
在本指南中,我们将涵盖以下内容:
什么是Jsoup?
Jsoup 是一个Java HTML解析器。换句话说,Jsoup是一个Java库,允许您解析任何HTML文档。使用Jsoup,您可以解析本地HTML文件或从URL下载远程HTML文档。
Jsoup还提供了一系列广泛的方法来处理DOM。具体来说,您可以使用CSS选择器和类似Jquery的方法来选择HTML元素并从中提取数据。这使得Jsoup成为一个对初学者和专业人士都有效的Web Scraping Java库。
请注意,Jsoup并不是唯一一个执行Java Web Scraping的库。HtmlUnit 是另一个流行的Java Web Scraping库。查看我们关于使用HtmlUnit进行Java Web Scraping的指南。
前提条件
在编写第一行代码之前,您需要满足以下前提条件:
- Java >= 8:任何版本的Java大于或等于8都可以。建议下载和安装Java的LTS(长期支持)版本。具体来说,本教程基于Java 17。在撰写本文时,Java 17是最新的LTS版本。
- Maven 或 Gradle:您可以选择自己喜欢的Java构建自动化工具。具体来说,您需要Maven或Gradle来实现依赖管理功能。
- 支持Java的高级IDE:任何支持Java与Maven或Gradle的IDE都可以。本教程基于IntelliJ IDEA,这可能是最好的Java IDE。
请按照上面的链接下载并安装所有需要的前提条件。按照顺序,设置Java、Maven或Gradle以及Java的IDE。按照官方安装指南操作,以避免常见的问题和故障。
现在,让我们验证您是否满足所有前提条件。
验证Java配置是否正确
打开您的终端。您可以通过以下命令验证是否安装了Java并正确设置了Java PATH:
java -version该命令应打印出类似以下内容:
java version "17.0.5" 2022-10-18 LTS
Java(TM) SE Runtime Environment (build 17.0.5+9-LTS-191)
Java HotSpot(TM) 64-Bit Server VM (build 17.0.5+9-LTS-191, mixed mode, sharing)验证Maven或Gradle是否已安装
如果您选择Maven,请在终端中运行以下命令:
mvn -v您应获取有关配置的Maven版本的信息,如下所示:
Apache Maven 3.8.6 (84538c9988a25aec085021c365c560670ad80f63)
Maven home: C:Mavenapache-maven-3.8.6
Java version: 17.0.5, vendor: Oracle Corporation, runtime: C:Program FilesJavajdk-17.0.5
Default locale: en_US, platform encoding: Cp1252
OS name: "windows 11", version: "10.0", arch: "amd64", family: "windows"如果您选择了Gradle,请在终端中执行以下命令:
gradle -v同样,这应该会打印出您安装的Gradle版本的信息,如下所示:
------------------------------------------------------------
Gradle 7.5.1
------------------------------------------------------------
Build time: 2022-08-05 21:17:56 UTC
Revision: d1daa0cbf1a0103000b71484e1dbfe096e095918
Kotlin: 1.6.21
Groovy: 3.0.10
Ant: Apache Ant(TM) version 1.10.11 compiled on July 10 2021
JVM: 17.0.5 (Oracle Corporation 17.0.5+9-LTS-191)
OS: Windows 11 10.0 amd64太好了!现在您已经准备好学习如何使用Jsoup在Java中进行Web Scraping了!
