
在本文中,你将看到:
- Google Antigravity 是什么,以及它作为 AI 驱动的编码平台能带来什么。
- 它的主要限制,以及如何通过 Bright Data 的网页抓取、搜索、发现和浏览器交互工具来克服这些限制。
- 关于如何在 Antigravity 中配置 Bright Data Web MCP 的分步指南。
让我们开始吧!
什么是 Google Antigravity?
Google Antigravity 是一个新一代的代理式开发平台。它超越了传统 IDE 所提供的传统软件开发体验,转而专注于“代理优先”的工作流。
基本上,Antigravity 引入了自主 AI 代理,它们可以规划、编码、测试并验证复杂的软件任务。它同时支持同步开发和异步多代理工作流,使你能够委派整个开发目标,同时仍然保持对执行过程的可见性和控制力。
Google Antigravity 提供的主要特性包括:
- 代理优先架构:围绕自主代理构建,这些代理执行完整的开发任务,而不是孤立的提示。
- 双界面模型:将 AI 驱动的 IDE 与任务控制风格的 Agent Manager 结合,用于并行运行多个代理。
- 跨界面自动化:代理可以跨代码编辑器、终端和浏览器运行。
- 浏览器控制能力:内置代理可以与网页交互,用于测试、爬虫和验证任务。
- 基于工件的透明性:生成结构化输出(计划、diff、截图、演练),帮助用户理解并验证代理行为。
- 异步多代理执行:支持在不同工作区同时运行多个代理。
- 用户反馈集成:允许内联反馈(例如,对工件或截图的评论),代理会将其纳入执行。
- 自我改进系统:代理从先前任务中学习,并存储可复用的知识,例如代码模式和工作流。
- 模型灵活性:支持多个前沿模型(例如 Gemini、Claude、GPT 变体)以实现不同的代理行为。
为什么要用网页抓取、搜索、发现和交互来扩展 Google Antigravity 代理
Antigravity 无疑是一个强大的解决方案,但它的 AI 助手与所有 LLM 共享一个核心限制:静态知识。毕竟,AI 模型只能基于它们训练时使用的数据来生成答案。
问题在于,LLM 训练数据 代表的是过去的一个快照。在像 IT 这样快速变化的领域,即使是最先进的模型也可能应用过时的实践或建议废弃的 API。
解决方案是为 Antigravity 代理配备对网页数据工具的可靠访问能力,用于搜索、抓取、发现和自动化浏览器交互。这正是 Bright Data 的 Web MCP 所提供的!
作为解决方案的 Bright Data Web MCP
Web MCP 暴露了 70+ 个 AI 就绪工具。即使在免费层级(每月 5k 次免费请求)中,它也包含核心工具(带有用于并行执行的批处理版本):
| 工具 | 描述 |
|---|---|
search_engine + search_engine_batch |
以 JSON 或 Markdown 格式检索来自 Google、Bing 或 Yandex 的结果 |
scrape_as_markdown + scrape_batch |
在绕过反机器人保护的同时,以 Markdown 提取干净的网页内容 |
discover |
AI 驱动的搜索,根据用户意图对结果进行排序 |
Pro 模式 才是 Web MCP 真正产生差异的地方。它解锁全部 70+ 工具,包括用于从 NPM、GitHub、PyPI、LinkedIn、Yahoo Finance、YouTube、Google Maps 以及另外 40+ 平台提取结构化数据的工具。它还启用自动化网页交互。
Bright Data 的与众不同之处在于其大规模基础设施,拥有覆盖 195 个国家/地区的 4 亿+ 住宅 IP。这使其能够在实现 99.99% 正常运行时间和 99.95% 成功率的同时,提供高可扩展性和无限并发。
借助 Bright Data Web MCP,你可以克服 LLM 的知识限制。在实践中,Antigravity + Web MCP 的组合使 AI 编码代理能够:
- 在 Web 上搜索准确的实时信息。
- 获取并学习最新的教程和文档。
- 抓取实时网站用于分析、处理或逼真的模拟数据。
- 与网页交互并自动化工作流。
- 处理许多其他高级任务……
如何将 Google Antigravity 连接到 Bright Data Web MCP
在本引导部分中,你将看到如何在 Antigravity 中配置 Bright Data MCP。它的编码代理将获得搜索网页、发现新来源、抓取网页并与其交互的能力。
按照下面的说明操作!
前提条件
要完成本部分,请确保你具备:
- 一个 Google 账号。
- 一个已设置 API key 的 Bright Data 账号(请遵循获取 Bright Data API key 的官方指南)
- 熟悉 MCP 的工作方式。
- 了解 Bright Data Web MCP 暴露的工具。
第 1 步:开始使用 Google Antigravity
下载 Google Antigravity,运行安装程序,并等待安装完成(可能需要一段时间,请耐心等待)。接下来,启动应用程序。
如果这是你第一次打开 Google Antigravity,你将看到以下屏幕:
按照设置向导操作。
你可以选择全新开始,或从 VS Code/Cursor 导入设置。然后,选择你的编辑器主题,选择你希望如何使用 Antigravity Agent(推荐选项是以审查驱动的开发),配置你的编辑器设置,并使用你的 Google 账号登录:
接受使用条款后,你将获得 Antigravity IDE 体验的访问权限:
干得好!Google Antigravity 现在已启动并运行,准备好用于 AI 辅助编码。
第 2 步:配置 Antigravity
首先打开一个项目目录。在本例中,我们将假设你正在使用一个空白的 antigravity-bright-data-project-sample/ 文件夹。你也可以像平时一样打开一个现有项目:
在右侧栏中,你可以访问 Antigravity 编码代理助手。你可以通过点击模型下拉菜单并选择不同的模型来配置模型: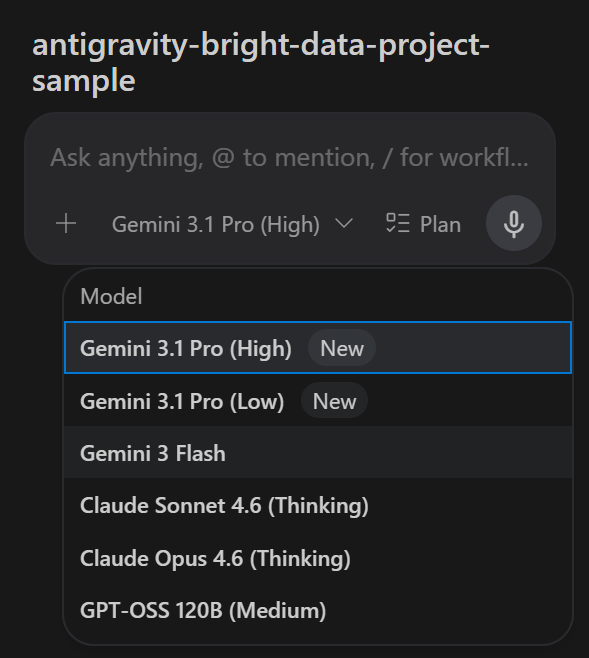
在本例中,我们将使用 Gemini 3 Flash,但任何其他可用模型都可以。很好!
