

从 Pinterest 提取数据与大多数 HTML 抓取任务 不同。Pinterest 的所有内容都是动态生成的,并不会在页面上留下任何像 JSON 这样的数据结构。
可以提取哪些数据?
在浏览器中查看 Pinterest 时,所有的 pin 都深度嵌套在一个带有 data-test-id="pinWrapper" 的 div 元素中。
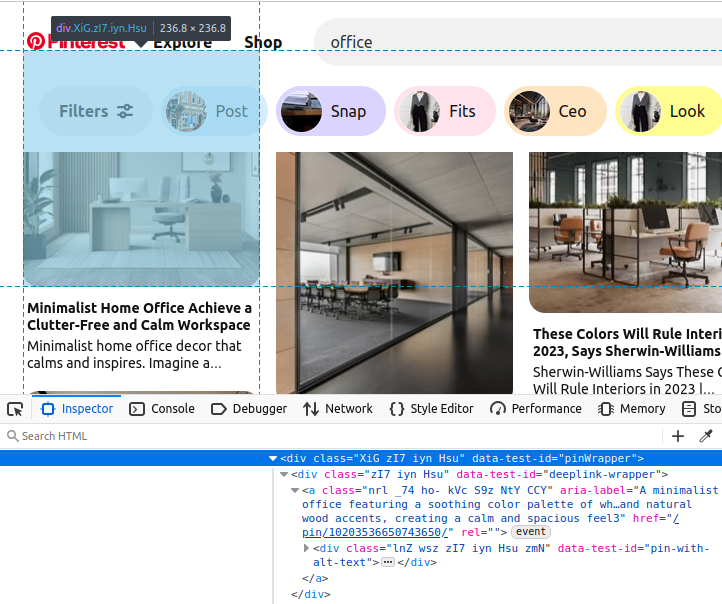
如果我们能在页面上找到这些对象,就能提取它们的所有数据,例如:
- 每个 pin 的标题。
- 直接指向该 pin 的链接。
- 搜索结果中该 pin 的图像。
使用 Playwright 抓取 Pinterest
快速开始
在 Python 中有很多优秀的 爬虫库,我们会使用 Playwright。首先,你需要确保已经安装了 Playwright。可以在 这里 查看他们的文档。Playwright 是目前最好的 无头浏览器 之一。
安装 Playwright
pip install playwright安装 Playwright 的浏览器
playwright install实际爬取 pin
现在,来看看如何从 Pinterest 抓取实际的 pin。下面的代码中,我们创建了两个函数:scrape_pins() 和 main()。其中,scrape_pins() 用于打开浏览器并从 Pinterest 中提取数据;main() 则充当异步运行的入口点。
import asyncio
from playwright.async_api import async_playwright
import json
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36"
async def scrape_pins(query):
search_url = f"https://www.pinterest.com/search/pins/?q={query}&rs=typed"
scraped_data = []
async with async_playwright() as p:
browser = await p.chromium.launch()
page = await browser.new_page(user_agent=user_agent)
response = await page.goto(search_url)
await asyncio.sleep(2)
try:
#find the pins on the page
pins = await page.query_selector_all("div[data-test-id='pinWrapper']")
#iterate through the pins and extract data
for pin in pins:
title_link = await pin.query_selector("a")
pin_url = await title_link.get_attribute("href")
title = await title_link.get_attribute("aria-label")
img = await title_link.query_selector("img")
img_src = await img.get_attribute("src")
extracted_data = {
"title": title,
"url": pin_url,
"img": img_src
}
#add the data to our results
scraped_data.append(extracted_data)
except:
print(f"Failed to scrape pins at {search_url}")
finally:
await browser.close()
#everything has finished, return our scraped data
return scraped_data
async def main():
search_query = "office"
office_results = await scrape_pins(search_query)
with open(f"{search_query}-results.json", "w") as file:
try:
json.dump(office_results, file, indent=4)
except Exception as e:
print(f"Failed to save results: {e}")
if __name__ == "__main__":
asyncio.run(main())在 scrape_pins() 中,我们的爬取过程主要执行如下步骤:
- 创建 URL:
search_url。 - 创建一个用于保存结果的数组:
scraped_data。 - 打开一个新的浏览器实例。
- 设置自定义的
user_agent以使 Playwright 在无头模式下运行,否则 Pinterest 会阻止我们。 - 使用
asyncio.sleep(2)等待两秒,以便页面内容加载。 - 使用
div[data-test-id='pinWrapper']选择器查找页面上所有可见的 pin。 - 对每个 pin,提取以下数据:
title:pin 的标题。url:指向该 pin 的直接链接。img:在搜索结果中展示的 pin 图片。
下面是使用上述 Playwright 爬虫得出的部分示例数据。
[
{
