网页抓取在大规模收集数据方面发挥着重要作用,尤其是在需要快速且明智决策的场景中。
在本教程中,你将学习:
- 什么是 Midscene.js 以及它如何工作,
- 使用 Midscene.js 的限制,
- Bright Data 如何帮助克服这些挑战,
- 如何将 Midscene.js 与 Bright Data 集成以实现高效网页抓取
让我们开始吧!
什么是 Midscene.js?
Midscene.js 是一个开源工具,可使用简明的英语来自动化浏览器交互。你无需编写复杂脚本,只需输入诸如“点击登录按钮”或“在邮箱输入框输入内容”这样的命令。Midscene 随后会使用 AI 代理将这些指令转换为自动化步骤。
它还支持现代浏览器自动化工具,如 Puppeteer 和 Playwright,特别适用于测试、UI 自动化以及抓取动态网站等任务。
具体而言,它提供的主要功能包括:
- 自然语言控制:使用清晰的英文提示而非代码来自动化任务。
- 与 MCP 服务器的 AI 集成:通过 MCP 服务器连接到 AI 模型,辅助生成自动化脚本。
- 内置 Puppeteer 和 Playwright 支持:作为流行框架之上的高层封装,让工作流易于管理和扩展。
- 跨平台自动化:支持 Web(通过 Puppeteer/Playwright)和 Android(通过其 JavaScript SDK)。
- 零代码体验:提供 Midscene Chrome 扩展 等工具,无需编写任何代码即可构建自动化流程。
- 简单的 API 设计:提供简洁、文档完善的 API,高效与页面元素交互并提取内容。
使用 Midscene 进行浏览器自动化的限制
Midscene 使用 GPT-4o 或 Qwen 等 AI 模型,通过自然语言命令来自动化浏览器。它可与 Puppeteer 和 Playwright 等工具配合,但也存在关键限制。
Midscene 的准确性依赖于指令的清晰度和页面的结构。含糊的提示如“点击按钮”在页面存在多个类似按钮时可能失败。AI 依赖截图和页面视觉布局,因此细微的结构变化或缺少标签可能导致错误或误点。在一个网页有效的提示,在外观相似的另一个网页上可能无效。
为尽量减少错误,请编写清晰、具体且与页面结构相匹配的指令。在将提示集成到自动化脚本之前,务必先用 Midscene Chrome 扩展进行测试。
另一项关键限制是资源消耗高。Midscene 的每一步自动化都会将截图和提示发送给 AI 模型,尤其在动态或数据量大的页面上会使用大量 Token。这可能导致 AI API 的速率限制,并随着自动化步骤数量的增加而产生更高的使用成本。
Midscene 也无法与受保护的浏览器元素交互,如 CAPTCHA、跨域 iframe 或身份验证墙后的内容。因此,抓取安全或受限内容不可行。Midscene 最适用于静态或中度动态、且内容结构化且可访问的网站。
为什么 Bright Data 更有效
Bright Data 是一款强大的数据收集平台,帮助你构建、运行并扩展网页抓取业务。它为企业和开发者提供强大的代理基础设施、自动化工具和数据集,助你访问、提取并与任意公开网站交互。
- 处理动态和大量 JavaScript 的网站 Bright Data 提供多种工具,如 SERP API、Crawl API、Browser API 和 Unlocker API,帮助你访问、提取并与动态加载内容的复杂网站交互。这些工具使你能够从任何平台检索数据,非常适合电商、旅游和房地产等场景。
- 高效的代理基础设施 Bright Data 通过四大网络(Residential、Datacenter、ISP、Mobile)提供强大且灵活的代理基础设施。这些网络覆盖全球数以百万计的 IP 地址,使用户能够在最小化封锁的同时可靠地收集网页数据。
- 支持多媒体内容 Bright Data 支持从公开来源提取包括视频、图像、音频和文本在内的多种内容类型。其基础设施专为大规模媒体采集而设计,可支持训练计算机视觉模型、构建语音识别工具以及驱动自然语言处理系统等高级用例。
- 提供现成数据集 Bright Data 提供结构完备、质量高且可即用的现成数据集。这些数据集覆盖电商、招聘、房地产、社交媒体等多个领域,适用于不同行业和用例。
如何将 Midscene.js 与 Bright Data 集成
在本教程部分,你将学习如何使用 Midscene 和 Bright Data 的 Browser API 从网站抓取数据,以及如何将两者结合以获得更强的网页抓取能力。
为演示此过程,我们将抓取一个静态网页,其中展示了员工联系人卡片列表。我们将先分别使用 Midscene 和 Bright Data,然后通过 Puppeteer 集成两者,展示它们如何协同工作。
先决条件
要跟随本教程,请确保你具备以下条件:
- 一个 Bright Data 账户。
- 一个代码编辑器,如 Visual Studio Code、Cursor 等。
- 支持 GPT-4o 模型的OpenAI API Key。
- 具备 JavaScript 基础知识。
如果你还没有 Bright Data 账户,不必担心。我们会在下面的步骤中引导你创建。
步骤 #1:项目设置
打开终端,运行以下命令创建一个用于存放自动化脚本的新文件夹:
mkdir automation-scripts
cd automation-scripts使用以下代码片段在新建文件夹中添加 package.json 文件:
npm init -y将 package.json 的 type 从 commonjs 改为 module。
{
"type": "module"
}接着,安装必要包以启用 TypeScript 执行并访问 Midscene.js 功能:
npm install tsx @midscene/web --save然后安装 Puppeteer 和 Dotenv:
npm install puppeteer dotenvPuppeteer 是一个 Node.js 库,提供用于控制 Chrome 或 Chromium 的高级 API。Dotenv 用于安全存储你的 API 密钥。
现在,所有必要的包都已安装,我们可以开始编写自动化脚本。
步骤 #2:使用 Midscene.js 自动化网页抓取
继续之前,请在 automation-scripts 文件夹中创建 .env 文件,并将 OpenAI API Key 以环境变量的方式写入:
OPENAI_API_KEY=<your_openai_key>Midscene 使用OpenAI GPT-4o 模型,根据用户指令执行自动化任务。
然后,在该文件夹内创建一个文件:
cd automation-scripts
touch midscene.ts在文件中引入 Puppeteer、Midscene Puppeteer Agent 和 dotenv 配置:
import puppeteer from "puppeteer";
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import "dotenv/config";将以下代码片段添加到 midscene.ts 文件:
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
//👇🏻 initialize puppeteer
const browser = await puppeteer.launch({
headless: false,
});
//👇🏻 set the page config
const page = await browser.newPage();
await page.setViewport({
width: 1280,
height: 800,
deviceScaleFactor: 1,
});
/*
----------
👉🏻 Write automation scripts here 👈🏼
-----------
*/
})()
);
该代码片段在异步的 IIFE(立即执行函数表达式) 中初始化了 Puppeteer。这一结构允许你在顶层使用 await,而无需将逻辑包裹在多个函数调用中。
接着,在 IIFE 内添加以下代码:
//👇🏻 Navigates to the web page
await page.goto(
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>"
);
// 👇🏻 init Midscene agent
const agent = new PuppeteerAgent(page as any);
//👇🏻 gives the AI model a query
const items = await agent.aiQuery(
"get all the contacts details from the screen"
);
//👇🏻 Waits for 5secs
await sleep(5000);
// 👀 log the results
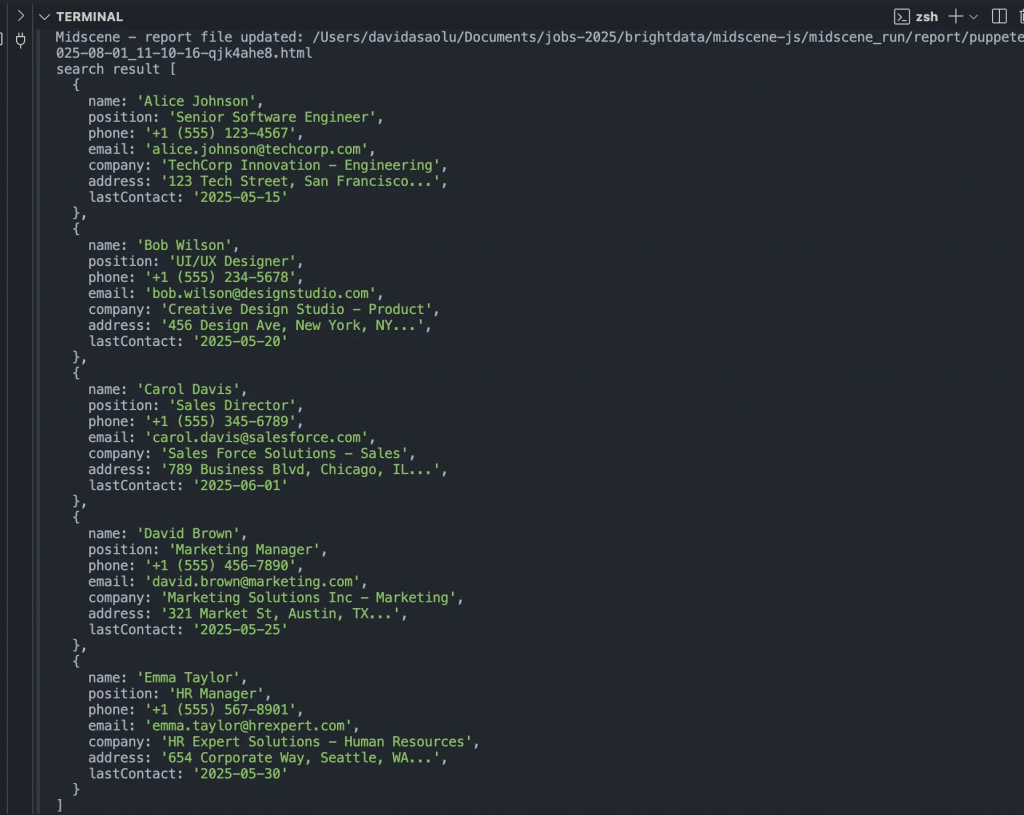
console.log("search result", items);上述代码将访问该网页地址,初始化 Puppeteer 代理,从网页中获取所有联系人信息,并将结果打印出来。
步骤 #3:使用 Bright Data Browser API 自动化网页抓取
在 automation-scripts 文件夹中创建 brightdata.ts 文件。
cd automation-scripts
touch brightdata.ts访问 Bright Data 首页 并创建账户。
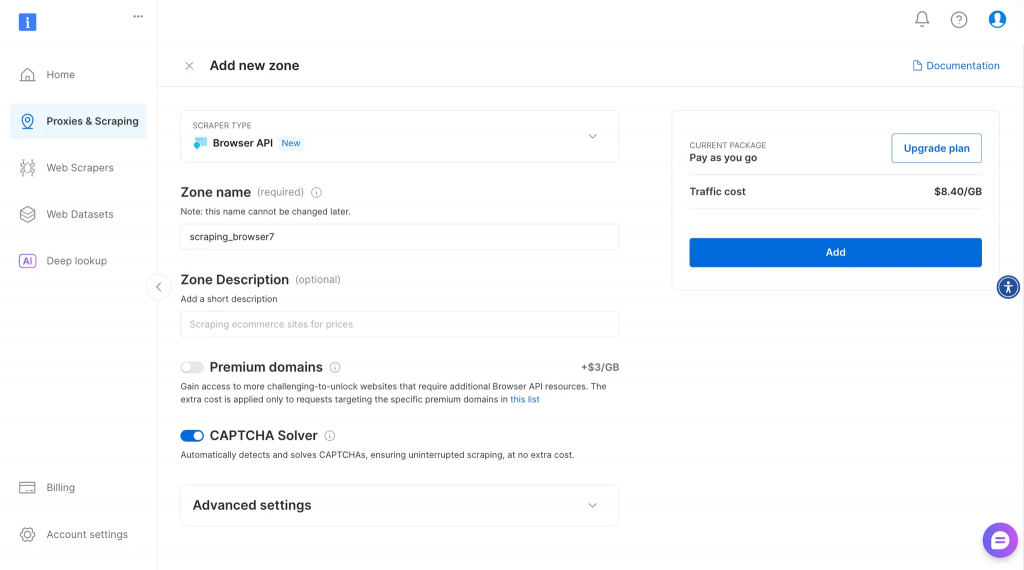
在控制台选择 Browser API,然后输入 Zone 名称和描述,创建一个新的 Browser API。
然后,复制你的 Puppeteer 凭据,并像下面这样将其保存到 brightdata.ts 文件中:
const BROWSER_WS = "wss://brd-customer-******";将 brightdata.ts 修改为如下内容:
import puppeteer from "puppeteer";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-******";
run(URL);
async function run(url: string) {
try {
/*
---------------------------
👉🏻 Web automation workflow 👈🏼
---------------------------
*/
//👇🏻 close the browser
await browser.close();
} catch (err) {