第 3 步:测试 Bright Data 的 Web MCP
在将 Google Antigravity 连接到 Web MCP 之前,请检查 MCP 服务器是否在你的机器上运行。
首先创建一个 Bright Data 账号。否则,如果你已经有账号,只需登录。为了快速设置,请在 Bright Data 控制面板的“MCP”部分按照向导操作: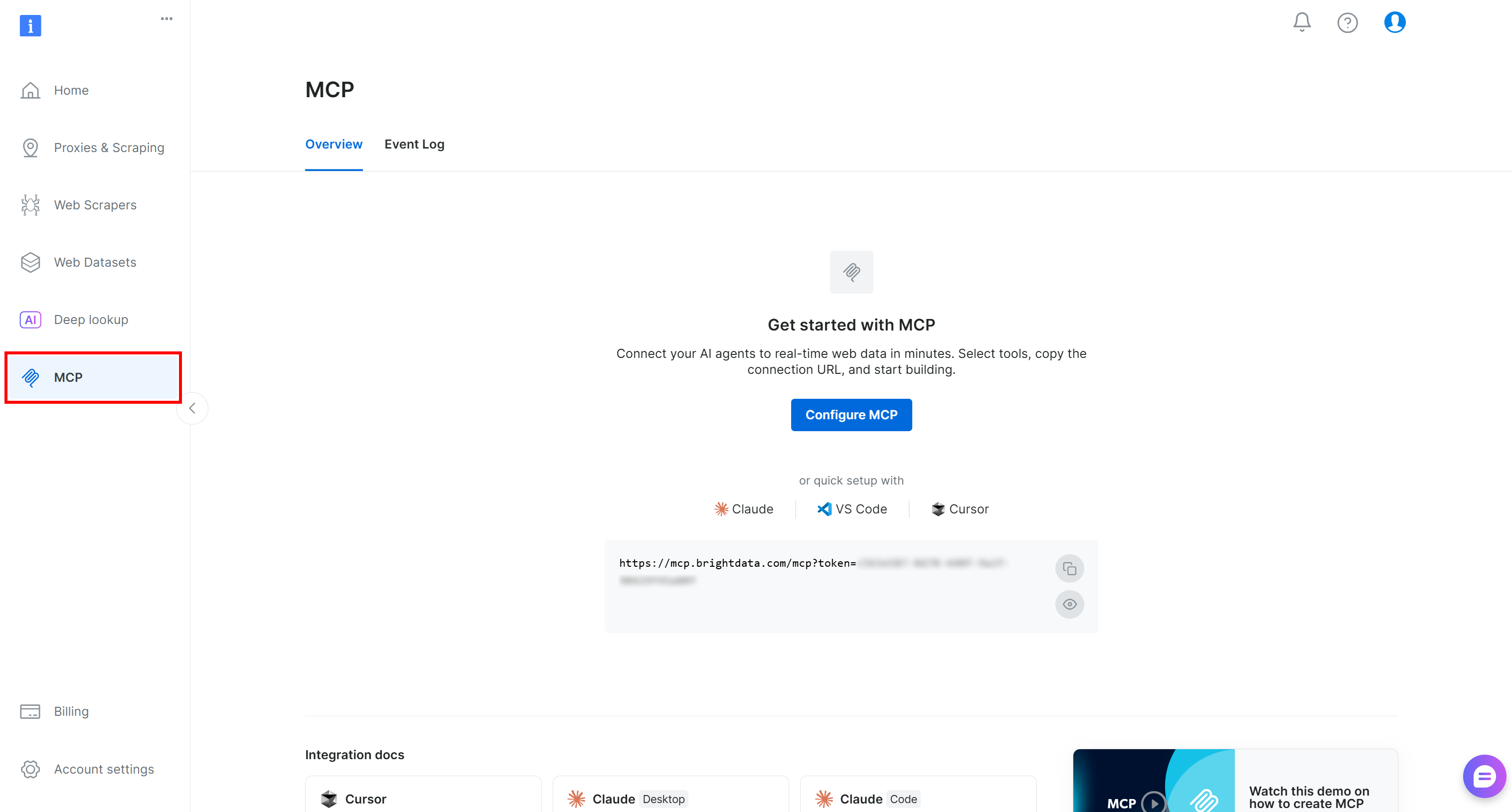
如需更详细的指导,请参考下面的说明。
首先,如果你尚未这样做,请生成你的 Bright Data API key并将其存放在安全的地方。你很快将需要它来将你的本地 Web MCP 实例认证到你的 Bright Data 账号。
接下来,在你的系统中全局安装 Web MCP:
npm install -g @brightdata/mcp使用以下命令验证本地 Web MCP 服务器启动:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcp或者等价地,在 PowerShell 中:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp将 <YOUR_BRIGHT_DATA_API> 替换为你实际的 Bright Data API key。上述命令设置所需的 API_TOKEN 环境变量,并通过 @brightdata/mcp 包在本地启动 Web MCP 服务器。
如果成功,你应该会看到:
在首次启动时,@brightdata/mcp 会在你的 Bright Data 账号中创建两个区域:
mcp_unlocker:用于 网络解锁器 的区域。mcp_browser:用于 Browser API 的区域。
这两个区域为 Web MCP 中可用的 70+ 工具提供支持。你也可以配置自定义区域名称,如官方仓库中所解释。
要确认已创建两个默认区域,请导航到 Bright Data 控制面板中的“Proxies & Scraping Infrastructure”。你应该会注意到“我的区域”表中列出了这两个区域: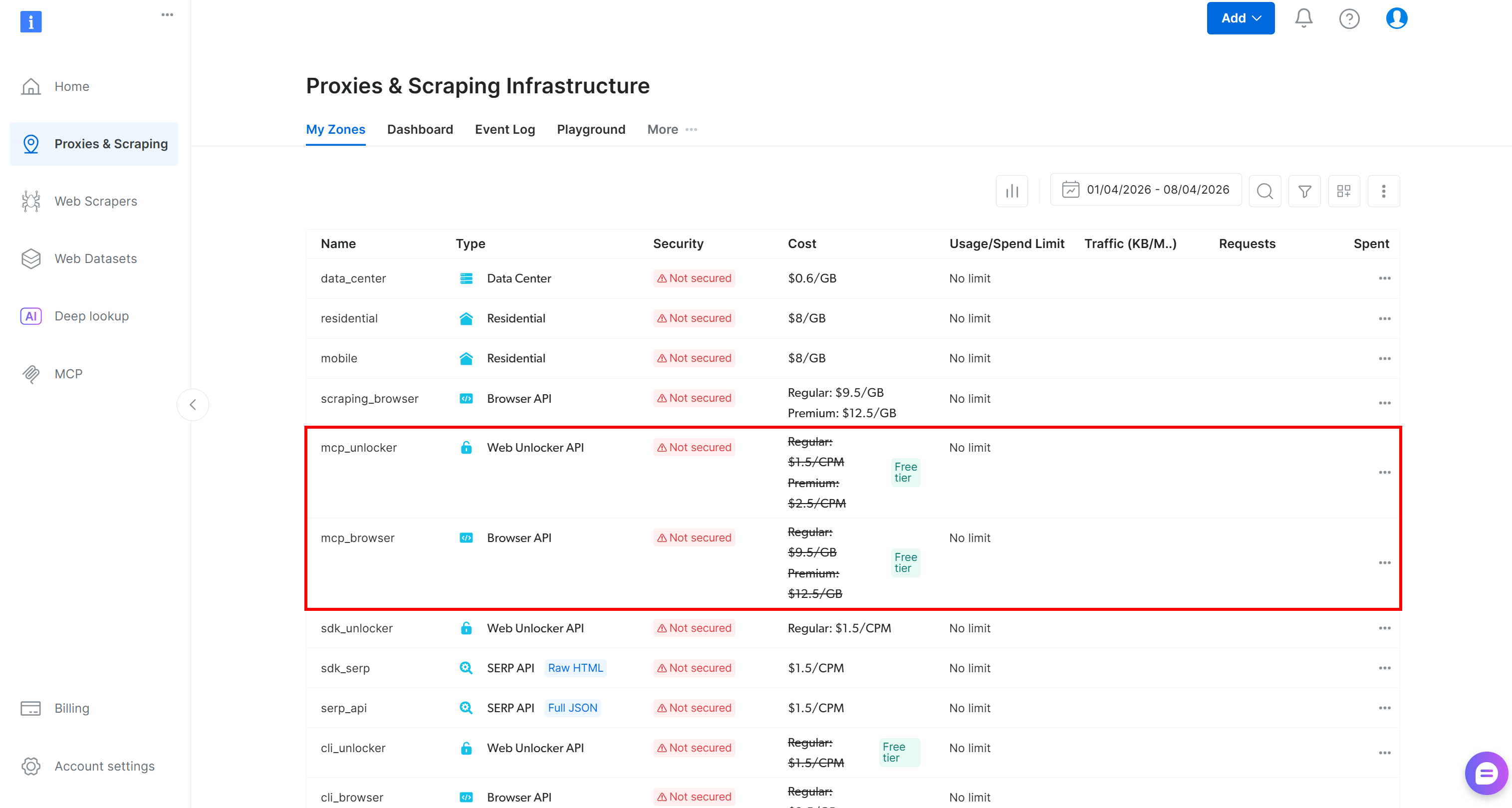
现在,请记住,在 Web MCP 免费层级 上,你的 AI 代理只能访问少数工具。
要解锁全部 70+ 工具,请通过设置 PRO_MODE="true" 环境变量来启用 Pro 模式:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcp或者,在 Windows 上:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcp注意:Pro 模式不包含在免费层级中,并且会产生额外费用。
很酷!你现在已经验证 Web MCP 服务器在你的机器上可以工作。接下来,你将配置 Antigravity 连接到它。
第 4 步:在 Antigravity 中配置 Web MCP
要访问 Antigravity Agent MCP 配置页面,首先点击“Agent”面板右上角的“…”按钮。然后选择“MCP Servers”: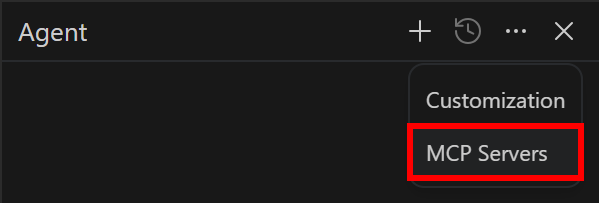
