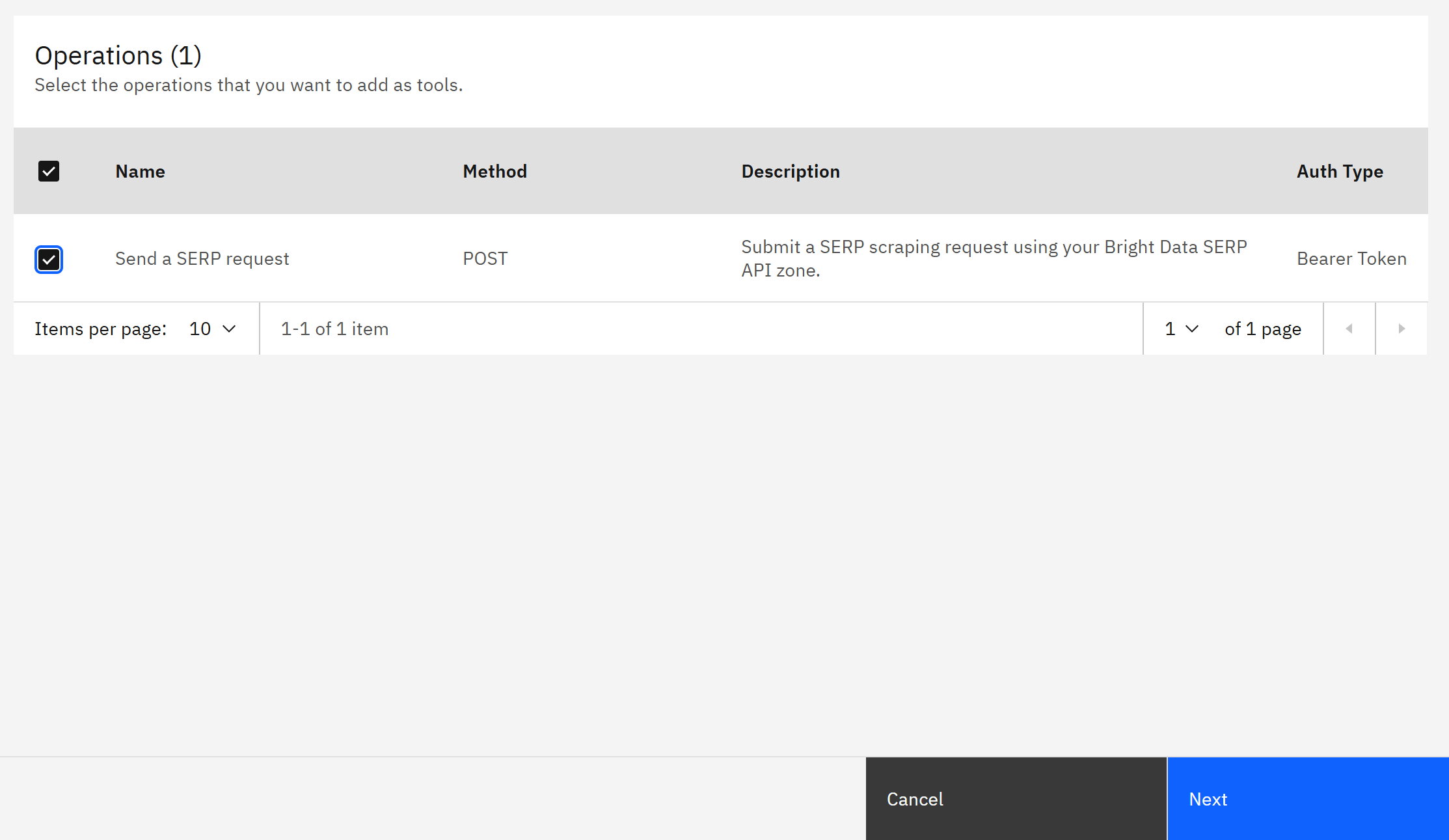
勾选它并点击 “Next” 按钮。接下来会进入 “Connections” 部分,你需要在这里配置用于通过 Bright Data API 密钥认证 SERP API 请求的连接。首先点击 “Add new item” 按钮: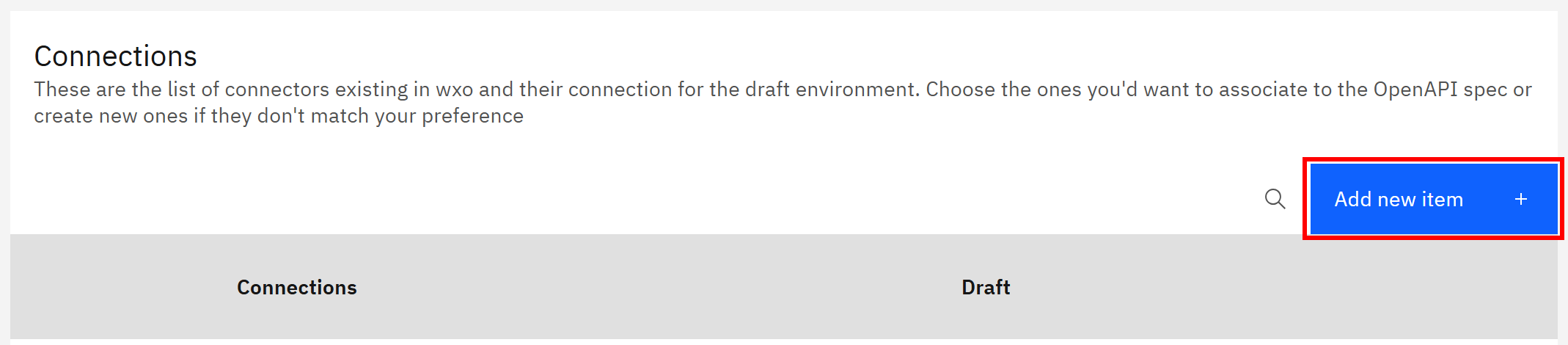
在 “Add new connection” 区域,为该连接设置一个 ID,例如 bright-data-api-key: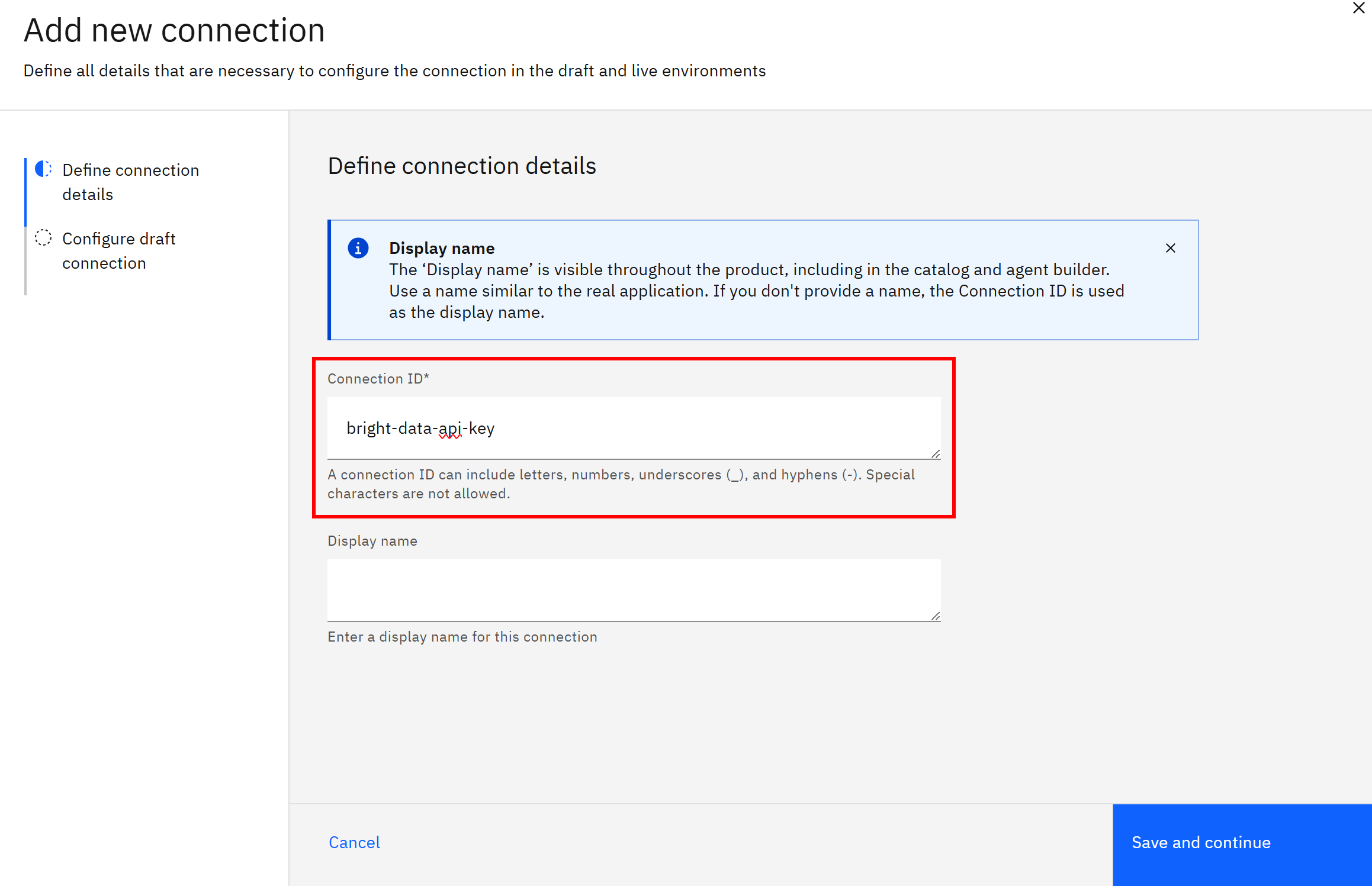
点击 “Save and continue”,再按如下方式配置你的连接:
- Authentication type:选择 “Bearer Token”。
- Credentials type:选择 “Team credentials”。
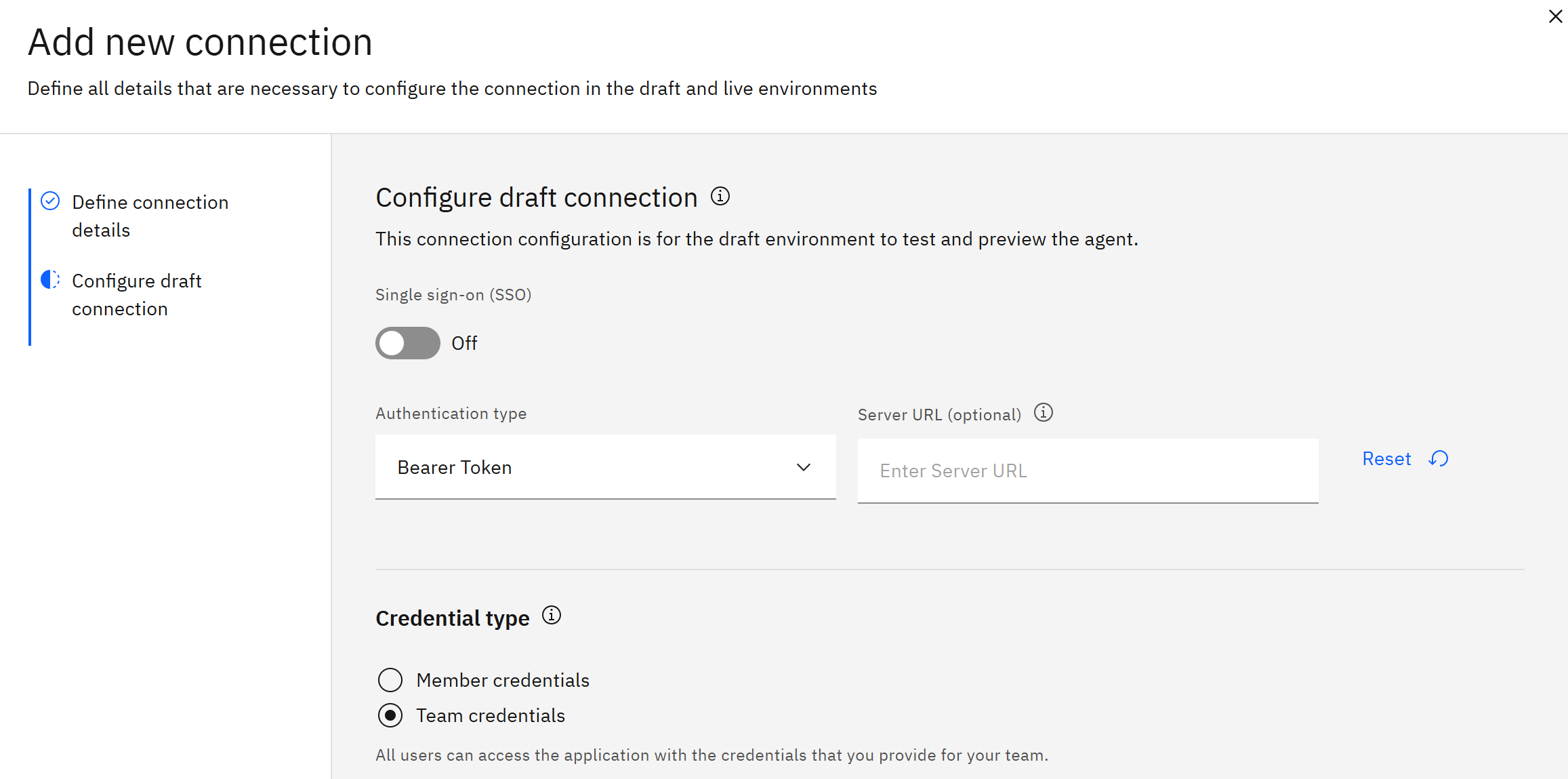
选择 “Team credentials” 后会出现 “Bearer token” 输入框,在其中粘贴你的 Bright Data API 密钥,然后点击 “Connect”: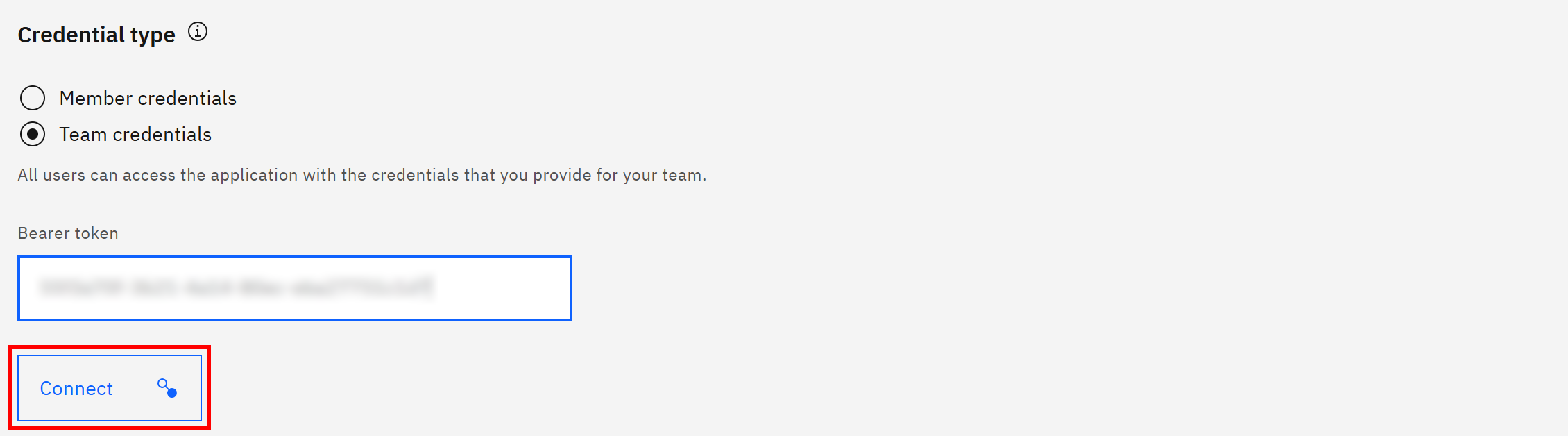
