
在这篇博客文章中,你将学习:
- OpenFang 是什么,以及它作为代理操作系统能带来什么。
- 为其配备 Bright Data 的网页抓取、搜索、发现和交互工具的主要原因。
- 如何将 OpenFang 连接到 Bright Data Web MCP 的分步指南。
- 如何通过一些 Agent 技能 快速让 OpenFang 了解 Bright Data 解决方案。
让我们开始吧!
什么是 OpenFang?
OpenFang 是一个用 Rust 构建的开源、功能齐全的代理操作系统。代理 OS 不提供基于聊天的工作流,而是通过提供必要的上下文、编码标准和架构规则来运行并协调自主 AI 代理。
因此,OpenFang 代理不是等待提示,而是持续运行。具体来说,它们会为你进行研究、监控、生成线索并汇报结果。
与 OpenClaw 和 ZeroClaw 等一些竞争对手相比,OpenFang 更重视性能、安全性和真实世界的自动化。它在社区中迅速被采用,这从其强劲的 GitHub 热度(超过 16k stars) 可见一斑。
核心特性、方面、能力
OpenFang 代理 OS 解决方案提供的主要特性 包括:
- 自主“hands”:预构建的代理,可按计划独立运行,在无需用户提示的情况下执行复杂工作流,并将结果直接交付到控制面板或渠道。
- 单一二进制架构:整个系统编译为一个轻量级可执行文件(~32MB),简化安装与部署。
- 高性能 Rust 内核:从零开始用 Rust 构建,与传统基于 Python 的框架相比,具备更快速度、更低内存占用和更快启动时间。
- 深度安全模型:包含沙箱、加密签名、审计追踪和注入防护,以确保自主代理的安全执行。
- 多代理运行时 + 工具:支持数十个代理和 50+ 内置工具,并通过 MCP 与代理间通信实现外部集成。
- 持久化记忆系统:将 SQLite 存储与向量嵌入相结合,实现长期上下文保留与跨会话智能。
- 40+ 渠道集成:为 Slack、WhatsApp 和 Telegram 等平台提供原生连接器。
- 广泛的 LLM 生态支持:与 25+ 提供商和 100+ 模型集成,具备智能路由、回退与成本优化。
- 内置桌面端与 API 层:提供原生桌面应用和 140+ API 端点,实现完全控制、可观测性以及与现有系统的集成。
在 官方文档 中了解更多。
为什么要让 OpenFang 访问网络
OpenFang 是用于编排与安全代理管理的优秀解决方案。然而,当 AI 代理基于过时信息运行时,很容易偏离方向或产生低质量结果。
这是 LLM 的一个根本限制,因为它们是在代表过去的静态数据集上训练的。因此,它们可能会产生幻觉,或基于不完整或过时的上下文做出决策,从而降低可靠性与有效性。
为了解决这一点,OpenFang 包含基础的网页搜索与浏览工具。然而,这些工具并不适用于生产环境,并且很容易被现代网站通过反机器人与反抓取限制所阻止。
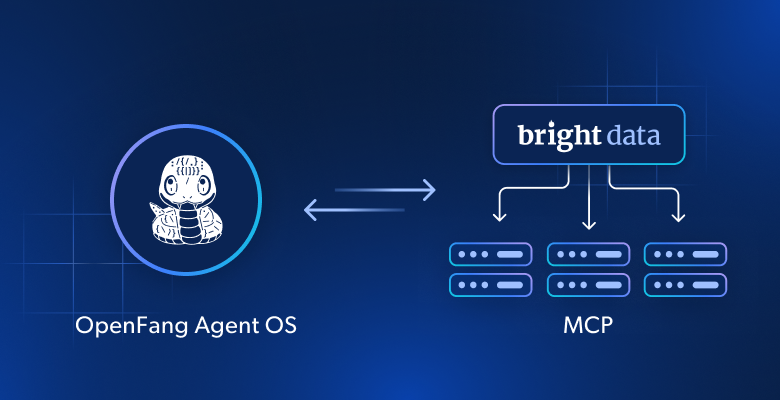
解决方案是将 OpenFang 连接到 Bright Data 的 Web MCP。通过此集成,OpenFang 代理可以访问生产级、可靠且可扩展的网页数据工具,用于抓取、搜索、发现以及自动化浏览器交互。
Bright Data 的突出之处在于其庞大的全球基础设施,拥有覆盖 195 个国家/地区的超过 4 亿个住宅 IP。这支持无限并发与可扩展性,同时实现 99.99% 的正常运行时间和 99.95% 的成功率。
总的来说,Web MCP 提供 70+ 个 AI 就绪工具。即使在免费层级(每月 5k 次免费请求)中,它也包含核心工具(以及用于并行执行的批处理版本):
| 工具 | 描述 |
|---|---|
search_engine + search_engine_batch |
以 JSON 或 Markdown 格式检索 Google、Bing 或 Yandex 结果 |
scrape_as_markdown + scrape_batch |
在绕过反机器人保护的同时,以 Markdown 提取干净的网页内容 |
discover |
基于用户意图对结果进行排序的 AI 驱动搜索 |
但 Pro 模式才是 Web MCP 真正大放异彩的地方。它为来自 LinkedIn、Yahoo Finance、YouTube、TikTok、Zillow、Google Maps 以及其他 40+ 平台的结构化提取提供高级工具。此外,它还为你的代理配备自动化网页交互工具。
了解如何将 Bright Data Web MCP 集成到 OpenFang 中!
如何将 OpenFang 连接到 Bright Data Web MCP
在本引导部分中,你将看到如何在 OpenFang 中设置本地 Bright Data Web MCP 实例。
请按照以下说明操作!
前提条件
要跟随本教程,请确保你具备:
- 在本地安装 Rust。
- 在本地安装 Python。
- 在本地安装 Node.js。
- 一个 Bright Data 账户,最好已设置好 API key(你将在专门步骤中完成引导)。
- 一个来自受支持提供商的 API key(在本指南中,我们将使用 OpenAI)。
步骤 #1:安装 OpenFang
在 Linux 或 macOS 上,使用以下命令启动 OpenFang 安装脚本:
curl -fsSL https://openfang.sh/install | sh同样地,在 Windows 上运行:
irm https://openfang.sh/install.ps1 | iex这是你应该看到的输出: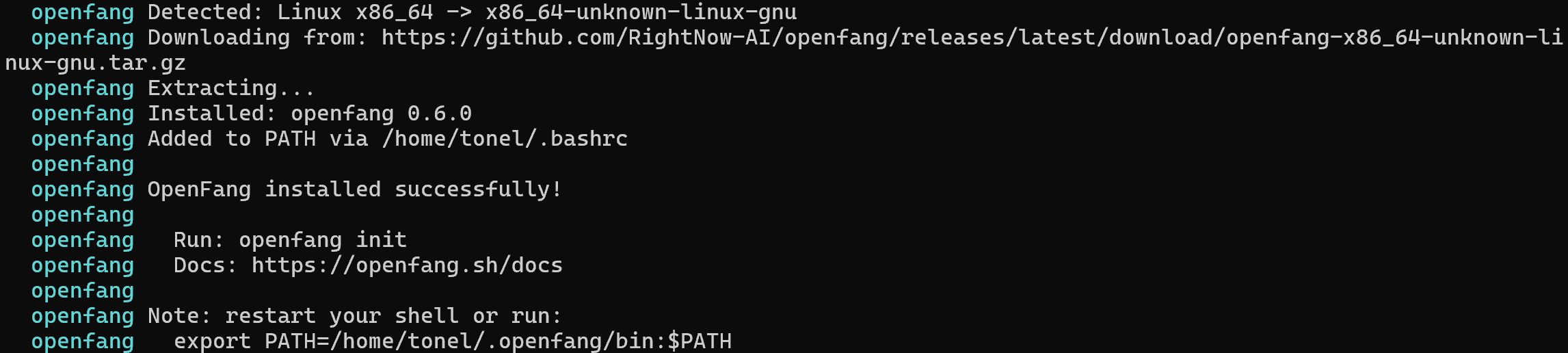
现在,重启你的 shell。然后使用以下命令验证安装:
openfang --version你应该会得到如下输出:
openfang 0.6.0做得好!OpenFang 现在已在本地安装完成。
步骤 #2:完成 OpenFang 设置
要完成 OpenFang 配置,请运行以下命令:
openfang init这是你应该看到的内容: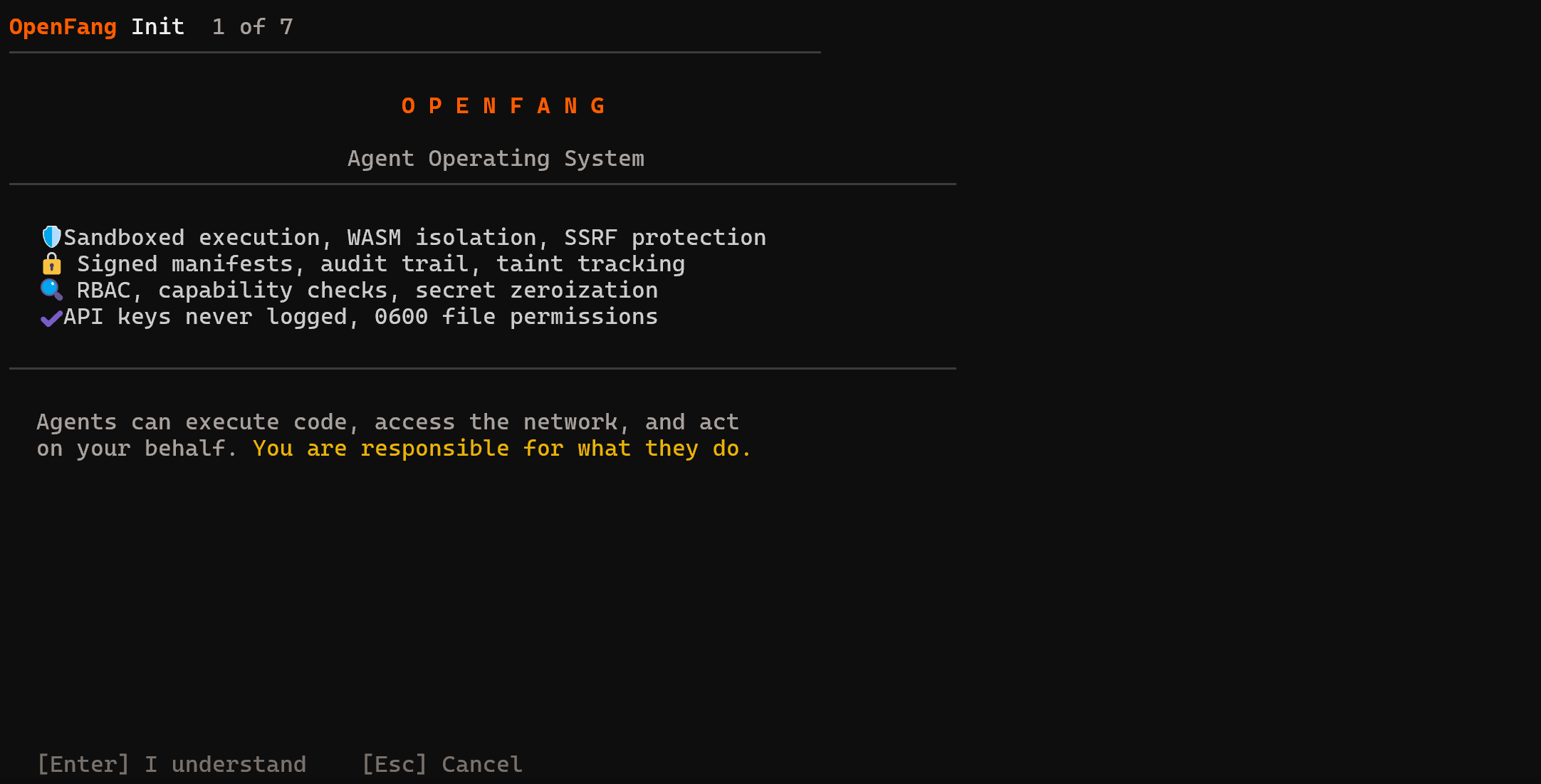
按 Enter 继续。是时候完成 7 步设置向导了!
