

在本教程中,你将学习:
- 什么是 BabyAGI,以及它作为一个 AI Agent 构建框架有什么独特之处。
- 为什么将 Bright Data 服务扩展到 BabyAGI 中可以开启各种有趣的应用场景。
- 如何通过自定义函数在 BabyAGI 中集成 Bright Data。
下面开始吧!
什么是 BabyAGI?
BabyAGI 是一个实验性的 Python 框架,用于创建自我构建的自主 AI Agent,这些 Agent 能够生成、优先排序并执行任务,以实现用户定义的目标。
它的作用类似一个极简但可自我改进的任务管理器,利用 OpenAI 等大型语言模型进行推理,并使用向量数据库作为记忆。总体而言,它通过一个智能循环来自动化复杂工作流程。
在核心设计上,BabyAGI 引入了一个名为 functionz 的基于函数的框架,用于从数据库中存储、管理和执行函数。这些函数还支持代码生成,使 AI Agent 能够注册新函数、调用它们并自主演化。
随后,一个内置的仪表板允许你管理函数、监控执行情况以及注册密钥。它采用图结构来跟踪导入内容、依赖函数和认证密钥,并支持自动加载和详细日志记录。
BabyAGI 的吸引力在于其简单性、自我构建能力和易用的 Web 仪表板。其核心理念是:最有效的自主 Agent 是那些能够在最少结构约束下自我扩展的 Agent。
BabyAGI 是一个开源项目并在持续维护中,在 GitHub 上拥有超 2.2 万颗星。
通过访问网页数据增强自构建 AI Agent
LLM 本质上受限于其训练时使用的静态数据,这往往会导致幻觉和其他常见问题。
BabyAGI 通过其自构建函数框架在一定程度上突破了这些限制。它利用 LLM 来编写自定义函数,然后将这些函数作为工具回传给 Agent,从而扩展其能力。
然而,用于生成这些函数的逻辑依然受限于 LLM 过时的知识。为了解决这一重大限制,BabyAGI 需要具备搜索网络并检索准确、最新信息的能力,以便生成更加可靠的函数。
这可以通过连接以下 Bright Data 服务来实现:
- SERP API:从 Google、Bing 等搜索引擎大规模采集搜索结果且不会被封锁。
- Web Unlocker API:通过一次请求访问任意网站并获取干净的 HTML 或 Markdown,自动处理代理、请求头和验证码。
- Web Scraping API:从 Amazon、LinkedIn、Instagram、Yahoo Finance 等热门平台获取结构化、解析后的数据。
- 以及其他解决方案……
通过这些集成,再结合 BabyAGI 的自构建架构,AI 能够自主演化、添加新函数,并处理远超标准 LLM 能力范围的复杂工作流。
如何通过 Bright Data 为 BabyAGI 扩展网页数据检索能力
在下面的分步指南中,你将学习如何通过自定义函数将 Bright Data 集成到 BabyAGI 中。这些函数会连接两个 Bright Data 产品:SERP API 和 Web Unlocker API。
按照以下步骤开始吧!
前置条件
要跟随本教程,你需要:
- 本地安装 Python 3.10+。
- 一个 OpenAI API 密钥。
- 一个已配置好 SERP API 区域、Web Unlocker API 区域并拥有有效 API 密钥的Bright Data 账号。
如果你的 Bright Data 账号尚未配置好,不用担心,后面会有专门步骤指导你完成。
第 1 步:创建一个 BabyAGI 项目
打开终端,为你的 BabyAGI 项目创建一个新文件夹。例如,命名为 babyagi-bright-data-app:
mkdir babyagi-bright-data-appbabyagi-bright-data-app/ 将包含用于启动 BabyAGI 仪表板并定义 Bright Data 集成函数的 Python 代码。
接着进入该项目目录,并在其中初始化一个虚拟环境:
cd babyagi-bright-data-app
python -m venv .venv在项目根目录下添加一个名为 main.py 的新文件,此时项目结构应为:
babyagi-bright-data-app/
├── .venv/
