
在本指南中,你将学习:
- AWS Step Functions 是什么,以及它为何对工作流自动化至关重要。
- 为什么网页抓取工作流非常适合使用这项 AWS 服务。
- Bright Data 如何帮助克服网页抓取的固有挑战。
- 如何将 Bright Data 集成到 AWS Step Functions 中:既可以通过直接 API 调用,也可以通过专用的 Lambda 函数。
让我们开始吧!
AWS Step Functions 简介
在展示如何使用 AWS Step Functions 编排网页抓取工作流之前,我们先进一步了解该方案的背景。
AWS Step Functions 是什么?
AWS Step Functions 是一项全托管服务,可让你在 AWS 各项服务之间协调与自动化复杂工作流。它是一项可视化编排服务,用于构建分布式应用,并通过将多个 AWS 服务连接为无服务器工作流来自动化流程。
从本质上讲,Step Functions 基于状态机(state machines),也就是由一系列步骤(称为“状态”)组成的工作流。每个状态会执行一项任务,例如调用某个 AWS 服务或运行自定义代码。
这种方式简化了编排、错误处理与监控,让你可以专注于应用逻辑而非基础设施。具体来说,它的主要优势包括:
- 简化编排:无需编写复杂代码即可管理多步骤流程及其依赖关系。
- 内置错误处理:重试与 catch 块可帮助工作流自动从失败中恢复。
- 并行与动态执行:并发运行任务或对数据集进行迭代,以实现更快处理。
- 支持人工介入(Human-in-the-loop):可在工作流中加入审批步骤或回调。
- 服务集成:可与 AWS Lambda、Glue、SQS、SNS、SageMaker 等无缝连接。
更多信息请参见 官方文档。
理解 AWS Step Functions 的工作原理
要真正理解 AWS Step Functions,建议从其核心概念入手,这些概念构成了任何工作流的基础:
- 状态机(State machine):Step Functions 的骨架。状态机代表你的工作流,会在任务推进过程中存储并更新状态。 你使用 JSON 与 Amazon States Language 来定义它。你可以选择用于长时间运行或需要人工介入的 Standard workflows,或用于短时、高吞吐任务的 Express workflows。
