
在本指南中,您将了解:
- 什么是 Langflow,以及它为何如此流行。
- 在 Langflow 应用中使用标准大模型的局限,以及如何通过外部数据来克服这些限制。
- 如何构建一个集成了 Bright Data 网络数据访问的 Langflow AI 应用。
让我们开始吧!
什么是 Langflow?
Langflow 是一个用 Python 和 JavaScript 构建的开源工具,用于创建和部署 AI 驱动的代理和工作流。在 GitHub 上拥有超过 92k 的星标,它是最受欢迎且广泛采用的AI 代理开发库之一。
Langflow 作为一个低代码可视化开发平台,让您仅通过拖拽预构建组件即可创建复杂的 AI 应用,几乎无需大量编码。同时,它也支持自定义代码集成,以获得最大的灵活性。
Langflow 提供了丰富的 AI 功能,包括代理(agents)、大模型(LLMs)、向量存储,以及与任何 API、模型或数据库的集成。
为何 AI 应用需要数据访问
相比其他框架,Langflow 以可视化低代码构建 AI 应用而脱颖而出。但正如任何基于大模型的系统一样,Langflow 应用的“智能”程度取决于它能访问到的数据。
大模型是在静态数据集上训练的,对实时事件或私有业务数据没有内置感知。除非您将它们与新的、相关的数据源连接,否则它们与现实世界是隔离的。而网络是最广泛的信息来源。
为了解决大模型的这些限制,Langflow 允许您连接灵活的网络数据管道。这种模式在以下重要场景中非常基础:
然而,要从网络上可靠地获取准确的公开数据并非易事。您需要具备以下能力的基础设施:
- 几乎可以连接到任何网站(即使受到反爬虫技术保护)。
- 可靠地提取所需数据。
- 以结构化、AI 可用的格式返回数据。
这正是Bright Data 所提供的。将 Langflow 与 Bright Data 工具结合,您的 AI 应用将具备强大功能,包括:
- 实时网络爬取,同时绕过反机器人防护。
- 从 Amazon、LinkedIn、Zillow 等一流平台中结构化地提取数据。
- 获取搜索引擎结果,提供实时、基于查询的 SERP 数据。
- 通过自动化全页截图实现可视化数据捕获。
您可以通过自定义 Langflow 组件直接连接到 Bright Data,无需自己构建或维护复杂的后端逻辑。只要将组件接入您的流程,便可立即使用!
使用 Bright Data 在 Langflow 中构建具有网络数据访问的 AI 应用
在本分步教程中,您将使用 Langflow 构建一个 AI 代理,通过与 Bright Data 集成来检索实时网络数据。