└── main.pymain.py 将包含启动 BabyAGI 及扩展逻辑的代码。
在你喜欢的 Python IDE 中打开该项目目录,例如安装了 Python 扩展的 Visual Studio Code,或 PyCharm 社区版。
现在,激活刚刚创建的虚拟环境。在 Linux 或 macOS 中执行:
source .venv/bin/activate在 Windows 中则运行:
.venv/Scripts/activate激活虚拟环境后,安装所需的 PyPI 库:
pip install babyagi requests本应用的依赖包括:
完成!你现在已经拥有一个用于在 BabyAGI 中进行自主体开发的 Python 环境。
第 2 步:启动 BabyAGI 仪表板
在 main.py 文件中添加以下代码来初始化并启动 BabyAGI 仪表板:
import babyagi
if __name__ == "__main__":
app = babyagi.create_app("/dashboard")
app.run(host="0.0.0.0", port=8080)这将指示 BabyAGI 在如下地址暴露仪表板应用:
http://localhost:8080/dashboard通过运行以下命令验证应用是否正常工作:
python main.py在终端中,你应能看到日志显示仪表板正在 http://localhost:8080/dashboard 上监听:
在浏览器中访问该 URL,即可进入仪表板界面: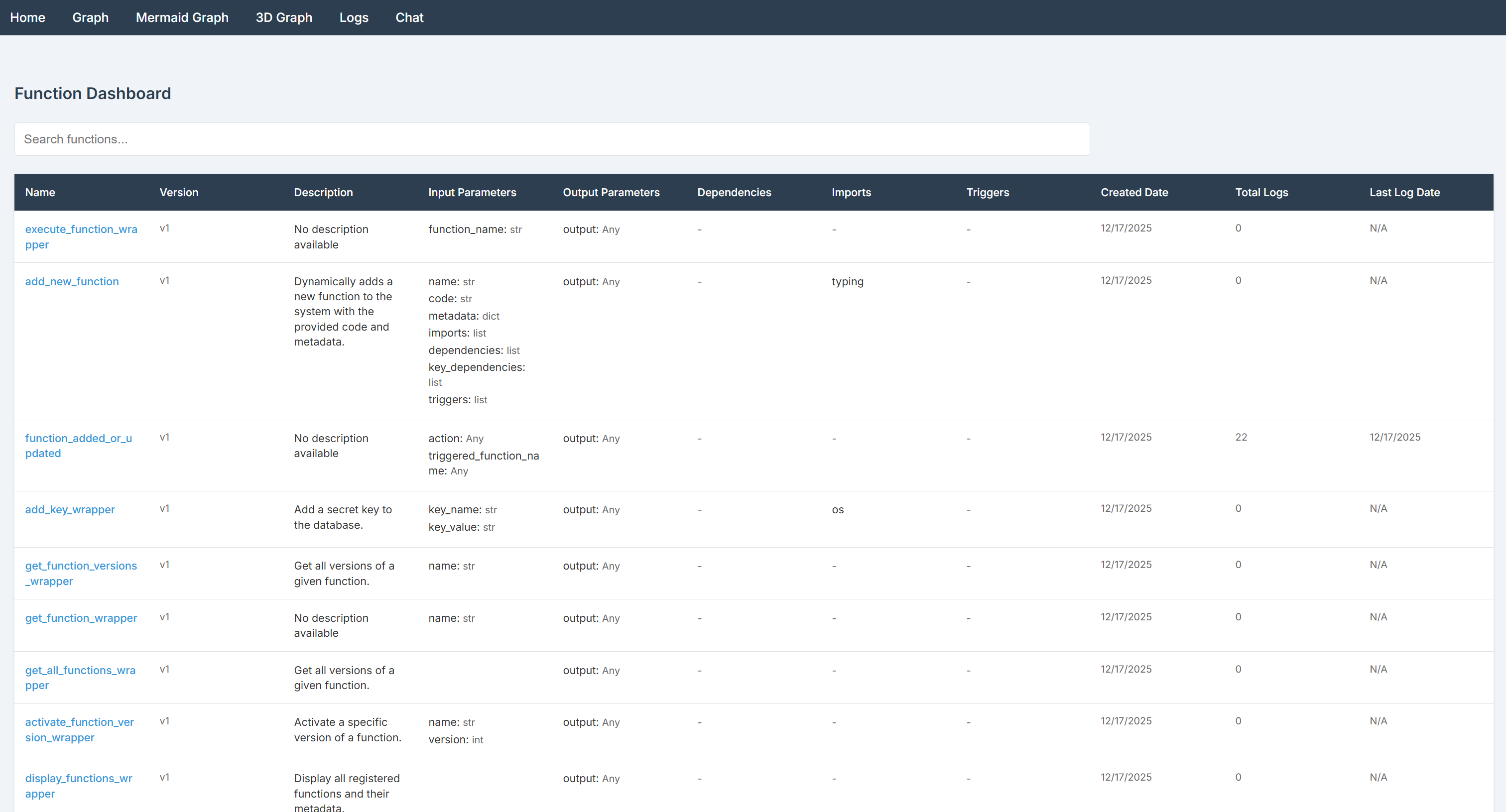
BabyAGI 仪表板首页会列出所有可用函数。默认情况下,该库自带两个预加载函数包:
- 默认函数:
- 函数执行:运行、添加、更新及检索函数及其版本。
- 密钥管理:添加和获取密钥(secret)。
- 触发器:配置基于其他函数执行的触发器。
- 日志:按需筛选并检索执行日志。
- AI 函数:
- AI 描述和向量嵌入:自动生成函数描述和向量嵌入。
- 函数选择:根据提示查找或推荐相似函数。
