

小样本学习正在改变 AI 和机器学习领域。有了小样本学习,算法只需要少量数据就能完成训练。如果你需要在有限数据的情况下 训练 AI 模型,小样本学习或许正是你一直在寻找的解决方案。
小样本学习的应用领域
小样本学习在现实世界中几乎无处不在。无论你需要一个真正通用的 LLM,还是想要一些 AI 驱动的爬虫,小样本学习都会或多或少用于模型的训练中。
- 医疗保健:在放射诊断或研究罕见疾病和病症时,大型数据集往往极其有限。你可以在 这里查看我们提供的医疗保健数据集。
- 机器人:在学习如何拾取物品时,自主机器人并不需要庞大的数据集。它们通过体验过程来进行泛化。
- 个性化科技:手机键盘和健身手表都高效地运用了小样本学习。
- 制药行业:在新药研发时,研究人员经常只有非常有限的数据集。在早期试验中使用小样本学习能够加速流程。
- 语言处理:语言学家和考古学家常常需要处理不再使用的古老语言。这些文字的一手来源稀少。AI 能够利用小样本学习来帮助破译这些语言。
- 图像识别:面部识别依赖小样本学习。大多数人不会用数千张同一个人的照片来训练 AI。对濒危或稀有物种的识别也采用同样的原理。
小样本学习与其他范式
小样本学习属于更广泛的机器学习方法族群,称为 n-shot 学习。在 n-shot 学习中,n 表示每个类别用于训练模型的带标签样本数量。
以下是一些其他的 n-shot 学习例子:
- 零样本(Zero-Shot):模型利用先验知识来预测从未见过的类别。想象一个只见过马和老虎的模型,虽然它从没见过斑马,但它可以推断出有条纹的马就是斑马。
- 单样本(One-Shot):模型在每个类别上只用一个样本进行训练。智能手机只需要一张你的照片就能学习你的脸,并允许你解锁屏幕,这就是单样本学习。
小样本学习如何运作?
小样本比零样本和单样本使用更多数据,但仍然依赖非常有限的数据集。只要拥有合适的训练数据,模型就能很快进行泛化,识别出其中的模式与趋势。
与零样本和单样本类似,小样本学习也建立在以下原则之上:
- 利用先验知识:模型利用之前任务中的知识和训练,在新、未知数据上寻找模式。
- 针对任务的自适应:模型会改变其内部表示(类别)和决策过程,以便在有限样本的新数据上正确完成任务。
- 从小数据集进行泛化:通过谨慎筛选的训练数据,模型在仅看到少量样本后依然能高效泛化。
小样本学习的类型
小样本学习并没有固定不变的形式;它属于更加庞大且不断发展的 AI 行业。不过,对于以下几个技巧,行业普遍存在共识。
迁移学习(Transfer Learning)