请注意,此处展示的 AI 代理示例只是整合后的一个简单示例。基于 Bright Data × Langflow 集成,您可以构建无数其他 AI 应用。如需灵感,请查看我们的可能用例列表。
请按以下指南操作,创建一个基于 Bright Data 的 Langflow AI 代理!
前提条件
要按照本教程操作,请确保满足以下要求:
- 至少双核 CPU 和 2 GB 内存(推荐:多核 CPU 和至少 4 GB 内存)。
- 本地安装 Python 3.10 至 3.12(Windows)或 3.10 至 3.13(macOS/Linux)。
- 本地安装了
uv包。 - 一把 Bright Data API 密钥。
- 用于连接任一支持的大模型的 API 密钥(本文示例使用 Google Gemini,可免费通过 API 使用)。
如果您还没有 Bright Data API 密钥,不必担心,本教程会引导您完成设置。
要安装 uv,请运行:
pip install uv如果您是 Windows 用户,还需要 Microsoft Visual C++ 14.0 或更高版本。下载并按照官方安装指南完成安装。
步骤 1:设置 Langflow
首先,为您的 Langflow 项目创建一个文件夹并进入:
mkdir langflow-agent
cd langflow-agentlangflow-agent 文件夹将作为您的项目目录。
在项目目录中,使用 uv 创建一个 Python 虚拟环境:
uv venv venv然后,在 macOS/Linux 上激活:
source venv/bin/activate在 Windows 上运行:
venvScriptsactivate激活虚拟环境后,在项目环境中安装 Langflow:
uv pip install langflow安装完成后,运行以下命令验证设置:
uv run langflow run等待 Langflow 启动本地服务器。准备就绪后,浏览器中访问:
http://localhost:7860打开该页面,如果一切正常且是您首次使用 Langflow,将看到如下界面:
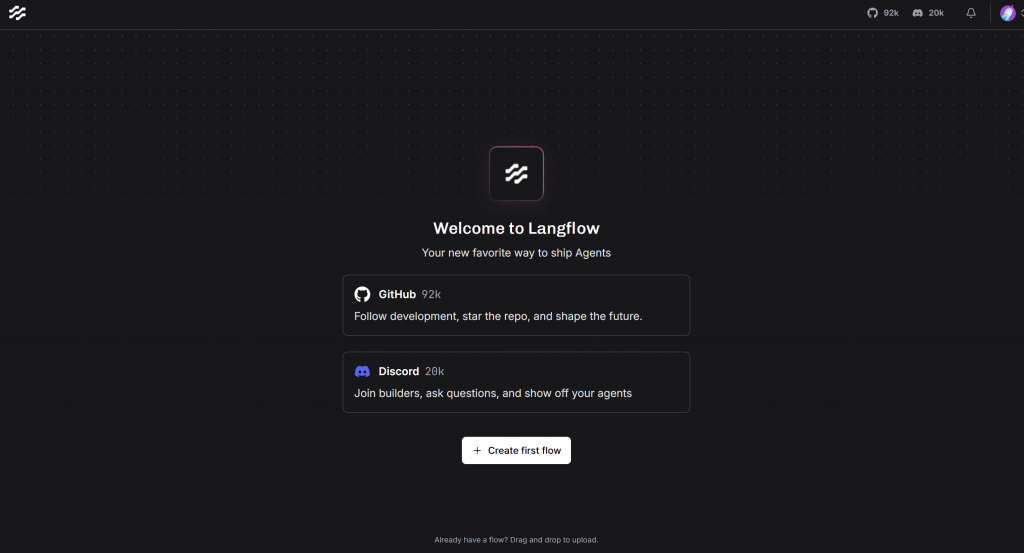
如遇错误,请参考官方安装指南。
太棒了!您的 Langflow 环境已成功搭建。
步骤 2:配置 Bright Data
要让您的 AI 应用具备从网络获取数据的能力,需要将其连接到Bright Data 的 AI 基础设施。
Bright Data 提供多种数据采集解决方案,本教程聚焦于:
- Web Unlocker:一款高级爬虫 API,可绕过防护并以 HTML 或 Markdown 格式返回任何网页。
