
厌倦了在亚马逊上手动比较商品?想对搜索结果向 AI 提问?需要比按价格或评分排序更深入的洞察?本教程将带你构建一款亚马逊商品分析器,支持查询 23 个亚马逊站点,用 AI 分析结果,并通过交互式仪表盘展示洞察。
你将构建的内容
完成本指南后,你将拥有一个可用的网页应用,它可以抓取亚马逊商品数据,并将其组织到一个易于浏览的仪表盘中,提供 AI 驱动的洞察。
核心功能与用户流程
工作流程如下:
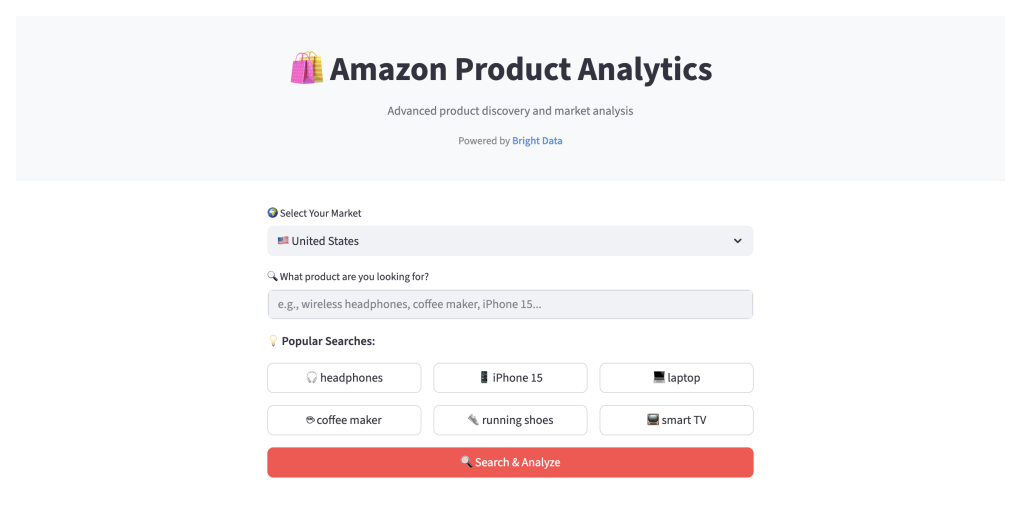
- 搜索与数据采集。 选择 23 个亚马逊站点之一(美国、德国、日本等),输入如“无线耳机”这样的商品关键词。应用使用 Bright Data 的 Web Scraper API 采集商品信息。
- 结构化结果展示。 通过简洁的分页界面呈现数据:
- 推荐。 按自定义评分算法(结合评分、评论数与折扣)排序的商品,包含三类:“综合最佳”、“最高评分”和“最佳优惠”。
- 市场分析。 通过交互式图表探索价格分布与评分模式,理解市场格局。
- AI 助手。 用自然语言提问,如“哪些产品在 100 美元以内评分最高?”。AI 会基于当前搜索结果进行分析,并给出带商品引用的答案。
- 商品结果。 浏览、排序并将完整数据集导出为 CSV 以供进一步分析。
了解了应用功能后,我们来看支撑它的技术。
技术栈与项目架构
我们的应用采用现代的 Python 技术栈,各组件针对数据处理、AI 与 Web 开发的特长而选。
| 组件 | 技术 | 用途 |
|---|---|---|
| 数据源 | Bright Data Amazon Scraper API | 无需自管代理或验证码的企业级亚马逊数据采集。 |
| 前端 | Streamlit | 仅用 Python 快速构建交互且美观的 Web 仪表盘。 |
| AI 集成 | Google Gemini | 自然语言洞察、数据总结与 AI 助手功能。 |
| 数据处理 | Pandas | 数据清洗、转换与分析的基石。 |
| 数学运算 | NumPy | 价值评分算法与统计计算。 |
| 可视化 | Plotly | 丰富的交互图表,便于用户探索。 |
| HTTP(S) 与重试 | Requests + Tenacity | 与外部 API 的稳健通信。 |
项目架构
项目采用模块化结构,确保关注点分离,便于维护与扩展。
├── streamlit_app.py # Main Streamlit application entry point
├── requirements.txt # Project dependencies
├── .env # API keys and environment variables (private)
└── amazon_analytics/ # Core application logic module
├── __init__.py # Package initialization
├── api.py # Bright Data API integration
├── data_processor.py # Data cleaning, normalization, and feature engineering
├── shopping_intelligence.py # Product recommendation and scoring engine
├── gemini_ai_engine.py # AI analysis and prompt engineering with Gemini
├── ai_engine_interface.py # Abstract AI engine interface
├── ai_response.py # Standardized AI response objects
└── config.py # Configuration management架构明确后,开始准备开发环境。
先决条件
在开始编码前,请准备好以下内容:
- Python 3.8+。 如未安装,请从Python 官方网站下载。
- Bright Data 账户。 访问 Amazon Scraper API 需要 API Key。注册免费试用并生成 API Key。
