
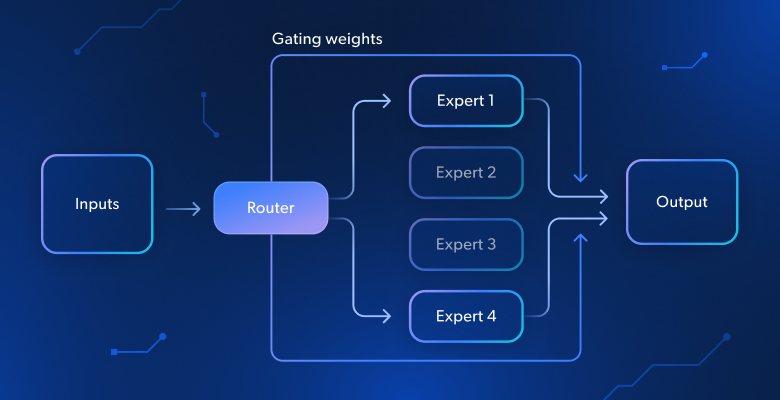
在本指南的 “专家混合物 “中,您将学习到以下内容:
- MoE 是什么,与传统模式有何不同
- 使用它的好处
- 如何实施的分步教程
让我们深入了解一下!
什么是 MoE?
MoE(专家混合物)是一种机器学习架构,它将多个专门的子模型–“专家”–结合到一个更大的系统中。每个专家学习处理任务的不同方面或不同类型的数据。
该架构的一个基本组件是 “门控网络 “或 “路由器”。该组件决定由哪位专家或专家组合来处理特定输入。门控网络还为每位专家的输出分配权重。权重就像分数,因为它们显示了每个专家的结果应具有多大的影响力。
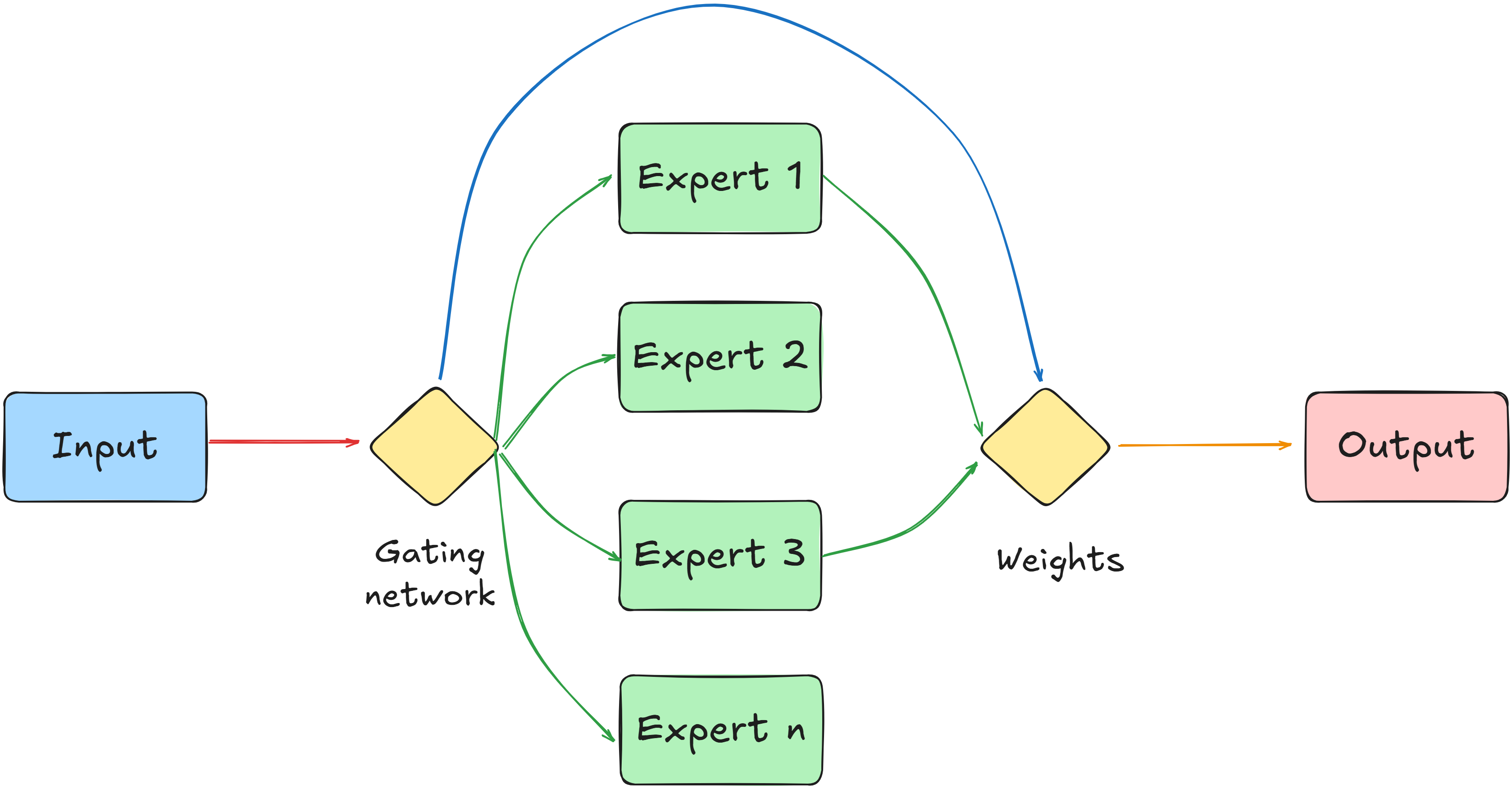
简单来说,门控网络使用权重来调整每位专家对最终答案的贡献。为此,它会考虑输入的具体特征。这样,系统就能比单一模型更好地处理多种类型的数据。
MoE 与传统密集型模型的区别
就神经网络而言,传统密集模型的工作方式与 MoE 不同。对于输入的任何信息,密集模型都会使用其所有内部参数进行计算。因此,每一次输入都会涉及到其计算机制的每一部分。
主要的一点是,在密集模型中,每项任务的所有部分都会参与。这与 MoE 形成鲜明对比,后者只激活相关的专家分区。
以下是 Moe 和 dense 型号的主要区别:
- 参数用法
:Polylang 占位符 不要修改
- 计算成本
:Polylang 占位符不修改
- 专业化和学习:
Polylang 占位符不要修改
专家混合架构的优势
MoE 架构与现代人工智能高度相关,尤其是在处理 LLM 时。原因在于,它提供了一种提高模型容量(即学习和存储信息的能力)的方法,而在使用过程中不会相应增加计算成本。
人工智能中的 MoE 的主要优势包括
- 减少推理延迟:MoE 模型可以减少生成预测或输出所需的时间,即推理延迟。这要归功于它只激活最相关专家的能力。
- 增强训练的可扩展性和效率:在人工智能训练过程中,您可以利用 MoE 架构的并行性。不同的专家可以在不同的数据子集或专门任务上同时接受训练。这可以加快收敛速度和训练时间。
- 提高模型的模块化和可维护性:专家子网络的离散性有利于采用模块化方法进行模型开发和维护。单个专家可以独立更新、重新培训或替换为改进版本,而无需对整个模型进行全面重新培训。这简化了新知识或新能力的整合,并能在特定专家性能下降时进行更有针对性的干预。
- 提高可解释性的潜力:专家的专业化可使人们更清楚地了解模型的决策过程。分析哪些专家在特定输入时会被持续激活,可以提供有关模型如何学会划分问题空间和归因相关性的线索。与单一的密集网络相比,这一特点为更好地理解复杂的模型行为提供了潜在的途径。
- 更高的规模能效:与传统的密集模型相比,基于 MoE 的模型每次查询的能耗更低。这是因为在推理过程中,参数的激活比较稀疏,因为每个输入只使用一小部分可用参数。
如何实施 MoE:分步指南
在本教程中,您将学习如何使用 MoE。特别是,您将使用一个包含体育新闻的数据集。MoE 将根据以下模型利用两位专家:
sshleifer/distilbart-cnn-6-6:用于对每条新闻的内容进行摘要。distilbert-base-uncased-finetuned-sst-2-english:用于分析每条新闻的情感倾向。在情感分析中,“情感(sentiment)” 指文本中表达的情绪基调、观点或态度。分析结果可能包括:- 积极(Positive): 表达赞同、快乐或满意等积极情绪。
- 消极(Negative): 表达不满、悲伤、生气或批评等消极情绪。
- 中性(Neutral): 表达无明显情绪或意见,通常为客观事实。
流程结束时,每个新闻条目都将保存在一个 JSON 文件中,其中包含
- ID、标题和 URL。
- 内容摘要。
- 带有置信度分数的内容情感。
包含新闻的数据集可以通过 Bright Data 的网页抓取器 API 来获取,该API是专门用于实时抓取超过100个网络域名的结构化网页数据的工具。
而包含输入JSON数据的数据集,则可使用我们指南“了解向量数据库:现代AI背后的引擎”中提供的代码生成。具体可参考文中“实际集成:分步指南”章节的步骤1。
输入的 JSON 数据集(称为news-data.js-)包含一个新闻条目数组,如下所示:
[
{
"id": "c787dk9923ro",
"url": "https://www.bbc.com/sport/tennis/articles/c787dk9923ro",
"author": "BBC",
"headline": "Wimbledon plans to increase 'Henman Hill' capacity and accessibility",
