
在本文中,你将学习:
- Apache Airflow 与 Apache Spark 是什么,以及它们分别能提供什么能力。
- 为什么将 Bright Data 的 Web Unlocker API 与 Airflow、Spark 进行编排,是一套强大的线索生成策略。
- 如何构建一个端到端流水线,以规模化方式采集、处理并存储结构化企业数据。
在进入具体工具与实现之前,我们先建立一些基础概念,并看看它们如何在一个线索生成工作流中彼此衔接。
什么是 Apache Airflow?
Apache Airflow 是一个开源的工作流编排平台,用于以编程方式编写、调度与监控数据流水线。它最初由 Airbnb 开发,支持数据工程师用纯 Python 将工作流定义为有向无环图(DAG),从而对任务依赖、重试、调度与告警实现完全控制。
它的主要目标是帮助你可靠运行复杂的多步骤数据流水线。实现方式包括:丰富的 Operator 生态(Bash、Python、HTTP、Spark、SQL 等),用于监控运行情况的可视化 Web UI,内置的重试与告警逻辑,以及与 AWS、GCP、Azure 等云平台的原生集成。
在理解了工作流编排之后,我们再来看看流水线中“数据处理”这一侧。
Apache Spark 是一个面向大规模数据处理的统一分析引擎。它提供分布式计算框架,可在一组机器集群上以内存方式处理海量数据,因此相比传统基于磁盘的处理系统快得多。
Spark 通过统一 API 支持批处理、流处理、SQL 查询、机器学习与图计算,并可在 Python(PySpark)、Scala、Java 与 R 中使用。对于清洗、去重、补全(enrich)以及转换大规模抓取到的企业数据这类数据密集型任务,Spark 是行业标准工具。
Apache Airflow vs Apache Spark:有什么区别?
如果你刚接触这套技术栈,很容易把两者混为一谈,因为它们经常一起出现。但它们的职责完全不同:
- Apache Airflow 是编排器(orchestrator)。它决定何时运行任务、按什么顺序运行、如何处理失败,以及如何监控整体流水线。它本身不负责数据处理。
- Apache Spark 是数据处理器(data processor)。它将原始或半结构化数据在分布式计算环境下进行规模化转换。
两者是很好的互补组合:Airflow 在正确的时间点、以正确的顺序调度并触发 Spark 作业;Spark 负责完成重型的数据转换工作。在本教程中,你将看到 Airflow 如何端到端编排整条流水线:触发 Bright Data 采集企业列表,把原始结果交给 Spark 做清洗与补全,并将最终线索写入数据库。
为什么要把 Bright Data 集成进 Airflow + Spark 流水线?
Airflow 提供 SimpleHttpOperator 与 PythonOperator ,使你可以把任何 REST API 调用作为流水线任务来执行。这意味着你可以把网页数据采集作为 DAG 中的一等步骤,与后续的转换与加载任务并列编排。
但是,要在规模化条件下把可靠、结构化的企业数据注入流水线,你需要一个数据源:它能处理反爬虫、支持地理定位,并能输出结构化结果,而无需你维护自定义抓取工具。这里就轮到 Bright Data 的 Web Unlocker API 出场了。
Web Unlocker API 让你可以访问任何公开网页,无论该页面是否有机器人防护、是否需要 JavaScript 渲染,或是否存在地域限制。你只需发送一个包含目标 URL 的 POST 请求,Bright Data 就会返回页面内容。无需浏览器自动化代码、无需代理管理、无需处理 CAPTCHA。
这种方式尤其适用于:
- 定期从企业黄页/目录网站采集最新商家列表,并写入 CRM 或外呼工具的线索生成流水线。
- 跨地区或跨行业聚合企业数据,用于竞品分析的市场研究工作流。
- 在线索数据库中追加联系方式、公司规模或行业分类等字段的数据补全系统。
- 监控企业列表变化、当目标公司更新资料时触发告警的销售情报平台。
将 Airflow 的调度与编排能力、Spark 的分布式数据处理能力,与 Bright Data 的网页数据基础设施 结合起来,你就能构建一个“自动驾驶”的生产级线索生成引擎。
如何使用 Airflow、Spark 与 Bright Data 构建线索生成流水线
在本节的实操指导中,你将构建一个端到端流水线,包含三个主要阶段:
- 获取企业列表 :Airflow 任务调用 Bright Data 的 Web Unlocker API,在三个城市范围内采集 Yellow Pages 的搜索结果。
- 校验已采集数据 :第二个任务读取已保存的结果,并确认数据已成功采集。
- 使用 Spark 处理 :PySpark 作业对原始记录进行清洗、去重与评分。
注意:这只是众多可选架构之一。你也可以将 Spark 输出写入 BigQuery、Snowflake 这类数仓;或通过 CRM 的 API 直接推送;或在自动线索评分前增加一个基于 LLM 的补全步骤。
按下列步骤操作,在 Apache Airflow 与 Spark 中构建一个由 Bright Data Web Unlocker API 驱动的自动化线索生成流水线!