连接验证成功后,你会看到类似如下的确认信息: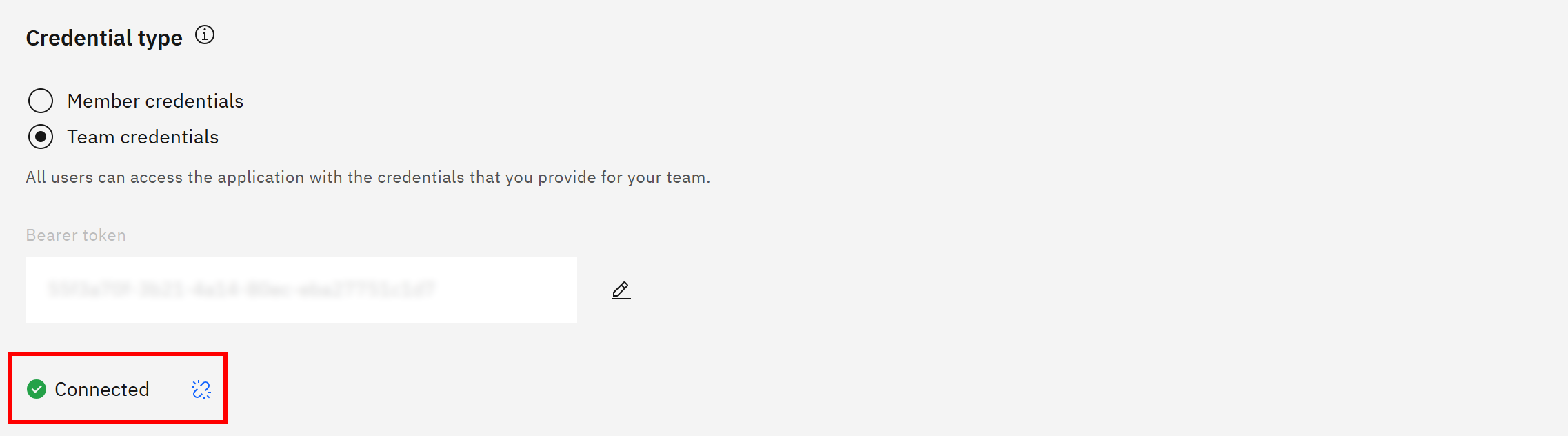
然后点击 “Finish”,并在 “Connections” 表格中选择 bright-data-api-key: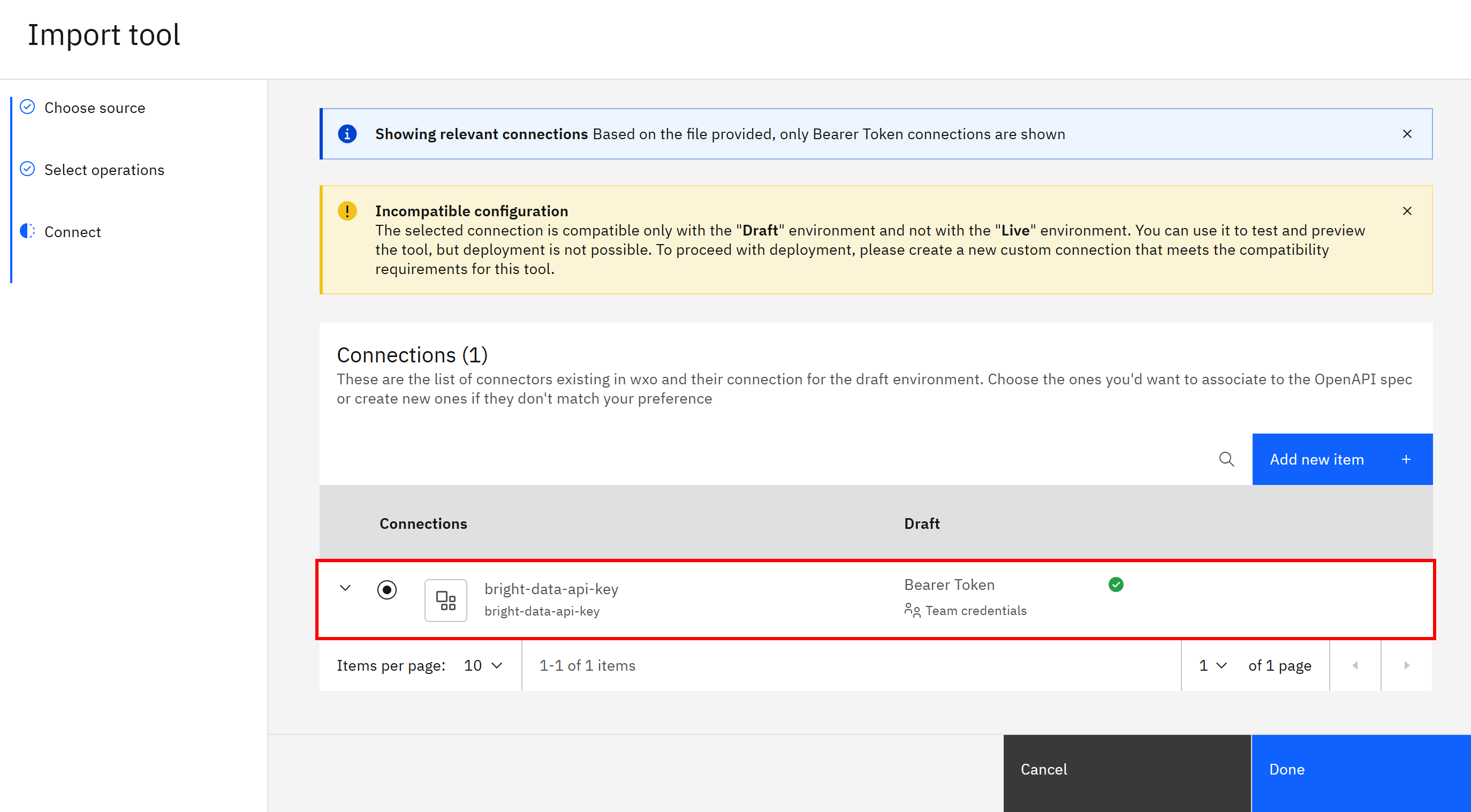
最后,点击“完成”(Done)以完成认证配置。
恭喜!你已经成功为 Bright Data SERP API 集成验证了自定义工具 “发送 SERP 请求”(Send a SERP request)。
步骤 6:完成 SERP API 工具配置
在代理的管理页面中,你现在可以在“工具集”(Toolset)部分看到 “发送 SERP 请求” 工具: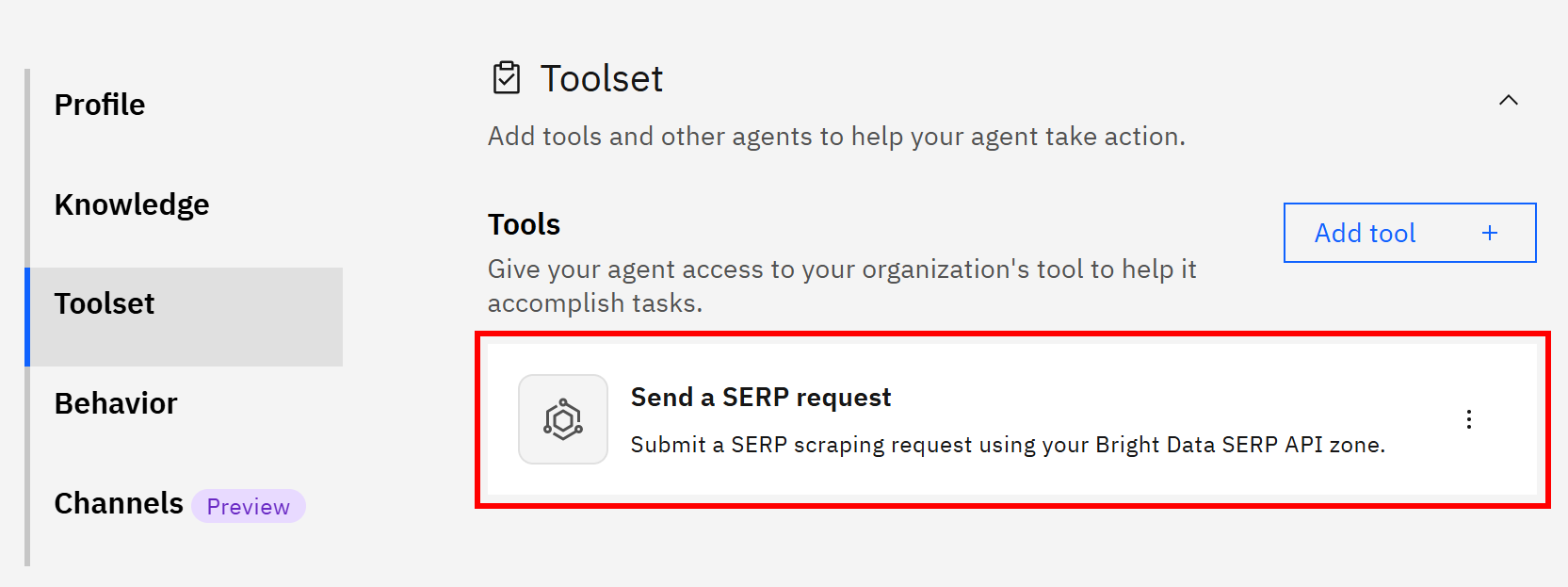
要进一步自定义该工具,点击“⋮”按钮并选择“编辑详情”(Edit Details)选项。