

Gerapy是Scrapy部署的全栈解决方案。如果你查看一下提交历史,就会发现它虽然有一些依赖性调整,但自 2022 年以来就没有真正更新过。启动 Gerapy 是一个艰难的过程,经常充满了尝试和错误。
本指南旨在让 Gerapy 更简单。在本指南结束时,您将能够回答以下问题。
- 为什么 Gerapy 不能与我的标准 Python 安装一起使用?
- 如何为 Gerapy 配置 Python 和 pip?
- 如何创建管理员账户?
- 如何撰写我的第一篇文章?
- 如何排除抓取器的故障?
- 如何测试和部署我的抓取器?
Gerapy 简介
让我们更好地了解一下什么是 Gerapy 以及它的独特之处。
什么是 Gerapy?
Gerapy 为我们提供了 Django 管理仪表板和 Scrapyd API。这些服务为您提供了一个简单而强大的界面来管理您的堆栈。在这一点上,它是一个传统程序,但它仍能改善工作流程并加快部署速度。Gerapy 让 DevOps 和以管理为导向的团队更容易使用网络抓取。
- 用于创建和监控抓取器的图形用户界面仪表板。
- 点击按钮即可部署抓取器。
- 实时查看发生的日志和错误。
是什么让 Gerapy 与众不同?
Gerapy 为您提供一站式抓取器管理服务。由于 Gerapy 的遗留代码和依赖性,使用 Gerapy 是一个繁琐的过程。不过,一旦你能使用它,你就能解锁一个专为大规模处理抓取器量身定制的完整工具集。
- 从浏览器内部构建抓取程序
- 无需触碰命令行,即可将它们部署到 Scrapyd。
- 集中管理所有爬虫和抓取器。
- 前端基于 Django,用于蜘蛛管理。
- 后台由 Scrapyd 提供支持,便于构建和部署。
- 内置任务自动化调度程序。
如何使用 Gerapy 对网络进行抓取
Gerapy 的设置过程非常费力。您需要解决技术债务问题并进行软件维护。经过反复试验,我们发现 Gerapy 甚至无法兼容更现代版本的 Python。我们首先安装了 Python 3.13。对于 Gerapy 的依赖关系来说,它太现代了。我们又尝试了 3.12,结果还是不行,依赖关系问题更多了。
结果,我们需要 Python 3.10。除此之外,我们还需要修改 Gerapy 的一些实际代码,以修复一个已废弃的类,然后我们需要手动降级 Gerapy 中几乎所有的依赖项。在过去三年中,Python 经历了巨大的变化,而 Gerapy 的发展却没有跟上步伐。我们需要重现 Gerapy 三年前的理想状态。
项目设置
Python 3.10
首先,我们需要安装 Python 3.10。这个版本并没有灭绝,但已不再广泛使用。在原生 Ubuntu 和 Windows WSL 上,可以使用 apt.
sudo apt update
sudo apt install software-properties-common
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt update
sudo apt install python3.10 python3.10-venv python3.10-dev然后可以使用--version标志检查是否已安装。
python3.10 --version如果一切顺利,您应该会看到与下面类似的输出结果。
Python 3.10.17创建项目文件夹
首先,新建一个文件夹。
mkdir gerapy-environment接下来,我们需要cd进入新项目文件夹并设置虚拟环境。
cd gerapy-environment
python3.10 -m venv venv激活环境。
source venv/bin/activate环境激活后,您可以检查 Python 的激活版本。
python --version如您所见,在虚拟环境中,python现在默认安装到了 3.10 版本。
Python 3.10.17安装依赖项
下面的命令将安装 Gerapy 及其所需的依赖版本。正如你所看到的,我们需要使用pip== 手动定位许多遗留软件包。
pip install setuptools==80.8.0
pip install scrapy==2.7.1 gerapy==0.9.13 scrapy-splash==0.8.0 scrapy-redis==0.7.3 scrapyd==1.2.0 scrapyd-client==1.2.0 pyopenssl==23.2.0 cryptography==41.0.7 twisted==21.2.0现在,我们将使用init命令创建一个实际的 Gerapy 项目。
gerapy init接下来,我们进入 gerapy文件夹,运行migrate创建数据库。
cd gerapy
gerapy migrate现在,是时候创建一个管理员账户了。该命令默认赋予你管理员权限。
gerapy initadmin最后,我们启动 Gerapy 服务器。
gerapy runserver你应该看到这样的输出结果。
Watching for file changes with StatReloader
Performing system checks...
System check identified no issues (0 silenced).
