

在本文中,你将了解:
- 什么是 Microsoft TaskWeaver,以及它的独特之处。
- 为什么通过 Bright Data 服务扩展 TaskWeaver 可以帮助你突破大语言模型的局限。
- 如何通过自定义插件将 Bright Data 集成到 TaskWeaver 中。
让我们开始吧!
什么是 Microsoft TaskWeaver?
Microsoft TaskWeaver 是一个开源、代码优先的智能体框架,它可以将自然语言请求转化为可执行的 Python 代码。它的最终目标是为能够自主规划和执行复杂任务的 AI 智能体提供支撑。
该技术的工作方式是接收你的提示词,然后将其拆分为可执行步骤。接着,它会选择合适的插件来实现目标,生成用于执行计划的 Python 代码,在安全环境中运行代码,并返回结果。
TaskWeaver 是开源的,并在 GitHub 上获得了 6000 多个 Star。它的一些核心特性包括:
- 代码优先方法:将用户请求转换为 Python 代码,使智能体能够直接生成并执行解决方案。
- 插件生态:通过插件支持各类专业任务,使框架具有高度可扩展性。
- 丰富的数据处理能力:可原生处理 Python 数据结构,如 DataFrame,为高级数据分析铺平道路。
- 领域自适应:可集成特定领域知识,从而产出更精准的结果。
- 有状态且可反思的执行:可以维护上下文,并对自身代码执行情况进行反思和自我纠错。
- 安全且开源:在安全环境中运行代码,同时提供开源、即开即用的体验。
更多信息请参阅官方文档。
为什么要为 TaskWeaver 增加网页数据获取能力
大语言模型(LLM)本质上受其训练数据的限制。它们虽能生成文本、代码或多媒体内容,但输出始终基于过期的已有知识。此外,它们无法像人类用户那样与在线网页进行实时交互。这两点是当前 AI 模型的主要限制。
TaskWeaver 通过支持智能体集成自定义插件,帮助克服这些限制。你可以将插件理解为 LLM 可调用的专业工具,用于执行超出其内置能力范围的任务,从而有效扩展其适用范围与实际价值。
通过调用这些插件,TaskWeaver 智能体生成的代码可以与外部环境交互并执行复杂操作。以 Bright Data 为例,它提供了一系列强大的工具:
- Web Unlocker API:通过一次请求抓取任意网站,并返回干净的 HTML 或 Markdown,同时自动处理代理、反封锁、请求头和验证码。
- SERP API:大规模采集来自 Google、Bing 等搜索引擎的结果,而无需担心被封锁。
- Web Scraping API:从 Amazon、Instagram、LinkedIn、Yahoo Finance 等常见站点获取结构化、已解析的数据。
- 以及其他 Bright Data 解决方案……
凭借与上述服务相连的插件,TaskWeaver 智能体可以实时搜索网页、提取内容,并从热门站点获取结构化数据。这样,AI 就能够处理远超标准 LLM 能力范围的复杂、企业级工作流。
如何通过自定义插件将 Bright Data 集成到 TaskWeaver 中
在本教程部分,你将学习如何将 TaskWeaver 智能体与 Bright Data 集成,用于网页数据获取。
具体来说,你将看到如何为 TaskWeaver 应用扩展一个连接 Bright Data Web Unlocker API 的自定义工具。这样,你的代码优先智能体就可以从任意网页抓取数据,并根据你的需求进行处理。
注意:采用类似的方法,你也可以参考我们与 smolagents 的集成指南,那是另一种代码优先的 AI 智能体技术。
请按照下面的步骤仔细操作!
前置条件
要跟随本教程,你需要:
- 本地已安装 Python 3.10 或更高版本:用于运行 TaskWeaver 及其插件。