- 状态(States):工作流中的每一步。状态可以执行工作(Task)、做出决策(Choice)、暂停执行(Wait)、处理失败或成功(Fail/Succeed)、分支执行(Parallel),或对输入进行重复处理(Map)。不同状态的组合定义了你的工作流逻辑。
- 任务状态(Task states):工作流中的工作单元。服务任务(service tasks)可自动与 Lambda 或 Glue 等 AWS 服务交互;而活动任务(activity tasks)则连接外部代码或人工,适用于异步步骤或审批场景。
- 执行与监控(Execution and monitoring):Step Functions 会记录每一步的输入、输出、重试与错误,让你能够追踪问题并验证工作流行为。
无服务器网页抓取工作流编排
AWS Step Functions 提供了一种高效方式,可用可扩展且可靠的方式编排无服务器 网页抓取 工作流。 你无需构建一个庞大的单体抓取脚本,而是可以将流程拆分为更小的事件驱动步骤,并通过状态机对它们进行协调。
例如,一个工作流可能先触发数据采集任务,接着进行 数据解析 与校验,然后将结果存储到 Amazon S3 或数据库等服务中。 Step Functions 可以在与 AWS Lambda、AWS Glue 或 Amazon SQS 等服务集成的同时,协调这些步骤。
这种方式带来多项优势:更好的可扩展性、内置重试与错误处理、抓取任务的并行处理,以及对每次工作流执行的清晰监控。
然而,大规模网页抓取同样会面临挑战。原因在于许多网站实现了反机器人防护与 反爬机制,可能会拦截自动化请求。 常见示例包括限流、指纹识别、验证码(CAPTCHA)、JavaScript 挑战等。
在 AWS Step Functions 中实现无瑕疵的网页数据获取
对于使用 AWS Step Functions 编排网页抓取工作流的团队, Bright Data 提供了一套全面解决方案,支持成功的大规模网页数据获取。
Bright Data 提供 多种专用抓取服务,可与 Step Functions 无缝集成:
- SERP API:大规模获取搜索引擎结果,用于 SEO 洞察或市场分析。