INFO - 2026-05-24 13:49:16,241 - process: 1726 - scheduler.py - gerapy.server.core.scheduler - 105 - scheduler - successfully synced task with jobs with force
May 24, 2026 - 13:49:16
Django version 2.2.28, using settings 'gerapy.server.server.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.使用仪表板
如果您访问http://127.0.0.1:8000/,系统会提示您登录。您的默认账户名是admin,密码也是admin。登录后,您将进入 Gerapy 的仪表板。
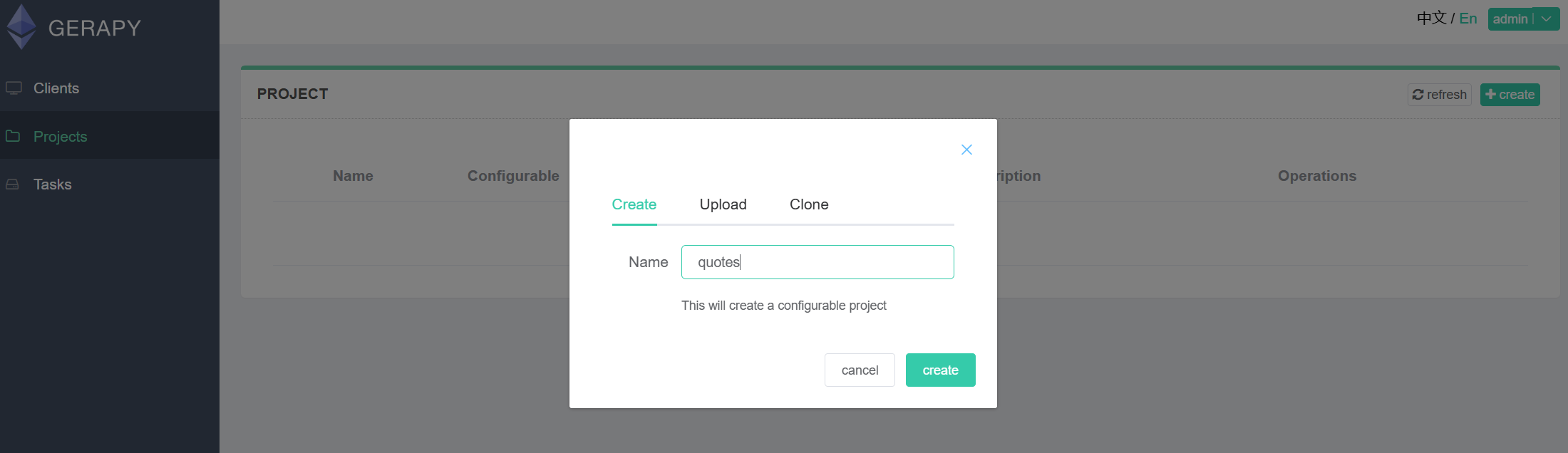
点击 “项目 “选项卡,创建一个新项目。我们将其命名为 “报价“。
获取目标网站
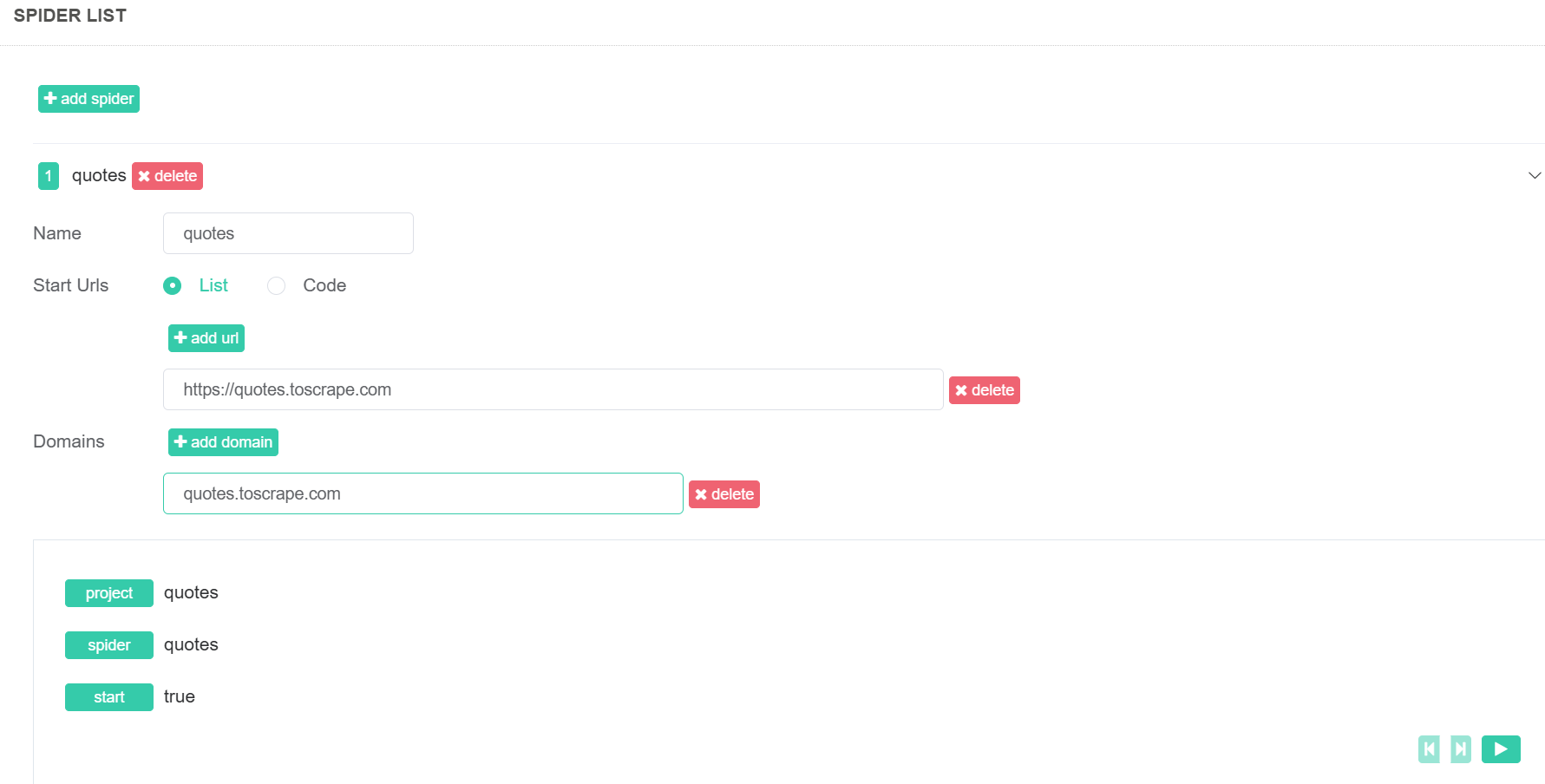
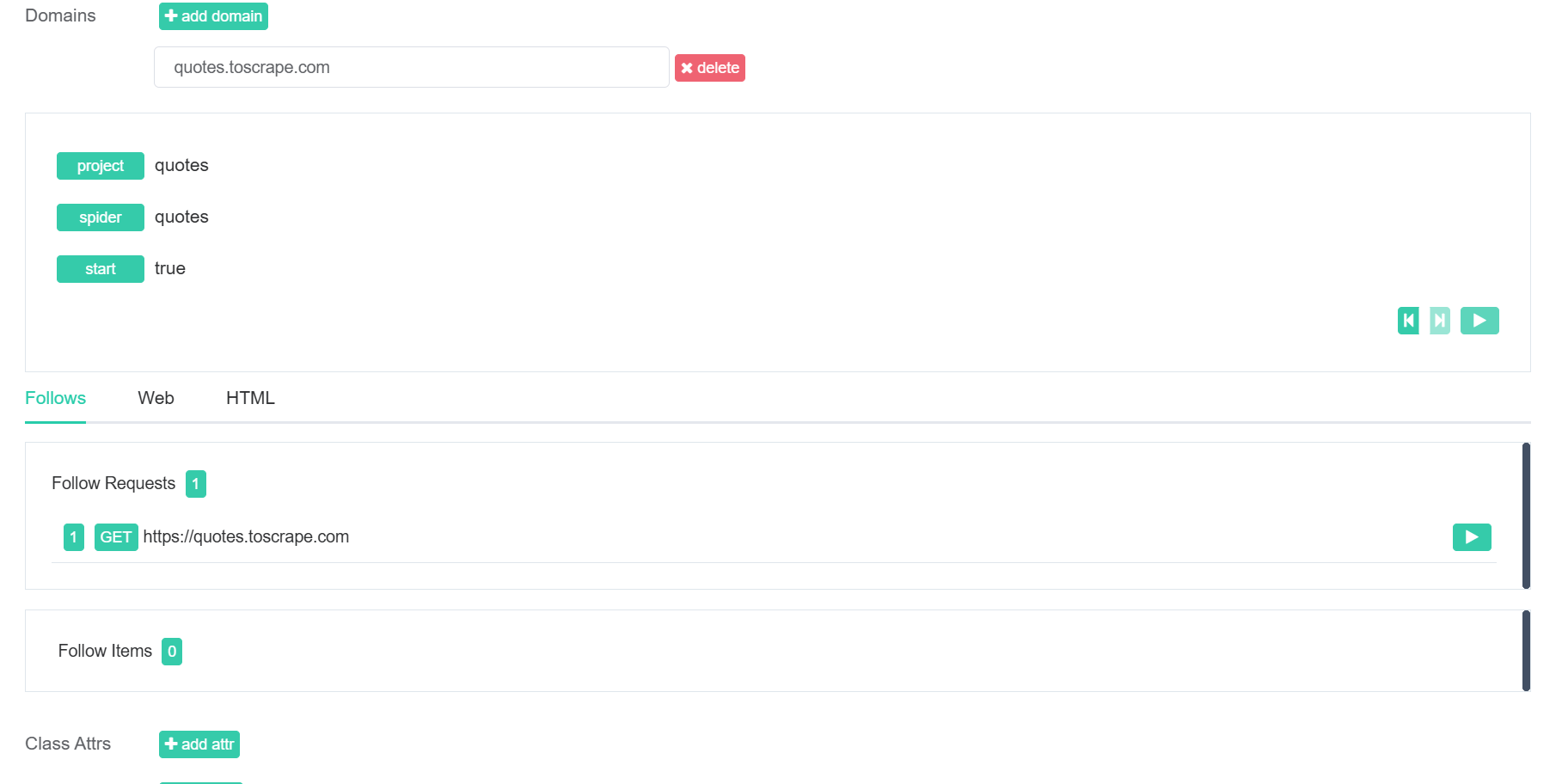
现在,我们将创建一个新的蜘蛛。在新项目中,点击 “添加蜘蛛 “按钮。在 “Start Urls “部分,添加https://quotes.toscrape.com。在 “域 “下,输入quotes.toscrape.com。