- 本地已安装 Git:用于从 GitHub 克隆 TaskWeaver 仓库。
- 正在运行的 Docker 守护进程(daemon):需要处于运行状态以避免在使用(可选的)代码校验功能时出现错误。
- 一个 OpenAI API 密钥(或来自任一受支持 LLM 提供商的 API 密钥)。
要使用 Bright Data,你还需要:
- 一个带有 API 密钥的 Bright Data 账号。
- 在账号中配置好的 Web Unlocker 区(zone)。
暂时不用担心如何配置 Bright Data,我们将在后续步骤中专门介绍。
步骤一:创建一个 Microsoft TaskWeaver 项目
首先,为你的 TaskWeaver 项目创建一个文件夹,并在终端中进入该目录:
mkdir taskweaver-bright-data-example
cd taskweaver-bright-data-example在项目文件夹中创建虚拟环境:
python -m venv .venv然后激活它。在 Linux/macOS 中运行:
source .venv/bin/activate在 Windows 中运行:
.venv\Scripts\activate接下来,通过以下命令安装 TaskWeaver:
git clone https://github.com/microsoft/TaskWeaver.git
cd TaskWeaver
pip install -r requirements.txt这会在你的项目文件夹中克隆 TaskWeaver/ 目录,并使用 pip 将所有依赖安装到刚创建的虚拟环境中。
TaskWeaver 作为一个进程运行,需要一个项目目录来存放插件、配置文件和会话数据。你刚克隆的仓库中,在 TaskWeaver/project/ 目录下提供了一个示例项目: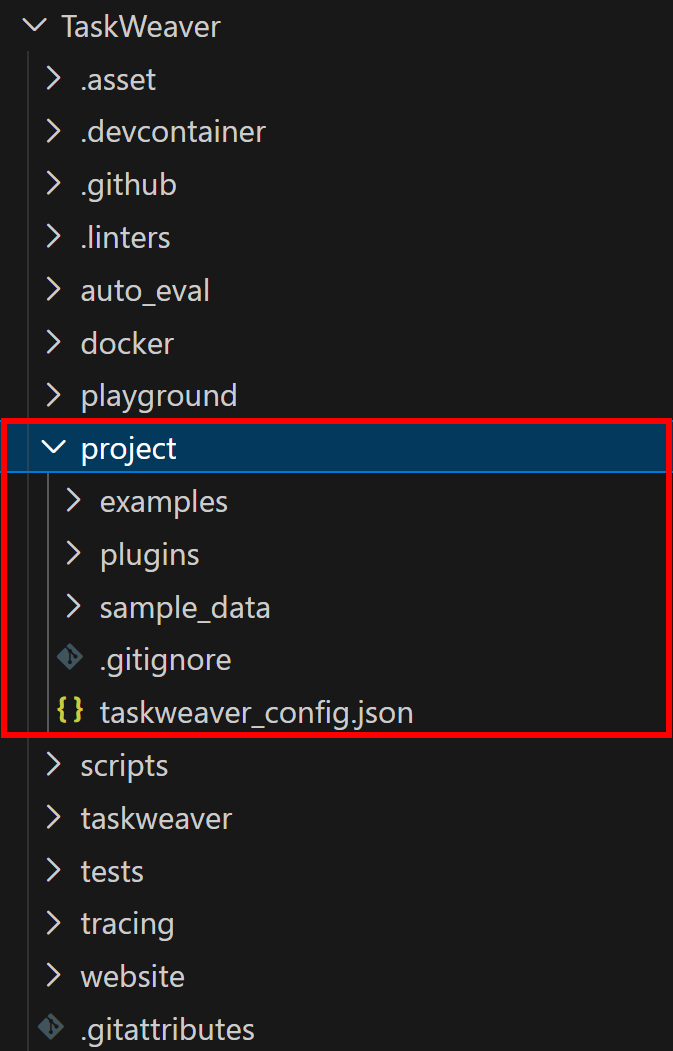
将 project 文件夹中的内容拷贝到你的工作空间中。完成后,你的 taskweaver-bright-data-example/ 文件夹结构应如下所示:
taskweaver-bright-data-example/
├─ .venv/
├─ TaskWeaver/
├─ plugins/ # Folder to store your plugins
├─ examples/
│ ├─ planner_examples/ # Example planner scripts
│ └─ code_generator_examples/ # Example code generator scripts
├─ sample_data/ # Optional sample datasets
├─ .gitignore
└─ taskweaver_config.json # Project configuration file一般来说,一个典型的 Microsoft TaskWeaver 项目目录包含特定的文件夹和文件,具体可参考官方文档中的说明。
在你偏好的 Python IDE 中加载 taskweaver-bright-data-example/ 目录,例如 Visual Studio Code 或 PyCharm。
在虚拟环境已激活的情况下,保持在 /TaskWeaver 文件夹内,使用以下命令启动应用:
python -m taskweaver这会从 /TaskWeaver 文件夹启动 TaskWeaver 进程,并从 taskweaver-bright-data-example/ 文件夹加载项目文件和目录。
如果一切正常,你会在终端中看到类似如下信息:
成功!Microsoft TaskWeaver 已经正常运行。应用首次运行后,会在目录中自动创建以下文件夹:
workspace/:用于存储项目的会话数据。logs/:用于存储程序生成的日志文件。
注意:如果你此时尝试输入提示词,会失败,因为尚未配置与 LLM 的连接。我们将在下一步中进行配置。
步骤二:在 TaskWeaver 中配置 LLM
TaskWeaver 支持多种 LLM。本教程中,我们将集成一个 OpenAI 模型,你也可以很容易将说明适配到其他受支持的 LLM 提供商。
要在 TaskWeaver 中配置 GPT-4.1 mini 模型,请确保 taskweaver-bright-data-example/ 目录下的 taskweaver_config.json 文件内容如下:
{
"llm.api_key": "<YOUR_OPENAI_API_KEY>",
"llm.model": "gpt-4.1-mini"
}将 <YOUR_OPENAI_API_KEY> 替换为你的实际 OpenAI API 密钥。
注意:在撰写本文时,TaskWeaver 尚不支持 GPT-5 模型。如果你尝试配置 GPT-5 模型,会遇到如下错误:
{'error': {'message': "Unsupported parameter: 'max_tokens' is not supported with this model. Use 'max_completion_tokens' instead.", 'type': 'invalid_request_error', 'param': 'max_tokens', 'code': 'unsupported_parameter'}}很好!你的 TaskWeaver 项目现在已经接入 OpenAI GPT-4.1 mini 模型,可以开始处理提示词了。
步骤三:设置 Bright Data Web Unlocker API 区(Zone)
要将你的 TaskWeaver 智能体连接到 Bright Data,并为其提供网页抓取能力,你首先需要完成一些准备工作。具体来说,你需要为 Bright Data 账号配置一个 Web Unlocker 区。
如果你还没有账号,请创建 Bright Data 账号;如果已经有,请直接登录。登录后,进入“Proxies & Scraping”页面。在“My Zones”区域中,查看表格里是否有一行名为 “Web Unlocker API”: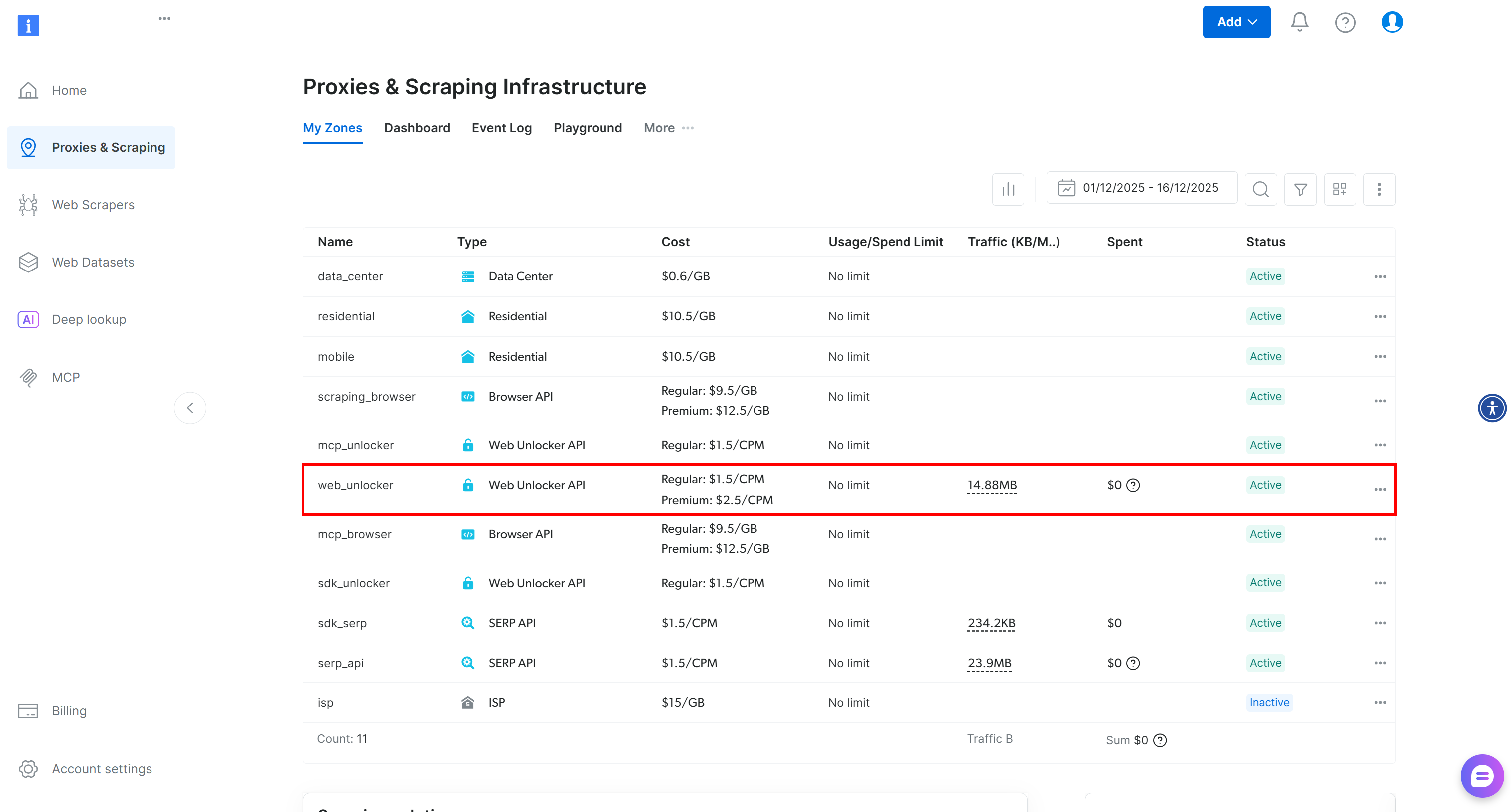
如果没有看到 “Web Unlocker API” 这一行,说明你的 Bright Data 账号中尚未设置对应的 zone。要创建一个,在页面往下滚动找到 “Unlocker API” 区域,然后点击“Create zone”: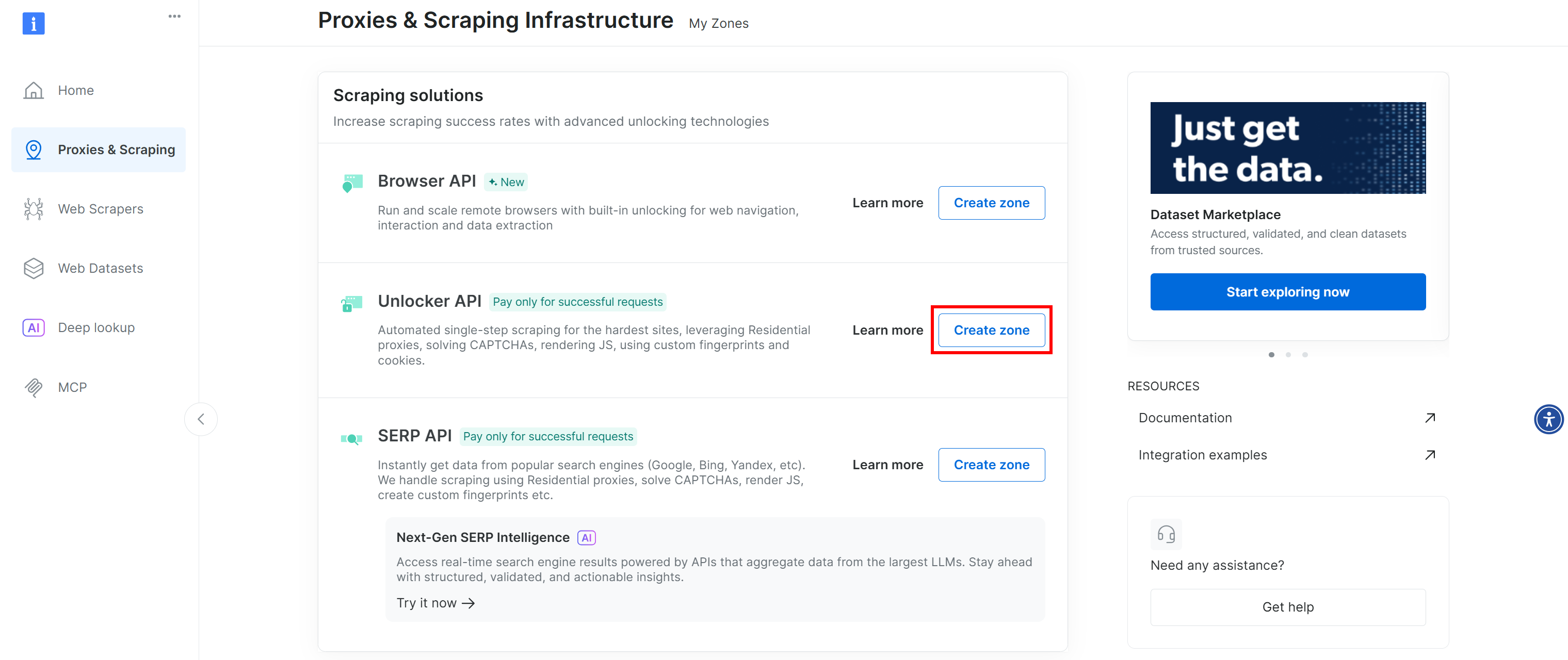
创建一个 Web Unlocker API zone,并为其指定名称,例如 web_unlocker(或任意你喜欢的名字)。请记住该名称,稍后在自定义插件中通过 API 访问服务时需要用到。
在 Web Unlocker zone 页面上,确保开关已设置为 “Active”,表明该 zone 已启用。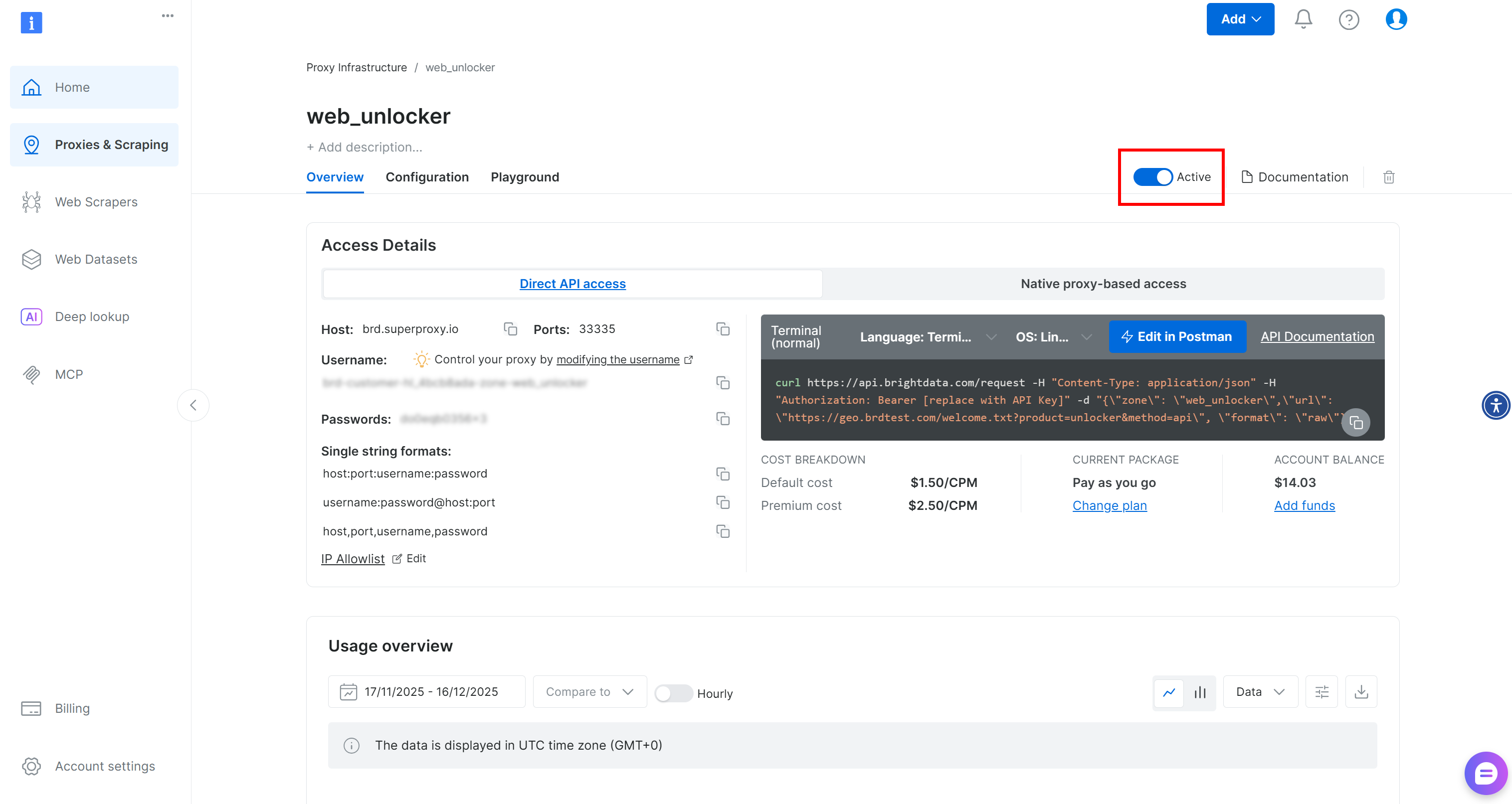
最后,按照官方指南生成你的 Bright Data API 密钥。请妥善保管该密钥,后续步骤中会用到。
很好!你已完成使用 Bright Data Web Unlocker API 插件所需的全部准备工作。
步骤四:定义用于 Bright Data 集成的 TaskWeaver Web Unlocker 插件
