

在本指南中,我们将使用 LlamaIndex的 Bright Data 工具提取数据。完成本教程后,您将能够完成以下所有操作。
- 以 markdown 格式提取网站数据
- 网页截图
- 在应用程序内执行 Google 搜索
- 使用数据源和 Bright Data 的 Web Scraper API 按需触发采集
简介:什么是 LlamaIndex?
在人工智能时代之前,数据收集是一个脆弱且维护成本高的过程。对网站布局的一次改动就可能导致整个流程中断。而在现代,只要使用正确的工具,就不会出现这种情况。
LlamaIndex 可将语言模型连接到外部工具和数据源。它预装了最低限度的模型,可与这些工具集实现最低限度的协同工作。特别是在我们的案例中,LlamaIndex 可以与Bright Data 的 MCP Server 集成。
在接下来的几节中,我们将介绍 LlamaIndex 的 Bright Data 工具集的功能。请确保您已安装 Python。
先决条件
我们在这里的要求出奇地低。对于简单的搜索操作,我们甚至不需要 LLM。您需要 LlamaIndex 和一个 Bright Data API 密钥,仅此而已!
LlamaIndex
LlamaIndex 提供一整套工具,你可以用以下命令安装。如果你只是想搜索网页,这并不是严格要求。
pip install llama-index您可以通过 pip 使用以下命令安装光明数据工具。
pip install llama-index-tools-brightdata亮数据
首先,您需要一个 Bright Data 账户。您可以使用此链接注册免费试用 Unlocker。注册账户后,请保存您的 API 密钥。
您可以在 Bright Data “代理 “面板或用户设置中找到您的 API 密钥。

使用 LlamaIndex 搜索
BrightDataToolSpec:您通往 Bright Data MCP 的桥梁
通过 LlamaIndex,我们可以访问BrightDataToolSpec类。下面的代码段设置了对所有工具的访问。请记住将 API 密钥替换为您自己的密钥,并将区域名称替换为您的个人区域之一。
from llama_index.tools.brightdata import BrightDataToolSpec
brightdata = BrightDataToolSpec(
api_key="your-api-key",
zone="your-zone-name")抓取为 Markdown
下面的代码段将为您设置刮取任何页面并以 markdown 格式返回其内容。scrape_as_markdown()方法将为我们完成这一切。
from llama_index.tools.brightdata import BrightDataToolSpec
brightdata = BrightDataToolSpec(
api_key="your-api-key",
zone="your-zone-name")
result = brightdata.scrape_as_markdown(url="https://www.amazon.com")
print(result.text)下面是该命令的一些输出示例。正如你所看到的,我们成功刮取了亚马逊的数据并将其转换为 markdown。

## Skip to
* [ Main content](#skippedLink)
---
## Keyboard shortcuts
* Search
alt + /
* Cart
shift + alt + C
* Home
shift + alt + H
* Orders
shift + alt + O
* Show/Hide shortcuts
shift + alt + Z
To move between items, use your keyboard's up or down arrows.