如何使用Jsoup构建一个Web Scraper
在这里,您将学习如何构建一个使用Jsoup进行Web Scraping的脚本。该脚本将能够自动从网站中提取数据。具体来说,目标网站是Quotes to Scrape。如果您不熟悉此项目,这不过是一个用于Web Scraping的沙盒。
这是Quotes to Scrape的样子:
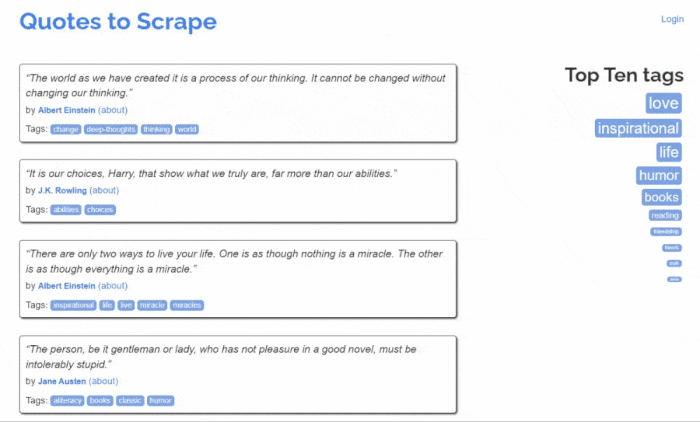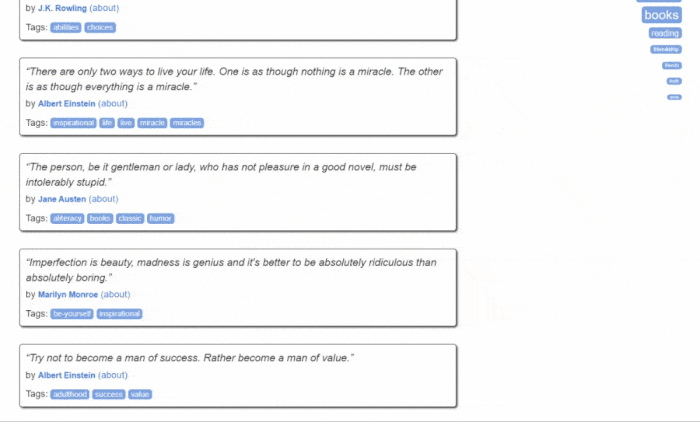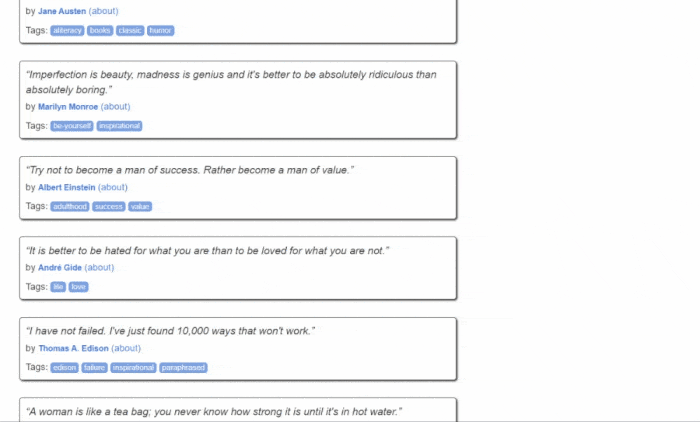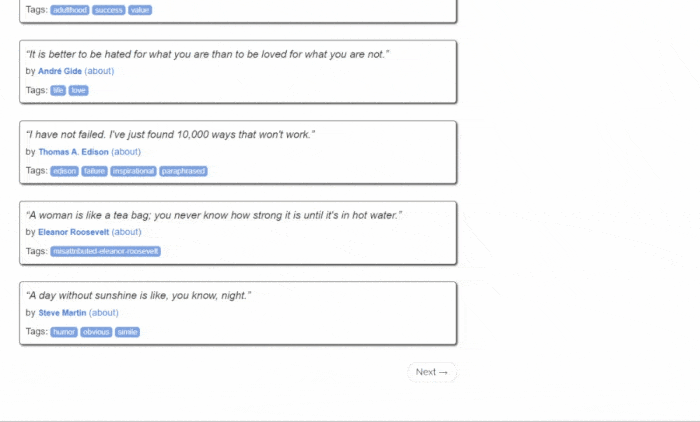
如您所见,目标网站仅包含一个分页的引文列表。Jsoup Web Scraper的目标是遍历每个页面,检索所有引文,并将这些数据返回为CSV格式。
现在,按照这个逐步的Jsoup教程,学习如何构建一个简单的Web Scraper!
