沃尔玛是全球营业额和员工人数最多的公司。与主流观点相反的是,沃尔玛不仅仅是一家零售公司。事实上,它是全球最大的电商网站之一,也是产品信息的重要来源。然而,由于产品组合繁多,不可能手动采集这些数据,因此成为了网络抓取的理想用例。
通过网络抓取,您可以快速检索上千种有关沃尔玛产品的数据(例如产品名称、价格、描述、图片和评分),并以您认为有用的任意格式存储数据。抓取沃尔玛数据让您能够监控不同产品的价格和库存水平,分析市场动向和客户行为,并创建不同的应用程序。
在本文中,您将了解两种完全不同来抓取Walmart.com。首先,您将按照分步说明学习如何使用 Python 和Selenium来抓取沃尔玛网页。Selenium 是一种主要用于自动化 Web 应用程序以进行测试的工具。其次,您将学习如何更轻松地使用亮数据Bright Data的沃尔玛爬虫 Walmart Scraper来完成同样的操作。
抓取沃尔玛网页
您可能知道,抓取网站(包括沃尔玛网页)的方式有很多种。其中一种方法需要利用Python和Selenium。
指南:使用 Python 和 Selenium抓取沃尔玛页面
在网络抓取方面,Python 是最流行的编程语言之一。与此同时,尽管Selenium主要用于自动化测试,但它能够自动化web浏览器,因此也可以用于抓取网络。
本质上,Selenium 模拟了 Web 浏览器中的手动操作。使用 Python 和 Selenium,您可以模拟打开 Web 浏览器和任意网页,然后从该特定页面中抓取信息。Selenium通过利用WebDriver来控制 Web 浏览器,实现抓取。
如果您尚未安装 Selenium,您需要安装Selenium库和浏览器驱动程序。 Selenium文档中提供了执行此操作的说明。