提取逻辑
接下来,我们将添加提取逻辑。下面的parse()函数使用 CSS 选择器从页面中提取引号。有关选择器的更多信息,请点击此处。
向下滚动到 “内部代码 “部分,添加您的解析函数。
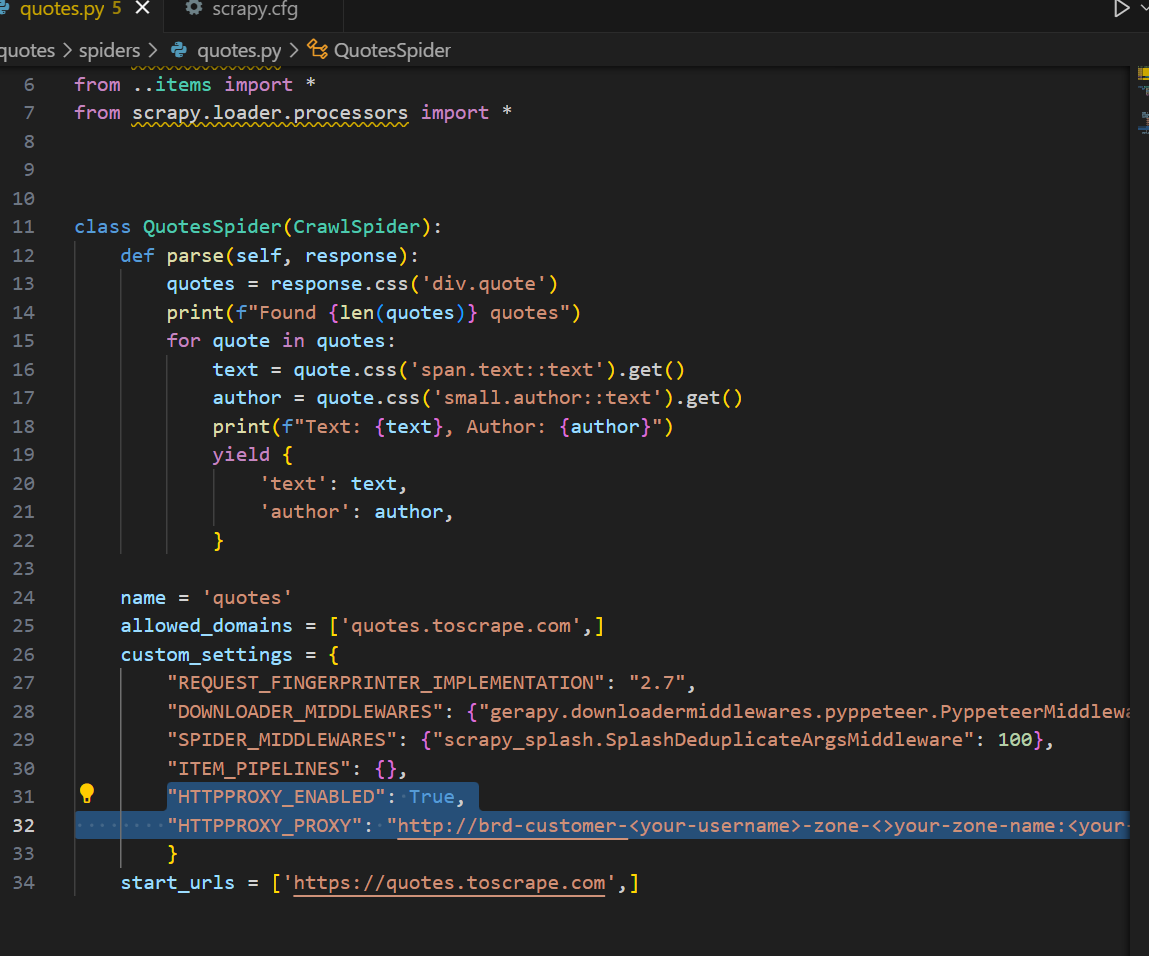
def parse(self, response):
quotes = response.css('div.quote')
print(f"Found {len(quotes)} quotes")
for quote in quotes:
text = quote.css('span.text::text').get()
author = quote.css('small.author::text').get()
print(f"Text: {text}, Author: {author}")
yield {
'text': text,
'author': author,
}现在,点击屏幕右下角的 “保存 “按钮。如果你现在运行蜘蛛,会遇到一个关键错误。Gerapy 正在尝试使用 Scrapy 中的BaseItem。然而,BaseItem早在几年前就从 Scrapy 中移除了。
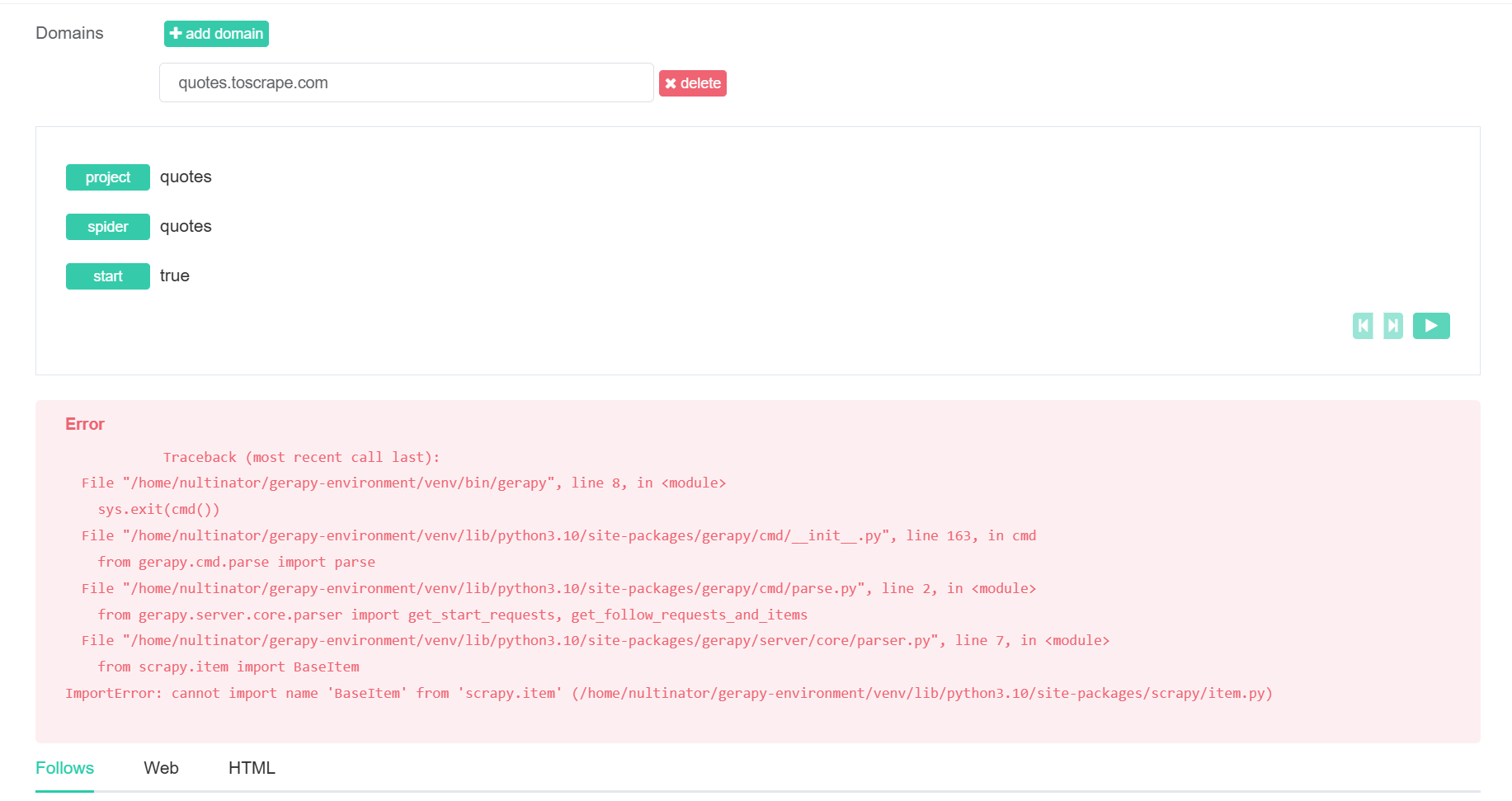
修复 BaseItem 错误
