
上下文(如文化、环境或关系上下文)存在于所有通信中,并会影响通信效率。在网络通信中,HTTP 标头是网络服务器和客户端在发送 HTTP 请求或接收 HTTP 响应时进行交换的技术上下文。这种上下文可用于促进身份验证、确定缓存行为或管理会话状态。它还可以帮助网络服务器确定 HTTP 请求的来源以及对其的响应方式。这种响应可能包括渲染网站以满足客户端设备的要求,或向您提供数据。而使用机器人完成后一响应的操作即为网页抓取,当您需要从网站自动获取数据时,该操作非常有用。
人们在构建抓取工具时,经常忽视 HTTP 标头配置一事,因为默认设置让系统可以继续执行他们的请求。但是,一旦没有适当配置 HTTP 标头,就很难让抓取工具和网络服务器之间保持持续的通信。这是因为站点所有者可以根据默认 HTTP 标头中的信息,例如用户代理 (User-Agent)、引荐页 (Referer) 和接受语言 (Accept-Language),来设置网络服务器,以检测机器人和自动脚本。
然而,如果您正确配置标头,就可以模拟正常的用户流量,从而增强抓取操作的可靠性。在本文中,您将全面了解 HTTP 标头及其在网页抓取中的作用,并深入学习它们的优化技巧,以实现有效的数据采集。
为何需要 HTTP 标头
HTTP 标头是网络通信所需的请求和响应中的键值对。网络服务器通过请求标头接收有关客户端和相关资源的信息和指令。同时,响应标头为客户端提供更多有关获取的资源和收到的响应的信息。HTTP 标头有很多种,以下是在网页抓取时至关重要的几种标头:
用户代理
用户代理是一个字符串,用于唯一标识发送请求的客户端。该字符串的内容可能包括应用程序的类型、操作系统、软件版本和软件供应商。
默认情况下,该标头的参数设置值很容易让您的抓取工具被识别为机器人。例如,如果您想使用 Python 请求脚本从电子商务网站上抓取价格数据,则您的抓取工具将在其 HTTP 标头中发送类似与下方内容的用户代理信息:
"python-requests/X.X.X"
不过,您可以通过更改用户代理来模仿不同的浏览器和设备,从而避免抓取工具被发现。为此,您需要将 Python 请求的用户代理标头信息替换成以下内容:
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36"
这个新标头包含浏览器及其运行的本机平台的信息。
接受语言
接受语言标头用于指定您希望以哪种语言接收请求的资源。如有必要,您还可以添加国家/地区代码或字母类型,例如,如果您将接受语言设置为 “en-US”,则表示即使您身处其他大洲,也希望所请求的资源使用美国英语。您也可以使用字母类型定义标头,例如指定接受语言为 “sr-Latn”,从而将标头定义为拉丁字母版的塞尔维亚语。这可以确保您检索到相应的本地化数据。
当有多种语言时,接受语言标头会变成以逗号分隔的语言列表,其中包含的质量值用于定义接受语言的优先级顺序。以 “en -GB;q=1.0, en-US;q=0.9, fr;q=0.8” 为例,“q” 值越大,优先级越高,且 “q” 值的范围为 0 至 1。
Cookie
Cookie 标头包含可让网络服务器在多个请求-响应周期中识别用户会话的数据。抓取时,您可以在客户端生成 Cookie (或使用以前存储的 Cookie),并将它们包含在新请求的 HTTP 标头中。这使得网络服务器能够将您的请求与有效的用户会话进行关联,并返回所需数据。例如,如果您需要发出多个请求以从电子商务网站上获取特定于用户的数据,则应在 HTTP 请求的 Cookie 标头中包含会话 Cookie,以便抓取工具保持登录状态、保存相关数据,并避开基于 Cookie 的机器人检测系统。