步骤1:设置Java项目
在这里,您将看到如何在IntelliJ IDEA 2022.2.3中初始化一个Java项目。请注意,任何其他IDE也可以。在IntelliJ IDEA中,设置一个Java项目只需点击几下。启动IntelliJ IDEA并等待其加载。然后,在顶部菜单中选择File > New > Project...选项。
现在,在New Project弹出窗口中初始化您的Java项目,如下所示:
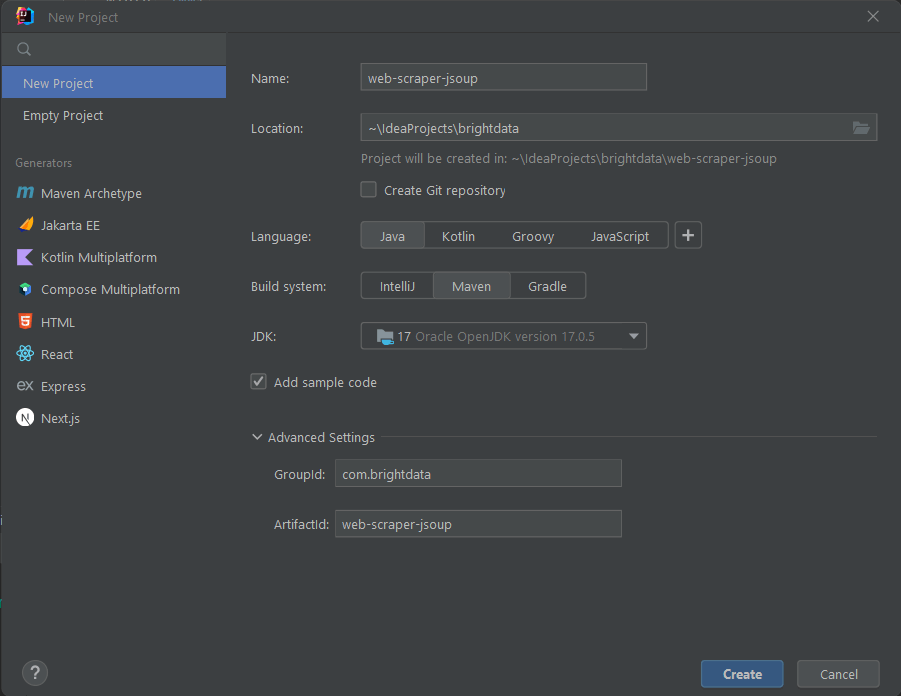
为您的项目命名并选择位置,选择Java作为编程语言,并根据您安装的构建工具选择Maven或Gradle。点击Create按钮,等待IntelliJ IDEA初始化您的Java项目。现在您应该看到以下空的Java项目:
现在是时候安装Jsoup并开始从网络中抓取数据了!
步骤2:安装Jsoup
如果您是Maven用户,请在pom.xml文件的dependencies标签内添加以下几行:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>您的Mavenpom.xml文件现在应该如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.brightdata</groupId>
<artifactId>web-scraper-jsoup</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
</dependencies>
</project>或者,如果您是Gradle用户,请将以下行添加到build.gradle文件的dependencies对象中:
implementation "org.jsoup:jsoup:1.15.3"您刚刚将jsoup添加到您的项目依赖项中。现在是时候安装它了。在IntelliJ IDEA中,点击下面的Gradle/Maven重新加载按钮:
这将安装jsoup依赖项。等待安装过程结束。现在,您可以访问Jsoup的所有功能。您可以通过在Main.java文件顶部添加以下导入行来验证Jsoup是否已正确安装:
import org.jsoup.*;如果IntelliJ IDEA没有报告错误,则意味着您现在可以在Java Web Scraping脚本中使用Jsoup。
现在让我们编写一个使用Jsoup的Web Scraper!