由于ChromeDriver大量普及,因此本文也会提到。但无论使用哪种驱动程序,步骤都是相同的。
现在看看如何使用 Python 和 Selenium 执行一些常见的网页抓取任务:
搜索产品
您需要先导入Selenium,再使用它模拟搜索沃尔玛产品。您可以使用以下代码来完成此操作:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service导入 Selenium 后,下一步是使用它打开 Web 浏览器,本文选择Chrome浏览器。不过,您也可以选择喜欢的其他浏览器。浏览器打开后,步骤都是相同的。打开浏览器非常简单,您可以将以下代码作为Python脚本,或是从Jupyter Notebook中运行该代码来完成操作:
s=Service('/path/to/chromedriver')
driver = webdriver.Chrome(service=s)这段简单的代码,唯一的功能就是打开Chrome浏览器。输出内容如下:
现在您已经打开了Chrome浏览器,接下来需要跳转到沃尔玛主页,您可以使用以下代码来完成此操作:
driver.get("https://www.walmart.com")
正如您在屏幕截图中看到的,这一步会打开 Walmart.com。
下一步是使用检查/Inspect工具手动查看页面的源代码。利用该工具,您能够检查网页上的任意具体元素,查看(甚至编辑)各种网页的HTML和CSS。
由于您想要搜索产品,因此需要导航到搜索栏,单击右键,然后点击Inspect。找到type属性为search的input标签。这里需要您将搜索词输入搜索栏。然后,您需要找到name属性并查看其值。在本示例中,您可以看到name属性的值为q:
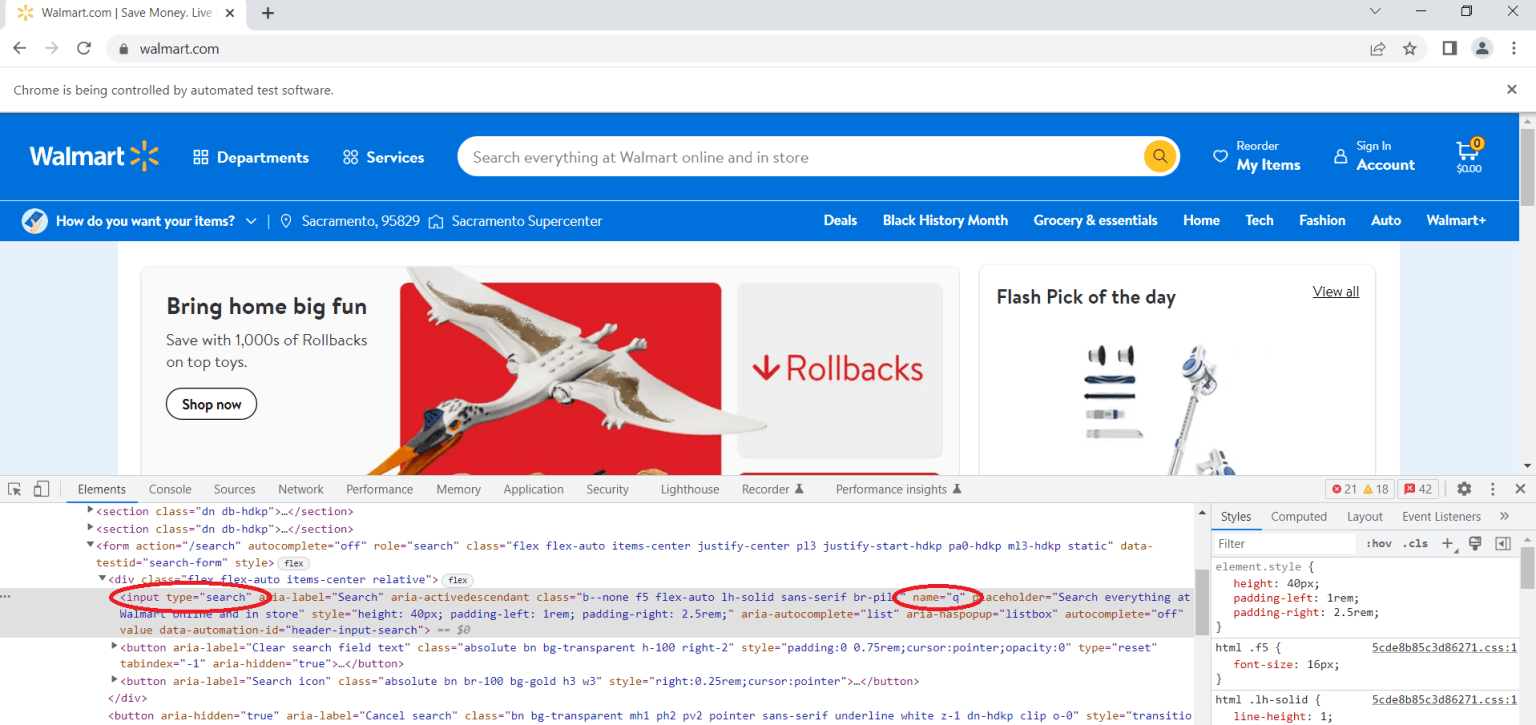
要在搜索栏中输入查询,您可以使用以下代码:
search = driver.find_element("name", "q")
search.send_keys("Gaming Laptops")此代码将输入Gaming Laptops查询,但您可以通过将“Gaming Laptops”术语替换为其他术语来输入您想要的任何短语:
请注意,前面的代码只是将搜索词输入到搜索栏中,并没有进行实际的搜索。要真正搜索该术语,您需要输入以下代码行:
search.send_keys(Keys.ENTER)输出内容如下所示:
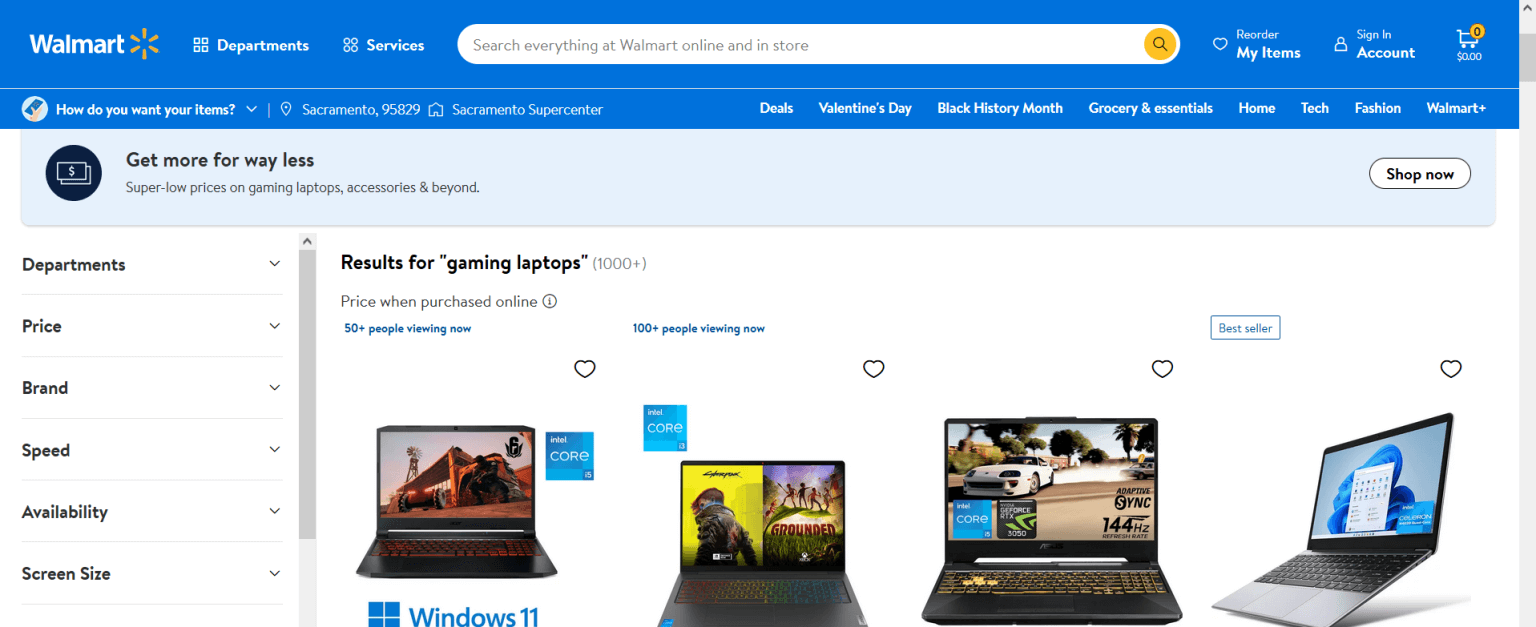
现在,您应该会获得输入搜索词的所有结果。如果您想搜索不同的术语,只需要使用新的搜索术语运行最后两行代码。
导航至产品页面并抓取产品信息
您可以使用 Selenium 执行另一个常见任务:打开特定产品页面并抓取相关信息。例如,您可以抓取产品的名称、详情、价格、评分或评论。
假设您选择了一个想要抓取的产品。首先,您需要打开产品页面,可以使用以下代码来执行操作(假设在第一个示例中您已经安装并导入了Selenium):
url = "https://www.walmart.com/ip/Acer-Nitro-5-15-6-Full-HD-IPS-144Hz-Display-11th-Gen-Intel-Core-i5-11400H-NVIDIA-GeForce-RTX-3050Ti-Laptop-GPU-16GB-DDR4-512GB-NVMe-SSD-Windows-11-Ho/607988022?athbdg=L1101"