Cookie 标头由一个或多个由分号和空格 (“; ”) 隔开的键值对列表组成。它通常采用 “name0=value0; name1=value1; name2=value2” 这样的格式。
引荐页
引荐页包含请求资源的来源页面的绝对或部分 URL。例如,您在浏览电子商务网站的主页时,可能会点击引起您兴趣的链接。打开下一网页的 HTTP 请求的引荐页标头指向您发起请求的电子商务网站的主页。如果您从当前网页导航至其他网页,则之前查看的每个页面都将充当下一网页的引荐页。这类似于人际交往中的推荐机制。
当然,作为反爬取机制的一部分,一些网站会审查此类标头。这意味着,如果您想模拟其他网站的自然流量并避免被屏蔽,则需要将引荐页标头设置为有效的 URL,例如相关网站的主页或搜索引擎的 URL。
如何优化网页抓取的 HTTP 标头
在进行抓取时请谨记一点:您需要的数据对站点所有者来说非常宝贵,他们可能不愿意分享这些数据。因此,许多站点所有者都会采取措施,以发现想要访问其内容的自动代理。一旦被检测到,他们就会屏蔽您或返回无关数据。
HTTP 标头可以让您的抓取工具看起就像是浏览其网站的普通互联网用户,从而帮助您绕过这些安全措施。正确设置标头(如用户代理、接受、接受语言和引荐页等)可以让您有效模仿正常的网络流量,从而让网络服务器难以将您的机器人识别为抓取工具。
检索和设置自定义标头
我们将通过以下演示为您讲解 HTTP 标头的优化技巧:发出一个 Python 请求,以从虚拟电子商务网站 Books to Scrape 抓取悬疑推理图书。在执行此操作之前,您需要从浏览器的开发者工具中获取 HTTP 标头。
首先,在新的浏览器标签页上访问该网站:
然后在浏览器中启动开发者工具。您也可以右键单击页面上的任意位置并选择“检查 (Inspect)” 或查看工具子列表,完成此步操作。在开发者工具窗口,点击顶部菜单栏中的“网络 (Network)” 选项卡:
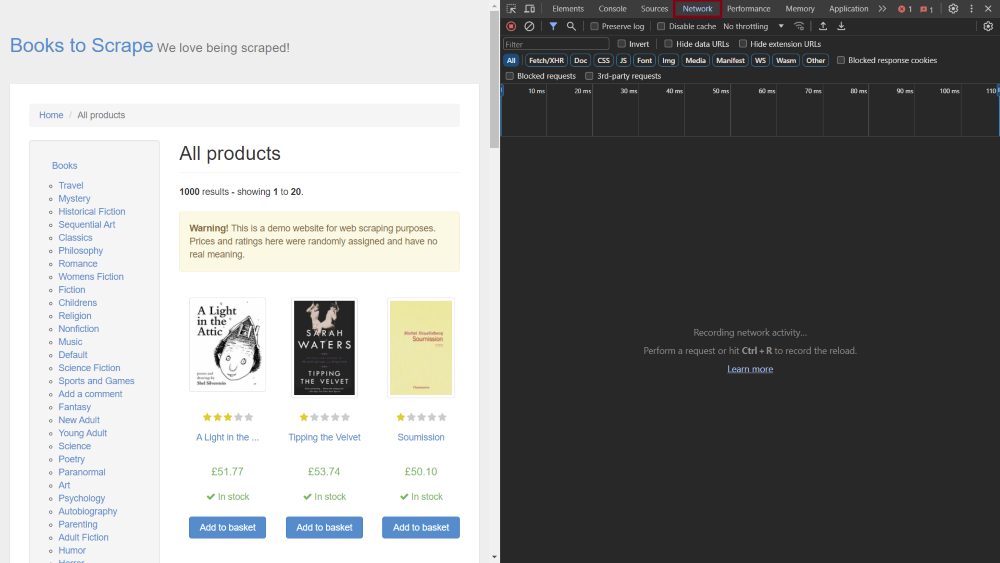
打开“网络 (Network)” 选项卡后,勾选“禁用缓存 (Disable cache)” 旁边的复选框。这样,您就可以查看整个请求标头。然后点击网站类别列表中的“悬疑推理 (Mystery)” 类别链接。这将打开包含该类别图书的页面,但更重要的是,请求列表会显示在开发者工具窗口上的“网络 (Network)” 选项卡中:
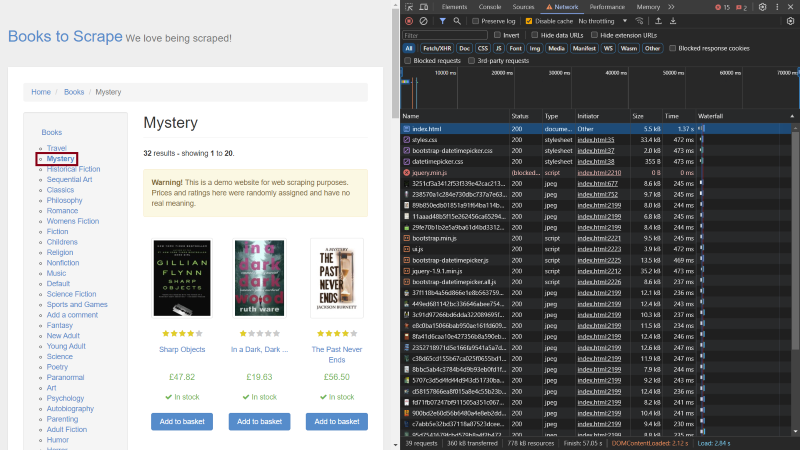
滚动至列表顶部并点击第一项。这将在开发者工具中打开一个小窗口。滚动至“请求标头 (Request Headers)”:
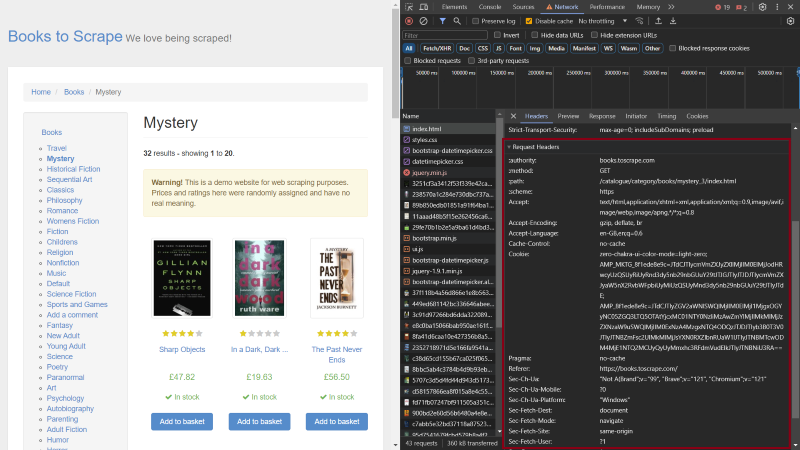
在“请求标头 (Request Headers)” 下,您可以找到 HTTP 请求标头,尤其是您刚刚看过的那些请求标头。要将这些标头与抓取工具一起使用,请先创建一个 Python 脚本,其中包含用户代理标头、接受标头、接受语言标头、Cookie 标头和引荐页标头的变量:
import requests
referer = "https://books.toscrape.com/"
accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8"
accept_language = "en-GB,en;q=0.6"