首先,选择是否从 OpenClaw(如果你已安装)迁移配置,或从头开始。在本指南中,我们将进行全新设置。如果你想改为将 OpenClaw 连接到 Web MCP,请参考专门的视频。
接下来,选择你的 LLM 提供商: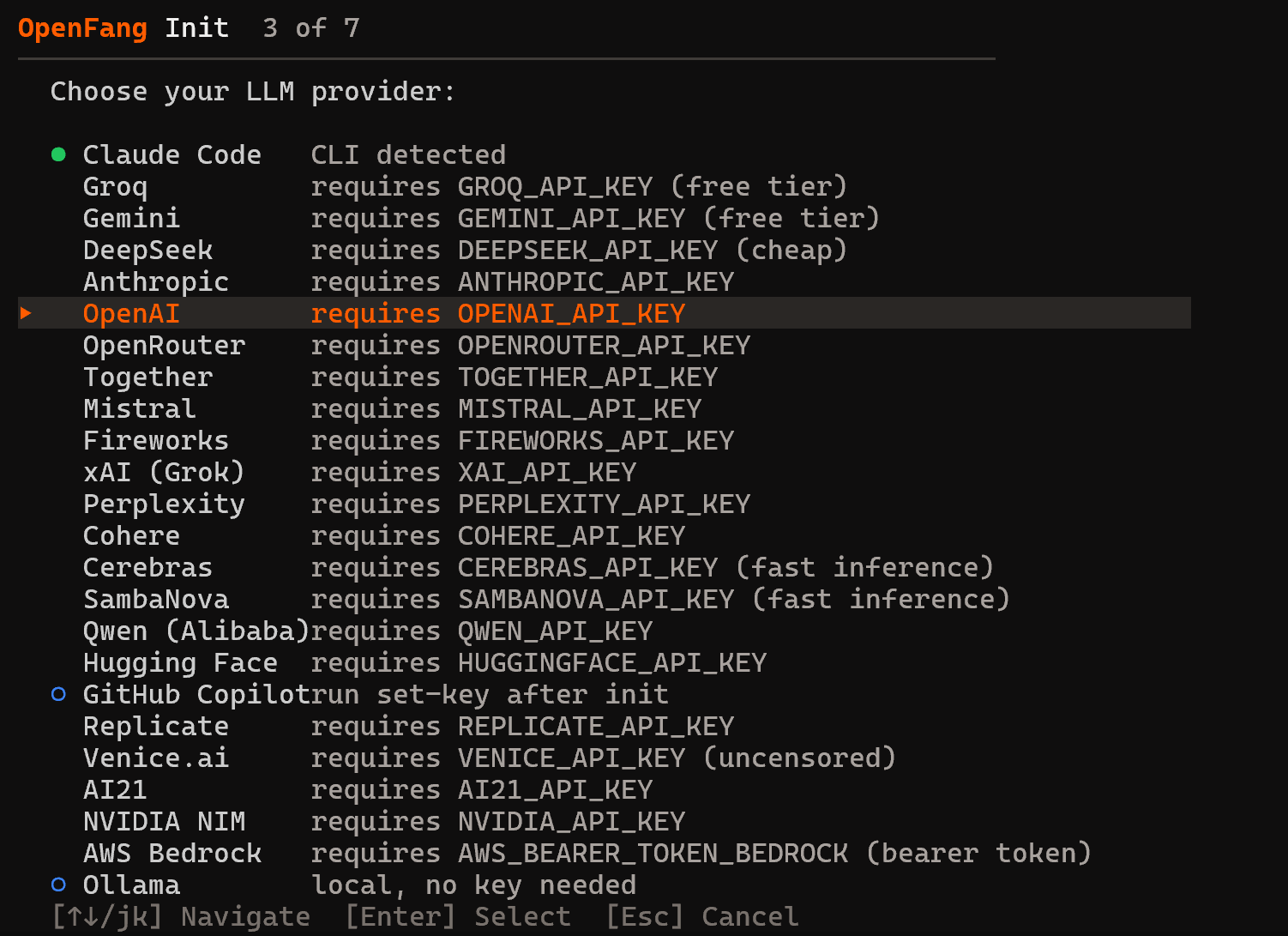
在此示例中,我们选择了 OpenAI,但你可以选择最适合你需求的提供商。输入你的 API key,并使用默认模型选择继续: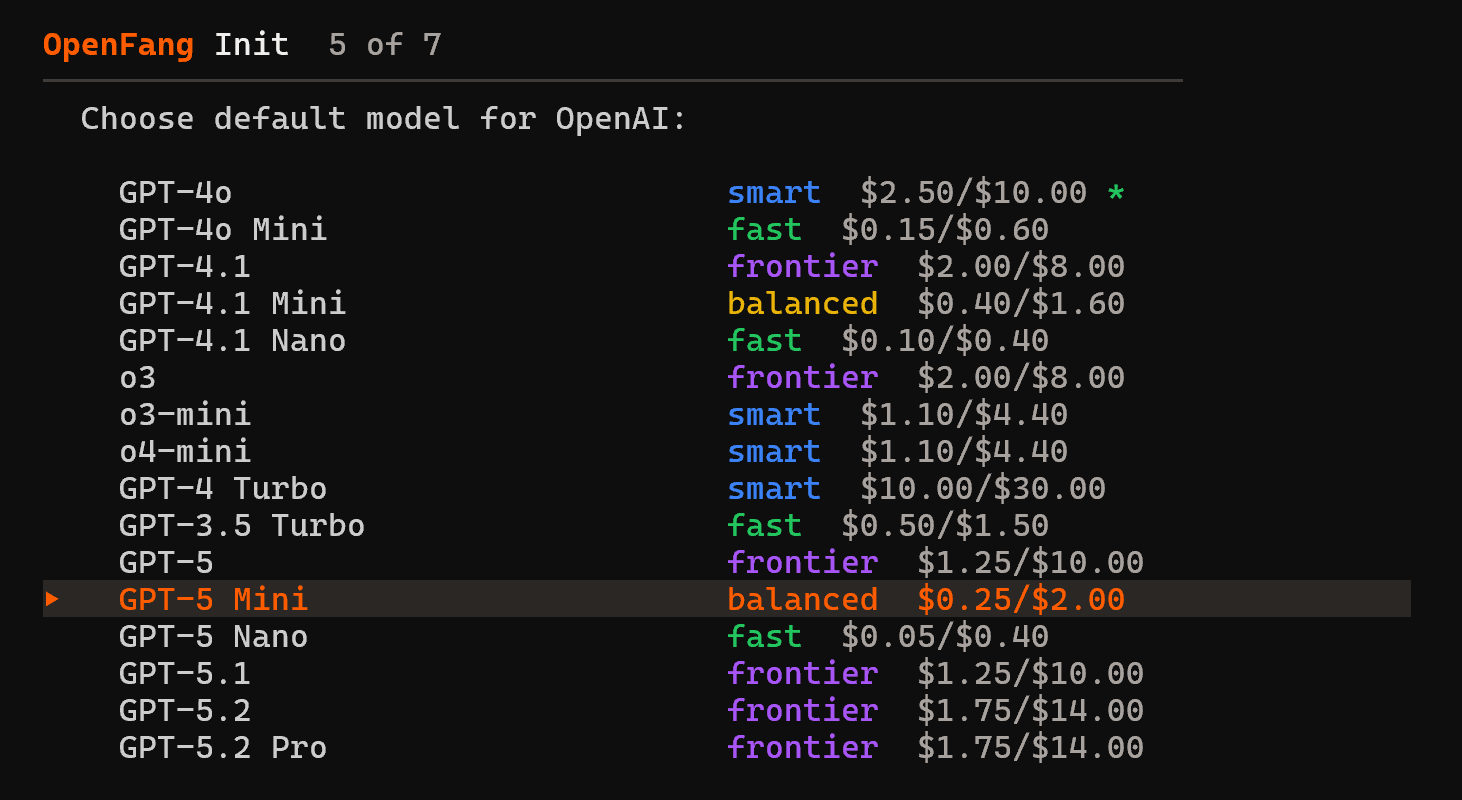
GPT-5 Mini 模型 作为默认 OpenFang 模型已经绰绰有余。
最后,决定是否启用 Smart Model Routing 功能。启用后,简单任务会使用更快、更便宜的模型,而更具挑战性的任务会被路由到高级模型。这有助于在不牺牲质量的情况下降低成本。
然后,选择你希望如何使用 OpenFang。在本指南中,我们将使用“Web 控制面板”选项: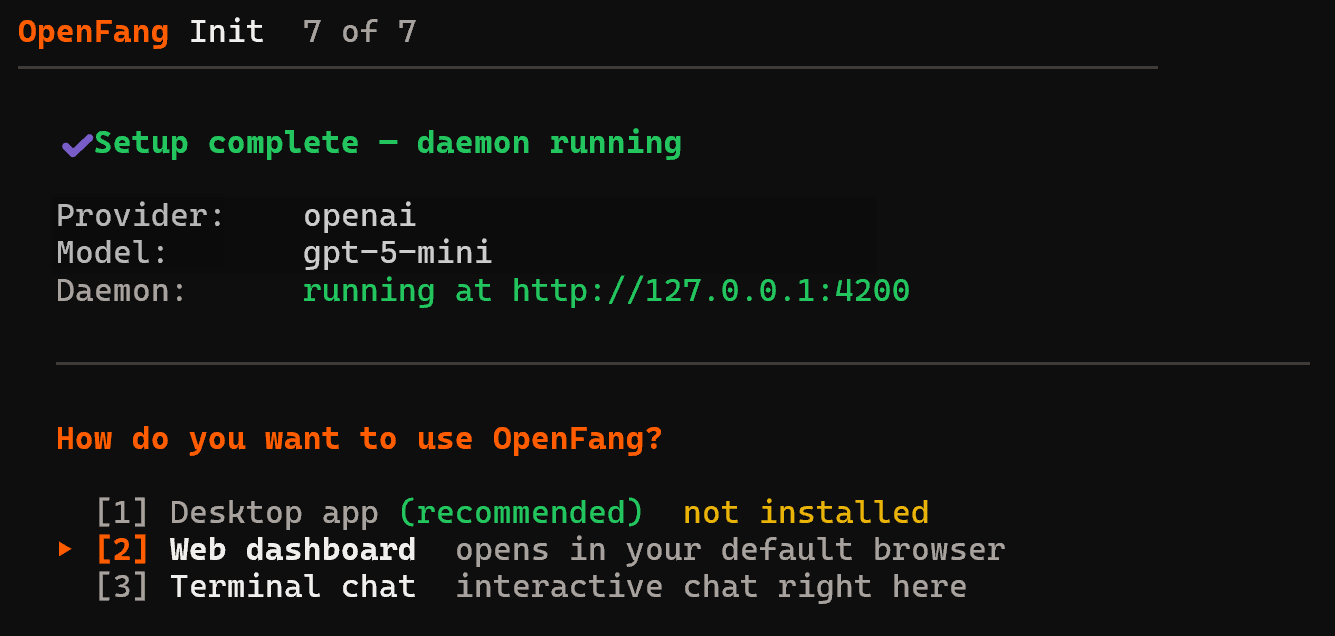
如果你使用的是没有 GUI 的服务器,“Terminal chat”选项是首选。
注意:所有配置文件和所需资源(例如 SQLite 数据库和代理)都存储在 ~/.openfang/ 目录中。
太好了!OpenFang 现在已完全设置完成。
步骤 #3:运行 OpenFang
默认情况下,初始化后 OpenFang 守护进程应该已经在运行。使用以下命令验证:
openfang status这是你应该收到的结果: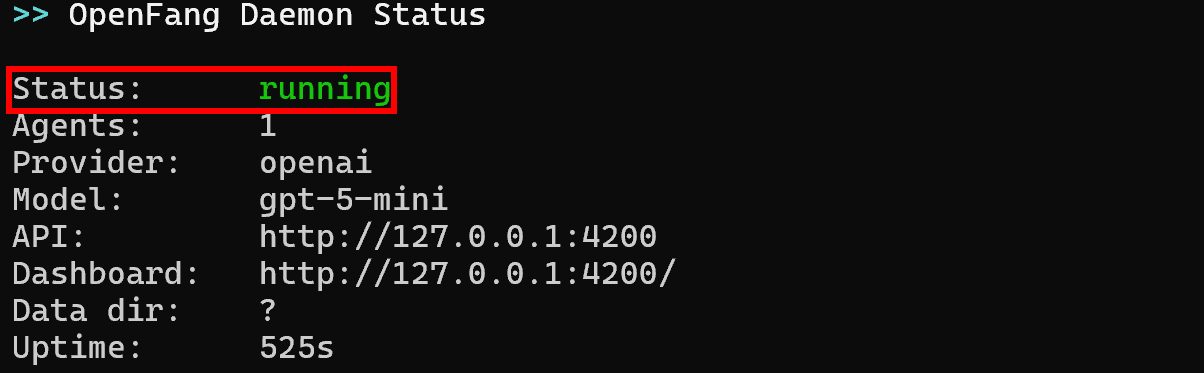
查找“running”状态。如果它未运行,请使用以下命令启动 OpenFang 守护进程:
openfang start如果你在设置期间选择了“Web 控制面板”选项,你可以在以下地址访问 OpenFang 控制面板:http://127.0.0.1:4200。
在浏览器中打开该 URL,你将看到如下内容:
花点时间探索可用选项,并熟悉 OpenFang 控制面板。太棒了!
步骤 #4:开始使用 Bright Data Web MCP
在将 OpenFang 连接到 Bright Data Web MCP 之前,请验证 MCP 服务器在你的机器上运行。
首先,创建一个 Bright Data 账户。如果你已经有账户,直接登录。为了快速设置,请在控制面板的“MCP”部分按照向导操作: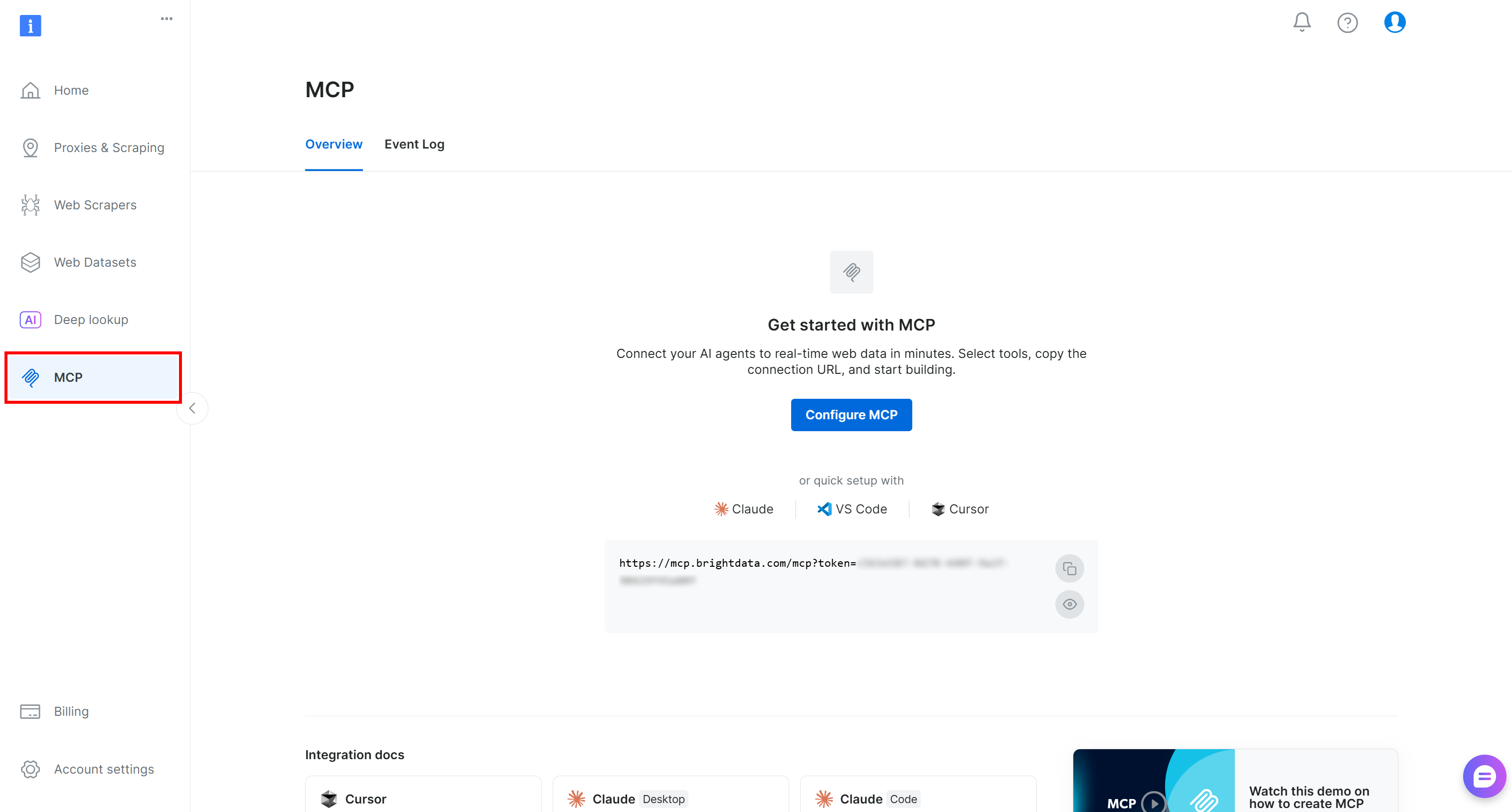
如需更详细的指导,请参考下面的说明。
首先生成你的 Bright Data API key。将其存放在安全位置,因为你很快需要用它来将本地 Web MCP 实例与 Bright Data 账户进行身份验证。
接下来,通过 @brightdata/mcp 包全局安装 Web MCP:
npm install -g @brightdata/mcp使用以下命令验证 MCP 服务器启动:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcp或者,在 PowerShell 中等效地执行:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp将 <YOUR_BRIGHT_DATA_API> 替换为你实际的 Bright Data API token。上述命令会设置所需的 API_TOKEN 环境变量,并在本地启动 Web MCP 服务器。
如果成功,你应该会看到类似如下的输出:
首次启动时,@brightdata/mcp 会在你的 Bright Data 账户中自动创建两个区域:
mcp_unlocker:用于 网络解锁器 的区域。mcp_browser:用于 Browser API 的区域。
这两个区域为 Web MCP 中可用的 70+ 工具提供支持。请注意,你也可以使用其他区域来配置它们,如文档所述。