插件是可以由 TaskWeaver 代码解释器编排的单元。更具体地说,每个插件都是一个可在生成代码中被调用的 Python 函数。
在 TaskWeaver 中,一个插件由两个文件组成:
- 插件实现:定义插件的 Python 文件。
- 插件 schema:以 YAML 文件形式定义插件的输入、输出和元数据。
这两个文件都应放在项目中的 plugins/ 子文件夹下。
在本例中,你需要添加一个调用 Bright Data Web Unlocker API 的插件。关于如何调用该 API 端点的详细信息,请参阅官方文档。
在已激活的虚拟环境中,先安装一个Python HTTP 客户端(如 Requests):
pip install requests然后,在 plugins/ 文件夹中添加 web_unlocker.py 插件文件,内容如下:
# taskweaver-bright-data-example/plugins/web_unlocker.py
import requests
from taskweaver.plugin import Plugin, register_plugin
@register_plugin
class WebUnlockerPlugin(Plugin):
def __call__(
self,
url: str,
data_format: str = None
):
# Read configuration values for API call
bright_data_api_key = self.config.get("api_key")
zone = self.config.get("zone", "web_unlocker")
default_format = self.config.get("data_format", "markdown")
# HTTP headers required by the Bright Data API for authentication
headers = {
"Authorization": f"Bearer {bright_data_api_key}",
"Content-Type": "application/json"
}
# Request payload sent to Bright Data Web Unlocker
payload = {
"zone": zone,
"url": url,
"format": "raw", # To get the response directly in the body
"data_format": data_format or default_format
}
# Send the request to Bright Data Web Unlocker API
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers,
)
# Raise an exception for non-2xx HTTP responses
response.raise_for_status()
# Extract response content and HTTP status code
content = response.text
status = response.status_code
# Natural-language summary returned to the LLM
description = (
f"Fetched page successfully using Bright Data Web Unlocker "
f"(HTTP {status}, {len(content)} characters)."