步骤3:连接到目标网页
您可以使用Jsoup在一行代码中连接到目标网站:
// downloading the target website with an HTTP GET request
Document doc = Jsoup.connect("https://quotes.toscrape.com/").get();借助Jsoup的connect()方法,您可以连接到网站。幕后,Jsoup对指定的URL执行HTTP GET请求,获取目标服务器返回的HTML文档,并将其存储在doc的JsoupDocument对象中。
请记住,如果connect()失败,Jsoup将引发IOException。这可能由于多种原因发生。但是,您应该知道,许多网站会阻止不包含有效User-Agent标头的请求。如果您不熟悉这一点,User-Agent标头是一个标识请求源自的应用程序和操作系统版本的字符串值。了解更多关于User-Agent的内容。
您可以在Jsoup中通过以下方式指定User-Agent标头:
Document doc = Jsoup
.connect("https://quotes.toscrape.com/")
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();具体来说,Jsoup的userAgent()方法允许您设置User-Agent标头。请注意,您可以通过header()方法设置任何其他HTTP标头值。
您的Main.java类现在应如下所示:
package com.brightdata;
import org.jsoup.*;
import org.jsoup.nodes.*;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
// downloading the target website with an HTTP GET request
Document doc = Jsoup
.connect("https://quotes.toscrape.com/")
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
}
}现在让我们开始分析目标网站,学习如何从中提取数据。
步骤4:检查HTML页面
如果您想从HTML文档中提取数据,首先必须分析网页的HTML代码。首先,您需要识别包含您想要抓取数据的HTML元素。然后,您需要找到选择这些HTML元素的方法。
您可以通过浏览器的开发者 工具实现这一点。在Google Chrome或任何基于Chromium的浏览器中,右键单击显示感兴趣数据的HTML元素。然后,选择Inspect。
这是您现在应该看到的:
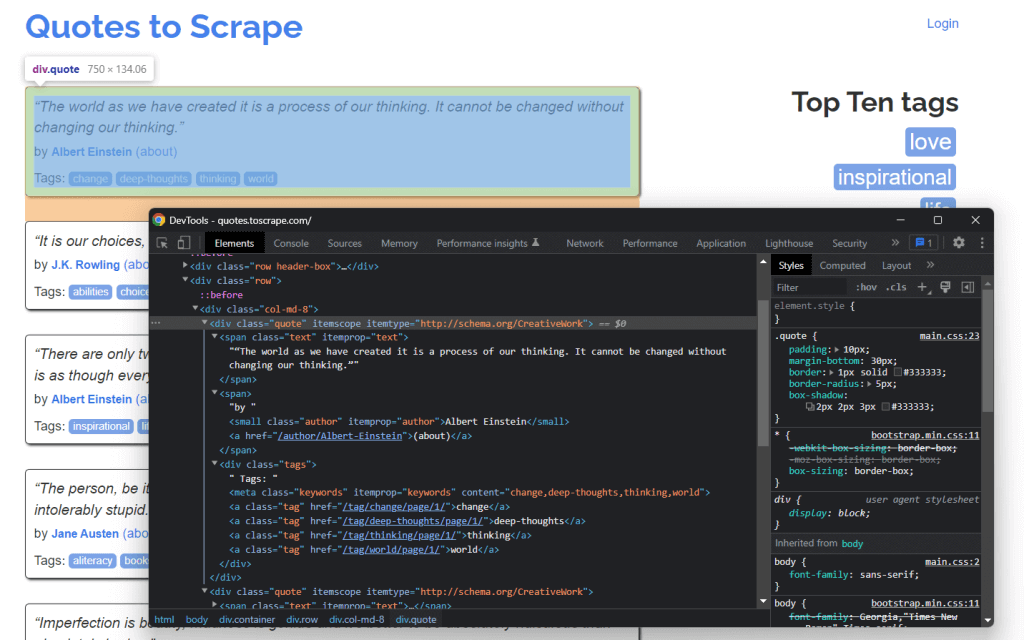
在Chrome DevTools中检查引文HTML元素
通过深入HTML代码,您可以看到每个引文都包含在<div>HTML中。具体来说,这个<div>元素包含:
- 包含引文文本的
<span>HTML元素 - 包含作者姓名的
<small>HTML元素 - 包含一系列
<a>HTML元素的<div>元素,这些元素包含与引文关联的标签。
现在,看看这些HTML元素使用的CSS类。借助这些CSS类,您可以定义选择这些HTML元素的CSS选择器。具体来说,您可以通过在.quote上应用CSS选择器来检索与引文相关的所有数据:
.text.author.tags .tag
现在,让我们学习如何在Jsoup中执行此操作。
步骤5:使用Jsoup选择HTML元素
Jsoup的Document类提供了多种选择DOM中HTML元素的方法。让我们深入了解其中最重要的一些。
Jsoup允许您根据标签提取HTML元素:
// selecting all <div> HTML elements
Elements divs = doc.getElementsByTag("div");这将返回DOM中包含的<div>HTML元素的列表。
同样,您可以根据类选择HTML元素:
// getting the ".quote" HTML element
Elements quotes = doc.getElementsByClass("quote");如果您想根据其id属性检索单个HTML元素,可以使用:
// getting the "#quote-1" HTML element
Element div = doc.getElementById("quote-1");您还可以根据属性选择HTML元素:
// selecting all HTML elements that have the "value" attribute
Elements htmlElements = doc.getElementsByAttribute("value");或者包含特定文本的元素:
// selecting all HTML elements that contain the word "for"
Elements htmlElements = doc.getElementsContainingText("for");这些只是一些例子。请记住,Jsoup提供了超过20种不同的方法从网页中选择HTML元素。查看所有方法。
