

在这篇博客文章中,你将看到:
- AutoGPT 是什么,以及它作为 AI agent 构建框架的特别之处。
- 为什么 AutoGPT agents 需要访问网页搜索、探索、交互,以及数据抓取能力才能受益更多。
- 如何将 Bright Data 集成到 AutoGPT 中,为 AI agents 提供以上这些能力。
让我们开始吧!
什么是 AutoGPT
AutoGPT 是一个开源平台,用于构建、部署并运行自主 AI agents。
它的突出点在于低代码的积木式界面、持续执行 agent 的能力,以及能够把工具、API 与数据源连接成端到端自动化流水线。
与简单脚本不同,AutoGPT agents 可以长期运行、对触发器作出响应,并管理多步骤任务。该项目由大型开源社区支持,在 GitHub 上获得了惊人的关注度,星标超过 183k。
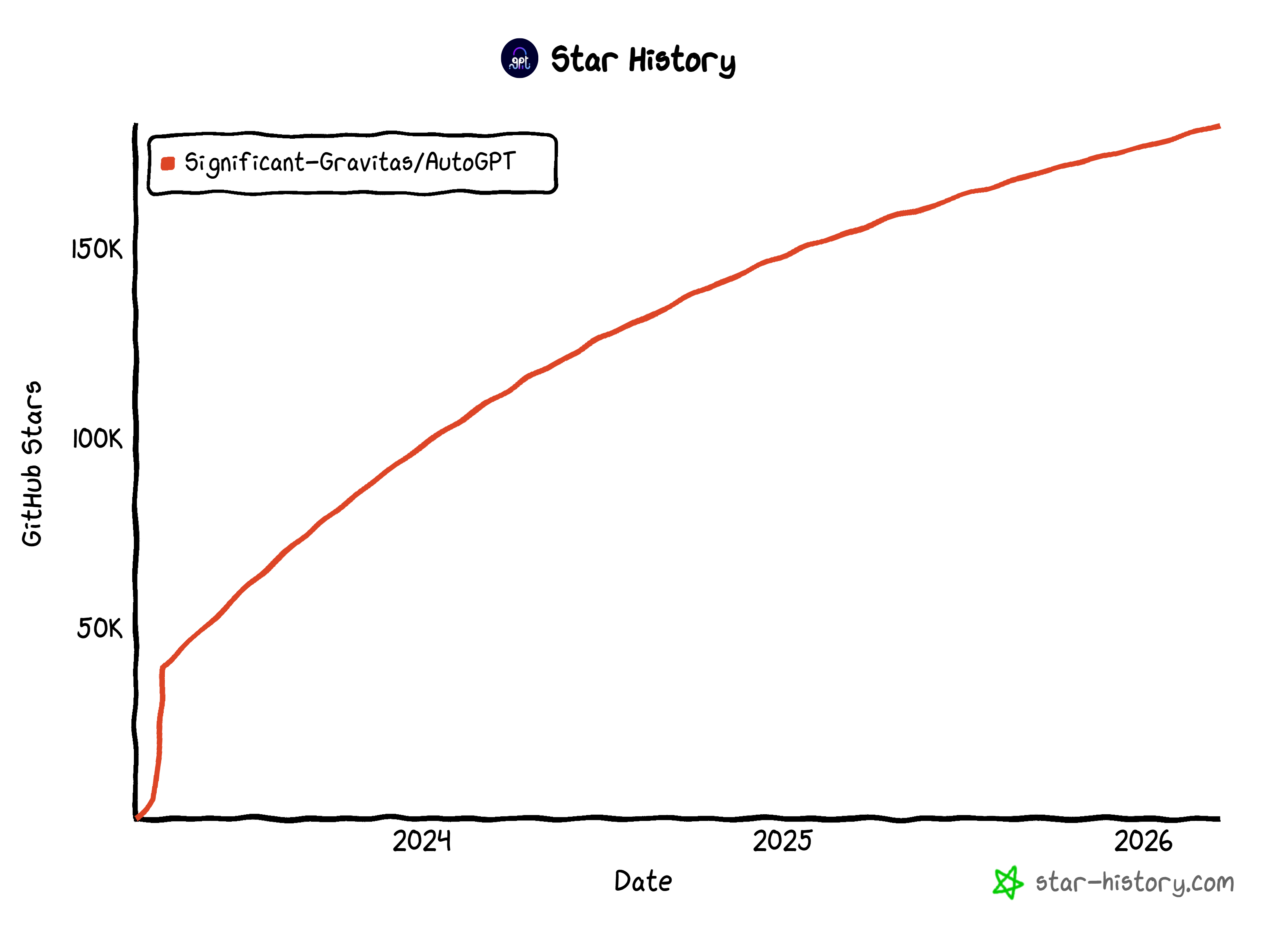
这些数据让它成为当今最受欢迎的 AI agent 框架之一。
为什么要把网页探索与数据获取能力集成到 AutoGPT 中
毫无疑问,AutoGPT 是一个功能丰富的解决方案。然而,所有基于 LLM 的 AI agents 都面临固有局限。标准语言模型训练自静态数据集,这意味着它们的知识被固定在某个时间点。
这会导致当 agents 尝试执行需要最新数据的真实世界任务时,出现信息过时、幻觉或知识缺口。此外,LLM 无法与真实世界交互,包括与 Web 交互。因此,基础 AI agents 会受这些原生限制所约束。
AutoGPT 的确包含用于网页搜索、探索及其他交互的原生工具,但与企业级解决方案相比,这些内置能力在规模、可靠性以及应对复杂反爬措施方面可能会更吃力。
这正是 Bright Data 发挥作用的地方。它构建在全球最大的代理网络之一之上——覆盖 195 个国家/地区、拥有超过 1.5 亿个 IP——其基础设施可提供 99.99% 的正常运行时间与无限并发。
将 Bright Data 集成到 AutoGPT 后,agents 就可以访问任何网站的实时网页内容、搜索结果以及结构化数据。具体来说,可增强 AutoGPT 工作流的 Bright Data 关键产品包括:
- Web Unlocker API:以原始 HTML 或 Markdown 访问任意网站内容,绕过 CAPTCHA 与反机器人保护。
- 搜索引擎 API:从 Google、Bing、Yandex 等众多搜索引擎采集搜索结果。
- 网页爬虫工具 API:从 Amazon、LinkedIn、Instagram、Yahoo Finance 等平台提取结构化数据。
- Crawl API:将整个网站转换为结构化数据集,用于后续 AI 处理。
通过把 AutoGPT 的代理式能力与 Bright Data 的解决方案结合起来,AI agents 能够自主获取实时信息,并执行远超标准 LLM 限制的复杂工作流。
如何将 Bright Data 集成到 AutoGPT:一步步指南
在本引导章节中,你将学习如何在 AutoGPT 中构建一个与 Bright Data 集成的 AI agent,用于 Web 数据获取。
具体来说,这个 agent 将充当书签助手,帮助你判断一篇线上文章是否值得保存以便稍后阅读。这只是一个用于展示集成方式的简单例子,但还可以拓展到许多其他用例。
请按下方说明操作!
前置条件
要自托管 AutoGPT,请确保你的系统满足以下硬件要求:
- 操作系统:Linux(推荐 Ubuntu 20.04 或更新版本)、macOS(10.15 或更新版本),或带 WSL2 的 Windows 10/11。
- CPU:建议 4 核及以上。
- 内存:至少 8 GB(建议 16 GB)。
- 存储:至少 10 GB 可用空间。
你还必须在本机安装这些工具:
- Docker Engine 20.10.0+
- Docker Compose 2.0.0+
- Git 2.30+
- Node.js 16.x+(含 npm 8.x+)
- Visual Studio Code 1.60+ 或任意现代代码编辑器
此外,请确保满足以下网络要求:
- 稳定的互联网连接。
- 可访问所需端口(将通过 Docker 配置)。
- 能够发起对外的 HTTPS 连接。
要在 AutoGPT 中实现该 AI agent,你还需要:
- 一个已配置 Web Unlocker API 区域(zone)并设置好 API key 的 Bright Data 账号。
- 来自 AutoGPT 支持的某个 LLM 提供商 的 API key(本例使用 OpenAI)。
先不用担心配置 Bright Data 账号,后续会在专门章节中带你完成。
步骤 #1:在本地安装 AutoGPT
确保你的系统满足硬件、软件与网络前置条件,并确认 Docker 正在运行。
为简化自托管 AutoGPT 的配置流程,推荐使用官方一行安装脚本。它会安装所有必要依赖、拉取最新代码并为你启动应用。
在 macOS 或 Linux 上,执行一行安装脚本:
curl -fsSL https://setup.agpt.co/install.sh -o install.sh && bash install.sh同样地,在 Windows 上,在 PowerShell 中运行以下命令:
powershell -c "iwr https://setup.agpt.co/install.bat -o install.bat; ./install.bat"安装过程可能需要几分钟,请耐心等待。完成后,你应该会看到类似如下输出: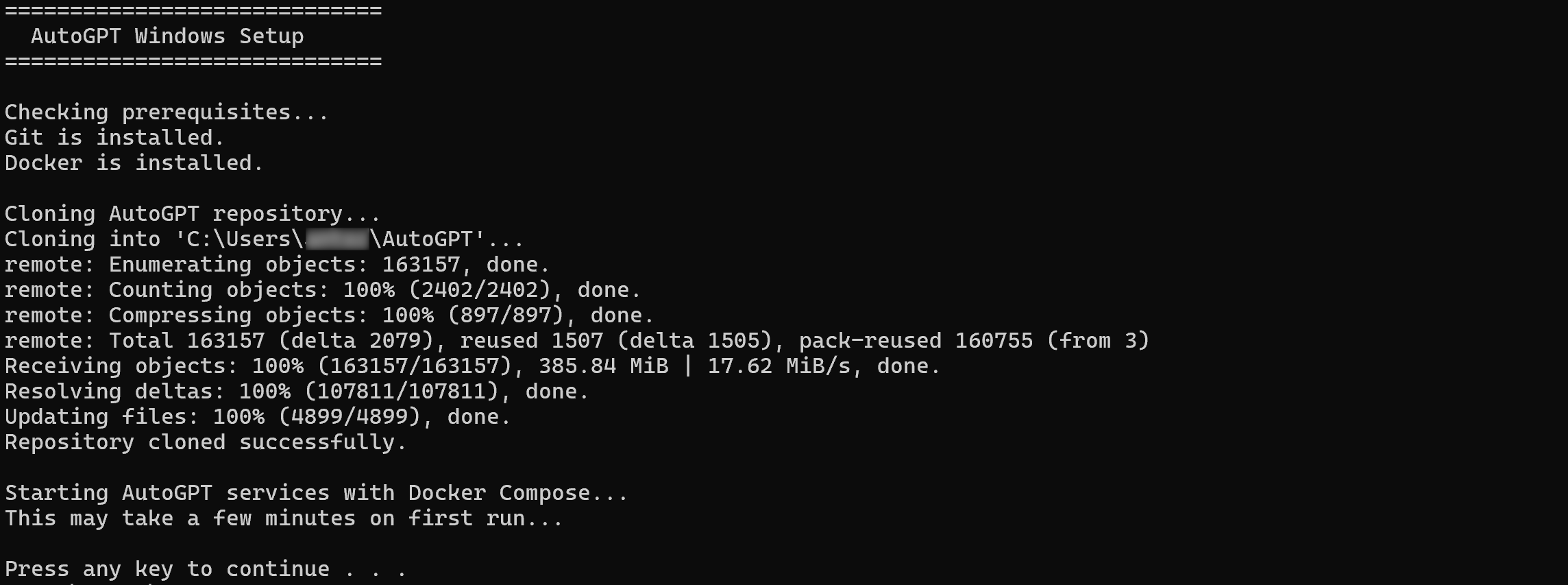
太棒了!此时 AutoGPT 应已成功在本地完成设置并可运行。
步骤 #2:启动平台
进入安装目录:
cd AutoGPT/autogpt_platform然后,将克隆仓库自带的 .env.default 文件复制为 .env:
cp .env.default .env该命令会在 autogpt_platform 目录中使用默认配置创建一个 .env 文件。仅当你需要自定义配置时才修改它;否则保持默认值即可。
接着,使用以下命令启动 AutoGPT 平台:
docker compose up -d --build该命令会以分离模式构建并启动 docker-compose.yml 中定义的所有必需后端服务。
当服务启动完成后,在浏览器访问 http://localhost 验证是否一切正常。
默认情况下,不同 AutoGPT 服务的地址为:
- 前端 UI 服务:
http://localhost。 - 后端 WebSocket 服务:
http://localhost:8001。 - 执行 API REST 服务:
http://localhost:8006。
你将看到如下界面:
注册并创建账号。登录后,你会进入 AutoGPT 前端中的 Agent Builder:
很好!现在你已经准备好创建第一个 agent,并将它连接到 Bright Data。
步骤 #3:设计 AI Agent 工作流
AutoGPT 提供了多个积木块(blocks),每个块负责一个特定动作或任务。在本例中,你要构建一个代理式工作流,用来:
- 接收任意网站的文章 URL 作为输入。
- 通过 Bright Data Web Unlocker API 以 Markdown 格式获取文章内容。
- 将内容传给 LLM,让它输出 1 到 10 的分数(表示文章是否值得加入书签),并给出类似人类的点评来解释分数。
- 返回结构化输出。

在 AutoGPT 中,可使用以下 blocks 来实现该工作流:
- Agent Input:从用户接收文章 URL。
- Create Dictionary:使用提供的 URL 构建 Bright Data Web Unlocker API 的请求体。
- Send Authenticated Web Request:向 Bright Data Web Unlocker API 发送请求并获取文章内容。
- AI Structured Response Generator:将文章内容传给 LLM,生成结构化的书签评估结果(分数 + 评论)。
- Agent Output:返回最终结构化结果。
很好!现在代理式工作流的步骤已经清晰,下一步就是实现它。不过首先,让我们从 Bright Data 开始。
步骤 #4:配置你的 Bright Data 账号
如前所述,你要实现的 AI agent 工作流依赖 Bright Data 的 Web Unlocker 产品。要在 AutoGPT 中连接它,你需要一个 Bright Data 账号、一个已配置的 Web Unlocker API zone,以及一个 API key。
如需快速指引,请参考《Bright Data Web Unlocker API 快速入门指南》。或者按以下步骤操作。
如果你还没有 Bright Data 账号,请创建一个新账号;否则直接登录。进入控制面板后,导航到 “Proxies & Scraping” 页面。查看 “My Zones” 表格: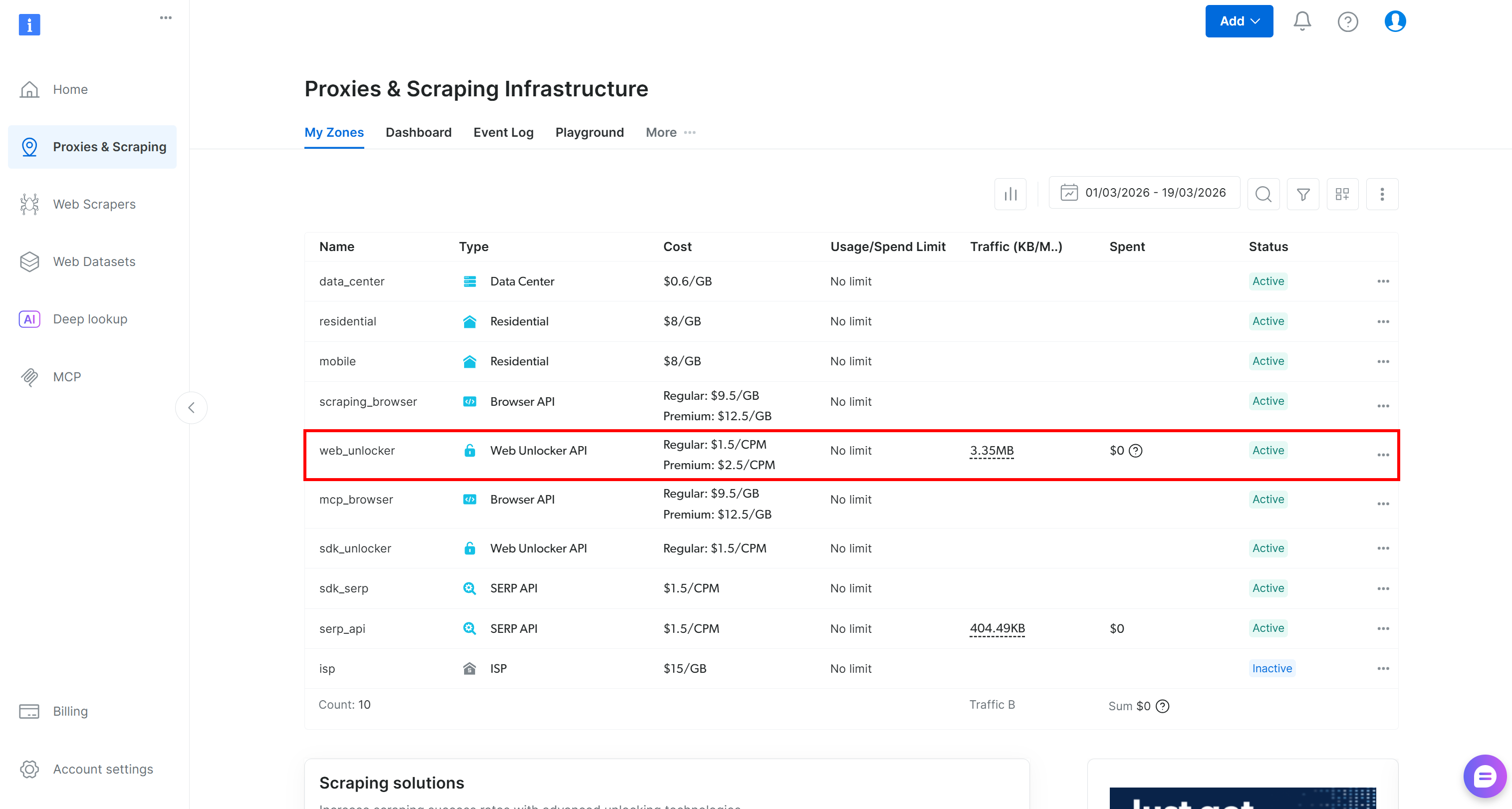
如果表格中已存在 Web Unlocker API zone(例如 web_unlocker),那么你就可以直接继续。
如果没有,则需要创建一个。滚动到 “Unblocker API” 卡片,点击 “Create zone” 按钮,并按向导操作。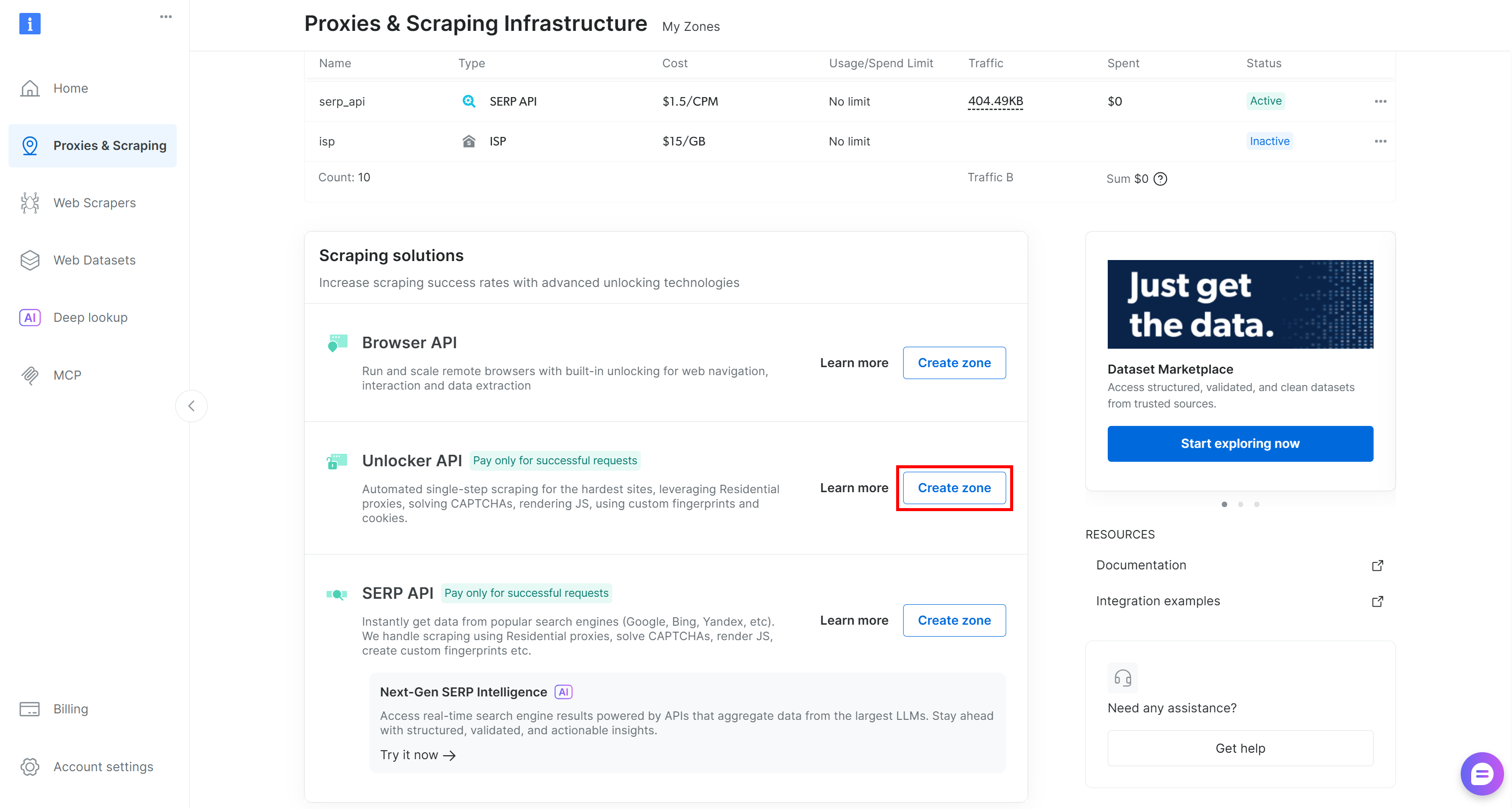
请谨慎命名 zone,因为稍后会用到。本文将假设该 zone 名称为 web_unlocker。
最后,生成你的 Bright Data API key 并安全保存。你将需要它来认证 AutoGPT 发往 Bright Data 的 HTTP 请求。
至此,Bright Data 的前置条件已完成。
步骤 #5:初始化 Agent
每个 AutoGPT 代理式工作流都需要输入与输出。首先进入 “Build” 区域打开 Agent Builder 页面:
点击 “Save” 按钮,为你的 agent 取名(例如 “Bookmark Likelihood Evaluator”),然后点击 “Save Agent”: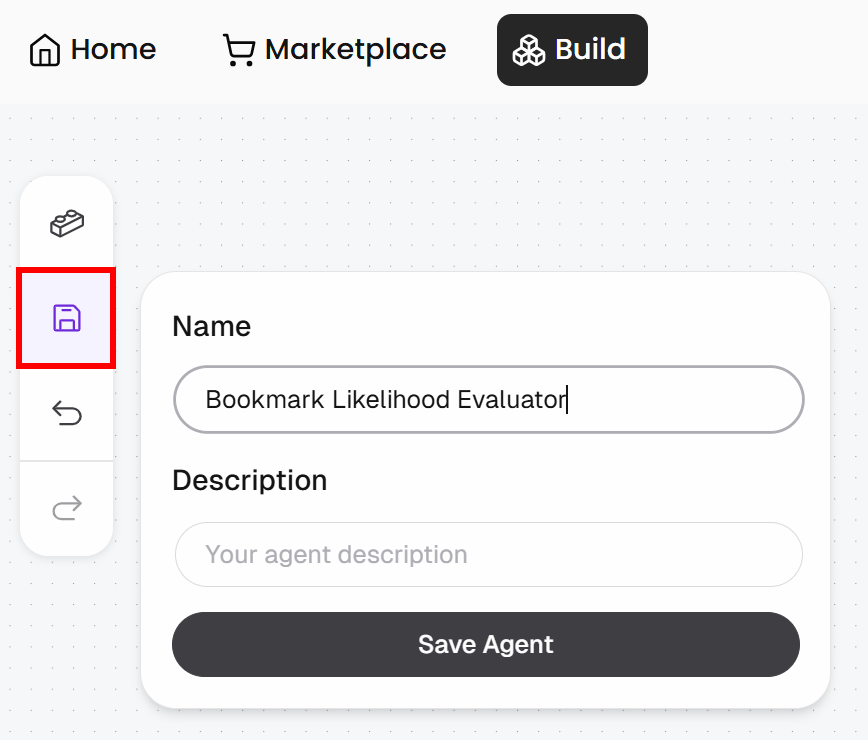
