

在这篇博客文章中,你将了解:
- 什么是 Cartesia,以及它为 AI 语音智能体开发提供了什么。
- 为什么语音智能体(就像其他任何智能体一样)需要访问互联网,才能高效且真正值得信赖。
- 如何通过集成 Bright Data,让 Cartesia AI 语音智能体具备网页搜索与信息提取能力。
让我们开始吧!
什么是 Cartesia?
Cartesia 是一个面向开发者的平台,用于构建实时 AI 语音智能体。它将低延迟语音模型与完整的智能体开发技术栈相结合,为你提供从想法到可投入生产的语音智能体所需的一切。
该平台专为快速迭代而设计,使开发者能够以最小阻力对对话式智能体进行原型开发、部署与优化。它在单一、统一的生态中处理语音、推理、部署与测试。
Cartesia 的语音技术栈由两大核心自研模型驱动:
- Sonic:一款流式文本转语音(TTS)模型,针对超低延迟与高表现力输出而优化。它能够笑、表达情绪,并以 40+ 种语言输出自然、类人的语音。
- Ink:一款快速且准确的语音转文本(STT)模型,面向真实世界对话场景设计,能够处理噪声、口音与语流不畅,同时保持接近实时的转写速度。
在构建智能体方面,Cartesia 同时提供内置的 Web Agent Builder,以及其开源 SDK:Line。Cartesia SDK 支持模板、工具集成、多智能体编排等能力,能够满足你打造智能、生产级语音智能体的全部需求。
为什么语音智能体需要 Web 访问能力
Cartesia 无疑是一个功能丰富的 AI 语音智能体构建方案,并且通过 LiteLLM 支持 100+ 个 LLM。然而,即使有如此多的选择,所有 LLM 都有同一个先天限制:它们的知识会被冻结在某个特定时间点。这会导致当智能体需要处理真实世界的最新任务时,出现回答过时、幻觉或知识缺口。
此外,LLM 也无法原生访问互联网或与外部系统交互。因此,标准的智能体工作流仍然会受到模型限制。要解决这一问题,必须通过自定义工具与外部服务进行集成。
这正是 Bright Data 的用武之地。将 Cartesia 连接到 Bright Data 后,你的智能体就可以获取实时信息、搜索结果,以及来自任意网站的结构化数据。
Bright Data 的企业级基础设施拥有全球最大的代理网络之一,具备覆盖 195 个国家/地区的 4 亿+ IP,从而实现对实时 Web 内容的安全、稳定与可扩展访问。
你可以为 Cartesia 语音智能体配备的主要 Bright Data 产品包括:
- SERP API:从 Google、Bing 等搜索引擎采集搜索结果,为更有依据的回答提供支持。
- Web Unlocker API:以原始 HTML 或 Markdown 形式访问任何网站内容,绕过 CAPTCHA 与反爬虫保护。
- Web Scraper APIs(抓取工具 API):从 Amazon、LinkedIn、Instagram 等平台提取结构化数据。
- Crawl API:将整站转换为结构化数据集,供下游 AI 工作流使用。
借助 Bright Data,Cartesia 智能体不再受限于预训练知识。它们可以探索、检索并基于实时、权威的 Web 数据进行推理,从而提供更准确、更具上下文感知能力、也更可执行的回答。
如何构建一个由 Bright Data Web 数据检索能力驱动的 Cartesia AI 语音智能体
在这一逐步实践的章节中,你将学习如何使用 Cartesia 构建一个 AI 语音智能体。该智能体将通过 Bright Data 增强 Web 搜索与网页抓取能力。
具体来说,这个 AI 语音智能体将模拟生成一段简短的新闻风格报告,你可以就指定主题收听。你也可以与智能体聊天,提出追问并进一步深入探索该主题。
注意:这只是一个可能的 AI 语音智能体实现方式。Bright Data 的集成支持许多其他用例。
你将集成 Bright Data 的两个 AI 就绪产品:
- 使用 Web Unlocker API,让智能体能够从任意 URL 提取数据。
- 使用 SERP API,让智能体能够搜索 Web。
这两个工具结合在一起,使 AI 智能体能够应用search-and-extract 模式,非常适合用于数据落地(grounding)与 Web 发现。
为了在构建智能体时获得更强的编程控制能力,我们将依赖 Line(即 Cartesia SDK)。这是因为 Agent Builder 非常适合做原型,但功能相对受限。
请按照以下说明操作!