cookie = "zero-chakra-ui-color-mode=light-zero; AMP_MKTG_8f1ede8e9c=JTdCJTIycmVmZXJyZXIlMjIlM0ElMjJodHRwcyUzQSUyRiUyRnd3dy5nb29nbGUuY29tJTJGJTIyJTJDJTIycmVmZXJyaW5nX2RvbWFpbiUyMiUzQSUyMnd3dy5nb29nbGUuY29tJTIyJTdE; AMP_8f1ede8e9c=JTdCJTIyZGV2aWNlSWQlMjIlM0ElMjI1MjgxOGYyNC05ZGQ3LTQ5OTAtYjcxMC01NTY0NzliMzAwZmYlMjIlMkMlMjJzZXNzaW9uSWQlMjIlM0ExNzA4MzgxNTQ4ODQzJTJDJTIyb3B0T3V0JTIyJTNBZmFsc2UlMkMlMjJsYXN0RXZlbnRUaW1lJTIyJTNBMTcwODM4MjE1NTQ2MCUyQyUyMmxhc3RFdmVudElkJTIyJTNBNiU3RA=="
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36"
custom_headers = {
"User-Agent": user_agent,
"Accept": accept,
"Accept-Language": accept_language,
"Cookie": cookie,
"Referer": referer
}
在此代码片段中,您导入了“请求”库,并将每个 HTTP 标头的变量定义为字符串。然后创建一个名为“标头”的字典,将 HTTP 标头名称映射至定义的变量。
接下来,将下方代码添加至脚本,发送不含自定义标头的 HTTP 请求并打印结果:
URL = 'https://books.toscrape.com/catalogue/category/books/mystery_3/index.html'
r = requests.get(URL)
print(r.request.headers)
在这里,您为悬疑推理书籍的 URL 分配了一个变量。然后,将此 URL 作为唯一参数调用 requests.get 函数并打印请求标头。
输出结果应如下所示:
{'User-Agent': 'python-requests/2.31.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
如您所见,默认的 HTTP 标头很可能让您的抓取工具被识别为机器人。通过向该函数传递一个附加参数来更新 requests.get 行:
r = requests.get(URL, headers=custom_headers)
在这里,您将创建的自定义标头 (custom_header) 字典和 URL 参数传递给 requests.get 函数。
输出结果应如下所示:
{'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8', 'Connection': 'keep-alive', 'Accept-Language': 'en-GB,en;q=0.6', 'Cookie': 'zero-chakra-ui-color-mode=light-zero; AMP_MKTG_8f1ede8e9c=JTdCJTIycmVmZXJyZXIlMjIlM0ElMjJodHRwcyUzQSUyRiUyRnd3dy5nb29nbGUuY29tJTJGJTIyJTJDJTIycmVmZXJyaW5nX2RvbWFpbiUyMiUzQSUyMnd3dy5nb29nbGUuY29tJTIyJTdE; AMP_8f1ede8e9c=JTdCJTIyZGV2aWNlSWQlMjIlM0ElMjI1MjgxOGYyNC05ZGQ3LTQ5OTAtYjcxMC01NTY0NzliMzAwZmYlMjIlMkMlMjJzZXNzaW9uSWQlMjIlM0ExNzA4MzgxNTQ4ODQzJTJDJTIyb3B0T3V0JTIyJTNBZmFsc2UlMkMlMjJsYXN0RXZlbnRUaW1lJTIyJTNBMTcwODM4MjE1NTQ2MCUyQyUyMmxhc3RFdmVudElkJTIyJTNBNiU3RA==', 