前置条件
要跟随本教程,你需要:
- 一个 Bright Data 账号,并且有可用的 Web Unlocker zone。登录 Bright Data 控制台,进入 Account Settings ,复制你的 API Token (UUID 格式),并记下你的 zone 名称。
- Docker Desktop (macOS 或 Windows)或原生 Python 环境(Ubuntu/Linux)。两种方式都将在步骤 1 中说明。
步骤 1:项目初始化
安装 Docker Desktop,并在继续前确保它正在运行。在 Docker Desktop 设置中进入 Resources ,至少分配 5GB 内存,因为 Airflow 的多容器栈需要这个配置。
步骤 2:创建项目结构
创建工作目录以及 Airflow 所需的文件夹:
mkdir airflow-lead-pipeline && cd airflow-lead-pipeline
mkdir dags spark_jobs logs plugins config你的项目结构会如下所示:
airflow-lead-pipeline/
├── dags/
│ └── lead_generation_dag.py
├── spark_jobs/
│ └── process_leads.py
├── logs/
├── plugins/
├── config/
├── Dockerfile
└── docker-compose.yaml步骤 3:配置 Docker Compose
下载官方 Airflow Docker Compose 文件:
curl -LfO 'https://airflow.apache.org/docs/apache-airflow/2.7.3/docker-compose.yaml'在同一目录创建 Dockerfile 。该文件用于扩展 Airflow 基础镜像并安装 requests 依赖:
FROM apache/airflow:2.7.3
RUN pip install requests pyspark打开 docker-compose.yaml 。在文件顶部附近找到 x-airflow-common 区块,并在 image: 行下面直接加入 build: . :
x-airflow-common:
&airflow-common
image: ${AIRFLOW_IMAGE_NAME:-apache/airflow:2.7.3}
build: .同时确保 _PIP_ADDITIONAL_REQUIREMENTS 这一行为空。依赖应在 Dockerfile 中安装,而不是通过该环境变量:
_PIP_ADDITIONAL_REQUIREMENTS: ""最后,在同一块的 volumes: 列表中新增一个对 spark_jobs/ 的挂载。默认文件只挂载 dags/ 、 logs/ 、 plugins/ 、 config/ ,因此如果不加这一行,worker 容器将找不到你的 Spark 作业文件:
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/spark_jobs:/opt/airflow/spark_jobs文件其余部分保持与下载版本一致。它默认提供:使用 Redis 作为消息 broker 的 CeleryExecutor、作为元数据数据库的 PostgreSQL、将项目目录中的 dags/ 、 logs/ 、 config/ 、 plugins/ 挂载为 volumes,默认账号用户名 airflow 、密码 airflow ,以及一个只在首次启动运行一次的 airflow-init 服务,用于迁移数据库并创建管理员用户。
构建自定义镜像并启动全部服务:
docker compose build
docker compose up -d等待约 60 秒后,检查 6 个容器是否都处于 healthy 状态:
docker compose ps期望输出:

在浏览器打开 http://localhost:8080 ,用用户名 airflow 与密码 airflow 登录。
步骤 4:编写 Airflow DAG
创建文件 dags/lead_generation_dag.py :
import json
import requests
from datetime import datetime, timedelta
from pathlib import Path
from airflow import DAG
from airflow.operators.python import PythonOperator
API_KEY = "your-brightdata-api-token-here"
ZONE = "web_unlocker1"
BASE_URL = "https://api.brightdata.com/request"
RAW_DATA_PATH = "/tmp/brightdata_raw/leads.json"
HEADERS = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
}
TARGETS = [
"https://www.yellowpages.com/search?search_terms=software+company&geo_location_terms=San+Francisco+CA",
"https://www.yellowpages.com/search?search_terms=marketing+agency&geo_location_terms=New+York+NY",
"https://www.yellowpages.com/search?search_terms=fintech+startup&geo_location_terms=Austin+TX",
]
default_args = {
"owner": "data-team",
"retries": 2,