要解决这个错误,我们实际上需要编辑 Scrapy 的内部代码。你可以通过命令行进行编辑。不过,使用带有搜索功能的图形用户界面文本编辑器要容易得多。
cd进入虚拟环境的源文件。
cd venv/lib/python3.10/site-packages/gerapy/server/core要在 VSCode 中打开文件夹,可以使用下面的命令。
code .打开parser.py,你会发现罪魁祸首。
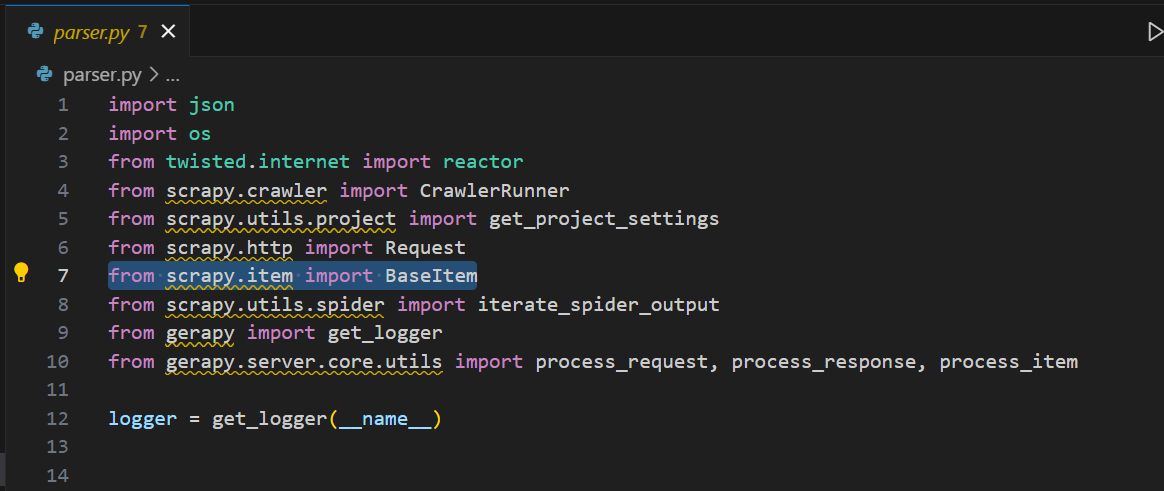
我们需要用以下内容替换这一行。
from scrapy import Item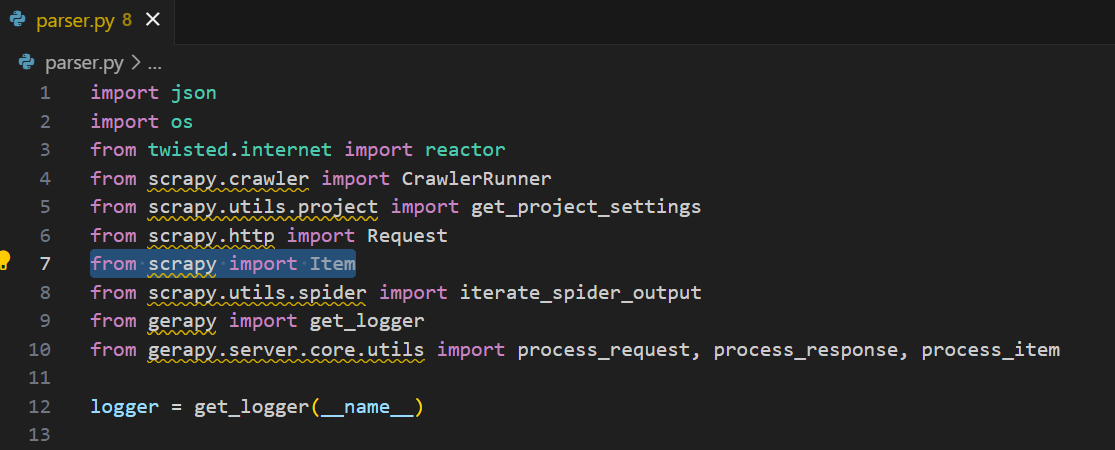
既然我们已经删除了BaseItem的导入,那么就需要删除BaseItem与Item 的所有实例。我们唯一的实例就在run_callback()函数中。完成保存更改后,关闭编辑器。
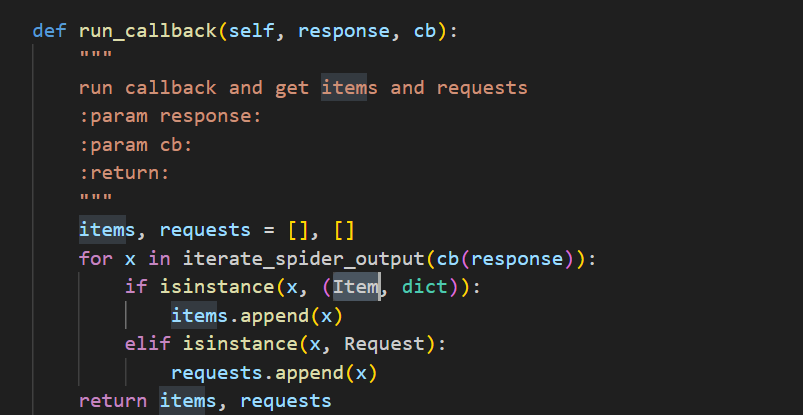
如果运行蜘蛛,现在会收到一个新错误。
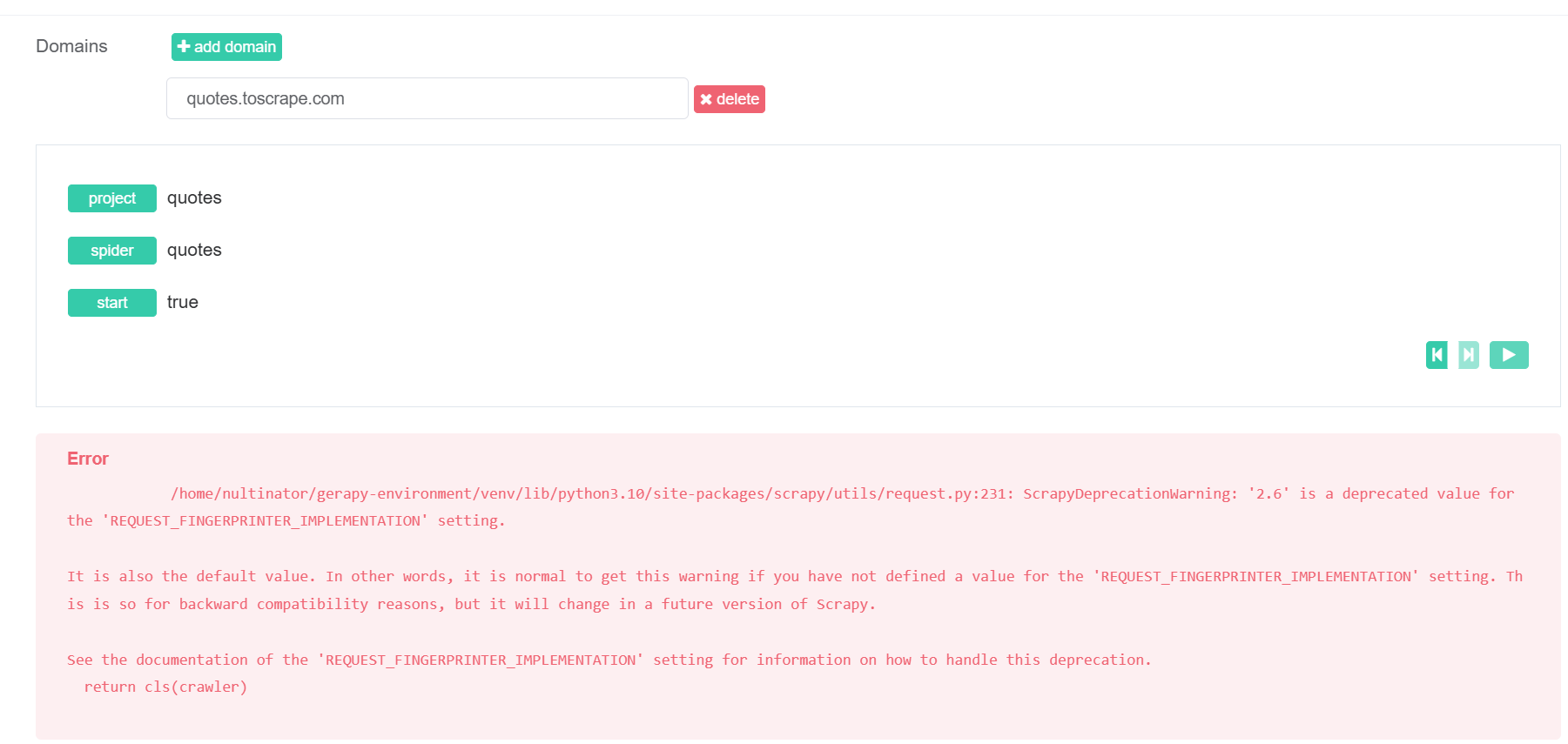
修复 REQUEST_FINGERPRINTER_IMPLEMENTATION 过时问题
虽然不明显,但 Gerapy 实际上是直接将我们的设置注入到 spider 中。
cd
cd gerapy-environment/gerapy/projects/quotes再次打开文本编辑器。