driver.get(url)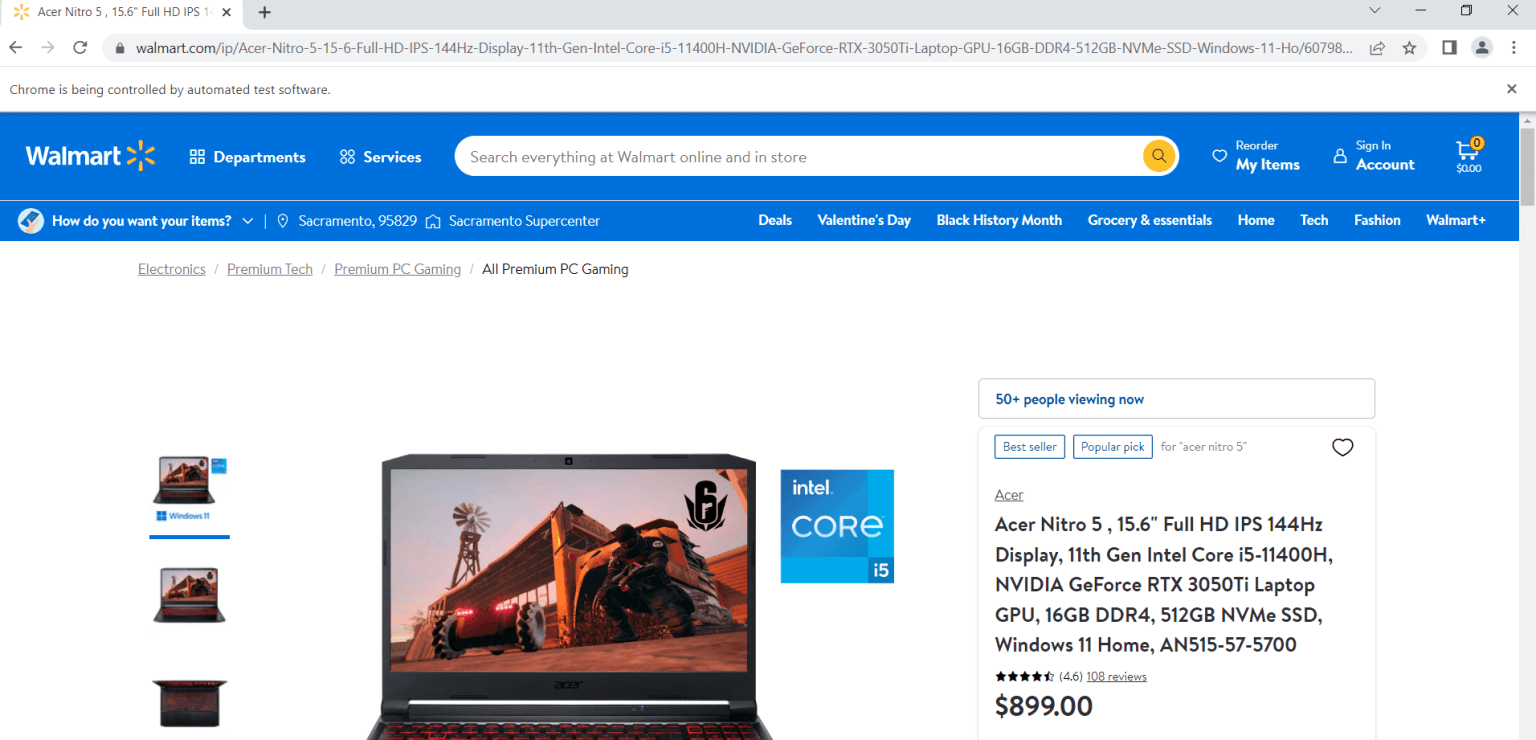
打开产品页面后,您需要使用检查/ Inspect工具。实质上,您需要导航到要抓取信息的元素,右键单击元素,然后单击Inspect 。例如,一旦检查产品名称,您就会注意到该名称位于 H1 标签中。由于这是页面上唯一的 H1 标签,因此您可以通过以下代码获取标签:
title = driver.find_element(By.TAG_NAME, "h1")
print(title.text)
>>>'Acer Nitro 5 , 15.6" Full HD IPS 144Hz Display, 11th Gen Intel Core i5-11400H, NVIDIA GeForce RTX 3050Ti Laptop GPU, 16GB DDR4, 512GB NVMe SSD, Windows 11 Home, AN515-57-5700'您可以通过类似方式找到并抓取产品的价格、评分和评论数量等信息:
price = driver.find_element(By.CSS_SELECTOR, '[itemprop="price"]')
print(price.text)
>>> '$899.00'
rating = driver.find_element(By.CLASS_NAME,"rating-number")
print(rating.text)
>>> '(4.6)'
number_of_reviews = driver.find_element(By.CSS_SELECTOR, '[itemprop="ratingCount"]')
print(number_of_reviews.text)