前置条件
要跟随本教程操作,请确保你具备以下条件:
- 基于 Unix 的操作系统(Linux、macOS,或 Windows 上的 WSL)。
- 本地已安装 Python 3.9+。
- 本地已安装
uv。 - 来自 Cartesia 支持的 LLM 提供商之一的 API key(这里我们将使用 Gemini API key)。
- 一个Bright Data 账号,并已配置 Web Unlocker API 与 SERP API,同时具备 API key。
- 一个Cartesia 账号,并已配置 API key。
暂时不用担心 Bright Data 与 Cartesia 账号的设置,你将在专门的小节中获得引导。
步骤 #1:初始化一个 Cartesia 项目
首先使用 uv 为你的项目创建一个文件夹(这是 Cartesia 快速入门指南中推荐的方法):
uv init cartesia-bright-data-voice-agent进入项目文件夹:
cd cartesia-bright-data-voice-agent你应该会看到类似如下的目录结构:
cartesia-bright-data-voice-agent/
├── .git/
├── .gitignore
├── .python-version
├── README.md
├── main.py
└── pyproject.toml这就是 uv init 命令的结果。
请关注 main.py 文件。你将把 Cartesia 逻辑添加到这里,以设计一个通过 Bright Data 扩展 Web 数据检索与搜索能力的 AI 语音智能体。
接下来,安装项目依赖:
uv add cartesia-line requests所需的两个库是:
cartesia-line:用于构建智能、低延迟语音智能体的 Cartesia Line SDK。requests:流行的 Python HTTP 客户端,将用于在自定义 Cartesia 工具中调用 Bright Data 的 API。
这些库将由 uv 自动安装到一个 .venv 虚拟环境中。现在你可以用你喜欢的 Python IDE 直接打开该项目。
做得好!你的空白 Cartesia 项目已经准备就绪。
步骤 #2:开始使用 Cartesia CLI
要在本地测试 Cartesia 智能体,你需要安装并登录 Cartesia CLI。进行身份验证需要 Cartesia API key,所以我们先准备好它!
如果你还没有账号,请创建一个新的 Cartesia 账号。否则,请登录。登录后,你将进入控制台:
现在,进入“API Keys”页面并点击“New”按钮: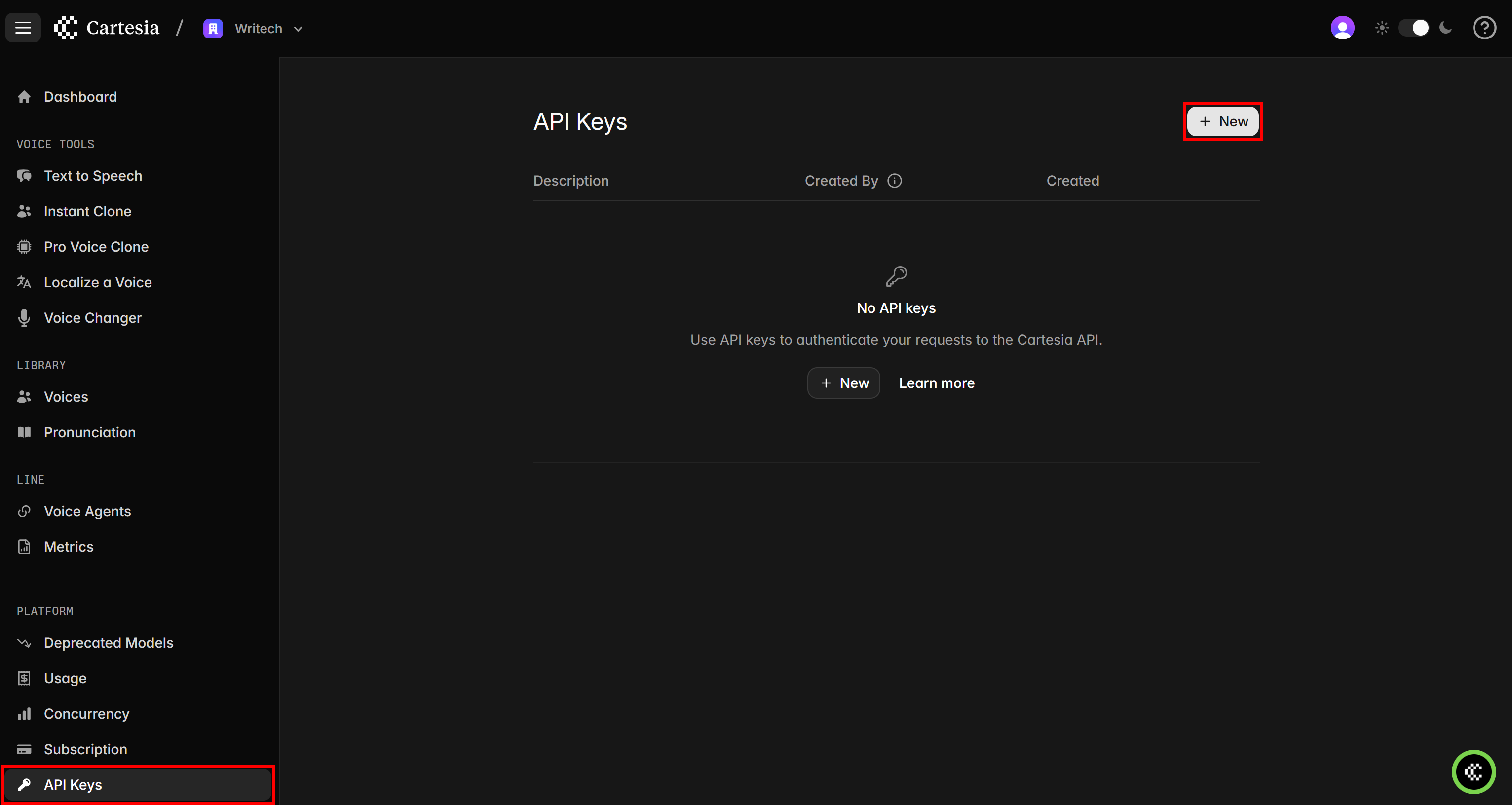
为你的 API key 命名(例如 “Bright Data 驱动的语音智能体”),点击“Create”,你将在弹窗中看到 API key。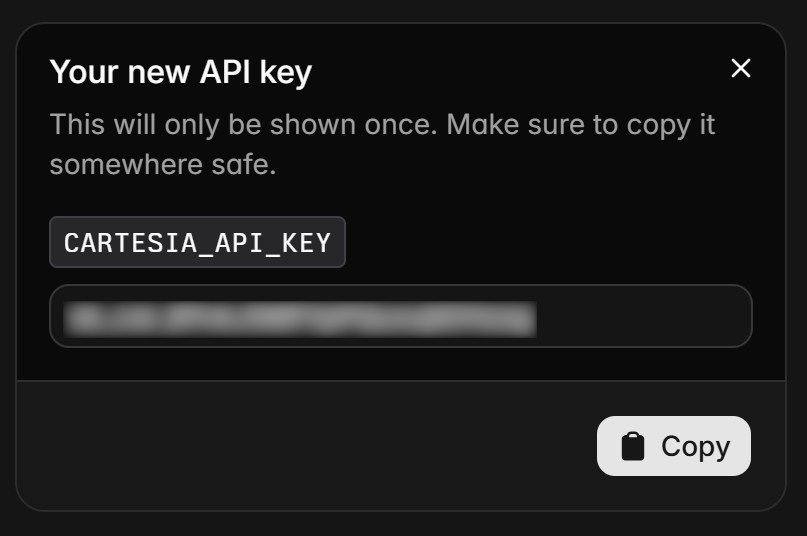
复制该 API token 并安全保存,因为你很快就会用到。
在基于 Unix 的终端中,通过以下命令安装 Cartesia CLI:
curl -fsSL https://cartesia.sh | sh安装完成后,重启你的 shell,以便在任意位置使用 cartesia 命令。
在 CLI 中进行身份验证,运行:
cartesia auth login系统会提示你输入 Cartesia API key。粘贴并回车。如果成功,你会看到类似这样的提示:
注意:在此示例中,“Writech”是 Cartesia 组织名称。你看到的消息会根据你的组织而变化。
很好!接下来设置你的 Bright Data 账号,以完成初始前置条件。
步骤 #3:设置 Bright Data 账号
要在 Cartesia 中连接 SERP API 与 Web Unlocker,你首先需要一个 Bright Data 账号,并已创建 SERP API zone 与 Web Unlocker API zone,同时具备 API key。
如果你还没有 Bright Data 账号,请创建一个新账号。如果已有账号,请登录。进入控制台后,前往“Proxies & Scraping”页面并查看“My Zones”表格: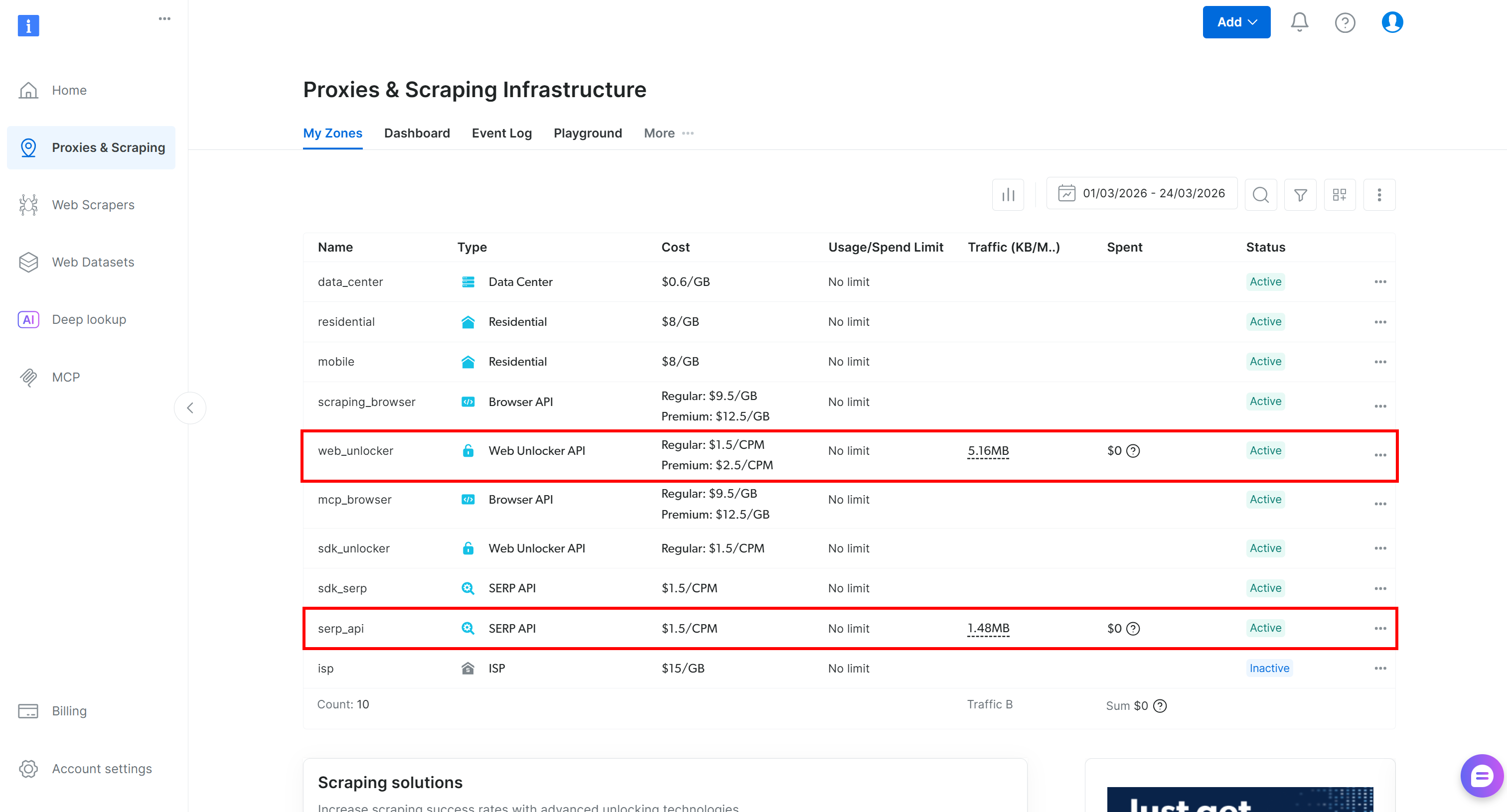
如果表格中已经列出了 Web Unlocker API zone(例如 web_unlocker)以及 SERP API zone(例如 serp_api),那么你就准备好了。这两个 zone 将用于通过自定义工具调用 Web Unlocker 与 SERP API 服务。
如果缺少任一区域(zone),请创建它。滚动到 “Unblocker API” 与 “SERP API” 卡片,然后点击 “Create zone”。按照向导添加这两个 zone: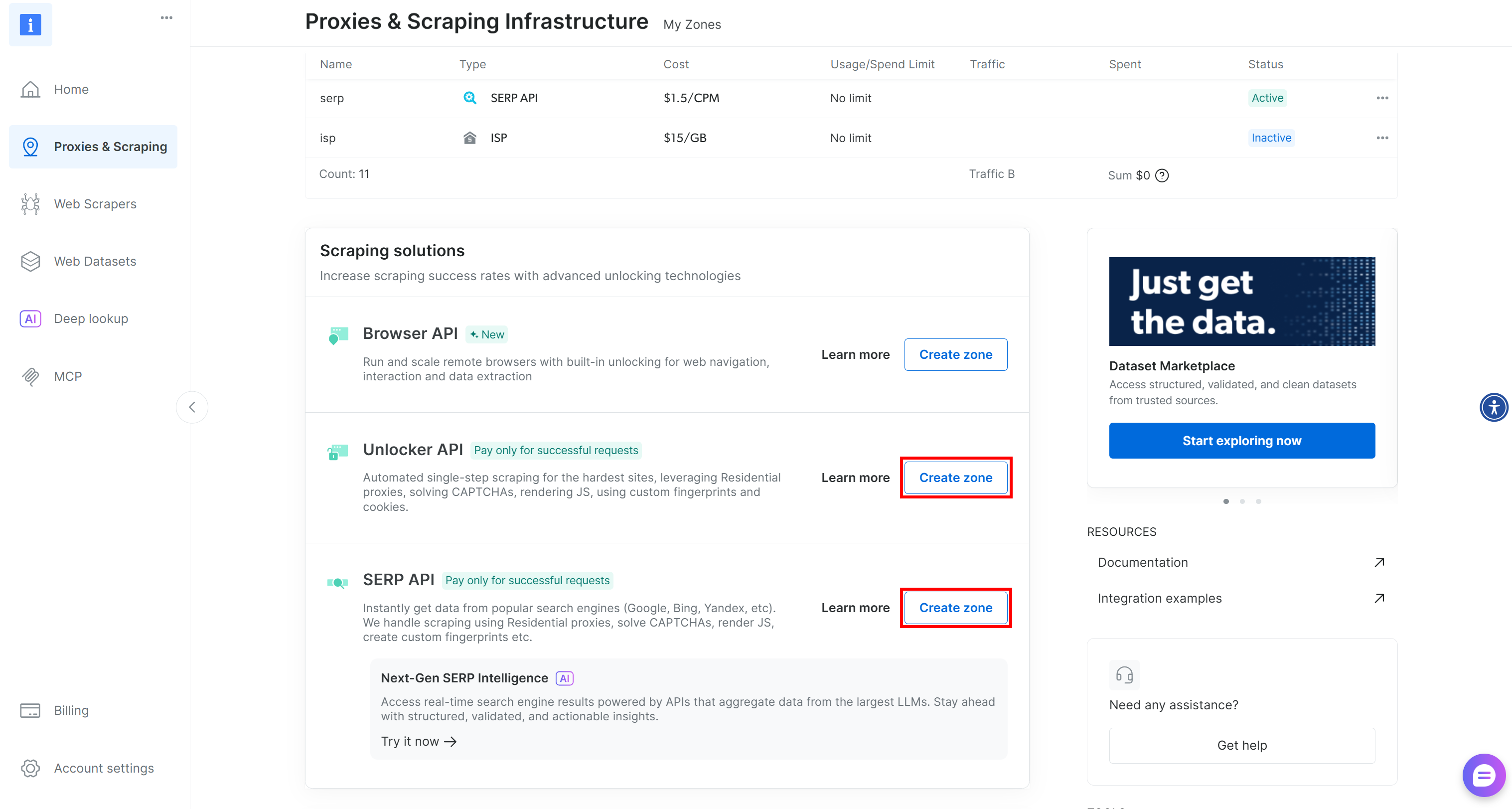
详细指导请参考以下文档页面:
请记住你为这两个 zone 设置的名称,因为下一步会用到。最后,生成你的 Bright Data API key 并安全保存。
太好了!现在 Bright Data 已准备好集成到 Cartesia 中。
步骤 #4:配置环境变量读取
该 AI 语音智能体工作流依赖若干敏感信息:LLM 提供商(此处为 Gemini)与 Bright Data(API key + zone 名称)。把这些敏感信息硬编码到代码中存在安全风险,因此最好将其存储在环境变量中。
Cartesia CLI 会在后台通过 python-dotenv 自动读取 .env 文件,因此你可以把所有敏感信息放在其中。首先在项目目录添加一个 .env 文件:
cartesia-bright-data-voice-agent/
├── .git/
├── .env # <-----------
├── .gitignore
├── .python-version
├── README.md
├── main.py
└── pyproject.toml然后将敏感信息填入其中:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"