BabyAGI 仪表板为你提供一个易用界面,用于管理函数、监控执行、处理密钥、配置触发器以及可视化依赖关系。建议先浏览各个页面熟悉其功能和选项。
第 3 步:配置密钥管理
你的 BabyAGI Agent 将连接到 OpenAI 和 Bright Data 等第三方服务。这些连接需要通过外部 API 密钥进行认证。直接在 main.py 中硬编码 API 密钥不是最佳实践,因为可能会带来安全风险。更好的做法是从环境变量中加载。
BabyAGI 内置了一个机制,可以从环境变量或本地 .env 文件中读取密钥,无需额外依赖。要使用此功能,请在项目目录中添加一个 .env 文件:
babyagi-bright-data-app/
├── .venv/
├── .env # <----
└── main.py在 .env 文件中添加变量后,你可以在代码中这样访问它们:
import os
ENV_VALUE = os.getenv("ENV_NAME")这样就完成了!你的脚本现在从环境变量中安全加载第三方集成所需的密钥,而不是硬编码。
此外,你也可以直接在仪表板中设置这些密钥。首先,你需要配置 OpenAI API 密钥(下一步会介绍)。完成后,进入仪表板中的“Chat”页面。在函数选择器中选择 add_key_wrapper 函数,然后通过类似如下的消息为你的密钥下发配置:
Define an ENV_NAME secret whose value is ENV_VALUE.提交提示后,你应能看到类似以下的结果: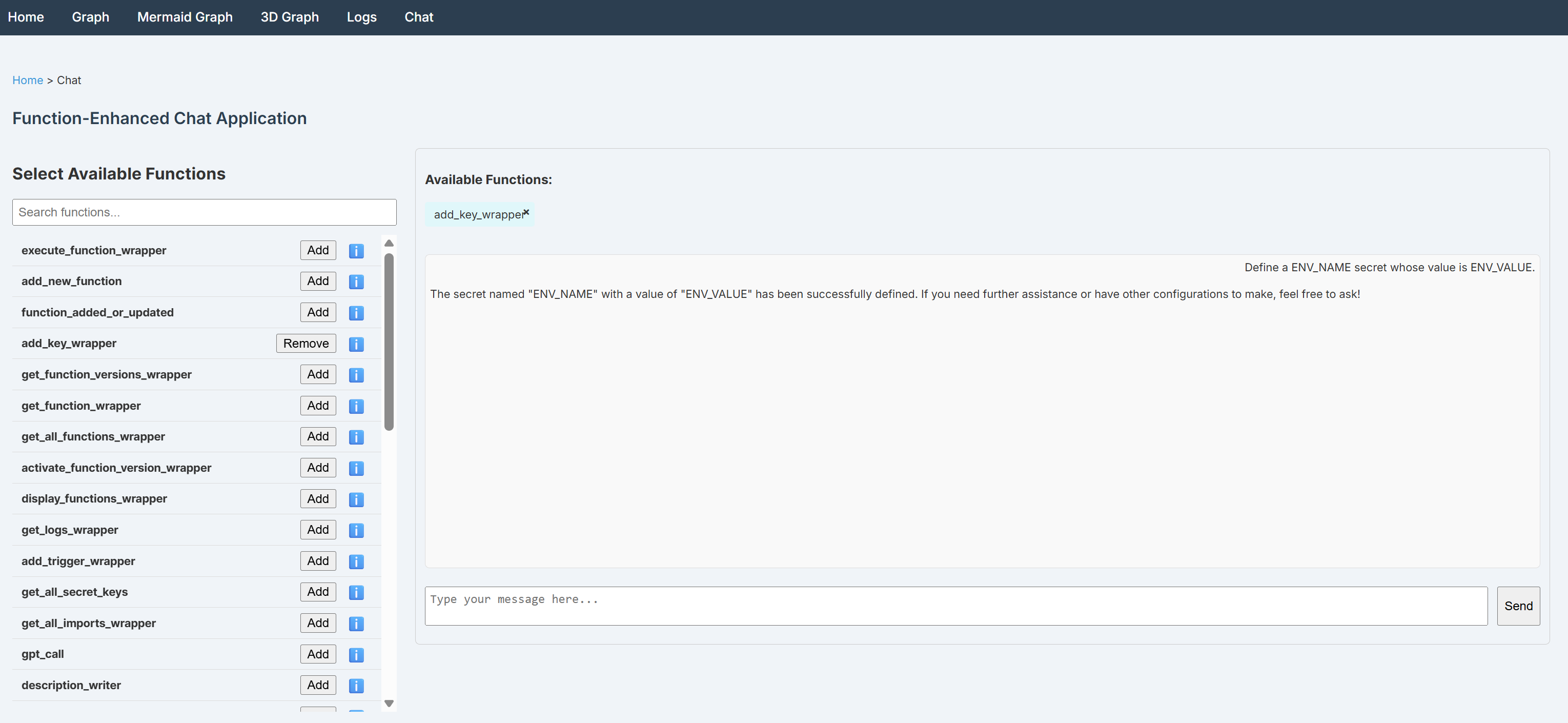
如图所示,密钥已成功创建。你可以添加 get_all_secrets_keys 函数并调用它来验证密钥是否存在。
第 4 步:将 BabyAGI 连接到 OpenAI 模型
BabyAGI 仪表板中的“Chat”页面允许你通过对话界面选择并调用函数:
在后台,该界面基于 LiteLLM 提供服务,通过 OpenAI 集成实现。因此,你必须在密钥中配置一个 OpenAI API 密钥。
