作为一种数据采集技术,网页抓取经常因各种防护措施而受阻,例如 IP 禁令、地理封锁和隐私保护措施。值得庆幸的是,代理服务器可以帮您克服这些障碍。它们可以充当计算机和网络之间的中介,用自己的 IP 地址处理请求。这一功能不仅有助于您避开与 IP 有关的限制和封锁,还便于您访问受到地理限制的网站内容。此外,代理服务器可以在网页抓取期间保持隐匿性,保护您的隐私。
使用代理服务器还可以提高网页抓取工作的效率和可靠性。它们能在多台服务器上分发请求,确保每台服务器都不会承受过大的负载,从而优化整个流程。
在本教程中,您将了解如何在 Node.js 中使用代理服务器进行网页抓取项目。
阅读前须知
建议您在学习本教程前先熟悉一下 JavaScript 和 Node.js。如您尚未在计算机上安装 Node.js,请 马上安装它。
您还需要安装一个合适的文本编辑器。文本编辑器有好多种可选择,例如 Sublime Text。本教程使用 Visual Studio Code (VS Code)。它操作方便,且功能丰富,让编码变得更轻松。
首先,新建一个名为 web-scraping-proxy 的目录,然后初始化 Node.js 项目。打开终端或 shell,并使用以下命令导航到新目录:
cd web-scraping-proxy
npm init -y接下来,需要安装一些 Node.js 包来处理 HTTP 请求和解析 HTML。
请确保您已进入项目目录,然后运行以下命令:
npm install axios node-fetch playwright puppeteer http-proxy-agent
npx playwright installAxios 用于发出 HTTP 请求以检索网页内容。Playwright 和 Puppeteer 可自动进行浏览器交互,这对抓取动态网站至关重要。Playwright 支持各种浏览器,而 Puppeteer 则主要用于控制 Chrome 或 Chromium 浏览器。http-proxy-agent 库将用于为 HTTP 请求创建代理服务器。
此外还要使用 npx playwright install 安装 playwright 库所需使用的驱动程序。
完成上述步骤后,您就可以开始学习如何使用 Node.js 进行网页抓取了。
在网页抓取时,设置本地地理服务
网页抓取的第一步至关重要,那就是要建立代理服务器,本教程使用开源工具 mitmproxy。
首先,请前往 mitmproxy 下载页面,根据您的操作系统选择对应的 10.1.6 版本。如在安装过程中需要指导,那 mitmproxy 安装指南可以帮到您。
安装好 mitmproxy 后,在终端中输入以下命令以启动它:
mitmproxy 此命令将在终端中打开一个窗口,作为 mitmproxy 的界面:
为确保您的代理设置正确,请先进行测试。打开新的终端窗口并执行以下命令:
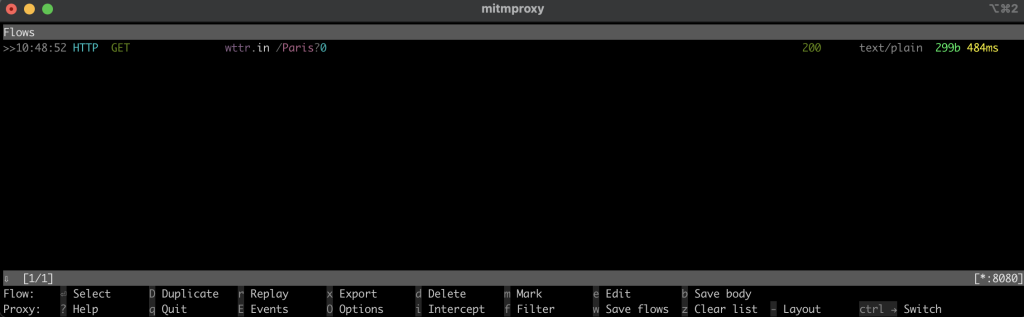
curl --proxy http://localhost:8080 "http://wttr.in/Paris?0"此命令用于获取巴黎的天气报告。输出结果应如下所示:
Weather report: Paris
Overcast
.--. -2(-6) °C
.-( ). ↙ 11 km/h
(___.__)__) 10 km
0.0 mm回到 mitmproxy 窗口后,您会发现它捕获了该请求,这表明您的本地代理运行正常:
在网页抓取时,在Node.js中实施代理服务