在配置页面上,检查所有设置,确保一切正确且符合你的需求: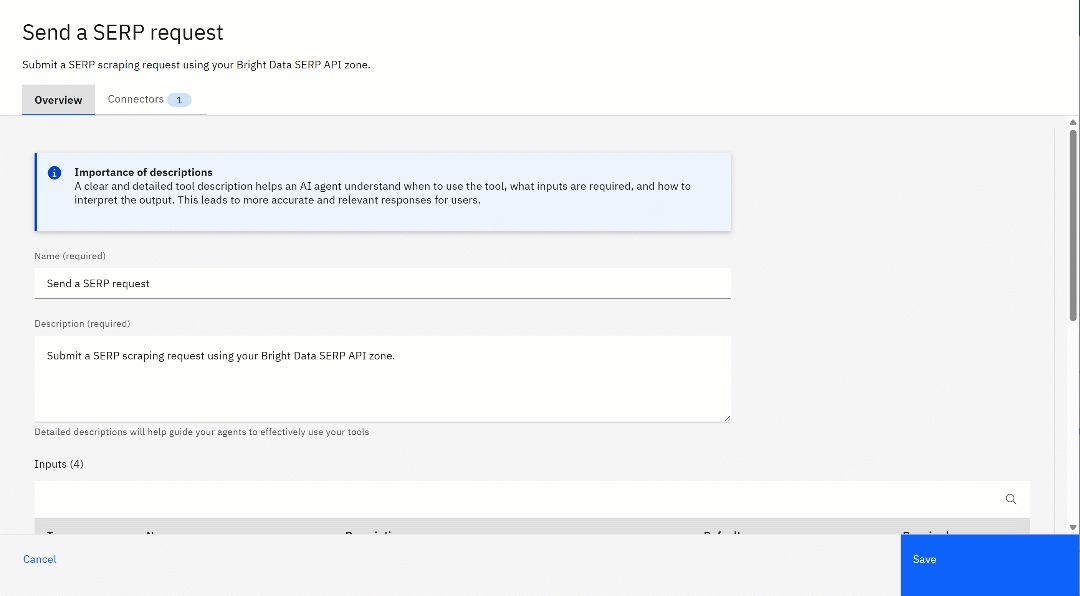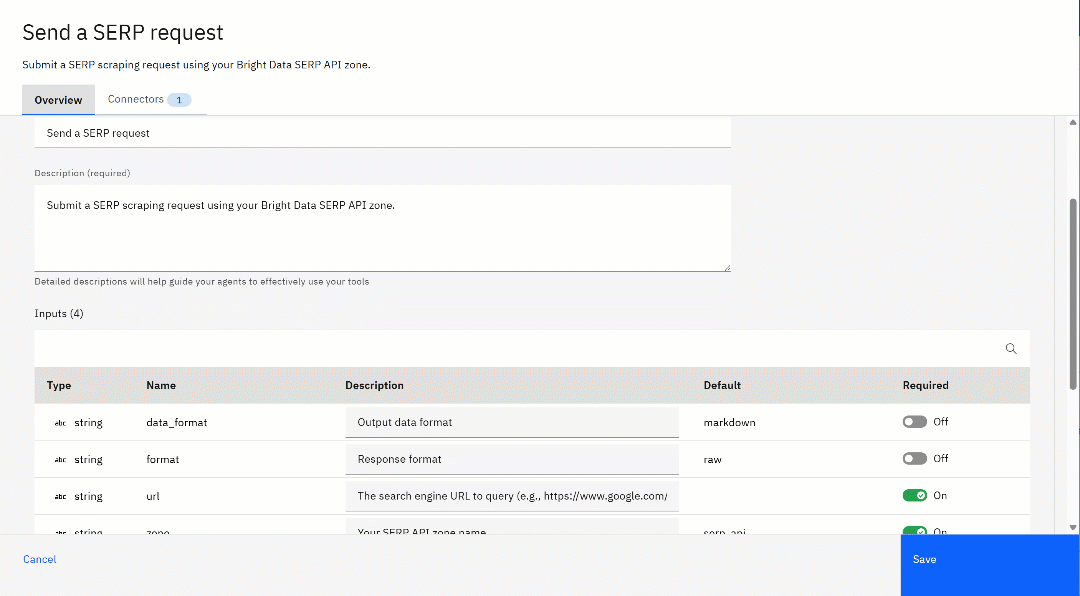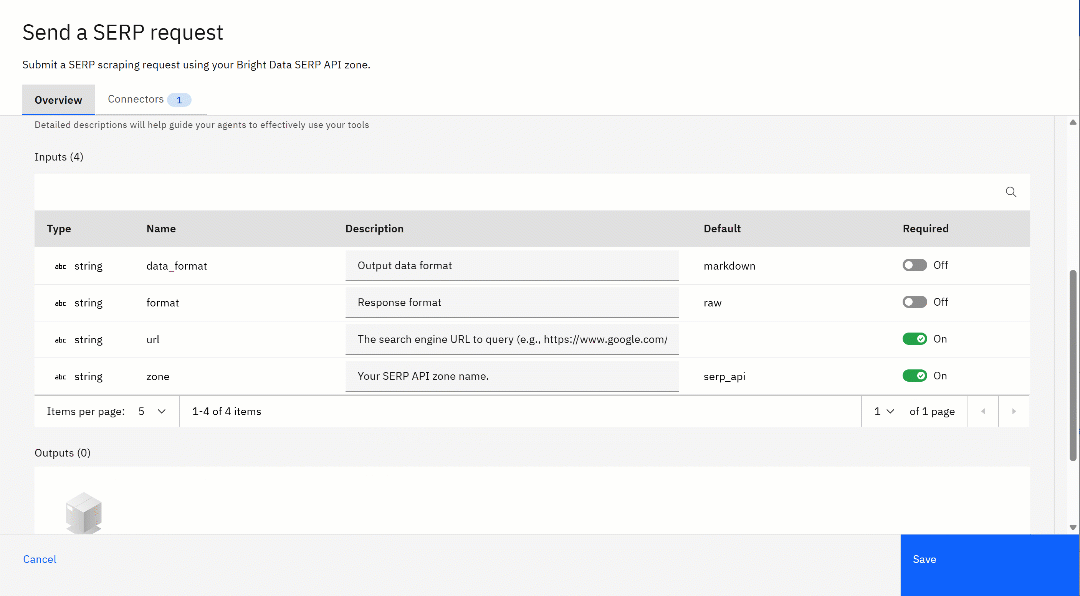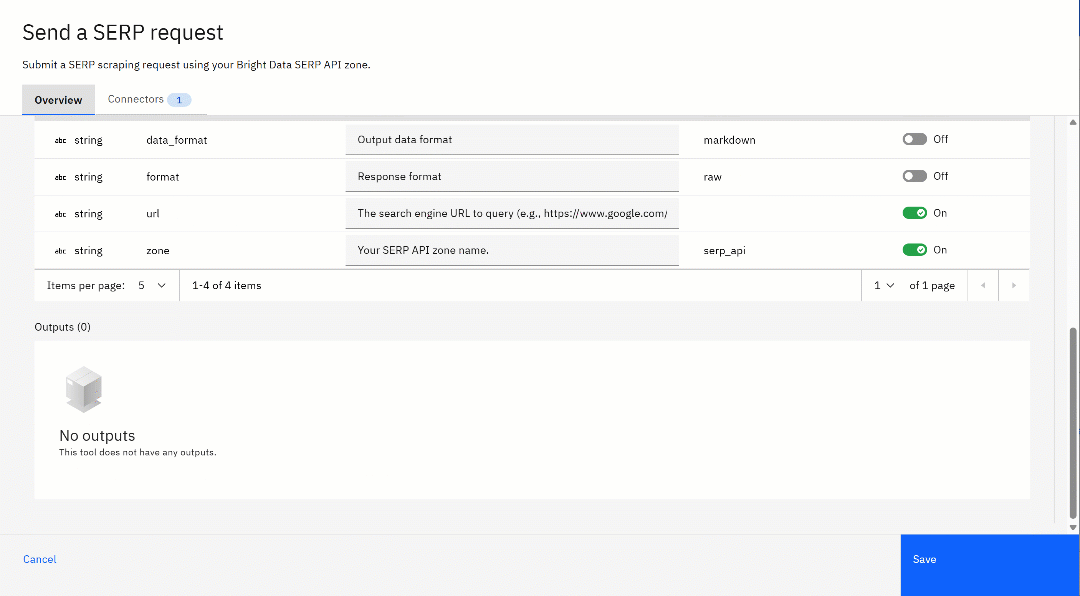
你会看到 API 描述和请求体参数,以及它们的默认值,这些都来自之前上传的 YAML 规范。
搞定!你已经通过基于 OpenAPI 规范定义的自定义工具,将 Bright Data 的 SERP API 集成进了你的 IBM watsonx 代理中。
步骤 7:测试代理
你的 IBM watsonx AI 代理现在已经配置好了,可以通过工具来获取 SERP 搜索结果。使用一个需要实时搜索引擎数据的提示来进行测试,例如:
Find the most recent news about AI humanoid robots and suggest five content ideas I could write about to explore this topic.(注意:这只是一个示例,你可以使用任何需要网页搜索结果的提示进行测试。)