[ .us ](/ref=nav%5Flogo)
Delivering to Bothell 98011 Update location
All
Select the department you want to search in All Departments Alexa Skills All The Best Pets Amazon Autos Amazon Devices Amazon Fresh Amazon Global Store Amazon Haul Amazon One Medical Amazon Pharmacy Amazon Resale Appliances Apps & Games Arts, Crafts & Sewing Audible Books & Originals Automotive Parts & Accessories Baby Beauty & Personal Care Books CDs & Vinyl Cell Phones & Accessories Clothing, Shoes & Jewelry Women's Clothing, Shoes & Jewelry Men's Clothing, Shoes & Jewelry Girl's Clothing, Shoes & Jewelry Boy's Clothing, Shoes & Jewelry Baby Clothing, Shoes & Jewelry Collectibles & Fine Art Computers Credit and Payment Cards Digital Music Electronics Garden & Outdoor Gift Cards Grocery & Gourmet Food Handmade Health, Household & Baby Care Home & Business Services Home & Kitchen Industrial & Scientific Just for Prime Kindle Store Luggage & Travel Gear Luxury Stores Magazine Subscriptions Metropolitan Market Movies & TV Musical Instruments Office Products Pet Supplies Premium Beauty Prime Video Same-Day Store Smart Home Software Sports & Outdoors Subscribe & Save Subscription Boxes Tools & Home Improvement Toys & Games Under $10 Video Games Whole Foods Market
Search Amazon
[ EN ](/customer-preferences/edit?ie=UTF8&preferencesReturnUrl=%2F&ref%5F=topnav%5Flang)
[ Hello, sign in Account & Lists ](https://www.amazon.com/ap/signin?openid.pape.max%5Fauth%5Fage=0&openid.return%5Fto=https%3A%2F%2Fwww.amazon.com%2F%3F%5Fencoding%3DUTF8%26ref%5F%3Dnav%5Fya%5Fsignin&openid.identity=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0%2Fidentifier%5Fselect&openid.assoc%5Fhandle=usflex&openid.mode=checkid%5Fsetup&openid.claimed%5Fid=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0%2Fidentifier%5Fselect&openid.ns=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0)
[ Returns & Orders ](/gp/css/order-history?ref%5F=nav%5Forders%5Ffirst) [ 0 Cart ](/gp/cart/view.html?ref%5F=nav%5Fcart)
[ All ](/gp/site-directory?ref%5F=nav%5Fem%5Fjs%5Fdisabled)
* [Amazon Haul](/haul/store?ref%5F=nav%5Fcs%5Fhul%5Fdisb)
* [Medical Care ](https://health.amazon.com/prime?ref%5F=nav%5Fcs%5Fall%5Fhealth%5Fingress%5Fonem%5Fh)
* [Saks](/luxurystores/saks?ref%5F=nav%5Fcs%5Fsaks%5Fdisc)
* [Best Sellers](/gp/bestsellers/?ref%5F=nav%5Fcs%5Fbestsellers)
* [Amazon Basics](/Amazon%5FBasics?channel=discovbar&field-lbr%5Fbrands%5Fbrowse-bin=AmazonBasics&ref%5F=nav%5Fcs%5Famazonbasics)