console.error("Error fetching data");
}
}上述代码声明了网页 URL 和 Bright Data 的 Browser API 凭据变量,并声明了一个接收 URL 作为参数的函数。
在“Web automation workflow”占位处添加如下代码:
//👇🏻 connect to Bright Data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to webpage
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 60000 });
console.log("Navigated! Waiting for popup...");下面的代码通过你的 API WebSocket 端点将 Puppeteer 连接到 Bright Data Browser。连接建立后,它会打开一个新的浏览器页面,并导航到传入 run() 函数的 URL。
最后,使用 CSS 选择器提取网页上的数据:
//👇🏻 Get contact details using CSS attribute
const contacts = await page.evaluate(() => {
const cards = document.querySelectorAll("#contactsGrid .contact-card");
return Array.from(cards).map((card) => {
const nameEl = card.querySelector(".contact-name");
const detailsEl = card.querySelectorAll(
".contact-details .detail-item span:not(.detail-icon)"
);
const metaEl = card.querySelector(".contact-meta");
if (!nameEl || !detailsEl.length || !metaEl) {
return null; // Skip if any required element is missing
}
const contact = {
name:
(nameEl as HTMLElement)?.dataset.name ||
(nameEl as HTMLElement)?.innerText.trim() ||
null,
jobTitle: (metaEl as HTMLElement)?.innerText.trim() || null,
phone: (detailsEl[0] as HTMLElement)?.innerText.trim() || null,
email: (detailsEl[1] as HTMLElement)?.innerText.trim() || null,
company: (detailsEl[2] as HTMLElement)?.innerText.trim() || null,
address: (detailsEl[3] as HTMLElement)?.innerText.trim() || null,
lastContact: (detailsEl[4] as HTMLElement)?.innerText.trim() || null,
};
return contact;
});
});
console.log("Contacts grid found! Extracting data...", contacts);上述代码遍历网页上的每个联系人卡片,并提取姓名、职位、电话号码、电子邮箱、公司、地址和最近联系日期等关键信息。
完整的自动化脚本如下:
import puppeteer from "puppeteer";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS ="wss://brd-customer-*******";
run(URL);
async function run(url: string) {
try {
//👇🏻 connect to Bright data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to webpage
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 60000 });
console.log("Navigated! Waiting for popup...");
//👇🏻 Get contact details using CSS attribute
const contacts = await page.evaluate(() => {
const cards = document.querySelectorAll("#contactsGrid .contact-card");
return Array.from(cards).map((card) => {
const nameEl = card.querySelector(".contact-name");
const detailsEl = card.querySelectorAll(
".contact-details .detail-item span:not(.detail-icon)"