BRIGHT_DATA_WEB_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE>" # e.g., "web_unlocker"
BRIGHT_DATA_SERP_API_ZONE="<YOUR_BRIGHT_DATA_SERP_API_ZONE>" # e.g., "serp_api"将所有占位符替换为你的实际值。由于流程在这些敏感信息未设置齐全时不应启动,因此请将以下逻辑添加到 main.py:
import os
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
if not GEMINI_API_KEY:
raise EnvironmentError("Missing environment variable: GEMINI_API_KEY")
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
if not BRIGHT_DATA_API_KEY:
raise EnvironmentError("Missing environment variable: BRIGHT_DATA_API_KEY")
BRIGHT_DATA_SERP_API_ZONE = os.getenv("BRIGHT_DATA_SERP_API_ZONE")
if not BRIGHT_DATA_SERP_API_ZONE:
raise EnvironmentError("Missing environment variable: BRIGHT_DATA_SERP_API_ZONE")
BRIGHT_DATA_WEB_UNLOCKER_ZONE = os.getenv("BRIGHT_DATA_WEB_UNLOCKER_ZONE")
if not BRIGHT_DATA_WEB_UNLOCKER_ZONE:
raise EnvironmentError("Missing environment variable: BRIGHT_DATA_WEB_UNLOCKER_ZONE")请记住,使用 .env 文件并非必须。你也可以直接在终端中设置环境变量:
export GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>" BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>" BRIGHT_DATA_WEB_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE>" BRIGHT_DATA_SERP_API_ZONE="<YOUR_BRIGHT_DATA_SERP_API_ZONE>"很好!你的环境变量现在已安全设置。接下来:实现用于网页抓取与搜索的 Bright Data 工具。
步骤 #5:定义用于网页抓取的 Web Unlocker 工具
默认情况下,Cartesia AI 语音智能体无法访问外部 Web。要实现这一点,你必须为其配备自定义工具,让智能体可以调用。这里你将定义一个工具,用于连接 Bright Data 的 Web Unlocker API 来进行网页抓取。