现在开始进入使用 Node.js 进行网页抓取的实践操作阶段。在本节中,您将编写一个脚本,用于通过本地代理服务器发送请求,进行网页抓取。
用Fetch Method抓取网站
在项目的根目录中新建一个名为 fetchScraping.js 的文件。此文件将包含一个代码,用于抓取网站内容(本文以 https://toscrape.com/ 为例)。
在 fetchScraping.js 中输入以下 JavaScript 代码。此脚本使用 fetch 函数通过代理服务器发送请求:
const fetch = require("node-fetch");
const HttpProxyAgent = require("http-proxy-agent");
async function fetchData(url) {
try {
const proxyAgent = new HttpProxyAgent.HttpProxyAgent(
"http://localhost:8080"
);
const response = await fetch(url, { agent: proxyAgent });
const data = await response.text();
console.log(data); // Outputs the fetched data
} catch (error) {
console.error("Error fetching data:", error);
}
}
fetchData("http://toscrape.com/");此代码片段定义了一个异步函数 fetchData,该函数会获取一个 URL,然后使用 fetch 向该 URL 发送请求,并通过本地代理路由该请求。然后它还会打印响应数据。
要执行网页抓取脚本,请打开终端或 shell 并导航至项目的根目录,即 fetchScraping.js 文件所在位置。使用以下命令运行脚本:
node fetchScraping.js您应该会在终端看到以下输出结果:
…output omitted…
<div class="row">
<div class="col-md-1"></div>
<div class="col-md-10">
<h2>Books</h2>
<p>A <a href="http://books.toscrape.com">fictional bookstore</a> that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: <a href="http://books.toscrape.com">books.toscrape.com</a></p>
<div class="col-md-6">
<a href="http://books.toscrape.com"><img src="./img/books.png" class="img-thumbnail"></a>
</div>
<div class="col-md-6">
<table class="table table-hover">
<tr><th colspan="2">Details</th></tr>
<tr><td>Amount of items </td><td>1000</td></tr>
<tr><td>Pagination </td><td>✔</td></tr>
<tr><td>Items per page </td><td>max 20</td></tr>
<tr><td>Requires JavaScript </td><td>✘</td></tr>