"retry_delay": timedelta(minutes=5),
}
def fetch_business_listings(**context):
results = []
for url in TARGETS:
print(f"Fetching: {url}")
response = requests.post(
BASE_URL,
headers=HEADERS,
json={
"zone": ZONE,
"url": url,
"format": "raw",
"data_format": "markdown",
},
timeout=60,
)
response.raise_for_status()
results.append({
"url": url,
"content": response.text,
"status": response.status_code,
})
print(f"Fetched {len(response.text)} chars from {url}")
Path(RAW_DATA_PATH).parent.mkdir(parents=True, exist_ok=True)
with open(RAW_DATA_PATH, "w") as f:
json.dump(results, f, indent=2)
print(f"Saved {len(results)} pages to {RAW_DATA_PATH}")
context["ti"].xcom_push(key="record_count", value=len(results))
def validate_output(**context):
count = context["ti"].xcom_pull(key="record_count", task_ids="fetch_listings")
with open(RAW_DATA_PATH) as f:
data = json.load(f)
print(f"Validation passed: {count} pages collected")
for item in data:
print(f" URL: {item['url']} | Status: {item['status']} | Size: {len(item['content'])} chars")
with DAG(
dag_id="brightdata_lead_generation",
default_args=default_args,
description="Collect business leads using Bright Data Web Unlocker",
schedule_interval="0 6 * * 1",
start_date=datetime(2026, 3, 12),
catchup=False,
tags=["lead-generation", "brightdata"],