);
const metaEl = card.querySelector(".contact-meta");
if (!nameEl || !detailsEl.length || !metaEl) {
return null; // Skip if any required element is missing
}
const contact = {
name: (nameEl as HTMLElement)?.dataset.name || (nameEl as HTMLElement)?.innerText.trim() || null,
jobTitle: (metaEl as HTMLElement)?.innerText.trim() || null,
phone: (detailsEl[0] as HTMLElement)?.innerText.trim() || null,
email: (detailsEl[1] as HTMLElement)?.innerText.trim() || null,
company: (detailsEl[2] as HTMLElement)?.innerText.trim() || null,
address: (detailsEl[3] as HTMLElement)?.innerText.trim() || null,
lastContact: (detailsEl[4] as HTMLElement)?.innerText.trim() || null,
};
return contact;
});
});
console.log("Contacts grid found! Extracting data...", contacts);
//👇🏻 close the browser
await browser.close();
} catch (err) {
console.error("Error fetching data");
}
}步骤 #4:使用 Midscene 与 Bright Data 的 AI 自动化脚本
Bright Data 通过与 Midscene 的集成,支持使用 AI 代理进行 Web 自动化。由于两者都支持 Puppeteer,将它们结合可以编写简单的 AI 驱动自动化流程。创建 combine.ts 文件,并将以下代码复制进去:
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import puppeteer from "puppeteer";
import "dotenv/config";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-******";
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
/*
---------------------------
👉🏻 Web automation workflow 👈🏼
---------------------------
*/
//👇🏻 close the browser
await browser.close();
})()
);上述代码创建了一个异步 IIFE,并包含一个 sleep 函数,便于在 AI 自动化脚本中添加延迟。
接着,在“Web automation workflow”占位处添加如下代码:
//👇🏻 connect to Bright Data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
//👇🏻 declares page
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to website
await page.goto(URL, { waitUntil: "domcontentloaded", timeout: 60000 });
// 👀 init Midscene agent
const agent = new PuppeteerAgent(page as any);
// 👇🏻 get contact details using AI agent
const items = await agent.aiQuery(
"get all the contacts details from the screen"
);
//👇🏻 delays for 5secs
await sleep(5000);
//👇🏻 logs the result
console.log("search result", items);
该代码初始化 Puppeteer 及其代理,导航到网页、获取所有联系人信息,并将结果打印到控制台。这展示了如何将 Puppeteer 的 AI 代理与 Bright Data Browser API 集成,借助 Midscene 的清晰指令实现自动化。
步骤 #5:整合在一起
在上一节中,你学习了如何将 Midscene 与 Bright Data Browser API 集成。完整的自动化脚本如下:
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import puppeteer from "puppeteer";