)
# Persist the fetched page as an artifact in the session workspace
self.ctx.add_artifact(
name="web_unlocker_page",
file_name="page_content.md",
type="txt",
val=content
)
# Return both the raw content and a human-readable description
return content, description该插件通过 Bright Data Web Unlocker API 抓取网页。它首先使用 self.config.get() 从插件 YAML 文件的 configurations 部分(稍后会定义)读取配置值。
随后,它发送 HTTP 请求、检查错误,并通过 self.ctx.add_artifact() 将抓取到的页面作为工件保存在 workspace 中,方便你在执行过程中和执行后进行查看。最后,它返回原始页面内容以及一段自然语言摘要,供 LLM 使用。
注意:默认情况下,Bright Data Web Unlocker API 调用会以 Markdown 格式返回网页内容,这种格式非常适合 LLM 消化。这是 Web Unlocker API 提供的一项实用功能,可用于支持 AI 集成并简化内容处理。
太棒了!在 TaskWeaver 智能体能够使用该插件之前,你还需要为其指定 YAML 格式的插件 schema 文件。
步骤五:继续定义插件 Schema
插件 schema 用于定义 TaskWeaver 中的 LLM 应如何理解和调用该插件。该文件必须采用 YAML 格式,因此请在 plugins/ 文件夹中创建一个名为 web_unlocker.yaml 的文件,内容如下:
# taskweaver-bright-data-example/plugins/web_unlocker.yaml
name: web_unlocker
enabled: true
plugin_only: true
description: >-
Fetches and unlocks web pages using Bright Data Web Unlocker API,
bypassing anti-bot protections and returning clean page content.
parameters:
- name: url
type: str
required: true
