

在这篇博客文章中,你将看到:
- Convex 是什么、它的心智模型如何运作,以及它与其他数据库的对比。
- Convex 的详细工作原理,以及它依赖的核心组件。
- 为什么 Convex 在存储实时网页数据时表现突出。
- 从网页获取实时数据的主要障碍与挑战。
- Bright Data 如何通过提供结构化的实时网页数据来帮助解决这些挑战,使其可直接存入 Convex。
- 如何开始使用一个完整 demo:Bright Data 负责获取网页数据,Convex 负责数据存储与无缝 UI 更新。
我们开始吧!
Convex 简介
第一步是了解 Convex:它是什么、能带来什么价值,以及它背后的核心心智模型。
什么是 Convex?
Convex 是一个开源、响应式(reactive)的后端平台,旨在让你的 Web 与移动应用保持同步。
在底层,它把数据库、无服务器函数(serverless functions)、身份认证以及客户端库整合为一个系统。就像 React 组件会对状态变化做出响应一样,Convex 查询会自动对数据库更新做出响应,非常适合实时、动态的应用。
查询使用 TypeScript 编写并直接在数据库中执行,既简化开发,也能以极少的基础设施开销构建快速的响应式应用。该方案还支持模块化组件、实时数据同步、调度(scheduling)以及 AI 辅助代码生成。它可与 React、Next.js、Vue、Svelte、Nuxt 等框架集成,同时也能与 Python、Swift(iOS)、Kotlin(Android)与 Rust 应用互操作。
其灵活性让它在开发者群体中很受欢迎,在 GitHub 上获得了 10.9k+ stars,并在 npm 上拥有 每周 40 万+ 下载量。
Convex 的核心理念:理解它的心智模型
与传统数据库不同,Convex 将数据库视为一个“实时、可响应的系统”,而不仅是被动的数据存储。每当数据被新增、更新或删除时,变化都会被记录到不可变的事务日志(transaction log)中——这是一份永久、带时间戳的所有操作历史。同时,查询不只是取数,它们会自动追踪自身读取过的数据片段(称为“read sets”)。
这使得 Convex 能立即检测:当某个查询依赖的数据发生变化时,系统即可实时更新结果。这套架构支持实时订阅(real-time subscriptions),并通过确定性事务与乐观并发控制机制保持强一致性。借助这些特性,多用户可并发与数据库交互而不产生冲突。