"topics": [
"Tennis"
],
"publication_date": "2026-04-03T11:28:36.326Z",
"content": "Wimbledon is planning to renovate its iconic 'Henman Hill' and increase capacity for the tournament's 150th anniversary. Thousands of fans have watched action on a big screen from the grass slope which is open to supporters without show-court tickets. The proposed revamp - which has not yet been approved - would increase the hill's capacity by 20% in time for the 2027 event and increase accessibility. It is the latest change planned for the All England Club, after a 39-court expansion was approved last year. Advertisement "It's all about enhancing this whole area, obviously it's become extremely popular but accessibility is difficult for everyone," said four-time Wimbledon semi-finalist Tim Henman, after whom the hill was named. "We are always looking to enhance wherever we are on the estate. This is going to be an exciting project."",
"videos": [],
"images": [
{
"image_url": "https://ichef.bbci.co.uk/ace/branded_sport/1200/cpsprodpb/31f9/live/0f5b2090-106f-11f0-b72e-6314f702e779.jpg",
"image_description": "Main image"
},
{
"image_url": "https://ichef.bbci.co.uk/ace/standard/2560/cpsprodpb/31f9/live/0f5b2090-106f-11f0-b72e-6314f702e779.jpg",
"image_description": "A render of planned improvements to Wimbledon's Henman Hill"
}
],
"related_articles": [
{
"article_title": "Live scores, results and order of playLive scores, results and order of play",
"article_url": "https://www.bbc.com/sport/tennis/scores-and-schedule"
},
{
"article_title": "Get tennis news sent straight to your phoneGet tennis news sent straight to your phone",
"article_url": "https://www.bbc.com/sport/articles/cl5q9dk9jl3o"
}
],
"keyword": null,
"timestamp": "2026-05-19T15:03:16.568Z",
"input": {
"url": "https://www.bbc.com/sport/tennis/articles/c787dk9923ro",
"keyword": ""
}
},
// omitted for brevity...
]按照下面的说明,创建你的模拟引擎示例!
先决条件和依赖性
要复制本教程,您的计算机必须安装Python 3.10.1 或更高版本。
假设您将项目的主文件夹命名为moe_project/。该步骤结束后,文件夹的结构如下:
moe_project/
