
在本指南中,我们将讲解一个用于 LLM 提及追踪的通用 LLM 爬虫的用法与架构。该项目会把以下爬虫整合到一个统一的界面中:
完成本指南后,你将能够做到以下几点:
- 使用 Bright Data Web Scraping API 触发爬虫任务。
- 轮询任务就绪状态并下载爬取结果。
- 使用 Bright Data 的输出格式轻松完成标准化。
- 同时对多个 LLM 的提示词结果进行对比,用于研究与验证。
想直接开始上手项目?请在 GitHub 查看。
为什么要构建通用 LLM 爬虫?
用户的检索行为已经发生变化。如今,用户会直接向 AI 聊天机器人提问并信任其生成的答案,很少再回到搜索引擎继续检索。这会显著改变 SEO 与市场情报的运作方式:如果你的品牌没有出现在聊天机器人的输出中,潜在客户可能永远不会发现你。
企业现在不仅要出现在搜索结果中,也要出现在模型输出中。Bright Data 预构建的 LLM 爬虫可对市场上最受欢迎的模型输出进行标准化。将这些 API 统一到单一接口后,团队就能在所有主流 LLM 之间对比推荐结果。
例如提示词:Who are the best residential proxy providers?
手动逐个询问每个 LLM 并阅读结果可能需要一小时甚至更久。使用统一结果后,你可以将同一提示词同时发送给多个 LLM,并使用正则表达式立即判断你的公司是否出现在回复中。
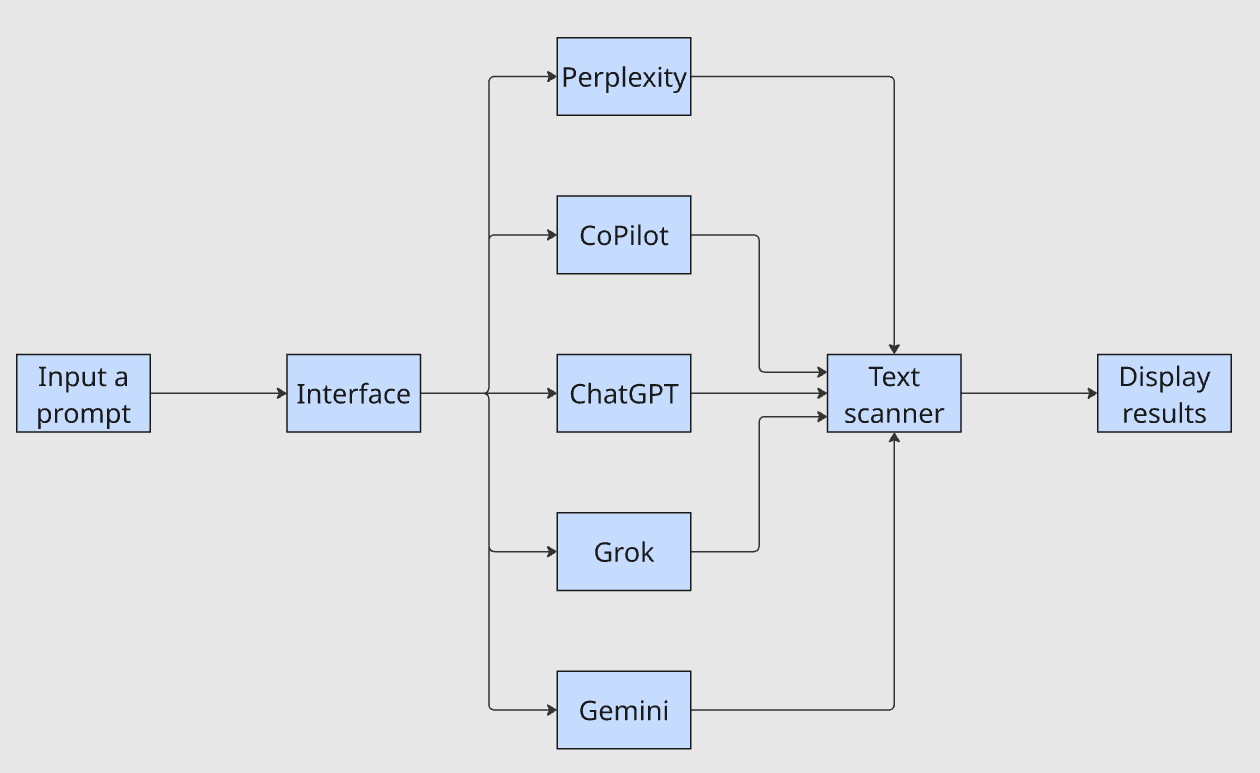
该界面接收一个提示词,将其转发给每个 LLM,把输出传给文本扫描器并展示结果。问题 我的公司是否出现在结果中? 将从“耗时一小时”缩短为“几分钟”。
构建实际软件
现在,我们需要开始构建实际的软件。我们会先创建基础项目骨架,然后在过程中逐步补全代码。本节不会包含完整代码库,这是概念性拆解,而不是逐行讲解。
开始
我们可以先创建一个新的项目文件夹:
mkdir universal-llm-scraper
cd universal-llm-scraper接着创建一个虚拟环境,防止依赖冲突:
python -m venv .venv然后激活虚拟环境。第一条适用于 Linux 或 macOS,Windows 请使用第二条命令:
Linux/macOS
source .venv/bin/activateWindows
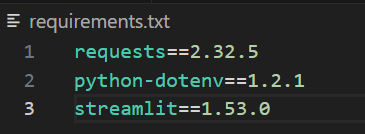
.\.venv\Scripts\Activate.ps1最后,创建一个名为 requirements.txt 的文件,并添加以下依赖。你可以自行调整版本号。不过这些版本在构建时表现良好,因此我们将其固定以获得可复现的行为。
requests==2.32.5
python-dotenv==1.2.1
streamlit==1.53.0完成后,该文件应如下图所示:
要安装这些依赖,只需运行下面的 pip 命令:
pip install -r requirements.txt将 AI 模型抽象为对象
接下来,我们需要理解:所有 AI 模型都可以作为对象来表示。每个模型包含以下属性:
name:模型的人类可读名称。dataset_id:爬虫的唯一标识符。url:用于访问该 AI 模型的实际 URL。
在下面的类中,我们创建了同样的模型对象。该类不需要任何方法或逻辑。如果你熟悉计算机科学,它类似于传统的 struct。
class AIModel:
def __init__(self, name: str, dataset_id: str, url: str):
self.name = name
self.dataset_id = dataset_id
self.url = url 编写模型检索器(Model Retriever)
接下来,我们需要编写一个模型检索器。这个类承担更多工作:它在 Bright Data 与我们其余代码之间提供统一的编排层。它使用你的 Bright Data API key 与 API 进行认证。我们还会提供一系列方法:get_model_response()、trigger_prompt_collection()、collect_snapshot() 和 write_model_output()。接下来我们会逐步补全这些方法。
class AIModelRetriever:
def __init__(self, api_token: str):
self.api_token = api_token
def get_model_response(self, model: AIModel, prompt: str):
pass
def trigger_prompt_collection(self, model: AIModel, prompt: str, country: str = ""):
pass
def collect_snapshot(self, model: AIModel, snapshot_id: str):
pass
def write_model_output(self, model: AIModel, llm_response: dict):
passget_model_response()
该方法主要用于编排。它使用 trigger_prompt_collection() 启动爬虫并获取 snapshot_id。随后使用 collect_snapshot() 轮询 API,在数据准备好后返回响应。最后用 write_model_output() 将响应写入文件。