"title": "A minimalist office featuring a soothing color palette of whites, greys, and natural wood accents, creating a calm and spacious feel3",
"url": "/pin/10203536650743650/",
"img": "https://i.pinimg.com/236x/b3/21/e2/b321e2485da40c0dde2685c3a4fdcb56.jpg"
},
{
"title": "a home office with two desks and an open door that leads to the outside",
"url": "/pin/261912534574291013/",
"img": "https://i.pinimg.com/236x/56/f1/29/56f129512885e1b3c9971b16f9445c9a.jpg"
},
{
"title": "home office decor, blakc home office, dark home office, moody home office, small home office",
"url": "/pin/60094976273327121/",
"img": "https://i.pinimg.com/236x/ba/75/c9/ba75c9be7e635cce3ee80acdf70d6f9f.jpg"
},
{
"title": "an office with a desk, chair and bookshelf in the middle of it",
"url": "/pin/599682506666665720/",
"img": "https://i.pinimg.com/236x/57/66/1d/57661dc80bebda3dfe946c070ee8ed13.jpg"
},
{
"title": "a home office with green walls and plants on the shelves, along with a computer desk",
"url": "/pin/1147080967585091410/",
"img": "https://i.pinimg.com/236x/ce/e8/b7/cee8b74151b29605a80e0f61898c249d.jpg"
},使用 Bright Data Scraper API 抓取 Pinterest
借助我们的 Pinterest Scraper API,你可以完全自动化这个流程,无需担心无头浏览器、选择器或其他细节!
请确保已经安装了 Python Requests 。
安装 Requests
pip install requests在你设置好 API 调用后,就可以通过 Python 触发它。下面代码中同样包含了两个函数:get_pins() 和 poll_and_retrieve_snapshot()。
get_pins():该函数接收keyword和api_key,然后创建并发送对我们 Scraper API 的请求,用于触发对 Pinterest 的搜索和抓取。poll_and_retrieve_snapshot():该函数接收api_key和snapshot_id,它每隔 10 秒检查一次数据是否准备就绪。一旦数据准备完成,就会下载快照并退出函数。
import requests
import json
import time
#function to trigger the scrape
def get_pins(api_key, keyword):
url = "https://api.brightdata.com/datasets/v3/trigger"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
params = {
"dataset_id": "gd_lk0sjs4d21kdr7cnlv",
"include_errors": "true",
"type": "discover_new",
"discover_by": "keyword",
}
data = [
{"keyword":keyword},
]
#trigger the scrape
response = requests.post(url, headers=headers, params=params, json=data)
#return the snapshot_id
return response.json()["snapshot_id"]
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file="snapshot-data.json"):
#create the snapshot url
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot is ready. Downloading...")
snapshot_data = response.json()
#write the snapshot to a new json file
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
break
elif response.status_code == 202:
print("Snapshot is not ready yet. Retrying in 10 seconds...")
