
如果你进行过一段时间的网络爬虫,你可能会遇到被地理围栏或IP封禁的网站。代理服务器可以帮助你解决这些问题,掩盖你的真实身份,获取被禁止的资源。
Rust代理服务器可以轻松实现以下功能:
- 避免IP封禁:使用一个新的代理IP可以让你绕过封禁,继续进行爬虫。
- 绕过地理限制:如果你对其他国家的内容感兴趣,本地代理可以让你获得临时的在线身份,使受限制的内容变得可访问。
- 保持匿名:代理服务器可以隐藏你的真实IP地址,保护你的隐私不被窥探。
这只是冰山一角!Rust强大的库和健壮的语法让设置和管理代理变得轻而易举。在本文中,你将了解代理服务器以及如何在Rust中使用代理服务器进行网络爬虫。
在Rust中使用代理服务器
在Rust中使用代理服务器之前,你需要先设置一个。在本教程中,你将在本地机器上的Nginx服务器中设置一个代理,并使用它从Rust二进制文件发送爬虫请求到爬虫沙箱(例如https://toscrape.com/)。
首先,在本地系统上安装Nginx。对于Linux,你可以使用以下命令通过Homebrew安装:
sudo apt install nginx然后使用以下命令启动服务器:
nginx接下来,你需要配置服务器使其作为某些位置的代理。例如,你可以配置它作为位置/的代理,并为它处理的每个请求添加一个头(例如X-Proxy-Server)。为此,你需要编辑nginx.conf文件。
文件的位置根据主机操作系统的不同而不同。参考Nginx文档获取帮助。在Linux上,你可以在/etc/nginx/nginx.conf找到nginx.conf。打开它并在文件中的http.server对象中添加以下代码块:
http {
server {
# Add the following block
location / {
resolver 8.8.8.8;
proxy_pass http://$http_host$request_uri;
proxy_set_header 'X-Proxy-Server' 'Nginx';
}
}
}这将代理配置为将所有传入请求转发到原始URL,同时为请求添加一个头。如果你可以访问目标服务器上的日志,可以检查此头以验证请求是否通过代理发出。
现在,运行以下命令重新启动Nginx服务器:
nginx -s reload此服务器现在已准备好作为爬虫的正向代理。
在Rust中创建一个网络爬虫项目
要设置一个新的爬虫项目,请使用Cargo运行以下命令创建一个新的Rust二进制文件:
cargo new rust-scraper项目创建后,你需要添加三个crate。首先添加reqwest和scraper。你将使用reqwest发送请求到目标资源,并使用scraper从reqwest接收到的HTML中提取所需数据。然后添加第三个cratetokio,以通过reqwest处理异步网络调用。
要安装这些,在项目目录中运行以下命令:
cargo add scraper reqwest tokio --features "reqwest/blocking tokio/full"接下来,打开src/main.rs文件并添加以下代码:
use reqwest;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>>{
let url = "http://books.toscrape.com/";
let client = reqwest::Client::new();
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
extract_products(&html_content);
Ok(())
}
fn extract_products(html_content: &str) {
let document = scraper::Html::parse_document(&html_content);
let html_product_selector = scraper::Selector::parse("article.product_pod").unwrap();
let html_products = document.select(&html_product_selector);
let mut products: Vec<Product> = Vec::new();
for html_product in html_products {
let url = html_product
.select(&scraper::Selector::parse("a").unwrap())
.next()
.and_then(|a| a.value().attr("href"))
.map(str::to_owned);
let image = html_product
.select(&scraper::Selector::parse("img").unwrap())
.next()
.and_then(|img| img.value().attr("src"))
.map(str::to_owned);
let name = html_product
.select(&scraper::Selector::parse("h3").unwrap())
.next()
.map(|title| title.text().collect::<String>());
let price = html_product
.select(&scraper::Selector::parse(".price_color").unwrap())
.next()
.map(|price| price.text().collect::<String>());
let product = Product {
url,
image,
name,
price,
};
products.push(product);
}
println!("{:?}", products);
}
#[derive(Debug)]
struct Product {
url: Option<String>,
image: Option<String>,
name: Option<String>,
price: Option<String>,
}这段代码使用reqwestcrate创建一个客户端,并获取URLhttps://books.toscrape.com上的网页。然后,它在一个名为extract_products的函数中处理页面的HTML,以从页面中提取产品列表。提取逻辑使用scrapercrate实现,并且无论是否使用代理都保持不变。
现在,尝试运行此二进制文件以查看它是否正确提取产品列表。为此,运行以下命令:
cargo run你应该在终端中看到如下输出:
Finished dev [unoptimized + debuginfo] target(s) in 0.80s
Running `target/debug/rust_scraper`
[Product { url: Some("catalogue/a-light-in-the-attic_1000/index.html"), image: Some("media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg"), name: Some("A Light in the ..."), price: Some("£51.77") }, Product { url: Some("catalogue/tipping-the-velvet_999/index.html"), image: Some("media/cache/26/0c/260c6ae16bce31c8f8c95daddd9f4a1c.jpg"), name: Some("Tipping the Velvet"), price: Some("£53.74") }, Product { url: Some("catalogue/soumission_998/index.html"), image: Some("media/cache/3e/ef/3eef99c9d9adef34639f510662022830.jpg"), name: Some("Soumission"), price: Some("£50.10") }, Product { url: Some("catalogue/sharp-objects_997/index.html"), image: Some("media/cache/32/51/3251cf3a3412f53f339e42cac2134093.jpg"), name: Some("Sharp Objects"), price: Some("£47.82") }, Product { url: Some("catalogue/sapiens-a-brief-history-of-humankind_996/index.html"), image: Some("media/cache/be/a5/bea5697f2534a2f86a3ef27b5a8c12a6.jpg"), name: Some("Sapiens: A Brief History ..."), price: Some("£54.23") }, Product { url: Some("catalogue/the-requiem-red_995/index.html"), image: Some("media/cache/68/33/68339b4c9bc034267e1da611ab3b34f8.jpg"), name: Some("The Requiem Red"), price: Some("£22.65") }, Product { url: Some("catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"), image: Some("media/cache/92/27/92274a95b7c251fea59a2b8a78275ab4.jpg"), name: Some("The Dirty Little Secrets ..."), price: Some("£33.34") }, Product { url: Some("catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html"), image: Some("media/cache/3d/54/3d54940e57e662c4dd1f3ff00c78cc64.jpg"), name: Some("The Coming Woman: A ..."), price: Some("£17.93") }, Product { url: Some("catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html"), image: Some("media/cache/66/88/66883b91f6804b2323c8369331cb7dd1.jpg"), name: Some("The Boys in the ..."), price: Some("£22.60") }, Product { url: Some("catalogue/the-black-maria_991/index.html"), image: Some("media/cache/58/46/5846057e28022268153beff6d352b06c.jpg"), name: Some("The Black Maria"), price: Some("£52.15") }, Product { url: Some("catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html"), image: Some("media/cache/be/f4/bef44da28c98f905a3ebec0b87be8530.jpg"), name: Some("Starving Hearts (Triangular Trade ..."), price: Some("£13.99") }, Product { url: Some("catalogue/shakespeares-sonnets_989/index.html"), image: Some("media/cache/10/48/1048f63d3b5061cd2f424d20b3f9b666.jpg"), name: Some("Shakespeare's Sonnets"), price: Some("£20.66") }, Product { url: Some("catalogue/set-me-free_988/index.html"), image: Some("media/cache/5b/88/5b88c52633f53cacf162c15f4f823153.jpg"), name: Some("Set Me Free"), price: Some("£17.46") }, Product { url: Some("catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html"), image: Some("media/cache/94/b1/94b1b8b244bce9677c2f29ccc890d4d2.jpg"), name: Some("Scott Pilgrim's Precious Little ..."), price: Some("£52.29") }, Product { url: Some("catalogue/rip-it-up-and-start-again_986/index.html"), image: Some("media/cache/81/c4/81c4a973364e17d01f217e1188253d5e.jpg"), name: Some("Rip it Up and ..."), price: Some("£35.02") }, Product { url: Some("catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html"), image: Some("media/cache/54/60/54607fe8945897cdcced0044103b10b6.jpg"), name: Some("Our Band Could Be ..."), price: Some("£57.25") }, Product { url: Some("catalogue/olio_984/index.html"), image: Some("media/cache/55/33/553310a7162dfbc2c6d19a84da0df9e1.jpg"), name: Some("Olio"), price: Some("£23.88") }, Product { url: Some("catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html"), image: Some("media/cache/09/a3/09a3aef48557576e1a85ba7efea8ecb7.jpg"), name: Some("Mesaerion: The Best Science ..."), price: Some("£37.59") }, Product { url: Some("catalogue/libertarianism-for-beginners_982/index.html"), image: Some("media/cache/0b/bc/0bbcd0a6f4bcd81ccb1049a52736406e.jpg"), name: Some("Libertarianism for Beginners"), price: Some("£51.33") }, Product { url: Some("catalogue/its-only-the-himalayas_981/index.html"), image: Some("media/cache/27/a5/27a53d0bb95bdd88288eaf66c9230d7e.jpg"), name: Some("It's Only the Himalayas"), price: Some("£45.17") }]这表明爬虫逻辑正确工作。现在,你已经准备好将Nginx代理添加到此爬虫中。
使用你的代理
你会注意到,爬虫请求通过main()函数中的一个完整的reqwest客户端发送(而不是使用一次性的get调用)。这意味着你可以在创建客户端时轻松配置代理。
要配置客户端,请更新以下代码行:
async fn main() -> Result<(), Box<dyn Error>>{
let url = "https://books.toscrape.com/";
# Replace this line
let client = reqwest::Client::new();
# With this one
let client = reqwest::Client::builder()
.proxy(reqwest::Proxy::https("http://localhost:8080")?)