- Google API Key。 使用 Gemini 模型所需。可在 Google AI Studio 生成。
- 基础知识。 需对 Python、Pandas 与 Web API 概念有基本了解。
准备就绪后,开始项目设置。
步骤 1 – 设置开发环境
首先,克隆项目仓库,创建虚拟环境隔离依赖,并安装所需库。
安装
在终端运行以下命令:
# Clone the repository
git clone https://github.com/triposat/amazon-product-analytics.git
cd amazon-product-analytics
# Create and activate a virtual environment
python -m venv venv
source venv/bin/activate # On Windows use: venvScriptsactivate
# Install the required libraries
pip install -r requirements.txt配置 API Key
接着,在项目根目录创建 .env 文件安全存储你的 API Key。
# Create the .env file
touch .env在文本编辑器中打开 .env,添加你的密钥:
BRIGHT_DATA_TOKEN=your_bright_data_token_here
GOOGLE_API_KEY=your_google_api_key_here环境已配置完成。接下来从数据采集开始。
步骤 2 – 使用 Bright Data 抓取亚马逊商品数据
高质量数据是应用的基础。手动抓取亚马逊复杂且繁琐——需要管理代理、适配不同页面布局,并想办法绕过亚马逊验证码与拦截机制。
Bright Data 的 Amazon Web Scraper API 将这些复杂性全部抽象化,提供:
- 企业级可靠性。 基于遍布 195 个国家、超过 1.5 亿合规来源的住宅代理 IP 网络,确保持续稳定访问。
- 零基础设施负担。 自动 IP 轮换、验证码处理与代理管理均在后台完成。
- 全面的结构化数据。 提供干净、结构化的 JSON 数据,每个商品 20+ 数据点,包括 ASIN、价格、评分、评论、卖家信息、商品描述、图片、库存等。
- 具性价比的定价。 按量计费,单条记录起价 $0.001,适配各种规模的项目。
API 集成(api.py)
我们的 api.py 中的 BrightDataAPI 类负责与 API 的所有交互。它采用触发-轮询-下载的流程,适合处理可能耗时较长的抓取任务。
trigger_search 方法用于启动抓取任务。注意使用了 tenacity 库的 @retry 装饰器——当请求失败时会采用指数退避自动重试,提高稳健性。
# amazon_analytics/api.py
class BrightDataAPI:
def __init__(self, token: Optional[str] = None):
self.token = token or BRIGHT_DATA_TOKEN
self.base_url = "https://api.brightdata.com/datasets/v3"
self.headers = {
"Authorization": f"Bearer {self.token}",
"Content-Type": "application/json"
}
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=10),
retry=retry_if_exception_type((requests.RequestException, BrightDataAPIError))
)
def trigger_search(self, keyword: str, amazon_url: str, pages_to_search: str = "") -> str:
"""Triggers a new scraping job and returns the snapshot ID."""