- Web Unlocker:访问任意网页,绕过 CAPTCHA、JavaScript 障碍与 IP 限制等反机器人防护。
- Web Scraping APIs:以最少配置从电商平台、社交网络及其他网页来源获取结构化信息。
- Crawl API:从任意域名自动化提取全站内容,并输出为 Markdown、纯文本、HTML 或 JSON。
这些方案依托一个 覆盖 195+ 国家/地区、超过 1.5 亿个 IP 的代理网络, 为生产级用例提供无限并发能力。此外,所有服务都内置 Bright Data 的反机器人工具包,用于避免验证码与其他访问限制。
将 Step Functions 的编排能力与 Bright Data 的网页数据工具结合,可构建全自动化流水线,完成抽取、转换与存储。 这意味着即使在复杂的大规模、企业级场景中,也能持续稳定运行。
如何将 Bright Data 网页抓取方案集成到 AWS Step Functions
要将 Bright Data 集成到 AWS Step Functions 中以实现自动化网页数据获取,有两种方式:
- 使用 “HTTP Endpoint – Call HTTPS APIs” 节点:直接连接 Bright Data 的各类 API(Web Unlocker API、Web Scraping APIs、SERP API、Crawl API 等)。
- 使用 “AWS Lambda – Invoke” 节点:在 Lambda 函数中编写自定义代码(Python 或其他支持语言),与 Bright Data 产品集成以获取数据,并可选择应用特定逻辑 (例如只访问特定字段、以特定结构返回数据,或应用 自定义解析逻辑)。
在下方章节中,我们将带你分别完成这两种方式。但首先,我们来看看两种方法的优缺点。
HTTP Endpoint – Call HTTPS APIs 节点:优缺点
👍 优点:
- 搭建快速。
- 更易管理与维护。
- 适合抓取单个网页的数据。
👎 缺点:
- 自定义数据处理的灵活性有限。
- 更难处理需要多次、不同 Bright Data 抓取 API 调用的复杂工作流。
AWS Lambda – Invoke 节点:优缺点
👍 优点:
- 可完全控制网页数据处理与转换。