'Referer': 'https://books.toscrape.com/'}
此时,您可以看到标头已使用从浏览器获得的信息进行了更新。如此一来,任何网络服务器都更难发现您正在自动访问他们的网站,从而降低您被屏蔽的几率。
优化标头的好处
适当优化 HTTP 标头对于确保抓取操作的持续成功至关重要。
优化标头的一大好处是降低被拦截几率。优化标头后,抓取工具与网站的交互就类似于普通用户与网站的交互。因此,您可以避开一些机器人检测系统,降低抓取工具随时间推移被屏蔽的风险(被拦截率)。
优化 HTTP 标头的另一个好处是可以提高成功率,因为被拦截率的降低使得数据抓取工作变得更容易。
此外,用心优化 HTTP 标头还能提高抓取效率,确保您收到符合需求的数据。
标头优化技巧
适当配置标头对于确保网络抓取项目的成功至关重要,但您不能止步于此——尤其当您需要大规模抓取数据时。以下是提高抓取成功率的一些小技巧:
轮换标头
除了通过定义用户代理等标头来模仿普通用户的正常流量,您还可以定义几个不同的 HTTP 标头,并在每个请求之间轮换它们。如此一来,您就可以模拟多个用户访问网络服务器并为它们分配生成的流量。这将进一步降低您被识别为机器人并遭到屏蔽的几率。
您可以使用十到数百个用户代理,具体视您的抓取规模而定。短时间内需要发送的请求越多,就越有必要在更多的用户代理之间进行切换。
保持标头更新
在优化 HTTP 标头时,另一注意事项是要定期维护标头。用户通常会在浏览器新版本发布后进行更新,因此任何给定时间内的有效标头都很有可能与最新版浏览器的标头相一致。如果您使用一个或多个涉及过时的浏览器或软件版本的用户代理来设置标头,那网络服务器将能区分您与普通用户,从而可能屏蔽您的请求。这一注意事项同样适用于其他需要经常更新的标头。
避免错误的标头配置
您还应该努力避免错误的标头配置。当一个标头(如用户代理)与您设置的其他标准标头不匹配时,就会发生这种情况。例如,如果用户代理被设置为在 Windows 上运行的 Mozilla Firefox 浏览器,而其余标头被定义为在 Windows 上运行的 Chromium 浏览器,则您的抓取工具很有可能被屏蔽。
此外,当您使用代理服务器(充当客户端和服务器之间的中介)时,您可能会不小心添加识别标头,使得浏览器端的检测系统将您的请求识别为自动请求。要检查标头,请发送测试请求,确保代理服务器未添加识别标头。
结语
在本文中,您了解了以下 HTTP 标头:用户代理标头、引荐页标头、接受语言标头和 Cookie 标头,它们是至关重要的网络抓取标头。您必须优化 HTTP 标头,以确保抓取操作的持续性和有效性。
在网页抓取项目中,适当使用 HTTP 标头发出请求不但可以降低被拦截率,还能让您更容易绕过反抓取机制,提高抓取成功率。它还让您的抓取操作变得更高效。但是,涉及 JavaScript 挑战和验证码的高级反抓取机制仍可能造成阻碍。Bright Data 通过为您提供屡获殊荣且用户友好的代理网络、先进的抓取浏览器、全面的 Web Scraper IDE 和网络解锁器,简化您的抓取操作。无论您是初学者还是专业人士,这些产品都能助您实现抓取目标。立即开始免费试用,探索 Bright Data 的产品。