在 Cartesia 中,工具本质上就是一个函数,并使用可用的工具装饰器之一进行注解。下面是如何构建一个连接 Web Unlocker API 的 Cartesia 网页抓取工具:
@loopback_tool
def bright_data_web_unlocker(
ctx,
page_url: Annotated[str, "The URL of the page to scrape"]
) -> str:
"""
Retrieve web page content using the Bright Data Web Unlocker API
"""
url = "https://api.brightdata.com/request"
data = {
"zone": BRIGHT_DATA_WEB_UNLOCKER_ZONE,
"url": page_url,
"format": "raw",
"data_format": "markdown"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Make a request to the Bright Data Web Unlocker API
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text请注意,Cartesia SDK 使用函数的 docstring 作为工具描述,并使用参数的类型注解。同时,每个工具的第一个参数都必须是 ctx,它表示工具上下文。该上下文可访问会话状态,并确保向前兼容。
bright_data_web_unlocker() 函数使用 Requests HTTP 客户端 向你的 Bright Data Web Unlocker API zone 发起 POST 请求。这会返回由 page_url 参数指定网页的 Markdown 版本。关于可用参数与选项的更多细节,请参考 Bright Data 文档。
注意 data_format 参数被设置为 "markdown"。这启用了“以 Markdown 方式抓取”功能,以 AI 优化的 Markdown 格式返回抓取内容——非常适合 LLM 摄入。format 参数设置为 "raw",这样 API 会返回纯净的抓取 Markdown 内容,而不是将其包裹在 JSON 中。
太棒了!你的 Cartesia AI 应用现在包含了一个可使用 Bright Data 对任意网站进行网页抓取的工具。
步骤 #6:定义用于 Web 搜索的 SERP API 工具
类似地,定义一个用于调用 SERP API 的自定义函数工具:
@loopback_tool
def bright_data_serp_api(
ctx,
query: Annotated[str, "The Google search query"]
) -> str:
"""
Query the web for a specific term using Bright Data’s SERP API.