- 允许实现自定义逻辑(例如重试、条件分支等)。
- 可在单个函数中集成多个 Bright Data 服务。
👎 缺点:
- 需要用 Python、Node.js 或其他支持语言进行编码。
- 增加一个需要监控与维护的额外服务。
前置条件
要跟随下方的分步指导,你需要:
- 一个可用的 AWS 账号(即使是免费试用也可以)。
- 一个 Bright Data 账号,并准备好 API key。
- 对 RESTful HTTP 调用的基础了解,或具备用于 Lambda 集成的基础 Python 编程能力。
配置你的 Bright Data 账号
如果你还没有 Bright Data 账号,请先创建一个。否则,登录并 按照说明创建 API key。 你需要该 key 来对 HTTP 调用进行身份验证(无论你是从 HTTP 节点直接调用 Bright Data,还是在 Lambda 函数中调用)。
请确保你已设置好 Bright Data Web Unlocker API(如果你计划跟随 Lambda 教程部分,还需要 SERP API):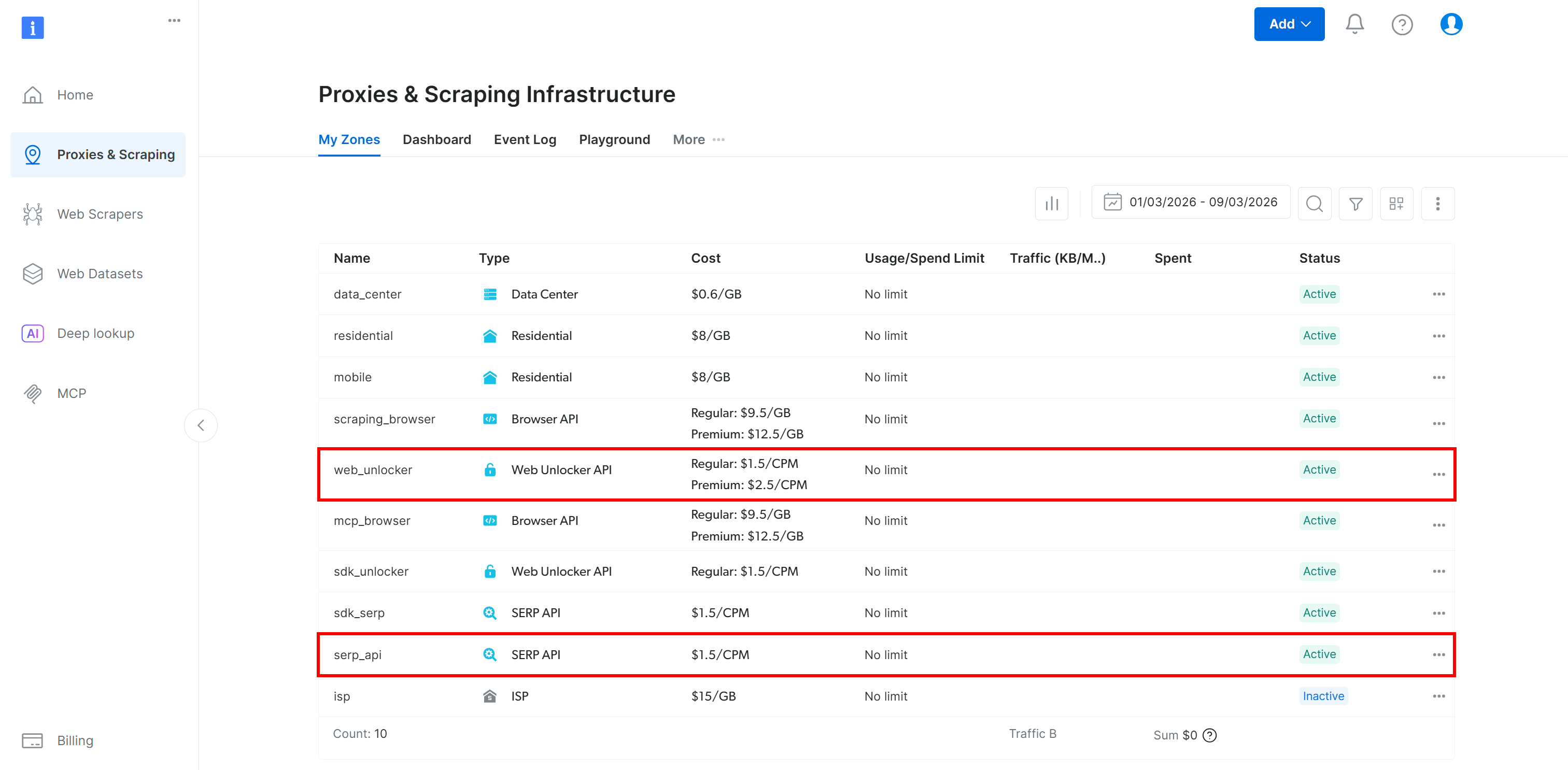
更多信息请参考以下文档页面:
设置你的 AWS Step Functions 工作流
首先 登录 AWS Console, 搜索 “Step Functions” 服务并打开服务页面: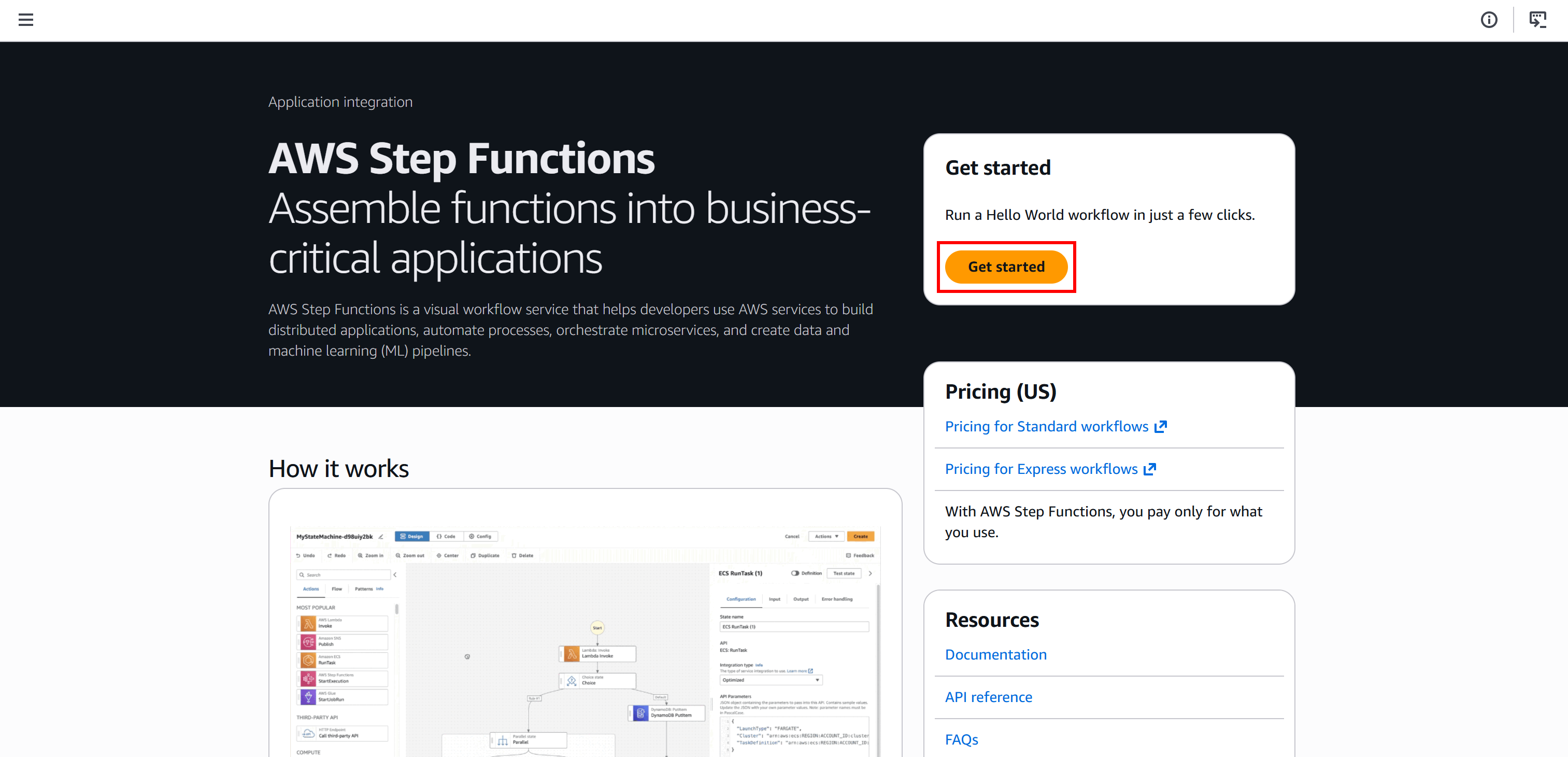
在这里,点击 “Get Started” 按钮,然后选择 “Create your own”,开始从零构建无服务器工作流: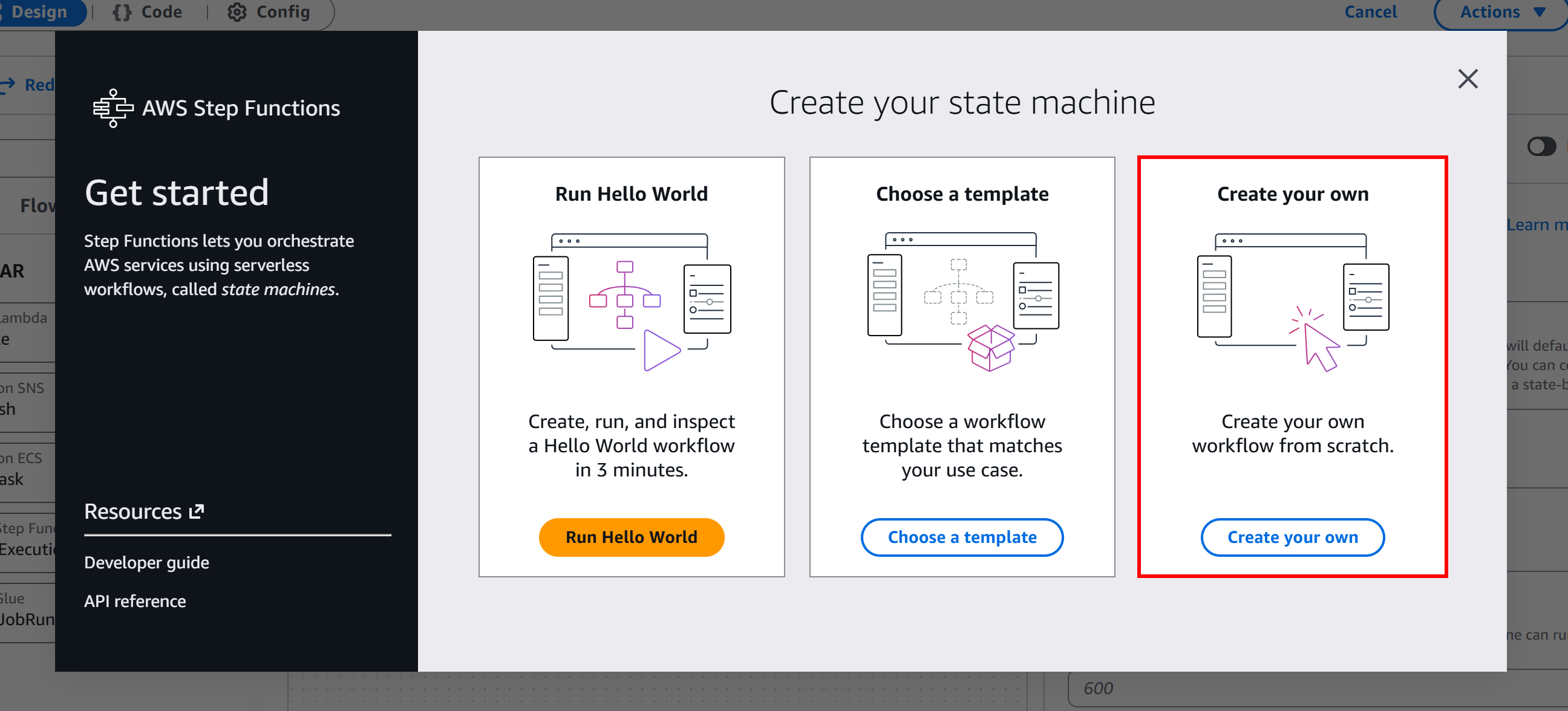
为你的状态机命名(例如 "BrightDataWebScrapingMachine"),并选择你要创建的状态机类型。 在本教程中,我们将使用 “Standard” 状态机: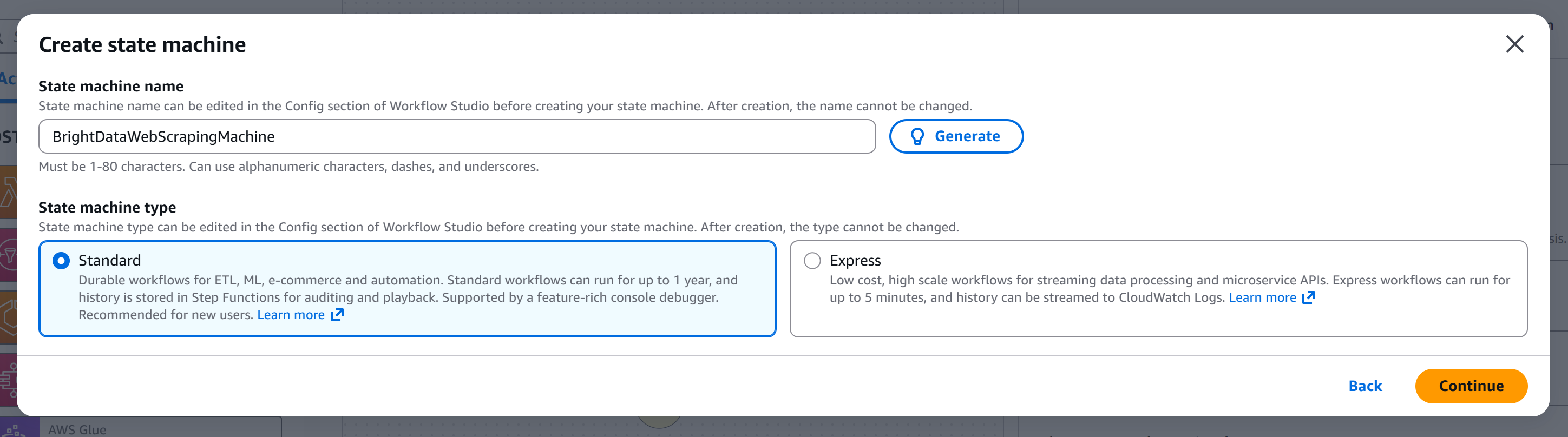
点击 “Continue” 进入工作流编辑器页面: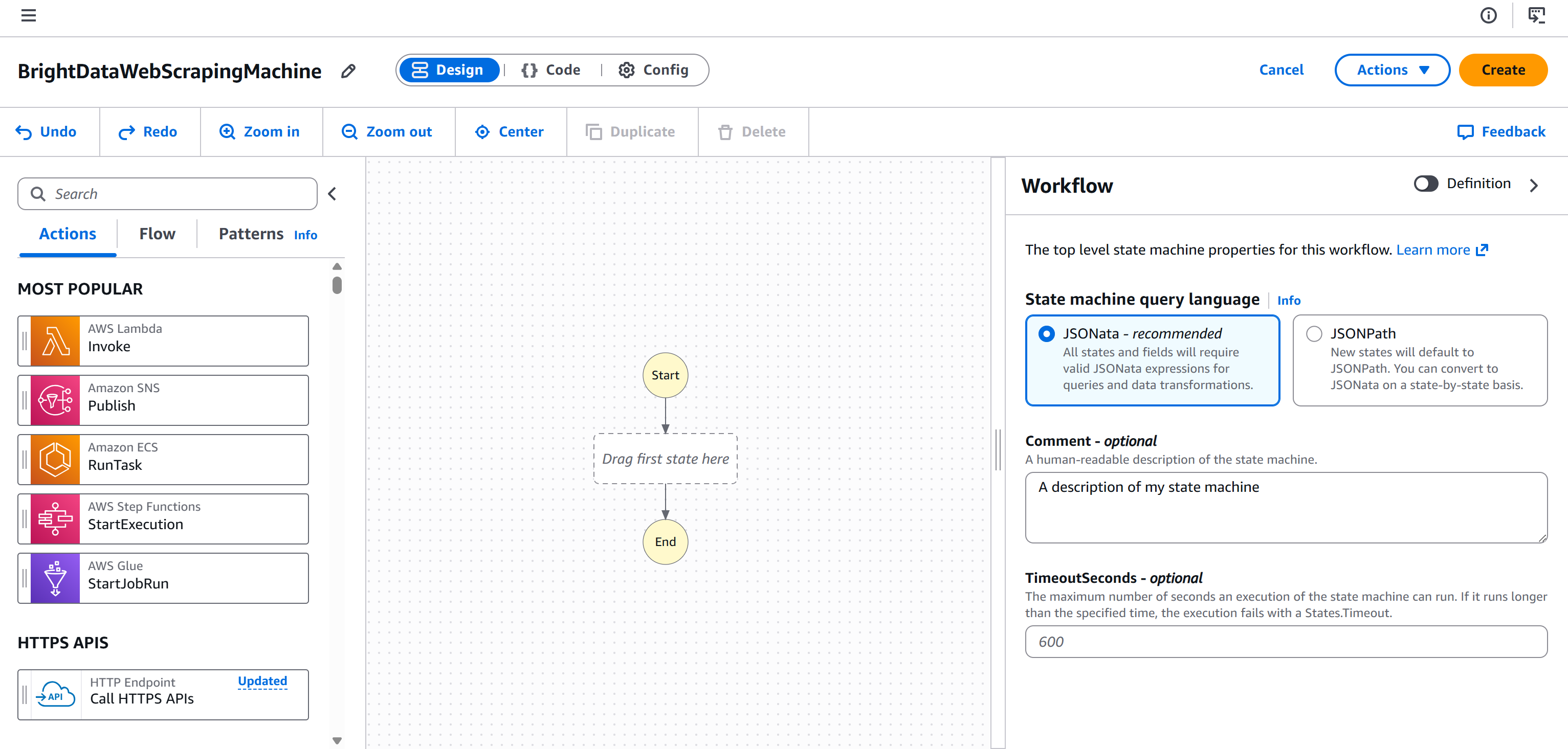
现在你已经完成所有基础设置,准备将 Bright Data 网页抓取节点添加到 AWS Step Functions 工作流中。