) as dag:
fetch_listings = PythonOperator(
task_id="fetch_listings",
python_callable=fetch_business_listings,
)
validate_data = PythonOperator(
task_id="validate_data",
python_callable=validate_output,
)
fetch_listings >> validate_data将 your-brightdata-api-token-here 替换为你的实际 API token,并将 ZONE 更新为你的 Web Unlocker zone 名称。
我们拆解一下各部分的作用:
API_KEY与ZONE:你的 Bright Data 凭证。API token 是你在账号设置中拿到的 UUID 格式 token,不是 zone 密码。TARGETS:三个 Yellow Pages 搜索 URL,分别覆盖:旧金山的软件公司、纽约的营销机构、奥斯汀的 fintech 初创公司。fetch_business_listings:遍历每个目标 URL,并向 Web Unlocker API 发送 POST 请求。Bright Data 会处理反爬虫措施、代理轮换与 JavaScript 渲染,并将页面内容以 Markdown 返回。结果会写入磁盘,同时把记录数写入 Airflow 的 XCom,供下一个任务读取。validate_output:读取保存的文件并记录每个 URL、HTTP 状态码与内容大小。它相当于下游处理前的轻量级数据质量检查。fetch_listings >> validate_data:>>运算符定义任务依赖关系:只有抓取成功后,验证任务才会运行。
重要提示: 当你首次部署一个带周期调度的 DAG 时,应始终把
start_date设为今天,并设置catchup=False。如果你把start_date设为过去日期且catchup=True,Airflow 会为从该日期起错过的每个时间间隔都排队一个回填(backfill)任务。例如一个从 10 周前开始的每周任务,当你解除暂停 DAG 时会立刻产生 10 次并发运行,争抢 worker 资源。
步骤 5:编写 PySpark 转换作业
创建文件 spark_jobs/process_leads.py :
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, trim, regexp_replace, when, lit
import sys
def main(input_path: str, output_path: str):
spark = SparkSession.builder \
.appName("BrightData Lead Processing") \
.config("spark.sql.adaptive.enabled", "true") \