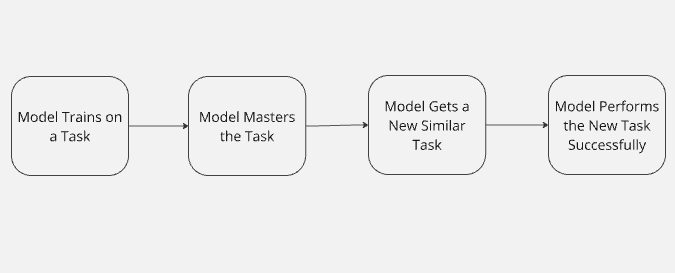
当一个模型在完成一项任务后,将所学到的知识应用到新任务上时,就被称为“迁移学习”。就像人类一样,AI 也可以利用以往的经验来适应新情况。模型的知识在不同任务之间转移,并在完成新任务时发挥作用。
想象一下,你教一个 AI 玩《使命召唤》。现在你需要这个模型去玩《堡垒之夜》。它已经掌握了瞄准、移动和作战策略等技能。从《使命召唤》中的经验为它在玩《堡垒之夜》时提供了更大的成功机会。
迁移学习并不局限于 AI 或机器学习。人类每天都在进行迁移学习。迁移学习是农业革命的主要推动力。史前人类学会了如何种植某些作物,然后把这些技能转移到其它所有能够食用的植物上。最终,他们把同样的原理应用到了驯养家畜上。
数据增强(Data Augmentation)
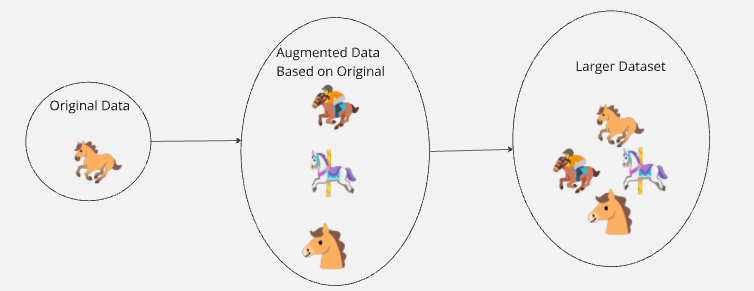
为了扩大小样本学习的能力,我们可以使用数据增强。在现实中,我们通常会生成与真实数据相似的虚构数据,并在其中添加随机性和噪声。
插值和外推可以帮助我们更好地理解数据增强。看下面的图表。可以看到,我们仅有四个真实数据点。图中的虚线根据这些点来绘制出一个模式。利用这些点,我们可以外推当 X=5 时,Y=10;当 X=0 时,Y=0。我们也可以插值当 X=1.5 时,Y=3。
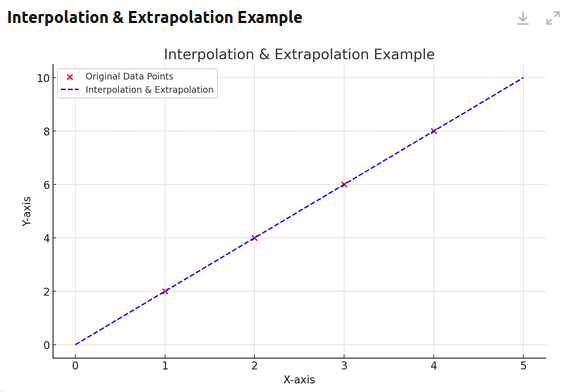
我们可以识别出有限数据中的趋势。一旦理解了这些趋势,就能基于原始数据所形成的规则生成无限多的额外数据。比如使用公式 (Y = 2X),可以把我们的 4 个数据点扩充为一个无限的点集。
在现实世界中,没有任何事物是完美的,类似上述情形并不多见。想象一下,你需要训练一个识别马的 AI。你只有一张棕马的真实照片,通过一些巧妙的编辑,你可以得到一匹红马、一匹黑马、一匹白马,甚至是一匹斑马。你从一张马的照片扩展出了一个更大的数据集。
你可以在这里了解更多关于数据增强的内容。
元学习(Meta Learning)
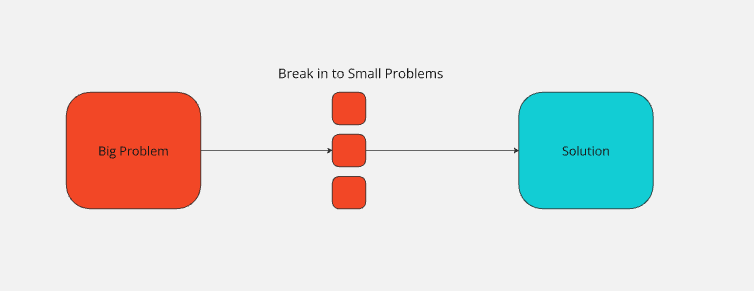
元学习更多关注的是解决问题的方法,而非具体数据。本质上,元学习让模型学会把更大的问题拆分成若干小问题,并在不同类型的问题上使用不同的策略。想想你在小学里学习的运算顺序。
看看下面这个问题:(2+(2*3))/4=?。要解决这个问题,我们需要把它拆分开来。
(2+(2*3))/4=?