Convex vs 其他数据库
为更好理解 Convex 与其他主流数据库的定位差异,请参考下表:
| 特性 | Convex | Firebase | Supabase | 传统 SQL 数据库 |
|---|---|---|---|---|
| 数据库类型 | 事务型文档存储 | NoSQL / Firestore | PostgreSQL | 关系型 SQL |
| 实时能力 | ✔️(内置,自动订阅) | ✔️(内置) | ➖(可选,通过独立服务器) | ❌(非原生) |
| 事务 | 始终事务化 | 有限 | 支持 | 支持 |
| Schema | 可选、渐进式、由 TypeScript 自动生成 | 灵活/无 schema | 强制(Postgres) | 严格、手动 |
| SQL 支持 | ❌ | ❌ | ✔️ | ✔️ |
| TypeScript 集成 | 完整 | 有限 | 部分(服务端) | 取决于 ORM |
| Auth/OAuth | 标准 + 原生 | 标准 + Firebase Auth | 标准 + 原生 | 自定义搭建 |
| 数据库职责 | 完全由 Convex 托管 | 共享 | 共享 | 完全由开发者管理 |
Convex 如何工作:架构、组件与数据流
Convex 的架构属于全栈后端平台,包含三个主要组件:
- 数据库:一个响应式的文档-关系型存储,JSON 类对象按表组织。每个项目的 Convex 数据库会自动在云端创建,无需手动配置连接或管理集群。
- 服务端函数:查询与变更(mutations)以 TypeScript 函数编写,无需 SQL 或 ORM。查询是纯函数且只读;变更在完全托管的事务中运行,具备ACID 保证、可串行化隔离级别,以及乐观并发控制。
- 客户端库:各框架专用库(Next.js、React、Vue、Svelte 等),订阅服务端函数,自动同步结果并管理 mutation 队列。无需手动订阅或状态管理即可确保一致的实时 UI 更新。
有了这三个组件,数据会通过服务端函数以响应式方式从数据库流向客户端。查询会自动追踪依赖关系,当数据变化时重新执行并实时推送更新。变更以完全托管事务运行,更新数据库及依赖查询,确保客户端始终看到最新状态,无需手动同步。
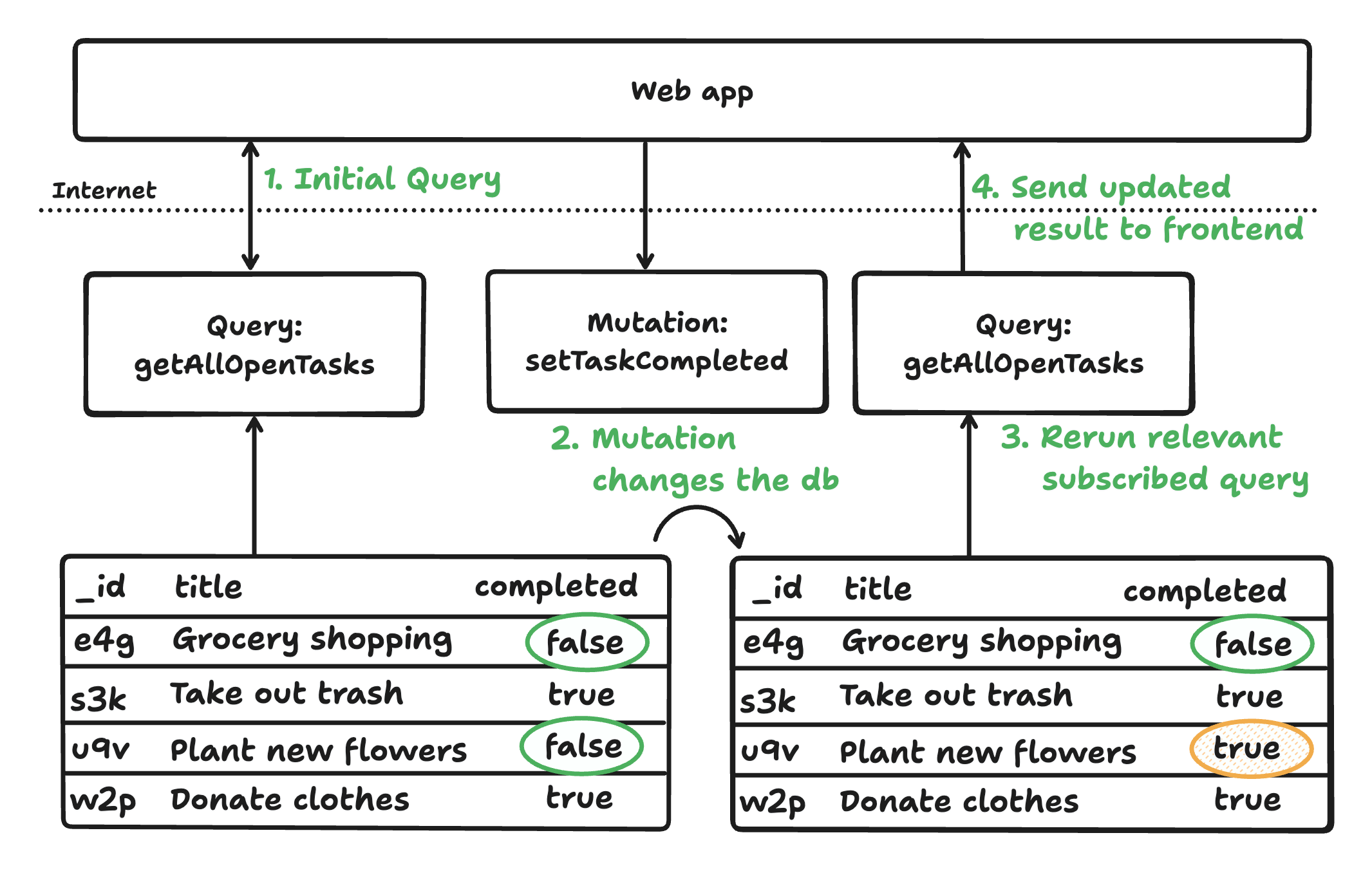
Convex 的一致性架构可在极少样板代码下保证应用具备响应式、一致性与类型安全。它对人类编写代码与 AI 生成代码都很友好,并抽象掉数据库调优与同步复杂度。Convex 还提供身份认证、调度,以及更多能力。