注:也可集成其他 Bright Data 工具(如 Web Scraper APIs),本指南重点介绍通用的 Web Unlocker。
在 Langflow 应用中使用 Web Unlocker,需完成:
- 在 Bright Data 账户中创建 Web Unlocker 区域(zone)。
- 生成 Bright Data API 令牌以进行身份验证。
请按下文操作,并参考官方文档。
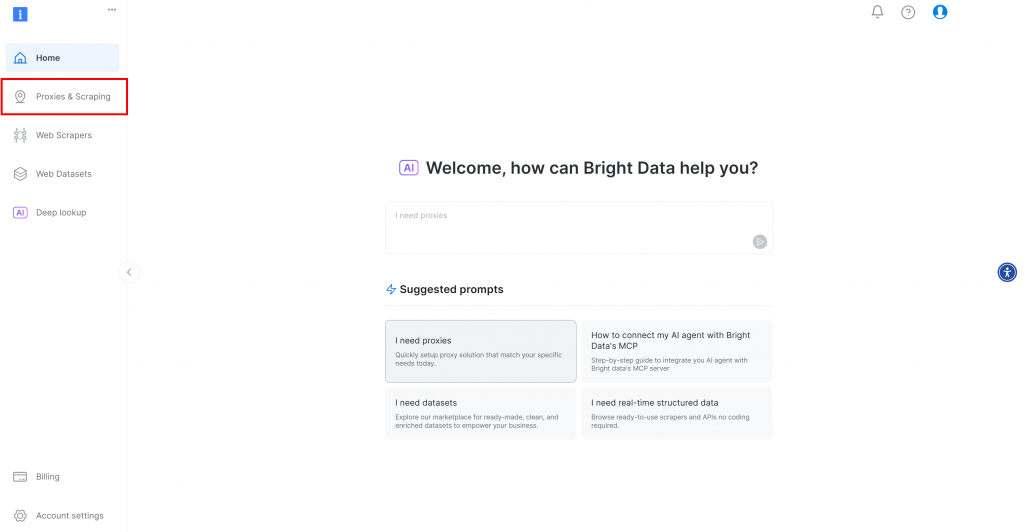
如果您尚无 Bright Data 账号,免费注册;已有账号则登录并打开控制面板,点击“Proxies & Scraping”按钮:
进入“Proxies & Scraping Infrastructure”页面:
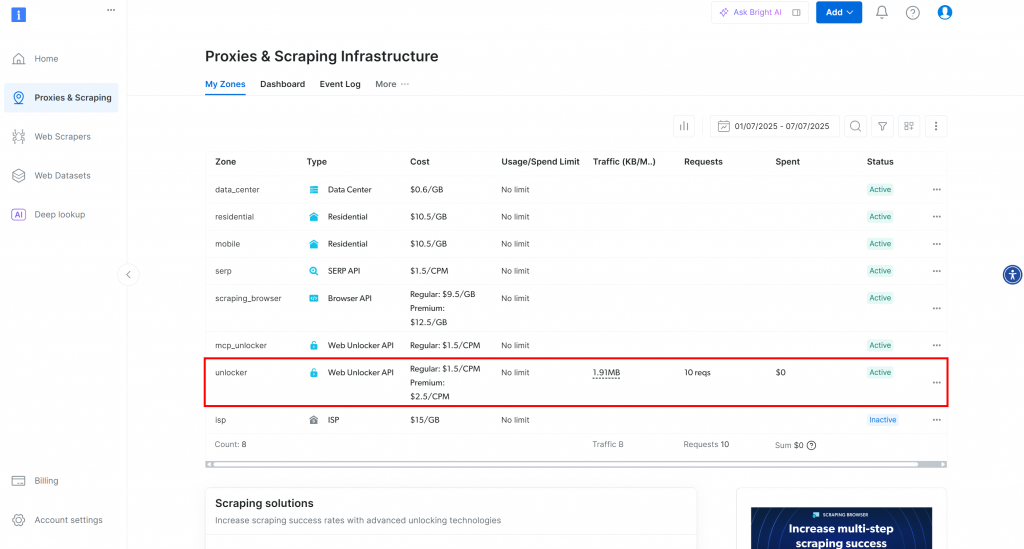
若已有 Web Unlocker 区域,会在此列出。本例中已存在名为 “unblocker” 的区域(请记住此名称,后续会用到)。
若尚未创建区域,向下滚动至 “Web Unlocker API” 卡片,点击“Create zone”:
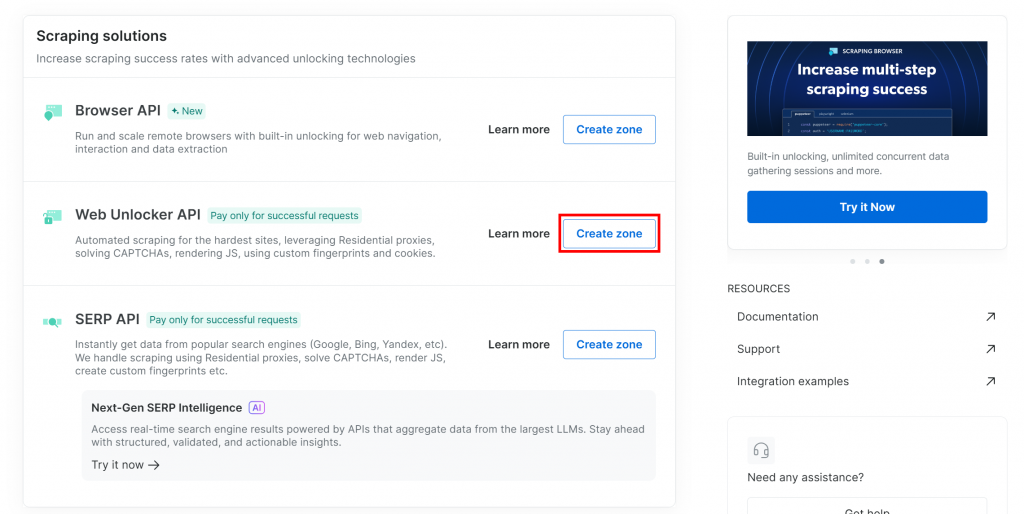
为区域命名(例如 “unlocker”),启用高级功能以获得最佳性能,然后点击“Add”:
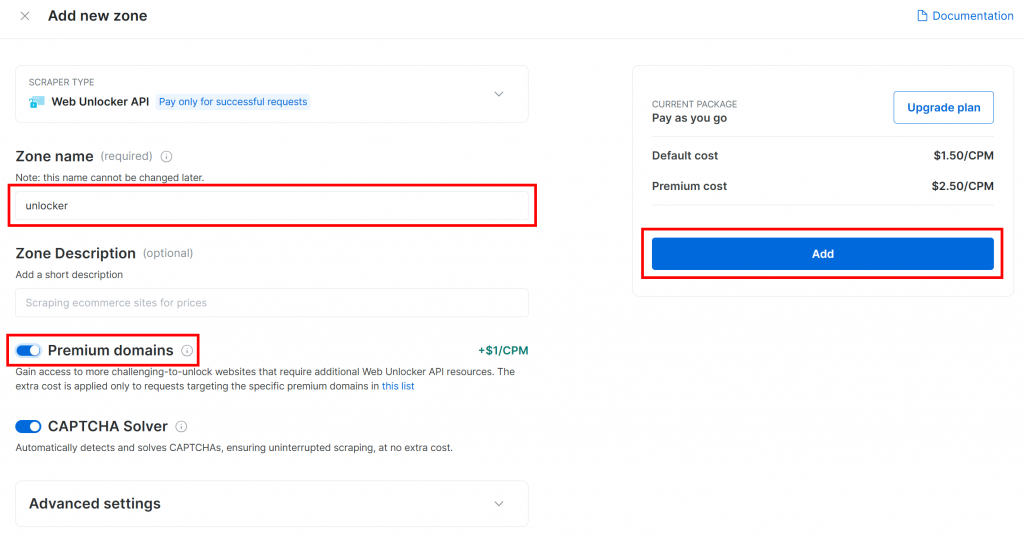
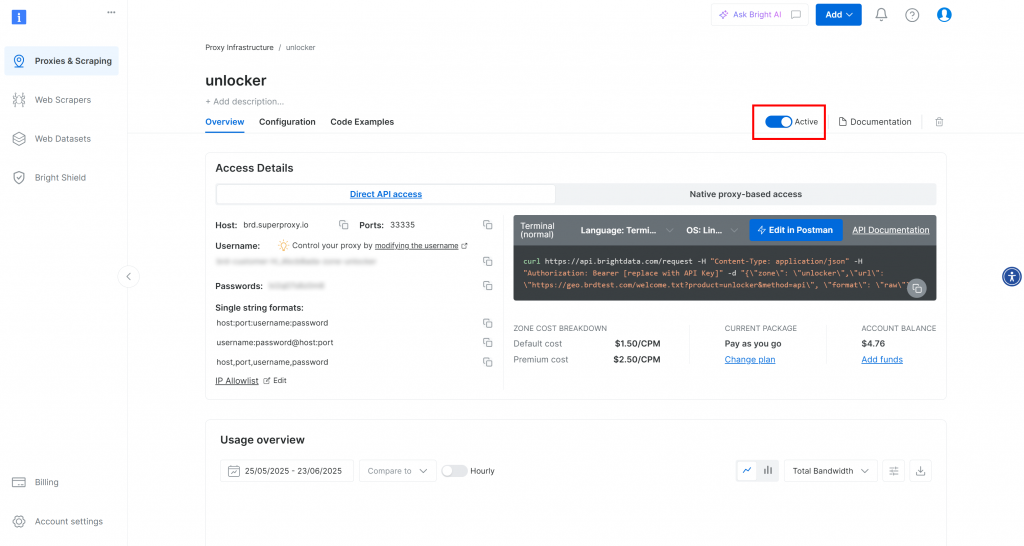
创建完成后会进入区域详情页,确保开关处于“Active”状态,表示已可使用:
接着,按照官方文档生成 API 密钥,妥善保存,待会会用到。
完美!现在您已准备好通过自定义组件将 Bright Data 集成到 Langflow。
步骤 3:初始化新的空白 Flow
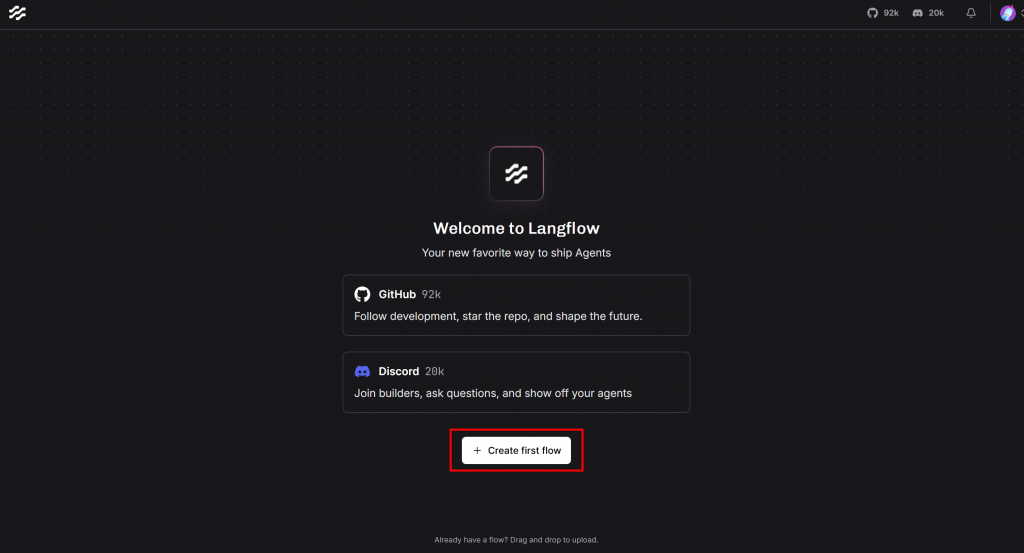
在继续之前,需在 Langflow 中创建一个新 Flow。回到本地服务器,点击“Create first flow”按钮:
在弹出的对话框中,点击右下角的“Blank Flow”:
为您的 Flow 命名,例如 “Langflow x Bright Data AI App”,创建后将看到如下空白画布:
接下来,您将在此画布上添加并连接组件,以定义您的 AI 应用。
步骤 4:定义自定义 Bright Data 组件
在 Langflow 中集成 Bright Data 最简便的方式是创建自定义组件,让 AI 代理可使用 Bright Data 的 Web Unlocker API 抓取网络数据。