.build()?;
//...
Ok(())
}在使用
reqwest配置代理时,重要的是要了解一些代理提供商(包括Bright Data)同时支持http和https配置,但可能需要一些额外的配置。如果使用https时遇到问题,请尝试切换到http以运行应用。
现在,再次尝试使用cargo run命令运行此二进制文件。你应该收到与之前类似的响应。不过,请确保查看你的Nginx服务器日志,查看请求是否通过它代理。
根据你的操作系统的指示,找到你的Nginx服务器日志。对于基于Homebrew的Mac安装,访问和错误日志文件位于/opt/homebrew/var/log/nginx文件夹中。打开access.log文件,你应该在文件底部看到如下行:
127.0.0.1 - - [07/Jan/2024:05:19:54 +0530] "GET https://books.toscrape.com/ HTTP/1.1" 200 18 "-" "-"这表明请求通过Nginx服务器代理。现在,你可以在远程主机上设置服务器,以便利用它绕过地理限制或IP封禁。
旋转代理
在进行网络爬虫项目时,你可能需要在一组代理之间进行轮换。这可以让你在多个IP之间分散爬虫工作量,避免由于来自单一来源或位置的高流量而被检测到。
要实现代理轮换,你需要将以下函数添加到main.rs文件中:
#[derive(Debug)]
struct Proxy {
ip: String,
port: String,
}
fn get_proxies() -> Vec<Proxy> {
let mut proxies = Vec::new();
proxies.push(Proxy {
ip: "http://localhost".to_string(),
port: "8082".to_string(),
});
// Add more proxies.push statements here to create a bigger set of proxies
proxies
}这有助于你轻松定义代理集。然后你需要更新main函数以使用随机代理:
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let url = "https://books.toscrape.com/";
// Add these two lines
let proxies = get_proxies();
let random_proxy = proxies.choose(&mut rand::thread_rng()).unwrap();
let client = reqwest::Client::builder()
// Update the following line to match this
.proxy(reqwest::Proxy::http(format!("{0}:{1}", random_proxy.ip, random_proxy.port))?)