这是一个非常理想的提示,因为它请求的是基础模型本身可能不了解的最新信息——“AI 人形机器人”是一个不断有新进展的热门话题。
在代理的“预览”(Preview)区域中运行这一提示,你应该会看到类似下面的输出: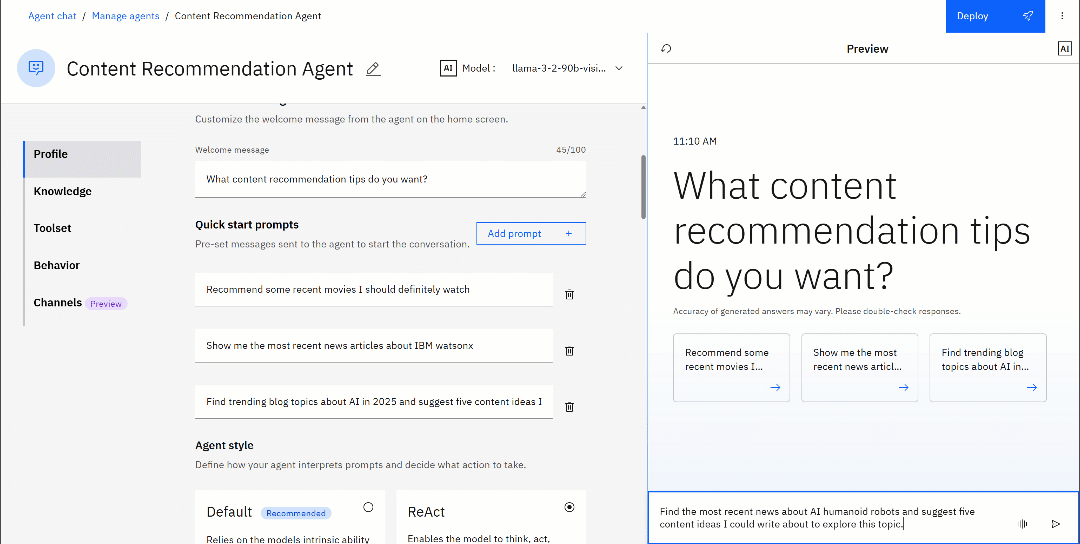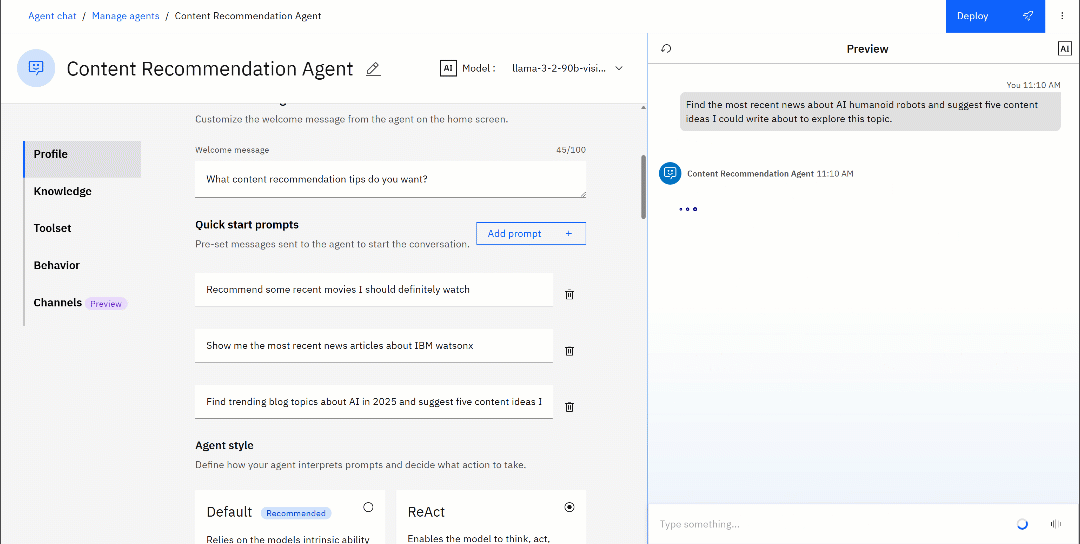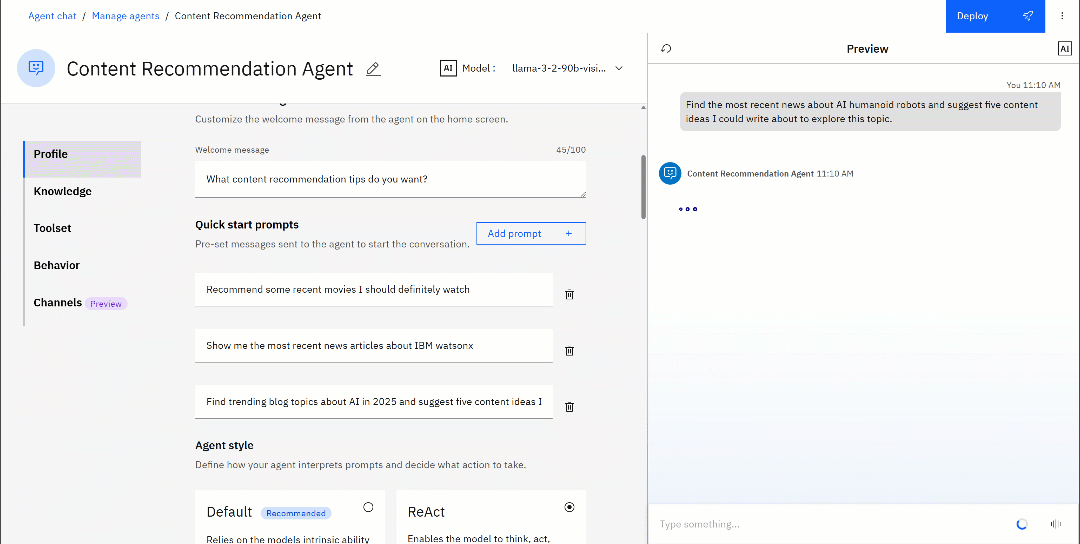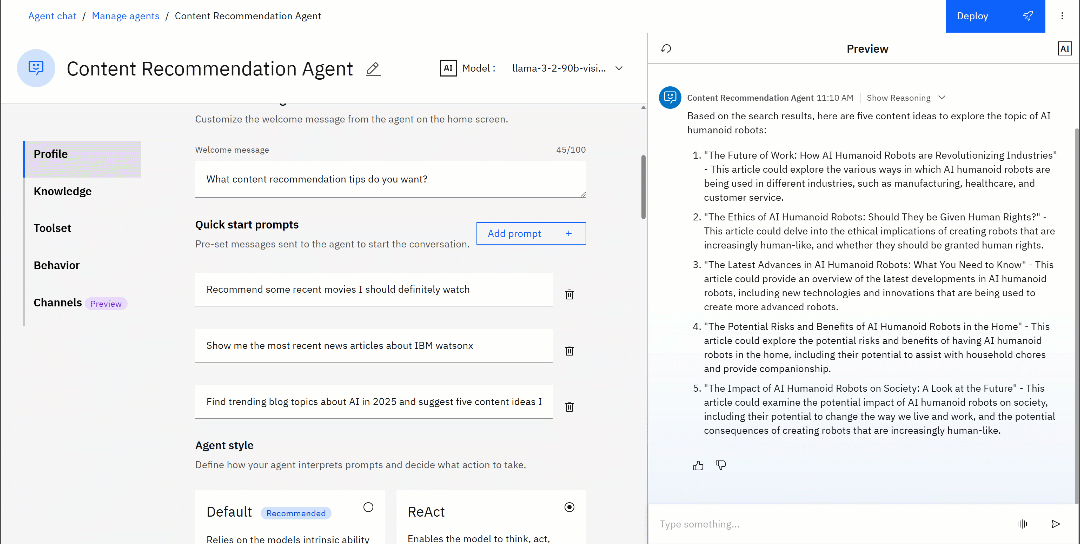
基于 ReAct 的代理会调用 “Send a SERP request” 工具,获取搜索结果,并对 SERP 信息进行处理,生成连贯的回答。
如果你曾经尝试过用 Python 抓取 Google 搜索结果,你就会知道这有多难——要对付机器人检测、IP 封禁、JavaScript 渲染(甚至引发了SERP 数据危机)等各种问题。Bright Data SERP API 会为你处理这一切,并以针对 AI 优化的 Markdown(或 HTML、JSON 等)格式返回已抓取的 SERP。