正如之前所学,CSS选择器是选择HTML元素的有效方法。您可以通过select()方法在Jsoup中应用CSS选择器来检索元素:
// selecting all quote HTML elements
Elements quoteElements = doc.getElementsByClass(".quote");由于Elements扩展了ArrayList,您可以遍历它以获取每个JsoupElement。请注意,您也可以对单个Element应用所有HTML选择方法。这将限制选择逻辑到所选HTML元素的子元素。
因此,您可以在每个.quote上如下选择所需的HTML元素:
for (Element quoteElement: quoteElements) {
Element text = quoteElement.select(".text").first();
Element author = quoteElement.select(".author").first();
Elements tags = quoteElement.select(".tag");
}现在让我们学习如何从这些HTML元素中提取数据。
步骤6:使用Jsoup从网页中提取数据
首先,您需要一个Java类来存储抓取的数据。在主包中创建一个Quote.java文件并如下初始化:
package com.brightdata;
package com.brightdata;
public class Quote {
private String text;
private String author;
private String tags;
public String getText() {
return text;
}
public void setText(String text) {
this.text = text;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getTags() {
return tags;
}
public void setTags(String tags) {
this.tags = tags;
}
}现在,让我们扩展上一节末尾的代码片段。从选择的HTML元素中提取所需数据,并将其存储在Quote对象中,如下所示:
// initializing the list of Quote data objects
// that will contain the scraped data
List<Quote> quotes = new ArrayList<>();
// retrieving the list of product HTML elements
// selecting all quote HTML elements
Elements quoteElements = doc.select(".quote");
// iterating over the quoteElements list of HTML quotes
for (Element quoteElement : quoteElements) {
// initializing a quote data object
Quote quote = new Quote();
// extracting the text of the quote and removing the
// special characters
String text = quoteElement.select(".text").first().text()
.replace("“", "")
.replace("”", "");
String author = quoteElement.select(".author").first().text();
// initializing the list of tags
List<String> tags = new ArrayList<>();
// iterating over the list of tags
for (Element tag : quoteElement.select(".tag")) {
// adding the tag string to the list of tags
tags.add(tag.text());
}
// storing the scraped data in the Quote object
quote.setText(text);
quote.setAuthor(author);
quote.setTags(String.join(", ", tags)); // merging the tags into a "A, B, ..., Z" string
// adding the Quote object to the list of the scraped quotes
quotes.add(quote);
}由于每个引文可以有多个标签,您可以将它们全部存储在Java的List中。然后,您可以使用String.join()方法将字符串列表简化为一个字符串。最后,您可以将此字符串存储在quote对象中。
在for循环结束时, quotes将存储从目标网站主页提取的所有引文数据。但是目标网站由许多页面组成!