code .现在打开你的蜘蛛。它的标题应该是quotes.py,位于spiders文件夹中。你应该能在 spider 类中看到你的parse()函数。在文件底部,你会看到一个名为custom_settings 的数组。Gerapy 已将我们的设置注入到 spider 中。
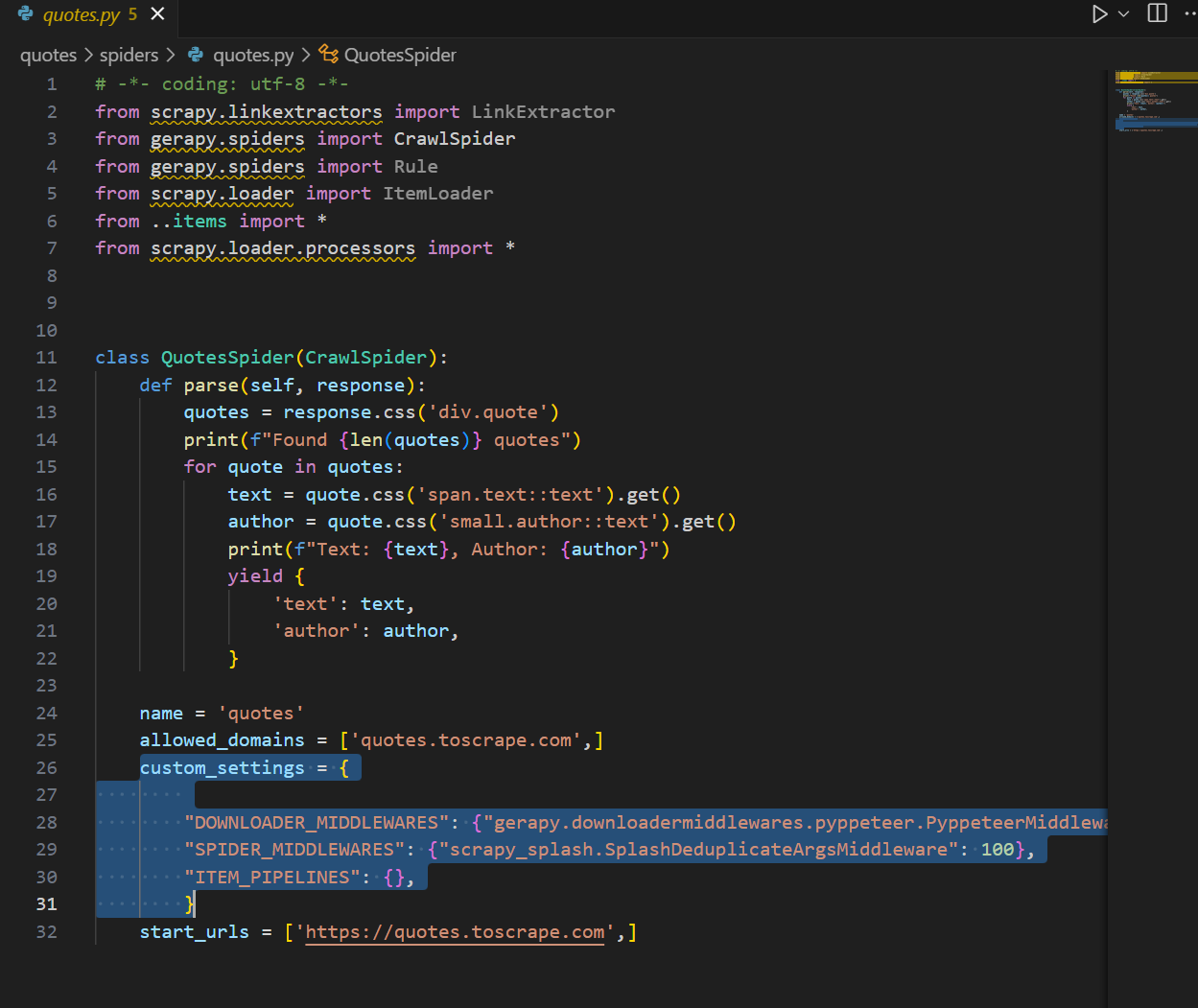
我们需要添加一个新设置。您需要使用2.7 版。2.6 版会继续出错。我们是在无数次试验和出错后才发现这一点的。
"REQUEST_FINGERPRINTER_IMPLEMENTATION": "2.7",现在,当你使用 Gerapy 的播放按钮运行蜘蛛时,所有错误都已解决。如下所示,我们看到的不再是错误信息,而是一个 “Follow Request(跟进请求)”。
把所有东西放在一起
制作刮刀
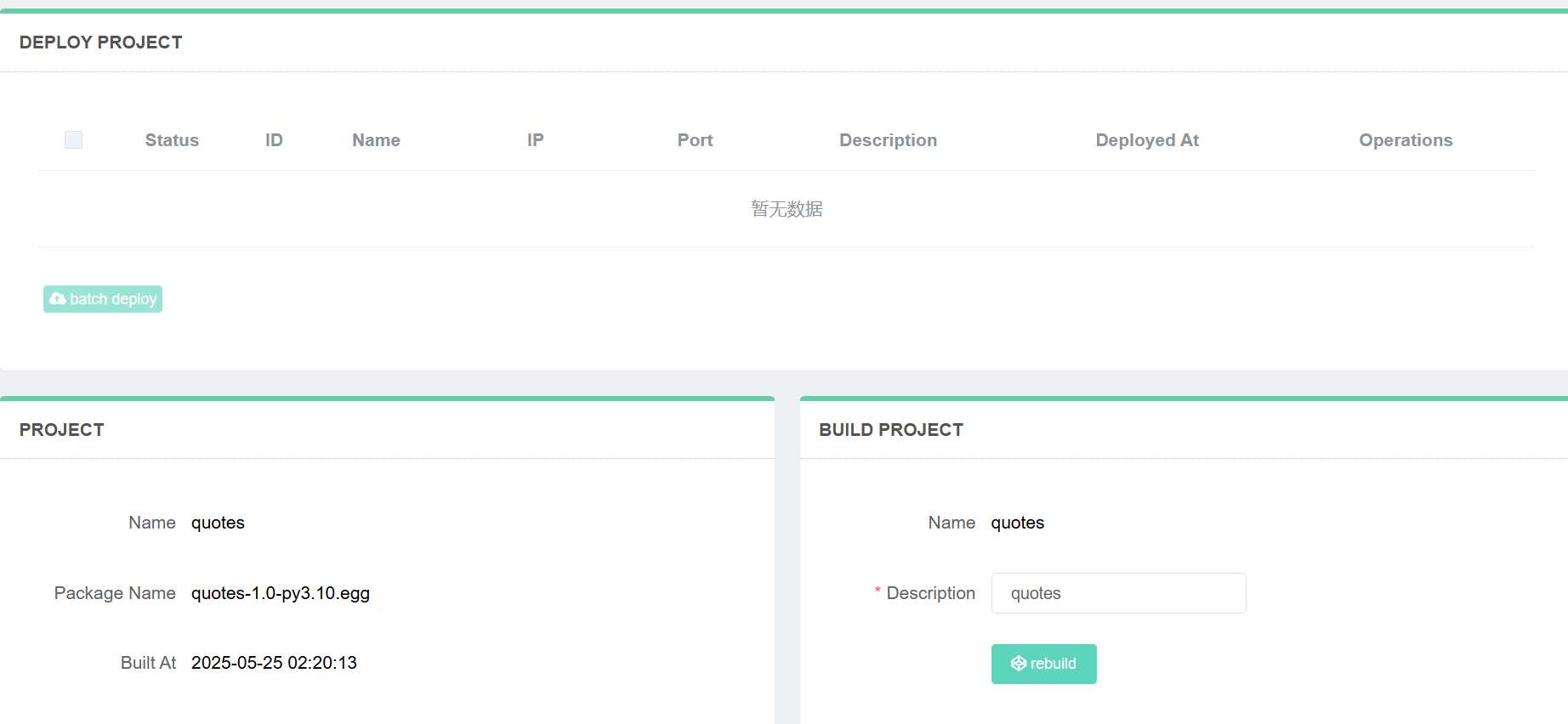
如果你回到 Gerapy 的 “项目 “选项卡,你会在项目的 “已构建 “栏中看到一个 “X”。这意味着我们的抓取器还没有内置到可执行文件中进行部署。

点击 “部署 “按钮。现在,点击 “构建”。
使用日程安排程序
要安排抓取器在特定时间或间隔运行,请单击 “任务”,然后创建一个新任务。然后,为计划选择所需的设置。
完成后,点击 “创建 “按钮。