.getOrCreate()
raw_df = spark.read.option("multiLine", True).json(input_path)
cleaned_df = raw_df.select(
trim(col("name")).alias("company_name"),
trim(col("phone")).alias("phone"),
trim(col("website")).alias("website"),
trim(col("address")).alias("address"),
trim(col("city")).alias("city"),
trim(col("state")).alias("state"),
trim(col("category")).alias("industry"),
col("rating").cast("float").alias("rating"),
col("reviews_count").cast("integer").alias("reviews_count"),
) \
.filter(col("company_name").isNotNull()) \
.filter(col("phone").isNotNull()) \
.dropDuplicates(["company_name", "phone"])
enriched_df = cleaned_df.withColumn(
"lead_score",
when(
(col("rating") >= 4.0) & (col("reviews_count") >= 50), lit("hot")
).when(
(col("rating") >= 3.0) & (col("reviews_count") >= 10), lit("warm")
).otherwise(lit("cold"))
).withColumn(
"website_clean",
regexp_replace(col("website"), "^https?://", "")
)
enriched_df.write.mode("overwrite").parquet(output_path)
print(f"Processed {enriched_df.count()} leads. Output written to {output_path}")
spark.stop()
if __name__ == "__main__":
main(sys.argv[1], sys.argv[2])这个作业做了四件事:从磁盘加载 fetch_listings 写出的原始 JSON;通过规范化空白字符、转换数值字段类型,并删除缺少公司名或电话的记录来清洗数据;按公司名与电话去重,移除跨城市重复的列表;最后为每条记录添加 lead_score 标签:评分 ≥4.0 且评论数 ≥50 的标记为 hot ;评分 ≥3.0 且评论数 ≥10 的标记为 warm ;其余全部为 cold 。