payload = [{
"keyword": keyword,
"url": amazon_url,
"pages_to_search": pages_to_search
}]
response = requests.post(
f"{self.base_url}/trigger",
headers=self.headers,
json=payload,
params={
"dataset_id": BRIGHT_DATA_DATASET_ID,
"include_errors": "true",
"limit_multiple_results": "150"
},
timeout=30
)
response.raise_for_status()
return response.json()["snapshot_id"]触发搜索后,wait_for_results 方法将轮询 API 直到任务完成并下载数据。它能防止应用阻塞等待,并包含超时以避免无限循环。
在可靠的数据采集基础上,下一步是对原始数据进行清洗与增强。
步骤 3 – 构建数据处理流水线
任何来源的原始数据都很少直接适合分析。我们的 data_processor.py 中的 DataProcessor 类负责对抓取的亚马逊数据进行清洗、规范化,并进行特征工程,使其可供 AI 与可视化层使用。更广泛的数据处理思路可参阅我们关于使用 Python 进行数据分析的指南。
智能价格解析
电商数据的一大挑战是国际化格式。例如,德国价格可能为“1.234,56”,而美国为“1,234.56”。parse_float_locale 函数能智能处理这些差异。
# amazon_analytics/data_processor.py (simplified for readability)
def parse_float_locale(self, value: Any) -> Optional[float]:
"""Robust float parser handling international number formats."""
if value is None or value == "":
return None
if isinstance(value, (int, float)):
return float(value)
if isinstance(value, str):
s = re.sub(r"[^0-9.,]", "", value)
has_comma = "," in s
has_dot = "." in s
if has_comma and has_dot:
# Determine decimal separator by last position
if s.rfind(',') > s.rfind('.'):
s = s.replace('.', '').replace(',', '.') # European format
else:
s = s.replace(',', '') # US format
elif has_comma:
# Check if comma is thousands separator or decimal
if re.search(r",d{3}$", s):
s = s.replace(',', '') # Thousands separator
else:
s = s.replace(',', '.') # Decimal separator
return float(s)
return None自定义价值评分算法
为帮助用户快速识别最佳商品,我们创建了自定义的 value_score。该组合指标将多个因素整合为一个易理解的分数。
# amazon_analytics/data_processor.py
def compute_value_score(
self,
rating: Optional[float],
num_ratings: Optional[int],
discount_pct: Optional[float],
min_reviews: int = 10
) -> float:
"""Computes a composite value score based on quality, social proof, and deal value."""
score = 0.0
# 40% weight for product quality (rating)
if rating and rating > 0:
score += (rating / 5.0) * 0.4
# 30% weight for social proof (number of ratings)
if num_ratings and num_ratings >= min_reviews:
# Logarithmic scale to prevent mega-popular items from dominating
review_score = min(math.log10(num_ratings) / 4, 1.0)
score += review_score * 0.3
# 30% weight for deal value (discount percentage)
if discount_pct and discount_pct > 0:
discount_score = min(discount_pct / 50, 1.0) # Cap at 50% discount
score += discount_score * 0.3
return round(score, 2)该算法在质量(评分)、社会证明(评论量)与优惠(折扣)之间实现平衡,从而提供商品吸引力的整体衡量。
数据清洗与增强完成后,我们将其交给 AI 引擎进行更深层的洞察。
步骤 4 – 集成 Gemini 实现智能分析
这是应用真正变“聪明”的环节。我们使用 Google 的 Gemini AI 分析处理后的数据并回答用户问题。LLM 的一个主要挑战是“幻觉”(编造数据)。我们的 GeminiAIEngine 旨在防止这种情况。
# amazon_analytics/gemini_ai_engine.py (significantly simplified for tutorial clarity)
def _create_anti_hallucination_prompt(self, user_query: str, df: pd.DataFrame) -> str:
"""Creates a hallucination-proof prompt by including all data context."""