让我们学习如何使用Jsoup爬取整个网站。
步骤7:如何使用Jsoup爬取整个网站
如果仔细观察Quotes to Scrape主页,您会注意到一个“Next →”按钮。使用浏览器的开发者工具检查此HTML元素。右键单击它,然后选择Inspect。
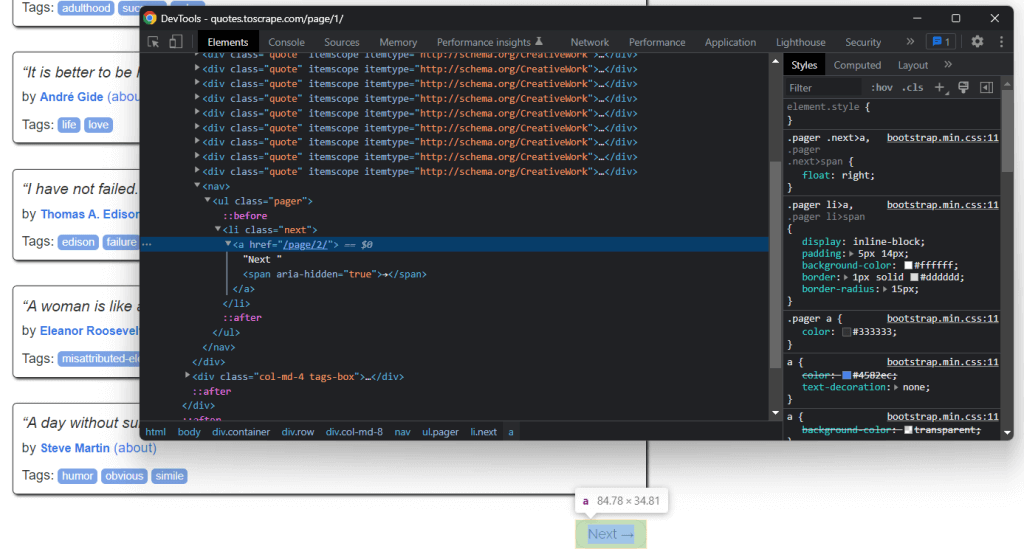
在这里,您可以注意到“Next →”按钮是一个<li>HTML元素。它包含一个<a>HTML元素,存储指向下一页的相对URL。请注意,您可以在目标网站的所有页面(除最后一页)上找到“Next →”按钮。大多数分页网站都遵循这种方法。
通过提取存储在该<a>HTML元素中的链接,您可以获取要抓取的下一页。因此,如果您想抓取整个网站,请遵循以下逻辑:
- 查找
.nextHTML元素- 如果存在,提取其<a>子元素中包含的相对URL并转到步骤2。
- 如果不存在,这是最后一页,您可以在此停止。
- 将提取的相对URL与网站的基本URL连接起来
- 使用完整URL连接到新页面
- 抓取新页面中的数据
- 返回步骤1。
这就是Web爬虫的工作原理。您可以使用Jsoup爬取分页网站,如下所示:
// the URL of the target website's home page
String baseUrl = "https://quotes.toscrape.com";
// initializing the list of Quote data objects
// that will contain the scraped data
List<Quote> quotes = new ArrayList<>();
// retrieving the home page...
// looking for the "Next →" HTML element
Elements nextElements = doc.select(".next");
// if there is a next page to scrape
while (!nextElements.isEmpty()) {
// getting the "Next →" HTML element
Element nextElement = nextElements.first();
// extracting the relative URL of the next page
String relativeUrl = nextElement.getElementsByTag("a").first().attr("href");
// building the complete URL of the next page
String completeUrl = baseUrl + relativeUrl;
// connecting to the next page
doc = Jsoup
.connect(completeUrl)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
// scraping logic...