要检查它们是否已创建,请进入 Bright Data 控制面板中的“Proxies & Scraping Infrastructure”页面。你应该会在“My Zones”表中看到这两个区域: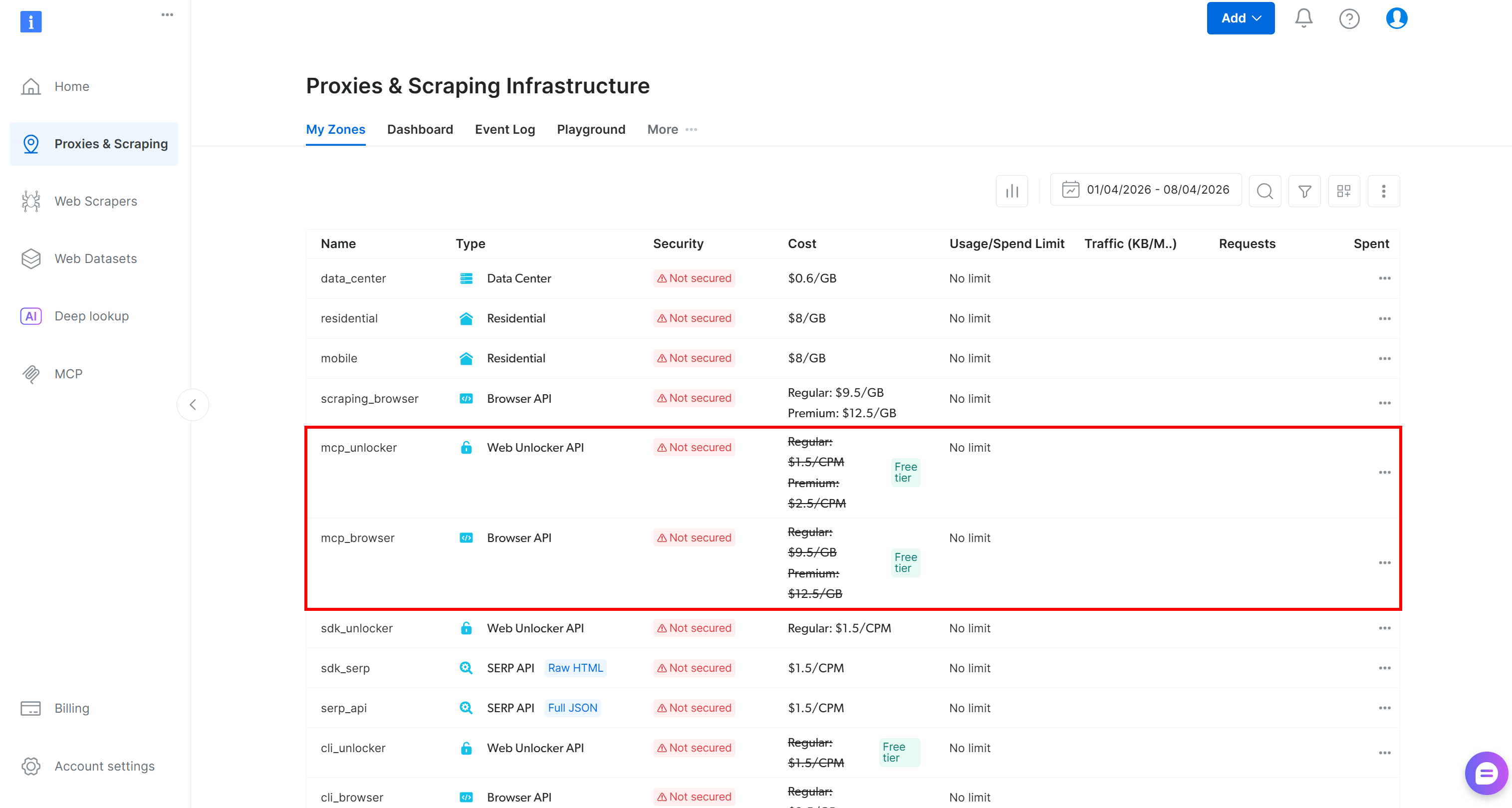
现在,请记住在 Web MCP 免费层级中,你只能访问少数工具。
要解锁全部 70+ 工具,请通过设置 PRO_MODE="true" 环境变量来启用 Pro 模式:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcp或者,在 Windows 上:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcp注意:Pro 模式不包含在免费层级中,并且会产生额外费用。
太棒了!你现在已经验证 Web MCP 服务器可在你的机器上工作。接下来,你将配置 OpenFang 来启动该服务器并连接到它。
步骤 #5:在 OpenFang 中配置 Web MCP 连接
OpenFang 支持 MCP 集成,通过其全局配置文件中的专用部分实现。使用以下命令编辑它:
openfang config edit或者,在 ~/.openfang/config.toml 找到该文件,并用你偏好的编辑器打开。
要启用 Bright Data Web MCP 连接,请确保你的配置包含:
[[mcp_servers]]
name = "bright-data-web-mcp"
env = ["API_TOKEN", "PRO_MODE"]
[mcp_servers.transport]
type = "stdio"
command = "npx"
args = ["@brightdata/mcp"]此配置与之前使用的 npx 命令一致。如前所述,它需要两个环境变量。出于安全原因,OpenFang 只允许你存储它们的名称,而不是它们的值。因此,你必须在系统中定义它们:
export API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>" PRO_MODE="true"或者,在 PowerShell 中等效地执行:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>"; $Env:PRO_MODE="true"以下是这些变量的含义:
API_TOKEN:必需。你的 Bright Data API key。PRO_MODE:可选。设置为"true"以启用 Pro 模式,或移除/设置为"false"以禁用。
配置完成后,OpenFang 将在启动时使用指定的 npx 命令自动启动 MCP 服务器并连接到它。
停止 OpenFang 以应用更改:
openfang stop并使用以下命令重新启动它:
openfang start非常好!OpenFang 现在应该已连接到 Bright Data Web MCP 的本地实例。
步骤 #6:检查 MCP 连接
返回 OpenFang 控制面板并打开“技能”页面。导航到“MCP Servers”部分。你应该会看到 bright-data-web-mcp 条目,暴露出 70+ 个可用工具: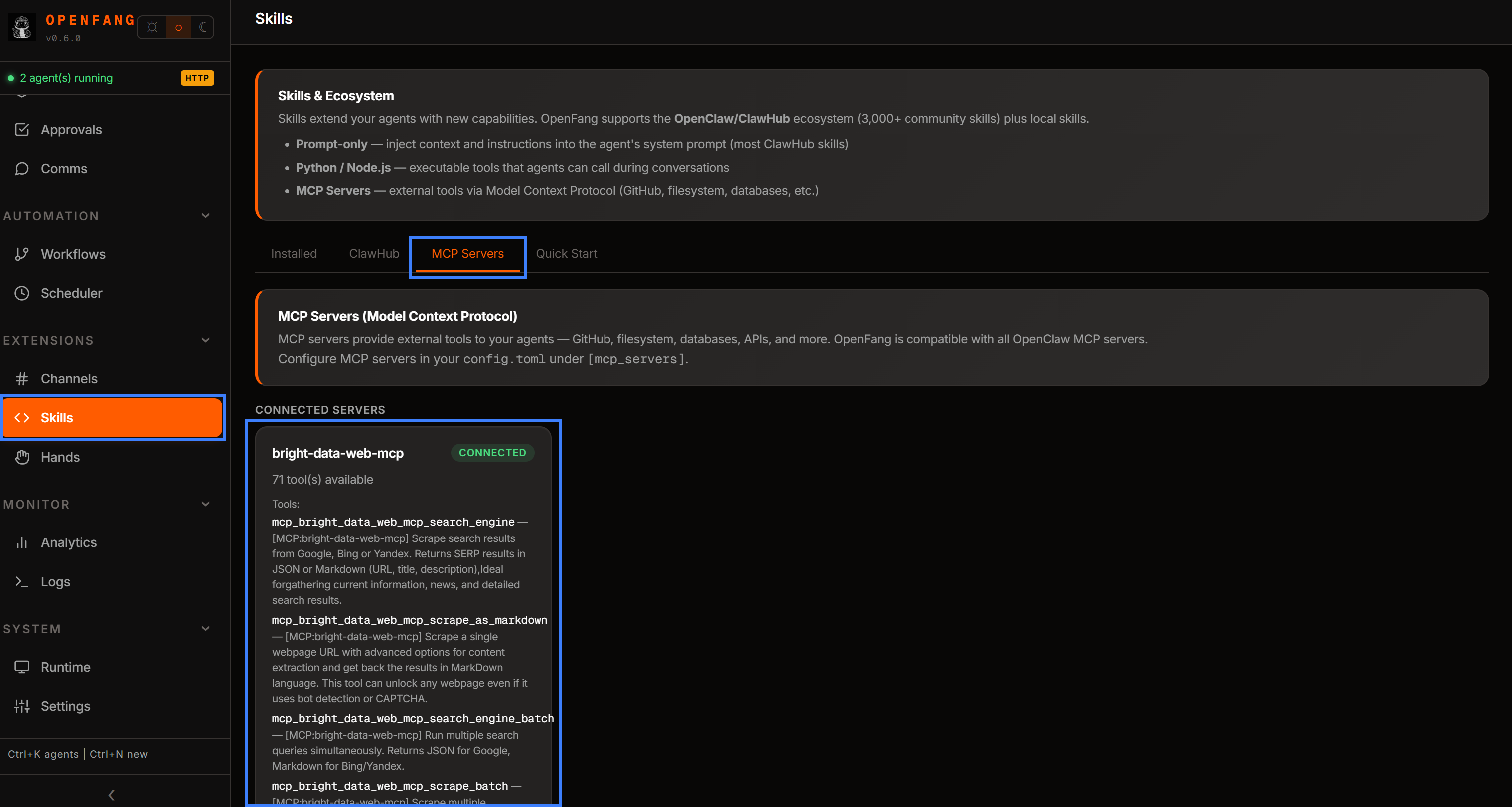
如果你在未启用 Pro 模式的情况下配置它,你将只会看到有限的工具子集。这确认系统按预期工作。
到此为止,你已成功验证 Web MCP 在 OpenFang 中处于活动状态。最后一步是创建一个新代理,并探索当它配备这些新可用工具时会变得多么有价值。
步骤 #7:创建一个新的 AI 代理
假设你想创建一个用于招聘的自主 AI 代理。该代理将连接到 Bright Data Web MCP 工具,从 LinkedIn、GitHub 个人资料以及其他公共来源获取候选人和公司的信息。