* [New Releases](/gp/new-releases/?ref%5F=nav%5Fcs%5Fnewreleases)
* [Registry](/gp/browse.html?node=16115931011&ref%5F=nav%5Fcs%5Fregistry)
* [Groceries ](/fmc/learn-more?ref%5F=nav%5Fcs%5Fgroceries)
* [Today's Deals](/deals?ref%5F=nav%5Fcs%5Fgb)
* [Gift Cards ](/gift-cards/b/?ie=UTF8&node=2238192011&ref%5F=nav%5Fcs%5Fgc)
* [Smart Home](/Smart-Home/b/?ie=UTF8&node=6563140011&ref%5F=nav%5Fcs%5Fsmart%5Fhome)
* [Music](/music/player?ref%5F=nav%5Fcs%5Fmusic)
* [Prime ](/prime?ref%5F=nav%5Fcs%5Fprimelink%5Fnonmember)
* [Customer Service](/gp/help/customer/display.html?nodeId=508510&ref%5F=nav%5Fcs%5Ffs%5Fhub%5Fnavbar%5Fc)
* [Books](/books-used-books-textbooks/b/?ie=UTF8&node=283155&ref%5F=nav%5Fcs%5Fbooks)
* [Pharmacy](https://pharmacy.amazon.com/?nodl=0&ref%5F=nav%5Fcs%5Fpharmacy)
* [Luxury Stores](/luxurystores?ref%5F=nav%5Fcs%5Fluxury)
* [Amazon Home](/home-garden-kitchen-furniture-bedding/b/?ie=UTF8&node=1055398&ref%5F=nav%5Fcs%5Fhome)
* [Fashion](/amazon-fashion/b/?ie=UTF8&node=7141123011&ref%5F=nav%5Fcs%5Ffashion)
* [Toys & Games](/toys/b/?ie=UTF8&node=165793011&ref%5F=nav%5Fcs%5Ftoys)
* [Beauty & Personal Care](/Beauty-Makeup-Skin-Hair-Products/b/?ie=UTF8&node=3760911&ref%5F=nav%5Fcs%5Fbeauty)
* [Sell](/b/?%5Fencoding=UTF8&ld=AZUSSOA-sell&node=12766669011&ref%5F=nav%5Fcs%5Fsell)
* [Gift Shop](/gcx/Gifts-for-Everyone/gfhz/?ref%5F=nav%5Fcs%5Fgiftfinder)
* [Automotive](/automotive-auto-truck-replacements-parts/b/?ie=UTF8&node=15684181&ref%5F=nav%5Fcs%5Fautomotive)
* [Home Improvement](/Tools-and-Home-Improvement/b/?ie=UTF8&node=228013&ref%5F=nav%5Fcs%5Fhi)
* [Computers](/computer-pc-hardware-accessories-add-ons/b/?ie=UTF8&node=541966&ref%5F=nav%5Fcs%5Fpc)
* [Sports & Outdoors](/sports-outdoors/b/?ie=UTF8&node=3375251&ref%5F=nav%5Fcs%5Fsports)
[Prime Day is July 8-11](/primeday/?%5Fencoding=UTF8&ref%5F=nav%5Fswm%5FUS%5FPD25%5FLU%5FGW%5FSWM%5FAnnounce&pf%5Frd%5Fp=72020f4f-d636-4d60-9e39-399532eba237&pf%5Frd%5Fs=nav-sitewide-msg-text&pf%5Frd%5Ft=4201&pf%5Frd%5Fi=navbar-4201&pf%5Frd%5Fm=ATVPDKIKX0DER&pf%5Frd%5Fr=JA1EM1AGN54HEE871RFM) 截图
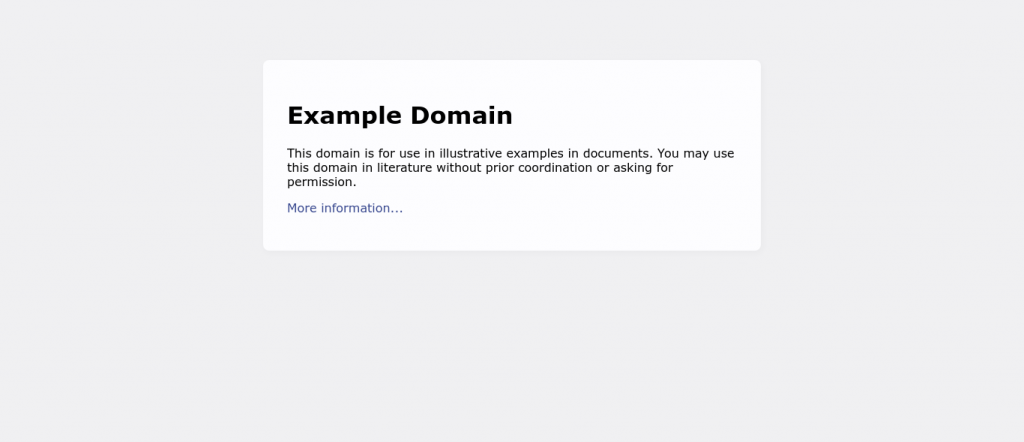
屏幕截图是另一种出色的网络搜索工具。大多数现代 LLM 都能查看和解释图片。在下面的代码段中,我们使用get_screenshot()方法对页面进行截图。
from llama_index.tools.brightdata import BrightDataToolSpec
brightdata = BrightDataToolSpec(
api_key="your-api-key",
zone="your-zone-name")
result = brightdata.get_screenshot(url="https://example.com", output_path="my-screenshot.png")下面的截图来自BrightDataToolSpec。这可能是所有 Python 中最简单的截图方法。
搜索引擎
