
本文讲解如何使用 PySpark 与 Bright Data 运行大规模网页抓取工作负载。如果你需要抓取几十万商品页、监控数百个网站的价格,或从数百万页面构建训练数据集,那么单机脚本无法满足需求。
本文的模式会告诉你:如何把抓取任务分发到集群,同时在请求量增长时保持流水线的可靠性。
读完后,你将学会如何: 使用 PySpark 将大型 URL 列表当作分布式数据集来处理 在分区(partition)层面高效运行抓取工作负载 设计能够处理重试与失败的 worker,而无需重启整个任务 随着请求量扩大,处理代理路由与网络可靠性
当网页抓取变成分布式问题
大多数抓取项目的起步方式都类似:开发者写个脚本,读取一组 URL,发送请求,然后保存结果。
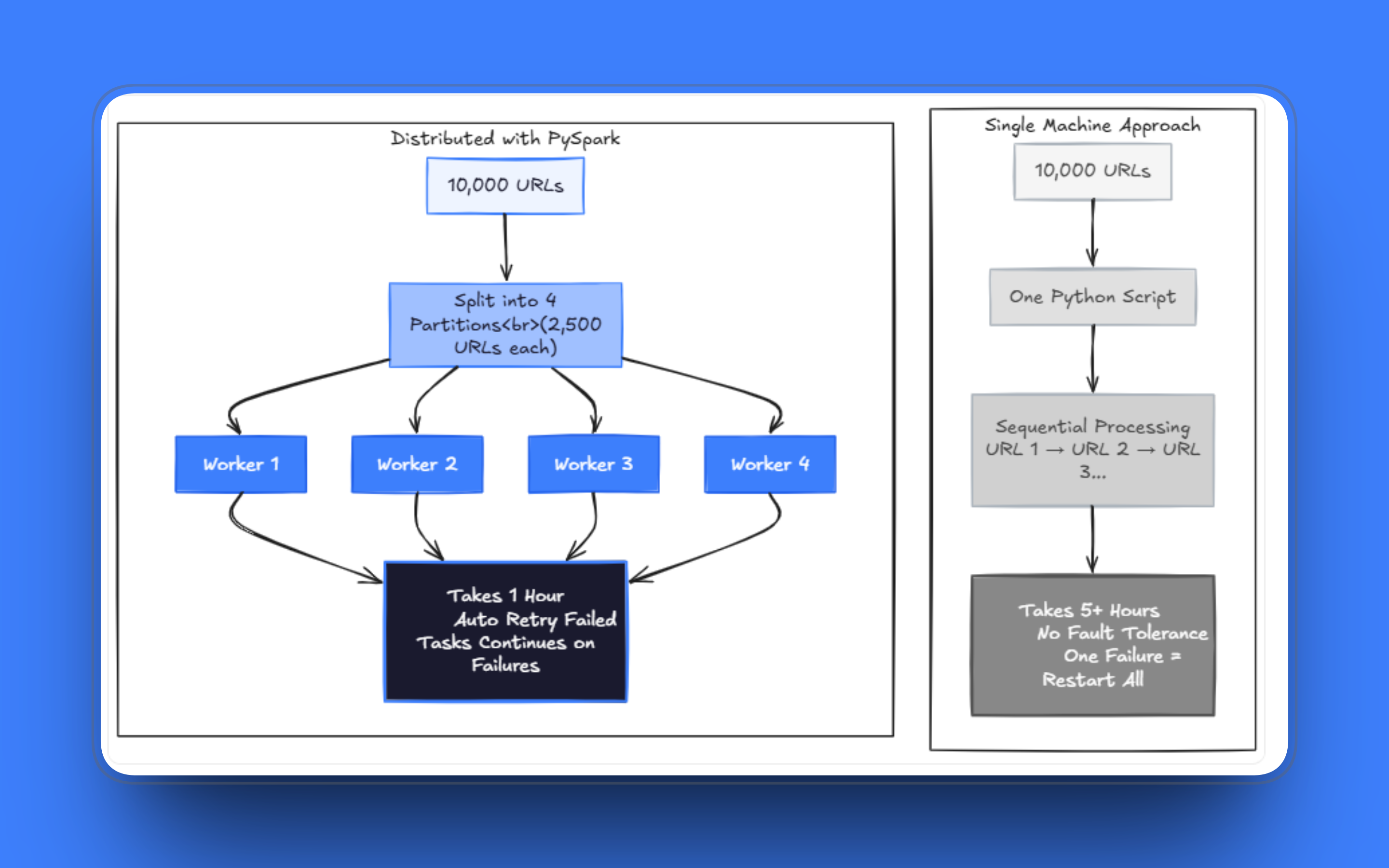
当工作负载扩张时,问题就会出现。原本几分钟的任务变成几小时;少量失败请求就可能在处理了上千页面之后让整次运行卡住;要在同一个脚本里既处理抓取与解析、又管理重试,很快就会变得混乱。我见过团队把这种单文件爬虫工具维护几个月,不断修补一个又一个边界情况,但真正的问题是:架构已经不适配当前问题规模了。
即便用了线程,在单机上抓取几十万页面也要花不现实的时间。规模化时,你需要在多个 worker 上并行运行,并且系统必须在一部分请求失败时依然能继续运行。正确方向是:不要把 URL 列表当作有序队列,而要把它当作可分发的数据集来处理。
为什么 PySpark 很适合这个场景
PySpark 的核心理念是:把数据集切分为多个分区,并在集群中并行处理。这个模型与网页抓取高度吻合:每个 URL 是一个工作单元;分区将 URL 聚成批次;executors 独立处理这些批次。
相比用 Celery 队列或自建多进程系统来编排任务,Spark 提供了容错与调度,而你无需自己实现。如果某个任务失败,Spark 会重新调度;如果节点掉线,工作会被重新分配。你仍需要在任务内部写合理的重试逻辑,但编排层由 Spark 负责。
模式 1:将 URL 作为分布式数据集
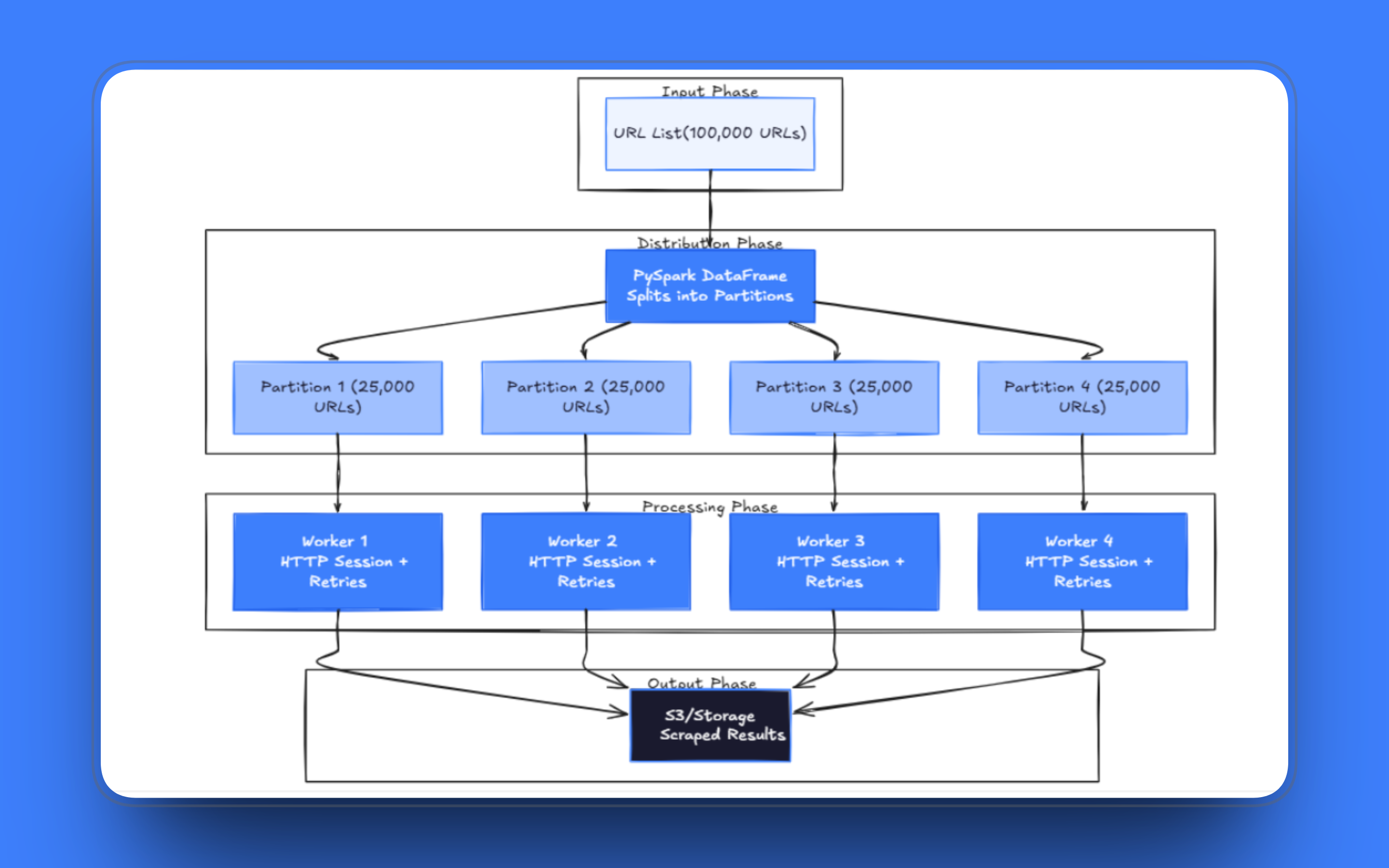
任何分布式抓取流水线的基础,都在于如何加载 URL 列表。使用 PySpark 时,把 URL 放入 DataFrame,Spark 会自动将其分发到各个 worker。每个分区保存数据切片,Spark 将分区分配给可用的 executors。
一个基本设置如下:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("distributed_scraper").getOrCreate()
urls = [
("https://example.com/page1",),
("https://example.com/page2",),
("https://example.com/page3",)
]
df = spark.createDataFrame(urls, ["url"])在生产环境中,你会从文件、数据库表或对象存储加载 URL 列表,而不是硬编码。随着你开始添加抓取优先级、上次抓取时间戳等元数据,schema 也会变得重要。
分区数是你面对的第一个调参决策。分区太少,worker 会因等待慢请求而空转;分区太多,Spark 会把过多时间花在调度开销上而不是实际抓取。
对抓取工作负载来说,一个合理起点是每个 executor core 配置 2 到 4 个分区,然后根据任务日志再调整。如果 executors 在 1 秒内完成分区,或经常需要超过 10 分钟才完成,说明分区大小需要调整。
模式 2:在分区层面发起请求