├── venv/
├── news-data.json
└── moe_analysis.py在哪里?
venv/包含 Python 虚拟环境。news-data.json是输入 JSON 文件,其中包含您使用 Web Scraper API 抓取的新闻数据。moe_analysis.py是包含编码逻辑的 Python 文件。
您可以像这样创建venv/ 虚拟环境目录:
python -m venv venv要激活它,在 Windows 上运行
venvScriptsactivate同样,在 macOS 和 Linux 上,执行
source venv/bin/activate在激活的虚拟环境中,用以下命令安装依赖项:
pip install transformers torch这些图书馆是
transformers:Hugging Face 的最先进机器学习模型库。火炬PyTorch 是一个开源机器学习框架。
步骤 #1:设置和配置
通过导入所需的库和设置一些常量来初始化moe_analysis.py文件:
import json
from transformers import pipeline
# Define the input JSON file
JSON_FILE = "news-data.json"
# Specify the model for generating summaries
SUMMARIZATION_MODEL = "sshleifer/distilbart-cnn-6-6"
# Specify the model for analyzing sentiment
SENTIMENT_MODEL = "distilbert-base-uncased-finetuned-sst-2-english"该代码定义
- 输入 JSON 文件的名称,其中包含抓取到的新闻。
- 专家使用的模型。
完美!你已经具备了用 Python 开始学习 MoE 的条件。
步骤 #2:定义新闻摘要专家
这一步包括创建一个类,封装专家总结新闻的功能:
class NewsSummarizationLLMExpert:
def __init__(self, model_name=SUMMARIZATION_MODEL):
self.model_name = model_name
self.summarizer = None
# Initialize the summarization pipeline
self.summarizer = pipeline(
"summarization",
model=self.model_name,
tokenizer=self.model_name,
)
def analyze(self, article_content, article_headline=""):
# Call the summarizer pipeline with the article content
summary_outputs = self.summarizer(
article_content,
max_length=300,
min_length=30,
do_sample=False
)
# Extract the summary text from the pipeline's output
summary = summary_outputs[0]["summary_text"]
return { "summary": summary }上述代码
- 使用 Hugging Face 中的
pipeline()方法初始化摘要管道。 - 定义摘要专家使用
analyze()方法处理文章的方式。
很好!您刚刚在 MoE 架构中创建了第一个专家,负责汇总新闻。
步骤 #3:定义情感分析专家
与摘要专家类似,定义一个专门用于对新闻进行情感分析的类:
class SentimentAnalysisLLMExpert:
def __init__(self, model_name=SENTIMENT_MODEL):
self.model_name = model_name
self.sentiment_analyzer = None
# Initialize the sentiment analysis pipeline
self.sentiment_analyzer = pipeline(
"sentiment-analysis",
model=self.model_name,
tokenizer=self.model_name,
)
def analyze(self, article_content, article_headline=""):