方法 #1:使用 “Call HTTPS APIs” 节点
在这里,你将学习如何定义一个通过 HTTP 调用直接连接 Bright Data Web Unlocker API 的节点。 该节点可让你以编程方式从任何网页抓取数据。我们将把它配置为以 Markdown 格式返回数据, 这种格式非常适合 LLM 摄取。
注意:同样的流程也可以用于连接 Bright Data 的其他任何基于 API 的产品。
步骤 #1:添加 “HTTP Endpoint – Call HTTPS APIs” 节点
首先在左侧面板选择 “HTTP Endpoint – Call HTTPS APIs” 节点,并将其拖到 “Drag first state here” 区域: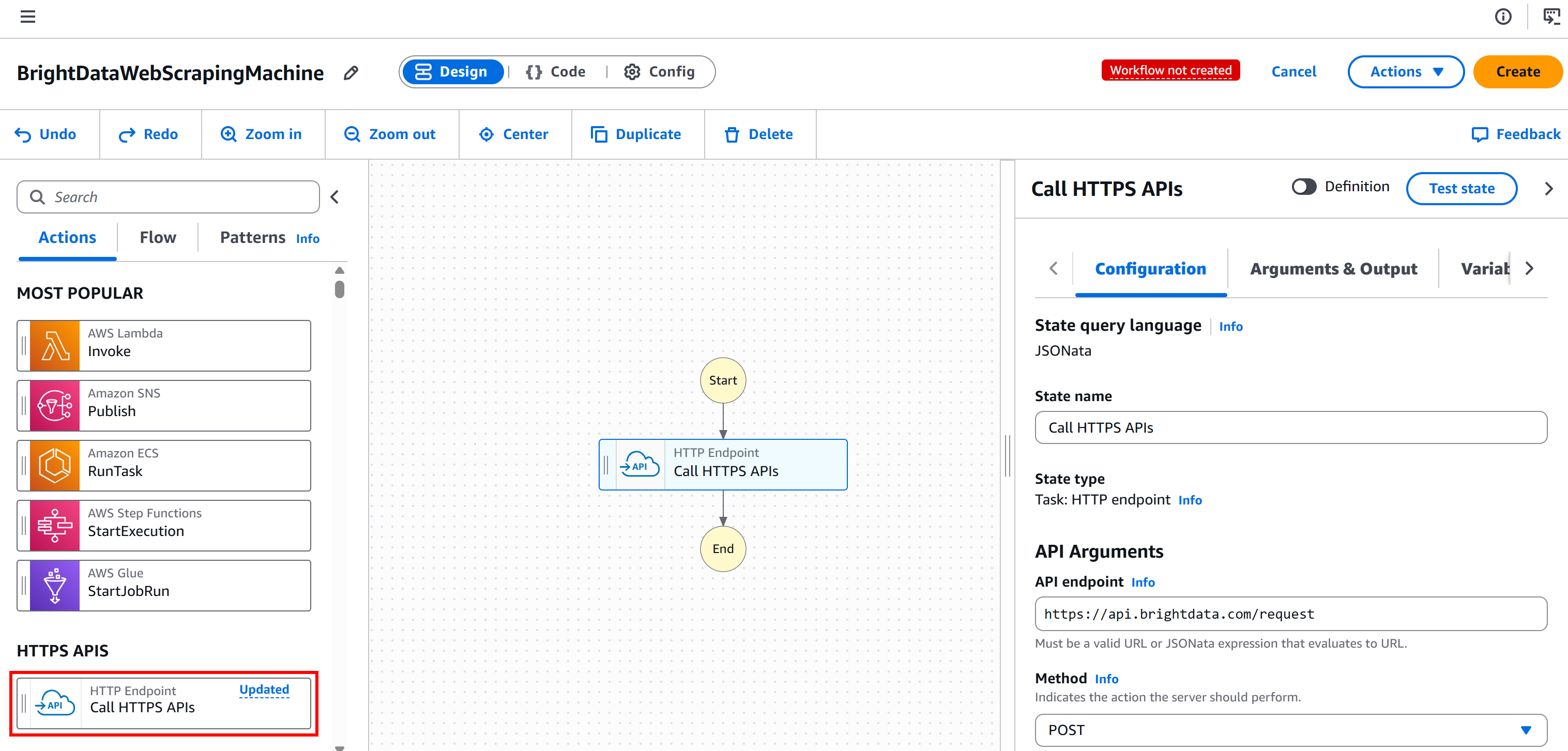
选中该节点,并在右侧 “Configuration” 选项卡中:
- 为你的状态命名。
- 将 “API endpoint” 设置为
https://api.brightdata.com/request。 - 将 “Method” 设置为
POST。
这样会将节点配置为连接到 POST https://api.brightdata.com/request 端点, 该端点是 Web Unlocker 与 SERP API 服务的 Bright Data 基础 API: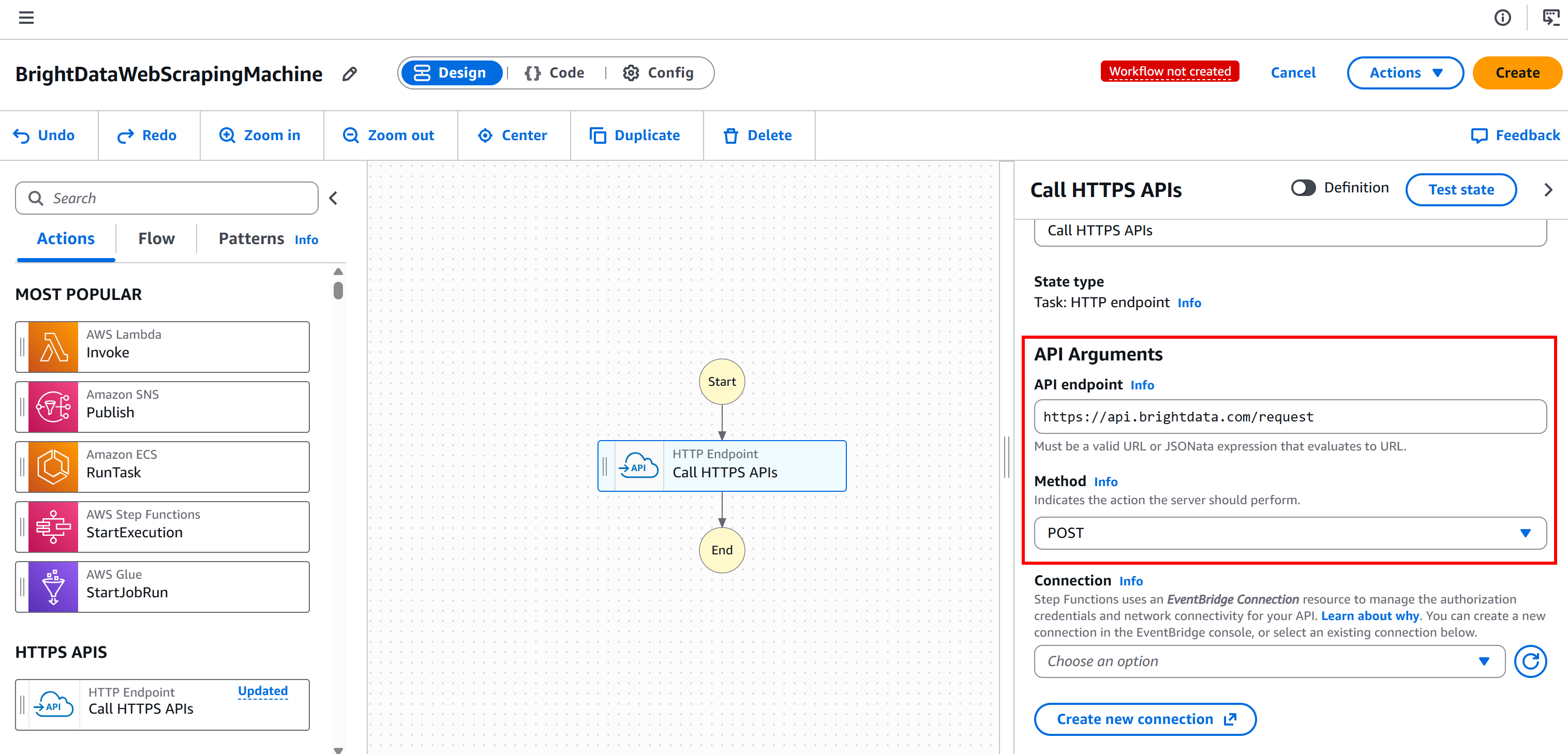
步骤 #2:配置 API 身份验证
Bright Data API 使用你的 Bright Data API key 进行认证。 具体来说,你必须以如下格式将其包含在 Authorization 请求头中:
Bearer <BRIGHT_DATA_API_KEY>为了避免在节点中硬编码 API key,你需要 通过 Amazon EventBridge 创建一个新的连接。 具体操作:在 “Configuration” 选项卡下的 “Connection” 区域中点击 “Create new connection” 按钮:
为你的连接命名(例如 brightdata-api),并将其设置为 “Public”(因为 Bright Data API key 是公开暴露的)。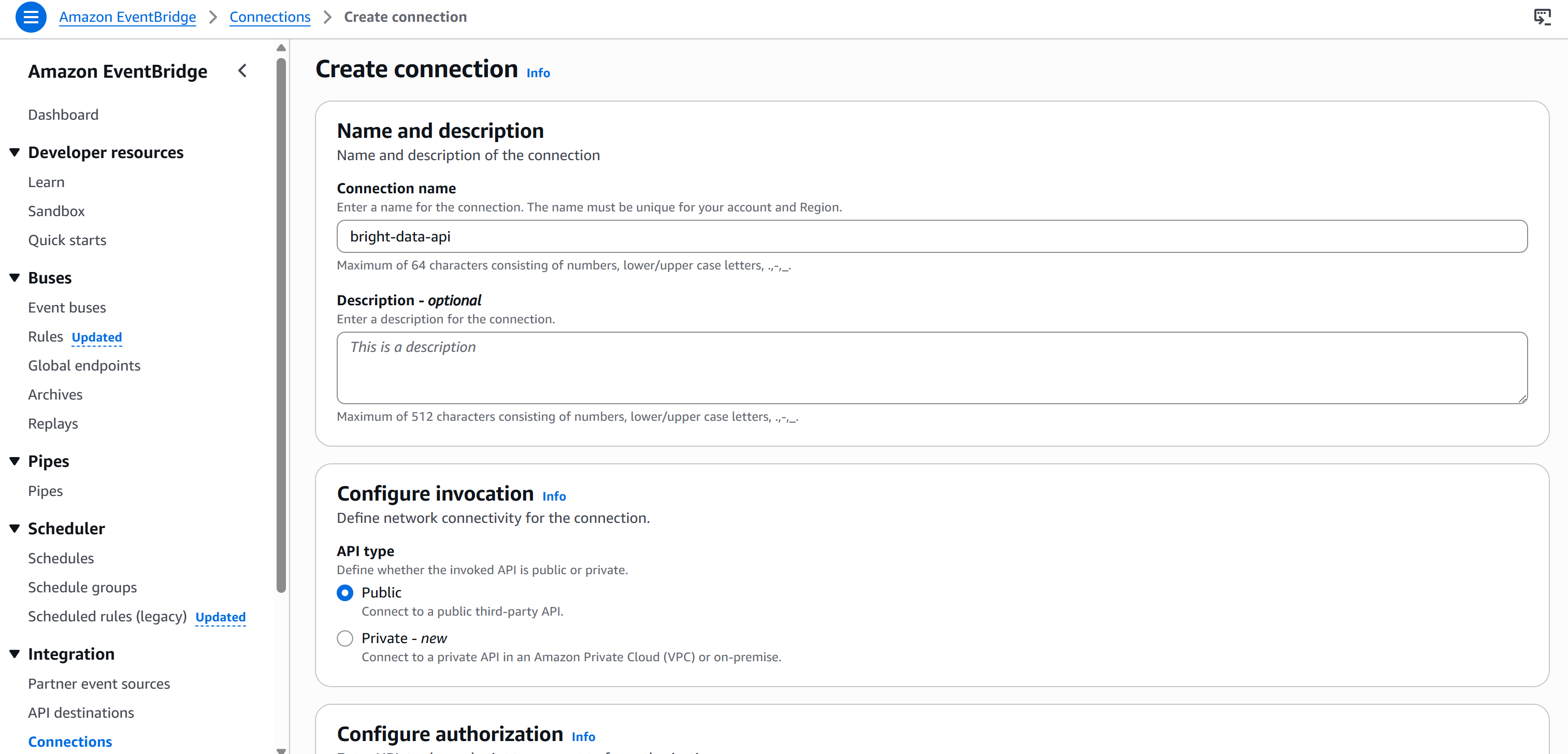