这将打开 MCP Store,你可以从官方市场添加服务器。由于你想配置自定义连接,请点击“Manage MCP Servers”: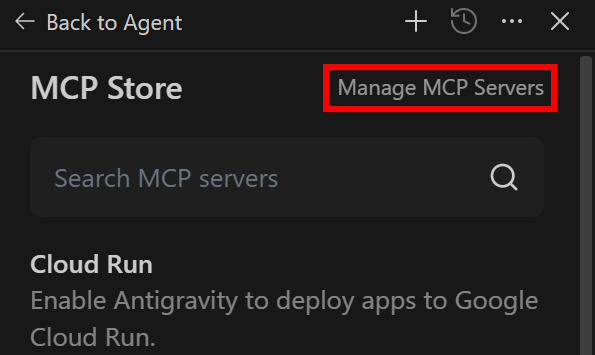
这将显示“Manage MCPs”面板。在这里,点击“View raw config”: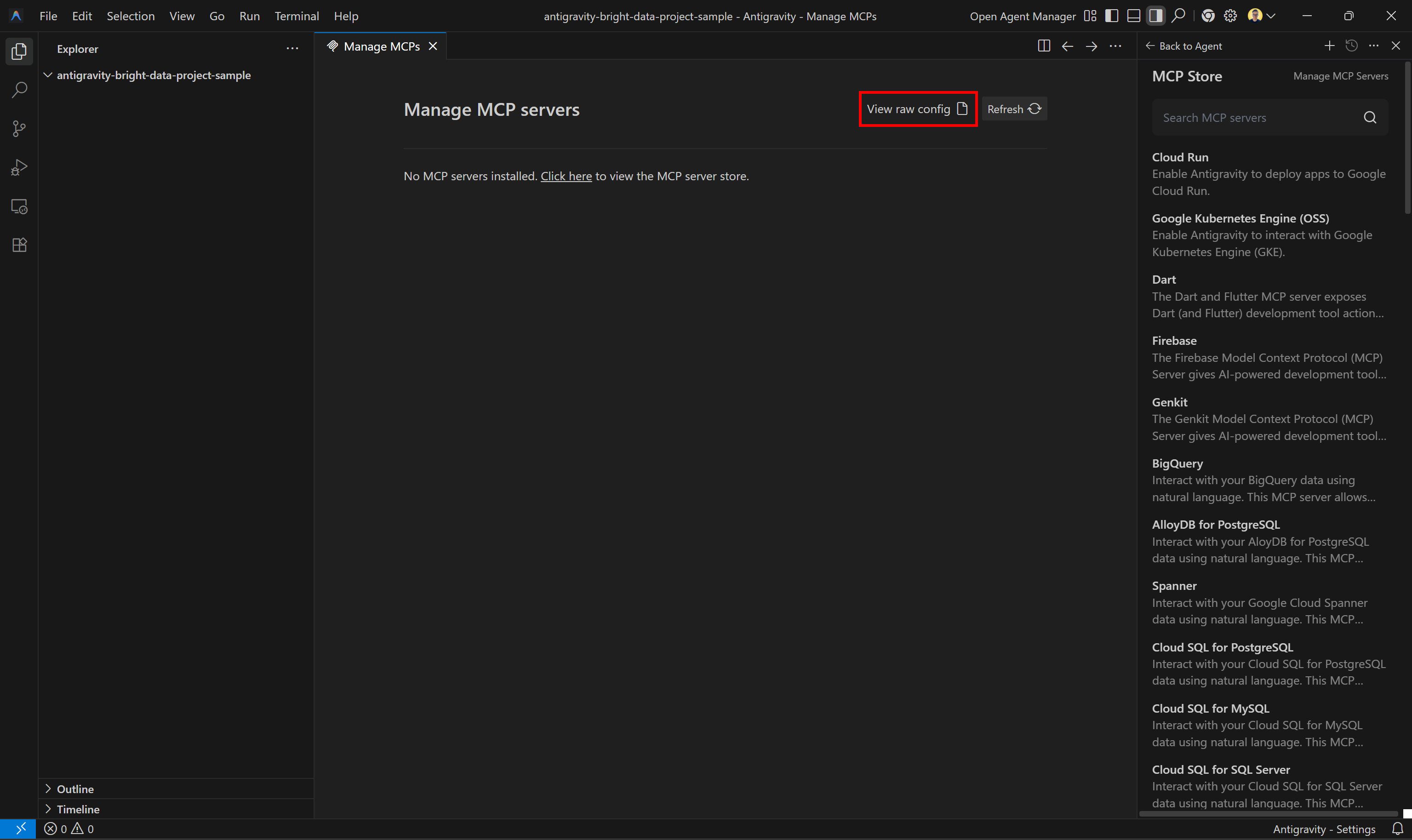
这将打开位于 ~/.gemini/antigravity/mcp_config.json 的系统级 MCP 配置文件: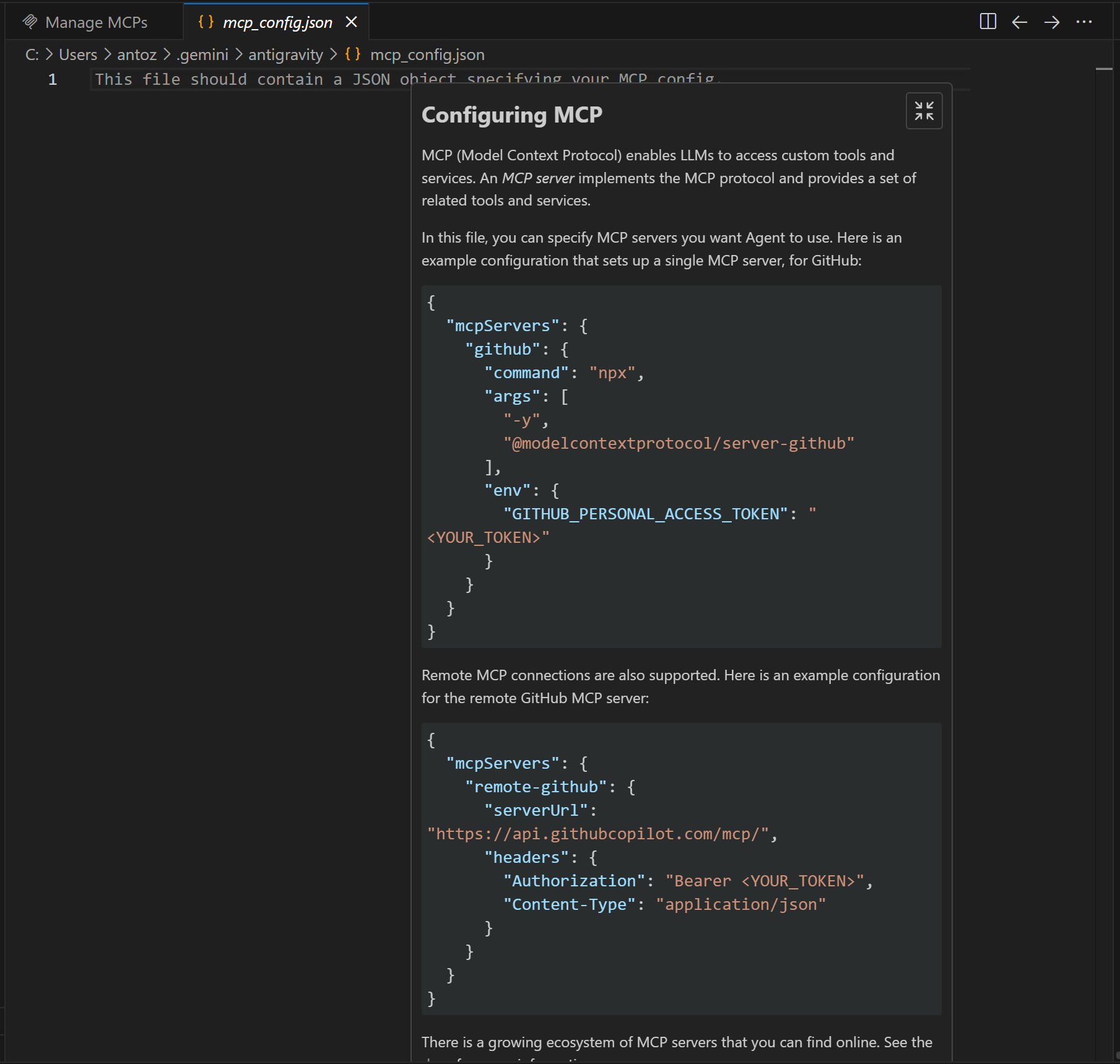
注意,Antigravity 已经建议了如何定义自定义 MCP 连接。
要配置 Bright Data Web MCP,请确保你的 mcp_config.json 包含:
{
"mcpServers": {
"bright-data-web-mcp": {
"command": "npx",
"args": [
"@brightdata/mcp"
],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_TOKEN>",
"PRO_MODE": "true"
}
}
}
}上述配置镜像了之前使用的 npx 命令,并需要以下环境变量:
API_TOKEN(必需):你的 Bright Data API keyPRO_MODE(可选):设置为"true"以启用 Pro 模式,或移除/设置为"false"以禁用
保存文件,然后返回“Manage MCPs”选项卡并点击“Refresh”按钮:
Antigravity 将使用指定的 npx 命令启动 Web MCP 服务器并连接到它。同样的过程也会在启动时自动运行。
不错!Bright Data Web MCP 暴露的工具现在应该可供你的编码代理使用了。
第 5 步:检查 Web MCP 连接
现在,在“Manage MCPs”选项卡的“Manage MCP servers”部分,你应该能看到所有 Web MCP 工具: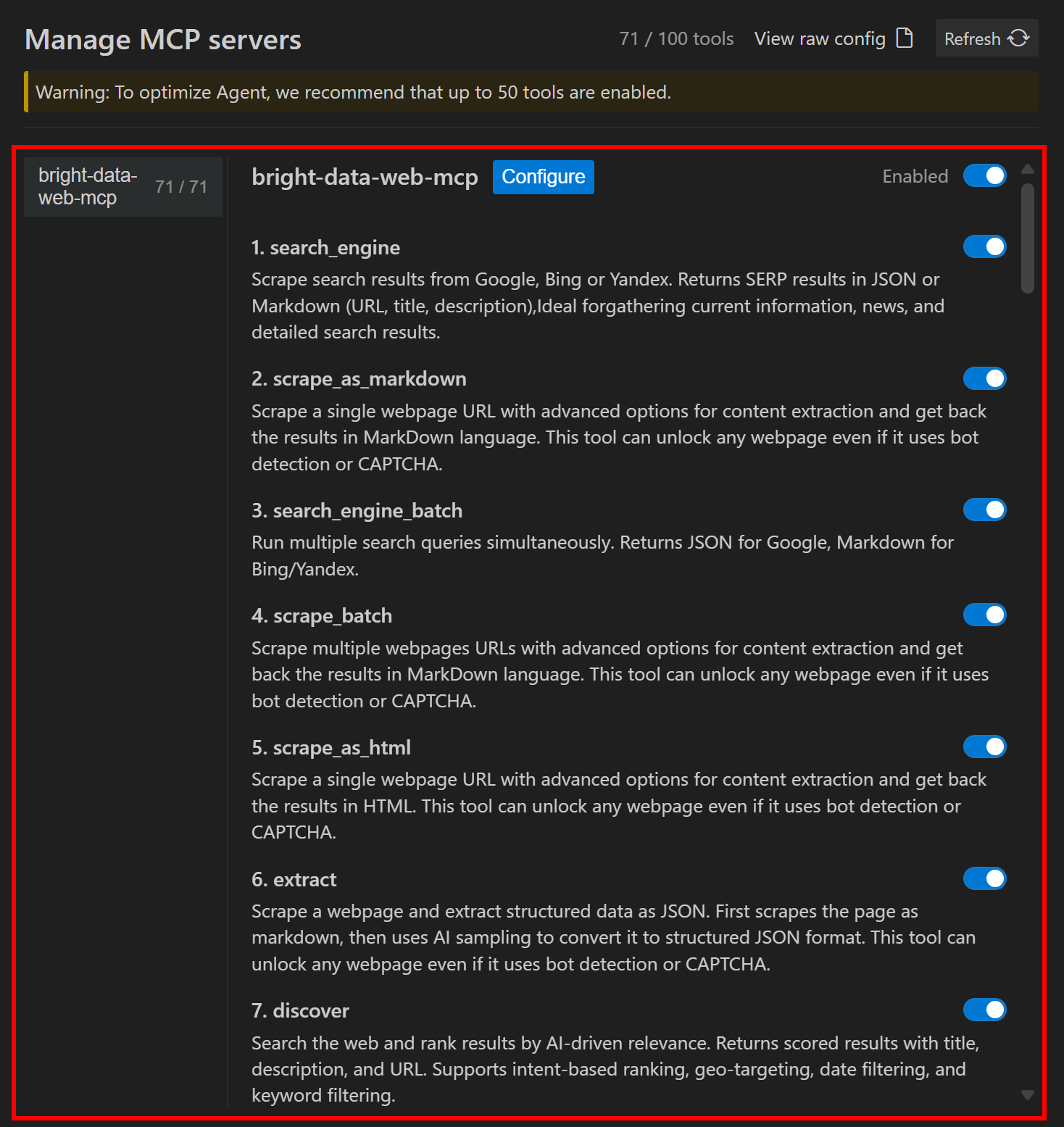
默认情况下,Web MCP 服务器已启用,并且其所有工具都处于激活状态。在本例中,服务器以 Pro 模式配置,因此我们获得了对全部 70+ 工具的访问权限。如果你以 Rapid 模式(PRO_MODE=false)配置它,你将只能看到免费工具。
太棒了!Google Antigravity 代理现在可以访问 Bright Data Web MCP 工具,用于抓取、搜索、网页发现、自动化交互、结构化数据源检索等。剩下的就是对该设置进行测试。
第 6 步:尝试 Bright Data + Antigravity 编码设置
Bright Data Web MCP 支持广泛的用例,并极大扩展了内置 Antigravity 代理的能力。在本示例中,我们将使用它来构建一个由真实世界数据驱动的简单 Flask 后端。
具体来说,目标是创建返回产品数据的 API 端点。代理不会使用虚假数据,而是通过从 Walmart(或其他电商平台)抓取来检索逼真的数据,然后围绕它构建一个应用程序。
为此,编写如下提示:
Search for the Walmart best sellers page and scrape it in Markdown. From the results, select the first 5 products. For each product, scrape its information in a structured format.
Store the scraped data in a local products.json file.
Then, build a simple Flask backend that uses the JSON file as a mocked local database and exposes:
- a GET /products endpoint to return all products
- a GET /products/<id> endpoint to return a single product注意:这不是一个普通 LLM(例如 Gemini、Claude)能够单独可靠完成的事情。像搜索、爬虫和提取结构化数据这样的任务需要专用工具,例如 Bright Data Web MCP 所提供的那些工具。
确保你已在本地安装 Python。然后,在 Antigravity 中执行该提示。你应该会看到类似这样的内容: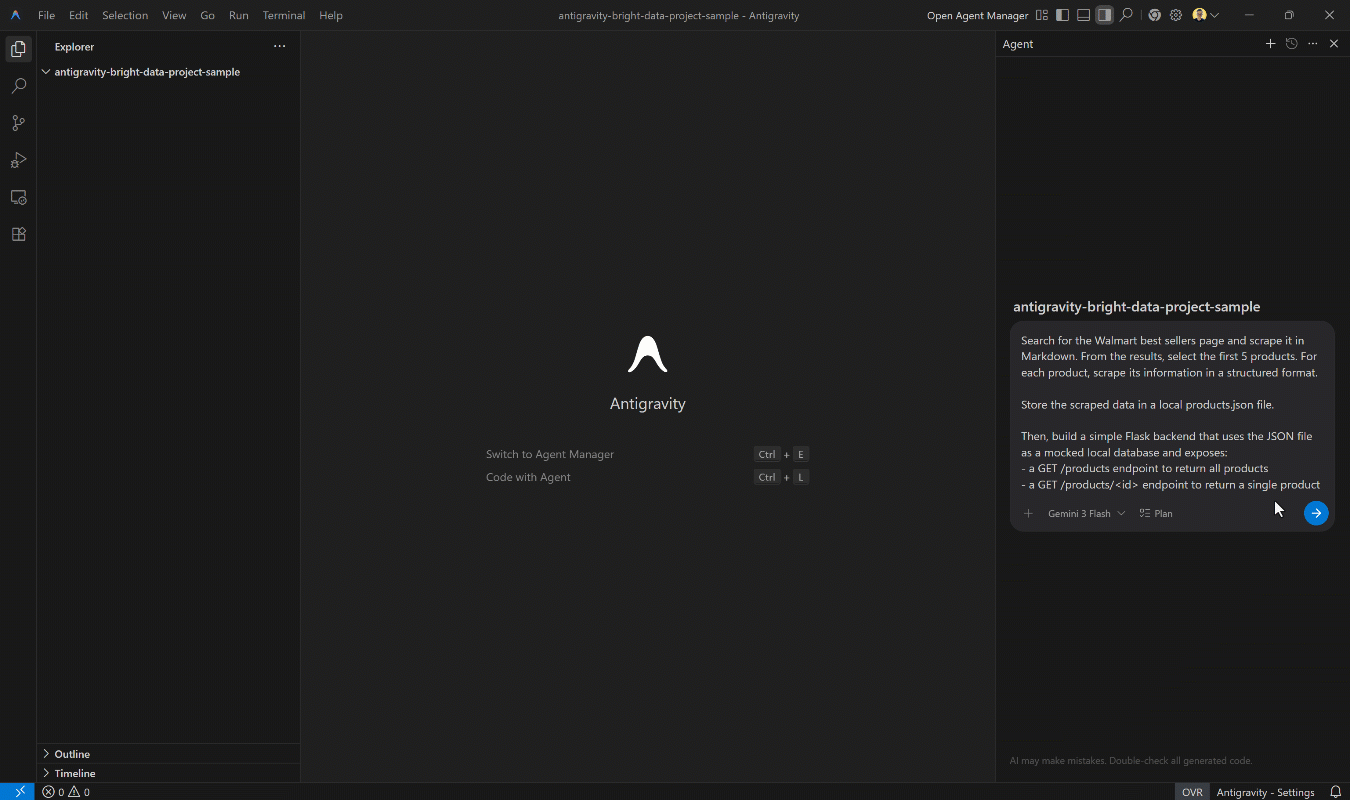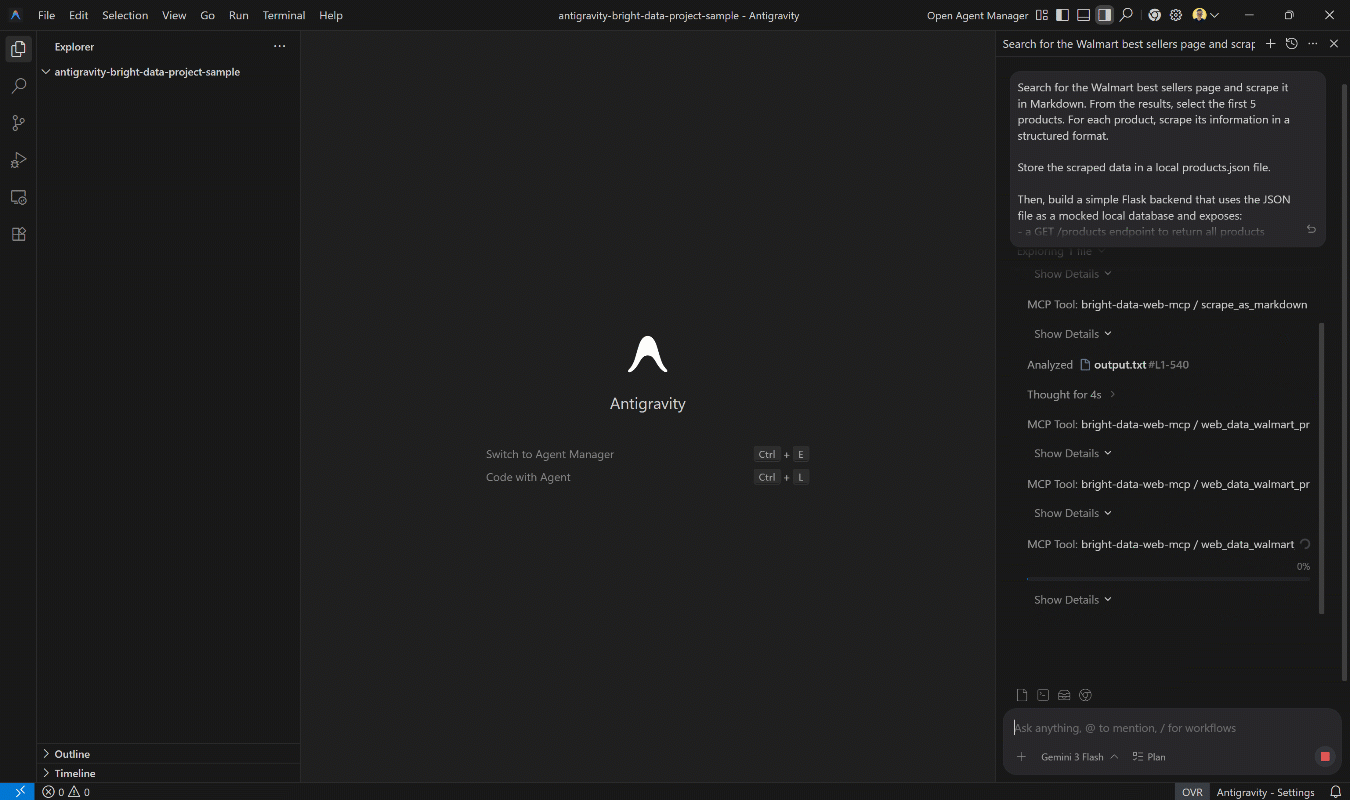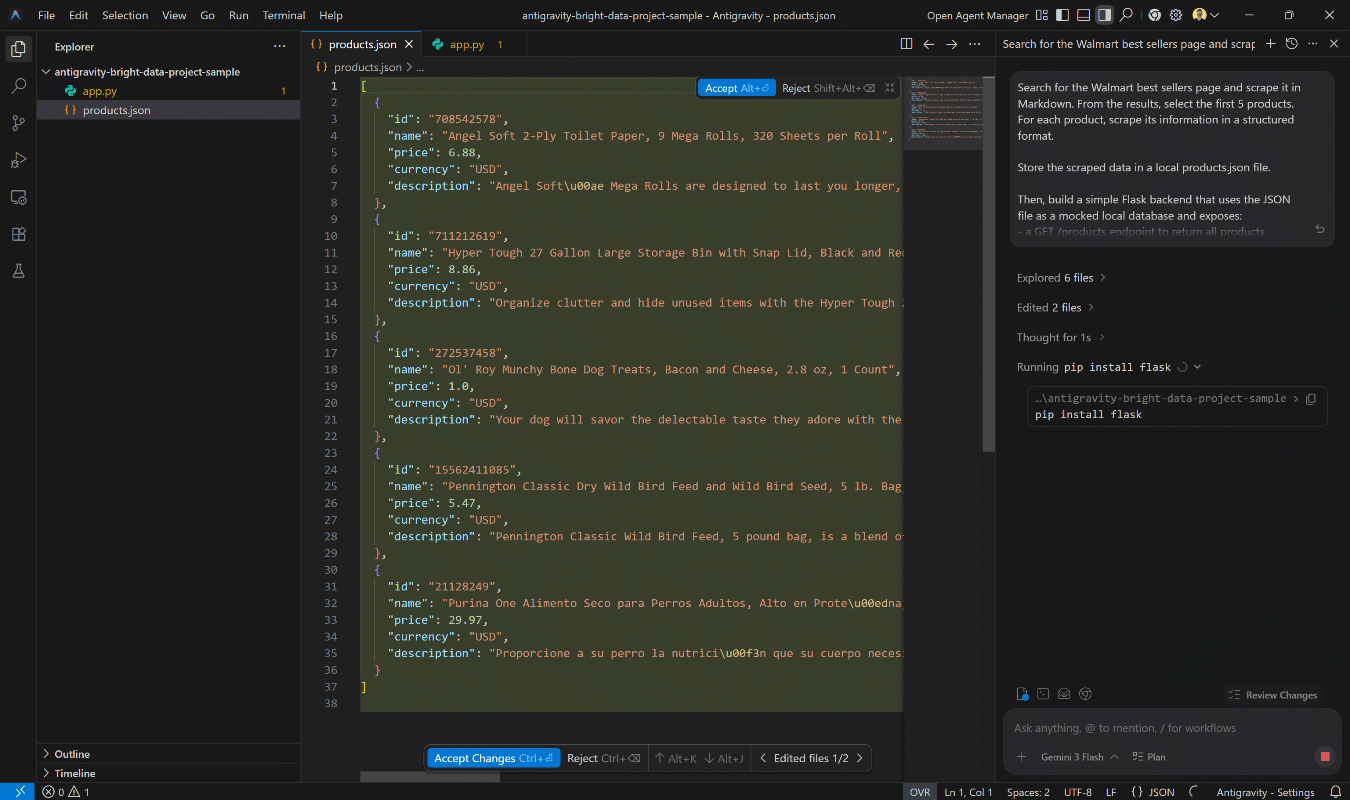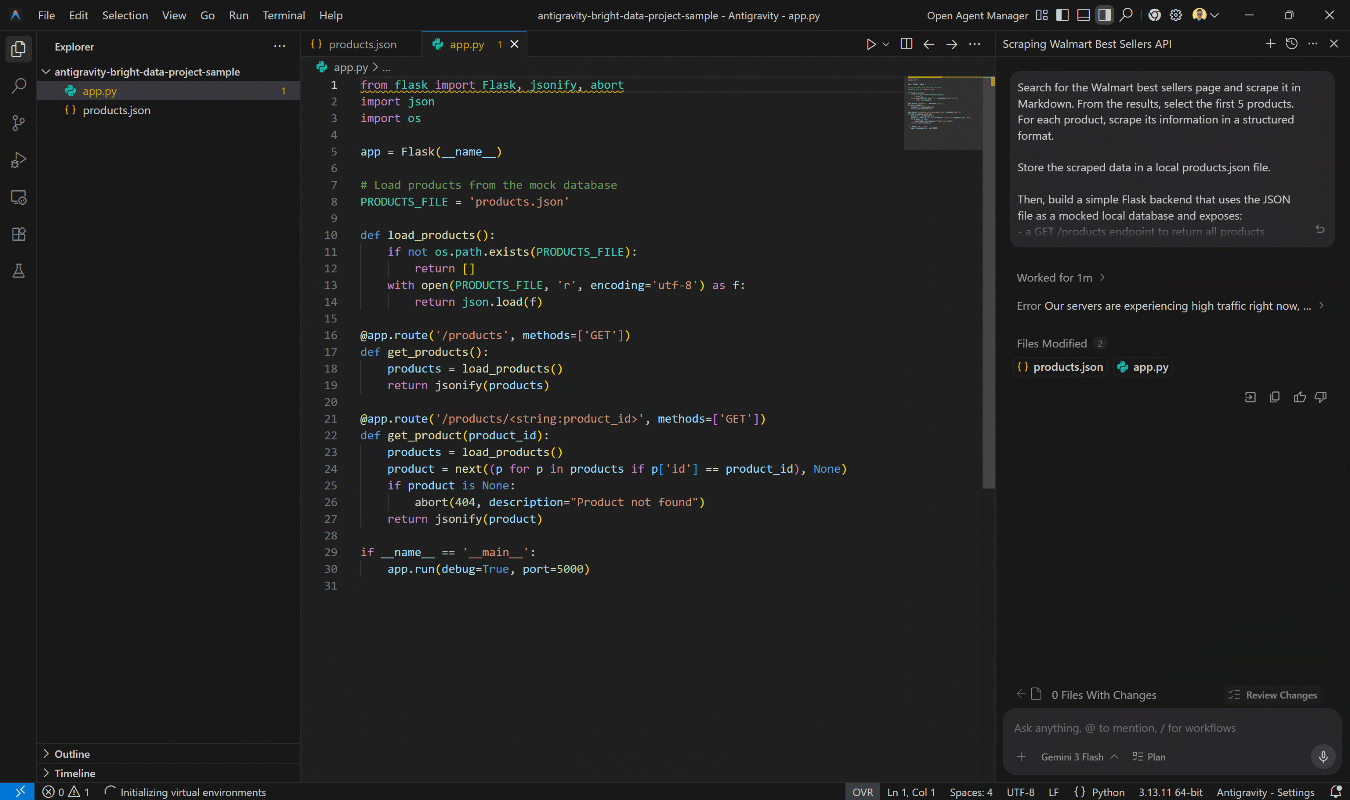