# Define max tokens
max_chars_for_sentiment = 2000
# Truncate the content if it exceeds the maximum limit
truncated_content = article_content[:max_chars_for_sentiment]
# Call the sentiment analyzer pipeline
sentiment_outputs = self.sentiment_analyzer(truncated_content)
# Extract the sentiment label
label = sentiment_outputs[0]["label"]
# Extract the sentiment score
score = sentiment_outputs[0]["score"]
return { "sentiment_label": label, "sentiment_score": score }这个片段
- 使用
pipeline()方法初始化情感分析管道。 - 定义用于执行情感分析的
analyze()方法。它还会返回情感标签(负面或正面)和置信度得分。
很好!您现在又多了一位计算和表达新闻文本情感的专家。
步骤 #4:实施门控网络
现在,您必须定义门控网络背后的逻辑,以确定专家的路由:
def route_to_experts(item_data, experts_registry):
chosen_experts = []
# Select the summarizer and sentiment analyzer
chosen_experts.append(experts_registry["summarizer"])
chosen_experts.append(experts_registry["sentiment_analyzer"])
return chosen_experts在此实施过程中,门控网络非常简单。它总是对每个新闻项目同时使用两位专家,但会按顺序使用:
- 它总结了全文。
- 它可以计算情绪。
注:本例中的门控网络非常简单。与此同时,如果您想使用一个更大的模型来实现同样的目标,所需的计算量将大大增加。相比之下,两位专家只在与他们相关的任务中发挥作用。这使得专家混合架构的应用简单而有效。
在其他情况下,可以通过训练 ML 模型来学习如何以及何时激活特定专家,从而改进这部分流程。这样,门控网络就能做出动态响应。
太棒了门控网络逻辑已经设置完毕,随时可以运行。
步骤 #5:处理新闻数据的主要协调逻辑
定义管理以下任务所定义的整个工作流程的核心功能:
- 加载 JSON 数据集。
- 初始化两位专家。
- 遍历新闻项目。
- 将其转给选定的专家。
- 收集结果。
您可以用以下代码来实现:
def process_news_json_with_moe(json_filepath):
# Open and load news items from the JSON file
with open(json_filepath, "r", encoding="utf-8") as f:
news_items = json.load(f)
# Create a dictionary to hold instances of expert classes
experts_registry = {
"summarizer": NewsSummarizationLLMExpert(),
"sentiment_analyzer": SentimentAnalysisLLMExpert()
}
# List to store the analysis results
all_results = []
# Iterate through each news item in the loaded data
for i, news_item in enumerate(news_items):
print(f"n--- Processing Article {i+1}/{len(news_items)} ---")
# Extract relevant data from the news item
id = news_item.get("id")
headline = news_item.get("headline")
content = news_item.get("content")
url = news_item.get("url")
# Print progress
print(f"ID: {id}, Headline: {headline[:70]}...")