步骤 6:触发并监控流水线
当你的 DAG 文件放入 dags/ 目录后,Airflow 会在 30 秒内自动加载。
Docker 用户 请解除暂停并触发 DAG:
docker compose exec --user airflow airflow-scheduler airflow dags unpause brightdata_lead_generation
docker compose exec --user airflow airflow-scheduler airflow dags trigger brightdata_lead_generation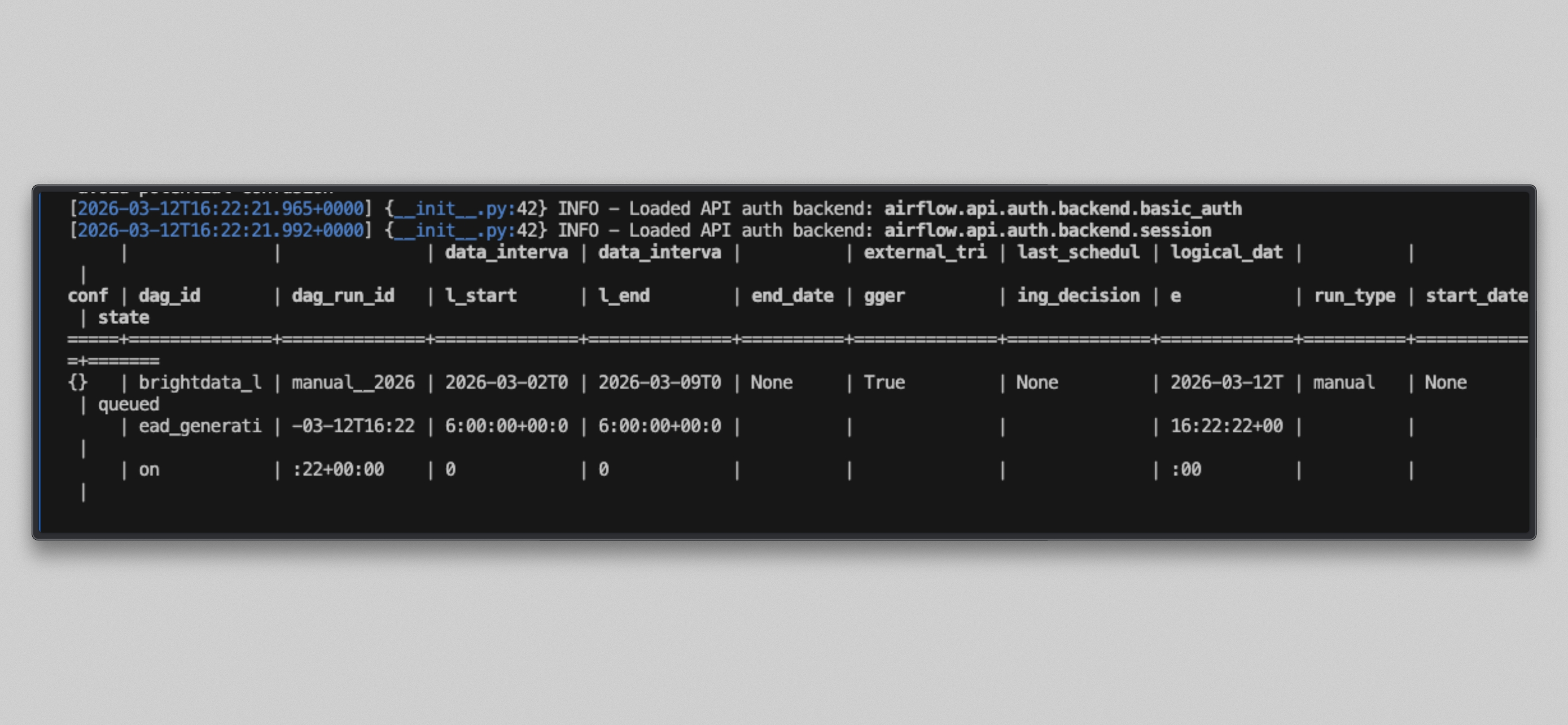
查看 worker 日志:
docker compose logs airflow-worker -f --tail=20任务运行后你会看到类似输出:
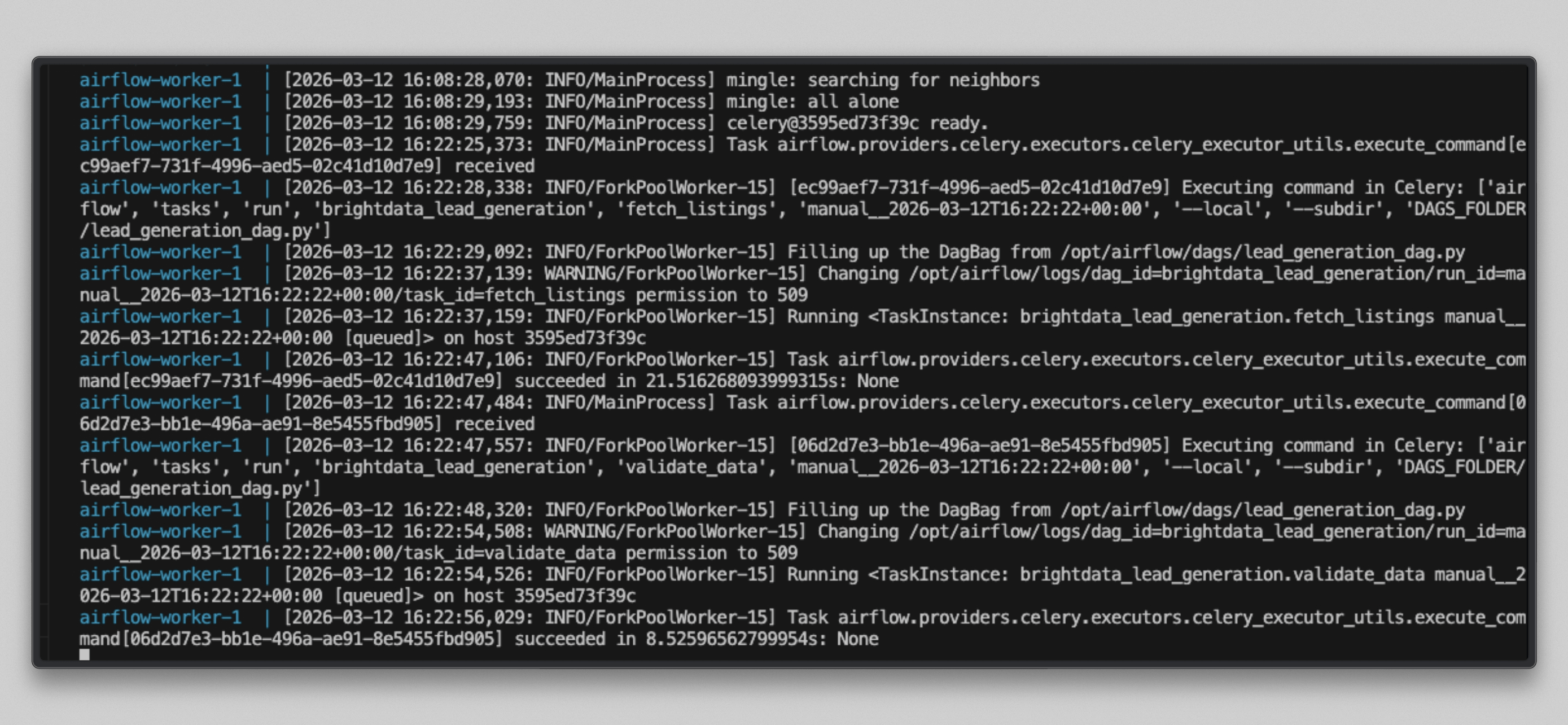
打开 http://localhost:8080 ,点击 brightdata_lead_generation DAG,并切换到 Grid 视图。每个任务方块在完成后会变绿。点击任意任务方块并选择 Log ,即可看到实时输出,包括每个被抓取的 URL 以及 Bright Data 返回的字符数。
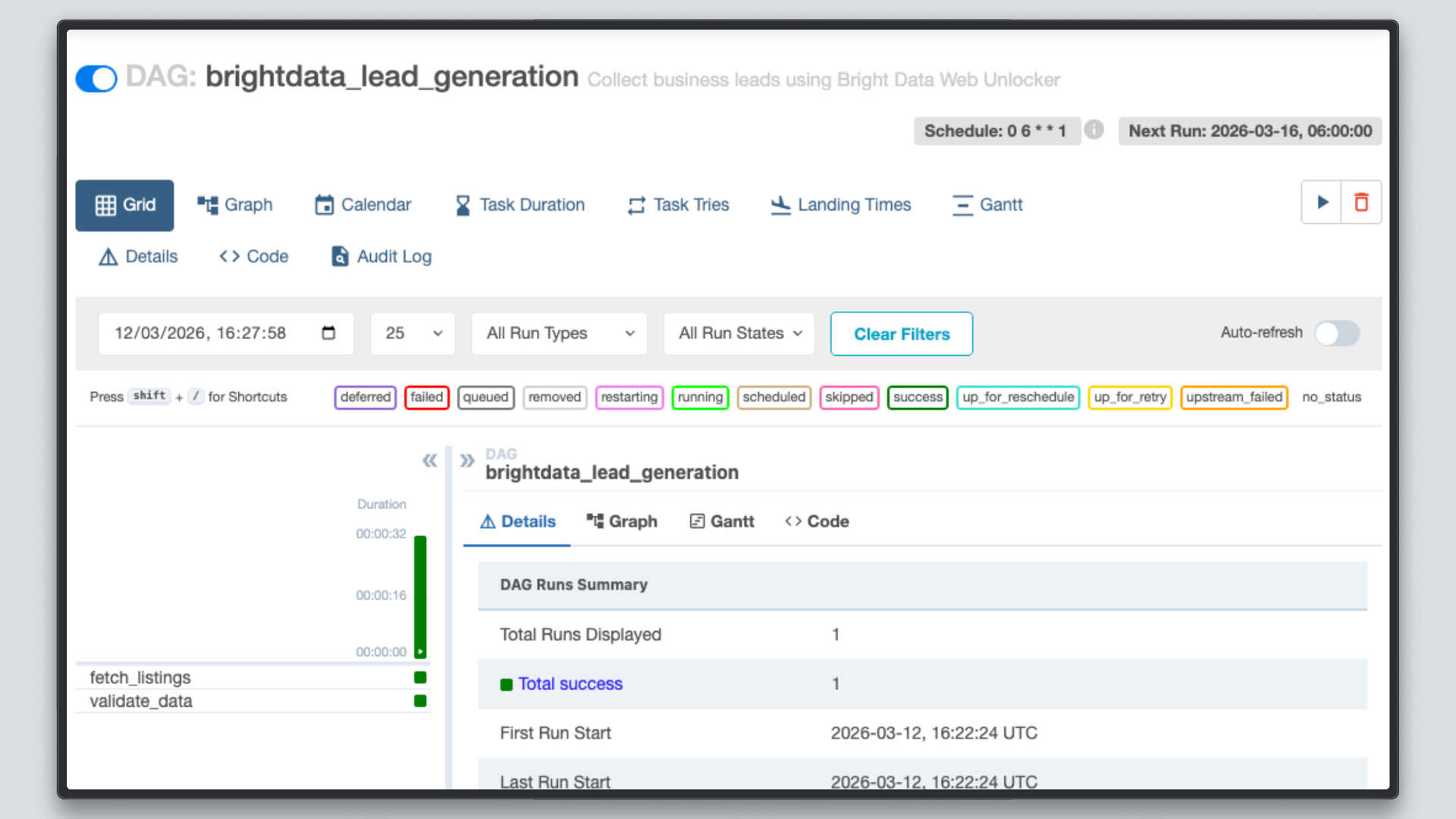
步骤 7:检查结果
当两个任务都变绿后,检查输出文件。
Docker 用户:
docker compose exec --user airflow airflow-worker cat /tmp/brightdata_raw/leads.jsonUbuntu 原生环境用户:
cat /tmp/brightdata_raw/leads.json你会看到一个包含 3 个条目的 JSON 数组,每个条目对应一个目标 URL:
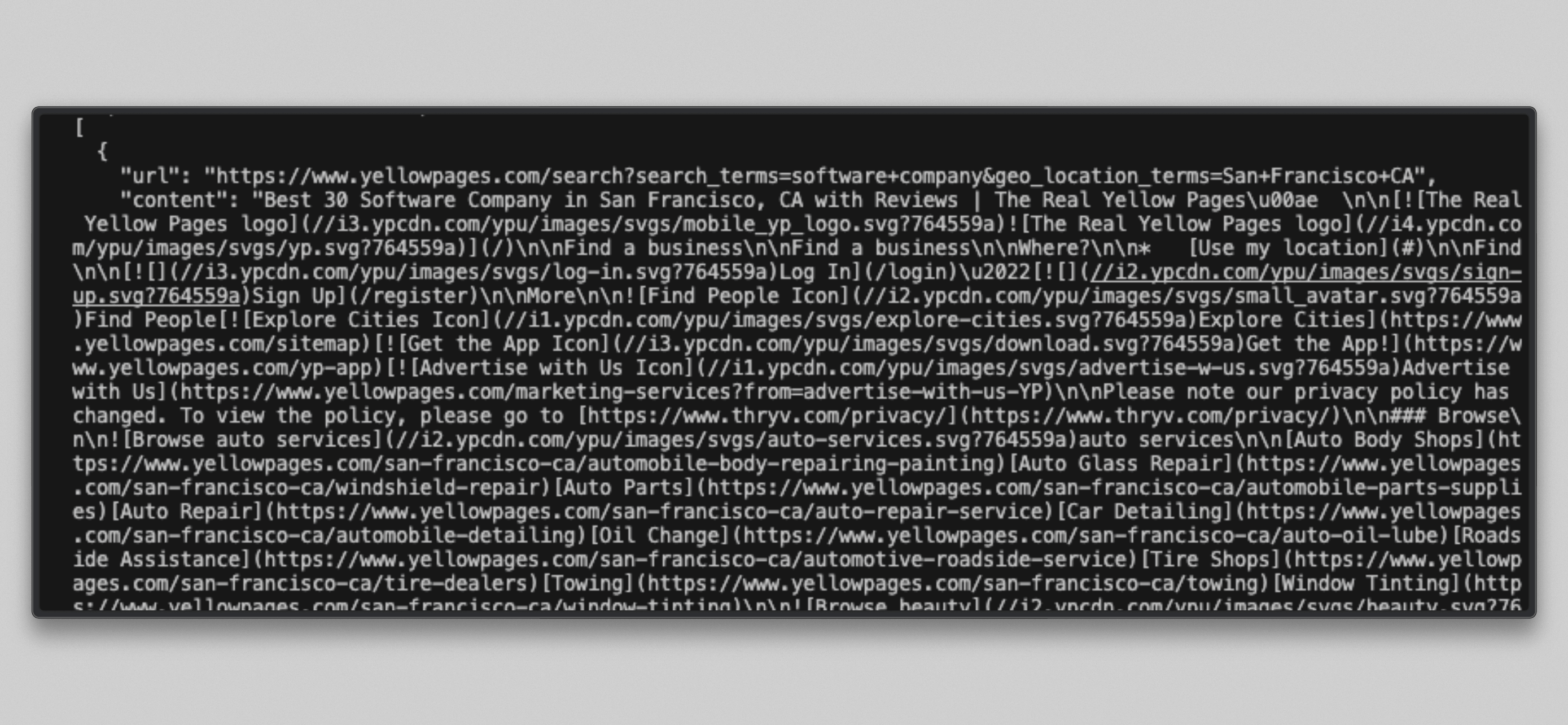
注意: 部分 Yellow Pages URL 可能会返回
bad_endpoint消息,原因是该站点在 Bright Data 的即时访问模式下受限。这是正常现象:Bright Data 会在响应中显式返回错误,而不是静默失败。如果你需要访问受限站点的完全权限,请联系你的 Bright Data 客户经理。
最后,对输出运行 Spark 作业:
docker compose exec --user airflow airflow-worker python /opt/airflow/spark_jobs/process_leads.py \
/tmp/brightdata_raw/leads.json \
/tmp/brightdata_processed/leads这会把清洗后的、打分后的 Parquet 文件写入 /tmp/brightdata_processed/leads ,已经可以直接加载进 PostgreSQL 或任何下游系统。