"""
url = "https://api.brightdata.com/request"
data = {
"zone": BRIGHT_DATA_SERP_API_ZONE,
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Make a request to the Bright Data SERP API
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text该函数会向你的 SERP API zone 发起 POST 请求:向 Google 发送查询,并通过 Bright Data 获取解析后的搜索结果。更多细节请参阅 Bright Data SERP API 文档。
很好!你的 Cartesia 应用现在已经包含所需的 Bright Data 驱动工具。
步骤 #7:定义 Cartesia 语音智能体
此时,你已经拥有定义Cartesia 智能体所需的全部构建块。推荐做法是使用内置的 LlmAgent 类,它通过 LiteLLM 支持 100+ LLM 提供商。
要定义语音智能体,你需要为该类提供:
- LLM 模型与 API key。
- 它可以使用的工具。
- 描述智能体应做什么的 system prompt。
- 一条初始消息。
以下是将所有内容组合起来的方法:
from line.llm_agent import LlmAgent, LlmConfig, end_call
from line.voice_agent_app import VoiceAgentApp
async def get_agent(env, call_request):
# Define the AI voice agent
SYSTEM_PROMPT = """
You are a helpful assistant capable of searching the web to retrieve up-to-date context.
Respond in a clear, news-style, informative tone.
"""
return LlmAgent(
model="gemini/gemini-3-flash-preview",
api_key=GEMINI_API_KEY,
tools=[
end_call,
bright_data_web_unlocker,
bright_data_serp_api
],
config=LlmConfig(
system_prompt=SYSTEM_PROMPT,
introduction="Hello! How can I help you today?",
),
)需要注意几点:
tools数组包含了前面定义的两个自定义 Bright Data 工具(bright_data_web_unlocker与bright_data_serp_api)。- 内置的
end_call工具是必需的,以便智能体能够优雅地结束对话。 - 配置的 LLM 模型是 Gemini 3 Flash,但任何其他 Gemini 模型也都可以。
最后,在 VoiceAgentApp 类中注册该智能体并运行:
app = VoiceAgentApp(get_agent=get_agent)
if __name__ == "__main__":
app.run()任务完成!你已经构建了一个用于新闻风格回答的 AI 语音智能体。该智能体能够搜索并检索来自 Web 的实时信息,从而提供更准确、更及时的回答。
步骤 #8:最终代码
此时 main.py 文件应包含如下内容:
# uv add cartesia-line requests
import os
from line.llm_agent import loopback_tool
from typing import Annotated
import requests
import urllib
from line.llm_agent import LlmAgent, LlmConfig, end_call
from line.voice_agent_app import VoiceAgentApp
# Read the required secrets from the env
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
if not GEMINI_API_KEY:
raise EnvironmentError("Missing environment variable: GEMINI_API_KEY")
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
if not BRIGHT_DATA_API_KEY:
raise EnvironmentError("Missing environment variable: BRIGHT_DATA_API_KEY")
BRIGHT_DATA_SERP_API_ZONE = os.getenv("BRIGHT_DATA_SERP_API_ZONE")
if not BRIGHT_DATA_SERP_API_ZONE:
raise EnvironmentError("Missing environment variable: BRIGHT_DATA_SERP_API_ZONE")
BRIGHT_DATA_WEB_UNLOCKER_ZONE = os.getenv("BRIGHT_DATA_WEB_UNLOCKER_ZONE")
if not BRIGHT_DATA_WEB_UNLOCKER_ZONE:
raise EnvironmentError("Missing environment variable: BRIGHT_DATA_WEB_UNLOCKER_ZONE")
@loopback_tool
def bright_data_web_unlocker(
ctx,
page_url: Annotated[str, "The URL of the page to scrape"]
) -> str:
"""
Retrieve web page content using the Bright Data Web Unlocker API
"""
url = "https://api.brightdata.com/request"
data = {
"zone": BRIGHT_DATA_WEB_UNLOCKER_ZONE,
"url": page_url,
"format": "raw",
"data_format": "markdown"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Make a request to the Bright Data Web Unlocker API
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text
@loopback_tool
def bright_data_serp_api(
ctx,
query: Annotated[str, "The Google search query"]
) -> str:
"""
Query the web for a specific term using Bright Data’s SERP API.
"""
url = "https://api.brightdata.com/request"
data = {
"zone": BRIGHT_DATA_SERP_API_ZONE,
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Make a request to the Bright Data SERP API
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text
async def get_agent(env, call_request):
# Define the AI voice agent
SYSTEM_PROMPT = """
You are a helpful assistant capable of searching the web to retrieve up-to-date context.
Respond in a clear, news-style, informative tone.