# Use the gating network to determine the expert to use
active_experts = route_to_experts(news_item, experts_registry)
# Prepare a dictionary to store the analysis results
news_item_analysis_results = {
"id": id,
"headline": headline,
"url": url,
"analyses": {}
}
# Iterate through the experts and apply their analysis
for expert_instance in active_experts:
expert_name = expert_instance.__class__.__name__ # Get the class name of the expert
try:
# Call the expert's analyze method
analysis_result = expert_instance.analyze(article_content=content, article_headline=headline)
# Store the result under the expert's name
news_item_analysis_results["analyses"][expert_name] = analysis_result
except Exception as e:
# Handle any errors during analysis by a specific expert
print(f"Error during analysis with {expert_name}: {e}")
news_item_analysis_results["analyses"][expert_name] = { "error": str(e) }
# Add the current item's results to the overall list
all_results.append(news_item_analysis_results)
return all_results在这个片段中
for循环遍历所有加载的新闻。try-except块执行分析并处理可能出现的错误。在本例中,可能出现的错误主要是由前面函数中定义的参数max_length和max_chars_for_sentiment引起的。由于并非所有检索到的内容都具有相同的长度,因此错误管理是有效处理异常的基础。
我们开始吧!你定义了整个流程的协调功能。
步骤 #6:启动处理功能
作为脚本的最后一部分,您必须执行主处理函数,然后将分析结果保存到输出 JSON 文件中,如下所示:
# Call the main processing function with the input JSON file
final_analyses = process_news_json_with_moe(JSON_FILE)
print("nn--- MoE Analysis Complete ---")
# Write the final analysis results to a new JSON file
with open("analyzed_news_data.json", "w", encoding="utf-8") as f_out:
json.dump(final_analyses, f_out, indent=4, ensure_ascii=False)在上述代码中
final_analyses变量调用 MoE 处理数据的函数。- 分析数据存储在
analyzed_news_data.json输出文件中。
就是这样!整个脚本就完成了,数据也得到了分析和保存。
步骤 #7:组合并运行代码
下面是moe_analysis.py文件现在应该包含的内容:
import json
from transformers import pipeline
# Define the input JSON file
JSON_FILE = "news-data.json"
# Specify the model for generating summaries
SUMMARIZATION_MODEL = "sshleifer/distilbart-cnn-6-6"
# Specify the model for analyzing sentiment
SENTIMENT_MODEL = "distilbert-base-uncased-finetuned-sst-2-english"
# Define a class representing an expert for news summarization
class NewsSummarizationLLMExpert:
def __init__(self, model_name=SUMMARIZATION_MODEL):
self.model_name = model_name
self.summarizer = None
# Initialize the summarization pipeline
self.summarizer = pipeline(
"summarization",
model=self.model_name,
tokenizer=self.model_name,
)
def analyze(self, article_content, article_headline=""):
# Call the summarizer pipeline with the article content
summary_outputs = self.summarizer(
article_content,
max_length=300,
min_length=30,
do_sample=False
)
# Extract the summary text from the pipeline's output
summary = summary_outputs[0]["summary_text"]
return { "summary": summary }
# Define a class representing an expert for sentiment analysis
class SentimentAnalysisLLMExpert:
def __init__(self, model_name=SENTIMENT_MODEL):
self.model_name = model_name
self.sentiment_analyzer = None
# Initialize the sentiment analysis pipeline
self.sentiment_analyzer = pipeline(
"sentiment-analysis",
model=self.model_name,
tokenizer=self.model_name,
)
def analyze(self, article_content, article_headline=""):
# Define max tokens
max_chars_for_sentiment = 2000
# Truncate the content if it exceeds the maximum limit
truncated_content = article_content[:max_chars_for_sentiment]
# Call the sentiment analyzer pipeline
sentiment_outputs = self.sentiment_analyzer(truncated_content)
# Extract the sentiment label
label = sentiment_outputs[0]["label"]
# Extract the sentiment score
score = sentiment_outputs[0]["score"]
return { "sentiment_label": label, "sentiment_score": score }
# Define a gating network
def route_to_experts(item_data, experts_registry):
chosen_experts = []
# Select the summarizer and sentiment analyzer
chosen_experts.append(experts_registry["summarizer"])
chosen_experts.append(experts_registry["sentiment_analyzer"])
return chosen_experts
# Main function to manage the orchestration process
def process_news_json_with_moe(json_filepath):
# Open and load news items from the JSON file
with open(json_filepath, "r", encoding="utf-8") as f:
news_items = json.load(f)
# Create a dictionary to hold instances of expert classes
experts_registry = {
"summarizer": NewsSummarizationLLMExpert(),
"sentiment_analyzer": SentimentAnalysisLLMExpert()
}
# List to store the analysis results
all_results = []
# Iterate through each news item in the loaded data
for i, news_item in enumerate(news_items):
print(f"n--- Processing Article {i+1}/{len(news_items)} ---")
# Extract relevant data from the news item
id = news_item.get("id")
headline = news_item.get("headline")
content = news_item.get("content")
url = news_item.get("url")
# Print progress
print(f"ID: {id}, Headline: {headline[:70]}...")