在 Agent Builder 页面,点击左侧 “Blocks” 按钮并添加一个 “Agent Input” block: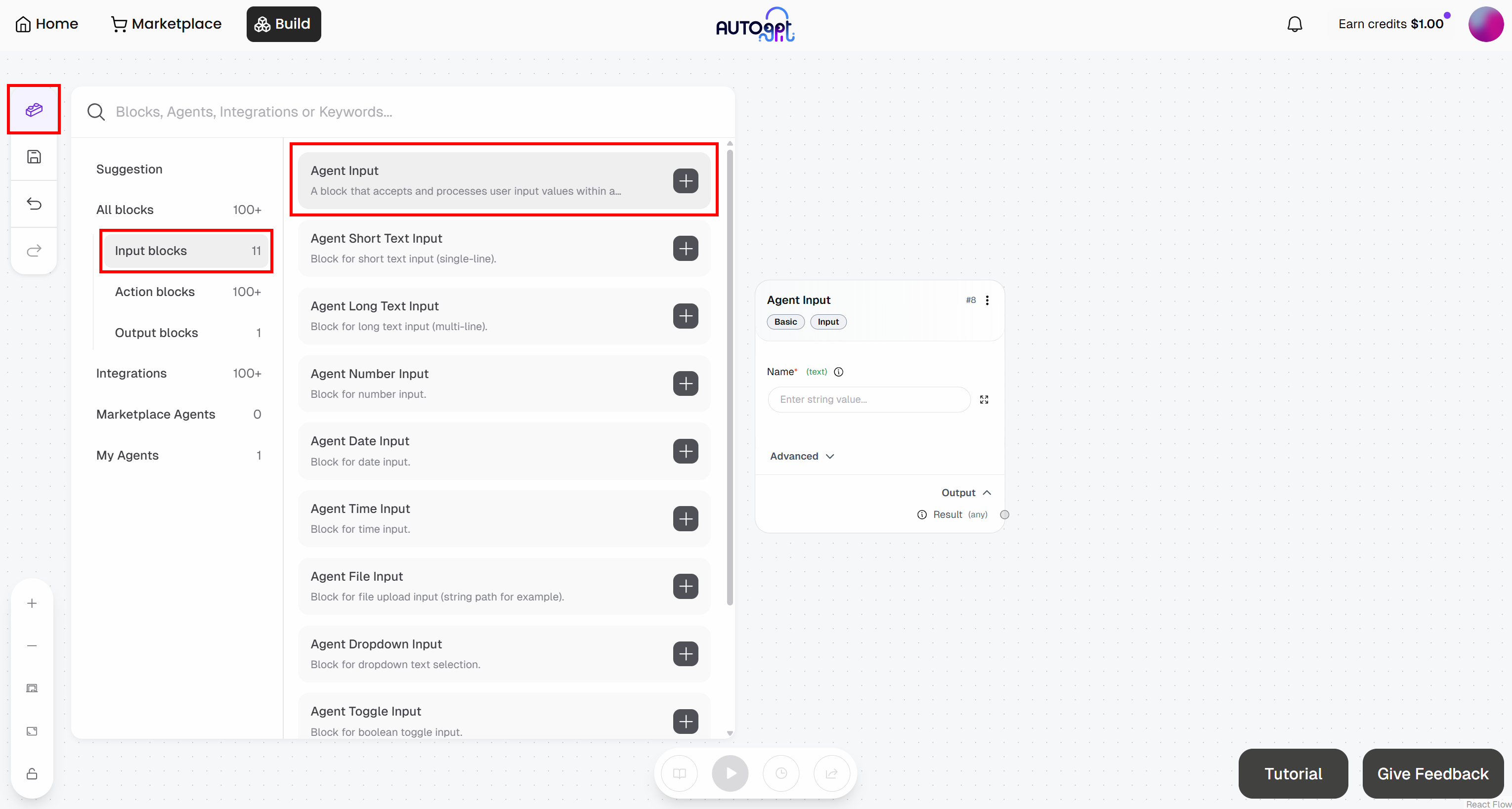
同样地,添加一个 “Agent Output” block: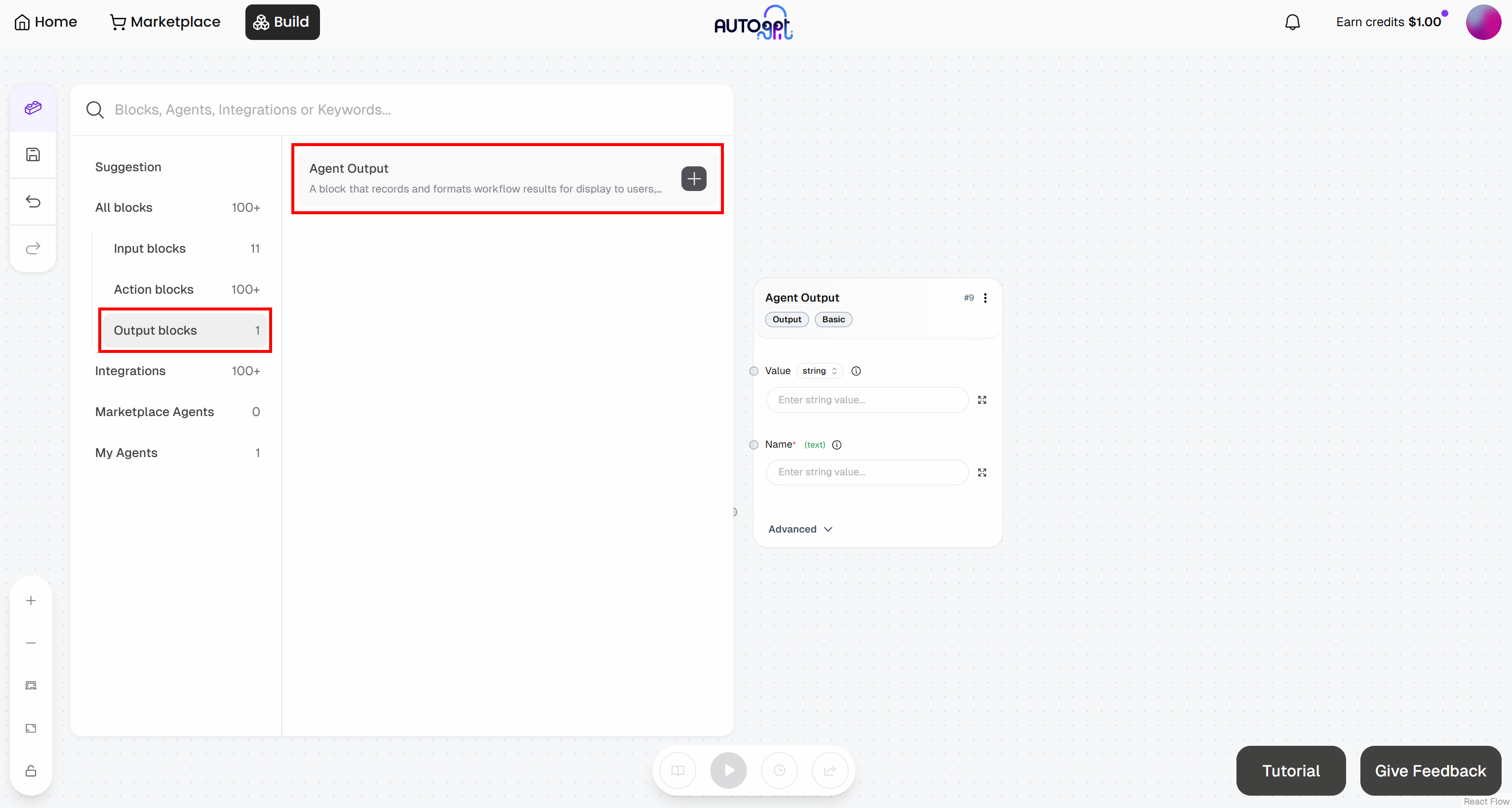
按如下配置这些 blocks:
- Agent Input:命名为 “Article URL”
- Agent Output block:命名为 “Bookmarking Likelihood”
此时,你的初始代理式工作流应如下所示: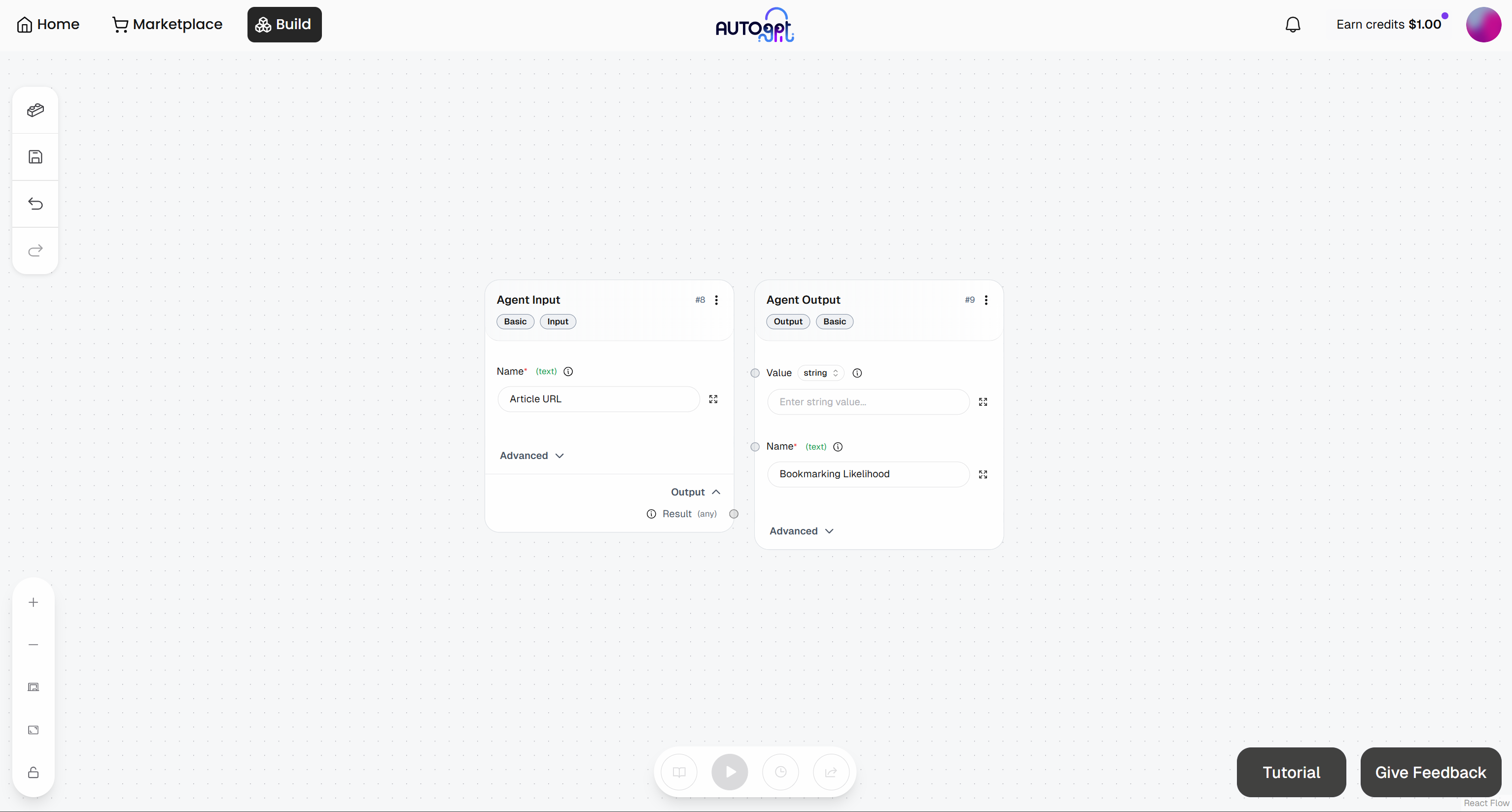
很好!现在继续定义剩余的代理式工作流。
步骤 #6:发起抓取/爬虫请求
要向 Bright Data Web Unlocker API 发起 HTTP 请求,你需要两个 blocks:
- Create Dictionary:定义请求体。
- Send Authenticated Web Request:向 Bright Data APIs 的 Web Unlocker 端点发送带认证信息的请求。
先添加 “Create Dictionary” block: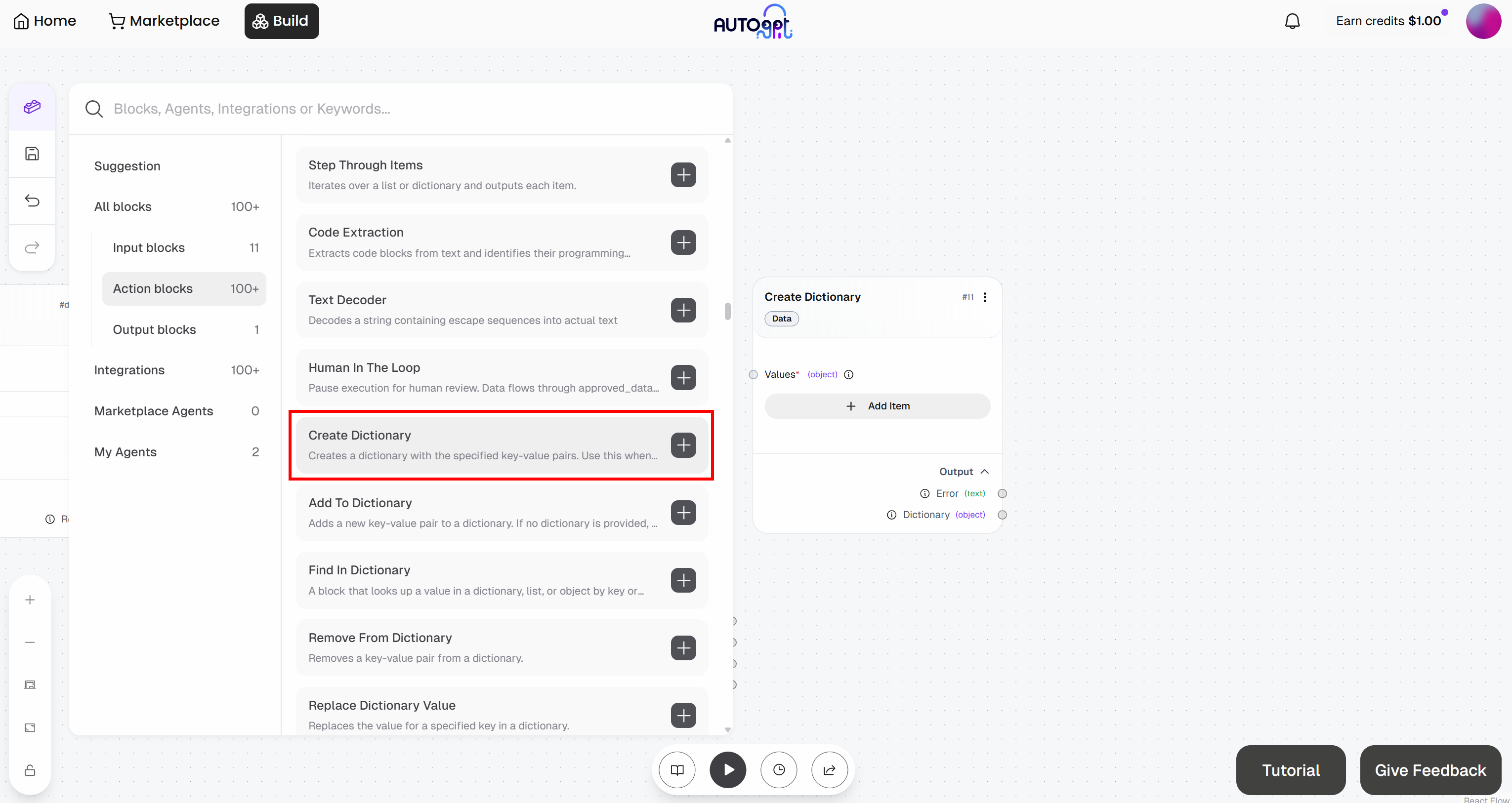
然后添加 “Send Authenticated Web Request” block: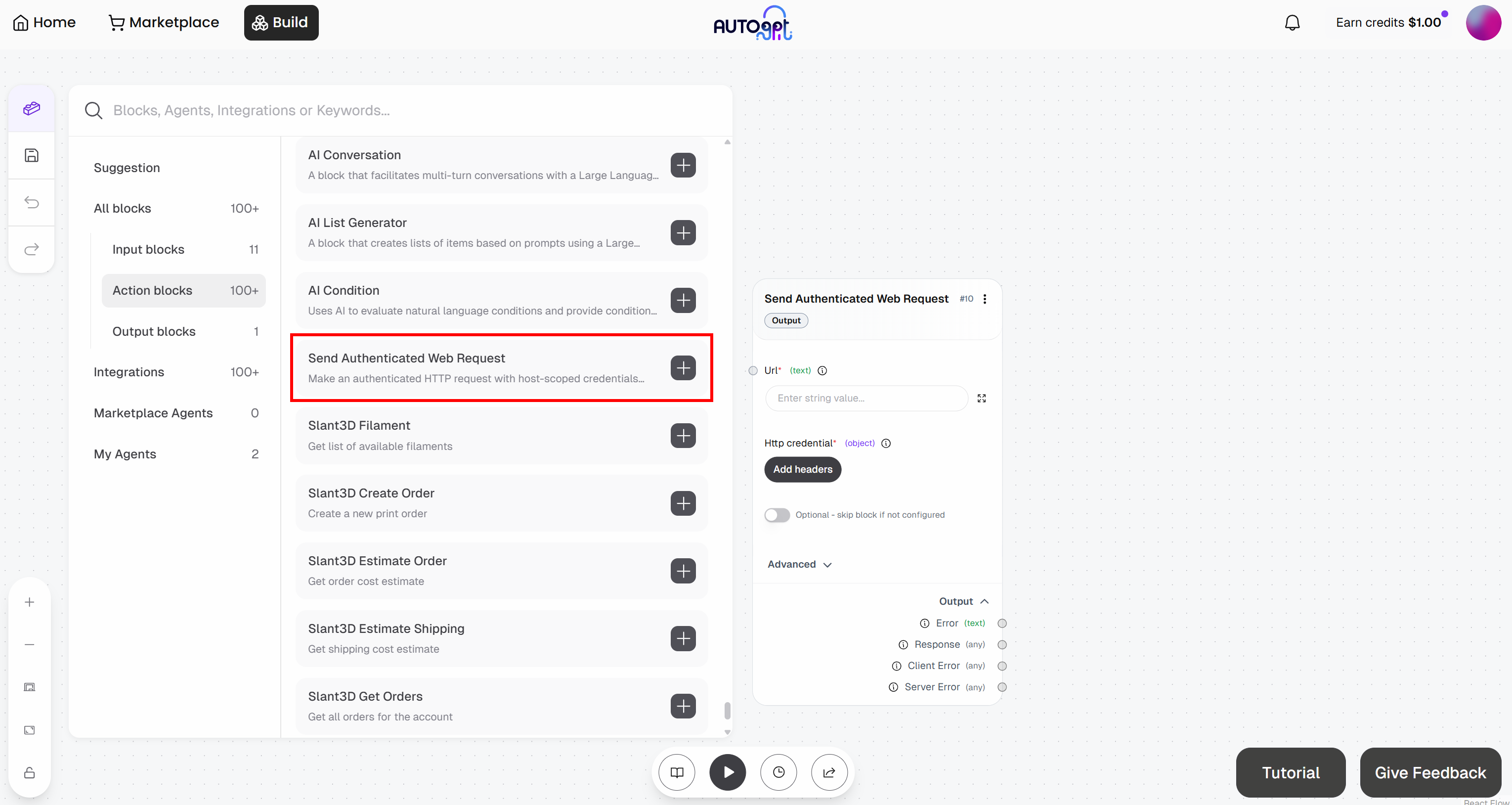
准备配置 “Send Authenticated Web Request” block。它将向 Web Unlocker API 发送请求。关于该端点如何工作及如何调用,请参考官方文档。
展开 “Advanced” 下拉菜单,并按如下填写整个 block:
- Url:
https://api.brightdata.com/request。 - HttpMethod:
POST
接下来,点击 “Http credentials” 下的 “Add headers” 按钮: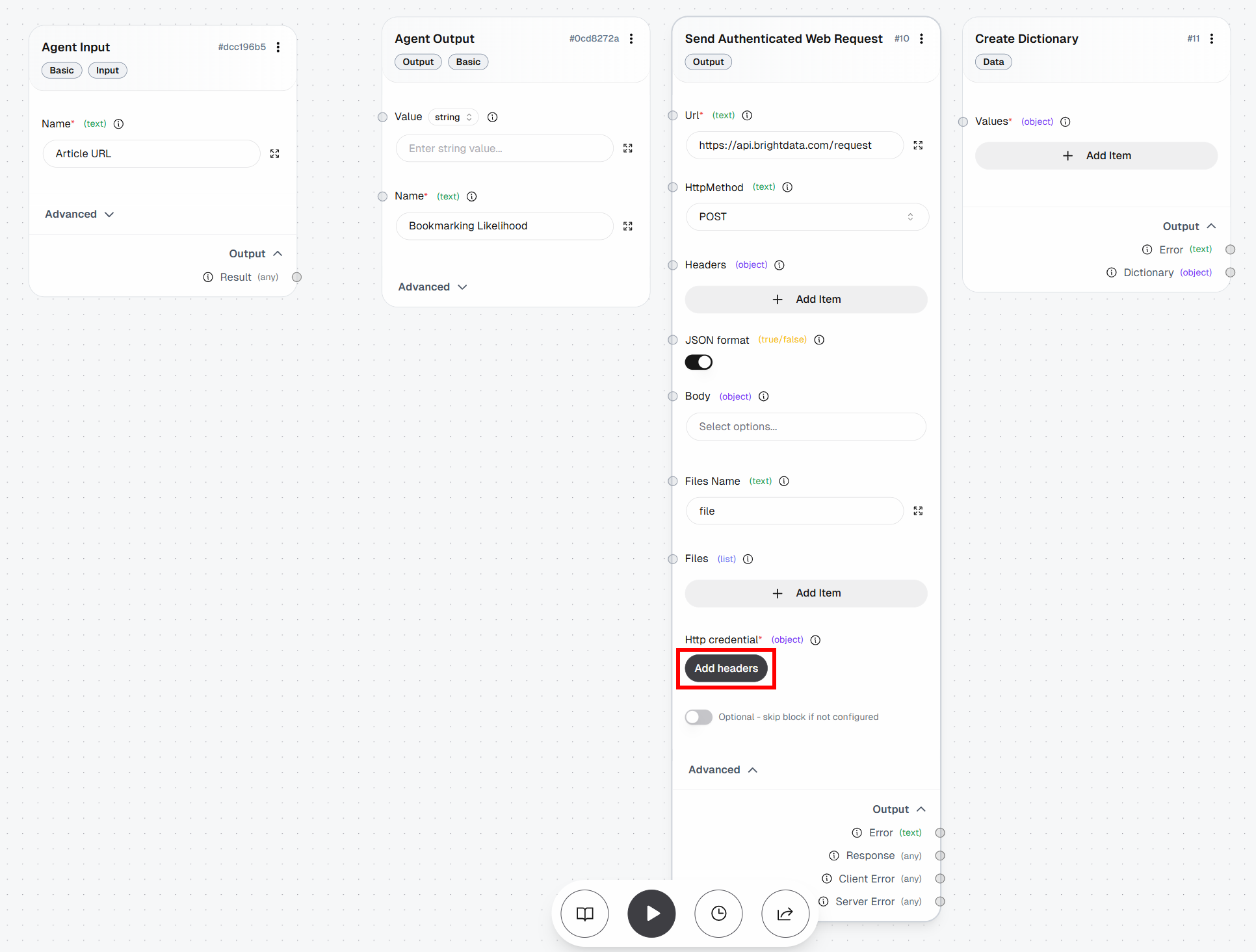
按如下配置基于 Header 的认证:
- Header Name:
Authorization - Header Value:
Bearer <YOUR_BRIGHT_DATA_API_KEY>
记得将 <YOUR_BRIGHT_DATA_API_KEY> 占位符替换为你的真实 Bright Data API key。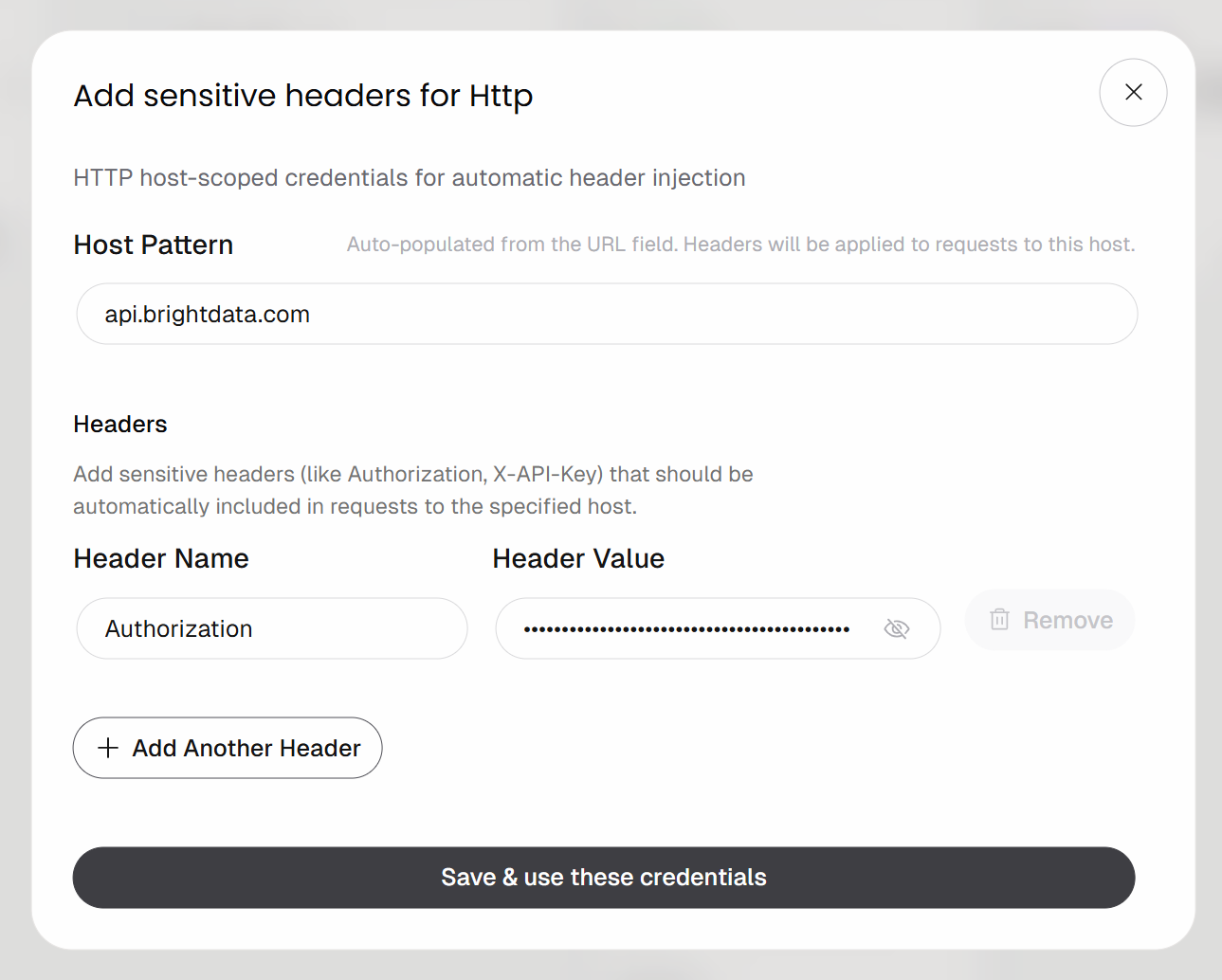
点击 “Save & use these credentials” 按钮确认。
该 POST 请求将通过 Authorization header 进行认证。这是调用 Bright Data APIs 推荐的认证方式。
现在,你需要定义请求体。在本例中,你需要如下 JSON payload:
{
"zone": "<YOUR_WEB_UNLOCKER_API_ZONE_NAME>",
"url": "<INPUT_URL>",
"format": "raw",
"data_format": "markdown"