与前面的工具一样,我们使用一个简单的方法search_engine()来调用搜索引擎。它默认使用谷歌,但也可以使用任何搜索引擎。您可以在此处了解有关 SERP 查询参数的更多信息。
可使用以下搜索引擎。
- 谷歌
- 宾
- Yandex
- DuckDuckGo
from llama_index.tools.brightdata import BrightDataToolSpec
brightdata = BrightDataToolSpec(
api_key="your-api-key",
zone="mcp_unlocker")
result = brightdata.search_engine(
query="Top News Articles"
)
with open("output.json", "w") as file:
json.dump(json.loads(result.json()), file, indent=4)注意我们是如何在将数据转储到 JSON 文件之前调用json.loads() 的。即使使用.json(),LlamaIndex 也会将 JSON 输出为字符串。如果您希望像处理dict 一样处理数据,json.loads()会将其转换为传统的 JSON 对象。
下面是我们的抓取器写入的 JSON 文件的一小部分。
{
"id_": "34bcf1ea-998a-48ce-beb2-0d6feff950e1",
"embedding": null,
"metadata": {
"query": "Top News Articles",
"engine": "google",
"url": "https://www.google.com/search?q=Top%20News%20Articles&num=10"
},
"excluded_embed_metadata_keys": [],
"excluded_llm_metadata_keys": [],
"relationships": {},
"metadata_template": "{key}: {value}",
"metadata_separator": "n",
"text_resource": {
"embeddings": null,
"text": "# Accessibility LinksnnSkip to main content[Accessibility help](https://support.google.com/websearch/answer/181196?hl=en)nnAccessibility feedbacknn[](https://www.google.com/webhp?hl=en&ictx=0&sa=X&ved=0ahUKEwizmMaNvoCOAxUmmYkEHa58MagQpYkNCAo)nnPress / to jump to the search boxnnTop News Articlesnn[Sign in](https://accounts.google.com/ServiceLogin?hl=en&passive=true&continue=https://www.google.com/search%3Fq%3DTop%2BNews%2BArticles%26num%3D10%26oq%3DTop%2BNews%2BArticles%26uule%3Dw%2BCAIQICINVW5pdGVkIFN0YXRlcw%26hl%3Den%26sourceid%3Dchrome%26ie%3DUTF-8&ec=GAZAAQ)nn# Filters and Topicsnn[AI Mode](/search?q=Top+News+Articles&sca%5Fesv=62890ff6c1b2e448&hl=en&udm=50&网络抓取 API
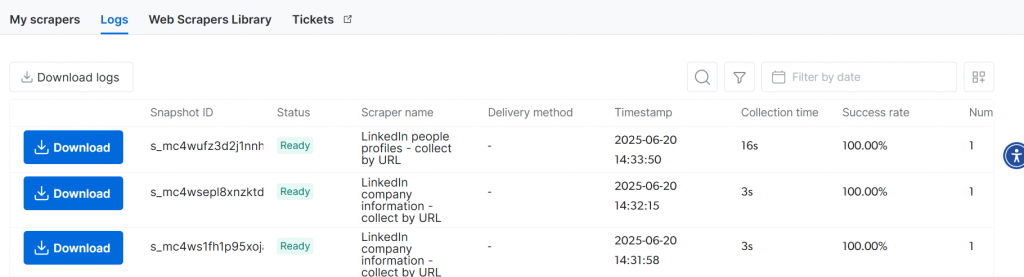
通过Scraping API,您可以创建可按需触发集合的数据源。在下面的代码中,我们使用web_data_feed()从 Scraper API 触发一个集合。
from llama_index.tools.brightdata import BrightDataToolSpec
brightdata = BrightDataToolSpec(
api_key="your-api-key",
zone="mcp_unlocker")
result = brightdata.web_data_feed(
source_type="linkedin_person_profile",
url="https://www.linkedin.com/in/williamhgates/",
timeout=600,
polling_interval=30)
print(result)稍等片刻后,前往日志页面。你会看到所有的收藏都已记录,只需点击按钮即可下载。
结论
现在,你已经提高了网络搜索的水平,大大减少了工作量。有了 LlamaIndex、Bright Data 和几行 Python,你几乎可以从网上获取任何你想要的数据。
无论您是提取标记符、捕获屏幕截图、运行谷歌搜索还是触发完整的搜索任务,LlamaIndex 和 Bright Data 都能让您收获宝贵的数据。
准备好更上一层楼了吗?将这个强大的工具组合接入实时数据管道或构建一个人工智能代理。
立即注册免费试用,提升数据收集水平!



技术写作者
 6 years experience
6 years experience
Jacob Nulty 是一位常驻底特律的软件开发者和技术写作者,探索人工智能与人类哲学,具备 Python、Rust 和区块链方面的经验。