def get_model_response(self, model: AIModel, prompt: str):
snapshot_id = self.trigger_prompt_collection(model, prompt)
if not snapshot_id:
raise RuntimeError(f"{model.name}: failed to trigger snapshot. Please wait and try again.")
llm_response = self.collect_snapshot(model, snapshot_id)
if not llm_response:
raise RuntimeError(f"Failed to collect snapshot {snapshot_id} for {model.name}. Please wait and try again")
self.write_model_output(model, llm_response)trigger_prompt_collection()
要触发采集,我们会把 API token 放入 HTTP headers 中,然后向 API 发起 POST 请求。我们最多重试三次,因为 HTTP 失败有时难以预测,重试可以应对这种情况。如果响应正常,就返回 snapshot_id。如果出现错误,则继续尝试直到用尽重试次数。超过重试次数后,退出函数。
def trigger_prompt_collection(self, model: AIModel, prompt: str, country: str = ""):
headers = {
"Authorization": f"Bearer {self.api_token}",
"Content-Type": "application/json",
}
data = json.dumps(
{"input":
[
{
"url": model.url,
"prompt": prompt,
"country":country,
}
],
})
tries = 3
while tries > 0:
response = None
try:
response = requests.post(
f"https://api.brightdata.com/datasets/v3/scrape?dataset_id={model.dataset_id}¬ify=false&include_errors=true",
headers=headers,
data=data,
timeout=POST_TIMEOUT
)
response.raise_for_status()
payload = response.json()
snapshot_id = payload["snapshot_id"]
return snapshot_id
except (ValueError, KeyError, TypeError, requests.RequestException) as e:
print(f"failed to trigger {model.name} snapshot: {e}")
tries -= 1
if response is not None and response.status_code >= 400:
print(f"Status: {response.status_code}")
print(response.text)
print("retries exceeded")
returncollect_snapshot()
拿到 snapshot_id 后,我们每分钟检查一次是否就绪。若采集仍在进行中,API 会返回状态码 202;当快照就绪,会返回 200。若收到其它状态码,我们会抛出错误并进入重试逻辑。若重试次数用尽,则退出该方法。
def collect_snapshot(self, model: AIModel, snapshot_id: str):
url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}"
ready = False
llm_response = None
print(f"Waiting for {model.name} snapshot {snapshot_id}")
max_errors = 3
while not ready and max_errors > 0:
headers = {"Authorization": f"Bearer {self.api_token}"}
try:
response = requests.get(url, headers=headers, timeout=GET_TIMEOUT)
except requests.RequestException as e:
max_errors -= 1
print(f"{model.name}: polling error ({e})")
continue
if response.status_code == 200:
print(f"{model.name} snapshot {snapshot_id} is ready!")