Web Unlocker API 从 Yellow Pages 提供了最新的实时内容,而你的流水线无需写一行抓取工具代码或代理管理代码,就能自动完成清洗、打分与存储。由于反爬虫检测系统与限速,手动采集企业列表一向非常困难。通过 Bright Data 的 Web Unlocker,你可以在无需维护基础设施的情况下,可靠地在任意地区从任意公开站点抓取页面内容。
进一步扩展
这条流水线是一个可用的基础,你可以从多个方向扩展:
- 用 Amazon S3 或 Google Cloud Storage 替换本地文件系统作为中间数据层,从而让流水线在分布式 worker 之间也能工作。
- 在 Spark 处理与写入数据库之间增加一个 LLM 补全步骤:调用 OpenAI 或 Anthropic API,为每条 hot lead 自动生成个性化外联摘要。
- 用 Airflow 已有的 provider operators,把本地输出替换为直接推送到 Salesforce、HubSpot 或 Pipedrive 等 CRM。
- 使用 Great Expectations 或 Airflow 的 SQLCheckOperator 增加数据质量检查任务,在写入前验证记录数与字段完整性。
将 Spark 作业扩展到托管集群(AWS EMR、 - Google Dataproc 或 Databricks),只需在 Airflow 中更新 Spark 连接 URL,DAG 与 PySpark 代码保持不变。
- 增加一个并行采集任务:使用 Bright Data 的 SERP API 为每条线索补充近期新闻或搜索可见性数据。
可拓展空间几乎无限!
结论
在本文中,你通过结合 Bright Data 的 Web Unlocker API、Apache Airflow 与 Apache Spark,构建了一条可运行的线索生成流水线。
Airflow 负责调度、重试、依赖管理与可观测性;Spark 负责对原始企业数据进行分布式清洗、去重与评分;Bright Data 则解决最难的一环:无需管理代理、无需编写抓取工具代码、也无需对抗反爬虫系统,就能从网页获得新鲜页面内容。
与无代码自动化工具不同,这套栈让你对流水线的每一层都有完全控制权:采集参数、转换逻辑、输出 schema 与调度频率。它能自然地集成到任何现代数据平台中,并随数据量增长而扩展。
若要构建更丰富的流水线,请探索 Bright Data 全套数据采集工具 ,包括用于搜索数据的 SERP API、用于 JS 重页面的 Web Unlocker,以及面向常见用例的现成数据集。
立即注册一个免费的 Bright Data 账号 ,开始采集你的流水线所需的企业数据。



AI 内容创作者
Arindam Majumder 是一名开发者推广专员、YouTube博主和技术作家,专注于将大语言模型 (LLM)、智能体工作流及 AI 内容讲解得简单易懂,拥有超过5000名关注者。