>>> '108 reviews'请记住:沃尔玛拥有主动反爬取的反垃圾邮件系统,这极大增加了通过上述方式抓取数据的难度。因此,如果您发现网络抓取行为持续受阻,可能不是因为您操作不当,而是因为这种方法无法应对。然而,下一节介绍的解决方案可能会更有效。
分步指南:使用亮数据抓取沃尔玛
如您所见,使用 Python 和 Selenium 抓取沃尔玛数据并不简单。有一种更简单的抓取方法,那就是使用亮数据 Bright Data的Web Scraper IDE 。借助此工具,您不但可以更轻松高效地执行之前展示的任务,而且能够摆脱沃尔玛的网页屏蔽。
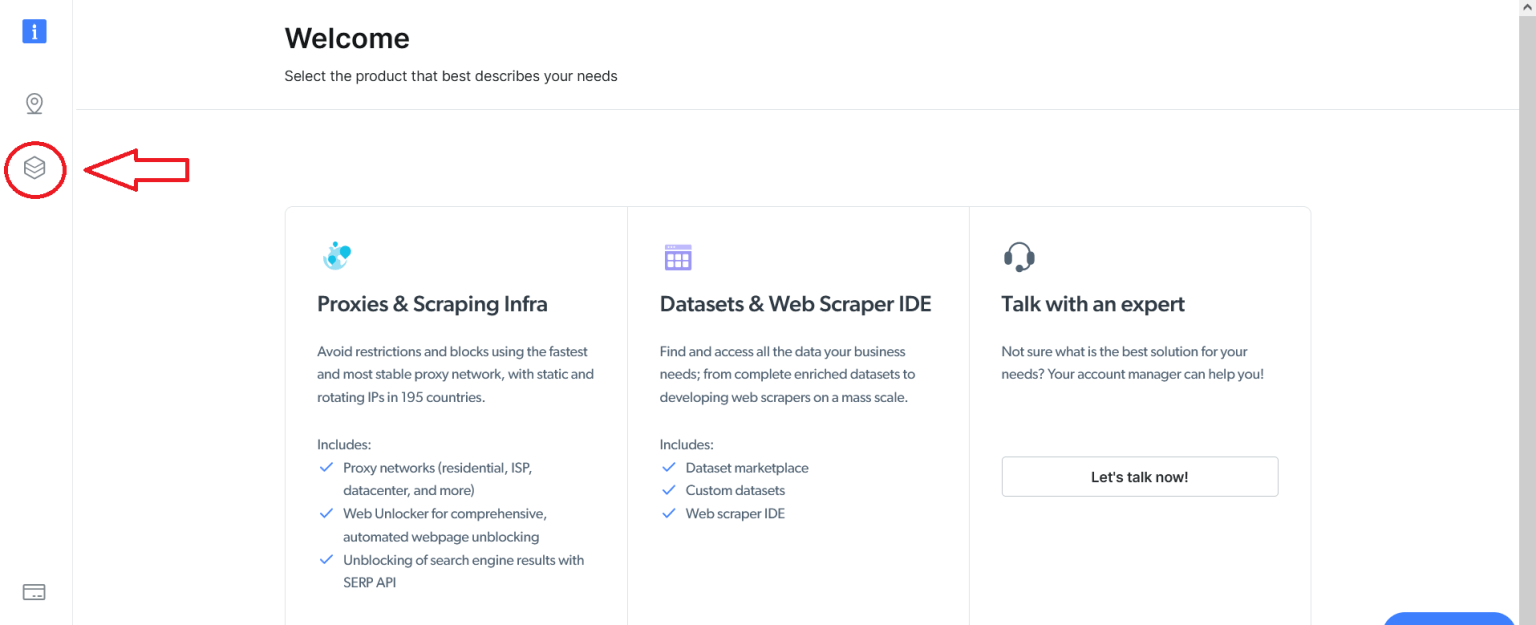
要使用Web Scraper IDE,您需要先注册Bright Data帐户。注册并登录后,您会看到以下页面。单击左侧的Datasets & Web Scraper IDE按钮:
接着,您会进入以下页面。在这里找到“我的爬虫/ My scrapers”字段:
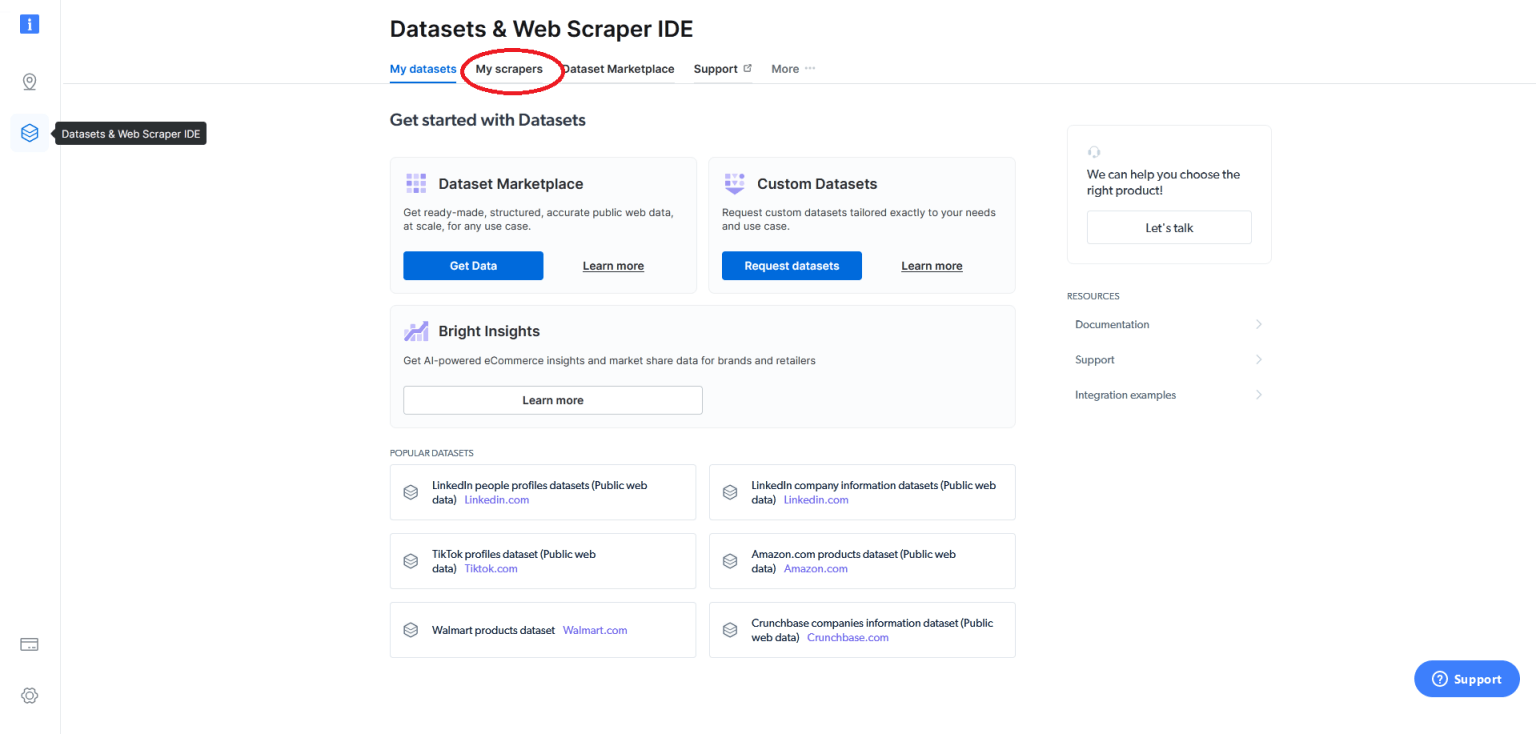
这里会显示您拥有的网络爬虫(如果有),并为您提供选项来开发网络爬虫(IDE)。假设这是您第一次使用Bright Data,也没有任何网络爬虫,您需要单击“开发网络抓取工具/ Develop a web scraper (IDE)” :
您可以选择使用现有模板或从头开始编写代码。要专门抓取 Walmart.com,请单击“从头开始/ Start from scratch” ,这一步会打开亮数据的Web Scraper IDE :
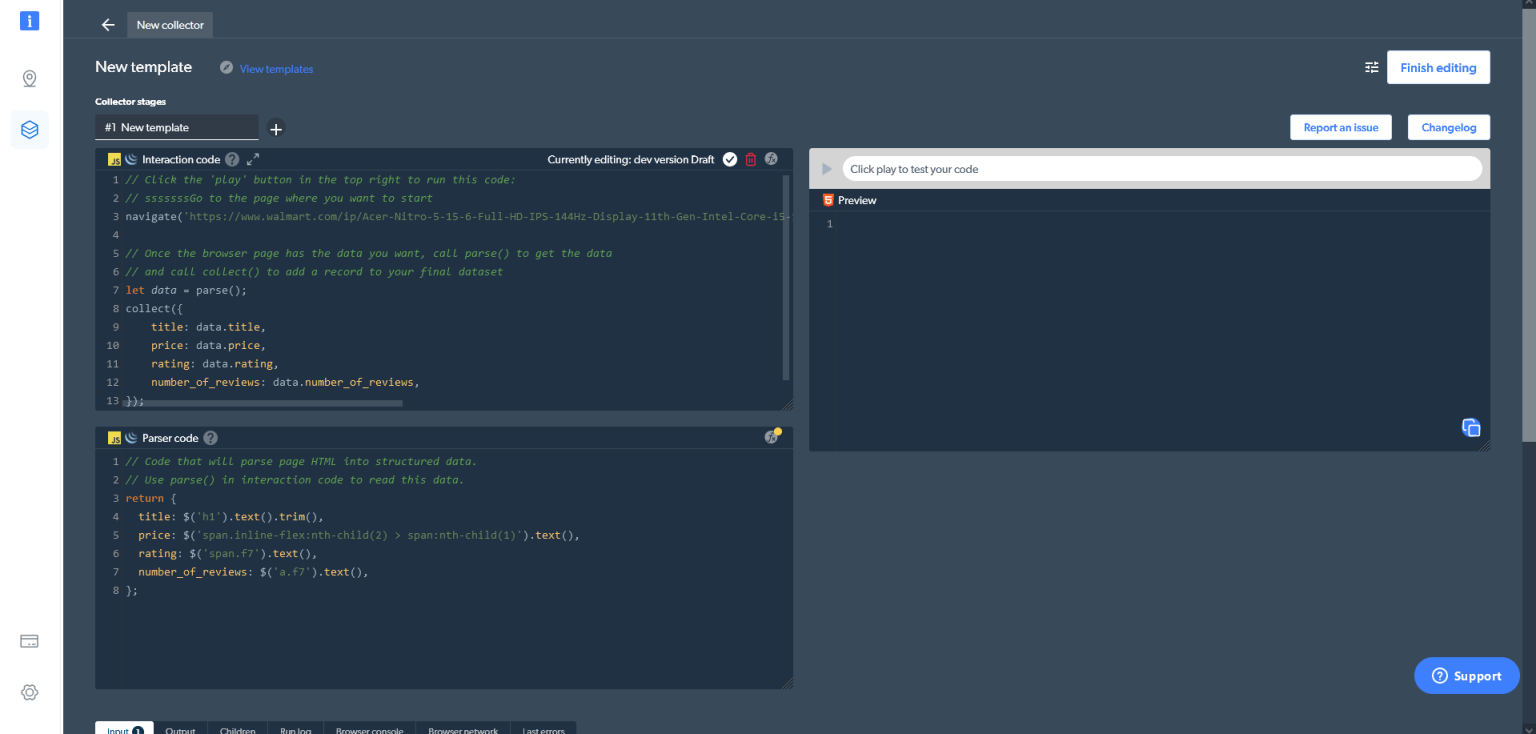