}这会指示 Bright Data API 使用你的 Web Unlocker API zone(例如 web_unlocker)对目标 URL 发起抓取。目标 URL 将由 “Agent Input” block 提供。format: "raw" 参数确保 API 直接在响应体中返回结果,而不是包装成 JSON 结构。data_format: "markdown" 参数用于将文章内容提取为 Markdown,这是一种非常适合 AI agent 摄取的格式。
为此,切换到 “Create Dictionary” block 并点击 “Add Item”。定义以下字段:
zone:<YOUR_WEB_UNLOCKER_API_ZONE_NAME>(例如"web_unlocker")url:(先留空,后续将动态填充)format:"raw"data_format:"markdown"
然后,将 “Create Dictionary” block 的 “Dictionary” 输出连接到 “Send Authenticated Web Request” block 的 “Body” 输入: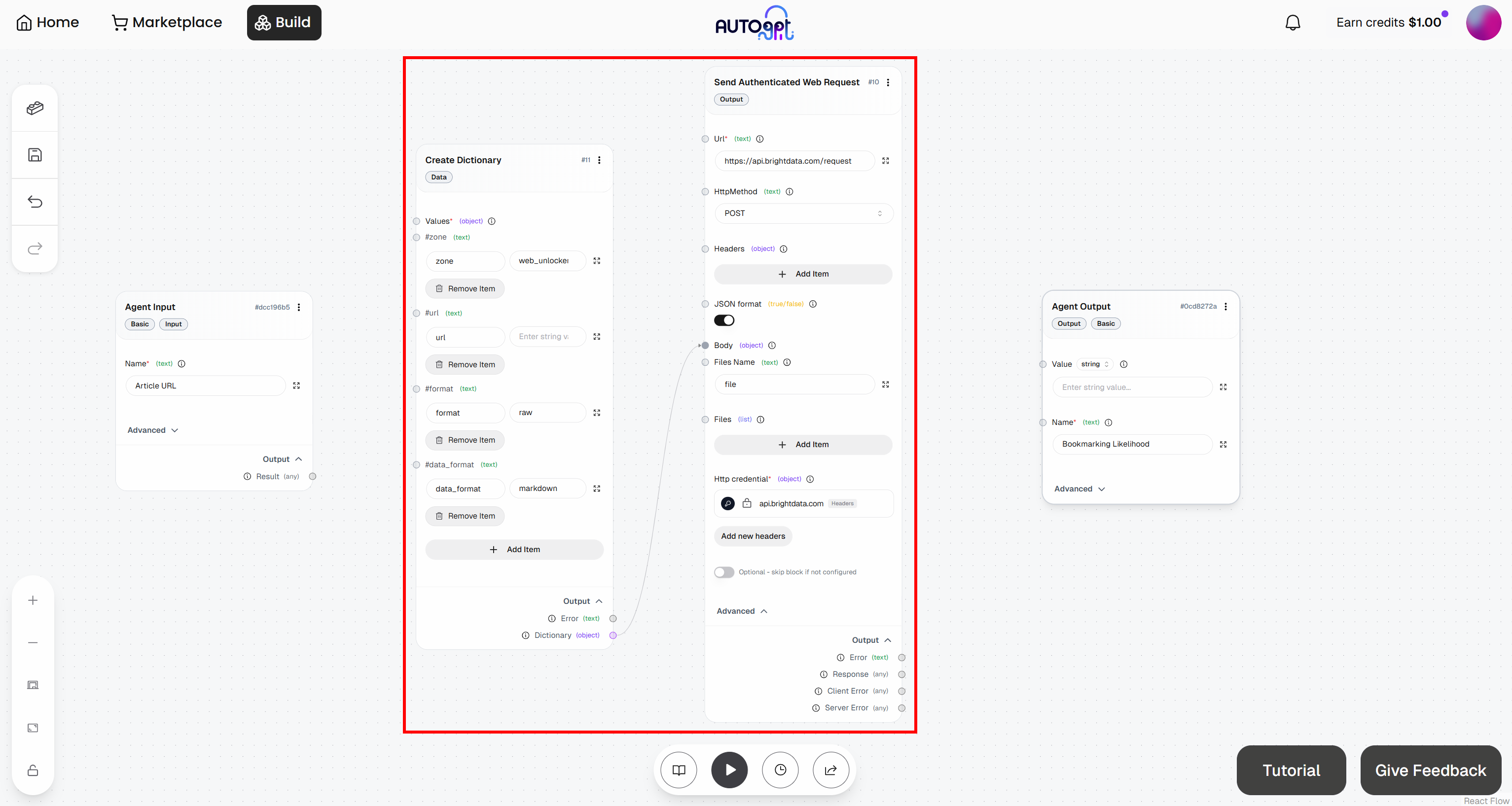
非常好!你的 AutoGPT 工作流中 Bright Data 集成现在已经完成。
步骤 #7:添加 LLM 引擎
最后缺少的 block 是 LLM 引擎:它负责分析通过 Web Unlocker API 进行网页抓取后获取到的 Markdown 内容,并给出书签评分。
由于你希望该工作流能长期评估不同文章,因此它需要输出一致且结构化的结果。
要实现这一目标,使用 “AI Structured Response Generator” block。它允许你指示 LLM 执行任务,并以预定义格式返回结果。
先把该 block 添加到工作流中: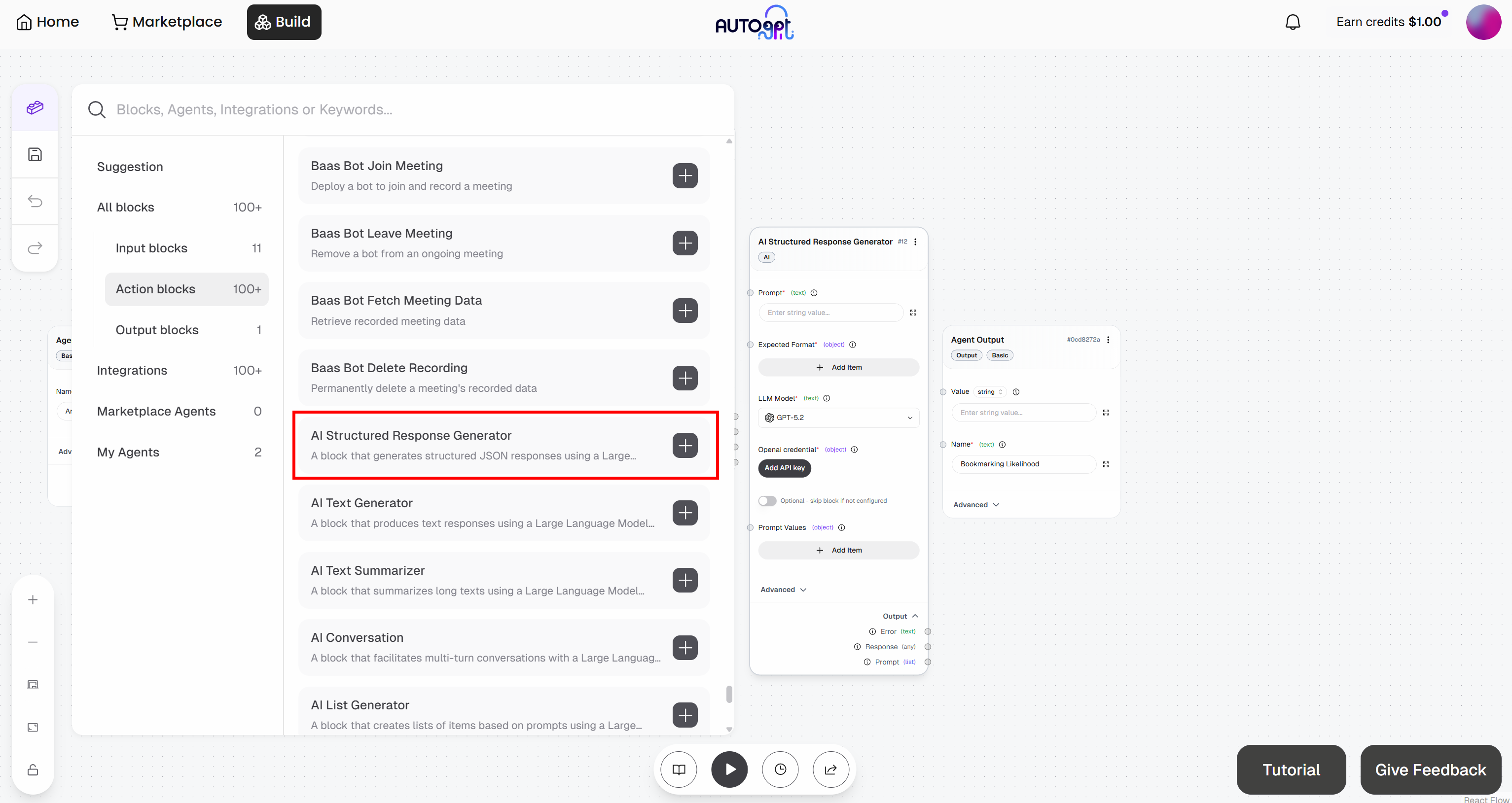
点击 “Add API Key” 按钮,将该 block 连接到你的 OpenAI 账号。为 key 命名,粘贴你的 OpenAI API key,然后点击 “Add API Key”: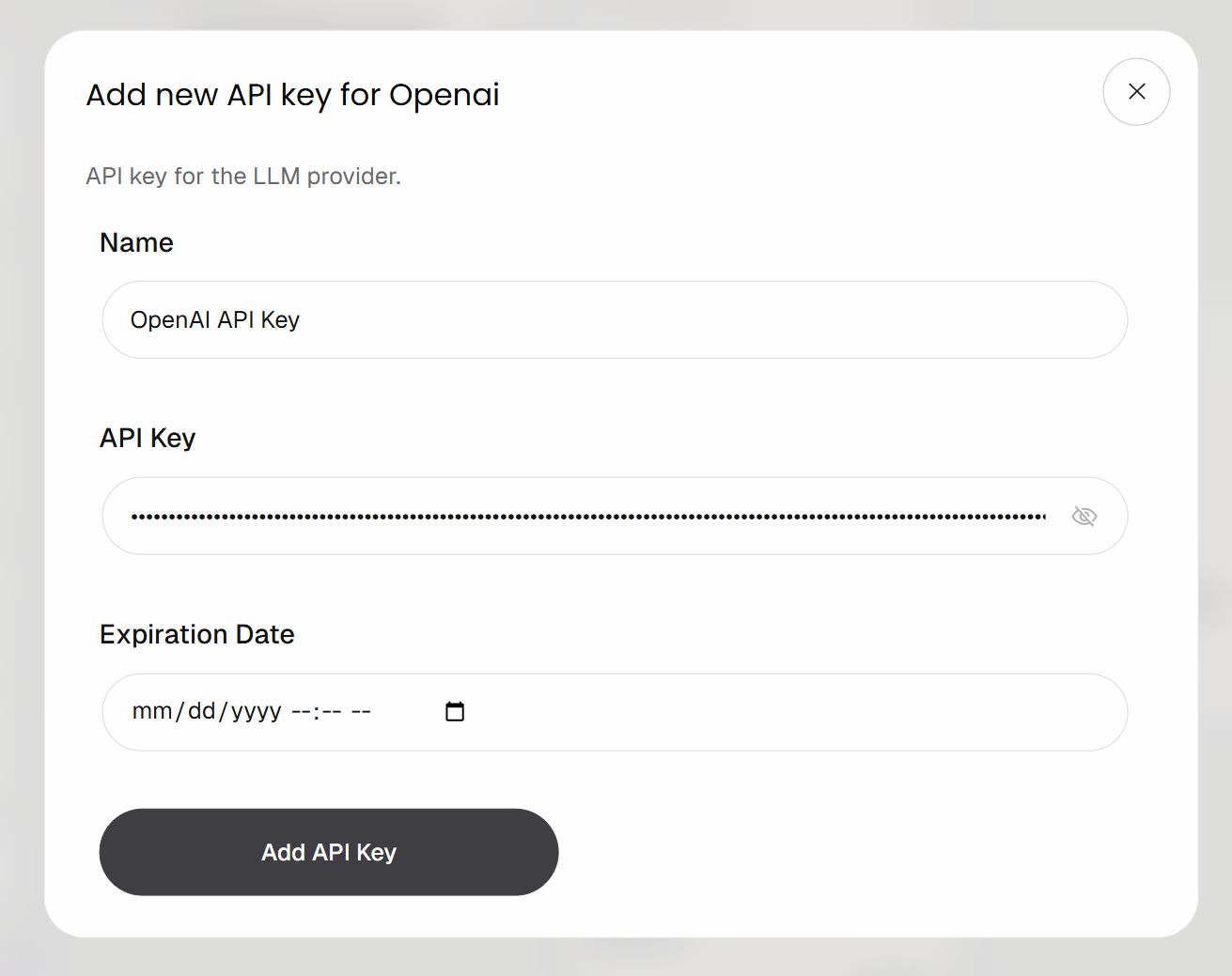
你的 “AI Structured Response Generator” block 现已完成认证,可调用已配置的 OpenAI 模型。
现在,用以下内容填充该 block:
- Prompt:
You are an expert content evaluator.
Your task is to analyze the following article and determine how worthwhile it is to bookmark for future reference.
Article:
"{{article}}"
Evaluate the article based on:
- Practical usefulness (does it provide actionable insights?)
- Depth (is it superficial or in-depth?)
- Signal-to-noise ratio (is it concise or full of fluff?)
- Reusability (is it something worth revisiting later?)