最自然的第一次尝试,是对 DataFrame 中每个 URL 做行级变换。这种方式能跑,但并不适合网页抓取。因为每个请求都会触发一次函数调用——除非你非常小心,否则每个 URL 都可能建立新连接。对数百万行来说,这种开销会迅速累积。
正确做法是使用 mapPartitions()。它不是一次处理一行,而是把整个分区作为迭代器交给你的函数。你可以只创建一次 HTTP session,并在分区内复用它来完成所有请求。与为每个 URL 建立新的 TCP 连接相比,复用长连接 session 的连接池会快得多,尤其是目标服务器支持 HTTP keep-alive 时。
from pyspark.sql import SparkSession
import requests
spark = SparkSession.builder.appName("distributed_scraper").getOrCreate()
urls = [
("https://example.com/page1",),
("https://example.com/page2",),
("https://example.com/page3",)
]
df = spark.createDataFrame(urls, ["url"])
def scrape_partition(rows):
session = requests.Session()
for row in rows:
url = row["url"]
try:
response = session.get(url, timeout=30)
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
except Exception:
yield {
"url": url,
"status_code": None,
"html": None
}
results = df.rdd.mapPartitions(scrape_partition)失败请求会返回一个字段为 null 的记录,而不是抛出异常。这是有意为之:如果异常向外传播,会直接终止整个分区任务,导致失败前已完成的工作全部丢失。返回 null 记录可以让分区继续运行,同时也为你后续识别并重试失败 URL 提供了干净方式。
还有一件值得尽早做的事:使用 StructType 明确定义输出 schema,而不是让 Spark 从 RDD 推断。schema 推断需要全量扫描数据,开销大;并且当响应内容意外为空时,有时还会产生不可预期的推断结果。
模式 3:设计能承受长时间运行的 worker
抓取 100 万页面的任务会运行数小时。在长时间运行过程中,你会遇到连接重置、DNS 超时、服务器限速导致的 429,以及服务器在响应中途断开连接等情况。这些不是你的代码 bug,只是规模化 HTTP 请求必然会发生的事情。
分区函数是处理这些问题的正确位置:重试逻辑、退避延迟(backoff)、超时设置、失败记录都应该放在这里。把这些都封装在一个分区函数中,能让 Spark 流水线的其他部分保持干净,并且你可以独立测试 worker 行为。
import requests
import time
def scrape_partition(rows):
session = requests.Session()
for row in rows:
url = row["url"]
attempts = 0
success = False
while attempts < 3 and not success:
try:
response = session.get(url, timeout=30)