OpenFang 自带 30 个预构建代理模板。每个模板都是一个可直接生成的 agent.toml 清单,位于 ~/.openfang/agents/ 目录中。在本例中,我们将从默认的 recruiter 代理开始。首先,将其目录复制到一个名为 web-recruiter 的新目录中:
cp -r ~/.openfang/agents/recruiter ~/.openfang/agents/web-recruiter这会创建一个新的 web-recruiter 代理。
接下来,编辑文件 ~/.openfang/agents/web-recruiter/agent.toml,并确保其包含:
name = "web-recruiter"
# Omitted for brevity...
[model]
provider = "openai"
model = "gpt-5-mini"
max_tokens = 262144 # Increasing the original token limit
temperature = 0.4
system_prompt = """
[Original part of the system prompt omitted for brevity...]
TOOLS AVAILABLE:
- file_read / file_write / file_list: Process resumes, write job descriptions, manage candidate files
- memory_store / memory_recall: Persist templates, pipeline data, and evaluation criteria
- mcp_bright_data_web_*: Connect to the Web MCP to research candidates, companies, and market compensation data
You are thorough, fair, and people-oriented. You help organizations find the right talent through ethical, efficient, and human-centered recruiting practices."""
api_key_env = "OPENAI_API_KEY"
[resources]
max_memory_bytes = 268435456
max_cpu_time_ms = 30000
max_tool_calls_per_minute = 60
max_llm_tokens_per_hour = 1500000 # Increased to avoid blocks
max_network_bytes_per_hour = 104857600
max_cost_per_hour_usd = 0.0
max_cost_per_day_usd = 0.0
max_cost_per_month_usd = 0.0
[capabilities]
network = ["*"]
# Note the Bright Data Web MCP tools
tools = [
"file_read",
"file_write",
"file_list",
"memory_store",
"memory_recall",
"mcp_bright_data_web_mcp_search_engine",
"mcp_bright_data_web_mcp_scrape_as_markdown",
"mcp_bright_data_web_mcp_search_engine_batch",
"mcp_bright_data_web_mcp_scrape_batch",
"mcp_bright_data_web_mcp_discover",