为了确认代理确实调用了 SERP API,展开响应中的“推理”(Reasoning)部分,并关注“步骤 1”(Step 1):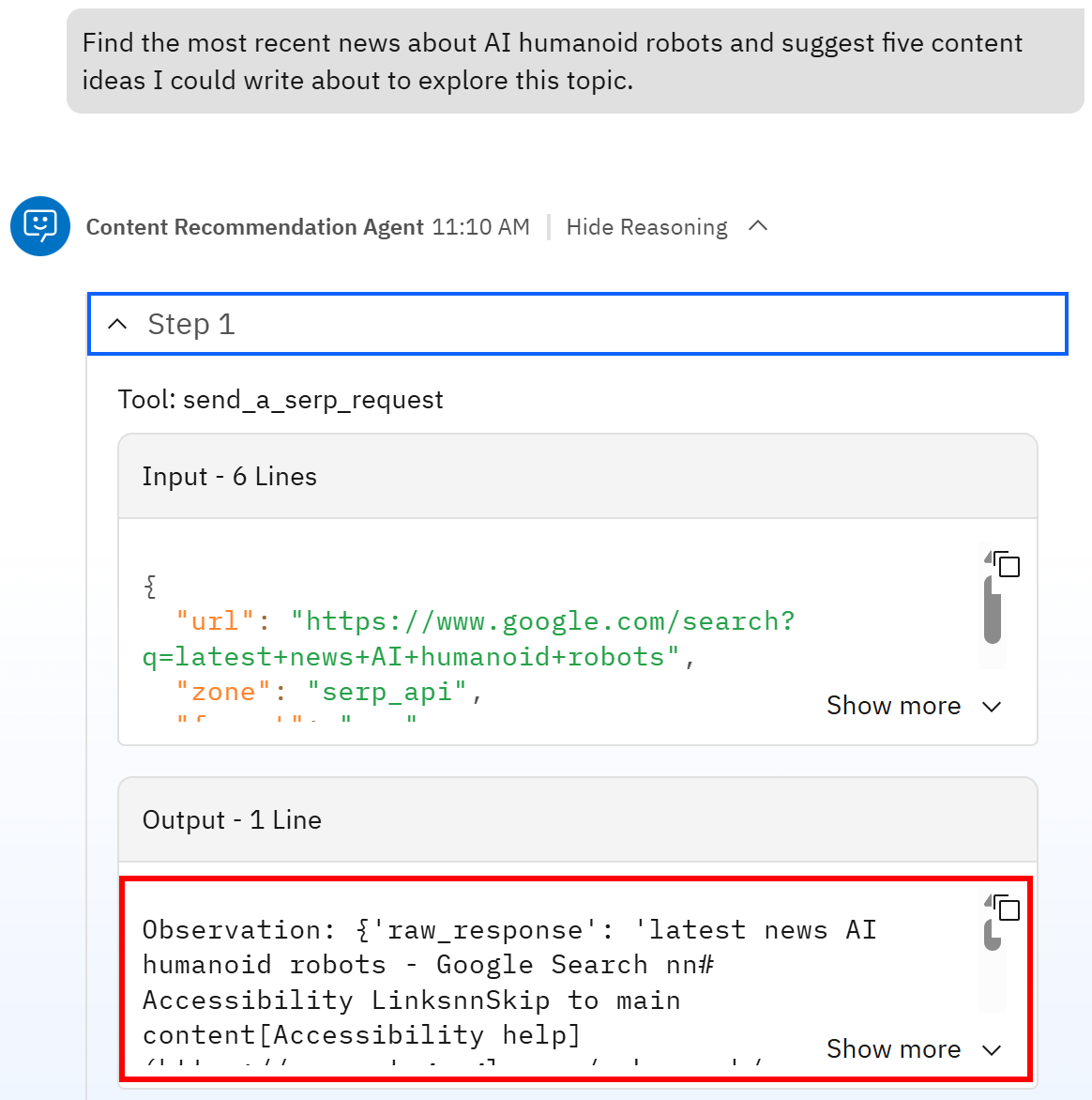
可以看到,第一步就是调用 Bright Data SERP API 工具,查询“latest news AI humanoid robots”(由模型从提示中推断出的搜索词)。随后,工具返回的是该搜索查询对应 SERP 页面的 Markdown 版本。
在这个示例中,AI 代理生成的回答如下:
Based on the search results, here are five content ideas to explore the topic of AI humanoid robots:
1. "The Future of Work: How AI Humanoid Robots are Revolutionizing Industries" - This article could explore the various ways in which AI humanoid robots are being used in different industries, such as manufacturing, healthcare, and customer service.