</table>
</div>
</div>
</div>
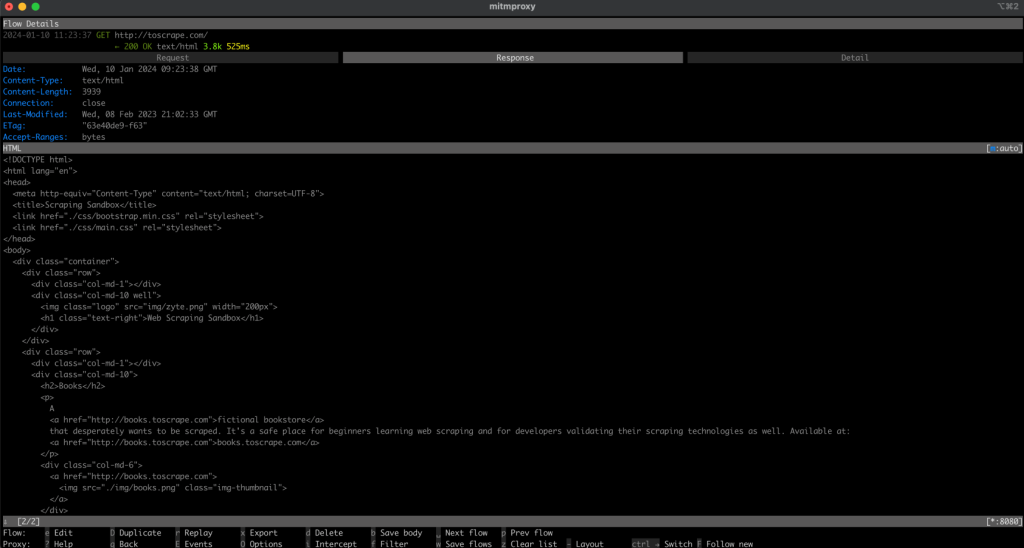
…output omitted…此输出结果是 http://toscrape.com 网页的 HTML 内容。成功显示此数据即表明您通过本地代理路由的网页抓取脚本运行正常。
现在,请返回 mitmproxy 窗口,您应该会看到请求记录,这表明您的请求是通过本地代理发送的:
用Playwright抓取网站
与 Fetch 相比,Playwright 是一款允许与网页进行更多动态交互的高级工具。您需要在项目中新建一个名为 playwrightScraping.js 的文件才能使用它。然后在该文件中输入以下 JavaScript 代码:
const { chromium } = require("playwright");
(async () => {
const browser = await chromium.launch({
proxy: {
server: "http://localhost:8080",
},
});
const page = await browser.newPage();
await page.goto("http://toscrape.com/");
// Extract and log the entire HTML content
const content = await page.content();
console.log(content);
await browser.close();
})();此代码使用 Playwright 启动被配置为使用本地代理服务器的 Chromium 浏览器实例。然后,它会在浏览器中打开一个新页面,导航至 http://toscrape.com 并等待页面加载。抓取完必要的数据后,浏览器就会关闭。
要运行此脚本,请确保您已进入包含 playwrightScraping.js 的目录。打开终端或 shell 并使用以下命令执行脚本:
node playwrightScraping.js 您运行脚本后,Playwright 会启动 Chromium 浏览器,导航至指定的 URL,并执行您添加的其他抓取命令。此过程会使用本地代理服务器,防止您暴露自己的 IP 地址并帮助您绕开潜在的限制。
所得到的输出结果应与之前的输出结果类似:
…output omitted…
<div class="row">
<div class="col-md-1"></div>
<div class="col-md-10">
<h2>Books</h2>
<p>A <a href="http://books.toscrape.com">fictional bookstore</a> that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: <a href="http://books.toscrape.com">books.toscrape.com</a></p>
<div class="col-md-6">
<a href="http://books.toscrape.com"><img src="./img/books.png" class="img-thumbnail"></a>
</div>
<div class="col-md-6">
<table class="table table-hover">
<tr><th colspan="2">Details</th></tr>