# Note: The actual implementation includes detailed field mapping,
# type conversion, and NaN handling for 20+ product attributes
products_data = []
for _, row in df.iterrows():
product = {
'name': str(row.get('name', 'N/A')),
'asin': str(row.get('asin', 'N/A')),
'final_price': float(row.get('final_price', 0)) if pd.notna(row.get('final_price')) else 0,
'rating': float(row.get('rating', 0)) if pd.notna(row.get('rating')) else 0,
'num_ratings': int(row.get('num_ratings', 0)) if pd.notna(row.get('num_ratings')) else 0,
# ... additional fields with proper type handling
}
products_data.append(product)
return f"""You are an expert Amazon product analyst with advanced reasoning capabilities.
ZERO HALLUCINATION RULES:
1. NEVER make up or invent ANY product information
2. ONLY use data explicitly provided below
3. If information is missing, clearly state "This information is not available"
4. Always cite specific product ASINs for verification
5. Use your reasoning to provide valuable insights based on the actual data
REASONING CAPABILITIES:
- Compare products by analyzing price, ratings, reviews, and features
- Identify best value products by considering price vs rating relationship
- Assess product trust by evaluating rating quality and review volume
- Detect deals by comparing initial_price vs final_price
USER QUERY: {user_query}
AVAILABLE PRODUCT DATA ({len(df)} products):
{json.dumps(products_data, indent=2)}
Use your reasoning to analyze this data and provide helpful, accurate insights. Include specific ASINs and numbers for verification."""关键防幻觉技术:
- 完整数据提供。 将所有商品信息提供给 AI,避免猜测空间。
- 明确边界。 明确告知 AI 能做与不能做的事。
- ASIN 引用。 强制 AI 引用具体商品以便核实。
- 结构化数据格式。 使用 JSON 格式提高数据解析可靠性。
这种提示词工程将 AI 转化为可靠的数据分析师,使其输出值得信赖并可核验。
AI 引擎就绪后,我们来构建推荐系统。
步骤 5 – 构建购物智能引擎
shopping_intelligence.py 中的 ShoppingIntelligenceEngine 使用处理后的数据生成三类主要推荐:“综合最佳”、“最高评分”和“最佳优惠”。该引擎应用了复杂的筛选标准,确保推荐质量。
系统以商品字典列表为输入,并为每类推荐使用独立的辅助方法与特定质量阈值。
# amazon_analytics/shopping_intelligence.py
class ShoppingIntelligenceEngine:
def analyze_products(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Generate shopping intelligence from product data."""
if not products:
return {'total_items': 0, 'top_picks': []}
top_picks = self._generate_top_picks(products)
return {
'total_items': len(products),
'top_picks': top_picks
}
def _generate_top_picks(self, products: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""Generate top product recommendations with reasoning."""
try:
# First, filter for valid products only
valid_products = []
for product in products:
rating = product.get('rating')
price = product.get('final_price')
if rating is not None and price is not None and rating > 0 and price > 0:
valid_products.append(product)
if not valid_products:
return []
picks = []
used_asins = set()
# Find each category using specialized methods
best_value = self._find_best_value(valid_products)
if best_value and best_value.get('asin') not in used_asins:
picks.append({
'product': best_value,
'reason': 'Best Overall Value',
'explanation': 'Excellent balance of quality, price, and customer reviews'
})
used_asins.add(best_value['asin'])
highest_rated = self._find_highest_rated(valid_products)
if highest_rated and highest_rated.get('asin') not in used_asins:
picks.append({
'product': highest_rated,
'reason': 'Highest Rated',
'explanation': 'Top customer satisfaction with proven track record'
})
used_asins.add(highest_rated['asin'])
best_deal = self._find_best_deal(valid_products)
if best_deal and best_deal.get('asin') not in used_asins:
picks.append({
'product': best_deal,
'reason': 'Best Deal',
'explanation': 'Great value with significant savings and good quality'
})
used_asins.add(best_deal['asin'])
# Fill remaining slots with quality products if needed
if len(picks) < 3:
remaining_products = [p for p in valid_products if p.get('asin') not in used_asins]
remaining_products.sort(key=lambda x: x.get('value_score', 0), reverse=True)
for product in remaining_products[:3-len(picks)]:
picks.append({
'product': product,
'reason': 'Quality Choice',
'explanation': 'Good balance of quality and value'
})
return picks[:3]
except Exception:
return []质量筛选方法
每个推荐类别都设定特定的质量阈值以确保可靠性:
def _find_best_value(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Find product with best value score - requires 10+ reviews."""