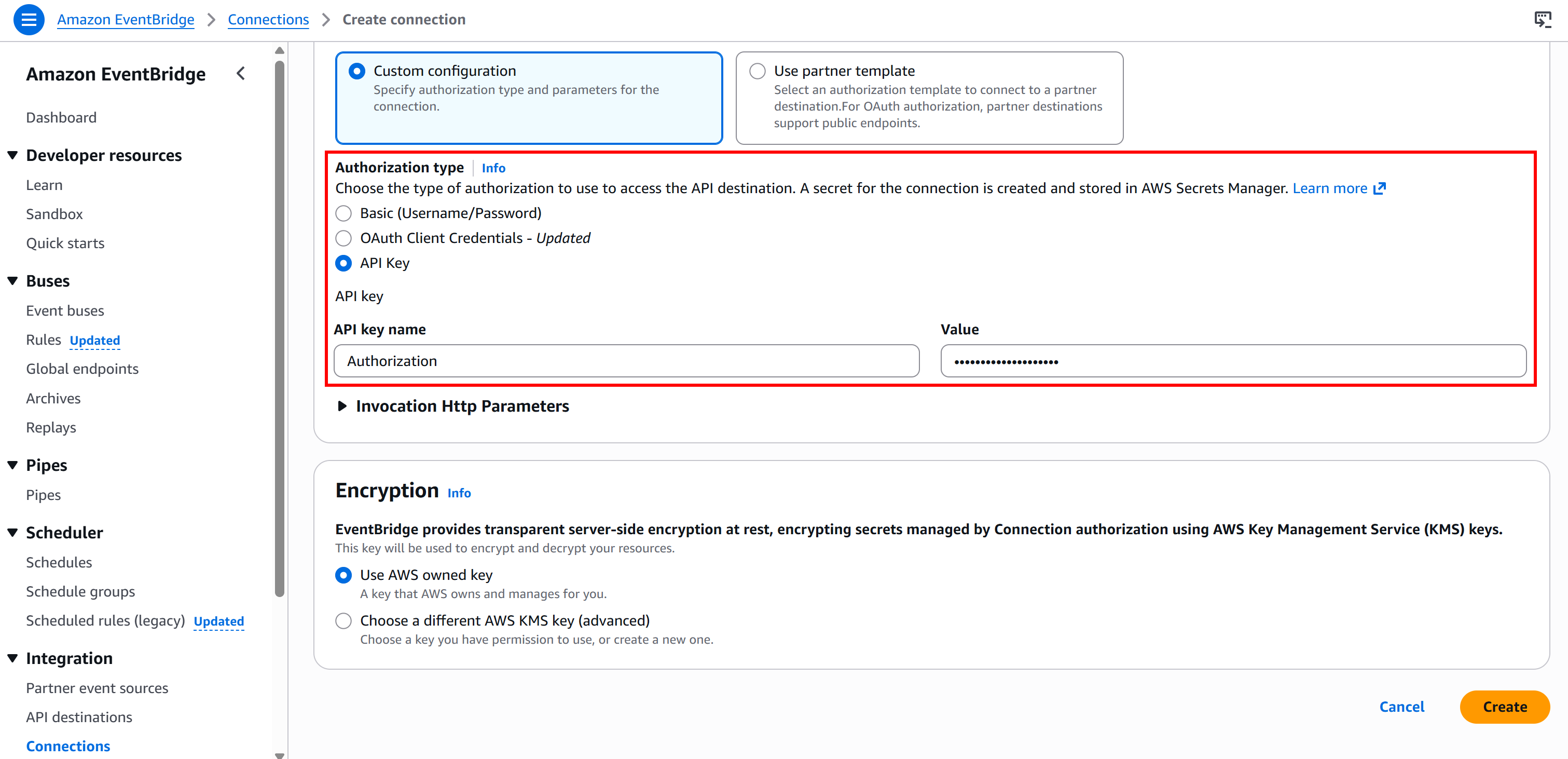
然后选择 “API Key” 认证类型,并按如下方式配置:
- API key 名称:
Authorization(必须与用于认证的 HTTP 请求头名称一致)。 - Value:
Bearer <BRIGHT_DATA_API_KEY>(将<BRIGHT_DATA_API_KEY>替换为你的真实 API key)。
最后,点击 “Create” 以创建 EventBridge 连接。创建完成后,你应该会看到: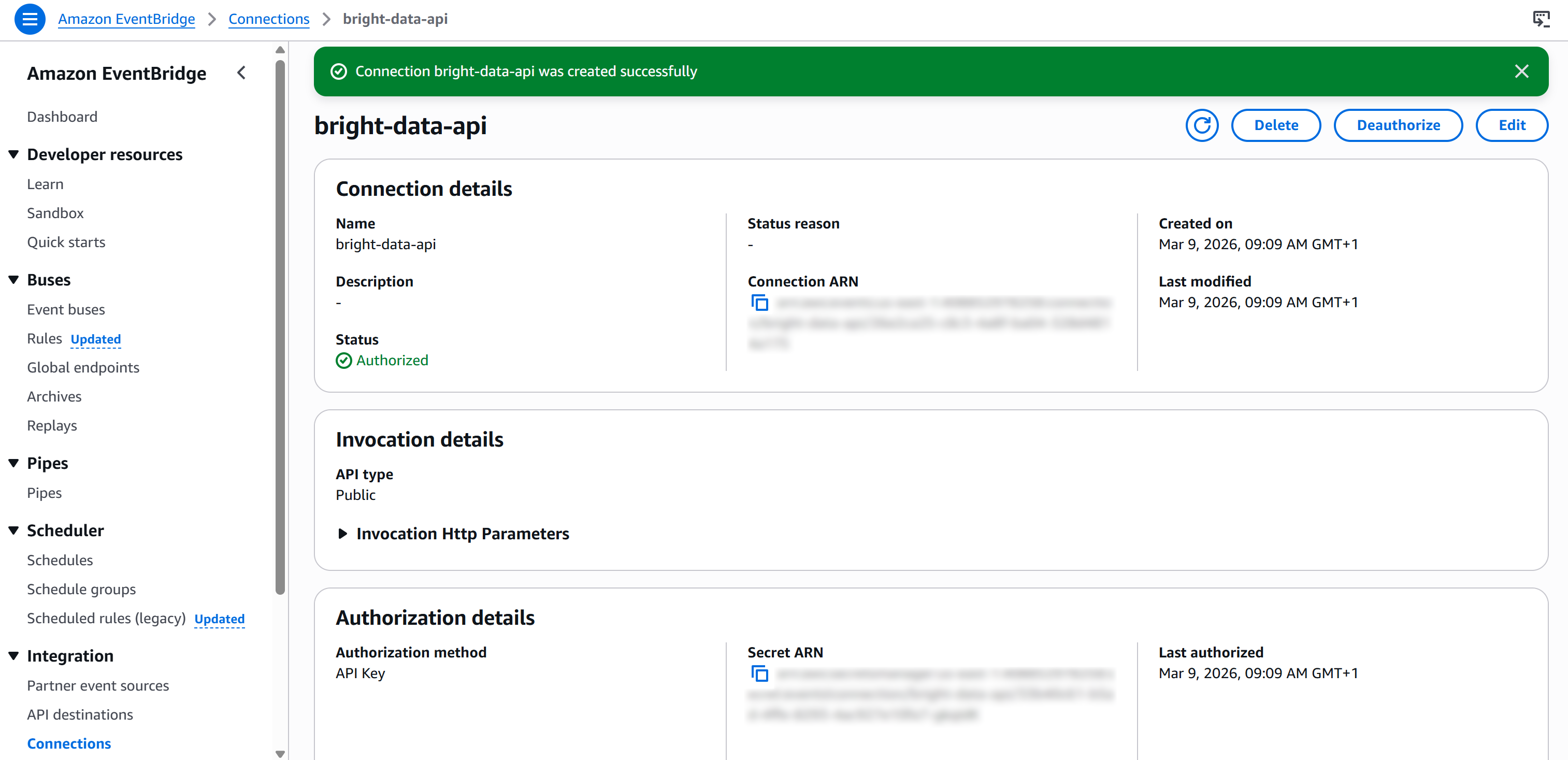
步骤 #3:完成 API 配置
回到工作流编辑器页面,选中 “HTTP Endpoint – Call HTTPS APIs” 节点并进入 “Configuration” 选项卡。 然后选择你刚创建的连接(bright-data-api):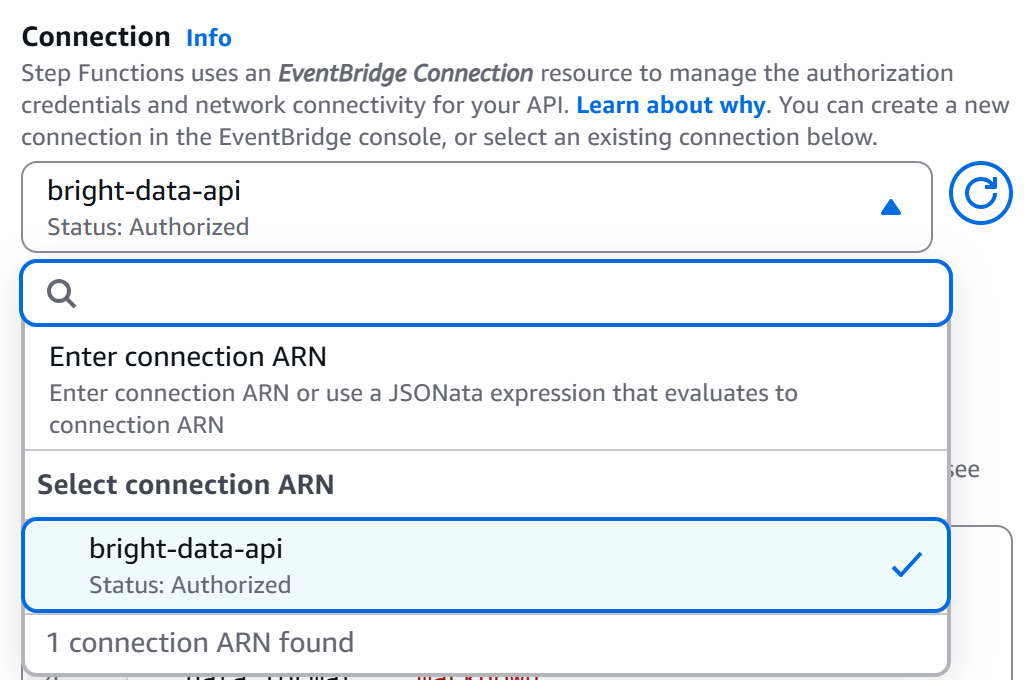
这样 Bright Data API key 就会以所需格式加入到 Authorization 请求头中用于认证。
接下来,将 HTTP body 定义为:
{
"zone": "<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE_NAME>",
"url": "{% $states.input.url %}",
"format": "raw",
"data_format": "markdown"
}将 <YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE_NAME> 替换为你在 Bright Data 账号中创建的 Web Unlocker zone 名称。 url 字段会动态读取工作流输入(通过 {% $states.input.url %} 语法),从而让你无需硬编码 URL 就能抓取不同页面。 同时, data_format: "markdown" 可确保 API 返回 AI 友好的 Markdown 格式响应。