// looking for the "Next →" HTML element in the new page
nextElements = doc.select(".next");
}如您所见,您可以通过简单的while循环实现上述爬取逻辑。只需几行代码。具体来说,您需要遵循do ... while的方法。
恭喜!您现在可以爬取整个网站。最后一步是学习如何将抓取的数据转换为更有用的格式。
步骤8:将抓取的数据导出为CSV
您可以将抓取的数据转换为CSV文件,如下所示:
// initializing the output CSV file
File csvFile = new File("output.csv");
// using the try-with-resources to handle the
// release of the unused resources when the writing process ends
try (PrintWriter printWriter = new PrintWriter(csvFile)) {
// iterating over all quotes
for (Quote quote : quotes) {
// converting the quote data into a
// list of strings
List<String> row = new ArrayList<>();
// wrapping each field with between quotes
// to make the CSV file more consistent
row.add(""" + quote.getText() + """);
row.add(""" +quote.getAuthor() + """);
row.add(""" +quote.getTags() + """);
// printing a CSV line
printWriter.println(String.join(",", row));
}
}此代码片段将引文转换为CSV格式并存储在output.csv文件中。如您所见,您无需额外的依赖即可实现此功能。您所需要做的只是使用File初始化一个CSV文件。然后,您可以通过PrintWriter将每个quote打印为CSV格式的行,填充output.csv文件。
请注意,当您不再需要PrintWriter时,应始终关闭它。具体来说,上述的try-with-resources将确保在try语句结束时关闭PrintWriter实例。
您从浏览一个网站开始,现在可以抓取其所有数据并将其存储在CSV文件中。现在是时候查看完整的Jsoup Web Scraper代码了。
将所有内容整合在一起
这是完整的Java中使用Jsoup进行Web Scraping的脚本:
package com.brightdata;
import org.jsoup.*;
import org.jsoup.nodes.*;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
import java.io.PrintWriter;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// the URL of the target website's home page
String baseUrl = "https://quotes.toscrape.com";
// initializing the list of Quote data objects
// that will contain the scraped data
List<Quote> quotes = new ArrayList<>();
// downloading the target website with an HTTP GET request
Document doc = Jsoup
.connect(baseUrl)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
// looking for the "Next →" HTML element
Elements nextElements = doc.select(".next");
// if there is a next page to scrape
while (!nextElements.isEmpty()) {
// getting the "Next →" HTML element
Element nextElement = nextElements.first();
// extracting the relative URL of the next page
String relativeUrl = nextElement.getElementsByTag("a").first().attr("href");
// building the complete URL of the next page
String completeUrl = baseUrl + relativeUrl;
// connecting to the next page
doc = Jsoup
.connect(completeUrl)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
// retrieving the list of product HTML elements
// selecting all quote HTML elements
Elements quoteElements = doc.select(".quote");