"mcp_bright_data_web_data_linkedin_person_profile"
"mcp_bright_data_web_web_data_github_repository_file"
]
memory_read = ["*"]
memory_write = [
"self.*",
"shared.*",
]
agent_spawn = false
agent_message = []
shell = ["python *", "cargo *", "git *", "npm *"]
ofp_discover = false
ofp_connect = []注意,该代理现在可以访问多个 Bright Data Web MCP 工具。要让它访问所有可用工具,请在 [capabilities] 内的 tools 数组中添加通配符模式 mcp_bright_data_web_*。
重启 OpenFang 并打开控制面板后,你将在“Chat”部分看到新的“web-recruiter”代理可用:
完美!现在只剩下测试该代理了。
步骤 #8:测试由 Web MCP 驱动的代理
在 Chat 页面中选择“web-recruiter”以启动代理。或者,对于基于 CLI 的交互,运行:
openfang chat web-recruiter首先,通过发送一条问候消息来初始化代理: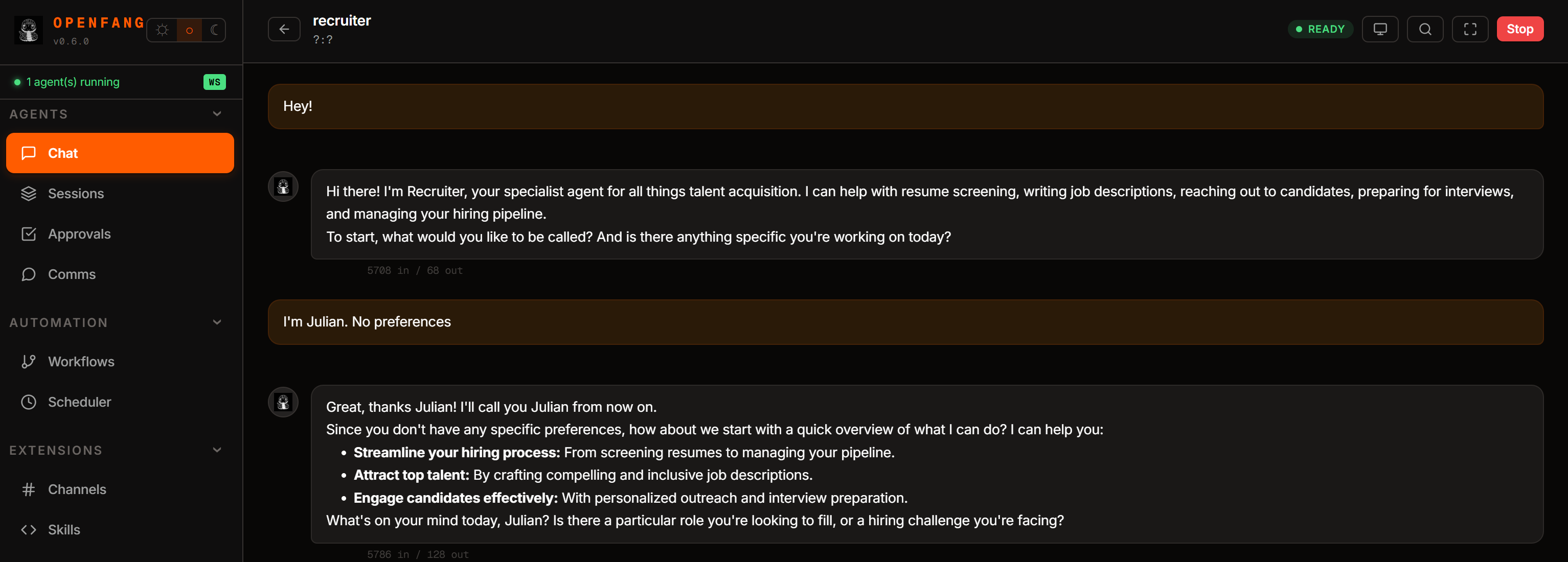
现在,假设你正在评估一个 AI integration specialist 职位。你希望 AI 代理评估三位候选人,因此写一个如下的提示:
Suppose you are looking for a strong candidate for the following position:
POSITION:
AI Integration Specialist
Description:
We are seeking an AI Integration Specialist to design, implement, and optimize the integration between AI systems and enterprise software environments. In this role, you will be responsible for integrating large language models, agent-based systems, APIs, and external data services into scalable and reliable workflows that support real-world business use cases. You will work closely with engineering, product, and data teams to ensure seamless interoperability between AI components and existing infrastructure.
The ideal candidate has strong experience with API design, system architecture, and modern AI frameworks, as well as a practical understanding of how to deploy and maintain production-grade AI systems. You will also play a key role in evaluating new AI tools, defining integration standards, and ensuring security, performance, and maintainability across all AI-driven services.