<tr><td>Amount of items </td><td>1000</td></tr>
<tr><td>Pagination </td><td>✔</td></tr>
<tr><td>Items per page </td><td>max 20</td></tr>
<tr><td>Requires JavaScript </td><td>✘</td></tr>
</table>
</div>
</div>
</div>
…output omitted…和之前一样,您会在 mitmproxy 窗口中看到请求记录。
用Puppeteer抓取网站
现在,使用 Puppeteer 抓取网站内容。Puppeteer 是一款功能强大的工具,可以高度控制无头 Chrome 或 Chromium 浏览器。此方法尤其适用于抓取使用 JavaScript 渲染的动态网站。
首先,在项目中新建一个名为 puppeteerScraping.js 的文件。此文件将包含 Puppeteer 代码,以使用代理服务器发送请求,进行网站抓取。
打开新建的 puppeteerScraping.js 文件并插入以下 JavaScript 代码:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
args: ['--proxy-server=http://localhost:8080']
});
const page = await browser.newPage();
await page.goto('http://toscrape.com/');
const content = await page.content();
console.log(content); // Outputs the page HTML
await browser.close();
})();在这段代码中,您将初始化 Puppeteer 以启动无头浏览器,并指定它使用本地代理服务器。浏览器将打开一个新页面,导航至 http://toscrape.com,并检索该页面的 HTML 内容。将内容记录到控制台后,浏览器会话就会关闭。
要执行您的脚本,请先在终端或 shell 中导航到包含 puppeteerScraping.js 的文件夹。使用以下命令运行脚本:
node puppeteerScraping.js 运行脚本后,Puppeteer 会使用代理服务器打开 http://toscrape.com/ 的 URL。您应该会在终端中看到打印出来的页面的 HTML 内容。这表明 Puppeteer 脚本正通过本地代理在准确无误地抓取网页。
所得到的输出结果应与之前的输出结果类似,并且您会在 mitmproxy 窗口中看到记录请求:
…output omitted…
<div class="row">
<div class="col-md-1"></div>
<div class="col-md-10">
<h2>Books</h2>
<p>A <a href="http://books.toscrape.com">fictional bookstore</a> that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: <a href="http://books.toscrape.com">books.toscrape.com</a></p>
<div class="col-md-6">
<a href="http://books.toscrape.com"><img src="./img/books.png" class="img-thumbnail"></a>