注意 Antigravity 代理如何:
- 使用
search_engine工具查找 Walmart 畅销商品页面(通过 Bright Data 搜索引擎 API)。 - 使用
scrape_as_markdownWeb MCP 工具将页面内容以 Markdown 形式抓取(由 Bright Data 网络解锁器 API 支持)。 - 处理 Markdown 以提取前 5 个产品 URL。
- 使用
web_data_walmart_productPro 模式工具抓取每个产品页面(每个产品一次调用)。 - 生成包含结构化且相关数据的
products.json文件。 - 请求安装 Flask 的权限(如有需要)。
- 创建一个 Flask 后端(
app.py),暴露所需的端点。
这正是预期行为。此时,你的项目文件夹应包含:
- 一个包含抓取到的 Walmart 产品数据的
products.json文件。 - 一个使用该数据作为只读数据库的
app.pyFlask 后端。
太好了!现在你可以运行并测试生成的应用程序。
第 7 步:测试最终结果
通过运行以下命令启动 Flask 服务器:
python app.py本地服务器现在应该运行在 http://127.0.0.1:5000。
使用以下命令测试 GET /products 端点:
curl http://127.0.0.1:5000/products 注意:在 Windows 上,请使用 curl.exe 而不是 curl。
你应该会收到类似这样的响应: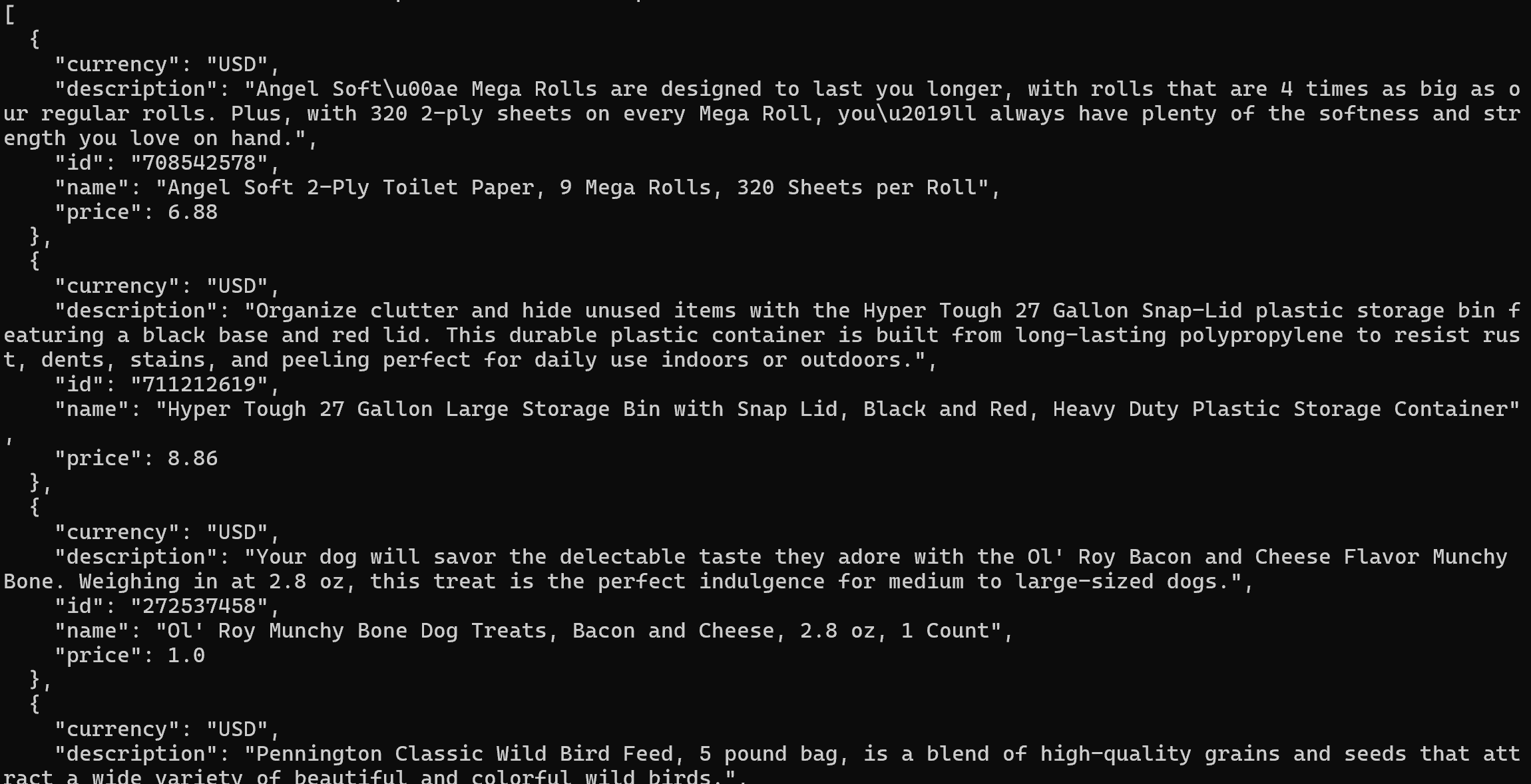