在 Langflow 中,自定义组件由 Python 类定义,包括:
- Inputs:组件所需的输入数据或参数。
- Outputs:组件返回给下游节点的数据。
- Logic:将输入转化为输出的内部处理逻辑。
您的 Langflow × Bright Data 自定义组件应当:
- 接受您的 Bright Data API 密钥和 Web Unlocker 区域名称作为输入(用于身份验证)。
- 接收您要抓取的目标网页 URL。
- 向 Web Unlocker API 发起请求,配置为以 Markdown 格式返回页面内容(这是一种 非常适合 AI 消费 的格式)。
- 将检索到的内容作为输出返回。
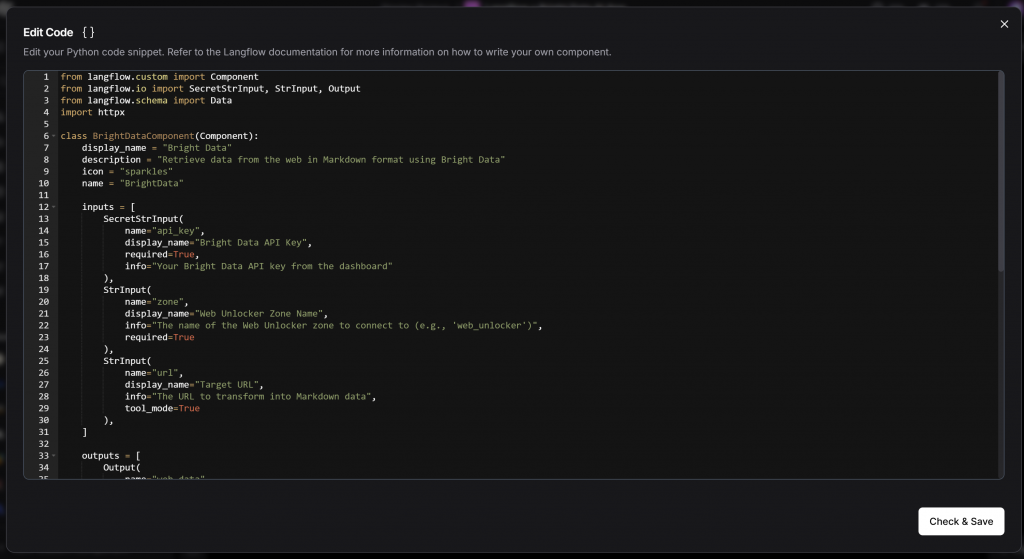
您可使用以下自定义 Python 组件实现上述功能(保持原有代码不变):
from langflow.custom import Component
from langflow.io import SecretStrInput, StrInput, Output
from langflow.schema import Data
import httpx
# A Langflow custom component must extend Component
class BrightDataComponent(Component):
# The component name shown in the Langflow UI
display_name = "Bright Data"
# The description in the component details
description = "Retrieve data from the web in Markdown format using Bright Data"
icon = "sparkles" # UI icon identifier
name = "BrightData" # Internal name used by Langflow
# --- INPUTS ---
# Define the inputs required by the component
inputs = [
SecretStrInput(
name="api_key",
display_name="Bright Data API Key",
required=True,
info="Your Bright Data API key from the dashboard"
),
StrInput(
name="zone",