ready = True
llm_response = response.json()
return llm_response
elif response.status_code == 202:
sleep(60)
else:
max_errors-=1
print("Error talking to the server")
print(f"Max errors exceeded, snapshot {snapshot_id} could not be collected")
returnwrite_model_output()
这个方法非常简单:用于保存模型输出。os.makedirs(OUTPUT_FOLDER, exist_ok=True) 用于确保 outputs 文件夹存在。随后把文件写入 outputs 文件夹,并使用 model.name 作为文件名。
def write_model_output(self, model: AIModel, llm_response: dict):
os.makedirs(OUTPUT_FOLDER, exist_ok=True)
path = os.path.join(OUTPUT_FOLDER, f"{model.name}-output.json")
with open(path, "w", encoding="utf-8") as file:
json.dump(llm_response, file, indent=4, ensure_ascii=False)
print(f"Finished generating report from {model.name} → {path}") 编写 main 文件
现在我们来编写 main 文件。它可用于在不加载 UI 的情况下运行后端流程。run_one() 用于在单个模型上运行流程。在 main() 中,我们使用 ThreadPoolExecutor() 让该函数在多个线程中同时运行。我们不再一次只做一个采集,而是每个线程执行一个采集,从而大幅提升速度。
import os
from concurrent.futures import ThreadPoolExecutor, as_completed
from dotenv import load_dotenv
from ai_models import chatgpt, perplexity, gemini, grok, copilot, AIModelRetriever
MAX_WORKERS = 5
def run_one(model, retriever, prompt):
retriever.get_model_response(model, prompt)
return model.name
def main():
load_dotenv()
api_token = os.environ["BRIGHTDATA_API_TOKEN"]
prompt = "Why is the sky blue?"
models = [chatgpt, perplexity, gemini, grok, copilot]
retriever = AIModelRetriever(api_token=api_token)
failures = 0
with ThreadPoolExecutor(max_workers=min(MAX_WORKERS, len(models))) as pool:
futures = {pool.submit(run_one, m, retriever, prompt): m for m in models}
for fut in as_completed(futures):
model = futures[fut]
try:
name = fut.result()
print(f"{name}: done")
except Exception as e:
failures += 1
print(f"{model.name}: failed ({e})")
if failures == len(models):
raise SystemExit(1)
if __name__ == "__main__":
main()你可以使用以下命令运行 main 文件:
python main.pyStreamlit UI
Streamlit UI 在概念上与 main 文件非常相似:我们仍使用多线程来运行每次采集。write_output() 与 sanitize_filename() 仅用于生成更干净的文件名。不同于在终端打印,我们通过 Streamlit 的变量在本地浏览器中启动并展示应用。
编写 UI
import os
import json
import re
from concurrent.futures import ThreadPoolExecutor, as_completed
from pathlib import Path
import streamlit as st
from dotenv import load_dotenv
from ai_models import chatgpt, perplexity, gemini, grok, copilot, AIModelRetriever
OUTPUT_DIR = Path("output")
MAX_WORKERS = 5
def sanitize_filename(name: str) -> str:
return re.sub(r"[^A-Za-z0-9._-]+", "_", name).strip("_")
def write_output(model_name: str, payload: dict) -> Path:
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
path = OUTPUT_DIR / f"{sanitize_filename(model_name)}-output.json"
path.write_text(json.dumps(payload, indent=4, ensure_ascii=False), encoding="utf-8")
return path
def main():
st.set_page_config(page_title="Universal LLM Scraper", layout="wide")
st.title("Universal LLM Scraper")
load_dotenv()
api_token = os.getenv("BRIGHTDATA_API_TOKEN")
if not api_token:
st.error("Missing BRIGHTDATA_API_TOKEN. Add it to a .env file in the project root.")