else:
print(f"Error: {response.status_code}")
print(response.text)
break
time.sleep(10)
if __name__ == "__main__":
API_KEY = "YOUR-BRIGHT-DATA-API-KEY"
KEYWORD = "office"
snapshot_id = get_pins(API_KEY, KEYWORD)
poll_and_retrieve_snapshot(API_KEY, snapshot_id)下面是下载到的文件中的部分示例数据。由于我们在触发请求时设置了 "include_errors": "true",文件中同时包含了出现错误的 pin 和正常数据。示例数据中有两个错误的 pin,也有两个包含完整数据的 pin。
[
{
"post_type": null,
"timestamp": "2026-02-17T15:26:17.248Z",
"input": {
"url": "https://www.pinterest.com/pin/jh46IGe2",
"discovery_input": {
"keyword": "office"
}
},
"warning": "Bad input. Wrong id!",
"warning_code": "dead_page",
"discovery_input": {
"keyword": "office"
}
},
{
"post_type": null,
"timestamp": "2026-02-17T15:26:18.757Z",
"input": {
"url": "https://www.pinterest.com/pin/4471026676503806548",
"discovery_input": {
"keyword": "office"
}
},
"warning": "Bad input. Page does not exist.",
"warning_code": "dead_page",
"discovery_input": {
"keyword": "office"
}
},
{
"url": "https://www.pinterest.com/pin/929782285570058239",
"post_id": "929782285570058239",
"title": "Essential Tips for Designing a Functional Small Office Space: Maximize Efficiency",
"content": "17 Smart Tips for Designing a Productive Small Office Space",
"date_posted": "2026-02-06T15:00:47.000Z",
"user_name": "wellnesswink",
"user_url": "https://www.pinterest.com/wellnesswink",
"user_id": "929782422978147260",
"followers": 232,
"likes": 0,
"categories": [
"Explore",
"Home Decor"
],
"attached_files": [
"https://i.pinimg.com/originals/c8/c0/d5/c8c0d5fb45352e40535db4510049a142.jpg"
],
"image_video_url": "https://i.pinimg.com/originals/c8/c0/d5/c8c0d5fb45352e40535db4510049a142.jpg",
"video_length": 0,
"post_type": "image",
"comments_num": 0,
"discovery_input": {
"keyword": "office"
},
"timestamp": "2026-02-17T15:26:19.502Z",
"input": {
"url": "https://www.pinterest.com/pin/929782285570058239",
"discovery_input": {
"keyword": "office"
}
}
},
{
"url": "https://www.pinterest.com/pin/889812838892568569",
"post_id": "889812838892568569",
"title": "20 Modern Masculine Home Office Design Ideas for Men",
"content": "Explore 25 chic home office decor ideas that blend style and functionality. Create a workspace you love and boost your productivity effortlessly!",
"date_posted": "2026-01-27T07:11:38.000Z",
"user_name": "artfullhouses",
"user_url": "https://www.pinterest.com/artfullhouses",
"user_id": "889812976285233957",
"followers": 10,
"likes": 0,
"categories": [
"Explore",
"Home Decor"
],
"attached_files": [
"https://i.pinimg.com/originals/f1/cb/f7/f1cbf7b127db2bef2306ba19ffcc0646.png"
],
"image_video_url": "https://i.pinimg.com/originals/f1/cb/f7/f1cbf7b127db2bef2306ba19ffcc0646.png",
"video_length": 0,
"hashtags": [
"Mens Desk Decor",
"Chic Home Office Decor",
"Mens Desk",
"Home Office Ideas For Men",
"Office Ideas For Men",
"Masculine Home Office Ideas",
"Masculine Home Office",
"Masculine Home",
"Chic Home Office"
],
"post_type": "image",
"comments_num": 0,
"discovery_input": {
"keyword": "office"
},
"timestamp": "2026-02-17T15:26:20.069Z",
"input": {
"url": "https://www.pinterest.com/pin/889812838892568569",
"discovery_input": {
"keyword": "office"
}
}
},可以看到,Scraper API 收集到的数据量远远大于我们用 Playwright 编写的初始爬虫。我们的 API 在爬取 Pinterest 关键词时,会对找到的所有 pin 进行爬取并保存。
这种方法不仅方便,而且我们的 Pinterest Scraper API 还能以极低的成本提取数据。我们的结果文件总共有接近 45,000 行,生成它只花费了 0.97 美元。

如果雇人来编写质量相同的爬虫,可能会花费几百美元,而且你还要等待数天才能获取数据。借助我们的 Scraper API,你只需花费一小部分成本并在几分钟内就能拿到数据。
结论
想要从 Pinterest 中提取数据并不困难。无论你是使用 Playwright 构建自己的爬虫,还是选择一个像我们 Pinterest Scraper 这样的全自动化解决方案,最合适的方法取决于你的实际需求。
如果你想快速、可靠且具备可扩展性地获取 Pinterest 数据,Bright Data 的 Scraper API 能够免去无头浏览器、代理以及验证码等诸多烦恼,直接呈现结构化数据。
✅ 更快的结果 – 几分钟即可获取数据,而非数小时
✅ 成本更低 – 只为提取到的数据付费
✅ 零维护 – 无需应对被阻止的请求
立即开始免费试用,让 Bright Data 的 Web Scraper API 改善你的 Pinterest 抓取流程吧!



技术写作者
 6 years experience
6 years experience
Jacob Nulty 是一位常驻底特律的软件开发者和技术写作者,探索人工智能与人类哲学,具备 Python、Rust 和区块链方面的经验。