2*3=6。现在可以把这个式子简化为(2 + 6)/4。2+6=8。现在问题变成8/4。8/4=2。把一系列小问题连接起来,就能证明(2+(2*3))/4=2。
通过把更大的问题分成更小的步骤,我们可以得出答案是 2。当我们教机器可以通过拆分大型问题来解决它们,并针对每个小问题采用合适的策略时,这就叫元学习。机器学到的是一种可适应多种场景的解题策略。
再来看看你很早就学到的另一个例子:一个句子开头需要大写字母,结尾需要标点符号。当模型学到这一点后,它不仅仅学会了写一个句子,而是学会了更有效地交流,让人类可以阅读并理解它的想法。
和前面提到的例子一样,人类在数十万年前就已经在使用类似元学习的方法,只不过我们近些年才将它应用到机器学习领域。
度量学习(Metric Learning)
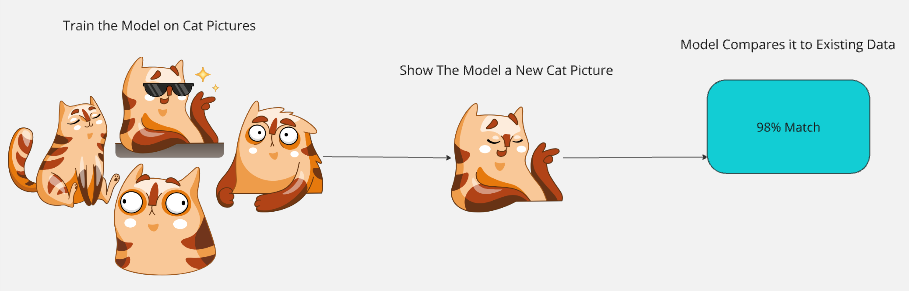
度量学习让模型学会比较数据之间的相似度,而不仅仅是为其分配标签。模型使用一个函数来比较各种度量,确定新数据与已经见过的数据有多相似。Teachable Machine 就允许我们对图像进行实验,亲身体验度量学习的原理。
想象我们用一组猫的照片来训练一个模型。模型分析这些图像,学会比较不同特征,如毛发、胡须和耳朵形状。
训练完成后,我们给模型一张新的猫照片。模型会把这张新照片和它的训练数据进行对比。通过对毛发、胡须、耳朵形状等数据点的观察,它会给出一个相似度分数。如果新图片与之前的数据有 98% 的相似度,模型就会判断这是只猫。
如果这个模型通过其他方法也学到了“猫很可爱”,那么在 98% 确认这是一只猫后,它或许会使用其他训练方式的逻辑,对你说:“你的这张猫图很可爱!”
小样本学习的内在问题
对于小样本学习而言,数据集小既是优势,也是劣势。机器学习本身就有各种各样的 陷阱。为了规避以下这些问题,小规模模型的训练需要运用前面提到的这些方法。
泛化
小样本模型在完成类似人脸识别这样的任务时表现很好,但当遇到全新的场景,如果数据与训练时用到的样本相差过大,就容易失败。
传统的大型语言模型会接受数百万、甚至数十亿或数万亿的数据点进行训练,使其能够更好地处理异常情况,并在应对未见过的数据时进行合理预测。
如果一个模型只见过几张铅笔手绘的猫图,它可能无法识别现实世界中的猫照片。没有足够健壮的数据集,模型就无法做出足够可靠的泛化。
数据多样性
小数据集往往无法充分体现大型数据集中丰富的多样性。想象一下,一个模型仅使用了少数几个人的地址数据,并且他们都来自美国。这个模型很可能会产生偏见,假设所有人都来自美国。要避免这种情况,需要使用广泛且多样化的数据集。我们提供的 数据集可以帮助你提升模型的表现。
在 2010 年代后期,这个问题困扰了全球范围内的许多 AI 模型。即使在现代 AI 中,有时也还会出现。社交媒体训练出的模型往往会继承其所见到的偏见。我们都听说过 2010 年代后期出现的“种族主义 AI 聊天机器人”,问题就出在这里。
特征表征
数据多样性不足也是一把双刃剑。再回想我们假设的动物识别模型,如果它只知道“所有猫都有四条腿”,那看到一匹马时就会觉得它跟猫非常相似。
如果一款人脸识别模型只是学到“脸上有眼睛、耳朵、嘴巴和鼻子”,但它并不会将这些特征与训练数据进行准确的比对,那么就会给出错误(甚至是危险)的结果。如果任何拥有这些特征的人都能解锁你的手机,这就造成了巨大的安全隐患。
结论
小样本学习能够减少对大型数据集的需求。自远古时代以来,人类就一直在使用小样本学习,如今我们才将其引入 AI 领域。它也面临一些挑战:泛化问题、数据多样性不足以及特征表征不完善在使用小数据集进行建模时都是障碍。好在迁移学习、数据增强、元学习和度量学习为我们提供了应对这些挑战的强大工具,不仅适用于大型模型,也适用于小型模型。



技术写作者
 6 years experience
6 years experience
Jacob Nulty 是一位常驻底特律的软件开发者和技术写作者,探索人工智能与人类哲学,具备 Python、Rust 和区块链方面的经验。