description: The full URL of the web page to retrieve.
- name: data_format
type: str
required: false
description: Output format of the page content ("markdown" or raw HTML, if omitted).
returns:
- name: content
type: str
description: The unlocked page content.
- name: description
type: str
description: A natural-language summary of the fetch operation.
configurations:
api_key: <YOUR_BRIGHT_DATA_API_KEY> # Replace with your Bright Data API key
zone: web_unlocker # Replace with your Web Unlocker zone name
data_format: markdown上述 YAML 文件描述了前面 WebUnlockerPlugin 类中 __call__() 函数的输入和输出。借助该 schema,TaskWeaver 的 LLM 能够理解 web_unlocker.py 插件的功能及在生成的 Python 代码中如何调用它。
在 configurations 部分中,指定你的 Bright Data API 密钥、Web Unlocker 区名称以及输出格式。将 api_key 和 zone 字段替换为你在步骤三中设置的实际值。
大功告成!你的 TaskWeaver + Bright Data 集成已经完成。
注意:你可以使用同样的方法,通过 API 集成其他 Bright Data 服务,例如 SERP API 或 Web Scraping API。
步骤六:测试 TaskWeaver 智能体
现在是时候验证 TaskWeaver 中的代码优先智能体是否可以调用由 Bright Data 提供支持的插件了。核心思路是:生成的代码会调用插件函数,从而访问由 Web Unlocker API 提供的解封网页能力。
要进行测试,你可以尝试如下提示词:
Fetch the latest MCP changelog from "https://modelcontextprotocol.io/specification/2025-11-25/changelog" and list the changes.对于普通的 LLM 来说,这个任务是无法完成的,因为它需要一个自定义工具访问 URL 并从中提取信息。但在 TaskWeaver + Bright Data 的组合下,智能体完全可以处理!