2. "The Ethics of AI Humanoid Robots: Should They be Given Human Rights?" - This article could delve into the ethical implications of creating robots that are increasingly human-like, and whether they should be granted human rights.
3. "The Latest Advances in AI Humanoid Robots: What You Need to Know" - This article could provide an overview of the latest developments in AI humanoid robots, including new technologies and innovations that are being used to create more advanced robots.
4. "The Potential Risks and Benefits of AI Humanoid Robots in the Home" - This article could explore the potential risks and benefits of having AI humanoid robots in the home, including their potential to assist with household chores and provide companionship.
5. "The Impact of AI Humanoid Robots on Society: A Look at the Future" - This article could examine the potential impact of AI humanoid robots on society, including their potential to change the way we live and work, and the potential consequences of creating robots that are increasingly human-like.这是一个非常不错的回答,对内容创作具有很高的参考价值!
现在,是时候让你的代理更进一步了。尝试一些与事实核查、品牌舆情监控、市场趋势分析等相关的提示,看看它在不同基于 RAG 和 Agent 的用例中的表现。
Et voilà!你刚刚在 IBM watsonx 中构建了一个集成 Bright Data SERP API 的 AI 代理。现在,这个代理可以按需获取最新、可靠且有上下文的网页搜索数据,为智能内容推荐提供支持。
结论
在这篇博客文章中,你了解了如何通过低代码工作流,将 Bright Data 的 SERP API 集成到 IBM watsonx AI 代理中。
这一方法非常适合希望在 IBM 平台上构建具备上下文感知能力的 AI 代理的业务用户,同时还能利用 Bright Data SERP API 的可扩展、企业级能力。如果你希望进一步升级 AI 工作流,不妨探索一下Bright Data 的 AI 基础设施。
立即注册 Bright Data,免费开始测试我们的 AI 就绪型网页数据解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。