</div>
<div class="col-md-6">
<table class="table table-hover">
<tr><th colspan="2">Details</th></tr>
<tr><td>Amount of items </td><td>1000</td></tr>
<tr><td>Pagination </td><td>✔</td></tr>
<tr><td>Items per page </td><td>max 20</td></tr>
<tr><td>Requires JavaScript </td><td>✘</td></tr>
</table>
</div>
</div>
</div>
…output omitted…一个更好的替代:亮数据的代理服务器
如果您想提高网页抓取能力,请考虑使用 Bright Data。Bright Data 的代理服务器为网络请求管理提供高级解决方案。
Bright Data 提供多种代理服务器,例如住宅代理、ISP 代理、数据中心代理和移动代理,让您能够从不同的地理位置访问任何网站。这使您可以模拟不同的用户代理并保持匿名性。
Bright Data 还提供代理轮换功能,通过在不同的代理之间自动进行切换,提高网页抓取活动的效率和隐匿性,防止您的 IP 地址被封锁。
此外,您可以使用 Bright Data 的抓取浏览器,它是一种自动浏览器,内置解锁功能,可解决验证码、Cookie 和浏览器指纹识别等问题。您还可以使用 Bright Data 的网络解锁器,它使用机器学习算法,可以绕过目标网站的任何屏蔽措施,让您在不被封锁的情况下顺利采集数据。
在一个Node.js项目中实施亮数据的代理服务
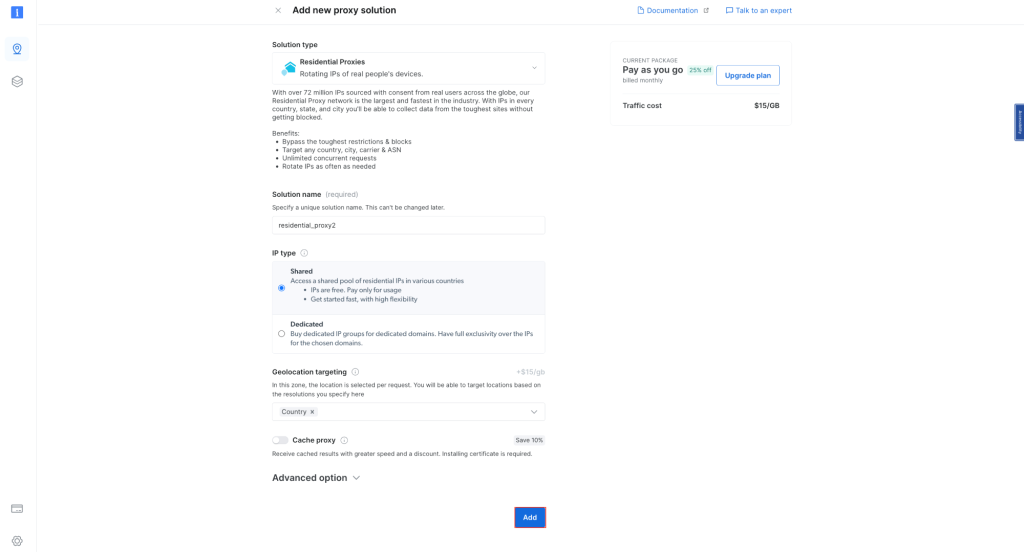
要将 Bright Data 的代理集成到 Node.js 项目中,请先注册账号,获取免费试用服务。激活账户后,请马上登录并进入“代理和抓取基础设施”界面,然后选择“住宅代理”来添加新代理:
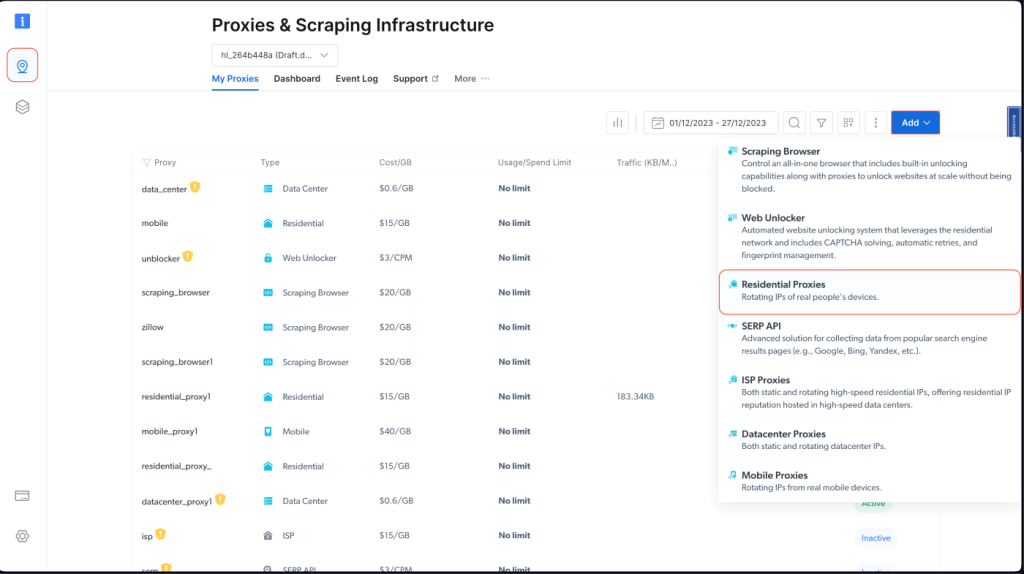
保留默认设置并完成住宅代理的创建:
代理创建完毕后,请记下相关代理凭据,例如主机、端口、用户名和密码。您将在下一步中用到这些凭据:
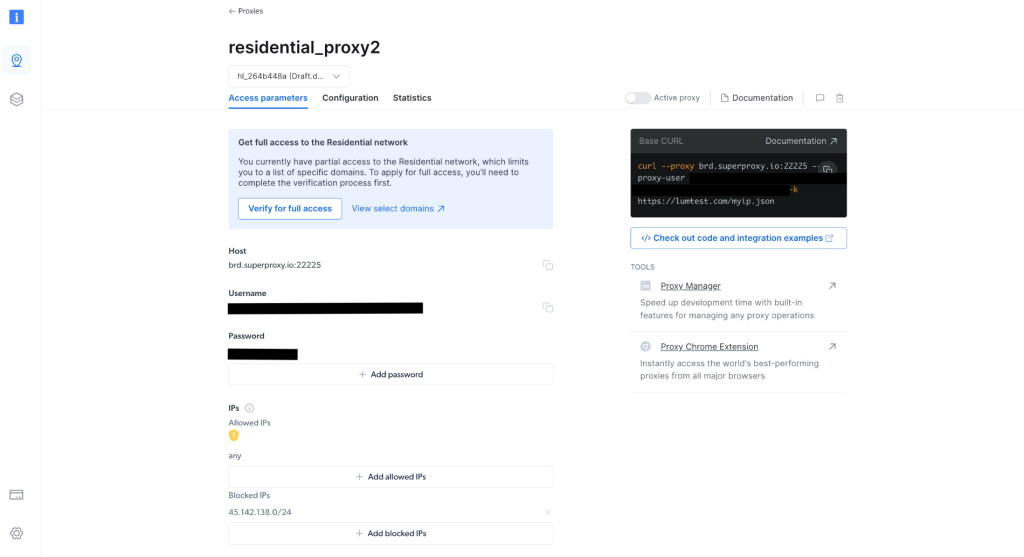
在项目中创建 scrapingWithBrightData.js 文件并添加以下代码片段,请务必要将占位符文本替换为 Bright Data 的代理凭据:
const axios = require('axios');
async function fetchDataWithBrightData(url) {
const proxyOptions = {
proxy: {
host: 'YOUR_BRIGHTDATA_PROXY_HOST',
port: YOUR_BRIGHTDATA_PROXY_PORT,
auth: {
username: 'YOUR_BRIGHTDATA_USERNAME',
password: 'YOUR_BRIGHTDATA_PASSWORD'
}
}
};
try {
const response = await axios.get(url, proxyOptions);
console.log(response.data); // Outputs the fetched data
} catch (error) {
console.error('Error:', error);