candidates = [p for p in products if
p.get('value_score') is not None and
p.get('num_ratings', 0) >= 10]
if not candidates:
return None
return max(candidates, key=lambda p: p.get('value_score', 0))
def _find_highest_rated(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Find highest rated product - requires 4.0+ rating and 50+ reviews."""
candidates = [p for p in products if
p.get('rating', 0) >= 4.0 and
p.get('num_ratings', 0) >= 50]
if not candidates:
return None
return max(candidates, key=lambda p: (p.get('rating', 0), p.get('num_ratings', 0)))
def _find_best_deal(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Find best discount - requires 10%+ discount and 3.5+ rating."""
candidates = [p for p in products if
p.get('discount_pct') is not None and
p.get('discount_pct', 0) >= 10 and
p.get('rating', 0) >= 3.5]
if not candidates:
return None
return max(candidates, key=lambda p: p.get('discount_pct', 0))关键设计决策:
- 质量阈值。 各类别设定最低标准,避免推荐劣质商品。
- 去重。 使用
used_asins确保每个商品只出现一次。 - 回退逻辑。 若少于 3 条推荐,用次优价值分补齐。
- 错误处理。 try/catch 防止异常数据导致崩溃。
该方法确保用户获得可靠的高质量推荐,而非仅仅“搜索到的前几个”。
后端组件已就绪,接下来用用户界面把它们串起来。
步骤 6 – 使用 Streamlit 设计交互式仪表盘
最后一环是用户界面,由 streamlit_app.py 实现。Streamlit 让你以极少的代码构建响应式 Web 仪表盘。应用采用标签页式布局,包含实时进度追踪与多种图表类型。
会话状态与组件缓存
应用使用特定的会话状态变量来管理数据流,并缓存后端组件以提升性能:
# streamlit_app.py - Session state initialization
if 'search_results' not in st.session_state:
st.session_state.search_results = []
if 'shopping_intelligence' not in st.session_state:
st.session_state.shopping_intelligence = {}
if 'current_run_id' not in st.session_state:
st.session_state.current_run_id = None
@st.cache_resource
def get_backend_components():
"""Initialize and cache backend components."""
api = BrightDataAPI()
processor = DataProcessor()
intelligence = ShoppingIntelligenceEngine()
ai_engine = get_gemini_ai()
return api, processor, intelligence, ai_engine内联搜索处理与进度追踪
搜索逻辑直接嵌入主流程,包含细致的进度追踪与数据持久化:
# streamlit_app.py - Search processing (simplified)
# Search execution with progress tracking
if search_clicked and keyword.strip():
progress_bar = st.progress(0)
status_text = st.empty()
start_time = time.time()
try:
# Trigger search
status_text.text("Starting Amazon search...")
snapshot_id = api.trigger_search(keyword, amazon_url)
progress_bar.progress(25)
# Wait for results with smart progress updates
status_text.text("Amazon is processing your search...")
results = smart_wait_for_results(api, snapshot_id, progress_bar, status_text)
progress_bar.progress(75)
# Process results
status_text.text("Analyzing products...")