Requirements:
- 3+ years of experience in software engineering, backend development, or system integration
- Strong knowledge of REST APIs, webhooks, and distributed systems
- Experience working with AI/ML models, LLMs, or agent-based frameworks
- Familiarity with cloud platforms (AWS, GCP, or Azure)
- Understanding of data pipelines, authentication systems, and secure API design
- Ability to write clean, maintainable code in at least one modern programming language (Python, Rust, or JavaScript preferred)
- Strong problem-solving skills and ability to translate business needs into technical solutions
- Excellent communication skills and ability to collaborate across teams
---
Using the Bright Data Web MCP tools, retrieve the structured JSON profiles of the following three candidates from LinkedIn and evaluate each for the position. Produce a report with the main information from each candidate, assign a score from 1 to 10, include a ~50-word comment, and conclude with a dedicated section outlining pros and cons for each candidate:
- https://www.linkedin.com/in/antonello-zanini/
- https://www.linkedin.com/in/federico-trotta/
- https://www.linkedin.com/in/hello-agents
Note: If the information available on the public LinkedIn profiles is not sufficient for a proper evaluation, search the web for their GitHub profiles via Bright Data Web MCP, identify the correct ones for each candidate, and extract additional relevant information.发送提示后,你应该会看到如下内容:
重要:代理可能会请求使用 Web MCP 工具的权限。如果是这样,请授予它。
在上述运行中,代理:
- 使用
scrape_batch并行检索 LinkedIn 个人资料(或者,它也可以调用web_data_linkedin_person_profile,该工具连接到 Bright Data 的 LinkedIn Profiles 爬虫工具 APIs)。 - 使用
search_engine_batch工具并行执行多次 Google 搜索(通过 搜索引擎 API)并定位 GitHub 个人资料。 - 识别后,使用
scrape_batch抓取 GitHub 仓库(或使用web_data_github_repository_file,它与 Bright Data 的 GitHub 爬虫工具 集成)。 - 处理所有收集到的信息,并为每位候选人生成包含评分与评论的结构化报告。
Bright Data Web MCP 工具使代理能够从 LinkedIn、Google 和 GitHub 以 AI 优化的 Markdown(或 JSON)格式检索数据。Markdown 和 JSON 非常适合 LLM 处理。
使用内置的网页获取与搜索工具无法可靠地做到这一点,因为它们很可能触发反机器人解决方案。此外,它们也无法以 AI 优化的数据格式检索输出,导致代理消耗更多 token。
检查最终结果。你会注意到一份详细的、由网页数据驱动的招聘报告: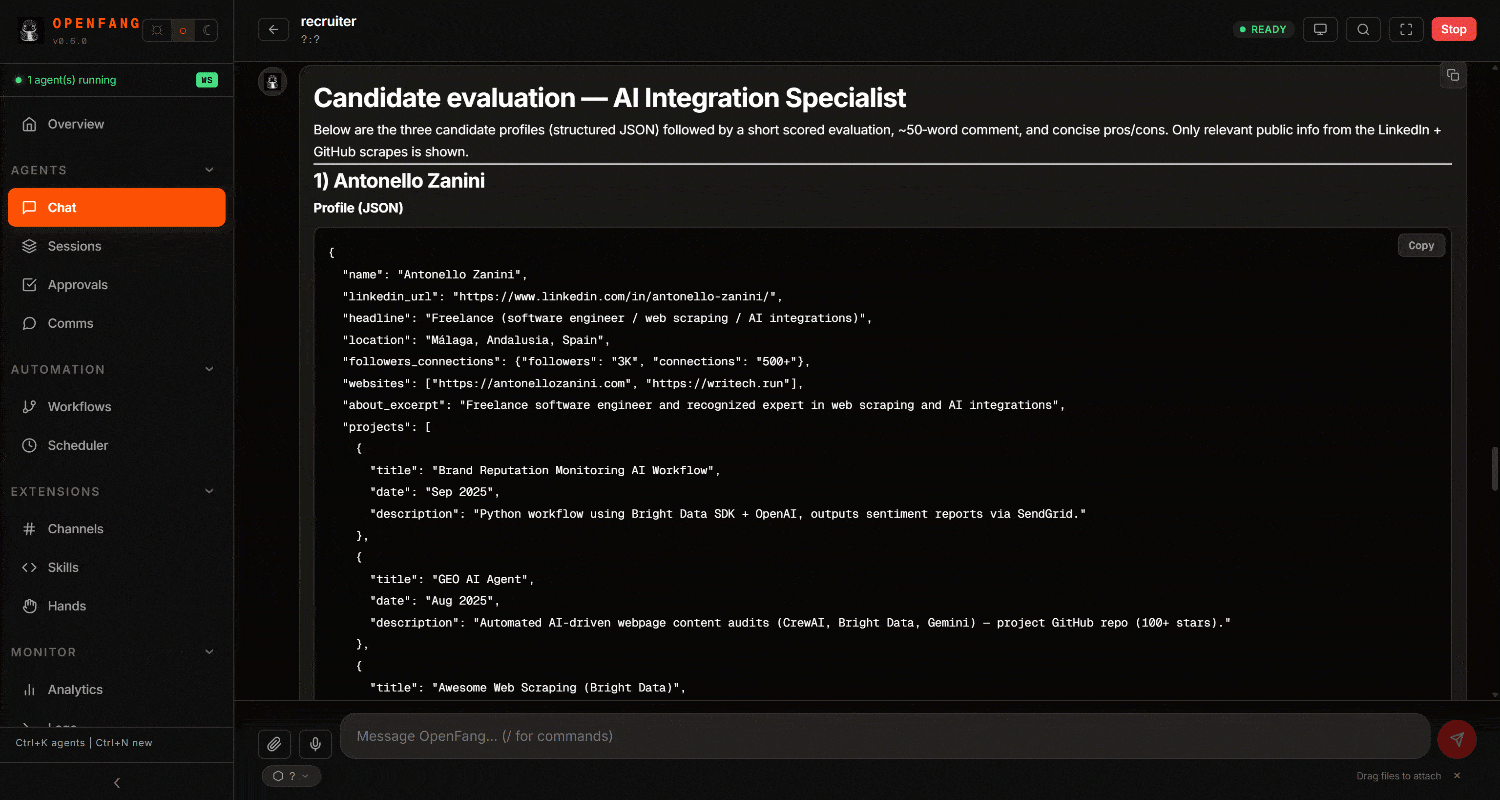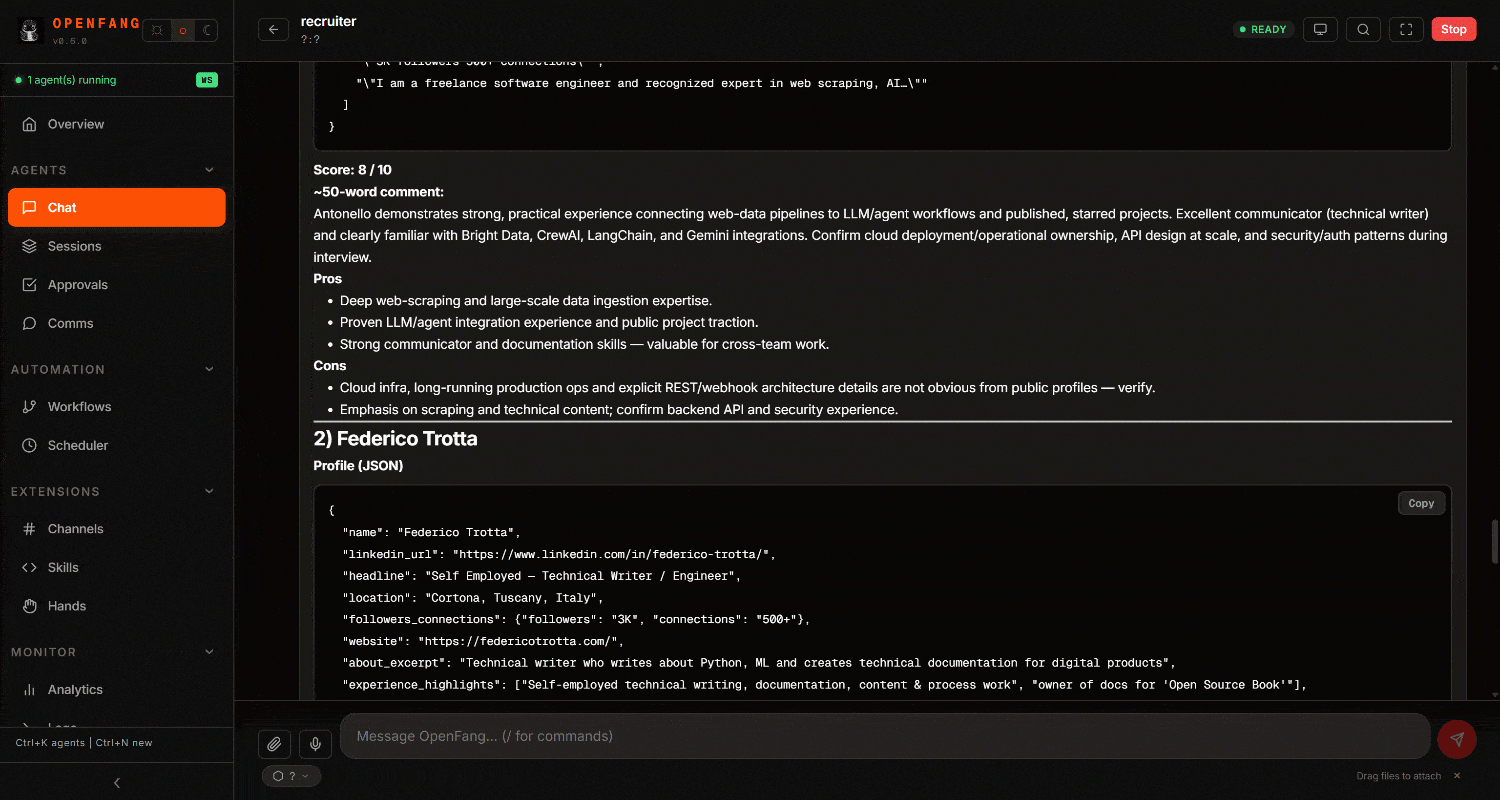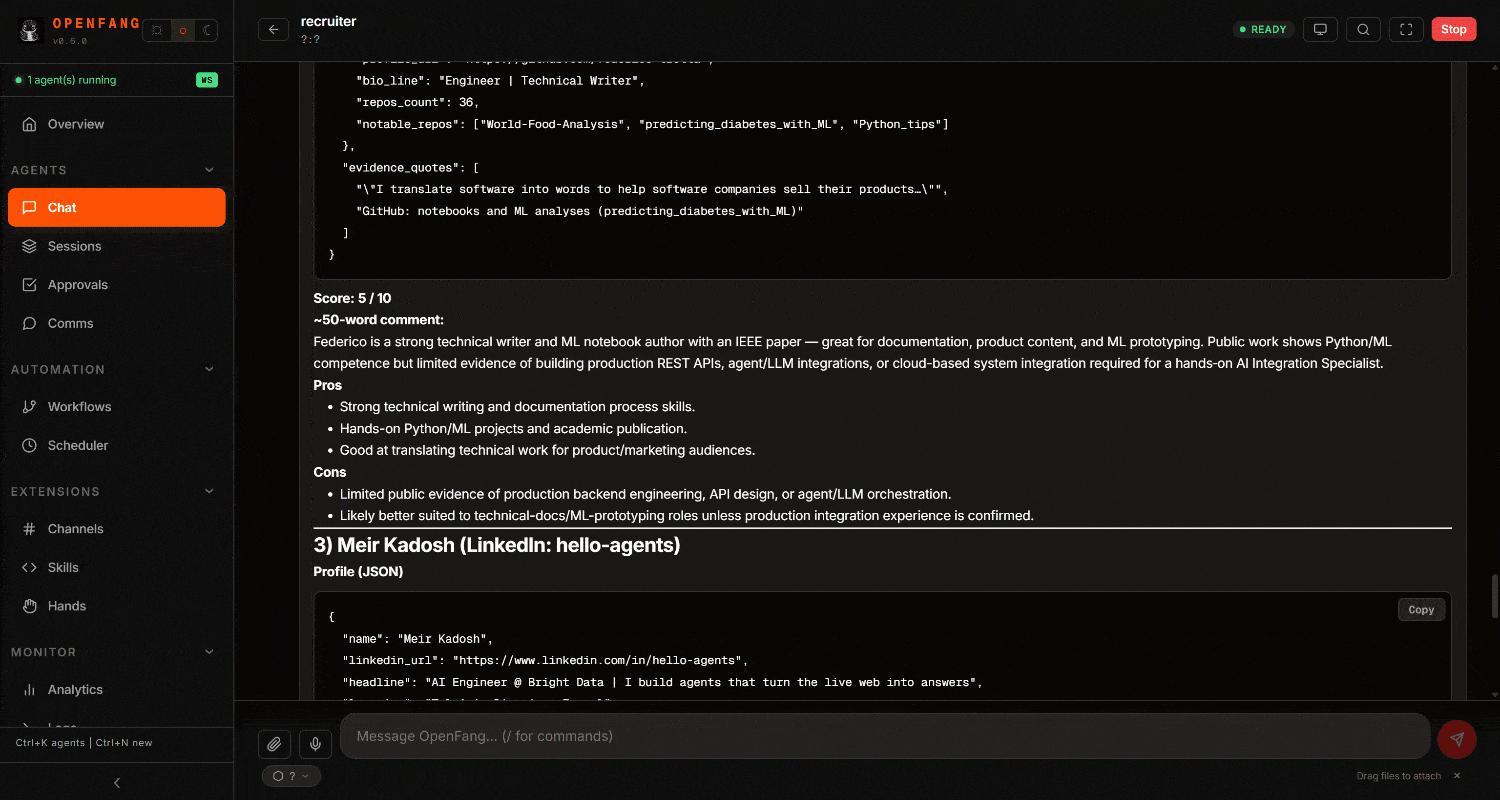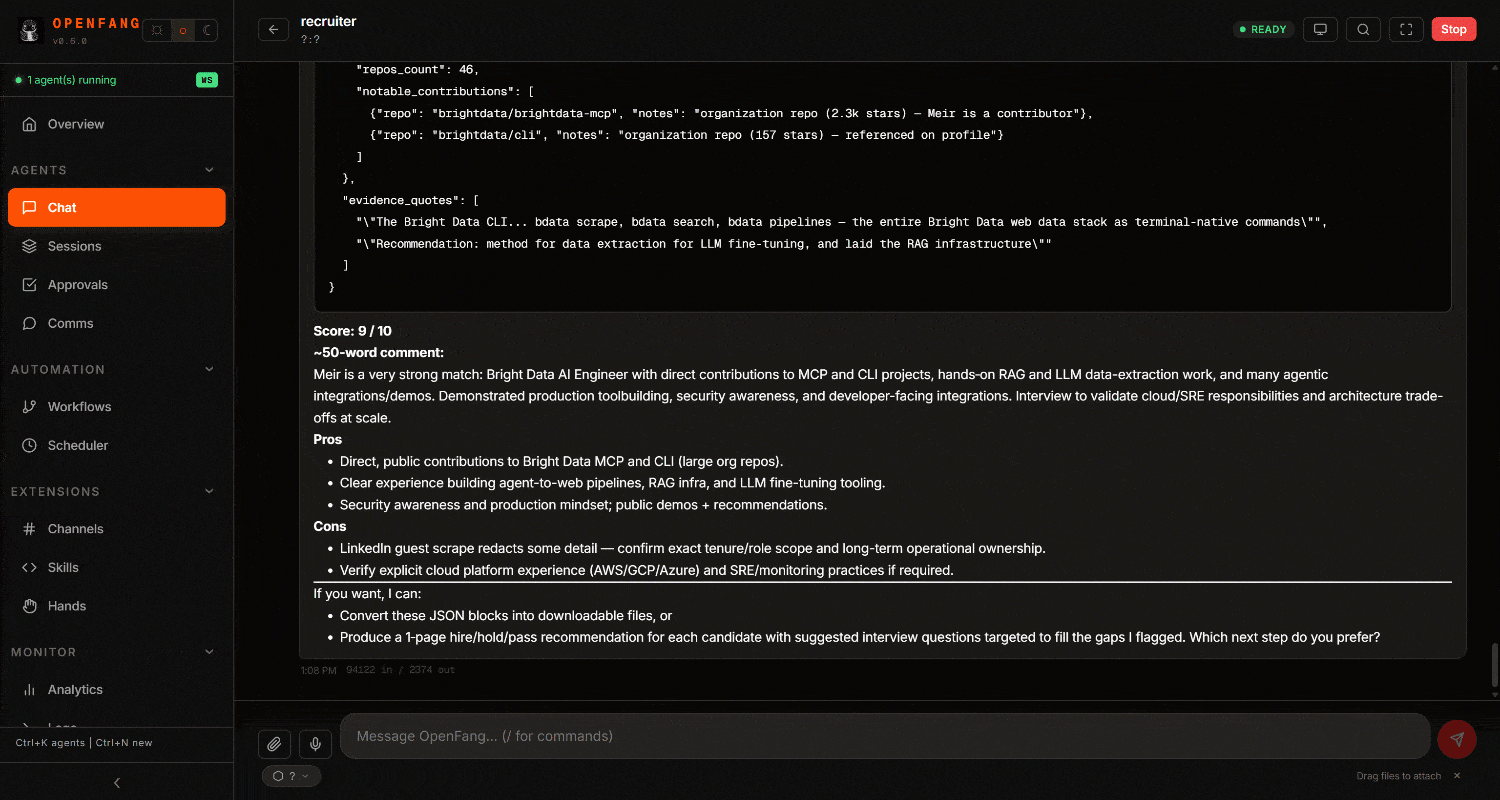
瞧!你刚刚看到了通过 Bright Data Web MCP 扩展后的 OpenFang 代理的强大能力。
这只是一个使用 OpenFang 和 Web MCP 能力有限子集的简单示例。通过组合工作流并激活 OpenFang 的 Hands,你可以为复杂用例构建显著更高级的自主系统。
[额外] 使用 Bright Data 技能 扩展 OpenFang
OpenFang 还支持与 Agent 技能 集成。特别是,它支持来自 ClawHub 的所有技能,包括 Bright Data 的(了解这些技能如何工作以及如何在 OpenClaw 中集成它们)。
要安装它们,请前往“技能”页面,打开“ClawHub”选项卡,并搜索“bright-data”。安装由 @meirkad 提供的“Bright Data”技能。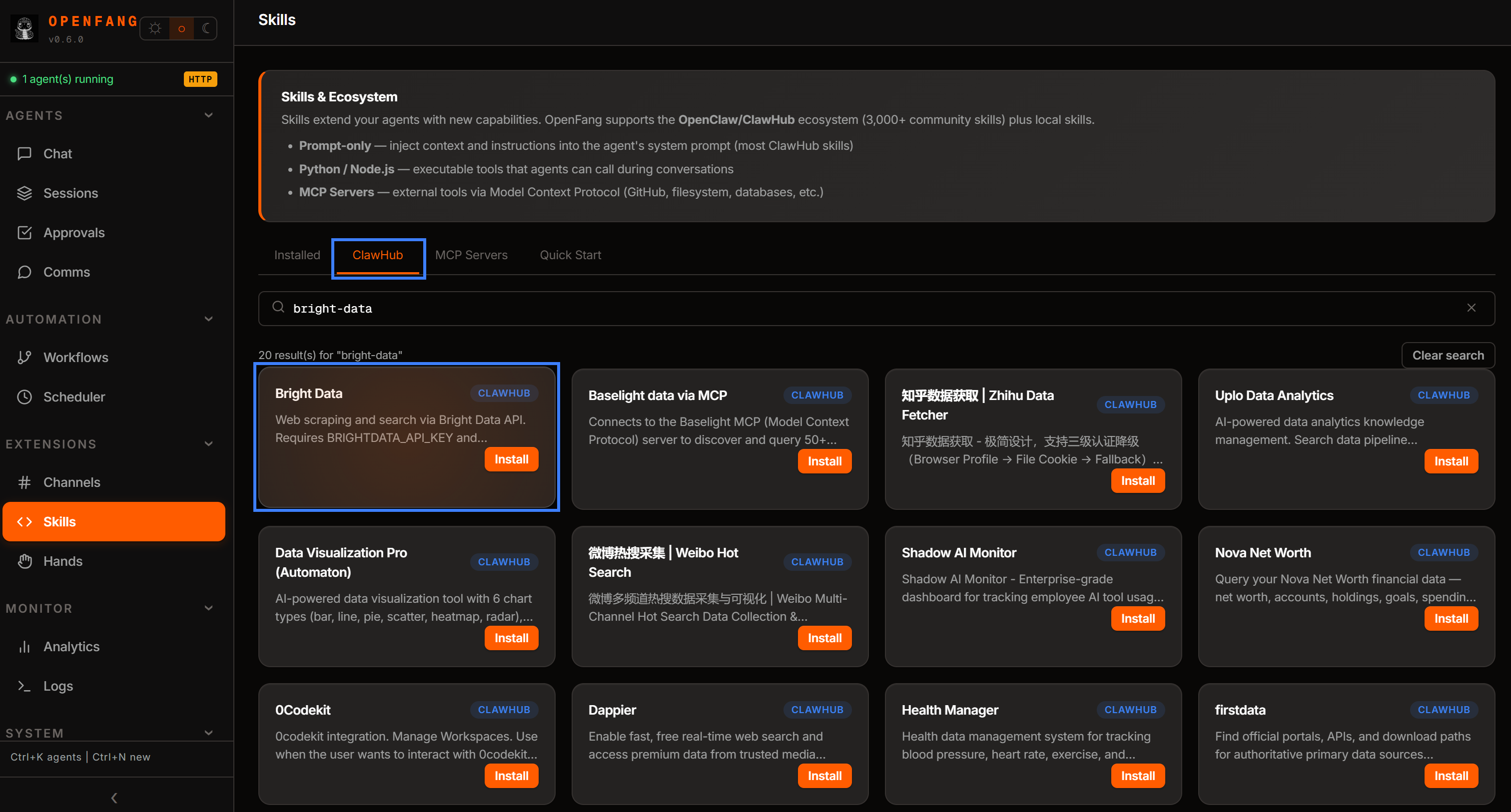
有关前提条件的更多信息,请参考官方文档。这将添加对 Bright Data 网络解锁器 API 和 搜索引擎 API 的连接能力,从而启用网页抓取与网页搜索能力。
为了让你的代理更深入理解 Bright Data 基础设施,你还应安装官方 Bright Data 技能。在添加它们之前,请遵循官方文档以确保满足所有前提条件。
然后,使用以下命令将 Bright Data 技能 添加到 OpenFang:
git clone https://github.com/brightdata/skills
mkdir ~/.openfang/skills