如果缺少 OPENAI_API_KEY 密钥,在 Chat 页面发送的任何消息都会失败,并出现类似以下错误:
{"error":"litellm.AuthenticationError: AuthenticationError: OpenAIException - The api_key client option must be set either by passing api_key to the client or by setting the OPENAI_API_KEY environment variable"}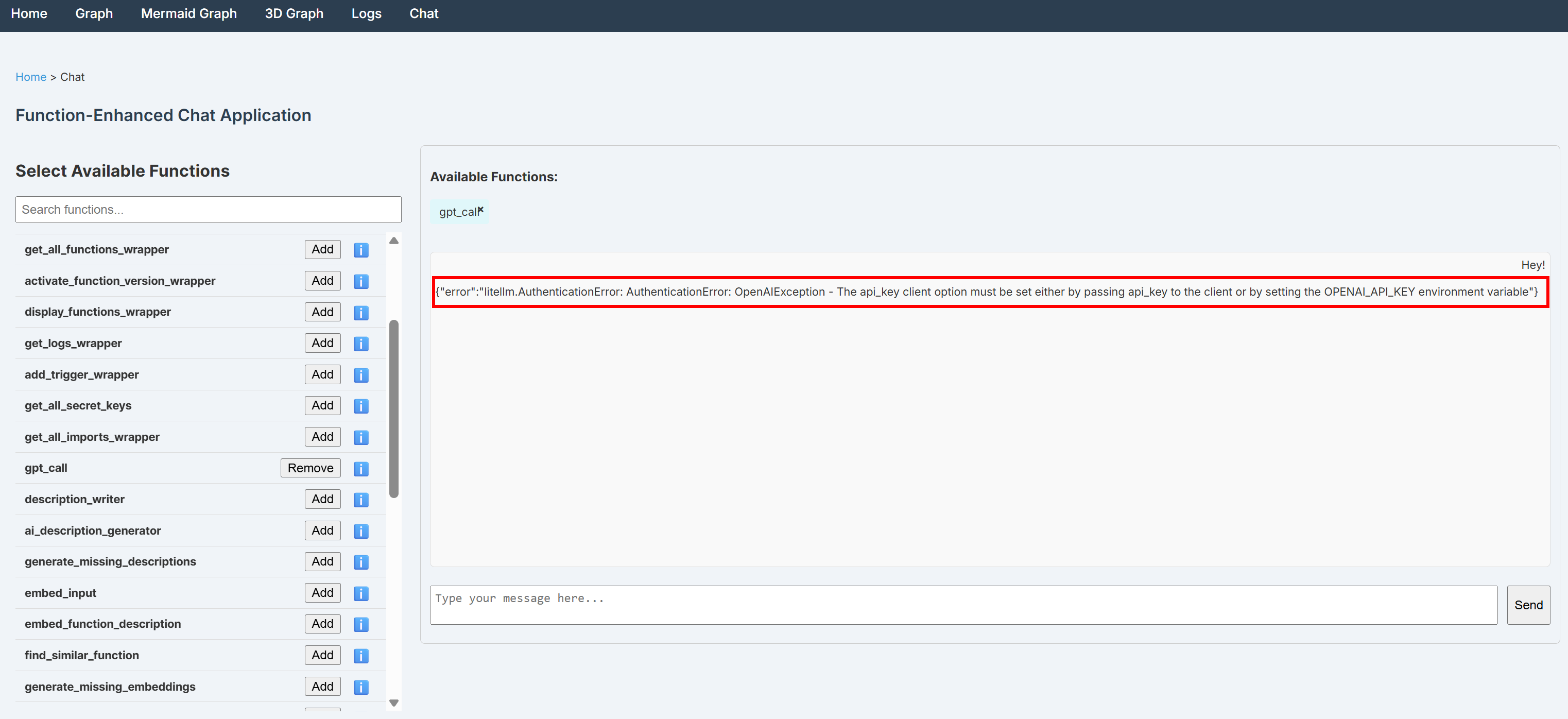
要解决该问题,只需在 .env 文件中添加 OPENAI_API_KEY 环境变量:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"保存文件后,重启 BabyAGI。为了确认集成是否生效,再次打开仪表板中的“Chat”页面。选择 get_call 函数(该函数会直接调用已配置的 OpenAI 模型),并发送一条简单消息,如“Hey!”。
你应能看到类似以下的响应: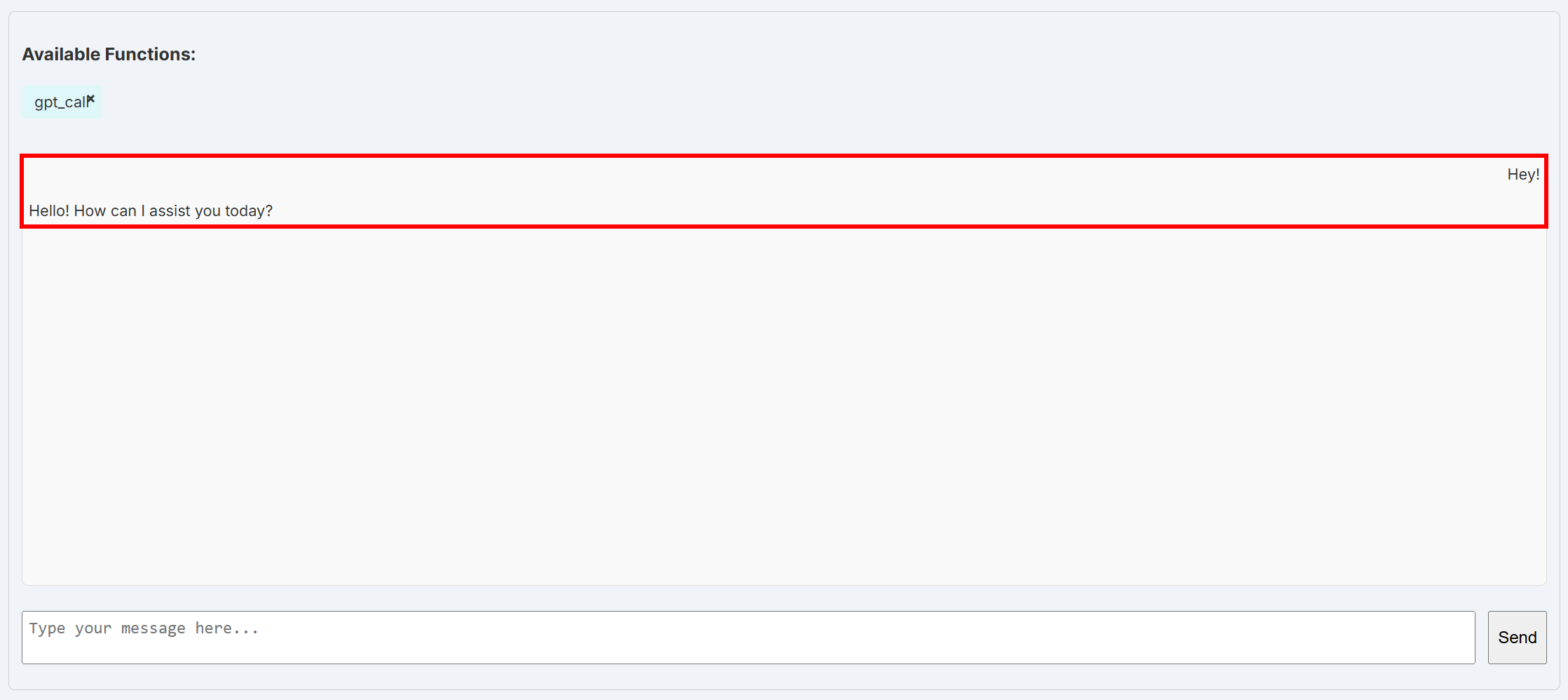
到这里,底层的 LiteLLM 层已经能够成功连接到默认的 OpenAI 模型。这是因为 LiteLLM 会自动从 OPENAI_API_KEY 环境变量中读取 OpenAI API 密钥。
很好!你的 BabyAGI 应用已经成功连接到一个 OpenAI 模型。
你也可以通过在代码中直接定义密钥达到同样效果:
babyagi.add_key_wrapper("openai_api_key", "<YOUR_OPENAI_API_KEY>")这会调用 add_key_wrapper 函数,其效果与在仪表板中使用该函数定义密钥相同。不过要注意,在完成 OpenAI 集成之前你无法使用仪表板方式,因为仪表板本身就依赖 OpenAI 连接才能运行。
第 5 步:开始使用 Bright Data