这对应于 Walmart 畅销商品页面中的前 5 个产品: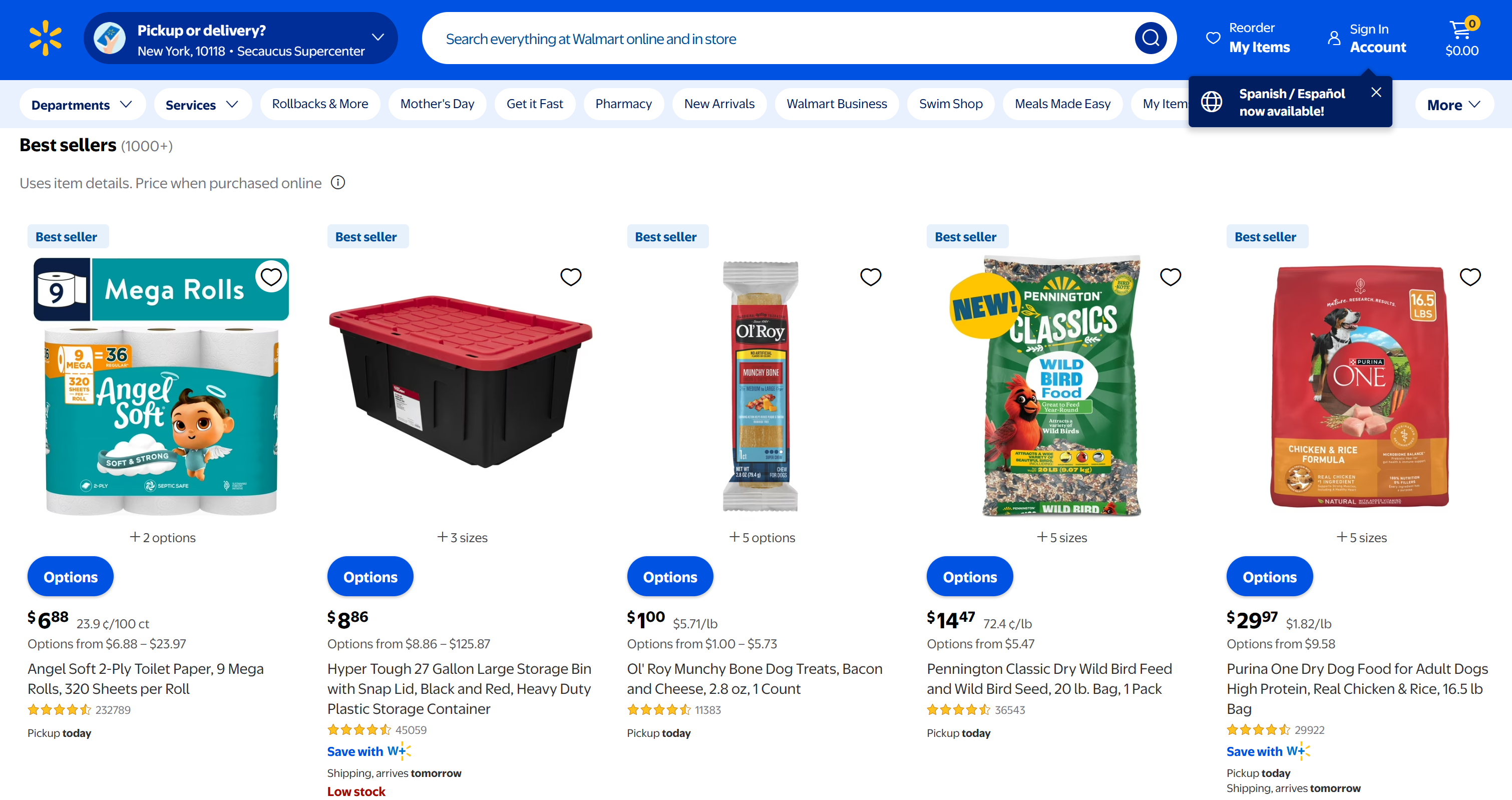
接下来,测试 GET /products/<id> 端点:
curl http://127.0.0.1:5000/products/272537458 这将返回 ID 为 272537458 的特定产品的数据: 瞧!你刚刚看到了通过 Bright Data Web MCP 增强的 Antigravity 代理的强大能力。
瞧!你刚刚看到了通过 Bright Data Web MCP 增强的 Antigravity 代理的强大能力。
这是一个简单的示例,但它突出了该设置的潜力。借助 Bright Data Web MCP,你的 Antigravity 代理可以变得显著更强大、更自主。
结论
在这篇博客文章中,你了解了 Google Antigravity 是什么,以及它为 AI 辅助编码提供的关键特性。更重要的是,你理解了如何以及为什么通过集成 Bright Data 并使用 Web MCP 来扩展它。
这种集成显著提升了 Antigravity 代理的能力。它现在可以执行网页搜索、提取结构化数据,并与真实世界的网站交互——解锁诸如 grounding、网页发现以及许多其他用例。
要进一步探索,请查看 Bright Data 生态系统中可用的全套 AI 就绪服务。
免费注册 Bright Data,并开始使用我们的网页数据工具进行构建!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