使用 Gerapy 搜索时的局限性
依赖关系
它的遗留代码带来了许多限制,我们将在本文中一一解决。为了让 Gerapy 运行起来,我们需要对其内部源代码进行编辑。如果你不愿意接触系统内部,那么 Gerapy 并不适合你。还记得BaseItem错误吗?
随着 Gerapy 依赖关系的不断发展,Gerapy 仍将保持不变。要继续使用它,您需要亲自维护您的安装。这就以维护的形式增加了技术债务,同时也是一个非常真实的试错过程。
请回顾下面的片段。每一个版本号都是通过细致的试错过程发现的。当依赖项出现问题时,你需要不断尝试不同的版本号,直到找到一个可以正常工作的版本号。仅在本教程中,我们就通过反复试验找到了 10 个依赖项的可用版本。随着时间的推移,情况只会越来越糟。
pip install setuptools==80.8.0
pip install scrapy==2.7.1 gerapy==0.9.13 scrapy-splash==0.8.0 scrapy-redis==0.7.3 scrapyd==1.2.0 scrapyd-client==1.2.0 pyopenssl==23.2.0 cryptography==41.0.7 twisted==21.2.0操作系统限制
最初尝试编写本教程时,我们尝试使用本机 Windows。这就是我们最初发现 Python 版本限制的原因。当前的 Python 稳定版本仅限于 3.9、3.11 和 3.13。无论操作系统如何,管理多个版本的 Python 都很困难。不过,Ubuntu 为我们提供了deadsnakesPPA 代码库。