}
}
fetchDataWithBrightData('http://lumtest.com/myip.json');此脚本用于配置 axios,以通过 Bright Data 代理路由 HTTP 请求。它使用此代理配置从指定的 URL 获取数据。本示例中的目标 URL 为 http://lumtest.com/myip.json,您可以根据自己的 Bright Data 配置查看不同的代理服务器端源。要执行脚本,请在终端或 shell 中导航到包含 scrapingWithBrightData.js 的文件夹。然后使用以下命令运行脚本:
node scrapingWithBrightData.js 运行命令后,您的 IP 地址的位置就会被输出到控制台,该位置主要与 Bright Data 的代理服务器有关。所得到的输出结果如下所示:
{
ip: '108.53.191.230',
country: 'US',
asn: { asnum: 701, org_name: 'UUNET' },
geo: {
city: 'Jersey City',
region: 'NJ',
region_name: 'New Jersey',
postal_code: '07302',
latitude: 40.7182,
longitude: -74.0476,
tz: 'America/New_York',
lum_city: 'jerseycity',
lum_region: 'nj'
}
}现在,如果您在 Node 中使用 scrapingWithBrightData.js 再次运行脚本,就会发现 Bright Data 代理服务器使用不同的 IP 地址位置。这证实了您每次运行抓取脚本后,Bright Data 都会使用不同的位置和 IP,使您可以绕过目标网站的任何封锁或 IP 禁令。
输出结果应如下所示:
{
ip: '93.85.111.202',
country: 'BY',
asn: {
asnum: 6697,
org_name: 'Republican Unitary Telecommunication Enterprise Beltelecom'
},
geo: {
city: 'Orsha',
region: 'VI',
region_name: 'Vitebsk',
postal_code: '211030',
latitude: 54.5081,
longitude: 30.4172,
tz: 'Europe/Minsk',
lum_city: 'orsha',
lum_region: 'vi'
}
}Bright Data 的界面和设置简单明了,即使是初学者,也能轻松高效地使用其强大的代理管理功能。
结论
在本文中,您学习了如何在 Node.js 中使用代理。如果没有诸如 Bright Data 这样妥善的代理管理解决方案,那就可能遇到 IP 禁令和目标网站限制访问等问题,从而阻碍您的抓取工作。您还了解到使用 Bright Data 代理来提高网页抓取效率是一件非常简单容易的事情。这些服务器不仅让您可以稳定、高效地采集数据,还功能丰富,适用于各种抓取场景。不过,在将这些技能付诸实践时,请务必要在网站条款和数据隐私法规定的范围内采集数据。遵守网站上载明的各项规则,合法抓取数据至关重要。凭借今天学到的知识,再加上 Bright Data 代理的加持,特别是其强大的功能,相信您已准备就绪,可以成功进行合乎道德的网页抓取工作了。祝您抓取顺利!
本教程中的所有代码都可在此 GitHub 存储库中找到。