import "dotenv/config";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-*****";
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
//👇🏻 connect to Bright Data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to Booking.com
await page.goto(URL, { waitUntil: "domcontentloaded", timeout: 60000 });
// 👀 init Midscene agent
const agent = new PuppeteerAgent(page as any);
const items = await agent.aiQuery(
"get all the contacts details from the screen"
);
await sleep(5000);
console.log("search result", items);
await browser.close();
})()
);在终端运行以下命令以执行脚本:
npx tsx combine.ts上述命令将执行自动化脚本,并在控制台输出联系人详情。
[
{
name: 'Alice Johnson',
jobTitle: 'Senior Software Engineer',
phone: '+1 (555) 123-4567',
email: '[email protected]',
company: 'TechCorp Innovation - Engineering',
address: '123 Tech Street, San Francisco...',
lastContact: 'Last contact: 2026-05-15'
},
{
name: 'Bob Wilson',
jobTitle: 'UI/UX Designer',
phone: '+1 (555) 234-5678',
email: '[email protected]',
company: 'Creative Design Studio - Product',
address: '456 Design Ave, New York, NY...',
lastContact: 'Last contact: 2026-05-20'
},
{
name: 'Carol Davis',
jobTitle: 'Sales Director',
phone: '+1 (555) 345-6789',
email: '[email protected]',
company: 'Sales Force Solutions - Sales',
address: '789 Business Blvd, Chicago, IL...',
lastContact: 'Last contact: 2026-06-01'
},
{
name: 'David Brown',
jobTitle: 'Marketing Manager',
phone: '+1 (555) 456-7890',
email: '[email protected]',
company: 'Marketing Solutions Inc - Marketing',
address: '321 Market St, Austin, TX...',
lastContact: 'Last contact: 2026-05-25'
},
{
name: 'Emma Taylor',
jobTitle: 'HR Manager',
phone: '+1 (555) 567-8901',
email: '[email protected]',
company: 'HR Expert Solutions - Human Resources',
address: '654 Corporate Way, Seattle, WA...',
lastContact: 'Last contact: 2026-05-30'
}
]步骤 #6:下一步
本教程展示了将 Midscene 与 Bright Data Browser API 集成所能实现的能力。你可以在此基础上继续扩展,自动化更复杂的工作流。
通过结合这两种工具,你可以高效且可扩展地完成以下浏览器自动化任务:
- 从动态或大量 JavaScript 的网站抓取结构化数据
- 自动化表单提交用于测试或数据收集
- 使用自然语言指令导航网站并与元素交互
- 借助代理管理与 CAPTCHA 处理运行大规模数据提取任务
结论
至此,你已经学习了如何使用 Midscene 和 Bright Data Browser API 自动化网页抓取流程,以及如何通过 AI 代理同时使用这两种工具来抓取网站。
Midscene 在浏览器自动化方面高度依赖 AI 模型,将其与 Bright Data 抓取浏览器配合使用,能够在减少代码量的同时实现高效的网页抓取功能。Browser API 只是 Bright Data 各类工具与服务如何赋能高级 AI 驱动自动化的一个例子。
立即注册,探索全部产品。



AI 内容创作者
Arindam Majumder 是一名开发者推广专员、YouTube博主和技术作家,专注于将大语言模型 (LLM)、智能体工作流及 AI 内容讲解得简单易懂,拥有超过5000名关注者。