为什么 Convex + 实时网页数据是绝配
像 Convex 这样的实时数据库,只有当数据源本身也是实时的,才能发挥其最大价值。换句话说,它的响应式架构非常适合需要反映实时状态的应用(例如股票价格、社交媒体信息流、新闻更新或电商库存)。
那么,地球上最大、最动态、持续变化的数据源是什么?是网页!网页数据来自数百万个来源并实时流动,使其成为基于 Convex 的响应式应用的理想输入。
当把 Convex 连接到实时网页数据流时,你的应用可以在无需复杂轮询、手动同步或状态管理的情况下,立即对更新做出响应。这消除了信息与 UI 之间的延迟,带来无缝且始终新鲜的用户体验。
将网页数据连接到 Convex 应用的挑战
现在你理解了为什么实时网页数据与 Convex 这样的方案高度契合。下一个问题是:如何真正把实时网页数据取回来?答案是网页抓取——以编程方式从网页中提取信息的过程。
网页抓取很强大,但也有一系列挑战,从技术障碍到运维复杂度,主要包括:
- 动态内容:现代网站依赖 JavaScript、AJAX 与复杂的导航与交互模式,使结构化数据提取更困难。
- 反爬虫措施:许多网站使用 CAPTCHA、限速、指纹识别等防护来检测并拦截自动化访问。
- 频繁变化:布局、HTML 结构与 URL 经常变化,会导致抓取工具失效并需要持续监控与维护。
- 可扩展性:规模化采集需要扎实基础设施、与可信代理提供商集成以进行 IP 轮换,并具备健壮的错误处理。
- 数据一致性:保证准确性、完整性与新鲜度很难,尤其是对高频更新数据。
因此,在网页数据之上构建一个完全响应式的 Convex 应用是一项艰巨任务。与其自己处理这些障碍,更合适的做法是依赖一个企业级的实时网页数据提供商,例如 Bright Data。
Bright Data + Convex:基于实时网页数据的响应式应用
在开发由实时网页数据驱动的响应式应用时,Bright Data 与 Convex 的组合非常突出。它们共同实现了清晰的职责分离:Bright Data专注于大规模数据采集,Convex 负责实时状态同步与 UI 更新。
Bright Data 让你可以以编程方式实时从网页中搜索并提取信息。抓取到的数据以结构化 JSON 返回,可轻松写入 Convex。随后 Convex 会通过响应式查询把数据即时传播给所有已连接客户端。