# Use the gating network to determine the expert to use
active_experts = route_to_experts(news_item, experts_registry)
# Prepare a dictionary to store the analysis results
news_item_analysis_results = {
"id": id,
"headline": headline,
"url": url,
"analyses": {}
}
# Iterate through the experts and apply their analysis
for expert_instance in active_experts:
expert_name = expert_instance.__class__.__name__ # Get the class name of the expert
try:
# Call the expert's analyze method
analysis_result = expert_instance.analyze(article_content=content, article_headline=headline)
# Store the result under the expert's name
news_item_analysis_results["analyses"][expert_name] = analysis_result
except Exception as e:
# Handle any errors during analysis by a specific expert
print(f"Error during analysis with {expert_name}: {e}")
news_item_analysis_results["analyses"][expert_name] = { "error": str(e) }
# Add the current item's results to the overall list
all_results.append(news_item_analysis_results)
return all_results
# Call the main processing function with the input JSON file
final_analyses = process_news_json_with_moe(JSON_FILE)
print("nn--- MoE Analysis Complete ---")
# Write the final analysis results to a new JSON file
with open("analyzed_news_data.json", "w", encoding="utf-8") as f_out:
json.dump(final_analyses, f_out, indent=4, ensure_ascii=False)太棒了!仅用大约 130 行代码,您就完成了第一个 MoE 项目。
使用以下命令运行代码
python moe_analysis.py终端输出应包括
# Omitted for brevity...
--- Processing Article 6/10 ---
ID: cdrgdm4ye53o, Headline: Japanese Grand Prix: Lewis Hamilton says he has 'absolute 100% faith' ...
--- Processing Article 7/10 ---
ID: czed4jk7eeeo, Headline: F1 engines: A return to V10 or hybrid - what's the future?...
Error during analysis with NewsSummarizationLLMExpert: index out of range in self
--- Processing Article 8/10 ---
ID: cy700xne614o, Headline: Monte Carlo Masters: Novak Djokovic beaten as wait for 100th title con...
Error during analysis with NewsSummarizationLLMExpert: index out of range in self
# Omitted for brevity...
--- MoE Analysis Complete ---执行完成后,项目文件夹中将出现analyzed_news_data.json 输出文件。打开该文件,将注意力集中在其中一个新闻条目上。分析字段将包含两位专家得出的摘要和情感分析结果:
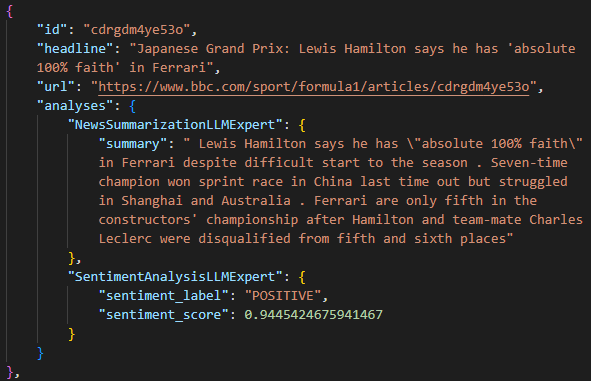
正如您所看到的那样,教育部的方法具有以下特点:
- 总结文章内容,并在
摘要下进行报告。 - 定义为积极情绪,置信度为 0.99。
任务完成
结论
在本文中,您将了解 MoE 以及如何在实际场景中逐步实施 MoE。
如果您想探索更多的 MoE 场景,并且需要一些新数据,Bright Data 可提供一套强大的工具和服务,用于从网页中检索最新的实时数据,同时克服抓取障碍。
这些解决方案包括
- 网页解锁器:该应用程序接口可绕过反抓取保护,以最小的代价从任何网页中获取干净的 HTML。
- 扫描浏览器:基于云的可控浏览器,具有 JavaScript 渲染功能。它能自动处理验证码、浏览器指纹、重试等。
- 网络抓取 API:用于以编程方式访问数十个常用域的结构化网络数据的端点。
如需了解其他机器学习应用场景,请访问我们的人工智能中心。
立即注册 Bright Data 并开始免费试用,测试我们的搜索解决方案!



技术写作者
 3 years experience
3 years experience
Federico Trotta 是一名技术写作者、编辑和数据科学家。擅长技术内容管理、数据分析、机器学习和 Python 开发。