// iterating over the quoteElements list of HTML quotes
for (Element quoteElement : quoteElements) {
// initializing a quote data object
Quote quote = new Quote();
// extracting the text of the quote and removing the
// special characters
String text = quoteElement.select(".text").first().text();
String author = quoteElement.select(".author").first().text();
// initializing the list of tags
List<String> tags = new ArrayList<>();
// iterating over the list of tags
for (Element tag : quoteElement.select(".tag")) {
// adding the tag string to the list of tags
tags.add(tag.text());
}
// storing the scraped data in the Quote object
quote.setText(text);
quote.setAuthor(author);
quote.setTags(String.join(", ", tags)); // merging the tags into a "A; B; ...; Z" string
// adding the Quote object to the list of the scraped quotes
quotes.add(quote);
}
// looking for the "Next →" HTML element in the new page
nextElements = doc.select(".next");
}
// initializing the output CSV file
File csvFile = new File("output.csv");
// using the try-with-resources to handle the
// release of the unused resources when the writing process ends
try (PrintWriter printWriter = new PrintWriter(csvFile, StandardCharsets.UTF_8)) {
// to handle BOM
printWriter.write('ufeff');
// iterating over all quotes
for (Quote quote : quotes) {
// converting the quote data into a
// list of strings
List<String> row = new ArrayList<>();
// wrapping each field with between quotes
// to make the CSV file more consistent
row.add(""" + quote.getText() + """);
row.add(""" +quote.getAuthor() + """);
row.add(""" +quote.getTags() + """);
// printing a CSV line
printWriter.println(String.join(",", row));
}
}
}
}如这里所示,您可以在不到100行代码中实现一个Java中的Web Scraper。借助Jsoup,您可以连接到网站,完整地爬取它,并自动提取其所有数据。然后,您可以将抓取的数据写入CSV文件。这就是这个Jsoup Web Scraper的目的。
在IntelliJ IDEA中,通过点击下面的按钮启动Web Scraping Jsoup脚本:

IntelliJ IDEA将编译Main.java文件并执行Main类。在抓取过程结束时,您将在项目的根目录中找到一个output.csv文件。打开它,应该包含以下数据:
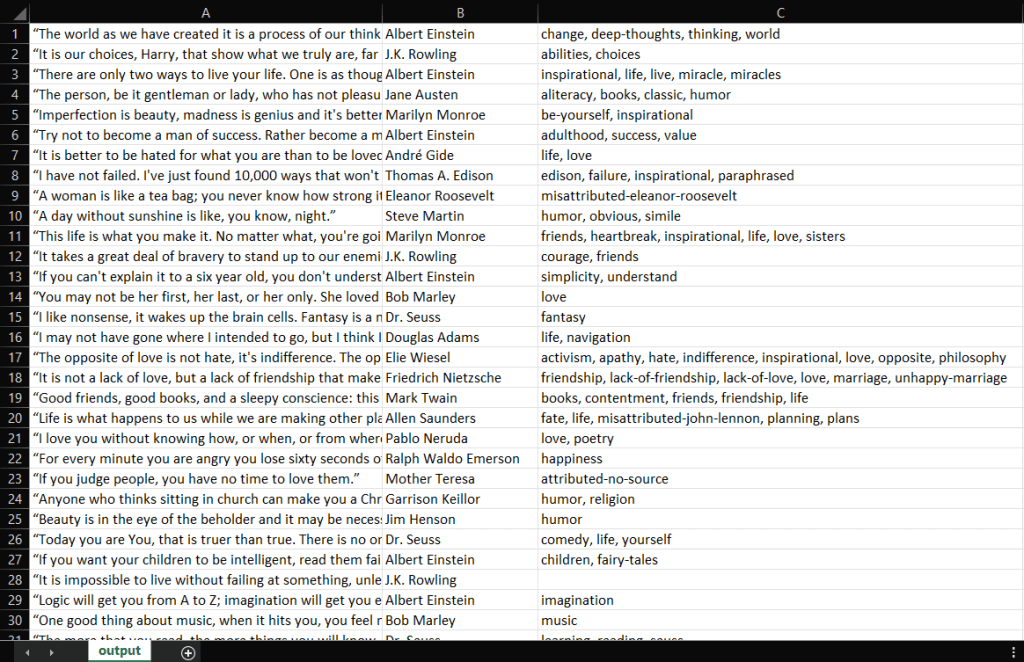
干得好!您现在拥有一个包含Quotes to Scrape的所有100个引文的CSV文件!这意味着您刚刚学会了如何使用Jsoup构建一个Web Scraper!
总结
在本教程中,您了解了构建Web Scraper所需的内容,了解了Jsoup是什么以及如何使用它从网络中抓取数据。具体来说,您通过一个实际的例子学习了如何使用Jsoup构建Web Scraping应用程序。正如您所学,使用Jsoup在Java中进行Web Scraping只需几行代码。
然而,Web Scraping并不容易。这是因为您必须面对许多挑战。不要忘记,反机器人和反抓取技术现在比以往任何时候都更受欢迎。您只需要一个强大且功能齐全的Web Scraping工具,由Bright Data提供。不想处理抓取?看看我们的数据集。
如果您想了解更多关于如何避免被屏蔽的信息,可以根据您的使用案例从Bright Data提供的众多代理服务中选择一个代理。联系我们,为您的项目找到完美的解决方案。



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