.build()?;
// Rest remains the same
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
extract_products(&html_content);
Ok(())
}现在,你需要安装randcrate以能够随机选择代理。你可以通过运行以下命令来完成此操作:
cargo add rand然后在main.rs文件顶部添加以下行以导入randcrate:
use rand::seq::SliceRandom;现在,尝试再次运行此二进制文件,看看它是否工作,使用cargo run命令。它应该输出与之前相同的结果,这表明随机代理列表设置正确。
Bright Data代理服务器
如你所见,手动设置代理需要大量工作。此外,你需要在远程服务器上托管代理服务器,以便能够利用新IP地址和位置的所有好处。如果你想避免所有这些麻烦,考虑使用Bright Data代理服务器。
虽然存在无数代理提供商,但Bright Data以其规模和灵活性而闻名。通过Bright Data,你可以获得遍布195个国家的超过7200万个住宅、移动、数据中心和ISP代理的大规模网络。使用大量住宅代理,你可以针对特定国家、城市甚至移动运营商进行精准爬取。
此外,Bright Data住宅代理无缝融入真实用户流量,而数据中心和移动选项则提供高速和可靠连接。Bright Data自动轮换保持你的爬虫灵活,最小化检测和封禁的风险。
要亲自体验,访问https://www.bright.cn/并点击右上角的免费试用。注册后,你将进入控制面板页面:
在此页面,点击查看代理产品,导航到代理和爬虫基础设施页面:
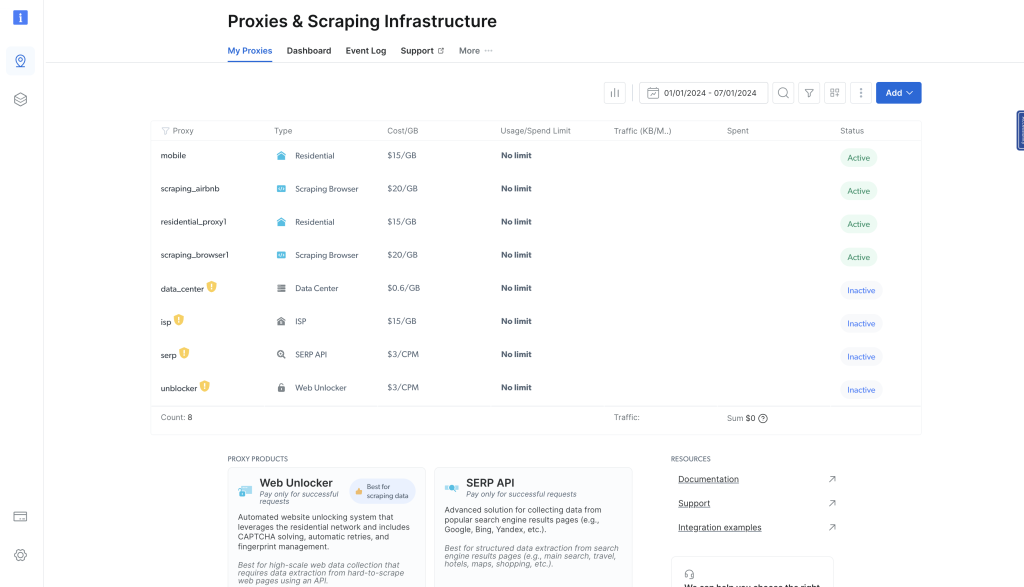
此页面列出你之前配置的所有代理。要添加代理,点击右上角的蓝色添加按钮,选择住宅代理:
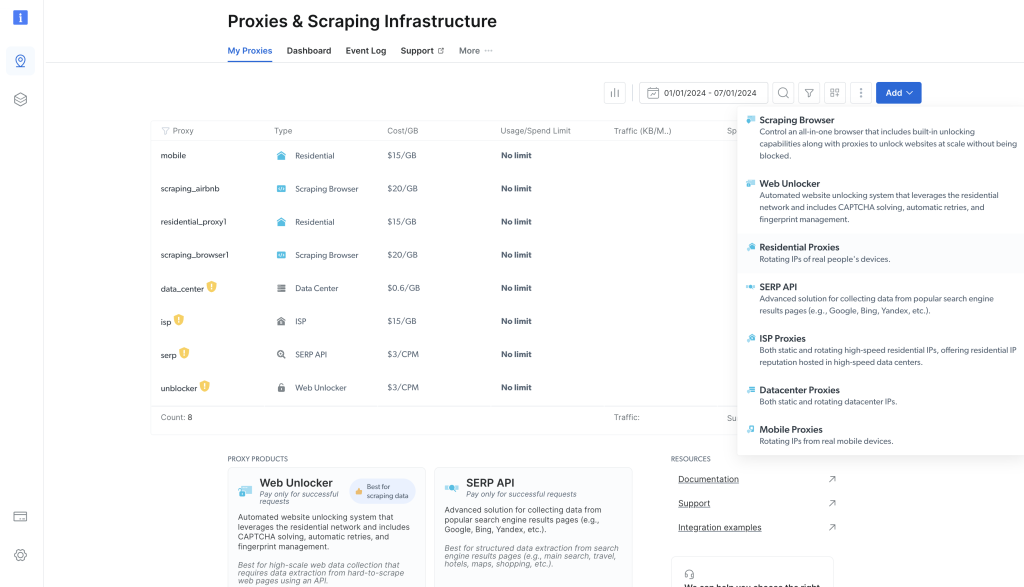
然后会弹出一个表单,你可以在其中配置新的住宅代理。保留默认选项,滚动到页面底部,点击添加。
住宅代理创建后,你将被导航到显示新创建代理详细信息的页面。点击访问参数选项卡查看代理的主机、用户名和密码:
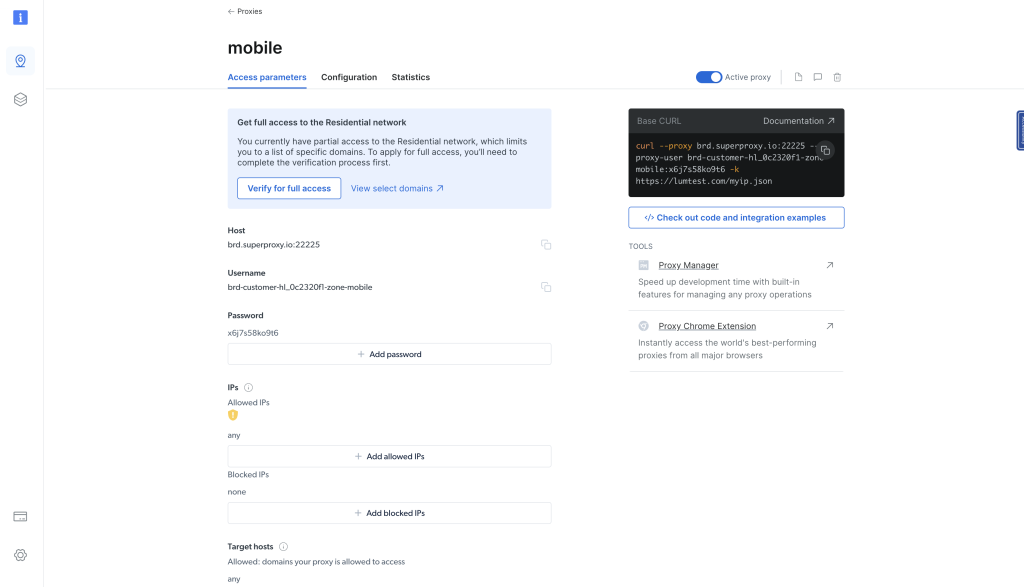
你可以使用这些参数将代理集成到你的Rust二进制文件中。为此,请更新src/main.rs文件中的main()函数,如下所示:
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let url = "https://books.toscrape.com/";
// Update the following block with the details from the Bright Data proxy details page
let client = reqwest::Client::builder()