display_name="Web Unlocker Zone Name",
info="The name of the Web Unlocker zone to connect to (e.g., 'web_unlocker')",
required=True
),
StrInput(
name="url",
display_name="Target URL",
info="The URL to transform into Markdown data",
tool_mode=True
),
]
# --- OUTPUT ---
# Define the output returned by the component
outputs = [
Output(
name="web_data",
display_name="Web Data Result",
method="get_web_data" # The name of the method used to generate the output
)
]
# --- LOGIC ---
# This method retrieves web data from Bright Data and returns it
def get_web_data(self) -> Data:
try:
# Bright Data Web Unlocker API endpoint
url = "https://api.brightdata.com/request"
# Request headers including API key for authentication
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
# Payload specifying the zone, URL, and output format
payload = {
"zone": self.zone,
"url": self.url,
"format": "raw",
"data_format": "markdown"
}
# Send the POST request with a 180-second timeout
with httpx.Client(timeout=180.0) as client:
response = client.post(url, json=payload, headers=headers)
# Raise an error if HTTP status code is not 2xx
response.raise_for_status()
# Extract contains the Markdown-formatted web data
markdown_data = response.text
return Data(data={"data": markdown_data})
# Handle timeout errors
except httpx.TimeoutException:
error_msg = "The Web Unlocker request timed out"
return Data(data={"error": error_msg, "data": None})
# Handle other HTTP errors (e.g., 4xx, 5xx)
except httpx.HTTPStatusError as e:
error_msg = f"Request failed with status {e.response.status_code}: {e.response.text}"
return Data(data={"error": error_msg, "data": None})该 BrightDataComponent 具有以下输入:
- 您的 Bright Data API 密钥。
- Web Unlocker 区域名称。
- 需要抓取的网页 URL。
组件使用 HTTPX 客户端向 Web Unlocker API 发送请求,配置为以 Markdown 格式返回响应,并将该 Markdown 内容作为输出。
注:我们选用 HTTPX,因为它是 Langflow 默认可用的 HTTP 客户端库。如需更多信息,可阅读我们的HTTPX 网络爬虫指南。
太好了!接下来学习如何将此组件添加到您的 Flow 中,并让 AI 代理使用它的输出。
步骤 5:添加自定义 Bright Data 组件
要注册刚才定义的组件,在左下角点击“New Custom Component”按钮。画布上会出现一个通用的 “Hello, World” 自定义组件。将鼠标移到它上方,点击“Code”部分以编辑逻辑:
在弹出的代码编辑器中,粘贴完整的 BrightDataComponent 类源代码:
点击“Check & Save”按钮。此时,原有的通用“Custom Component”将被您的 Bright Data 组件替换:
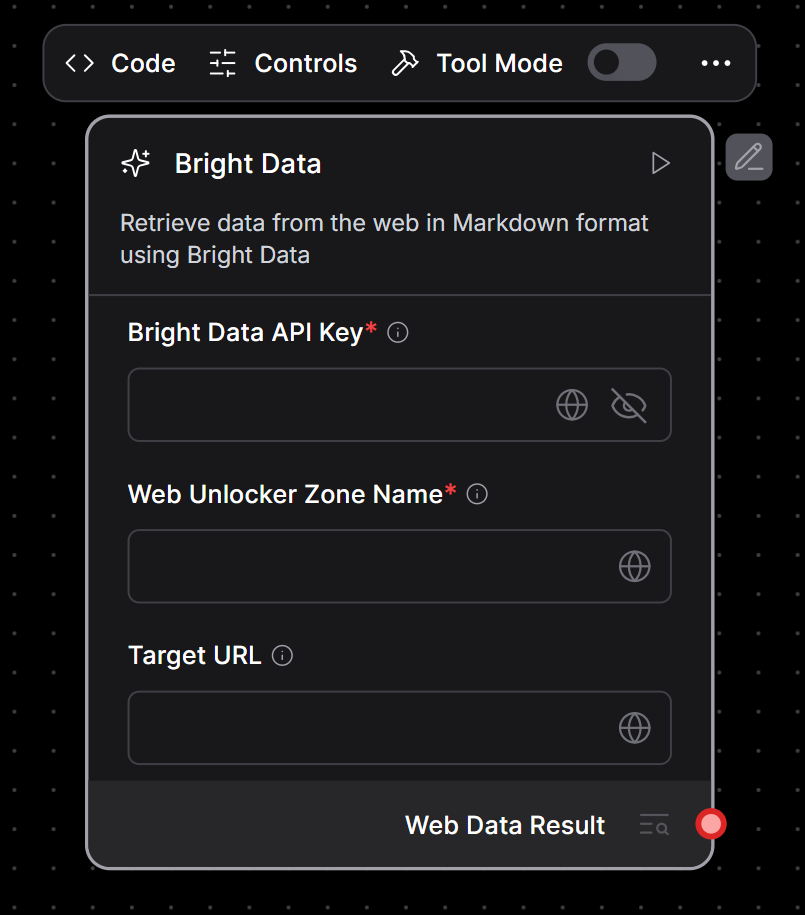
如您所见,画布上的占位组件已更新为用于 Bright Data 集成的定制组件。
注:无需在每个 Flow 中手动重建 Bright Data 组件。只需将组件代码保存在 Python 文件中,并按照Langflow 文档所述自动加载即可。