使用以下命令启动 TaskWeaver 应用:
python -m taskweaver粘贴上面的提示词并按回车。你应该能看到类似下面的过程展示: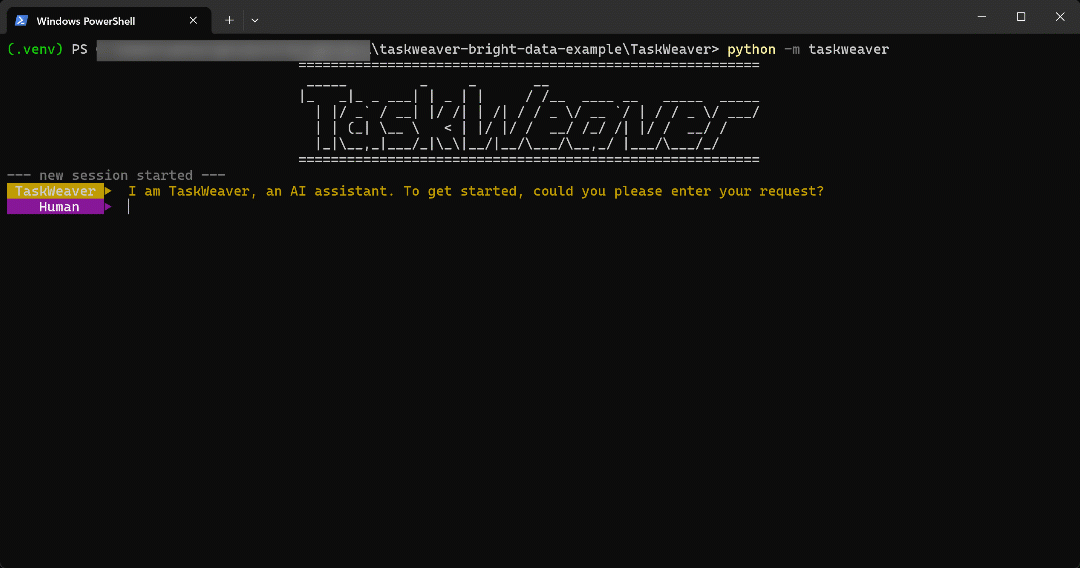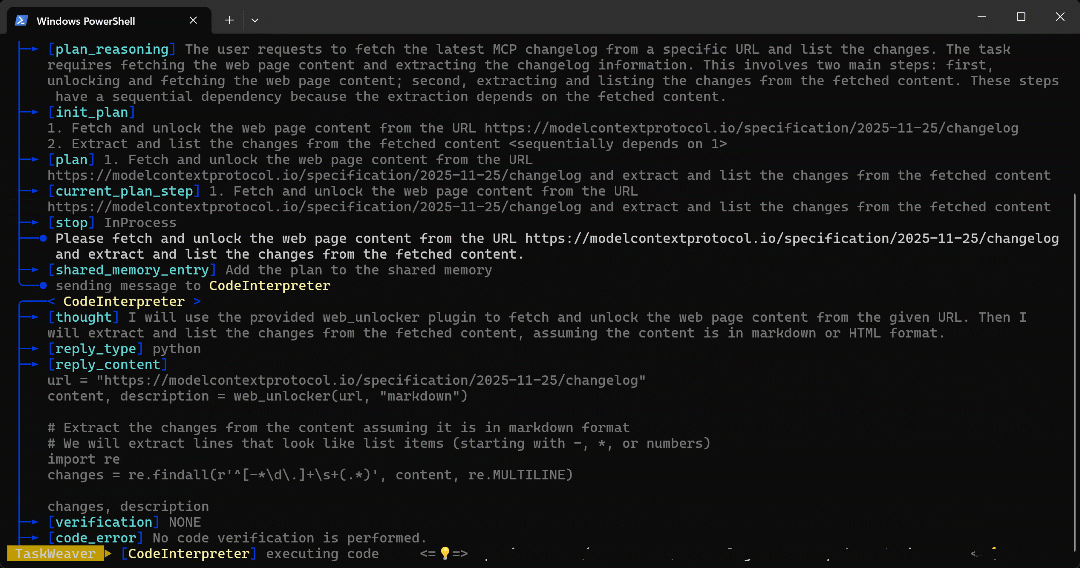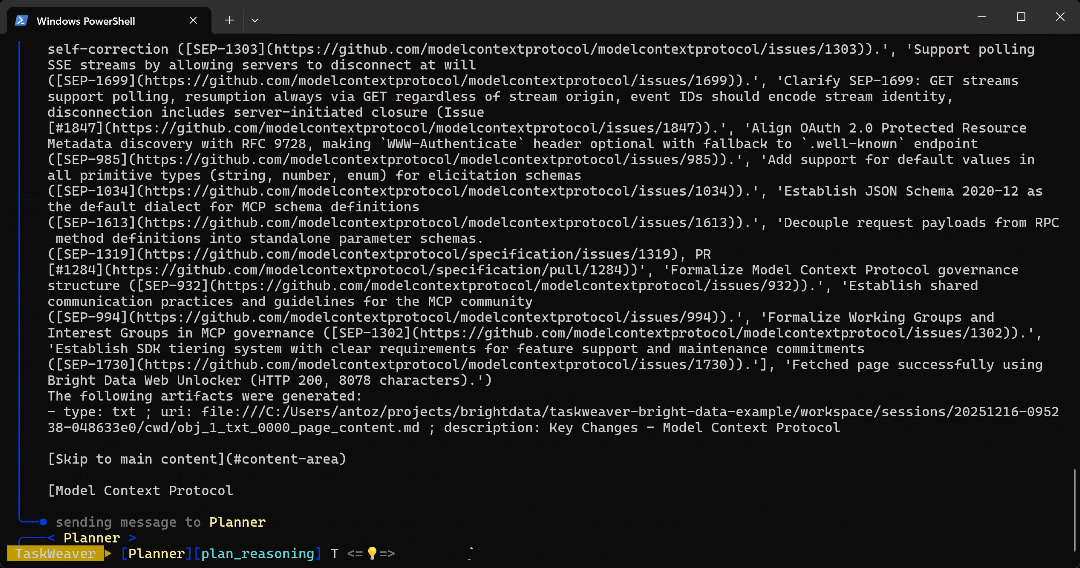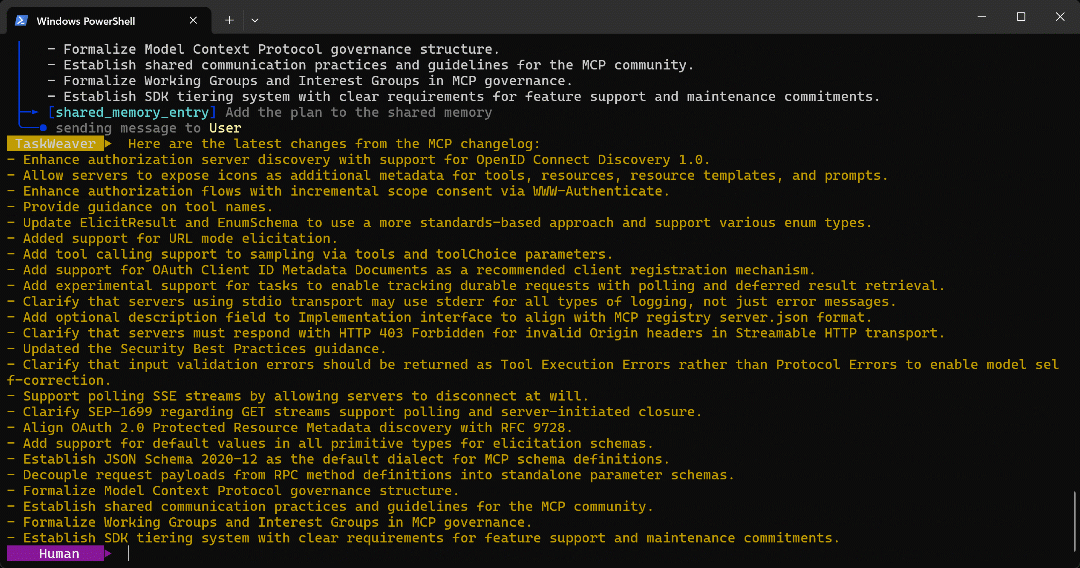
可以看到,智能体执行了如下步骤:
- TaskWeaver 的
Planner(规划器)首先生成了完成任务的计划。 - 该计划随后被发送给内部智能体
CodeInterpreter,它会生成实现目标所需的 Python 代码。 - Python 代码调用 Web Unlocker API 插件,然后通过 正则表达式提取文章中的所有项目符号列表。
- 代码被执行,所需数据通过 Web Unlocker API 获取,并根据
self.ctx.add_artifact()的配置保存在 workspace 文件夹中。 - 返回的 Markdown 数据(包含指定 URL 页面内容)被传回
Planner,然后执行下一步。 - 从目标页面中提取出的项目符号列表最终返回给用户。
可以看到,TaskWeaver 智能体运行得非常好。现在让我们仔细查看输出内容。
步骤七:查看输出结果
智能体运行结束时的最终输出如下: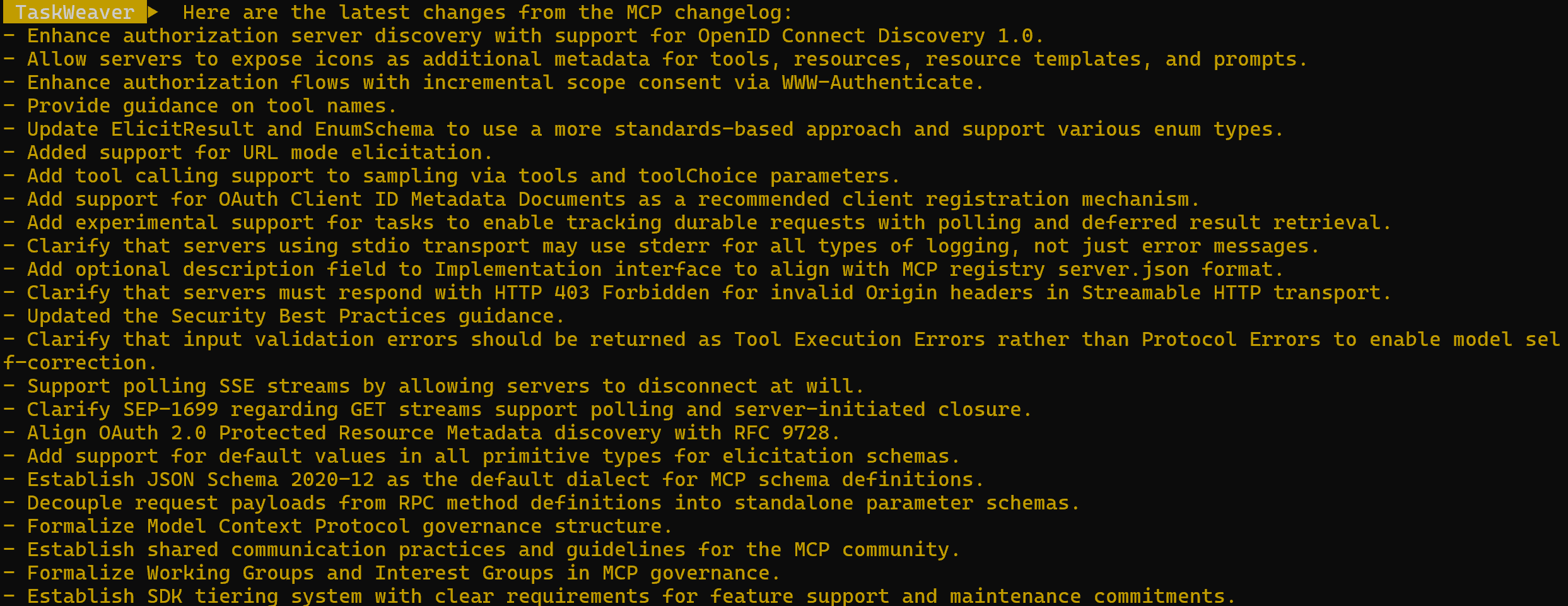
你可以在目标页面上验证,上面的列表与 MCP 更新日志中的内容完全一致: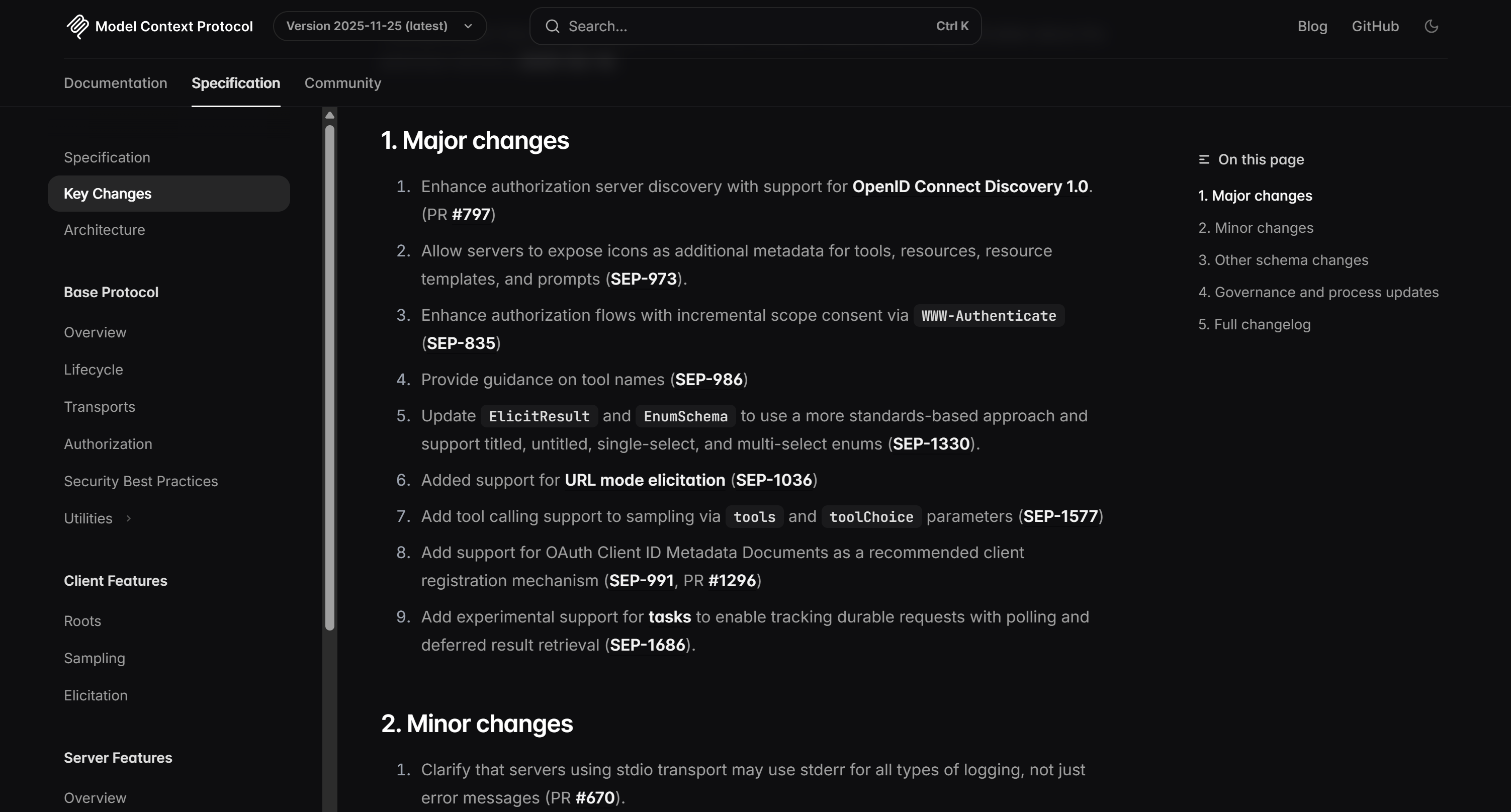
特别地,智能体是通过以下 Python 代码生成该输出的:
url = "https://modelcontextprotocol.io/specification/2025-11-25/changelog"
content, description = web_unlocker(url, "markdown")
# Extract the changes from the content assuming it is in markdown format
# We will extract lines that look like list items (starting with -, *, or numbers)
import re