processed_results = processor.process_raw_data(results)
shopping_intel = intelligence.analyze_products(processed_results)
# Store comprehensive results in session state
st.session_state.search_results = processed_results
st.session_state.shopping_intelligence = shopping_intel
st.session_state.current_run_id = str(uuid.uuid4())
st.session_state.raw_data = results
st.session_state.search_metadata = {
'keyword': keyword,
'country': countries[selected_country],
'domain': amazon_url,
'timestamp': datetime.now(timezone.utc).isoformat()
}
elapsed_time = time.time() - start_time
status_text.text(f"Found {len(processed_results)} products in {elapsed_time:.1f}s!")
progress_bar.progress(100)
except Exception as e:
st.error(f"Search failed: {str(e)}")多种交互式可视化
“市场分析”标签页会内联创建多种图表,并进行样式与注释配置:
# streamlit_app.py - Price distribution with median line
fig_price = px.histogram(
x=display_prices,
nbins=min(20, max(1, unique_prices)),
title="Price Range",
labels={'x': f'Price ({currencies.get(current_country_code, "USD")})', 'y': 'Number of Products'},
color_discrete_sequence=['#667eea']
)
# Add median line for context
fig_price.add_vline(x=q50, line_dash="dash", line_color="orange", annotation_text="Median")
st.plotly_chart(fig_price, use_container_width=True)
# Rating vs Price scatter with size and color encoding
fig_scatter = px.scatter(
df_scatter,
x='final_price',
y='rating',
size='num_ratings',
hover_data=['name', 'num_ratings'],
title="Quality vs Price",
labels={'final_price': f'Price ({currencies.get(current_country_code, "USD")})', 'rating': 'Rating (Stars)'},
color='rating',
color_continuous_scale='Viridis'
)
st.plotly_chart(fig_scatter, use_container_width=True)
# Value score distribution with percentile markers
fig_value = px.histogram(
x=value_scores,
nbins=20,
title="Best Value Products",
labels={'x': 'Value Score (0.0-1.0)', 'y': 'Number of Products'},
color_discrete_sequence=['#28a745']
)
p50 = np.percentile(value_scores, 50)
p75 = np.percentile(value_scores, 75)
fig_value.add_vline(x=p50, line_dash="dash", line_color="orange", annotation_text="Median")
fig_value.add_vline(x=p75, line_dash="dash", line_color="red", annotation_text="75th %ile")
st.plotly_chart(fig_value, use_container_width=True)高级图表特性
仪表盘包含具有商业智能意义的可视化:
- 价格直方图。 带中位数与四分位标记,用于市场定位。
- 评分散点图。 点大小代表评论量,颜色代表评分质量。
- 排名饼图。 展示搜索排名分布(1-5、6-10、11-20、21+)。
- 价格分层柱状图。 将商品分为入门/均衡/高端/奢华等层级。
- 折扣分析。 识别真实优惠与虚高标价。
这一整套可视化打造出专业级的分析仪表盘,输出可执行的市场洞察。
结论
你已成功构建了一款利用企业级数据采集、先进 AI 与交互式可视化的亚马逊商品分析器。项目完整源码可在 GitHub 获取并自由扩展。
你已经学会如何:
- 使用 Bright Data 的 Web Scraper API 以规模化方式可靠地抓取亚马逊数据。
- 实现稳健的数据处理流水线,处理复杂的真实世界数据挑战。
- 用 Google Gemini 打造防幻觉的 AI 助手,确保可信分析。
- 使用 Streamlit 与 Plotly 构建直观且交互的用户界面。
本项目可作为将海量网络数据转化为可执行商业智能的强力模板。接下来你可以扩展为专用的 亚马逊价格追踪器,或整合其他数据源。
电商数据世界广阔无垠。如需预先采集、即取即用的数据集,欢迎探索 Bright Data 的数据集市场,这里有海量选择。



技术写作者
 5 years experience
5 years experience
Satyam Tripathi 帮助 SaaS 和数据初创公司将复杂技术转化为可执行的内容,提升开发者采用度并增强用户理解。