Return a JSON object with:
- "score": an integer from 1 to 10 (1 = not worth bookmarking, 10 = must bookmark)
- "comment": a concise, human-like explanation (1–2 sentences max)
Guidelines:
- Be critical and avoid overrating
- Prefer higher scores only for content with long-term value
- Avoid generic comments
- *Model*: GPT-5.1 Mini (or any other general-purpose OpenAI model)在 prompt 中,请注意 {{article}} 占位符。它是一个变量,会被动态替换为某个 “Prompt Value”。具体来说,它将被替换为 “Send Authenticated Web Request” block 返回的 Markdown 内容。
要配置 “Prompt Value”,点击 “Add item” 并定义名为 article 的变量。然后,将 “Send Authenticated Web Request” block 的 “Response” 输出连接到 article prompt value: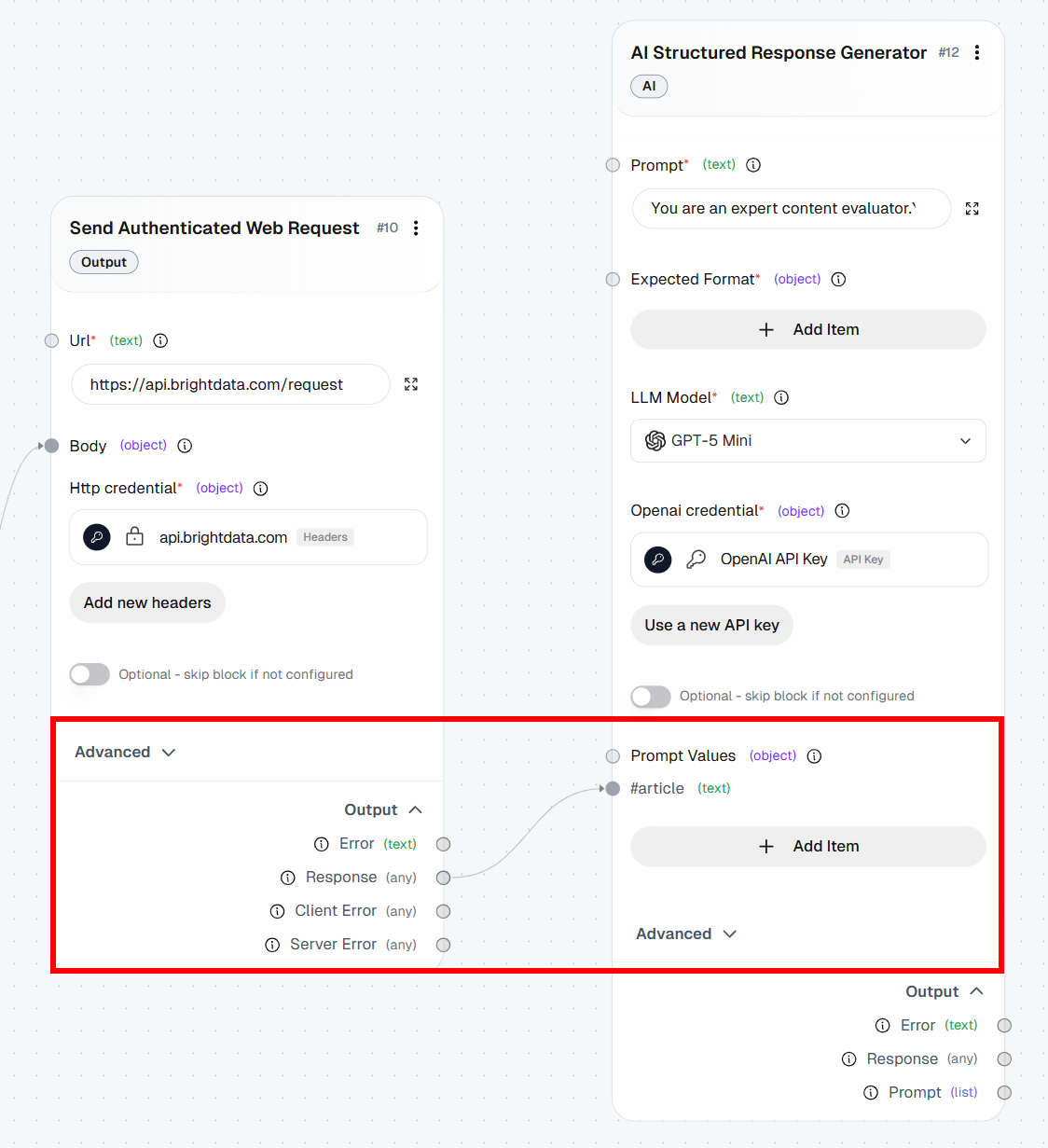
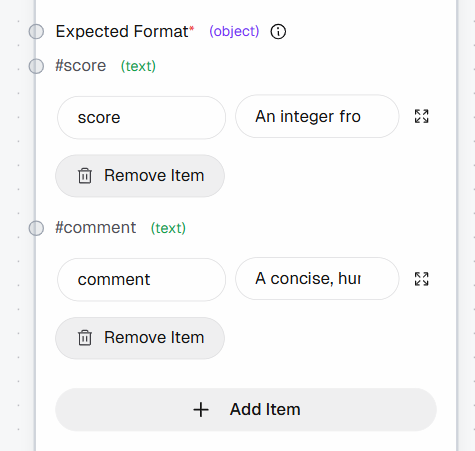
接着,在 “Expected Format” 区域添加以下字段来定义结构化输出:
score:“1 到 10 的整数(1 = 不值得加入书签,10 = 必须加入书签)”comment:“简洁、像人类的解释(最多 1–2 句)”
很好!你的 Bright Data 驱动的 AutoGPT 代理式工作流现在已包含全部 blocks。剩下只需要把它们全部连接起来。