Web Scraper IDE 由几个不同的窗口组成。在左上角,您能找到交互代码/ Interaction code窗口。顾名思义,您可以使用此窗口与网站进行交互,包括在导航和滚动页面、点击按钮等操作。下面是解析器代码/ Parser code窗口,您能够解析与网站交互的 HTML 结果。在右侧,您可以预览和测试您的代码。
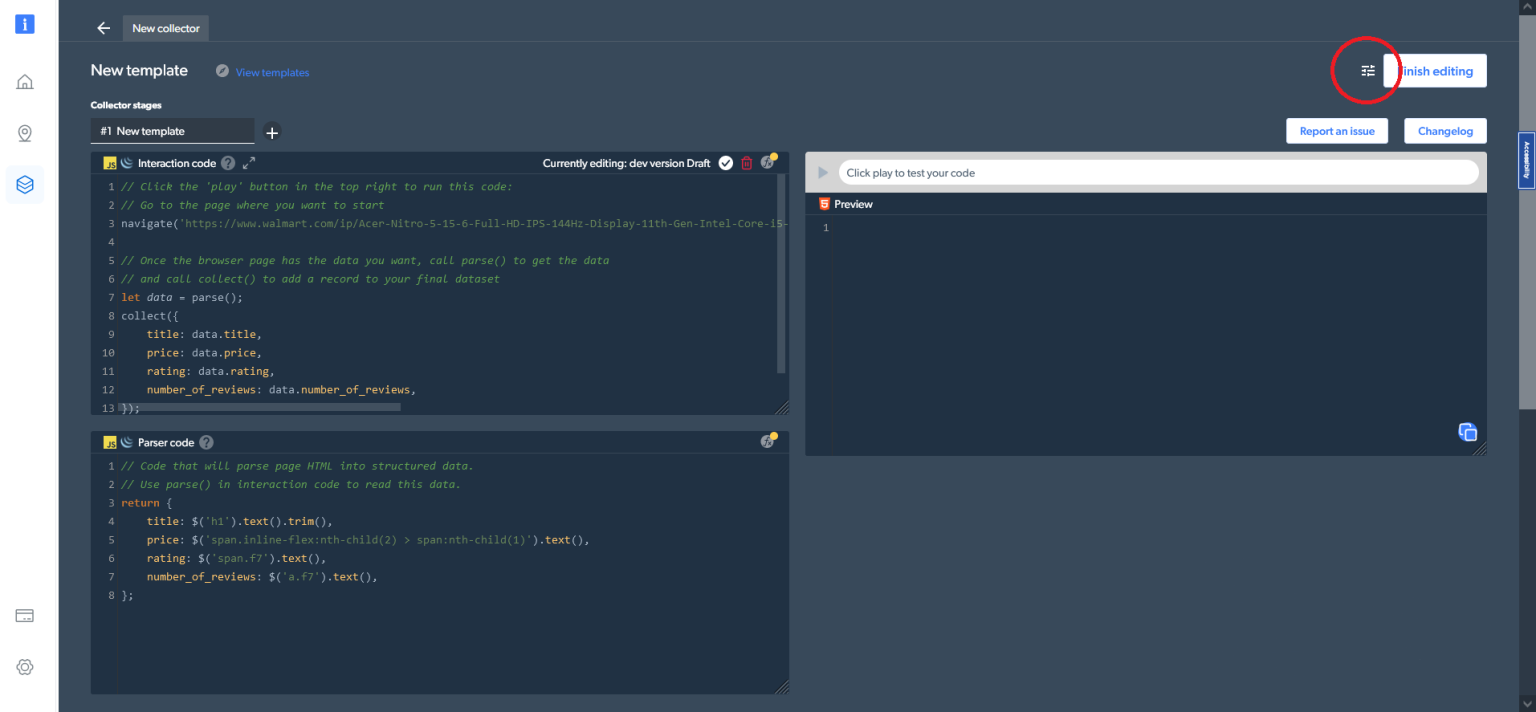
此外,在右上角的代码设置中,您可以切换不同的工作类型。您可以在代码(默认选项)和浏览器工作程序之间切换,来导航和抓取数据:
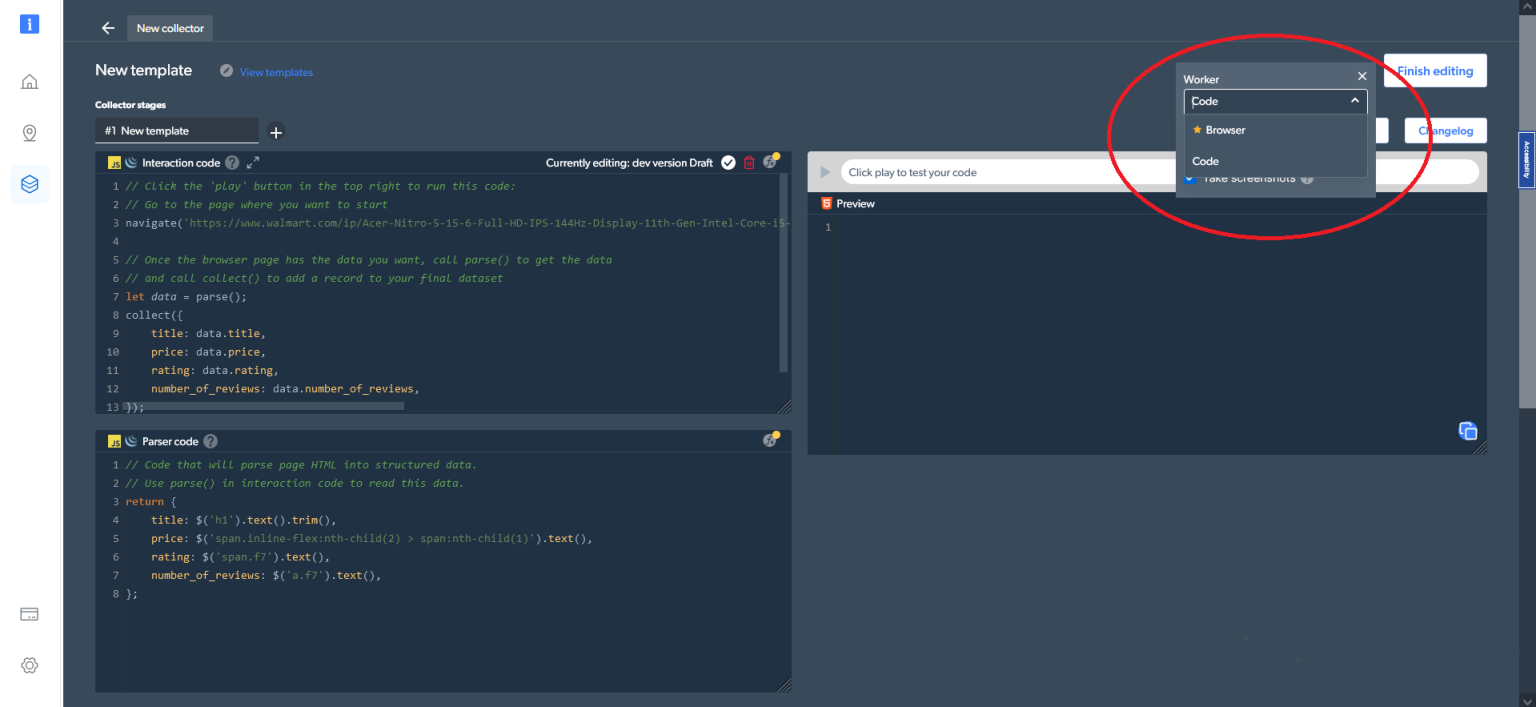
现在看看如何使用Web scraper IDE,像先前使用 Python 和 Selenium 那样来抓取同个产品的相同数据。首先,进入产品页面,您可以在交互代码/ Interaction code窗口中使用以下代码行来执行此操作:
navigate('https://www.walmart.com/ip/Acer-Nitro-5-15-6-Full-HD-IPS-144Hz-Display-11th-Gen-Intel-Core-i5-11400H-NVIDIA-GeForce-RTX-3050Ti-Laptop-GPU-16GB-DDR4-512GB-NVMe-SSD-Windows-11-Ho/607988022?athbdg=L1101');或者,您可以将可变的输入参数与navigator(input.url)一起使用。在这种情况下,请输入您想要抓取的URL,如下所示:
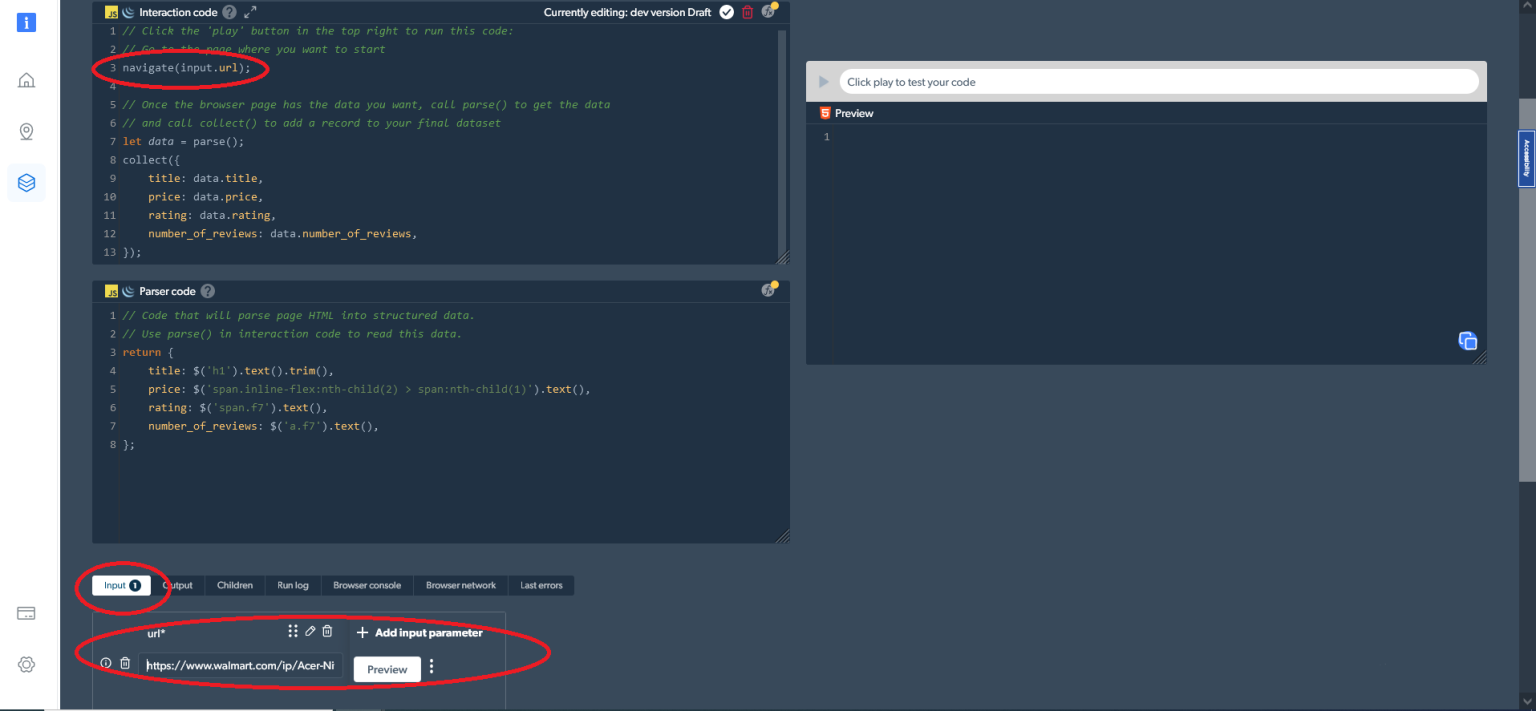
接下来,您需要使用以下代码来采集所需数据:
let data = parse();