Bright Data 的吸引力尤其在于其企业级基础设施:它运营着全球最大的代理网络之一,覆盖 195 个国家的 1.5 亿+ IP,并实现无限并发。这一基础提供了高可靠性:99.99% uptime、99.95% 成功率,以及 7×24 支持。
Bright Data 的所有实时数据获取解决方案都构建在这套基础设施之上,主要包括:
- 网页抓取工具 API:面向热门网站的现成 API endpoint,用于提取结构化实时数据。
- Unlocker API:自动处理 CAPTCHA、拦截机制与反爬虫系统,返回可访问的页面内容。
- SERP API:提供多搜索引擎实时结果,响应时间可低至亚秒级延迟。
- Crawl API:将整个网站转换为结构化数据集。
Convex + Bright Data 的组合让新鲜数据可以持续从网页流向用户,而无需承担抓取通常带来的运维负担。结果是一个可扩展、易维护、且完全响应式的系统——以实时网页数据为基础。
架构示例
下面是一个用 Convex 构建的响应式 Web 或移动应用架构示例,其中实时网页数据由 Bright Data 提供:
- 触发数据获取(Bright Data):当用户执行某个操作(例如点击按钮)时,前端向后端发请求;服务端调用 Bright Data API 从网页获取最新数据。抓取数据可以是商品价格、新闻文章、职位列表等。
- 后端处理(Convex):收到结构化 JSON 后,通过 mutation 写入 Convex。在此阶段,数据会被摄取、归一化、校验并存储到 Convex 数据库;你也可以按应用逻辑进行补充或转换。
- 实时 UI 更新(Convex 响应式):前端订阅 Convex 查询。一旦数据库更新,相关查询会自动重新运行;更新后的结果会即时推送到客户端,UI 无需手动干预即可实时刷新。
如何用 Convex 与 Bright Data 构建实时 AI 市场研究终端
为展示 Convex + Bright Data 集成能够解锁的可能性,我们来看一个真实 demo:Bright Data 的 AI Market Research Terminal(AI 市场研究终端)。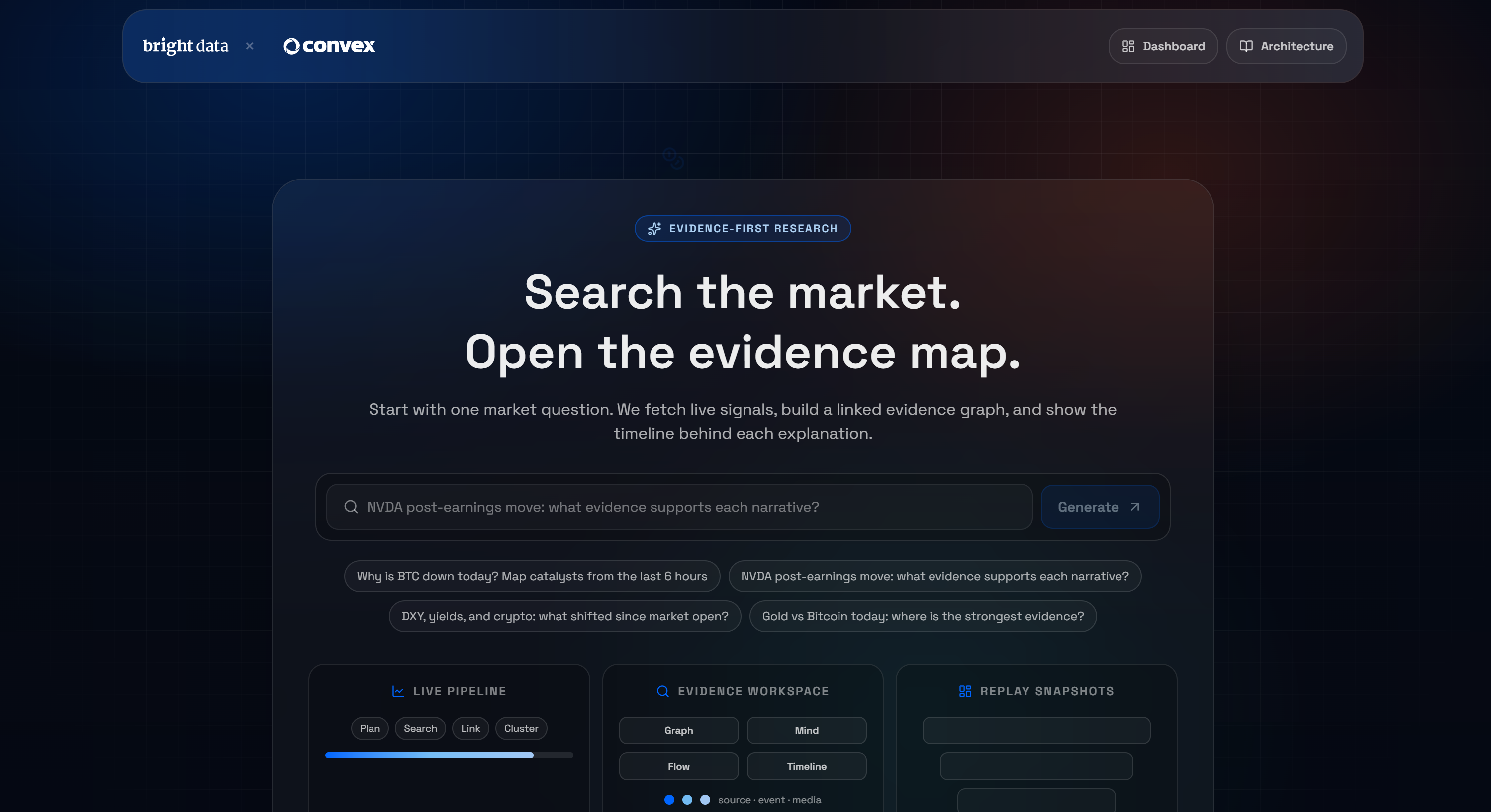
这是一个基于 Convex 的 Next.js 应用:你提出一个问题,它会返回一个来自实时网页抓取的证据图(evidence graph)。如果你不熟悉该概念,证据图是一种结构化表示,用于展示数据、论点与支撑证据之间的关系。