太棒了!您的 AI 流程现已可通过 Bright Data 获取网页数据。
步骤 6:将 AI 代理与 Bright Data 连接
您可以将 Bright Data 组件直接嵌入 Langflow 应用,也可将其转为 AI 代理可调用的工具(Tool)。这样,代理便能以 AI 友好的 Markdown 格式抓取任何网页的实时内容。
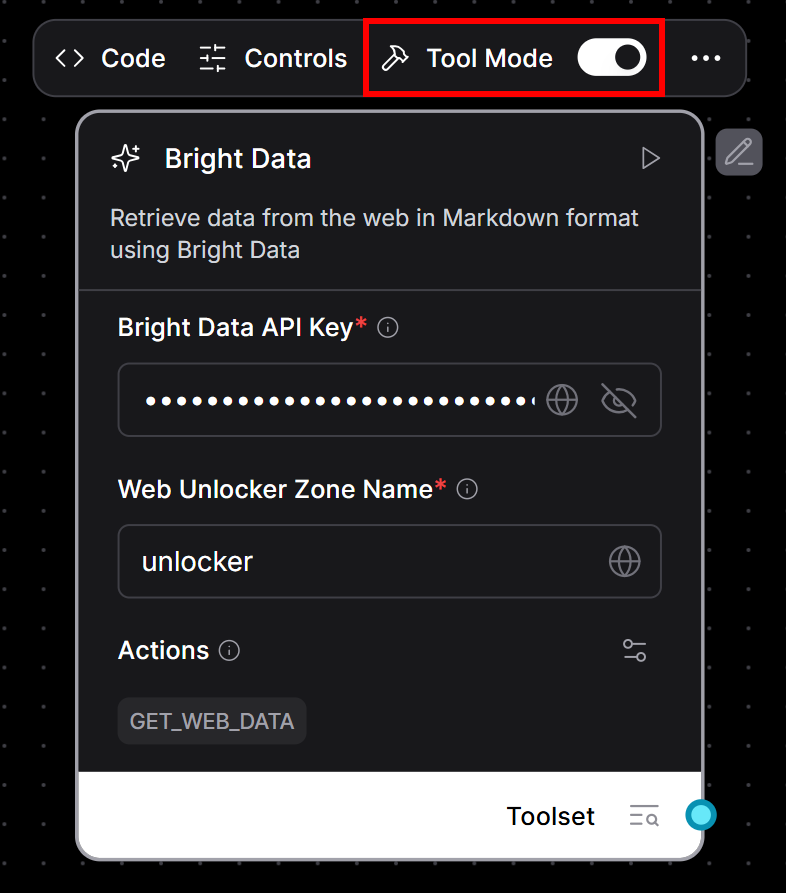
要将 Bright Data 组件设为工具:
- 将鼠标悬停在 Bright Data 组件上。
- 切换“Tool Mode”开关以启用。
- 填写以下必填字段:
- 您的 Bright Data API 密钥。
- Web Unlocker 区域名称(如
“unlocker”)。
页面应呈现如下状态:
接着,将该工具连接到 AI 代理:
- 在左侧栏找到“Agents > Agent”组件。
- 将其拖入画布。
- 配置代理使用您偏好的大模型(本示例使用 Gemini,选用免费模型
gemini-2.5-flash,并填写Gemini API 密钥)。 - 将 Bright Data 组件的输出连接到 Agent 组件的 “Tools” 输入:
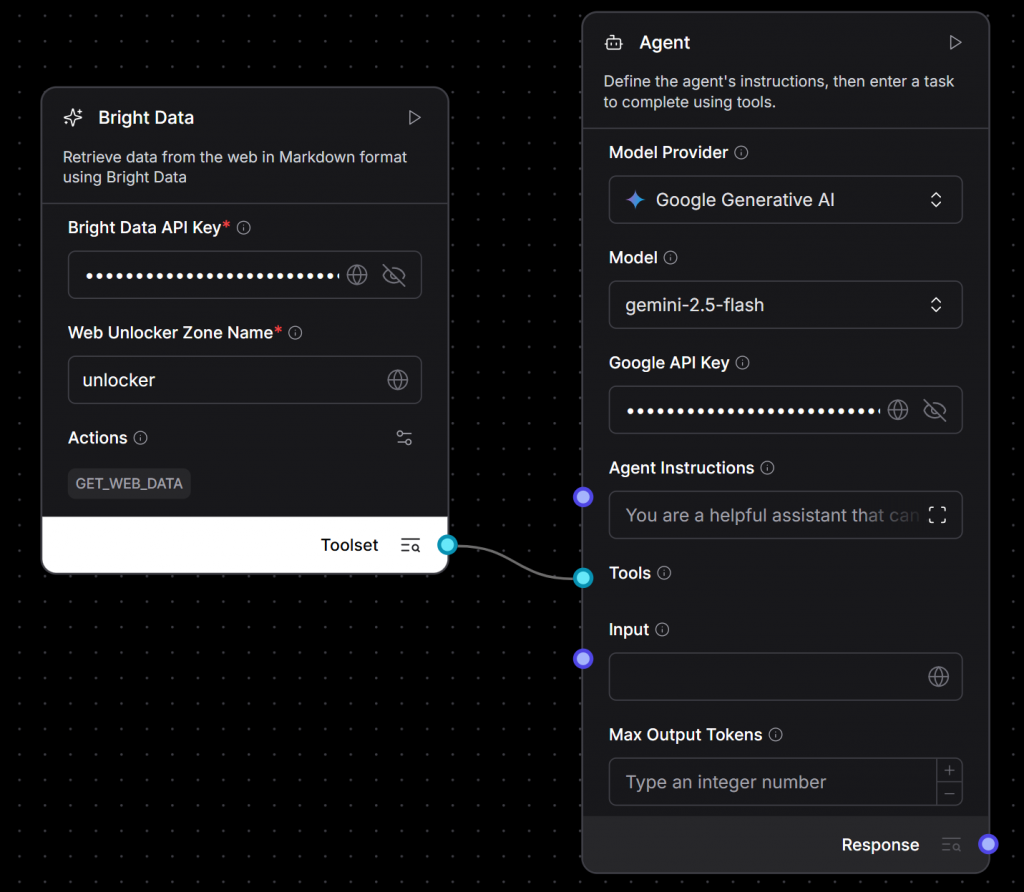
好了!您的核心 AI 应用已完成接线。这是一个基于 Gemini 的代理,能够通过 Bright Data 抓取实时网页内容。
步骤 7:完善 Flow
要让您的 AI 流程完整运行,还需添加输入与输出组件。请连接一个 Chat Input 组件到 AI 代理,将 Chat Output 组件连接到代理的输出。
此时,您的 Flow 应如下所示:
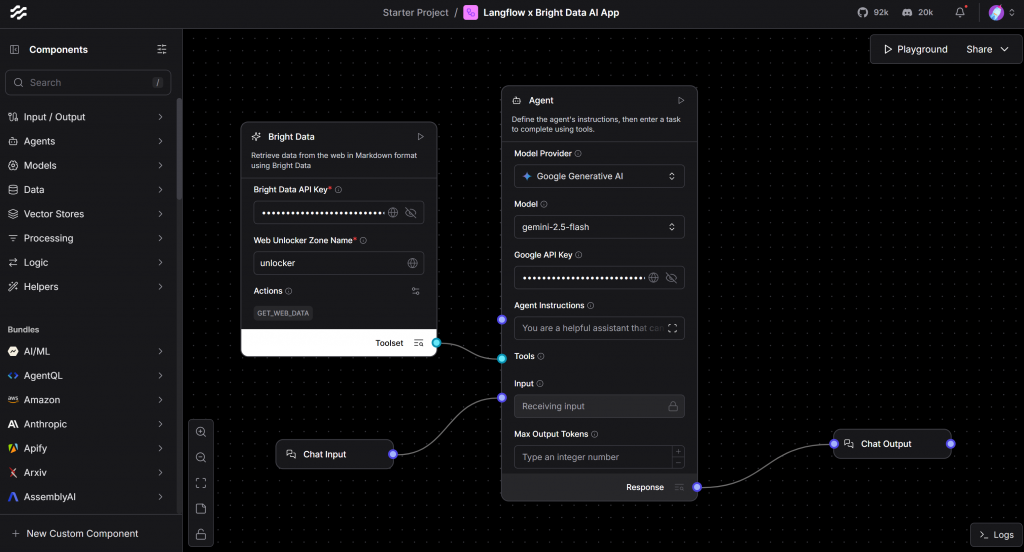
以上配置为您提供了一个聊天式界面,与 AI 代理进行交互。
就这样!您的 Langflow × Bright Data AI 应用已完成并可立即使用。
步骤 8:测试 AI 应用
要启动您的 AI 应用,点击 Langflow 界面右上角的 “Playground” 按钮:

您将看到:
它类似 ChatGPT 的界面,但完全由您自建的 AI 代理驱动。可尝试输入如下提示:
Give me a detailed summary with the key information about this product:
https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/背后执行流程:
- 提示从 Chat Input 传递到 AI Agent 组件。
- 代理使用配置的大模型(此例为 Gemini),并触发 Bright Data 组件工具。
- 代理接收爬取的网页内容,处理后将最终响应发回 Chat Output(即您在界面上看到的答案)。
此示例很有价值,因为单靠 Gemini 无法绕过 Amazon 的反爬虫保护。Bright Data 的 Web Unlocker 能绕过 Amazon CAPTCHA,提取页面数据,以 AI 可用的 Markdown 格式返回。
运行提示后,您将看到:
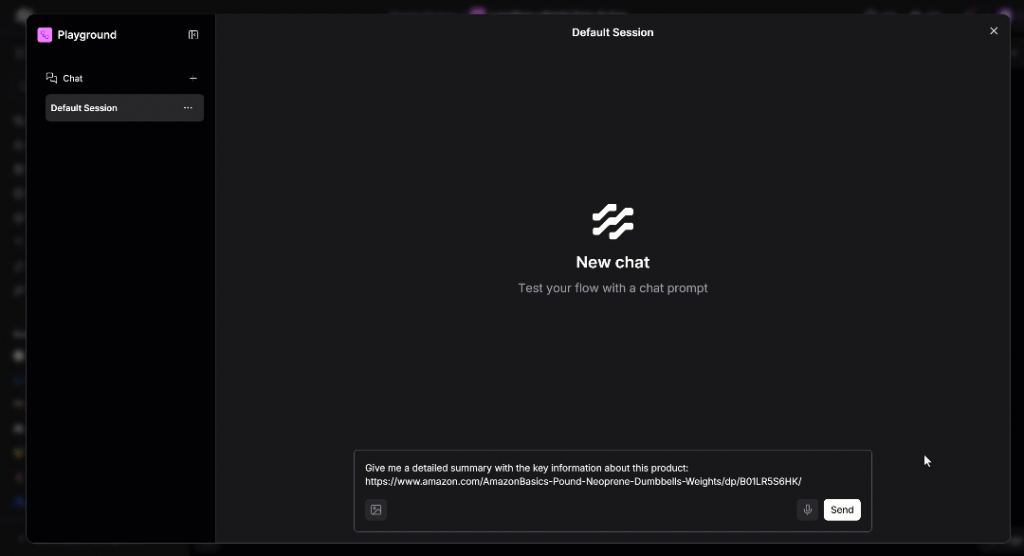
要确认代理确实使用了 Bright Data,请展开 “Accessing web_get_data” 下拉:
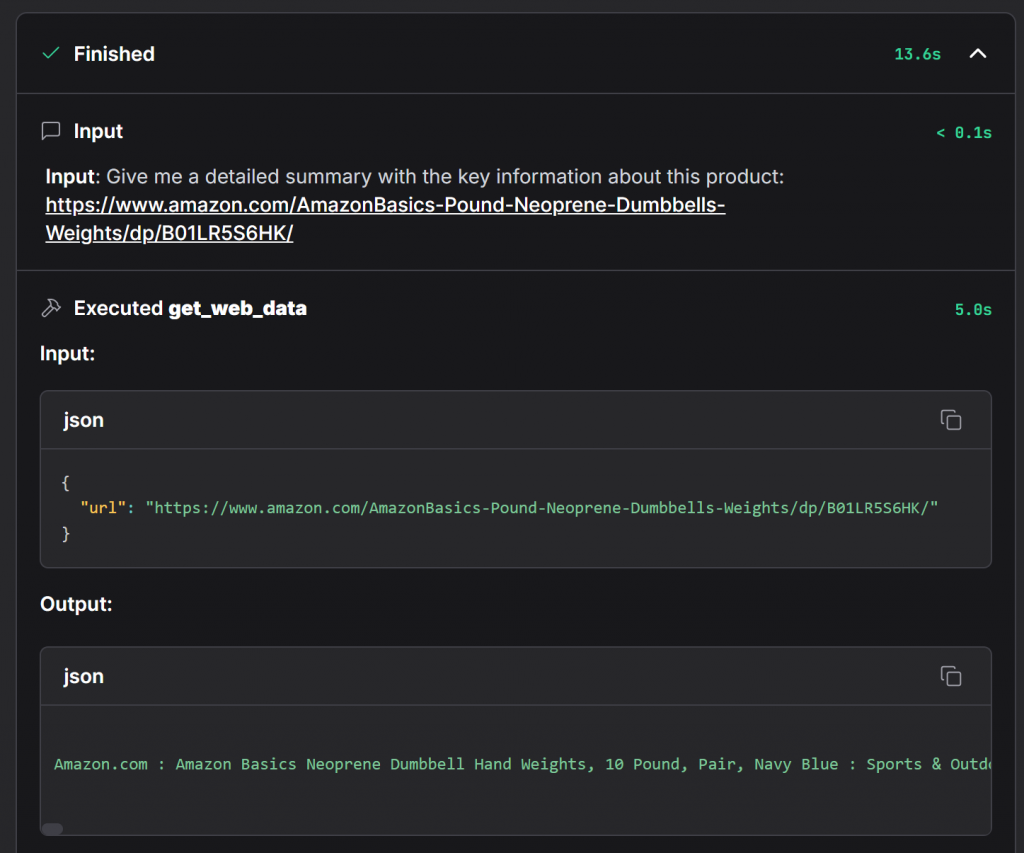
这里展示了 get_web_data 函数调用的完整细节,您可查看数据已成功从 Amazon 产品页面获取。
下图为 AI 代理实际输出内容的部分截图:

您可通过访问原始 Amazon 页面验证,所有信息均为真实抓取,未产出幻觉:
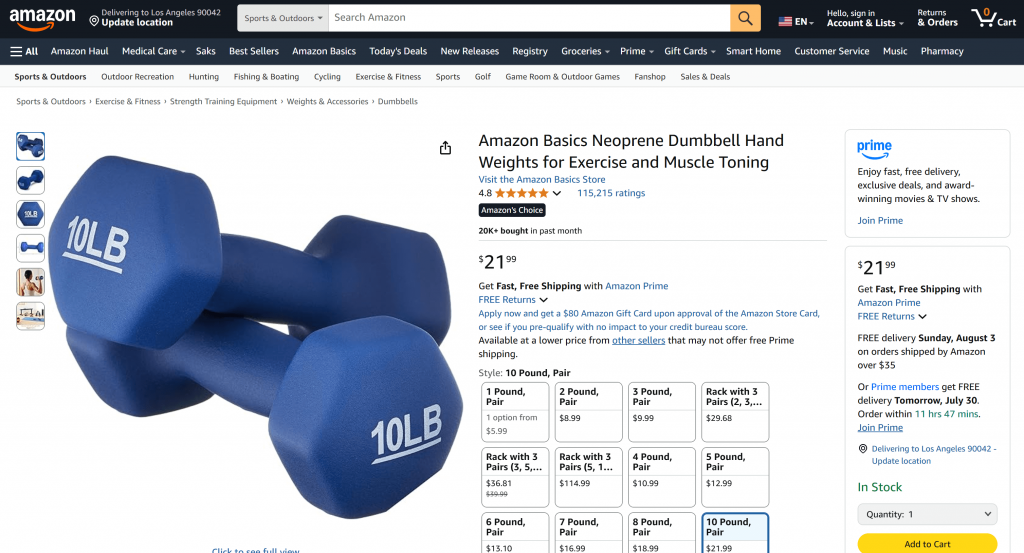
Voilà!您已成功构建并测试了一个基于 Langflow 与 Bright Data 的网络数据访问 AI 应用。
下一步
现在集成已就绪,您可以:
- 使用官方支持的部署方式将代理发布到云端或您的服务器。
- 扩展集成,连接其他 Bright Data 产品,如 Web Scraper APIs 或 SERP APIs。只需在
BrightDataComponent中修改逻辑,调用不同的 Bright Data API,详见官方文档。 - 重新组合组件,创建更高级的用例,包括 RAG 管道、数据工作流、AI 自动化流程等。
- 将您的 AI 代理连接到Bright Data MCP 服务器,即可开箱使用 50+ 工具。
结论
本文介绍了如何借助 Langflow 和 Bright Data 自定义集成,构建一个具备网络数据访问能力的 AI 代理。该设置使您的大模型能够实时检索并处理几乎任意网站的数据。
请记住,这里展示的只是一个基础示例。若要构建更复杂的代理,需要一套完善的工具来获取、验证并转换实时网页数据,使其更加适合 AI 消费。Bright Data AI 基础设施正是为此而生。
立即创建免费 Bright Data 账号,开始尝试我们的 AI 就绪数据获取工具吧!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