要在 BabyAGI 中使用 SERP API 和 Web Unlocker 服务,你需要一个已经配置了 SERP API 区域、Web Unlocker API 区域并拥有 API 密钥的 Bright Data 账号。下面一起来完成设置。
如果你还没有 Bright Data 账号,可以创建一个。否则,登录并进入仪表板。然后前往“Proxies & Scraping”页面,查看“My Zones”表格: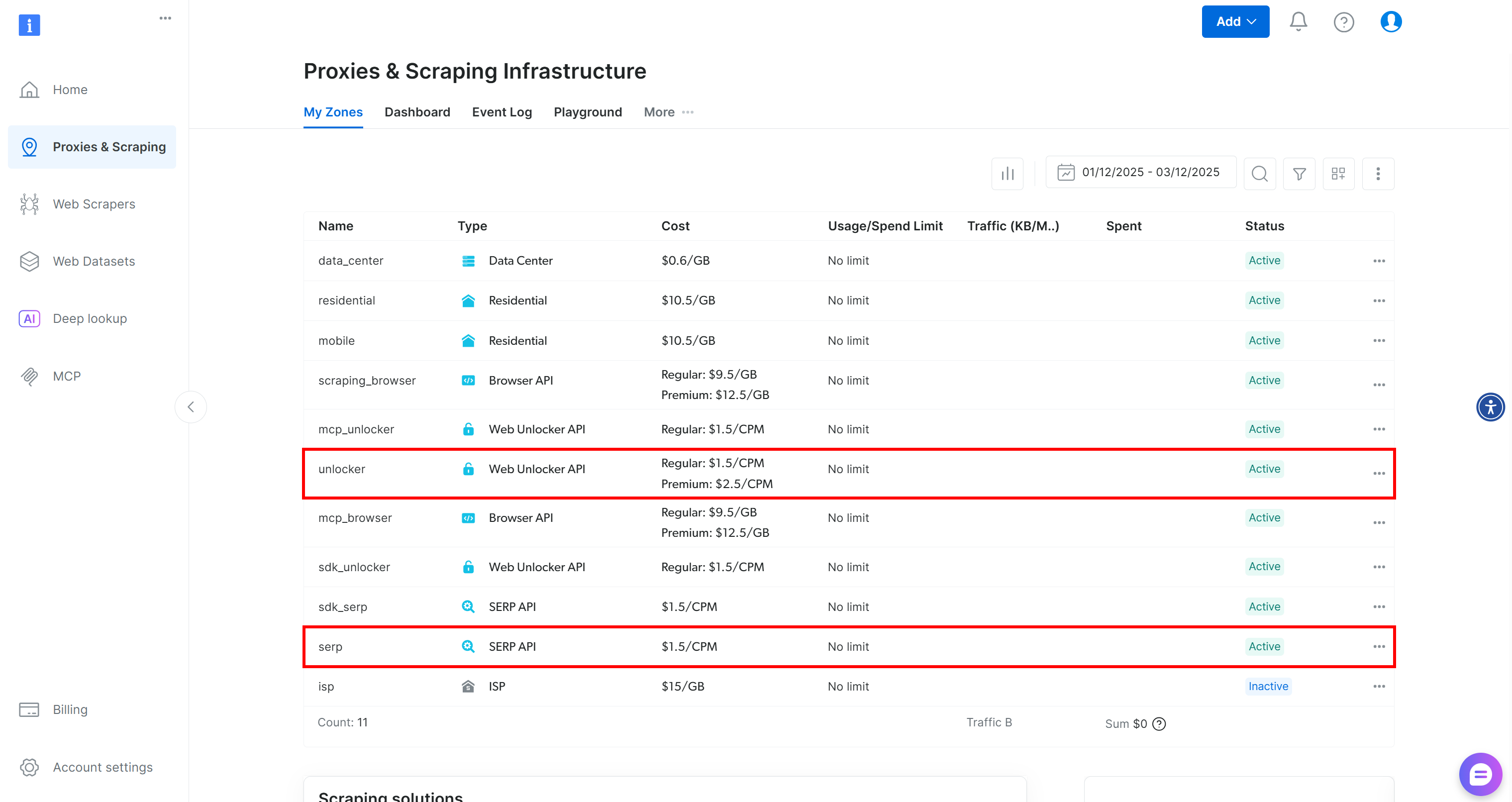
如果表格中已经包含一个 Web Unlocker API 区域(如示例中的 unlocker)和一个 SERP API 区域(如示例中的 serp),你就可以直接使用了。这两个服务将通过 BabyAGI 自定义函数来调用 Web Unlocker 和 SERP API。
如果这两个区域中有任意一个缺失,你需要创建它们。向下滚动到“Unblocker API”和“SERP API”卡片,然后点击“Create zone”按钮,按照向导创建这两个区域: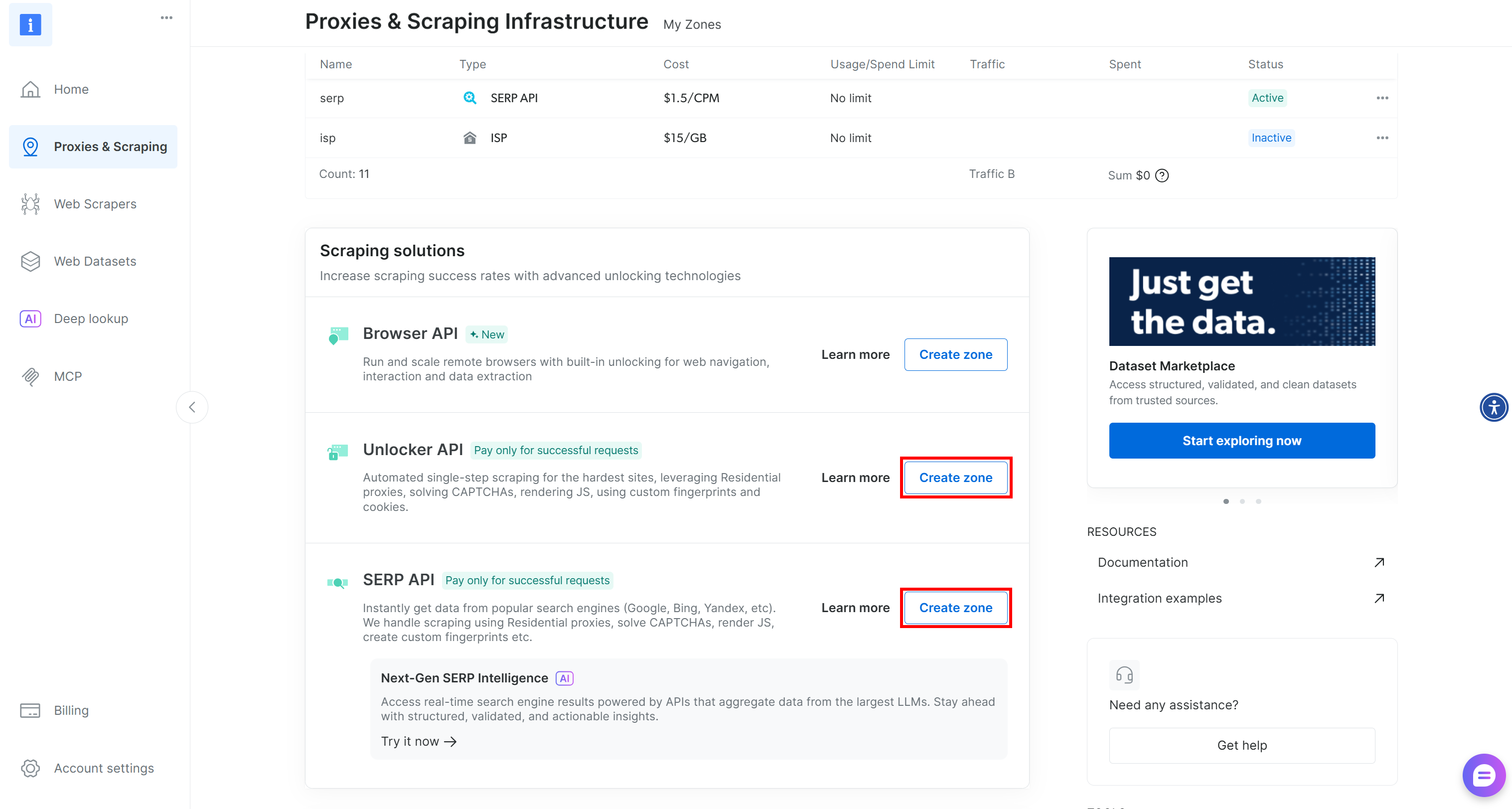
如需详细的逐步指导,可参考以下文档页面:
接下来,在 .env 文件中添加你的 Web Unlocker API 区域名和 SERP API 区域名:
SERP_API_ZONE="serp"
WEB_UNLOCKER_ZONE="unlocker"重要说明:在此示例中,我们假设 SERP API 区域名为 "serp",Web Unlocker API 区域名为 "unlocker"。如果你的实际区域名不同,请用真实名称替换。
最后,你需要生成 Bright Data API 密钥,并将其作为环境变量存储到 .env 中:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"这三个环境变量将由自定义的 BabyAGI 函数读取,用于连接你账号中的 SERP API 和 Web Unlocker API 服务。现在,你已经可以在 BabyAGI 中定义并使用它们了!