在底层,该应用遵循一个包含 8 个阶段的流水线:
- Plan:LLM 基于你的主题生成 4–6 条聚焦的搜索查询。
- Search:并发发送 4–6 个 Bright Data SERP API 请求。
- Scrape:使用 Bright Data Web Unlocker API 将 Top URL 提取为 Markdown。
- Extract:把 SERP 摘要与 Markdown 组合为结构化证据条目。
- Summaries:LLM 为每条证据提取关键要点、实体、催化因素与情绪。
- Artifacts:构建带置信度分数的知识图谱节点与边。
- Link:应用启发式增强(连通性修复、域名标签、tape events 等)。
- Render → Ready:将最终 artifacts 流式推送到客户端,同时在 Convex 中持久化会话。
现在来探索这个 demo 并在本地测试!看看真实的 Convex + Bright Data 应用如何在响应式工作流中采集、处理并交付实时网页数据。
前置条件
要跟随本教程,请确保你具备:
- 本地安装 Node.js 20+。
- 一个 OpenRouter API key。
- 一个Bright Data 账号,并已配置 SERP 与 Web Unlocker zones。
- 已创建 Convex 项目(免费层足够)。
- 本地安装 Git。
先不用担心 Bright Data 与 Convex 的设置,本教程会在后续两个小节中分别引导你完成。
步骤 #1:准备 Bright Data 账号
如介绍所述,该 demo 应用依赖两个 Bright Data 产品:
- SERP API
- Web Unlocker API
下面将引导你在账号中完成配置。如需更细说明,也可参考 Bright Data 官方文档:
如果你还没有账号,请创建账号;否则登录。登录后,在控制台中进入 “Proxies & Scraping” 页面。在 “My Zones” 区域,找到表格中标为 “SERP API” 的一行,以及 “Web Unlocker API” 的一行: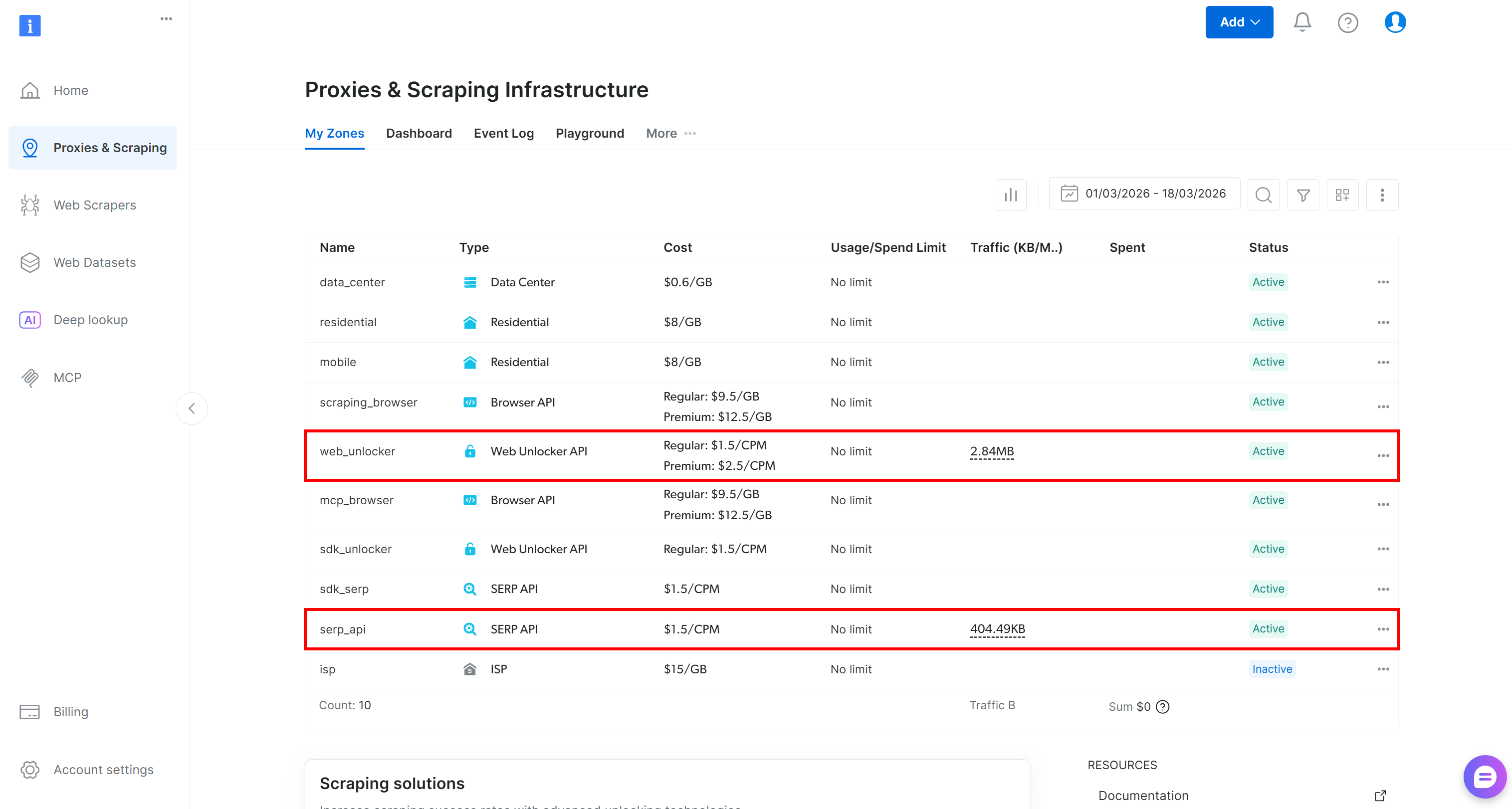
如果缺少其中任意一行,说明对应 zone 尚未创建。例如,要创建 SERP API zone,向下滚动到 “SERP API” 部分并点击 “Create Zone”: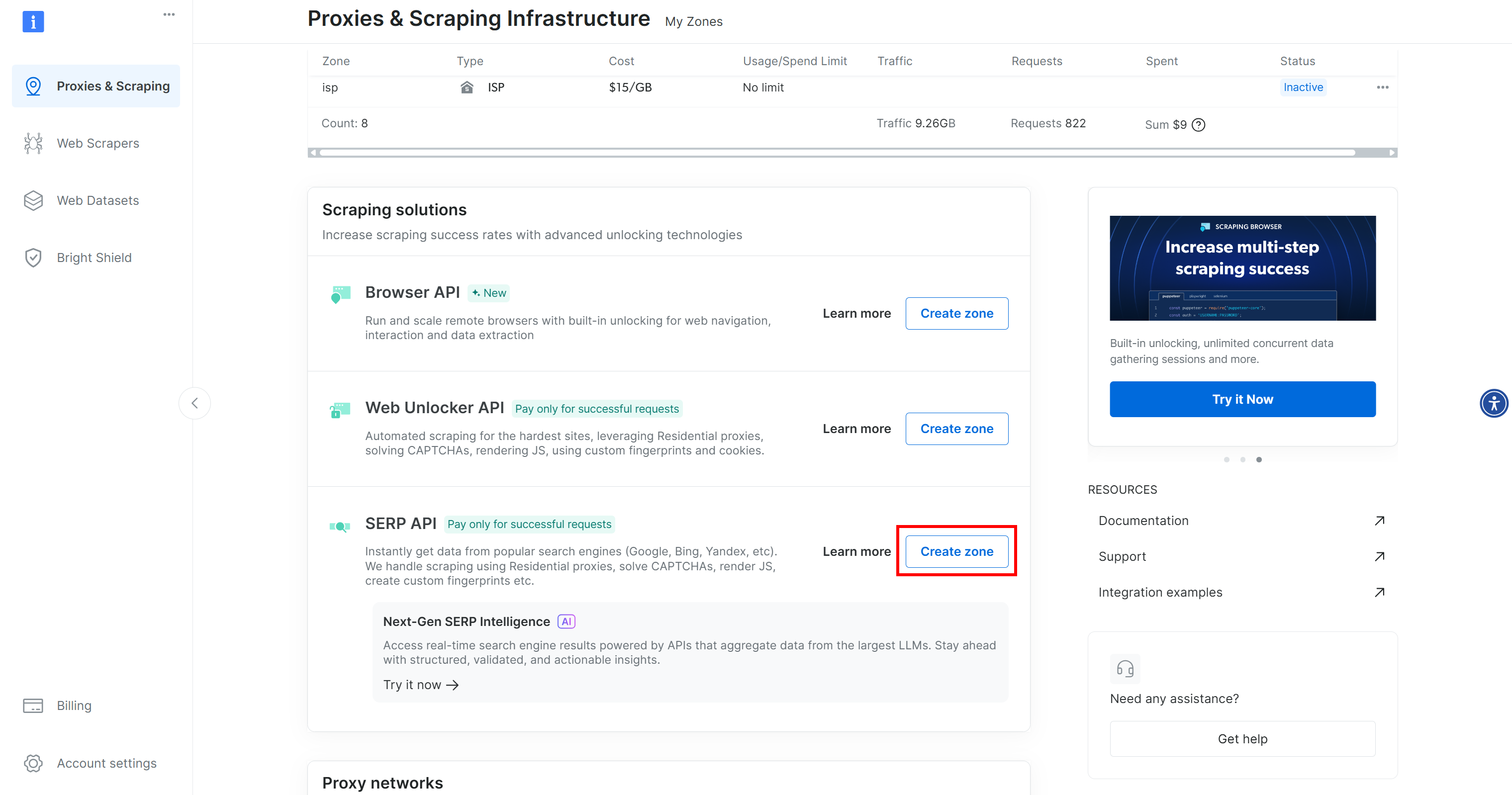