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
success = True
except Exception as e:
attempts += 1
time.sleep(2 ** attempts) # exponential backoff
if not success:
yield {
"url": url,
"status_code": None,
"html": None
}这里有几点需要注意:重试延迟使用指数退避,而不是固定 sleep。固定 2 秒对偶发网络抖动可以,但当遇到持续限速的服务器时,会显著拖慢 worker。另一个建议是:在返回 null 记录前记录异常类型;连接超时与 403 Forbidden 对应的上游含义完全不同。
生产环境中的任务监控
当任务在数小时内处理数百万 URL 时,你需要在运行过程中看到发生了什么。至少,建议从每个分区追踪这些指标:
def scrape_partition(rows):
session = requests.Session()
partition_stats = {
"urls_attempted": 0,
"urls_succeeded": 0,
"urls_failed": 0,
"status_codes": {}
}
for row in rows:
partition_stats["urls_attempted"] += 1
url = row["url"]
attempts = 0
success = False
while attempts < 3 and not success:
try:
response = session.get(url, timeout=30)
partition_stats["urls_succeeded"] += 1
code = response.status_code
partition_stats["status_codes"][code] = \
partition_stats["status_codes"].get(code, 0) + 1
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
success = True
except Exception as e:
attempts += 1
time.sleep(2 ** attempts)
if not success:
partition_stats["urls_failed"] += 1
yield {
"url": url,
"status_code": None,
"html": None
}
# Log stats when partition completes
print(f"Partition stats: {partition_stats}")任务运行时请观察 Spark UI 的任务完成速率。如果不同任务完成速度差异很大,说明分区不平衡。如果日志中持续出现 403 或 429,说明你的代理轮换需要调整,或你需要增加请求延迟。目标是在任务仍在运行时就发现问题,而不是 6 小时后任务失败才知道。
从 worker 写出结果(生产模式)
对于运行超过一小时的任务,有一种失败模式是重试逻辑无法覆盖的:driver 进程在运行中途挂掉。Spark 能重跑失败的单个任务,但 driver 一旦挂掉,整个作业都会丢失。
解决方式是:每个分区完成后就把结果写入持久化存储,而不是把所有结果回传给 driver 并一直保存在内存里直到任务结束。使用 foreachPartition():它处理每个分区,并允许你从 worker 直接写出输出,避免数据再经过 driver:
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
import requests, time, uuid
spark = SparkSession.builder.appName("distributed_scraper").getOrCreate()
spark.sparkContext.setCheckpointDir("s3://your-bucket/checkpoints/")
schema = StructType([
StructField("url", StringType(), True),
StructField("status_code", IntegerType(), True),
StructField("html", StringType(), True)
])
def scrape_and_write(rows):
session = requests.Session()
results = []
for row in rows:
url = row["url"]
attempts = 0
success = False
while attempts < 3 and not success:
try:
response = session.get(url, timeout=30)
results.append((url, response.status_code, response.text))
success = True
except Exception as e:
attempts += 1
time.sleep(2 ** attempts)
if not success:
results.append((url, None, None))
# Write this partition's results directly from the worker
partition_id = str(uuid.uuid4())
spark.createDataFrame(results, schema).write.mode("append").parquet(
f"s3://your-bucket/scrape-results/batch={partition_id}"
)
df.rdd.foreachPartition(scrape_and_write)每个 worker 都会独立写出自己的输出文件。如果 driver 在中途挂掉,已完成的分区结果已经落到存储中,只需重跑进行中的分区即可。对于后续还要对抓取结果做 Spark 转换的任务,rdd.checkpoint() 是一种更轻量的替代方案:它会在转换前把 RDD 物化到 checkpoint 目录,防止后续阶段失败时 Spark 需要重放整个抓取步骤。
模式 4:通过代理网络路由请求
并行运行多个 worker 会提升吞吐,但目标站点看到的将是来自你集群 IP 段的一波密集请求。大多数网站都会针对这种“来自单一 IP 段的集中流量”配置限速或封禁。通过住宅代理网络路由请求,可把流量分散到多个 IP,从而帮助 worker 继续运行而不触发封锁。
你只需在分区函数中为 session 配置一次代理,该 session 发出的所有请求都会自动通过代理网络路由:
import requests
BRIGHTDATA_PROXY = (
"http://brd-customer-<customer_id>-zone-<zone_name>:"
"<zone_password>@brd.superproxy.io:33335"
)
def scrape_partition(rows):