在我们的示例中,Web Unlocker zone 名称为 "``web_unlocker``",因此 body 变为: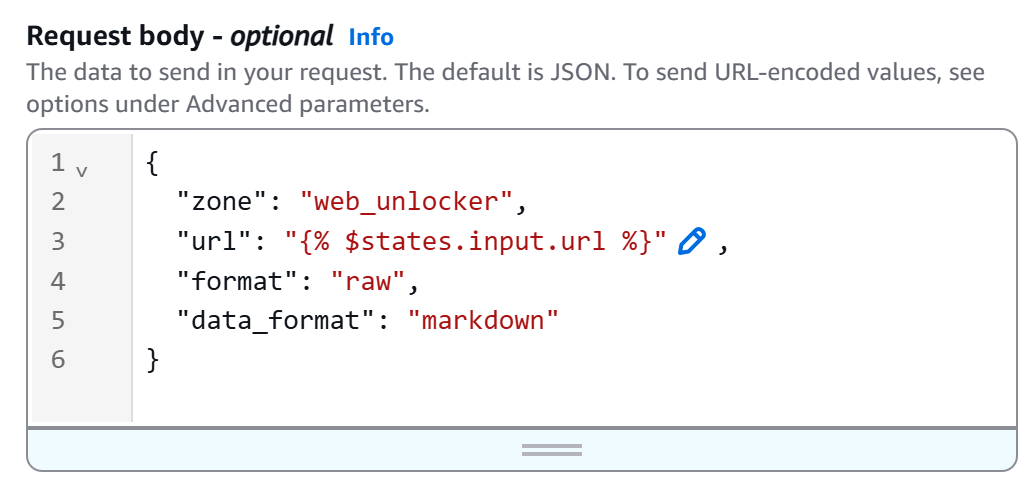
现在你的工作流会是这样: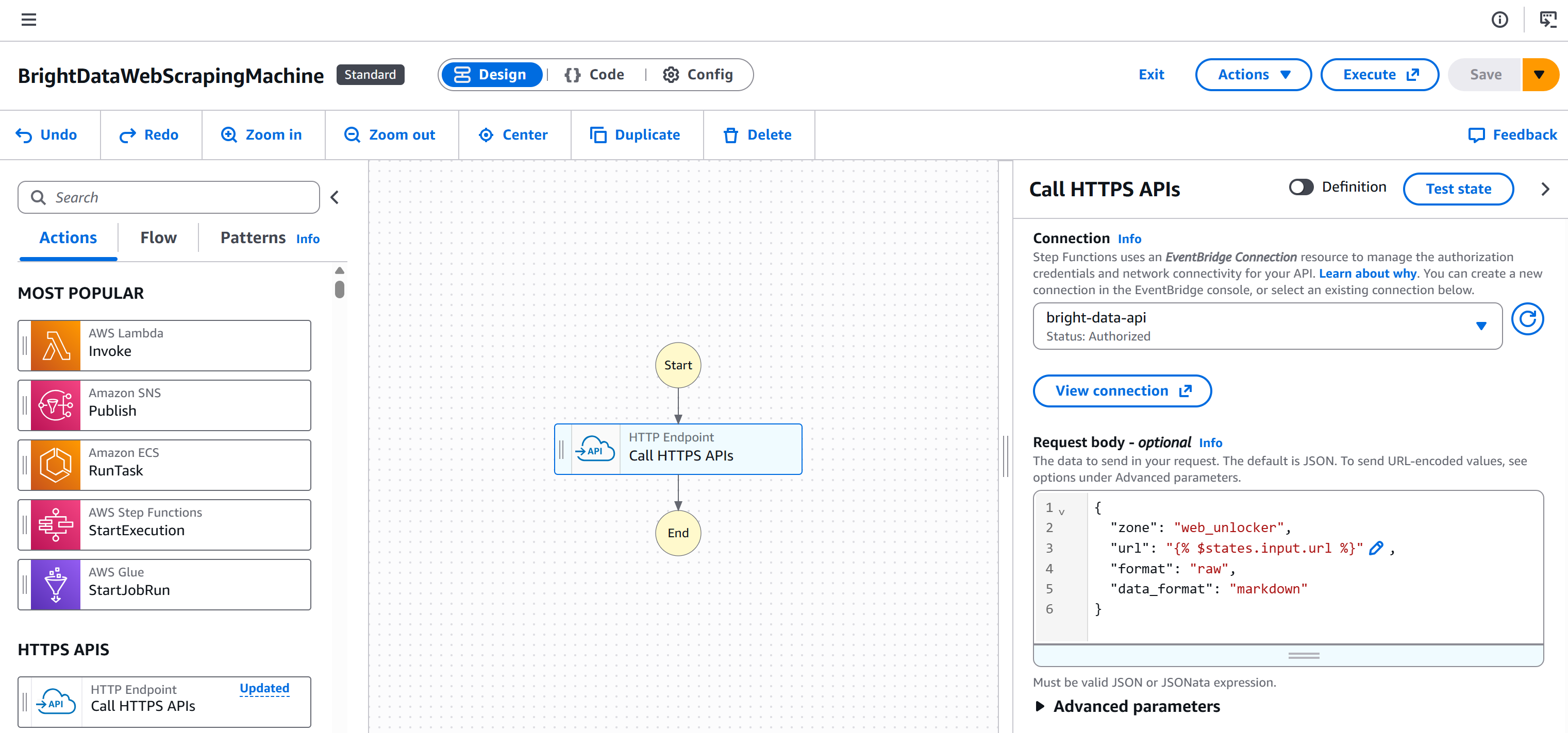
太棒了!配置已完成。接下来只需测试 Bright Data 在 AWS Step Functions 工作流中的集成效果。
步骤 #4:测试由 Bright Data 驱动的网页抓取节点
首先点击 “Create” 按钮,以 生成所需的 IAM role 以及你在 AWS Console 中用于测试的其他必要元素:
然后,在该节点上点击 “Test state” 按钮: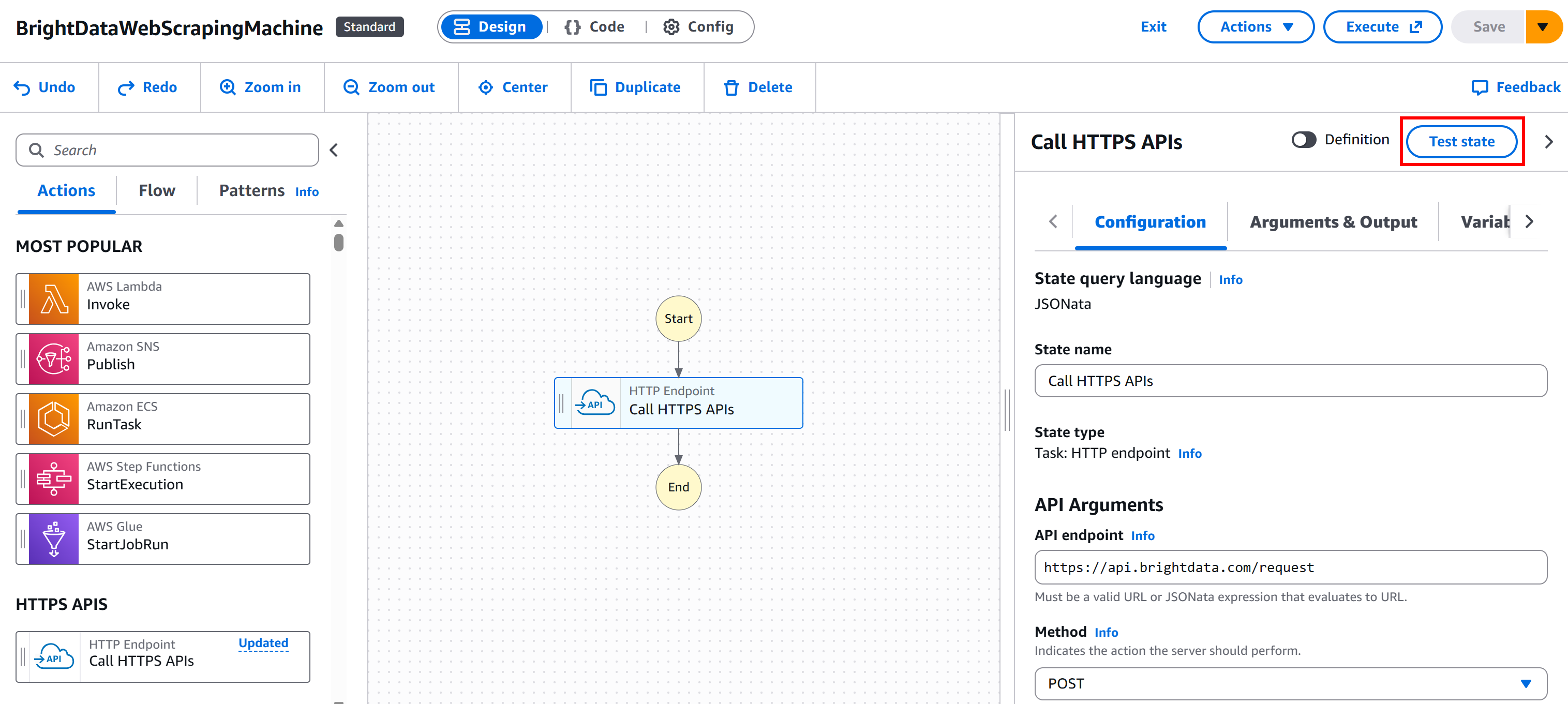
你将进入 “Test state” 弹窗: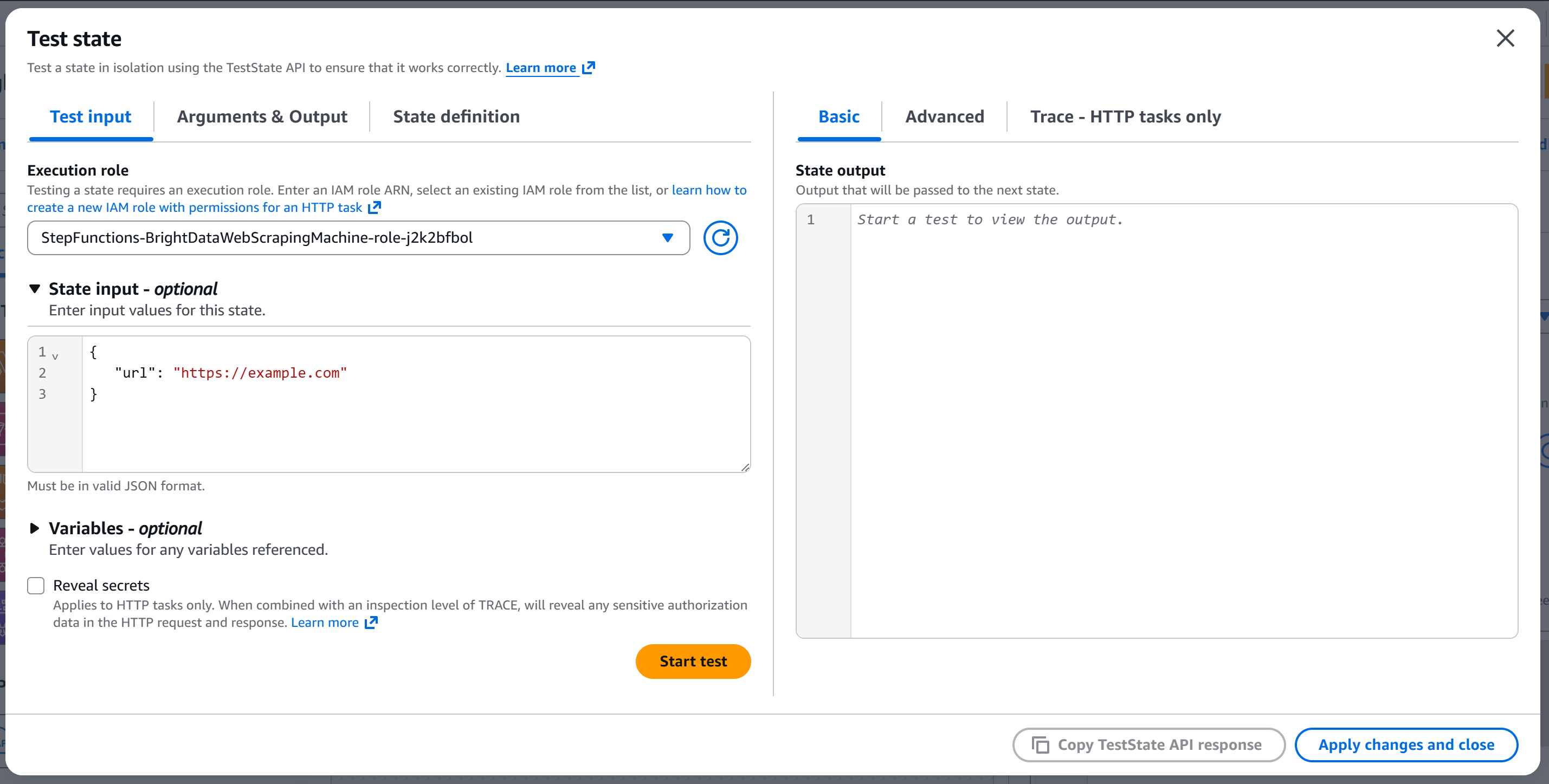
按如下方式配置 state input:
{
"url": "https://example.com"
}url 字段会被传递到 API body 中(因为该节点被配置为从输入中读取 url 字段来填充请求体)。
点击 “Start test” 运行节点。你应该会看到类似这样的输出: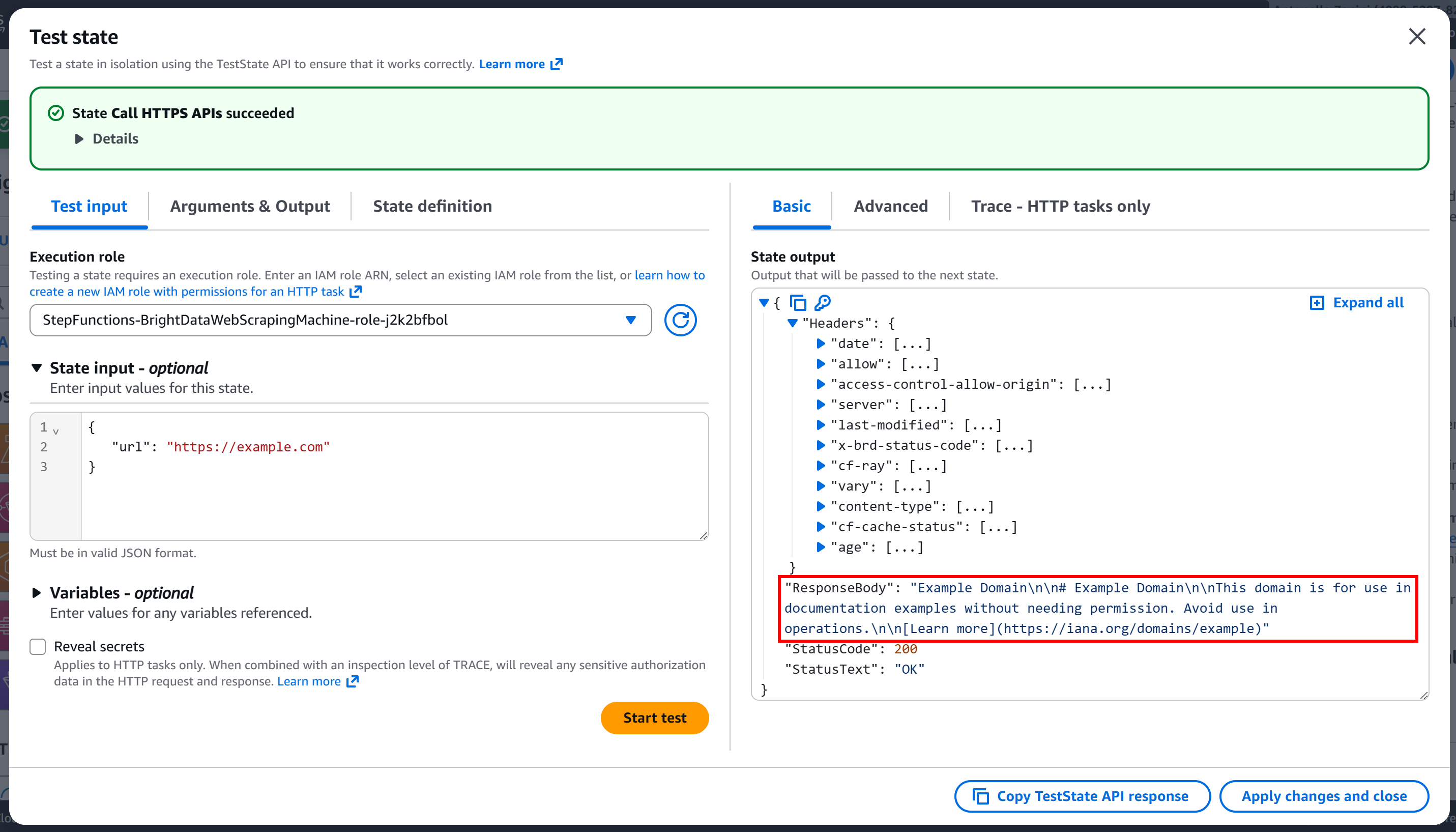
如你所见,请求已成功执行,响应体包含目标页面的 Markdown 版本:
搞定!你在 AWS Step Functions 中的 Bright Data 集成已完全可用,并可用于生产环境。
方法 #2:使用 Lambda 函数
在本节中,你将了解如何通过自定义 AWS Lambda 函数连接 Bright Data 服务。
为了简化集成并加快流程,你可以参考文章 “Give AWS Bedrock Agents the Ability to Search the Web via Bright Data SERP API” 中的步骤 #5、#6 和 #7。那些步骤会指导你创建一个用 Python 编写的 Lambda 函数,用于连接 Bright Data SERP API。
下面你将看到如何通过 AWS Step Functions 将该 Lambda 函数集成进你的网页抓取工作流!