创建 SERP API zone 并命名,例如 serp_api(或你喜欢的名称)。请记下该 zone 名称,后面会用到。
对 Web Unlocker API 重复同样过程。本教程假设你的 Web Unlocker zone 名称为 web_unlocker。
最后,按官方教程生成 Bright Data API key。请安全保存该 key,因为 Convex 驱动的 Next.js 应用需要用它对 SERP API 与 Web Unlocker 请求进行鉴权。
太棒了!你的 Bright Data 账号现在已完成配置,随时可以集成到 AI Market Research Terminal demo 中。
步骤 #2:设置 Convex 账号
先登录 Convex;如果还没有账号就注册一个。你会进入 Convex 控制台:
点击 “Create Project”。将项目命名为 “AI Market Research Terminal”(或你喜欢的名字),然后点击 “Create”: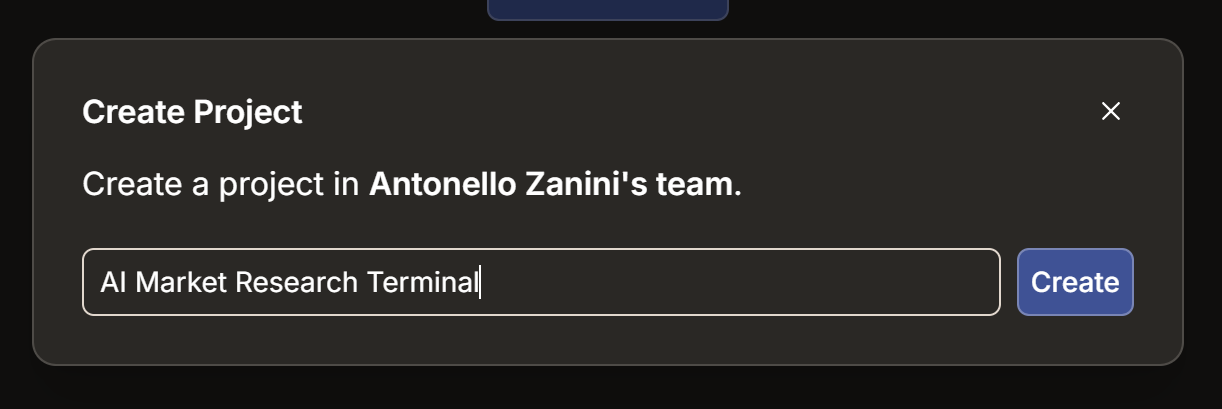
等待项目初始化,然后选择部署区域: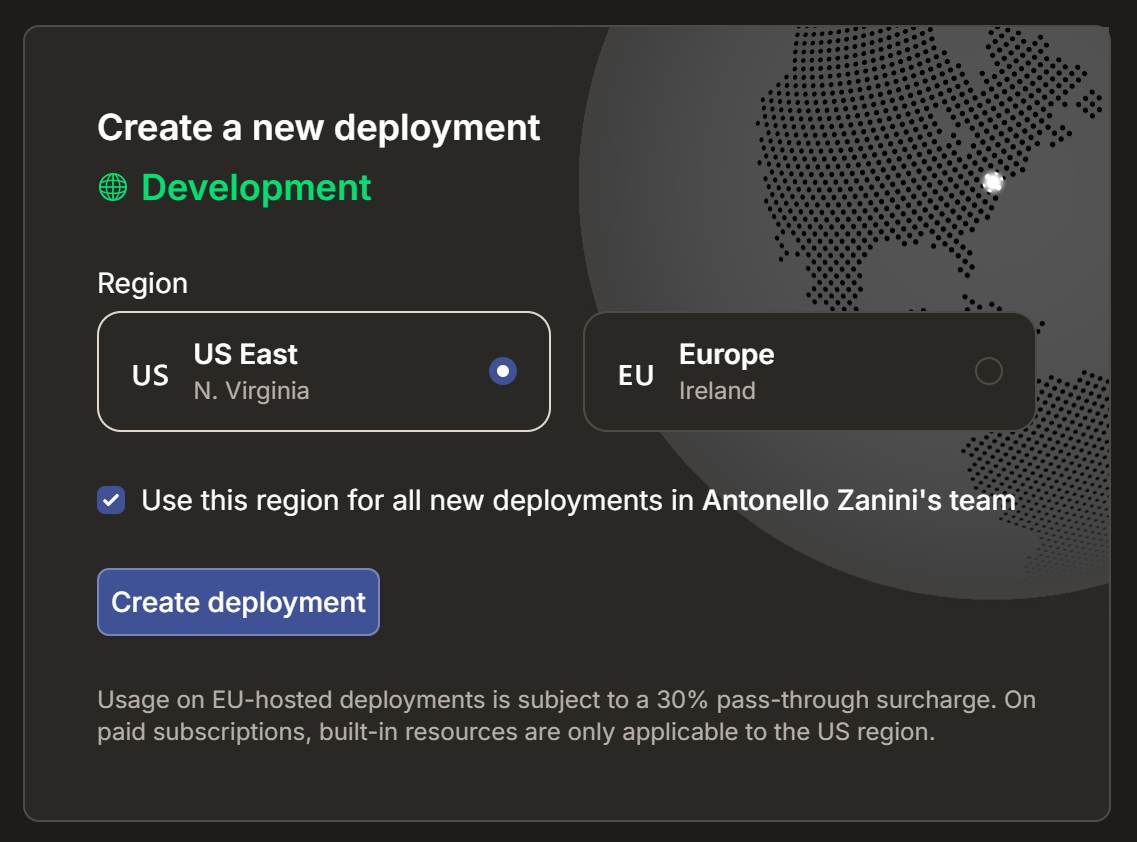
点击 “Configure Deployment” 确认。几秒后项目应就绪: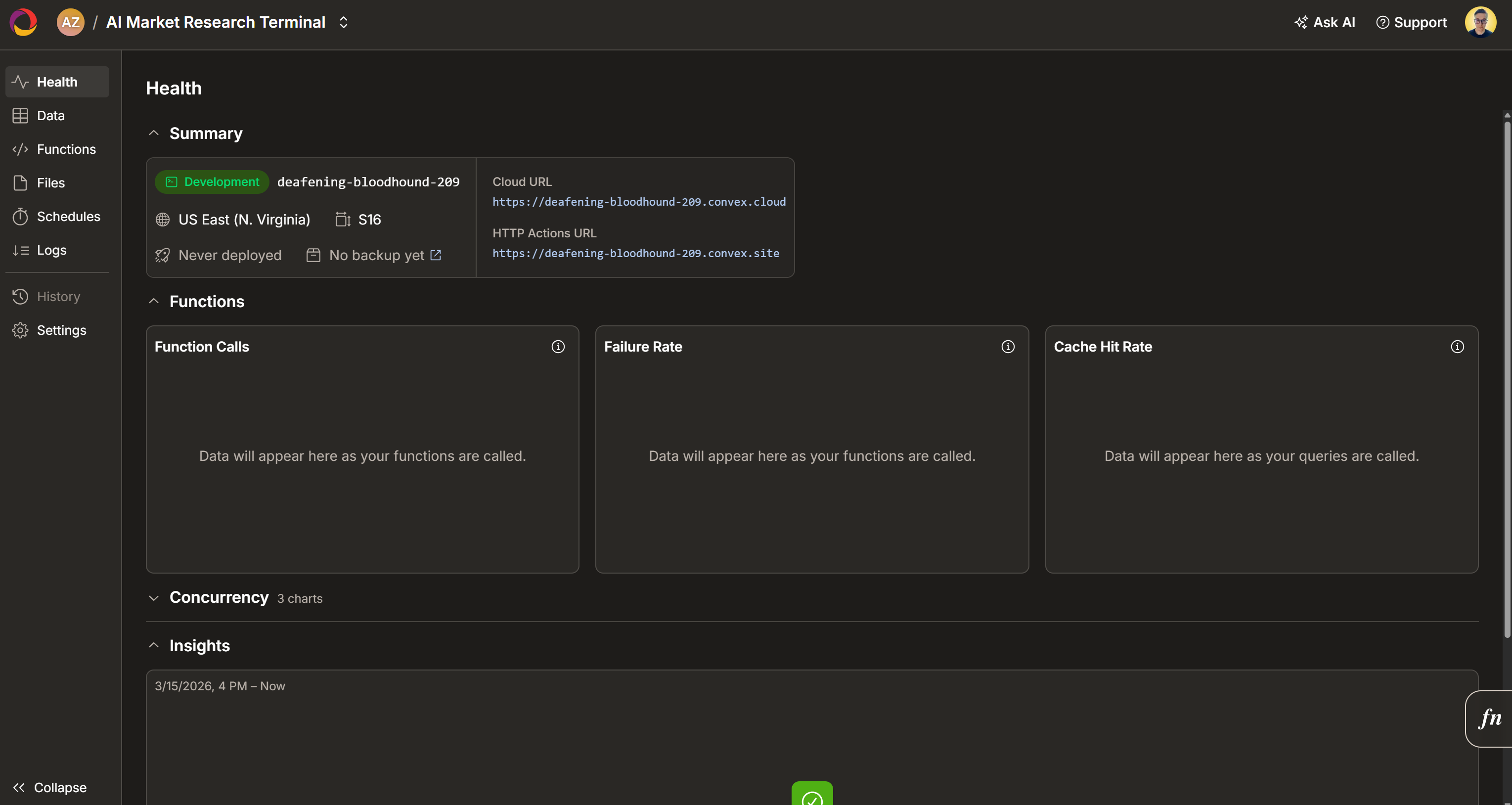
很好!你现在已经具备克隆并本地运行该项目所需的全部组件。
步骤 #3:配置项目
首先,将demo 仓库克隆到本地文件夹 ai-market-research-terminal/:
git clone https://github.com/brightdata/market-terminal ai-market-research-terminal此时你的 ai-market-research-terminal/ 文件夹应包含官方仓库列出的全部文件。
进入项目目录:
cd ai-market-research-terminal安装依赖:
npm install很好!现在你可以用任意 JS IDE 打开项目,例如 Visual Studio Code。浏览代码熟悉其工作方式。更多幕后细节可阅读 DEV 上的深度解析:专门的 deep dive。
步骤 #4:配置应用
应用的所有配置都从 .env.local 文件读取。仓库提供了示例文件 .env.local.example。复制它以创建你自己的 .env.local:
cp .env.local.example .env.local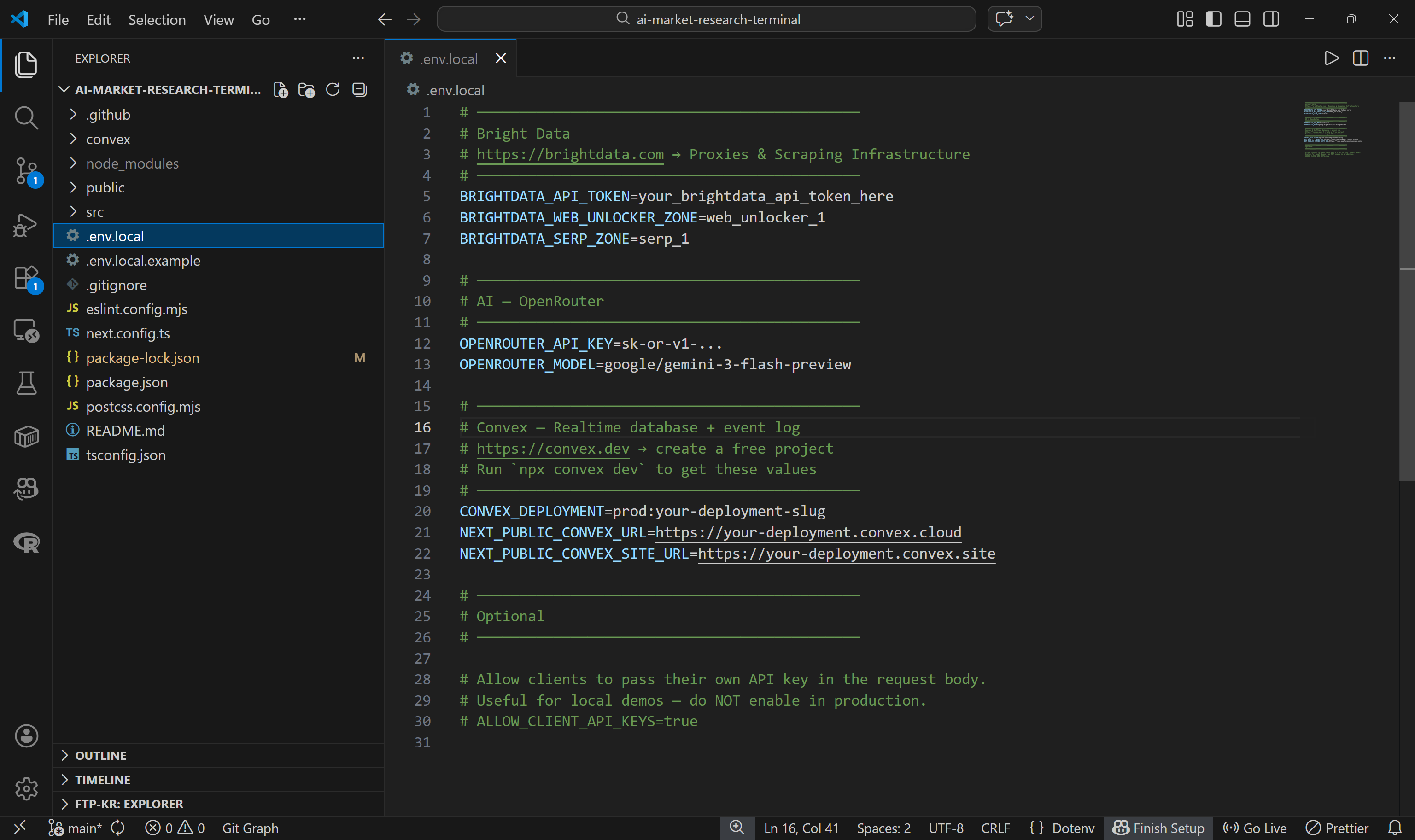
接下来,运行以下命令在项目根目录设置 Convex 连接器:
npx convex dev按提示操作,在浏览器中将设备连接到你的 Convex 账号,然后选择你在步骤 #2 创建的 “AI Market Research Terminal” 项目。Convex 会自动把必要的环境变量写入 .env.local,例如:
CONVEX_DEPLOYMENT=dev:deafening-bloodhound-209
NEXT_PUBLIC_CONVEX_URL=https://deafening-bloodhound-209.convex.cloud
NEXT_PUBLIC_CONVEX_SITE_URL=https://deafening-bloodhound-209.convex.site这些值用于让应用连接到你的 Convex 项目。
默认情况下,会在你的 Convex 项目中新增两张表(sessionEnvts 与 session):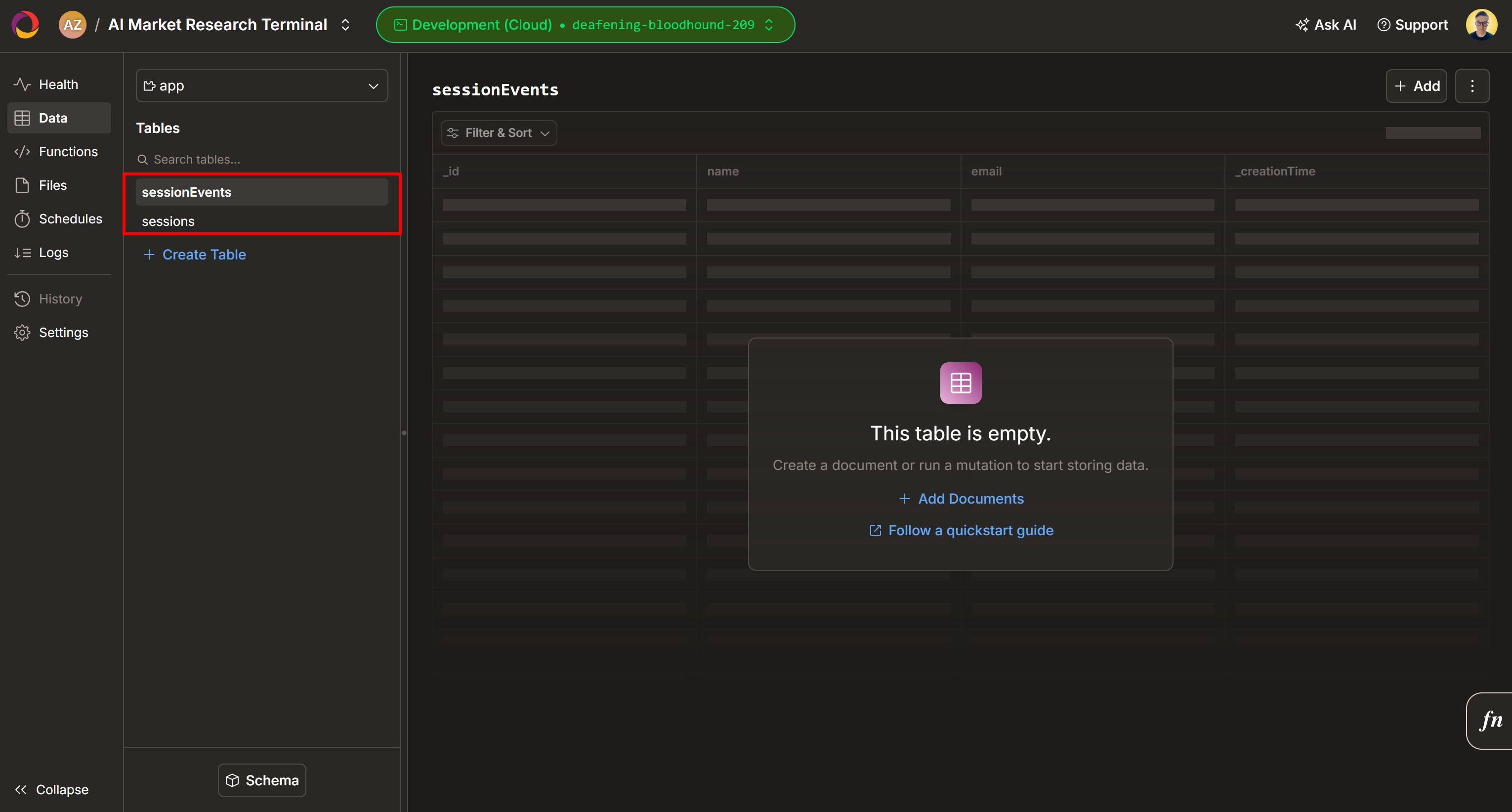
然后补全 .env.local 中其余环境变量:
BRIGHTDATA_API_TOKEN=<YOUR_BRIGHTDATA_API_KEY>
BRIGHTDATA_WEB_UNLOCKER_ZONE=<YOUR_BRIGHTDATA_WEB_ULOCKER_API_NAME> # e.g., "web_unlocker"
BRIGHTDATA_SERP_ZONE=<YOUR_BRIGHTDATA_SERP_API_NAME> # e.g., "serp_api"
OPENROUTER_API_KEY=<YOUR_OPENROUTER_API_KEY>
OPENROUTER_MODEL=google/gemini-3-flash-preview将占位符替换为你的 Bright Data API token、Web Unlocker zone 名称、SERP API zone 名称与 OpenRouter API key。注意默认 LLM 为 Gemini 3 Flash,但你也可以按需更换为其他支持的模型。
太好了!demo 已完成配置,准备好本地运行。
步骤 #5:本地运行应用
启动 demo:
npm run dev在浏览器打开 http://localhost/market-terminal 访问本地 AI Market Research Terminal 应用。你应看到: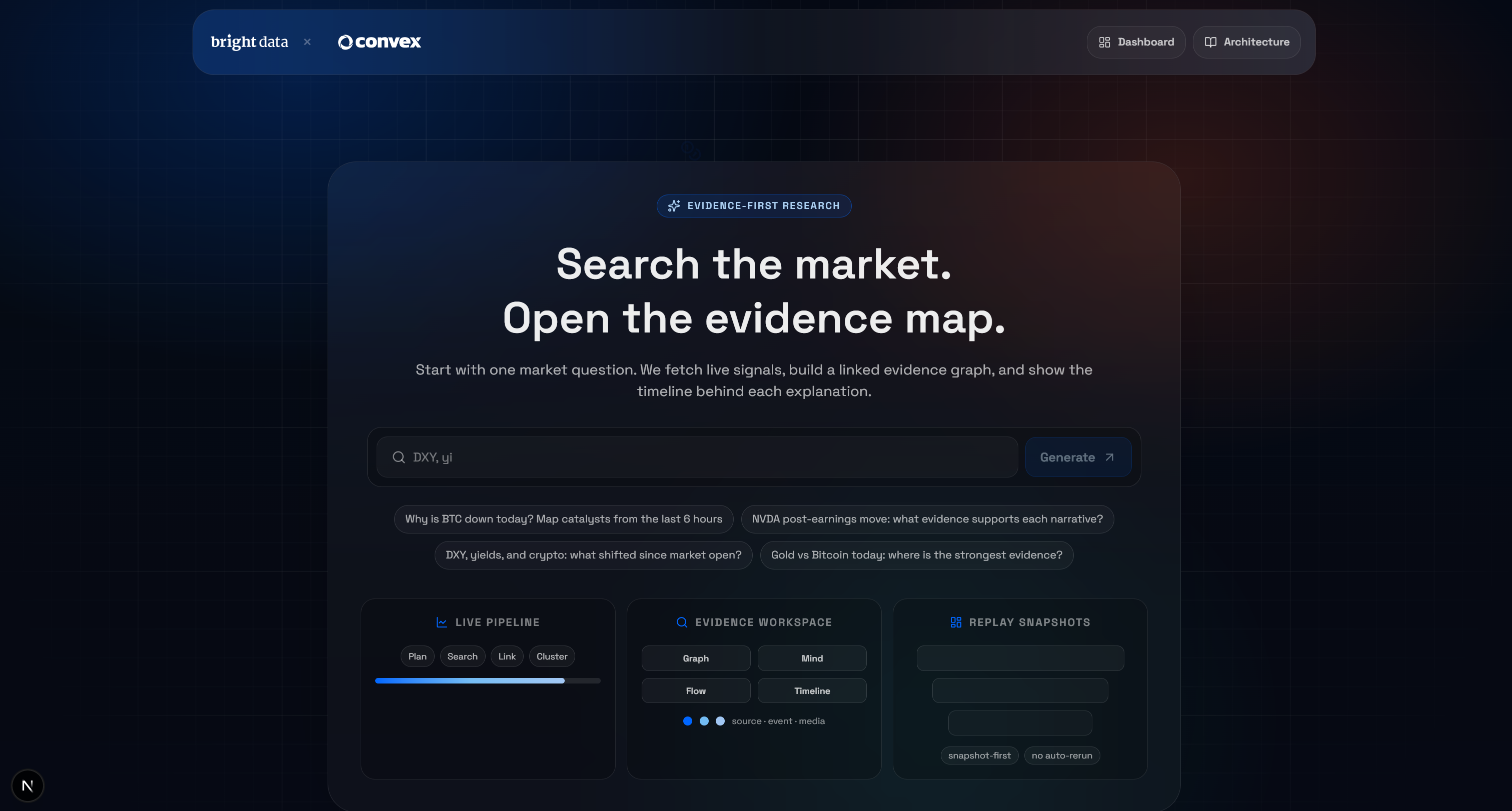
输入一个查询来测试应用,例如:
Why is BTC down today?点击 “Generate” 按钮,你将得到如下结果: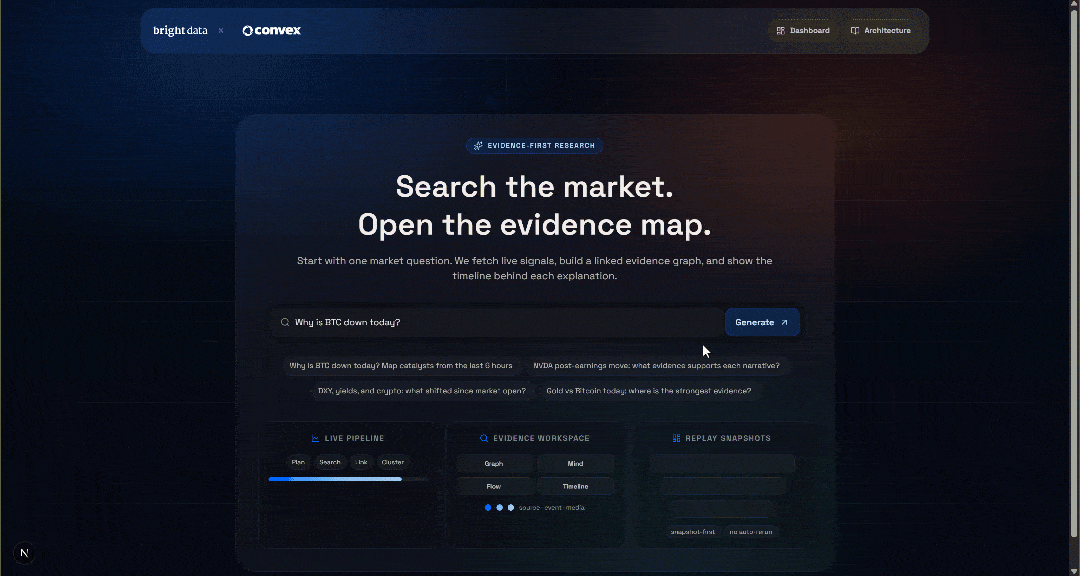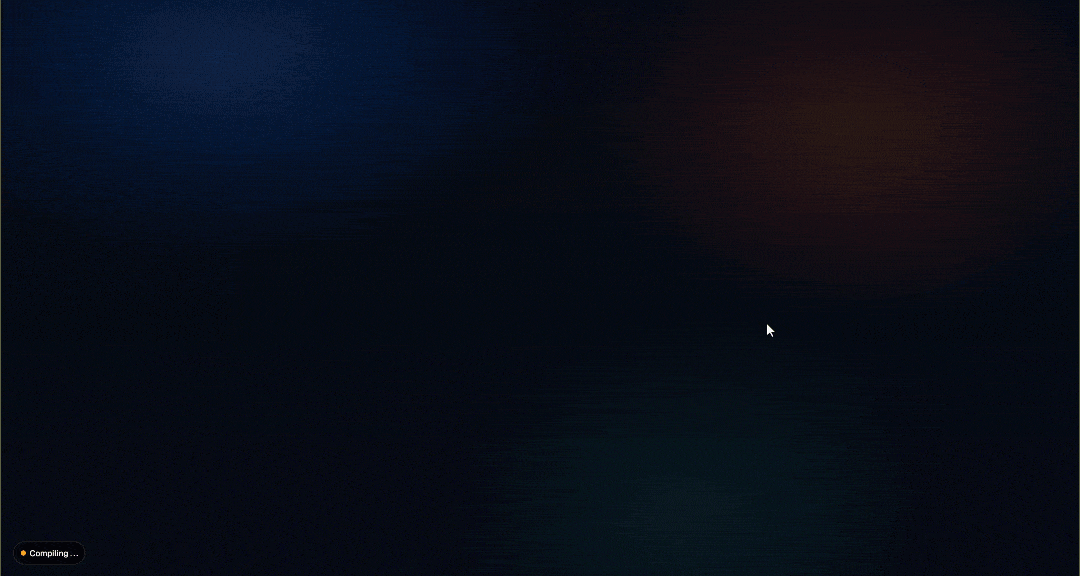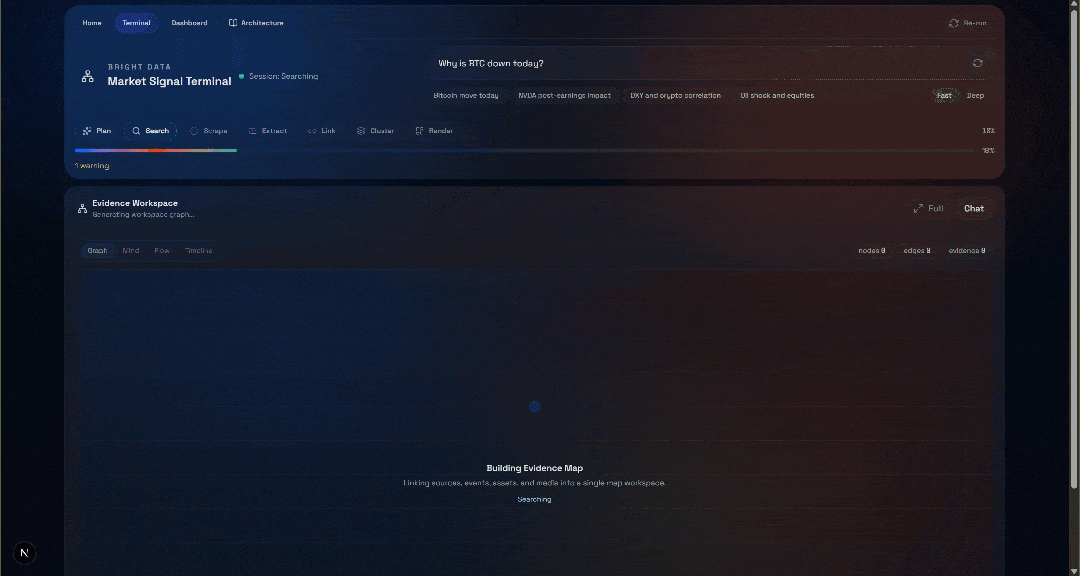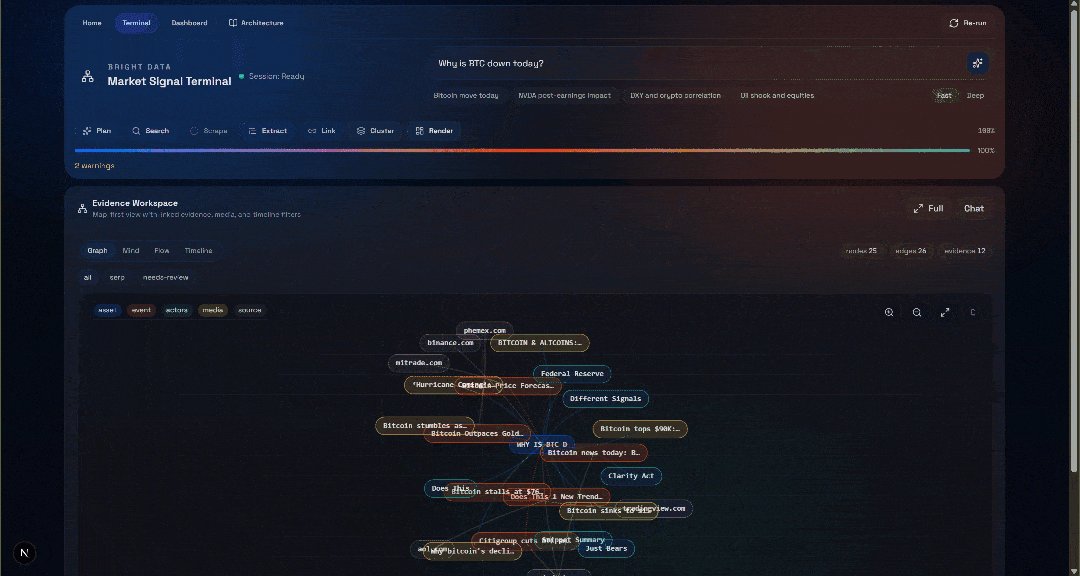
接着查看 “Evidence Workspace” 区域。该视图包含所有通过网页抓取实时获取的数据,并已聚合、处理并存入 Convex。此时你的 Convex 数据库会包含这次运行的数据: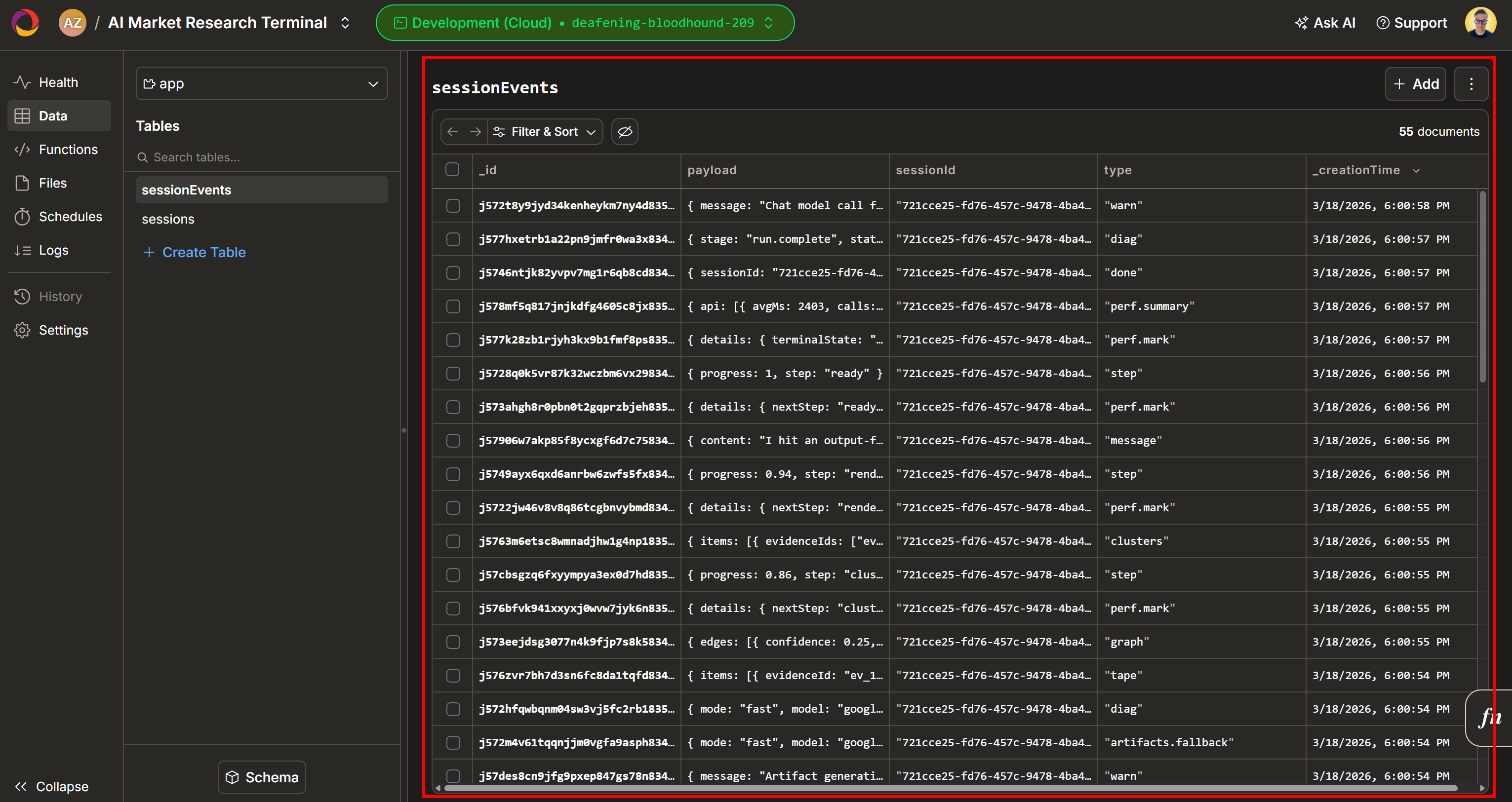
然后探索 “Graph”、“Mind”、“Flow” 与 “Timeline” 视图: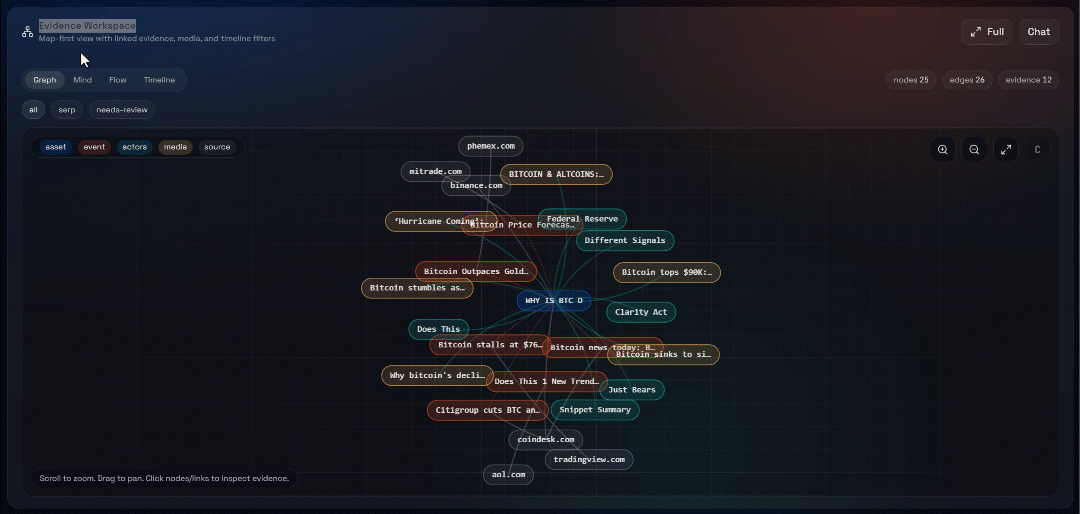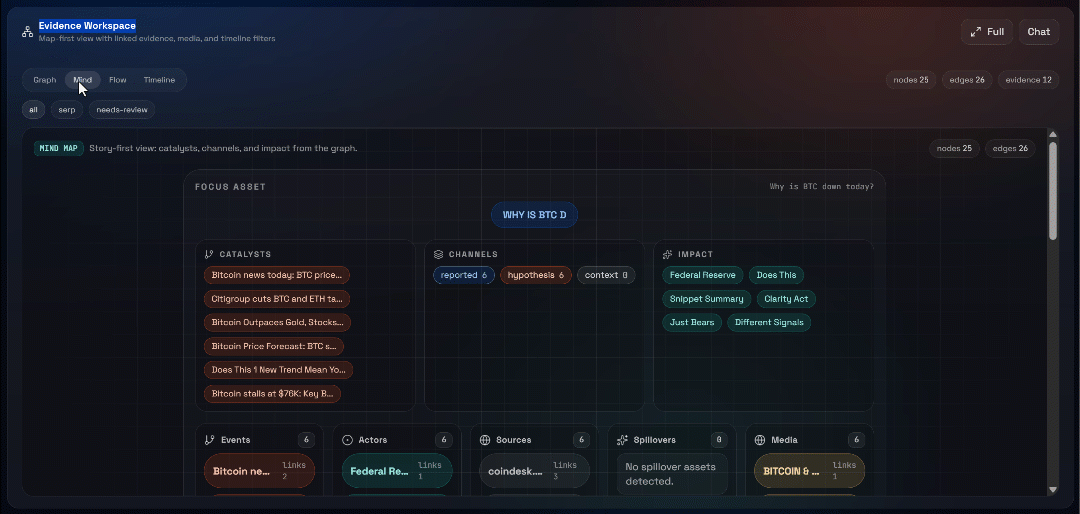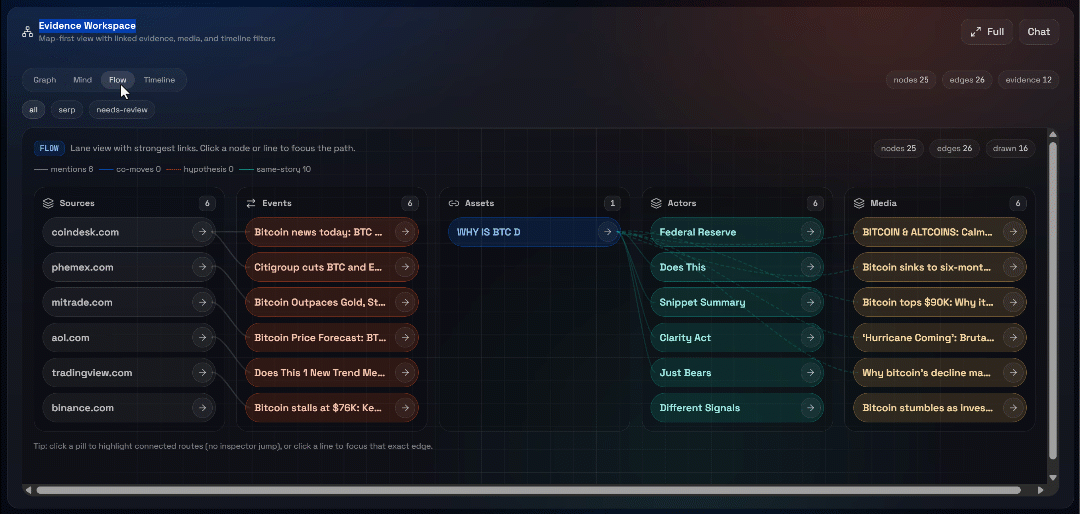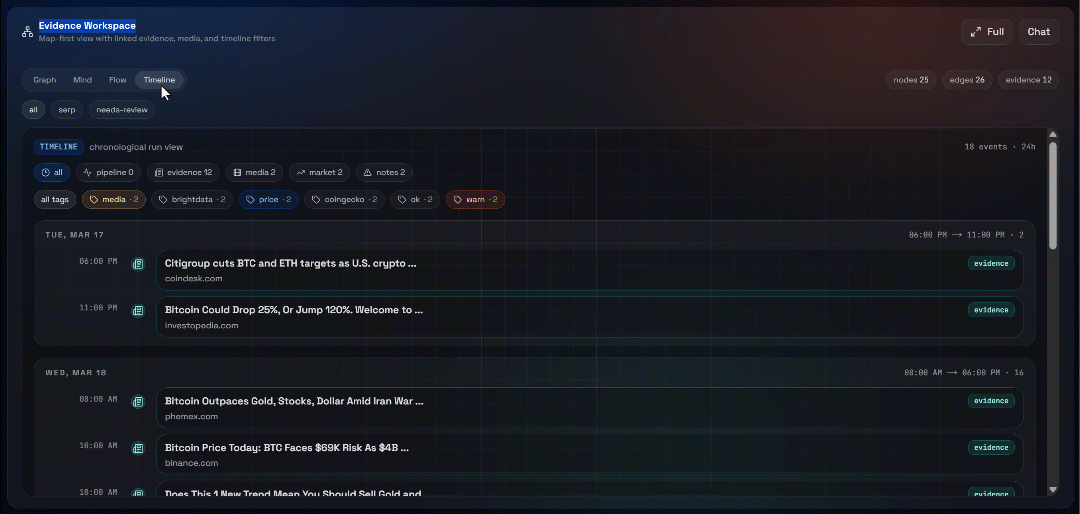
在这里你可以查看恢复的来源、过滤它们,并进一步探索数据以获得更深洞察。
完成!你现在拥有一个完全可用的 AI Market Research Terminal 应用:Bright Data 提供数据,Convex 作为后端数据库。它是一个实时、响应式的应用,将实时网页数据直接带到你的工作空间。
结论
本文中,你了解了 Convex 是什么、它如何工作,以及它如何支撑响应式应用。当 Convex 用于存储从网页实时抓取的新鲜数据时,这套方案会更加强大。
Bright Data 通过企业级基础设施支持实时网页抓取,这是多种网页抓取工具服务的底座,让你可以在不被拦截的情况下快速、可靠地从网页采集数据。
立即免费注册 Bright Data,探索我们的实时网页数据采集解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