"""
return LlmAgent(
model="gemini/gemini-2.5-flash",
api_key=GEMINI_API_KEY,
tools=[
end_call,
bright_data_web_unlocker,
bright_data_serp_api
],
config=LlmConfig(
system_prompt=SYSTEM_PROMPT,
introduction="Hello! How can I help you today?",
),
)
app = VoiceAgentApp(get_agent=get_agent)
if __name__ == "__main__":
app.run()很酷!只用大约 100 行 Python 代码,你就构建了一个具备 Web 数据发现能力的强大语音 AI 智能体。
步骤 #9:测试语音智能体
确保你已定义所有必需的环境变量(在 .env 文件中或通过 export 命令)。然后使用以下命令启动智能体:
PORT=8000 uv run python main.py这会在本地 http://localhost:8000 启动 Cartesia 应用,如日志所示:
在另一个终端中,通过运行以下命令与你的智能体交互:
cartesia chat 8000Cartesia Chat 体验将直接在你的终端中启动:
该设置让你可以通过聊天而非语音来模拟对话,从而让测试变得更简单。
试试如下提示词:
Search for the "US inflation news" query on the web, select specific 3/5 articles (not news hub pages), scrape their content, and use that information to produce a ~3-minute podcast summarizing key insights, citing the sources.下面是应该发生的过程:
注意智能体会先用查询词 “US inflation news” 调用 bright_data_serp_api 工具。在另一个终端中,你将看到 Bright Data SERP API 返回的 JSON 结果日志。然后智能体会从这些结果中选择 3 个相关的文章 URL: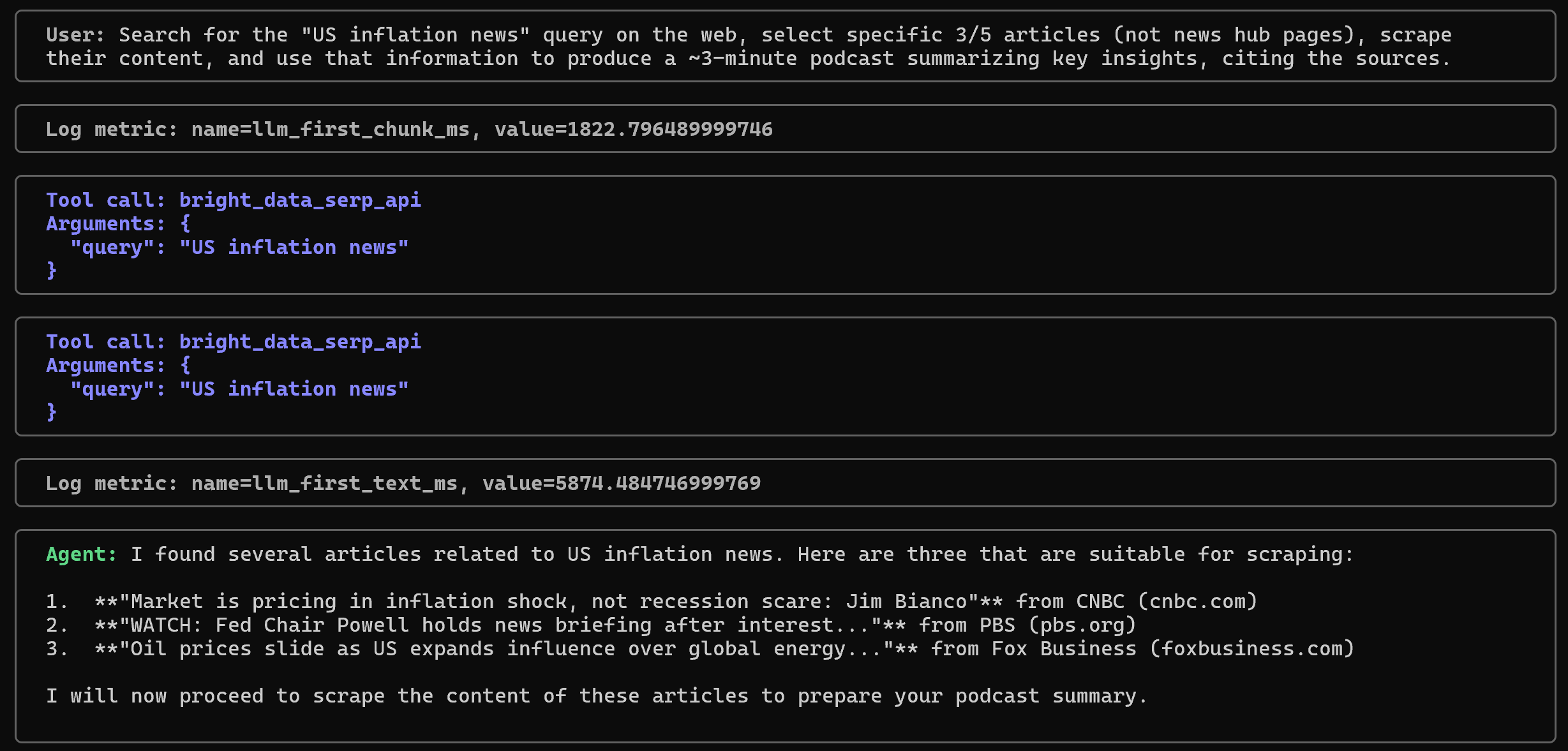
接着,它会使用 bright_data_web_unlocker 工具抓取每个页面,并生成有来源支撑的总结: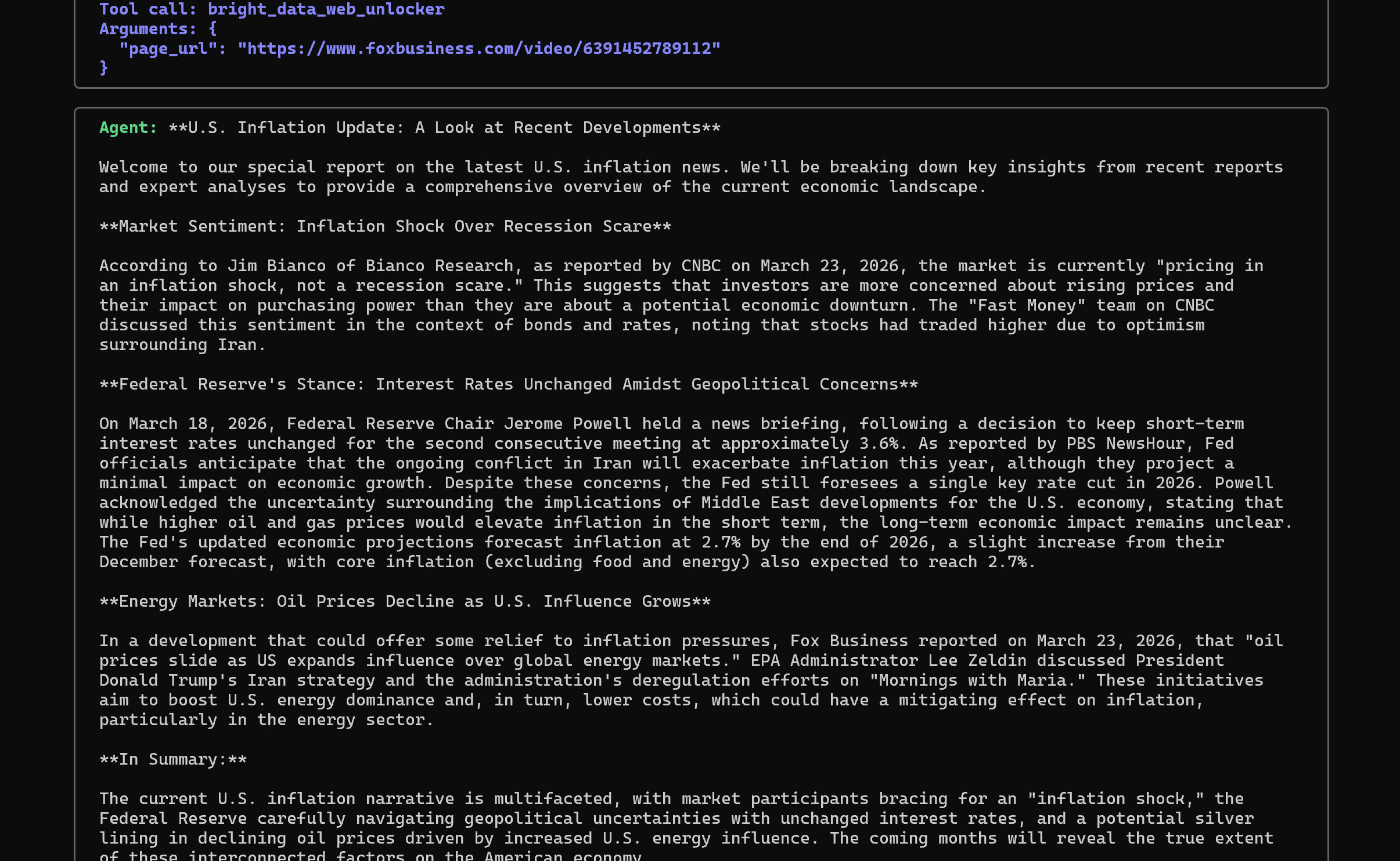
请注意输出语气类似记者风格,这与前面定义的 system prompt 相匹配。
Voilà!你已成功构建了一个能够主动搜索并从 Web 检索信息的语音智能体,从而生成更具上下文感知能力且更准确的回答。如果不集成 Bright Data 的搜索与网页抓取工具,这是不可能实现的。
下一步
现在你已经拥有一个可用的 AI 语音智能体,下一步是将其部署到 Cartesia,并用手机拨打调用它。为了进一步根据你的需求优化和定制智能体,请探索文档。
最后请记住——就像本教程展示的那样——你也可以集成其他基于 API 的 Bright Data 产品,以为你的智能体扩展更多能力。
此外,Cartesia 支持多种集成,包括 LiveKit(另一种构建 AI 语音智能体的技术)。更多信息请参见如何将 Bright Data 与 LiveKit 集成。
结论
在这篇博客文章中,你了解了 Cartesia 是什么,以及它为 AI 语音智能体开发带来了哪些价值。你也看到了它的不足,以及如何通过集成 Bright Data 来弥补这些限制。
通过为你的语音智能体添加两个专用工具,你赋予了它们 Web 搜索与网页抓取能力。实现这一点的关键,是将你的智能体连接到由 Bright Data SERP API 与 Web Unlocker API 驱动的自定义工具。
要进一步扩展功能——例如访问实时 Web 信息流或自动化 Web 交互——请将 Cartesia 语音智能体与面向 AI 的全套 Bright Data 服务进行集成。
立即免费注册 Bright Data 账号,并开始将 AI 就绪的 Web 数据解决方案集成到你的智能体中!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。