第 6 步:定义 SERP API 函数
首先定义一个 BabyAGI 函数,通过 Bright Data SERP API 执行网页搜索:
@babyagi.register_function(
imports=["os", "urllib", "requests"],
key_dependencies=["bright_data_api_key", "serp_api_zone"],
metadata={"description": "Search the web for a given query using Bright Data's SERP API."}
)
def bright_data_serp_api(query: str) -> str:
import requests
import os
import urllib
# Read the Bright Data API key from the env
BRIGHT_DATA_API_TOKEN = os.getenv("bright_data_api_key")
# Make a request to the Bright Data SERP API
url = "https://api.brightdata.com/request"
data = {
"zone": os.getenv("serp_api_zone"),
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_TOKEN}",
"Content-Type": "application/json"
}
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text该函数依赖 Requests HTTP 客户端 向你的 SERP API 区域发送 POST 请求。它特别是向 Google 发送查询,并通过 Bright Data 获取解析后的 SERP 结果。更多细节可参考 Bright Data SERP API 文档。
注意,BabyAGI 函数必须通过 @babyagi.register_function 装饰器注册。该装饰器接受如下字段:
imports:函数依赖的外部库列表。由于 BabyAGI 函数运行在隔离环境中,因此需要显式声明。dependencies:该函数依赖的其他 BabyAGI 函数列表。key_dependencies:函数运行所需的密钥列表。在这里,所需密钥为"bright_data_api_key"和"serp_api_zone",分别对应你在.env中定义的BRIGHT_DATA_API_KEY和SERP_API_ZONE环境变量。metadata["description"]:对函数行为的人类可读描述,有助于 OpenAI 模型理解该函数的用途。
很好!你的 BabyAGI 应用现在已经包含了 bright_data_serp_api 函数,可通过 Bright Data SERP API 执行网页搜索。
第 7 步:定义 Web Unlocker API 函数
类似地,定义一个调用 Web Unlocker API 的自定义函数:
@babyagi.register_function(
imports=["os", "requests"],
key_dependencies=["bright_data_api_key", "web_unlocker_zone"],
metadata={"description": "Fetch web page content through the Bright Data Web Unlocker API."}
)
def bright_data_web_unlocker(page_url: str, data_format: str = "markdown") -> str:
import requests
import os
# Read the Bright Data API key from the env
BRIGHT_DATA_API_TOKEN = os.getenv("bright_data_api_key")
# Make a request to the Bright Data Web Unlocker API
url = "https://api.brightdata.com/request"
data = {
"zone": os.getenv("web_unlocker_zone"),
"url": page_url,
"format": "raw",
"data_format": data_format
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_TOKEN}",
"Content-Type": "application/json"
}
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text该函数与 bright_data_serp_api 的工作方式基本相同,主要区别在于调用的是 Web Unlocker API。关于该 API 可用参数和选项的更多说明,请参考 Bright Data 文档。
注意,该函数依赖 web_unlocker_zone 密钥,它对应于第 5 步中定义的 WEB_UNLOCKER_ZONE 环境变量。此外,data_format 参数默认设为 markdown,以启用特殊的“以 Markdown 形式抓取”功能,将目标网页的抓取内容以优化过的 Markdown 格式返回,非常适合 LLM 摄取。
提示:采用类似的设置,你还可以扩展 BabyAGI 来集成其他基于 API 的 Bright Data 解决方案,例如Web Scraping API。
任务完成!你已经将所需的 Bright Data 驱动函数添加到了 BabyAGI 中。
第 8 步:完整代码
最终的 main.py 文件代码如下:
import babyagi
@babyagi.register_function(
imports=["os", "urllib", "requests"],
key_dependencies=["bright_data_api_key", "serp_api_zone"],
metadata={"description": "Search the web for a given query using Bright Data's SERP API."}
)
def bright_data_serp_api(query: str) -> str:
import requests
import os
import urllib