changes = re.findall(r'^[-*\d\.]+\s+(.*)', content, re.MULTILINE)
changes, description请注意,生成的代码片段是如何调用 web_unlocker() 插件函数来以 Markdown 格式获取页面内容的。随后,它使用一个简单的正则表达式对其进行处理,以提取相关信息。
要进一步验证 Web Unlocker API 是否返回 Markdown 格式的页面内容,可以查看 workspace/ 文件夹中的文件。每次智能体运行都会在 workspace/sessions/ 下生成一个会话子目录,用于保存该次运行产生的内容。
在对应会话目录下的 cwd/ 文件夹中,你会找到通过 self.ctx.add_artifact() 创建的 .md 文件。打开后即可看到 Web Unlocker API 返回的内容: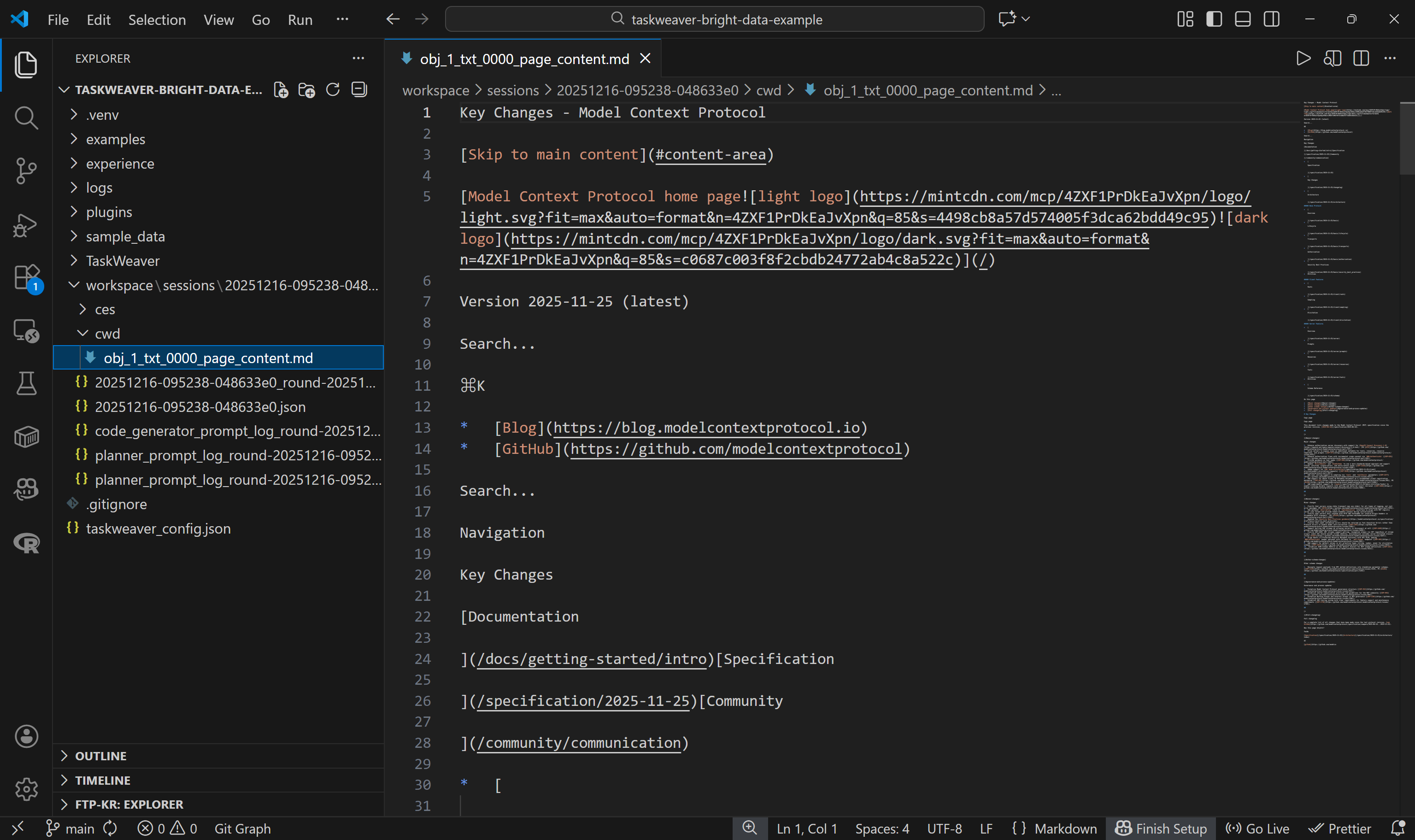
它与目标页面的 Markdown 版本完全一致,这也说明生成的 Python 代码中调用 Web Unlocker API 的部分工作得非常出色。
现在,你可以继续扩展你的智能体。尝试使用不同的提示词来处理更真实、更偏向企业级的场景。
就这样!你已经成功构建了一个使用 TaskWeaver 并集成 Bright Data 的代码优先 AI 智能体,该智能体可以可靠地从任意网页中获取适用于 AI 处理的数据。
下一步
本文展示的集成是一个基础示例。要进一步提升 TaskWeaver 智能体的能力并使其达到生产可用级别,可以考虑以下增强方向:
- 集成更多 Bright Data 解决方案,例如 SERP API,使智能体具备搜索全网并采集实时数据的能力。
- 配置 Web UI,作为开发、测试和监控智能体的可视化工作台。
- 启用高级特性,例如提示词压缩、自动插件选择以及遥测/可观测性,以提升性能、可扩展性和可维护性。
总结
在本教程中,你学习了如何通过连接外部 API 的自定义插件,将 Bright Data 集成到 TaskWeaver 中。
这样的架构可以实现实时网页搜索、结构化数据提取、在线内容流访问以及自动化网页交互。通过充分利用Bright Data 完整的 AI 数据服务套件,你可以释放代码优先 AI 智能体的全部潜力!
立即免费创建 Bright Data 账号,开始使用我们的 AI 就绪网页数据解决方案吧。



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