collect({
title: data.title,
price: data.price,
rating: data.rating,
number_of_reviews: data.number_of_reviews,
});最后,您需要将 HTML 解析为结构化数据。您可以使用解析器代码/ Parser code窗口中的以下代码来完成此操作:
return {
title: $('h1').text().trim(),
price: $('span.inline-flex:nth-child(2) > span:nth-child(1)').text(),
rating: $('span.f7').text(),
number_of_reviews: $('a.f7').text(),
};然后,您可以在 Web Scraper IDE 中获取想要的数据。只需要点击右侧的运行/ play按钮(或按Ctrl+Enter )输出结果。您还可以直接从 Web Scraper IDE 下载数据:
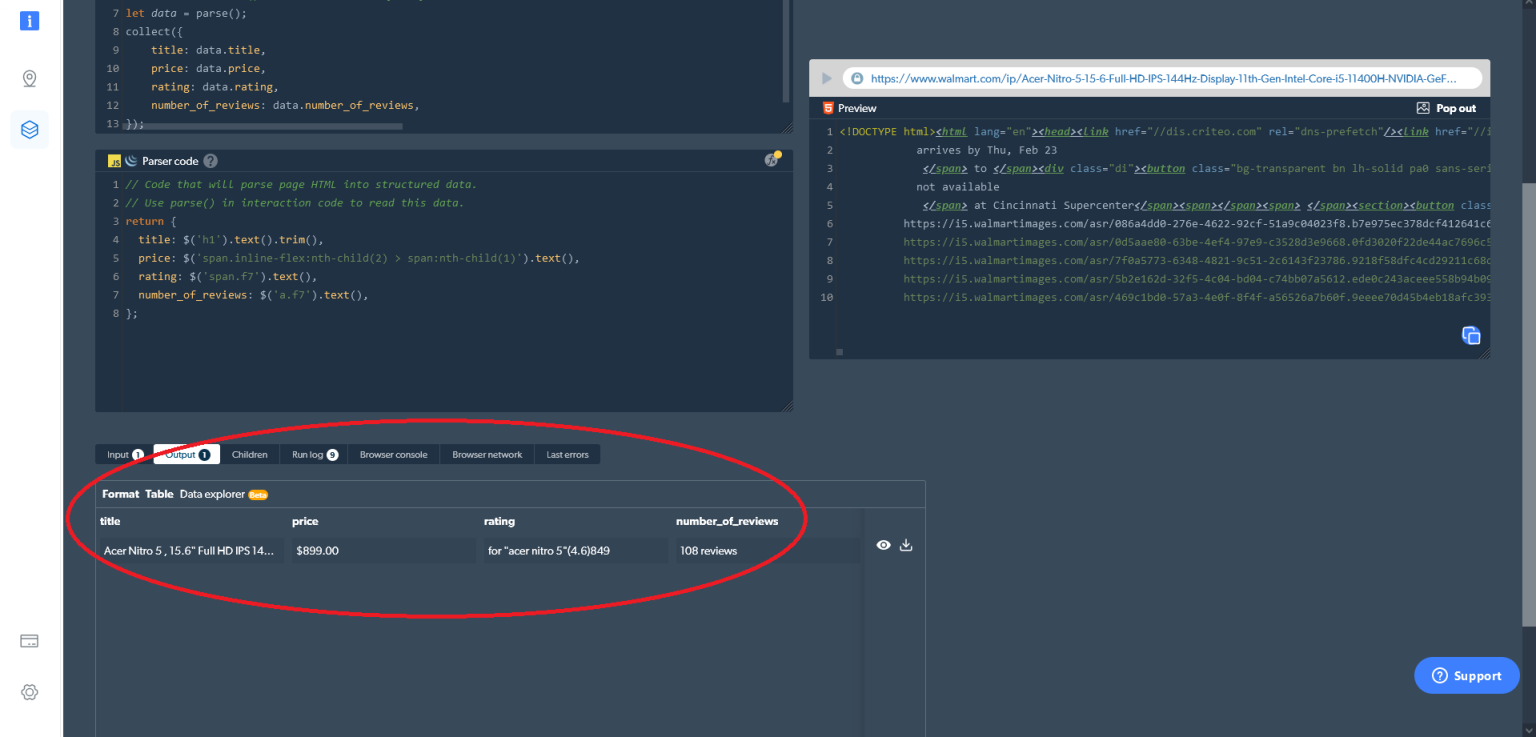
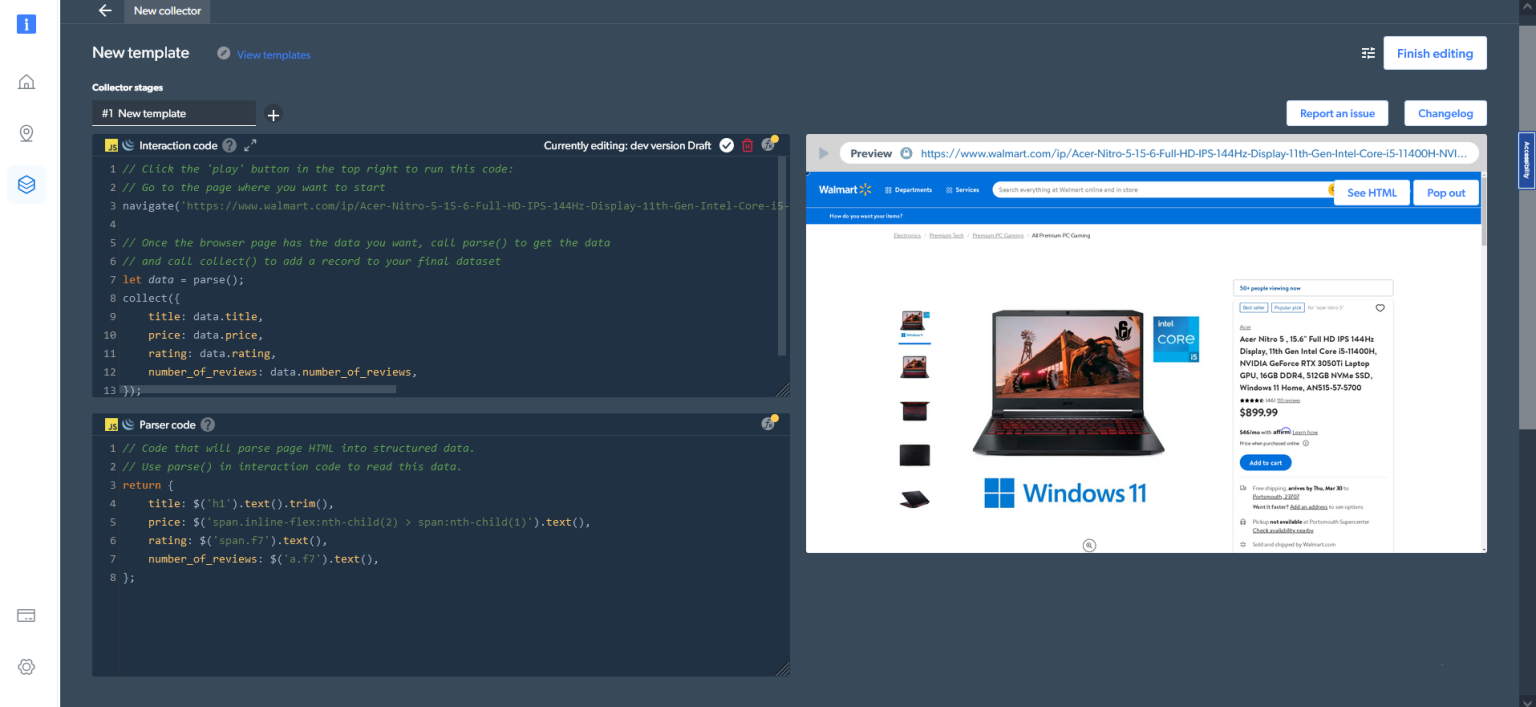
如果您选择“浏览器”而不是“代码”作为工作器类型,则输出如下:
直接从 Web Scraper IDE 获取结果只是您获取数据的一种选择。您还可以在“我的抓爬虫/ My scrapers”仪表板中设置您的交付偏好。
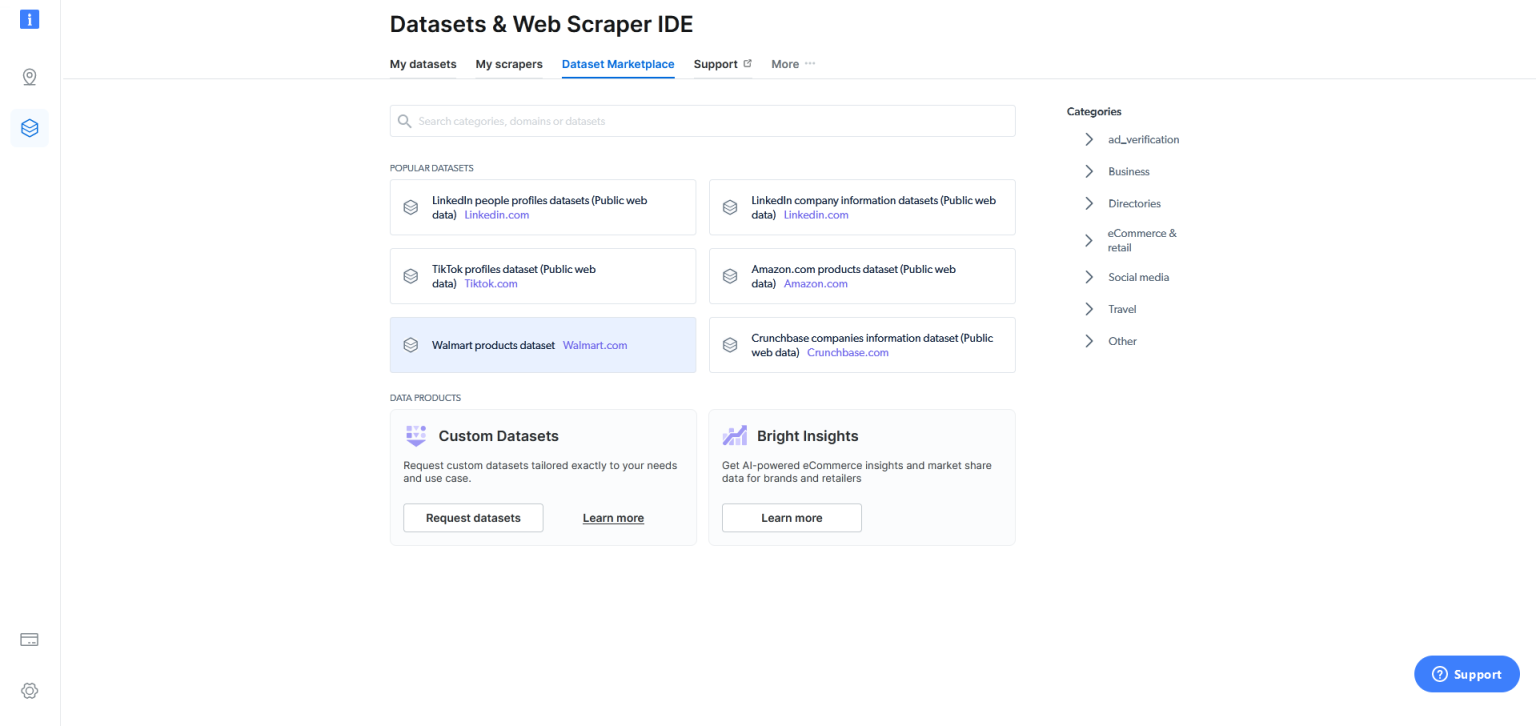
最后,如果使用Web Scraper IDE 抓取数据仍然十分困难,亮数据Bright Data还在Dataset Marketplace/数据集市场中提供了可用的沃尔玛产品数据集,只需轻点按钮即可获得大量数据集:
如图所示,与使用Python 和 Selenium自行构建爬虫相比,使用亮数据的Web Scraper IDE难度更小,也更用户友好。更重要的是,Bright Data Web Scraper IDE 让初学者也能开始从沃尔玛采集数据。相比之下,您需要扎实的编码知识才能使用Python和Selenium爬取沃尔玛网站。
除了易于使用, Bright Data沃尔玛爬虫/Walmart Scraper的可扩展性也令人印象深刻。您可以根据需要抓取任意数量的产品数据,不会遇到任何阻碍。
在网络抓取方面需要注意的关键问题是数据保护隐私法。许多公司会禁止或限制可以从网站抓取的信息。因此,如果您使用 Python 和 Selenium 构建自己的网络爬虫,需要确保不违反任何规定。但是,当您使用 Bright Data Web Scraper IDE 时,亮数据Bright Data会承担这一责任,并确保遵循行业最佳实践和所有数据保护法。
结论
本文讨论了抓取沃尔玛数据的意义,但更重要的是,您实际上了解了如何抓取上千种沃尔玛产品的价格、名称、评论数量和评分等数据。
如上所述,您可以使用Python和Selenium来抓取这些数据;不过这种方法难度很大,并且存在挑战,可能让初学者望而却步。也有一些解决方案可以让您更轻松地抓取沃尔玛数据,例如亮数据的Web Scraper IDE 。它拥有许多热门网站的功能和代码模板,让您能够摆脱验证码,在符合数据保护法的情况下采集数据。


在这个分步骤指南中,你将学习如何使用 Python 和 Selenium 爬取沃尔玛的网站,或者用亮数据的 Web Scraper IDE,一个更简单的解决方案来代替。