步骤 #8:连接所有 Blocks
要完成工作流,请将所有 blocks 连接起来,形成完整流水线。
先把 “Agent Input” block 的 “Result” 输出连接到 “Create Dictionary” block 的 url 字段。这样输入 URL 就会从工作流入口流入 Web Unlocker API 请求中,由其对页面进行爬虫抓取,并把结果传给 LLM 做分析。
最后,将 “AI Structured Response Generator” block 的 “Response” 输出连接到 “Agent Output” block。这样就闭合了工作流并完成数据流转。
你的最终 AutoGPT 工作流(通过 Bright Data 获得网页抓取能力增强)应如下所示: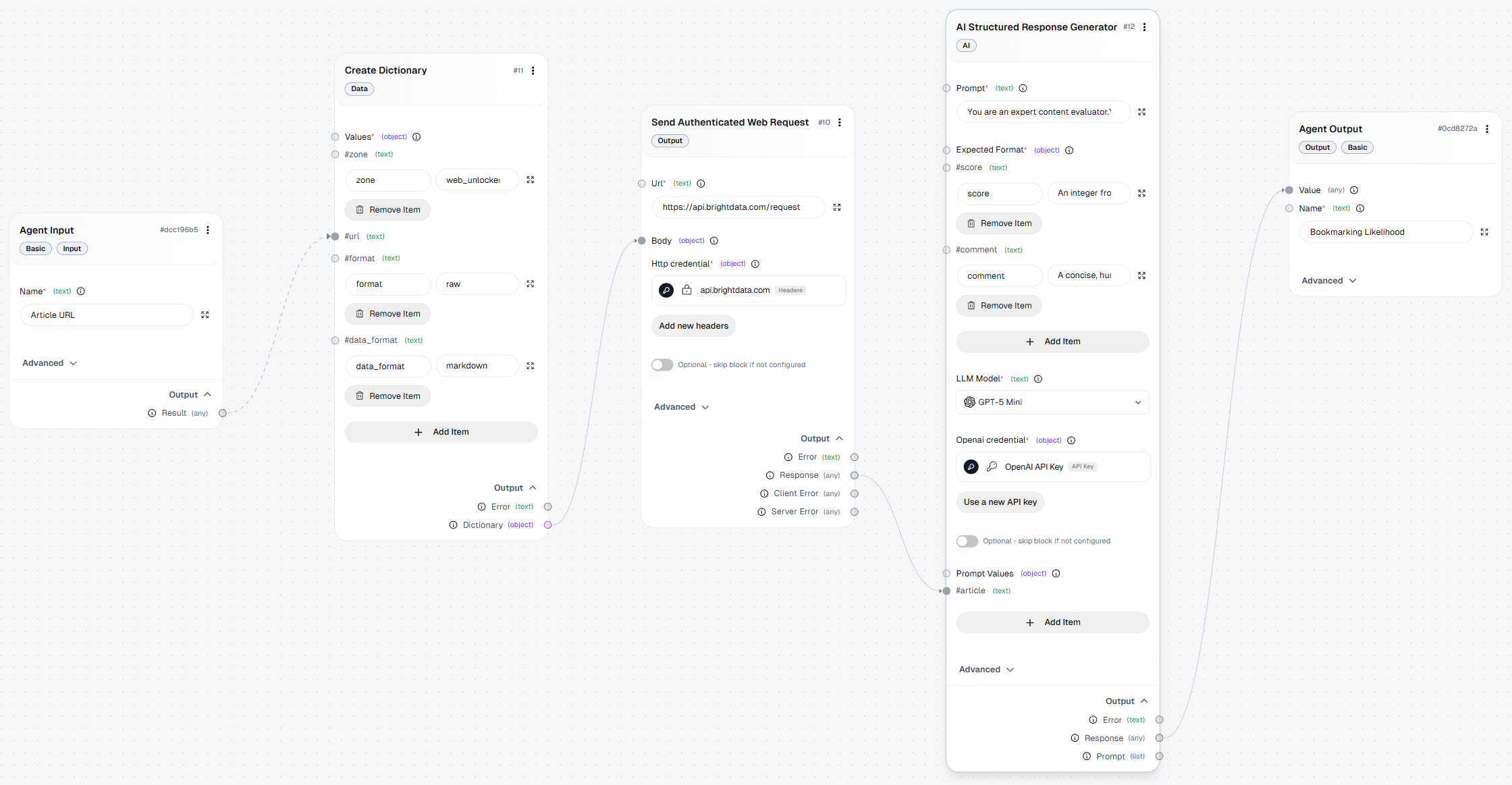
步骤 #9:测试 Agent
点击 “Run agent” 按钮启动你的代理式工作流并测试: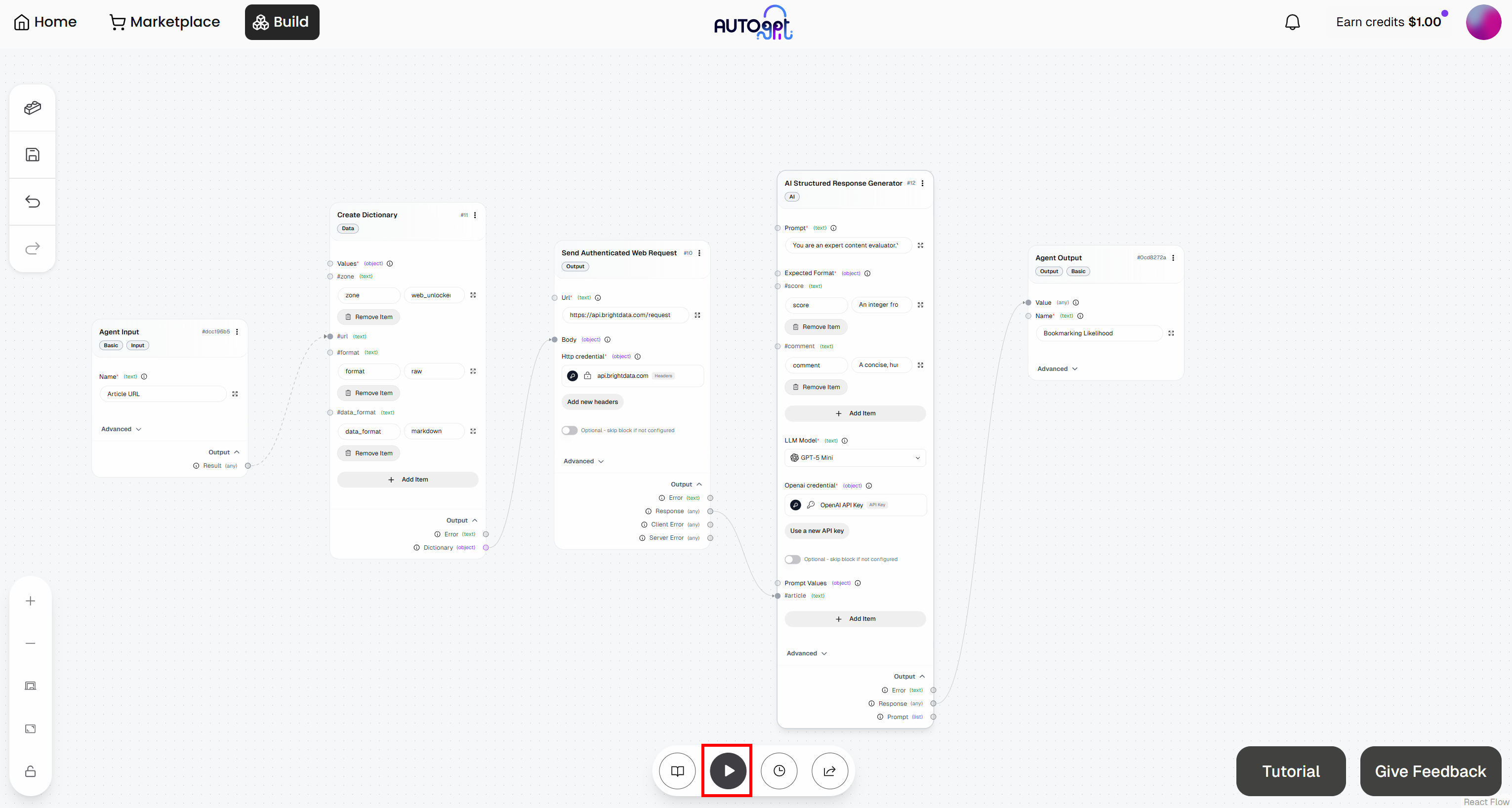
系统会提示你提供工作流输入 URL(即文章 URL)。粘贴如下博客文章链接:
https://awealthofcommonsense.com/2024/03/whats-the-investment-case-for-gold/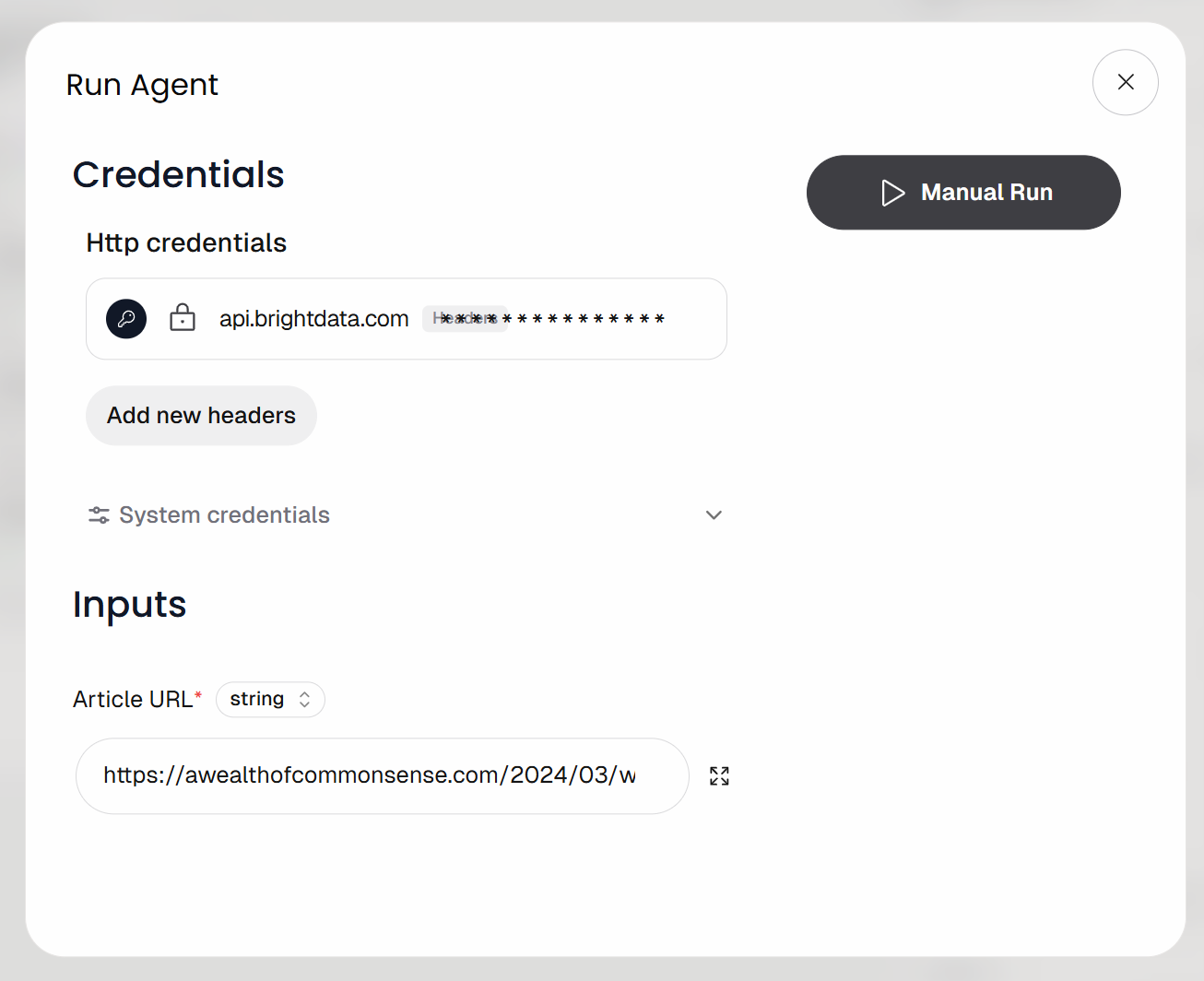
然后点击 “Manual Run” 按钮启动工作流。你应该会看到如下内容: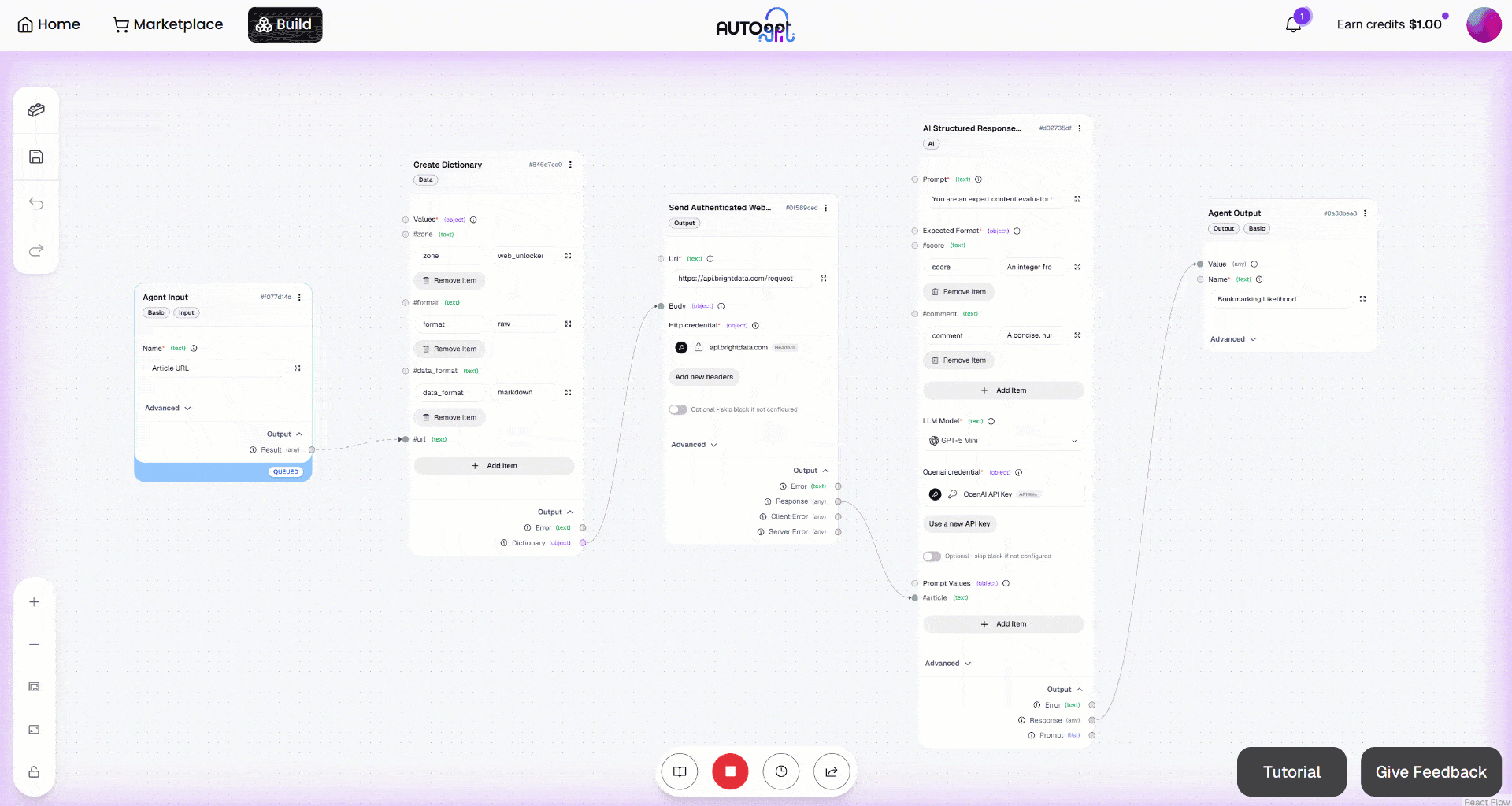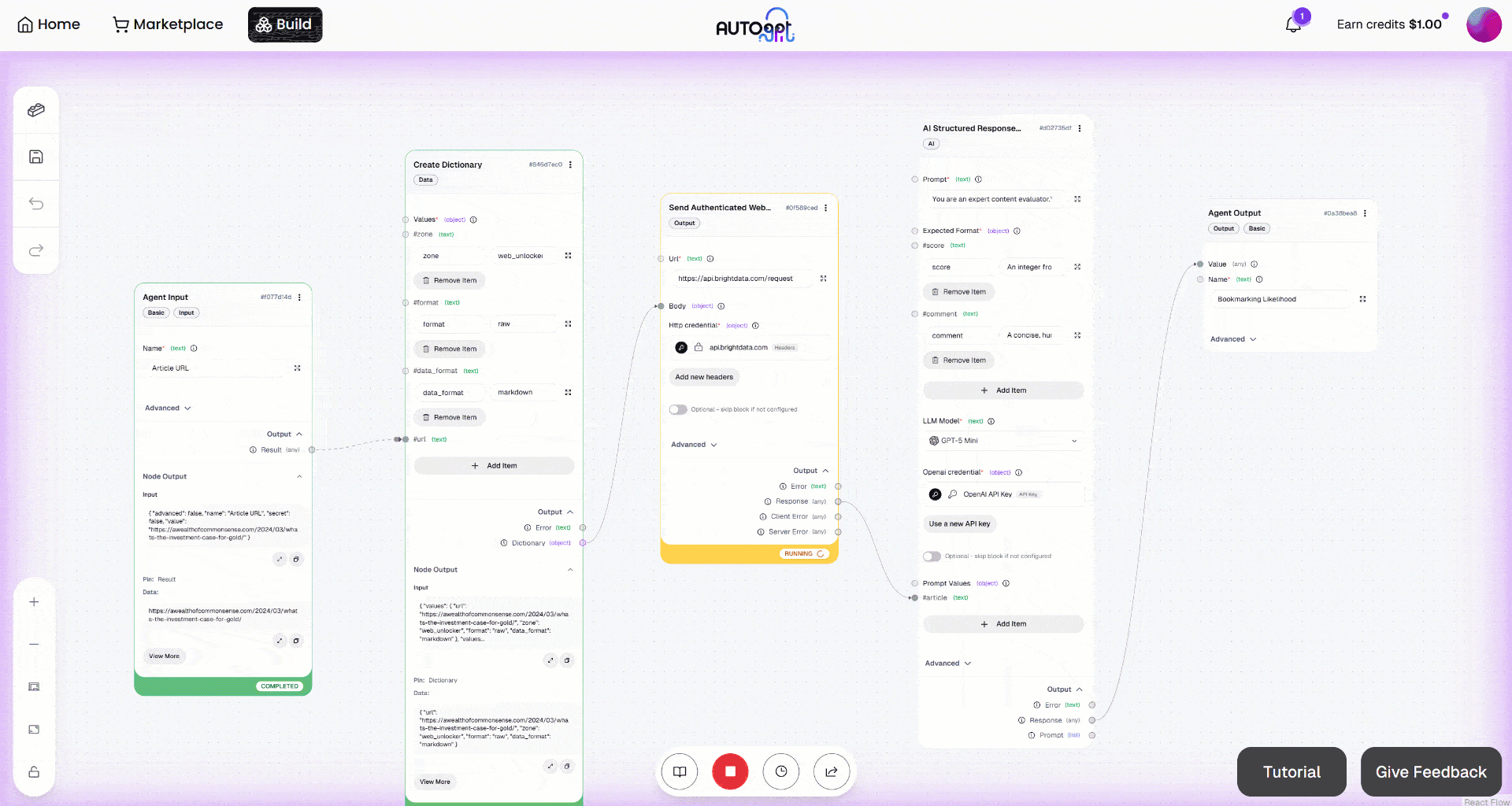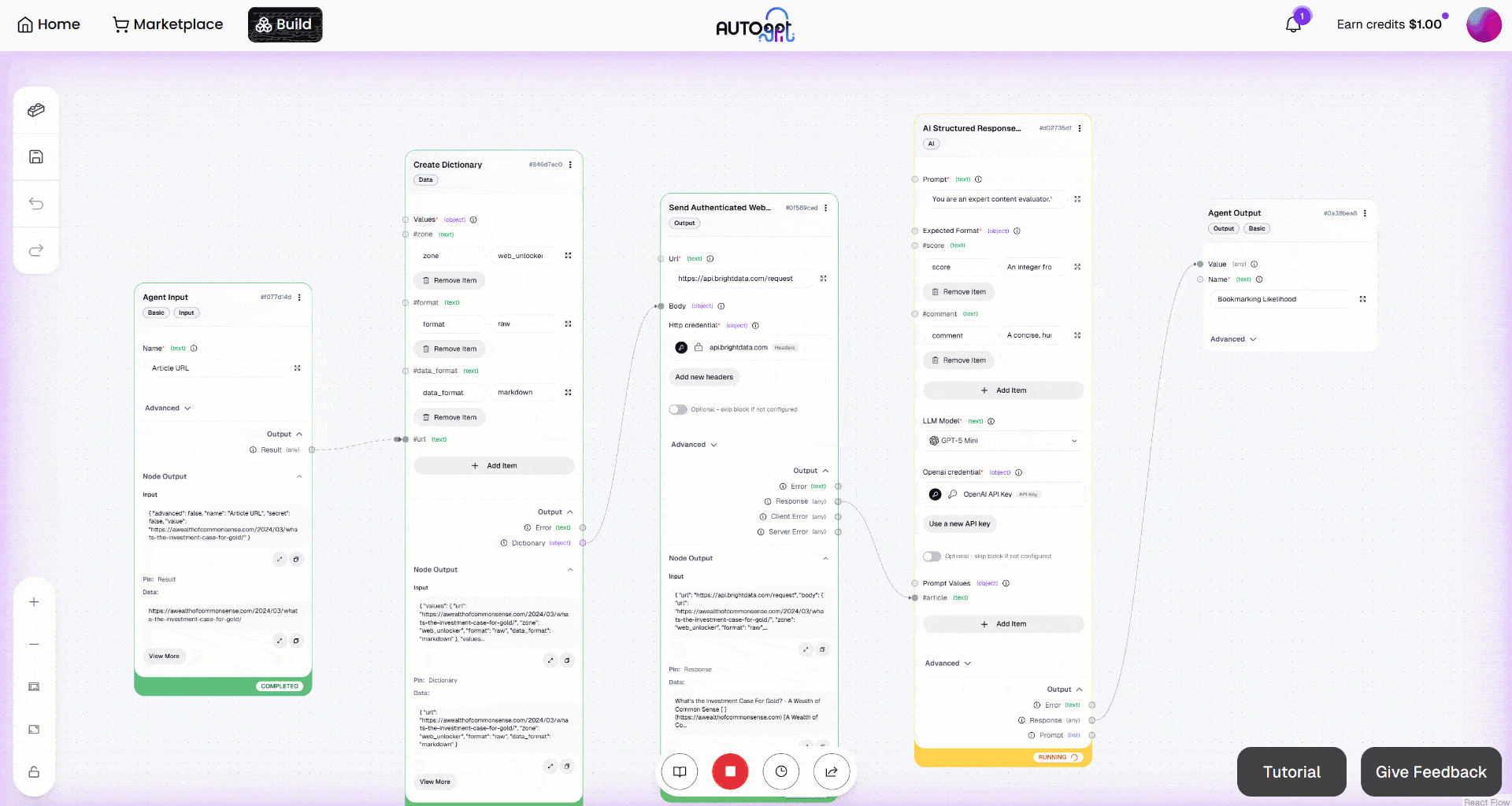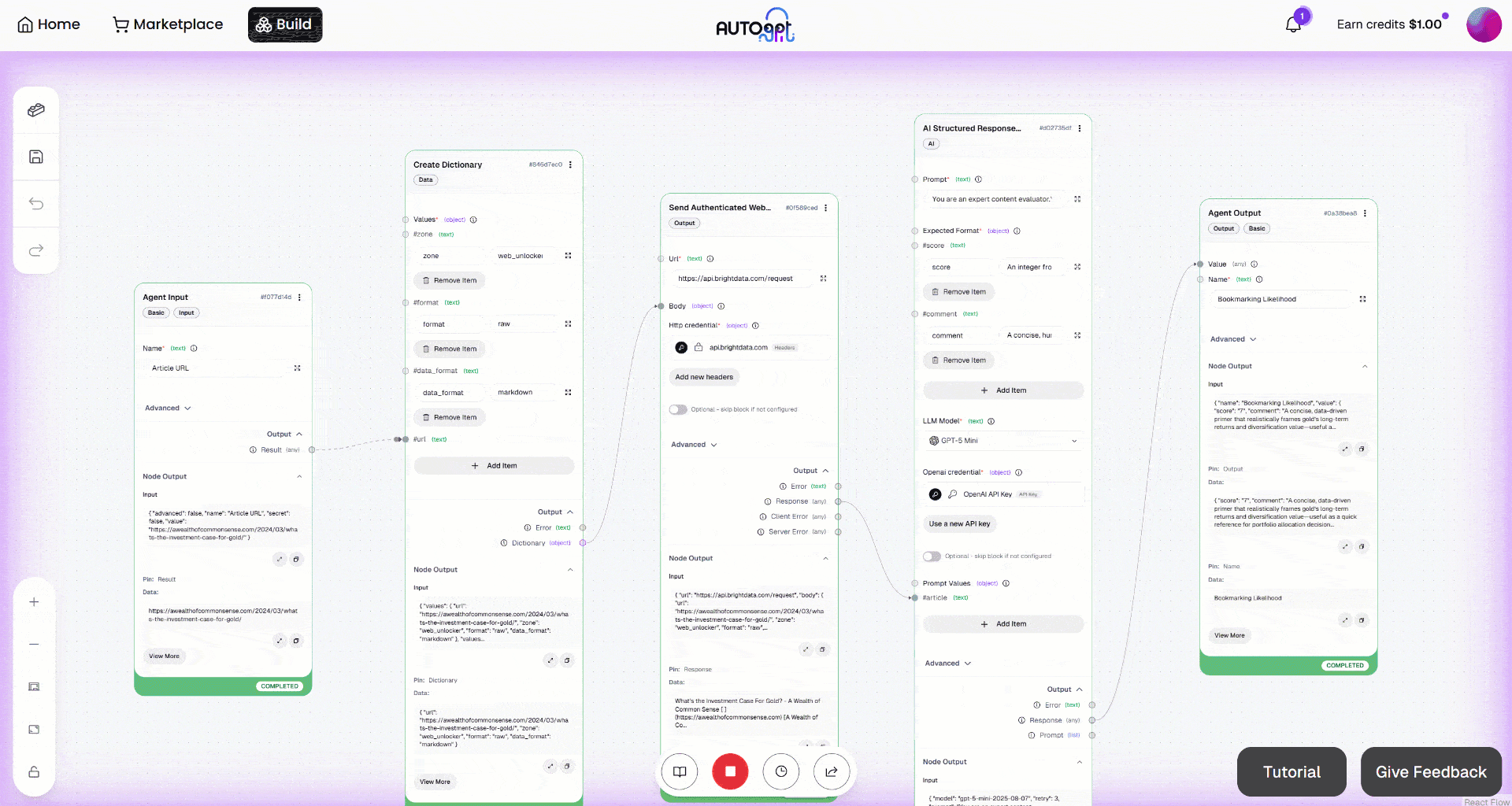
展开 “Agent Output” block 的输出。你会发现 AI agent 产生了如下结果: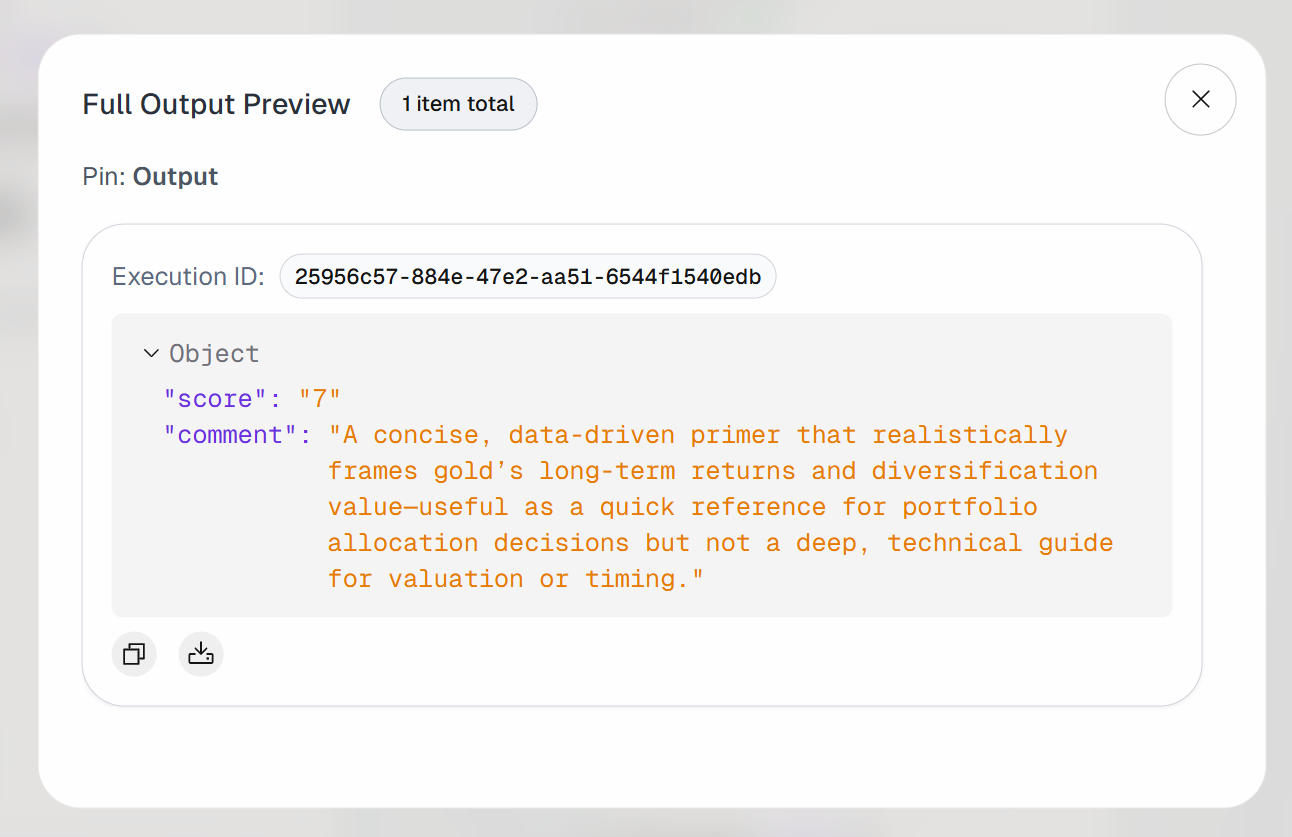