如果没有deadsnakes,也有可能找到兼容的 Python 版本,但即便如此,也需要处理 PATH 问题,并区分python(默认安装)和python3.10。在 Windows 和 macOS 中可能可以原生处理这个问题,但您需要找到不同的解决方法。在 Ubuntu 和其他基于 apt 的 Linux 发行版中,您至少可以获得一个可重现的环境,快速访问直接安装到 PATH 中的 Python 旧版本。
与 Gerapy 的代理集成
与香草 Scrapy 本身一样,代理集成也很容易实现。秉承 Gerapy 设置注入的真正精神,我们可以直接将代理注入到 spider 中。在下面的示例中,我们添加了HTTPPROXY_ENABLED和HTTPPROXY_PROXY设置,以便使用Web Unlocker 进行连接。
"HTTPPROXY_ENABLED": True,
"HTTPPROXY_PROXY": "http://brd-customer-<your-username>-zone-<your-zone-name>:<your-password>@brd.superproxy.io:33335"这是代理集成后的完整蜘蛛程序。记住将用户名、区域和密码换成你自己的。
伽玛疗法的可行替代品
- Scrapyd:这是 Gerapy 和其他任何 Scrapy 协议栈背后的实际支柱。有了 Scrapyd,你可以通过普通的 HTTP Requests 管理一切,还可以选择建立一个仪表板。
- 抓取功能:我们的抓取功能可让您直接将抓取程序部署到云端,并通过在线集成开发环境对其进行编辑–仪表板与 Gerapy 类似,但更灵活、更现代。
结论
在瞬息万变的世界中,Gerapy 是一款传统产品。它需要真正的维护,你需要亲自动手。像 Gerapy 这样的工具可以让您集中管理您的抓取环境,并从一个仪表板上监控一切。在 DevOps 圈子里,Gerapy 提供了真正的实用性和价值。
如果您不喜欢 Scrapy,我们还提供了许多可行的替代产品,以满足您的数据收集需求。以下产品只是其中的一部分。
- 自定义抓取器:无需代码即可创建抓取器,并将其部署到我们的云基础设施中。
- 数据集:访问每日更新的全网历史数据集。互联网历史资料库触手可及。
- 住宅代理:无论您喜欢自己编写代码还是使用人工智能搜索,我们的代理服务器都能让您在真实的住宅互联网连接上访问具有地理定位功能的互联网。
立即注册免费试用,让您的数据收集工作更上一层楼!



技术写作者
 6 years experience
6 years experience
Jacob Nulty 是一位常驻底特律的软件开发者和技术写作者,探索人工智能与人类哲学,具备 Python、Rust 和区块链方面的经验。