# Read the Bright Data API key from the env
BRIGHT_DATA_API_TOKEN = os.getenv("bright_data_api_key")
# Make a request to the Bright Data SERP API
url = "https://api.brightdata.com/request"
data = {
"zone": os.getenv("serp_api_zone"),
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_TOKEN}",
"Content-Type": "application/json"
}
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text
@babyagi.register_function(
imports=["os", "requests"],
key_dependencies=["bright_data_api_key", "web_unlocker_zone"],
metadata={"description": "Fetch web page content through the Bright Data Web Unlocker API."}
)
def bright_data_web_unlocker(page_url: str, data_format: str = "markdown") -> str:
import requests
import os
# Read the Bright Data API key from the env
BRIGHT_DATA_API_TOKEN = os.getenv("bright_data_api_key")
# Make a request to the Bright Data Web Unlocker API
url = "https://api.brightdata.com/request"
data = {
"zone": os.getenv("web_unlocker_zone"),
"url": page_url,
"format": "raw",
"data_format": data_format
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_TOKEN}",
"Content-Type": "application/json"
}
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text
if __name__ == "__main__":
app = babyagi.create_app("/dashboard")
app.run(host="0.0.0.0", port=8080)对应的 .env 文件内容如下:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"
SERP_API_ZONE="<YOUR_SERP_API_ZONE_NAME>"
WEB_UNLOCKER_ZONE="<YOUR_WEB_UNLOCKER_ZONE_NAME>"
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"通过以下命令启动 BabyAGI 仪表板:
python main.py在浏览器中打开 http://localhost:8080/dashboard,访问“Chat”页面并搜索“bright_data”。你会看到两条与 Bright Data 集成相关的函数出现在搜索结果中: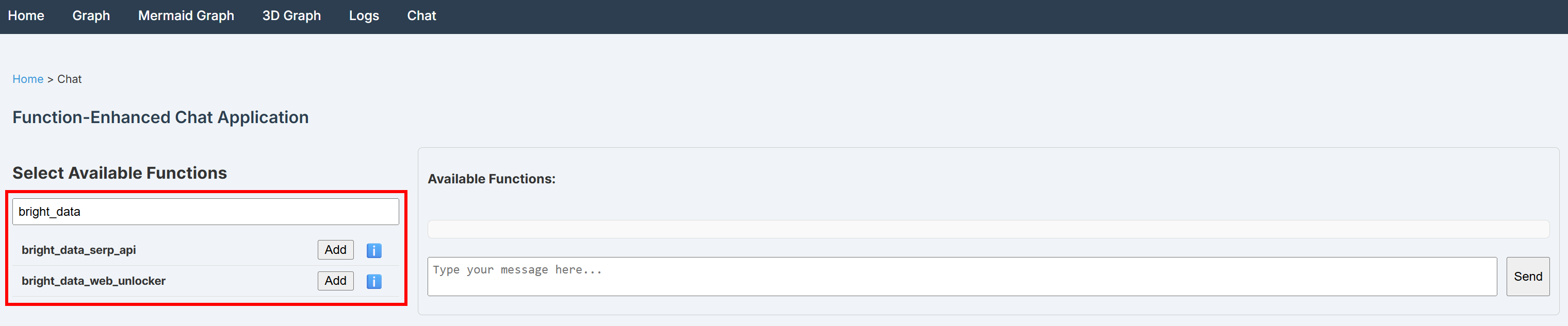
可以看到,这两个自定义函数均已成功注册。
第 9 步:测试 BabyAGI + Bright Data 集成
现在通过测试 Bright Data 函数来验证 BabyAGI 应用是否工作正常。使用默认的 chat_with_functions 函数来完成测试。该函数会启动一个与 LiteLLM 相连的对话流程,并从函数数据库中调用所选函数。
首先,选择 bright_data_serp_api 和 bright_data_web_unlocker 函数,然后选择 chat_with_functions:
接着,你需要使用一个既触发网页搜索又触发数据抽取的提示。例如:
Search the web for the latest Google AI announcements (2025), select the top 3 reliable news or blog articles, access each one, and summarize the key insights about the future of Google AI (mentioning the URLs of the source articles)注意:如果没有任何用于访问网络的外部工具,一个普通 LLM 是无法完成该任务的。
在对话中执行上述提示,你应该能看到类似如下的输出: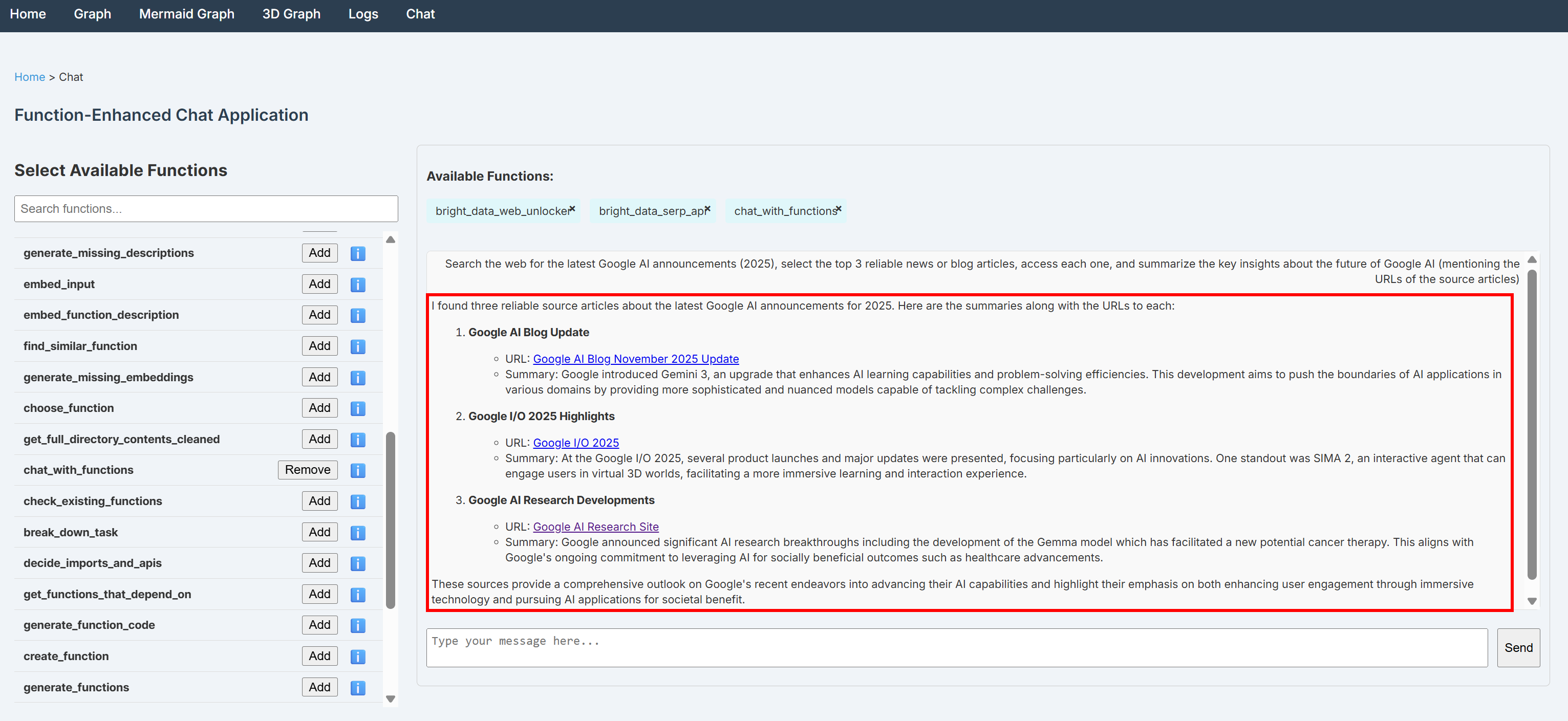
可以看到,输出包含了从 SERP API 搜索 Google 以及通过 Web Unlocker API 抓取新闻页面后得到的、有据可依的信息。
现在你已经验证了 Agent 能够与当前网络内容交互并从中学习,这意味着它具备自构建函数的能力,这些函数可以通过访问其它服务的文档来学习原本不掌握的技术细节。你可以通过 self_build 函数来测试这一自构建能力,具体可参阅 BabyAGI 文档。
欢迎你尝试不同的输入提示和其他 BabyAGI 函数。借助 Bright Data 函数,你的 BabyAGI 自构建 Agent 能够处理多种真实世界的应用场景。
Et voilà!你刚刚体验了将 Bright Data 与 BabyAGI 结合的强大威力。
总结
在本文中,你了解了如何通过调用 SERP API 和 Web Unlocker API 的自定义函数,将 Bright Data 能力集成到 BabyAGI 中。
这样的设置使得你可以从任意网页检索内容并执行实时网络搜索。若想进一步扩展功能,例如访问实时 Web 数据流、自动化网页交互等,可以将 BabyAGI 与 完整的 Bright Data AI 服务套件进行集成。
释放自构建 AI Agent 的全部潜力!
立即免费注册 Bright Data 账号,开始体验我们为 AI 场景准备的网页数据解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