步骤 #1:添加 “AWS Lambda – Invoke” 节点
先在左侧面板选择 “AWS Lambda – Invoke” 节点,然后将其拖到工作流的 “Drag first state here” 区域。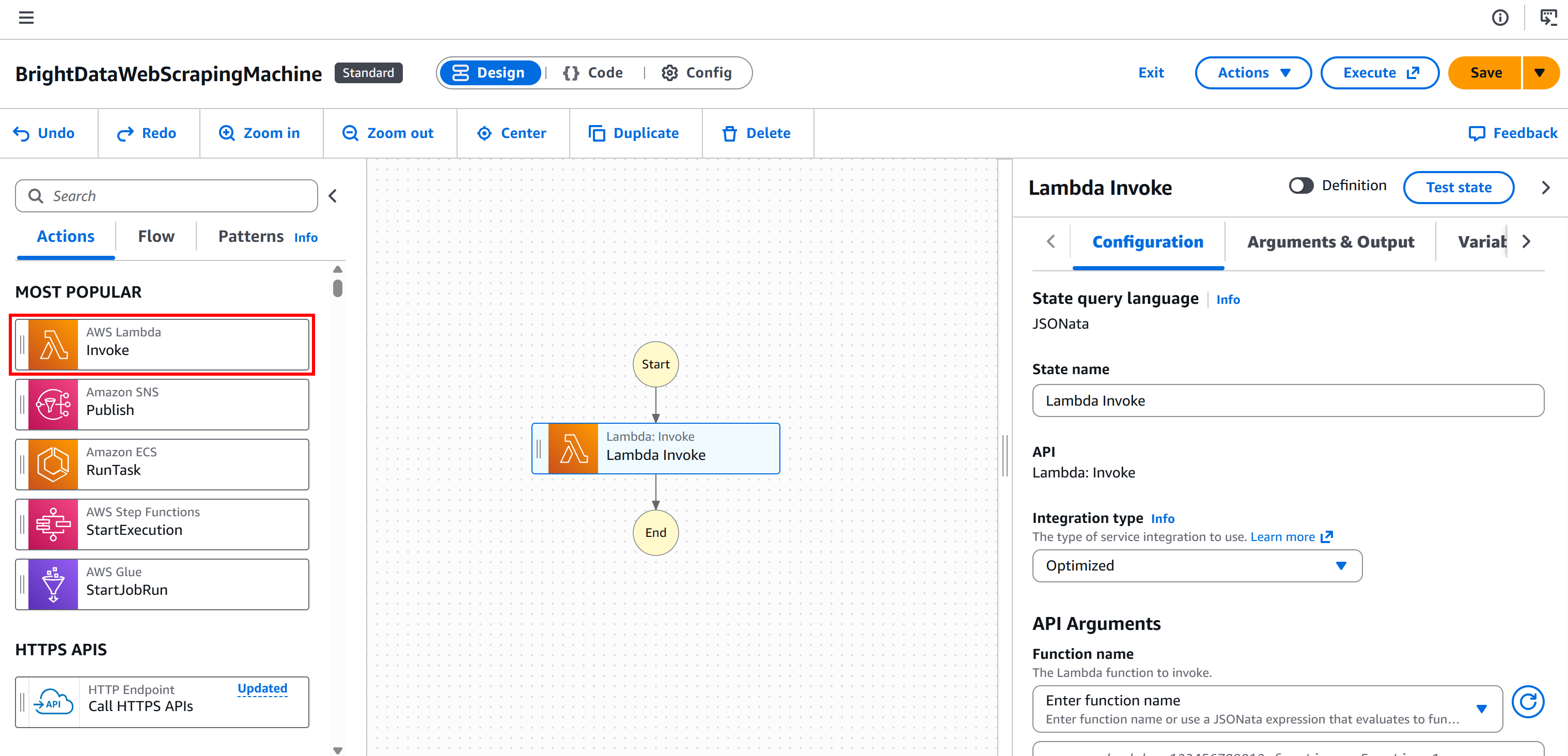
步骤 #2:配置 Lambda 函数
在 “AWS Lambda – Invoke” 节点的 “Configuration” 区域中,在 “API Arguments – Function Name” 模块下, 选择你要调用的 Lambda 函数: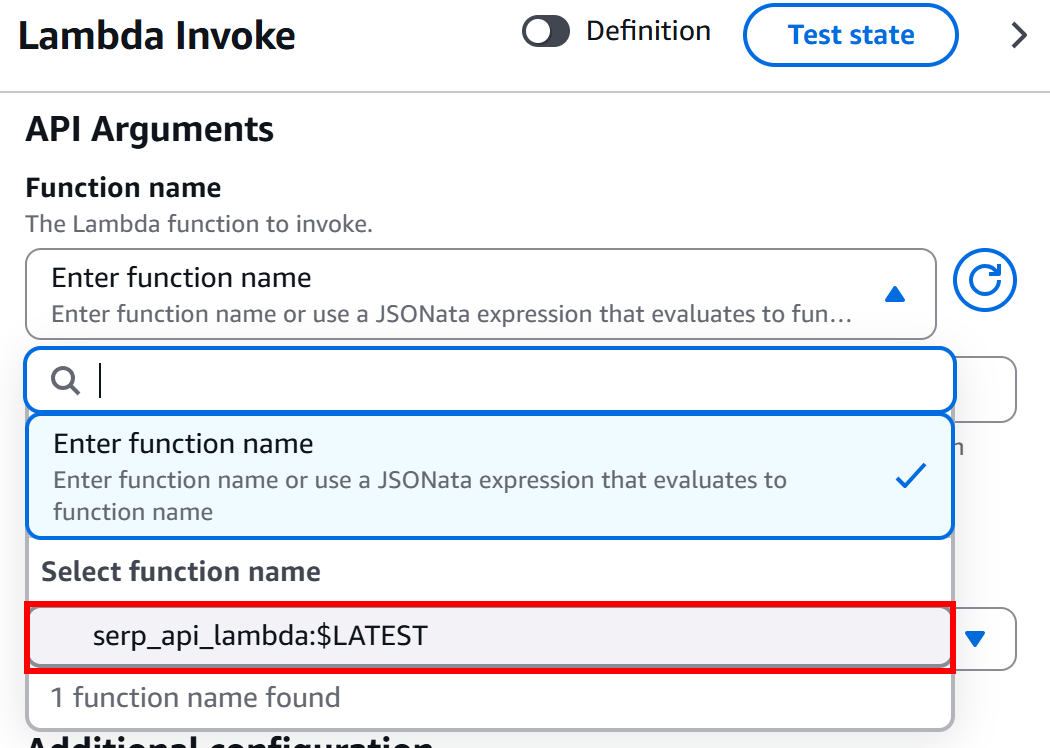
在该示例中,函数为 serp_api_lambda,其创建方式如本章开头的介绍所述。该函数集成了 Bright Data 的 SERP API。
太好了!你已经将一个由 Bright Data 驱动、用于 SERP 抓取的 Lambda 函数集成进 AWS Step Functions 工作流中。
结论
在本指南中,你了解了 AWS Step Functions 是什么,以及它为何非常适合用于编排自动化网页抓取工作流。
你看到 Step Functions 如何通过状态机、并行执行、重试与人工介入支持来简化工作流管理。 你也了解了 Bright Data 如何通过 Web Unlocker 与 SERP API 集成增强这一过程,绕过反机器人措施,确保不间断、企业级的网页数据获取。
通过将 Bright Data 集成到 Step Functions 中,你可以构建端到端流水线,在保持可扩展性、韧性与可观测性的同时, 完成数据采集、校验与存储到 S3 或其他 AWS 服务。
立即注册 Bright Data 账号,免费测试我们的网页数据解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。