session = requests.Session()
session.proxies = {
"http": BRIGHTDATA_PROXY,
"https": BRIGHTDATA_PROXY
}
for row in rows:
url = row["url"]
try:
response = session.get(url, timeout=30)
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
except Exception as e:
yield {
"url": url,
"status_code": None,
"html": None
}根据你的 Bright Data zone 配置,请求可能会抛出 SSL 校验错误,因为流量会经过其中间证书层。一个快速但不推荐的做法是传 verify=False 继续跑,但这会完全关闭证书校验,意味着 worker 无法再检测代理与目标之间的连接是否被篡改。
正确修复方式是下载 Bright Data 的 CA 证书,并通过 verify='/path/to/brightdata-ca.crt' 传入,从而保持完整校验。另一个需要注意的点:示例中的代理 URL 在生产环境中应来自环境变量或密钥管理器。在分布式环境里,这些凭证会被序列化并下发到每个 worker 节点,因此一旦泄露,影响范围会比单机更大。
对于需要 JavaScript 渲染内容的目标,仅使用标准代理还不够。Bright Data 的 Scraping Browser 可处理 JavaScript 执行、CAPTCHA 处理与浏览器指纹,并与 Playwright、Puppeteer 集成。分区函数结构保持不变;你只是把 requests session 换成一个指向 Scraping Browser endpoint 的 Playwright 浏览器实例。
常见问题排查
生产环境中有几个问题会反复出现。如果分区任务频繁超时,先检查分区大小。包含 10,000+ URL 的分区在请求较慢时会超过 Spark 默认超时。可以把分区重切成更小批次,或提高 spark.task.maxFailures 与 spark.network.timeout。
即便使用了代理仍出现 429,意味着多个 worker 同时在打同一个域名。可以在请求之间加随机抖动(jitter):
import random
import time
def scrape_partition(rows):
session = requests.Session()
for row in rows:
time.sleep(random.uniform(1, 3))
# ... rest of scraping logicexecutor 的内存错误通常意味着你在写出前累积了大量 HTML。更频繁地写出结果,或者如果你只需要提取字段,就在分区函数内解析后丢弃 HTML。
如果分区完成速度差异巨大,说明分布不均衡。可以提高分区数,把慢域名分散到更多 worker 上。
总结
这些模式为规模化提供了稳固基础:分发 URL 列表、在分区层面发起请求、构建能承受长时间运行的 worker,并通过代理网络路由流量,在请求量增长时保持不被封锁。
生产任务需要显式 schema、checkpoint 与正确的密钥管理,但无论规模大小,结构性决策都是一致的。在网络与基础设施方面,Bright Data覆盖了大量你原本需要自行构建与维护的内容。



技术写作者
Amitesh Anand 是一位开发者倡导者和技术写作者,分享有关 AI、软件和开发工具的内容,拥有 1 万粉丝和超过 40 万次观看。