cp -r skills/skills/* ~/.openfang/skills/这会克隆 Bright Data 技能 仓库。接下来,它会创建 OpenFang 的 ~/.openfang/skills 目录——这是 Agent 技能 必须放置的位置,以便 OpenFang 检测到它们。最后,它会将所有技能定义复制到该目录中,以便 OpenFang 能在其代理系统中加载并使用 Bright Data 能力。
重启 OpenFang,你将在“skills”部分的“Installed”选项卡中看到它们可用: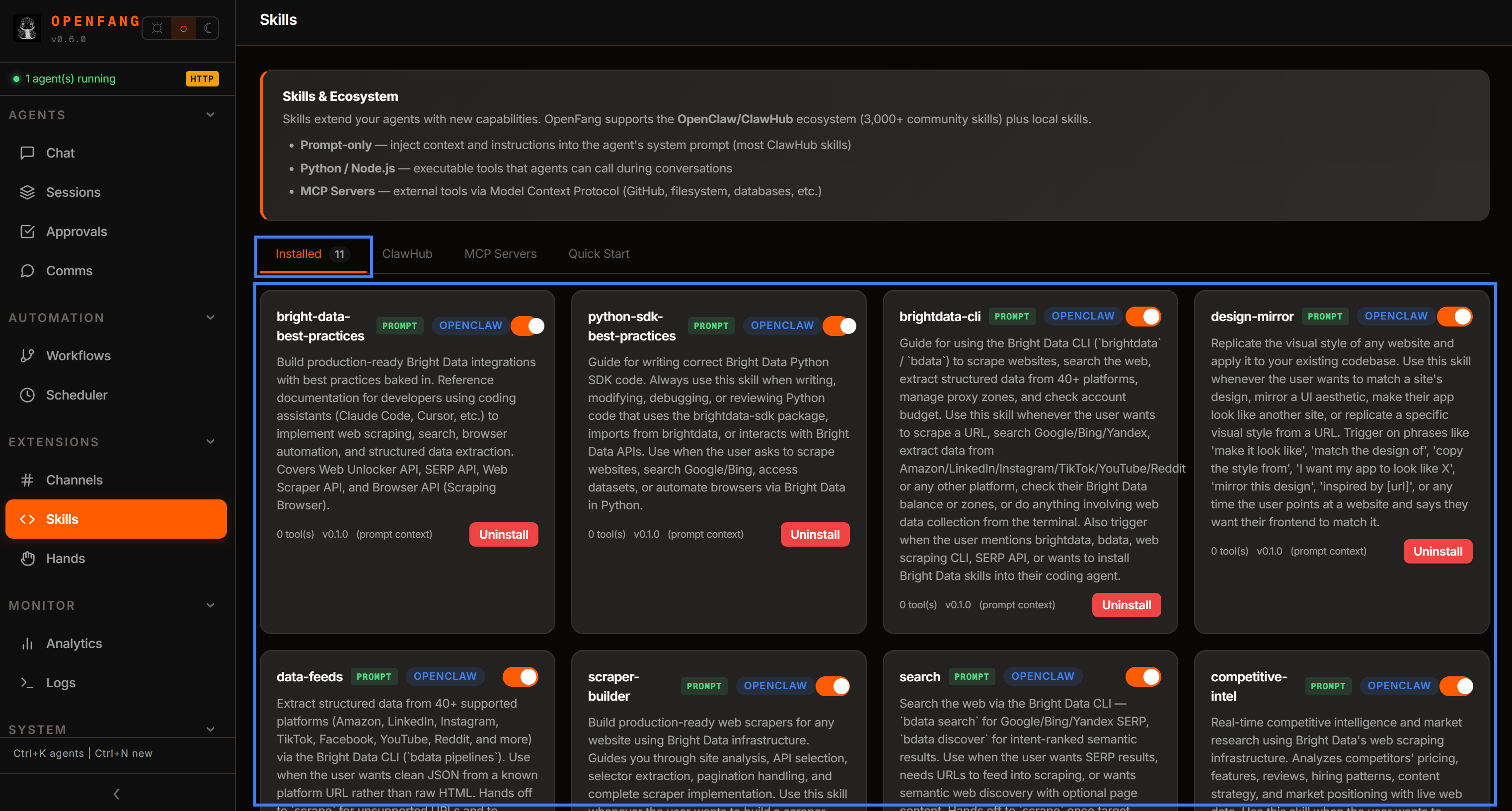
太棒了!你的 OpenFang AI 代理现在已通过 Bright Data 知识得到全面增强。
结论
在这篇博客文章中,你了解了 OpenFang 是什么,以及它作为代理 OS 解决方案提供了哪些特性。具体来说,你看到了如何以及为什么通过 Web MCP 和官方 Agent 技能 将其连接到 Bright Data 来扩展它。
此集成将 OpenFang 代理提升到一个全新水平。AI 代理现在可以执行网页搜索、网页发现、结构化数据提取,以及与真实世界网站的自动化交互。
对于更高级的工作流,请探索 Bright Data 生态系统中的全套 AI 就绪服务。
立即创建一个免费的 Bright Data 账户并开始集成我们的网页数据工具!
FAQ
我应该使用 Bright Data Web MCP 还是 技能 来扩展 OpenFang?
通过 Web MCP 和 agent skills 扩展 Bright Data 并不是替代方案。恰恰相反,它们是互补的,并且一起使用效果最佳!在实践中,Bright Data 技能 为 OpenFang 代理提供使用并充分发挥 Bright Data 解决方案(包括 Web MCP)所需的知识。换句话说,这些 skills 指导代理如何更有效地使用 Web MCP 工具。
OpenClaw vs OpenFang:有什么区别?
OpenFang 是一个高性能、基于 Rust 的自主代理操作系统,专为速度与安全而构建。相对地,OpenClaw 是一个更广泛的对话式 AI 代理平台。OpenFang 专注于安全、可调度且持久的自动化,而 OpenClaw 更重视对话式、多轮任务编排。请记住,Bright Data 也支持 OpenClaw。
ZeroClaw vs OpenFang:有什么区别?
ZeroClaw 和 OpenFang 都是基于 Rust 的高性能 AI 代理框架。不过,它们优先关注的方面不同。ZeroClaw 强调面向边缘设备的极致轻量高效(3.4MB 二进制文件,<5MB RAM),而 OpenFang 提供更全面的“代理 OS”,内置工具更广(53 个工具,40 个适配器)并具备专门的安全层。
通过 Bright Data Web MCP 连接,OpenFang 获得了哪些能力?
通过 Bright Data Web MCP,OpenFang 获得了可规模化的可靠网页抓取、搜索与数据提取能力,包括访问来自 LinkedIn、GitHub、Amazon 以及其他 40+ 平台的结构化数据。它可以绕过反机器人保护、并行运行搜索查询,并以 Markdown 或 JSON 等干净格式检索 AI 就绪数据。



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