.proxy(reqwest::Proxy::http("<BD proxy hostname & port>")?
.basic_auth("<your BD username>", "<your BD password>"))
.build()?;
// Rest remains the same
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
extract_products(&html_content);
Ok(())
}然后再次尝试运行二进制文件。它应该像之前一样正确返回响应。唯一的关键区别是请求通过Bright Data代理进行,隐藏了你的身份和真实位置。
你可以通过发送请求到显示客户端IP地址的API来确认这一点,使用以下代码片段:
use reqwest;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let url = "http://lumtest.com/myip.json";
// Update the following block with the details from the Bright Data proxy details page
let client = reqwest::Client::builder()
.proxy(reqwest::Proxy::http("<BD proxy hostname & port>")?
.basic_auth("<your BD username>", "<your BD password>"))
.build()?;
// Rest remains the same
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
println!("{:?}", html_content);
Ok(())
}当你使用cargo run命令运行代码时,你应该看到如下输出:
"{"ip":"209.169.64.172","country":"US","asn":{"asnum":6300,"org_name":"CCI-TEXAS"},"geo":{"city":"Conroe","region":"TX","region_name":"Texas","postal_code":"77304","latitude":30.3228,"longitude":-95.5298,"tz":"America/Chicago","lum_city":"conroe","lum_region":"tx"}}"这将反映你用于查询页面的代理服务器的IP和位置详细信息。
结论
在本文中,你学习了如何在Rust中使用代理。记住,代理就像数字面具,让你能够绕过在线限制,窥探网站背后的内容。它们还可以让你在浏览网络时保持匿名。
然而,自己设置代理是一个复杂的过程。通常建议你使用一个成熟的代理提供商,例如Bright Data,它提供了一个超过7200万个易于使用的代理池。