因此,这篇输入文章被认为足够有价值,值得加入书签以便未来阅读。
如果你查看 “Send Authenticated Web Request” block 的输出,你会看到: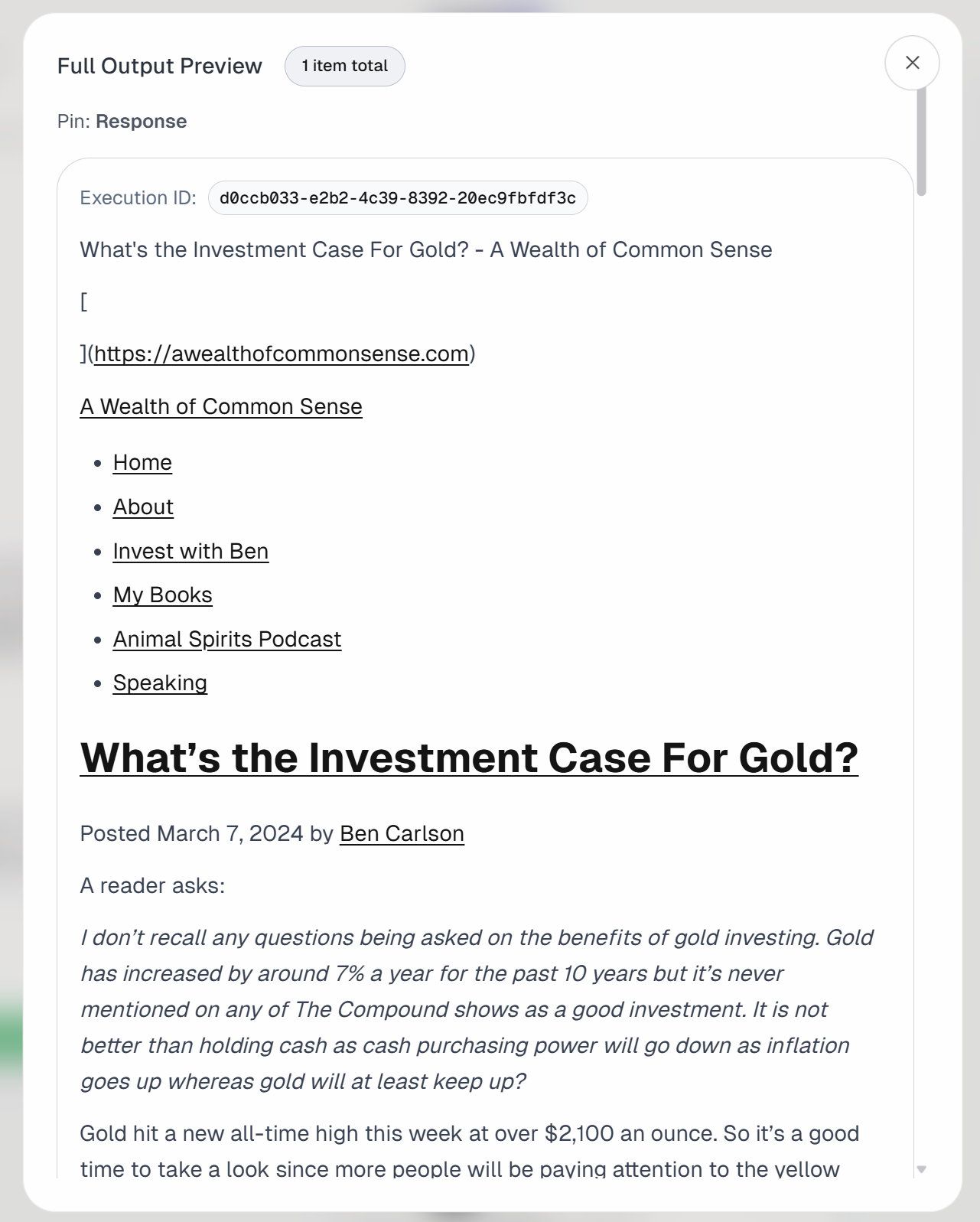
这对应于目标输入文章的 Markdown 版本: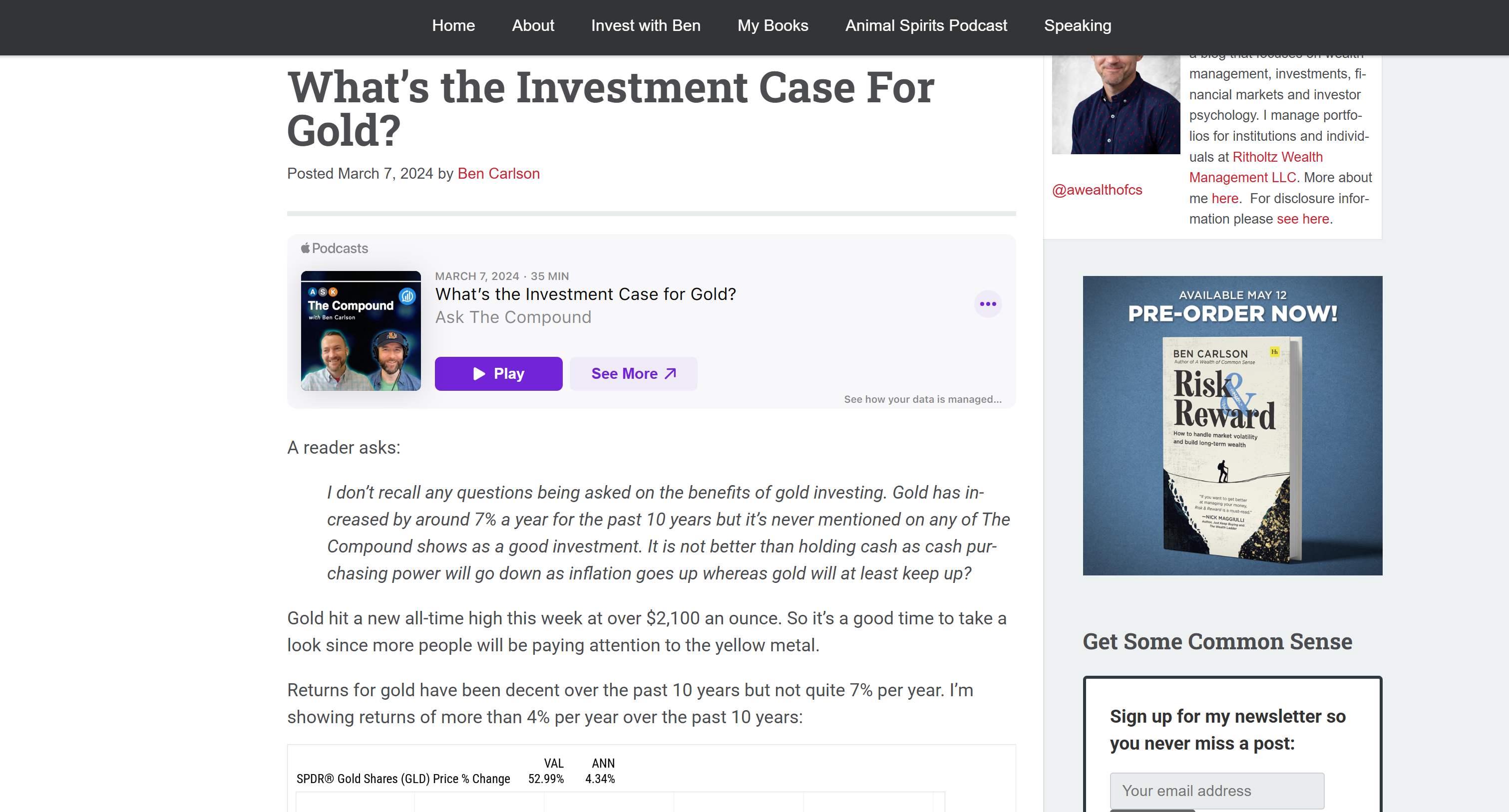
这证明 Bright Data Web Unlocker API 成功且快速地获取了页面内容,并以一种让 LLM 处理更高效、更有效的格式返回。
完成了!你刚刚在 AutoGPT 中构建了一个与 Bright Data 集成、可动态获取 Web 数据的 AI agent。
下一步
这只是一个简单示例,但请记住,AutoGPT + Bright Data 的集成可以扩展以支持更高级的代理式工作流。
例如,使用类似方法,你可以把 agent 连接到其他基于 Bright Data API 的产品,为其添加网页搜索与爬虫抓取能力。同样,你也可以集成能够从多个领域提供直接数据馈送的爬虫 API。
为了让你的 agent 更强大,请通过阅读官方文档探索 AutoGPT 提供的广泛能力。
结论
在这篇博客中,你学习了如何将 Bright Data 的网页探索、交互、搜索,以及数据抓取/爬虫能力添加到 AutoGPT 中。这使 AI agents 能够突破标准 LLM 常见的知识与交互限制。
你还看到如何构建一个简单的书签建议 AI agent。若要创建更复杂的代理式工作流——需要访问实时 Web 数据源、网页搜索或 Web 交互——请将 AutoGPT 与面向 AI 的 Bright Data 全套服务进行集成。
立即免费创建 Bright Data 账号,开始试用我们面向 AI 的 Web 数据解决方案吧!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