st.stop()
models = [chatgpt, perplexity, gemini, grok, copilot]
model_names = [m.name for m in models]
model_by_name = {m.name: m for m in models}
with st.sidebar:
st.header("Run settings")
prompt = st.text_area("Prompt", value="Who are the best residential proxy providers?", height=120)
target_phrase = st.text_input("Target phrase to track", value="Bright Data")
selected = st.multiselect("Models", options=model_names, default=model_names)
country = st.text_input("Country (optional)", value="")
save_to_disk = st.checkbox("Save results to output/", value=True)
redact_terms = st.text_area("Brand terms to hide (one per line)", value="")
redact_mode = st.selectbox("Hide mode", ["Mask", "Remove"], index=0)
run_clicked = st.button("Run scrapes", type="primary", use_container_width=True)
if "results" not in st.session_state:
st.session_state.results = {} # model_name -> payload
if "errors" not in st.session_state:
st.session_state.errors = {} # model_name -> error str
if "paths" not in st.session_state:
st.session_state.paths = {} # model_name -> saved path
def apply_redaction(text: str) -> str:
terms = [t.strip() for t in redact_terms.splitlines() if t.strip()]
if not terms:
return text
pattern = re.compile(r"(" + "|".join(map(re.escape, terms)) + r")", flags=re.IGNORECASE)
if redact_mode == "Mask":
return pattern.sub("███", text)
return pattern.sub("", text)
def extract_answer_text(payload: dict) -> str | None:
if not isinstance(payload, dict):
return None
if isinstance(payload.get("answer_text"), str):
return payload["answer_text"]
if "data" in payload and isinstance(payload["data"], list) and payload["data"]:
first = payload["data"][0]
if isinstance(first, dict) and isinstance(first.get("answer_text"), str):
return first["answer_text"]
return None
def mentions_target(payload: dict) -> bool:
if not target_phrase:
return False
answer = extract_answer_text(payload)
if isinstance(answer, str):
return target_phrase.lower() in answer.lower()
# Fallback: if we can't find answer_text, just search the serialized payload
try:
blob = json.dumps(payload, ensure_ascii=False)
return target_phrase.lower() in blob.lower()
except Exception:
return False
# Layout: status + results
status_col, results_col = st.columns([1, 2], gap="large")
with status_col:
st.subheader("Status")
if run_clicked:
st.session_state.results = {}
st.session_state.errors = {}
st.session_state.paths = {}
if not selected:
st.warning("Select at least one model.")
st.stop()
retriever = AIModelRetriever(api_token=api_token)
status_boxes = {name: st.empty() for name in selected}
progress = st.progress(0)
done = 0
total = len(selected)
def run_one(model_name: str):
model = model_by_name[model_name]
payload = retriever.run(model, prompt, country=country)
return model_name, payload
with ThreadPoolExecutor(max_workers=min(MAX_WORKERS, total)) as pool:
futures = [pool.submit(run_one, name) for name in selected]
for fut in as_completed(futures):
try:
model_name, payload = fut.result()
st.session_state.results[model_name] = payload
status_boxes[model_name].success(f"{model_name}: done")
if save_to_disk:
path = write_output(model_name, payload)
st.session_state.paths[model_name] = str(path)
except Exception as e:
err = str(e)
st.session_state.errors[f"job-{done+1}"] = err
st.error(err)
done += 1
progress.progress(done / total)
st.success("Run complete.")
# Show saved files (if any)
if st.session_state.paths:
st.caption("Saved files")
for k, v in st.session_state.paths.items():
st.write(f"- {k}: {v}")
if st.session_state.errors:
st.caption("Errors")
for k, v in st.session_state.errors.items():
st.write(f"- {k}: {v}")
with results_col:
st.subheader("Results")
if not st.session_state.results:
st.info("Click 'Run scrapes' to collect results.")
st.stop()
tabs = st.tabs(list(st.session_state.results.keys()))
for tab, model_name in zip(tabs, st.session_state.results.keys()):
payload = st.session_state.results[model_name]
with tab:
answer_text = extract_answer_text(payload)
mentioned = mentions_target(payload)
st.markdown(f"**Target phrase mentioned:** {'✅' if mentioned else '❌'}")
if answer_text and isinstance(answer_text, str):
st.markdown("### Answer")
st.text_area(
label="",
value=apply_redaction(answer_text),
height=260
)
else:
st.markdown("### Raw JSON")
st.json(payload)
if __name__ == "__main__":
main()是的,app.py 比 main 文件更长。但它与 main.py 相比只有几个关键差异:
- 状态管理:使用 Streamlit,我们把结果、错误以及文件路径存储在
st.session_state中,从而能在 UI 中取回并展示。 - 编排:不再硬编码提示词与模型采集,而是在 UI 中收集输入并触发执行。
- 文本检查:检查 answer text 是否包含目标短语;包含则显示 ✅,否则显示 ❌。
使用 UI
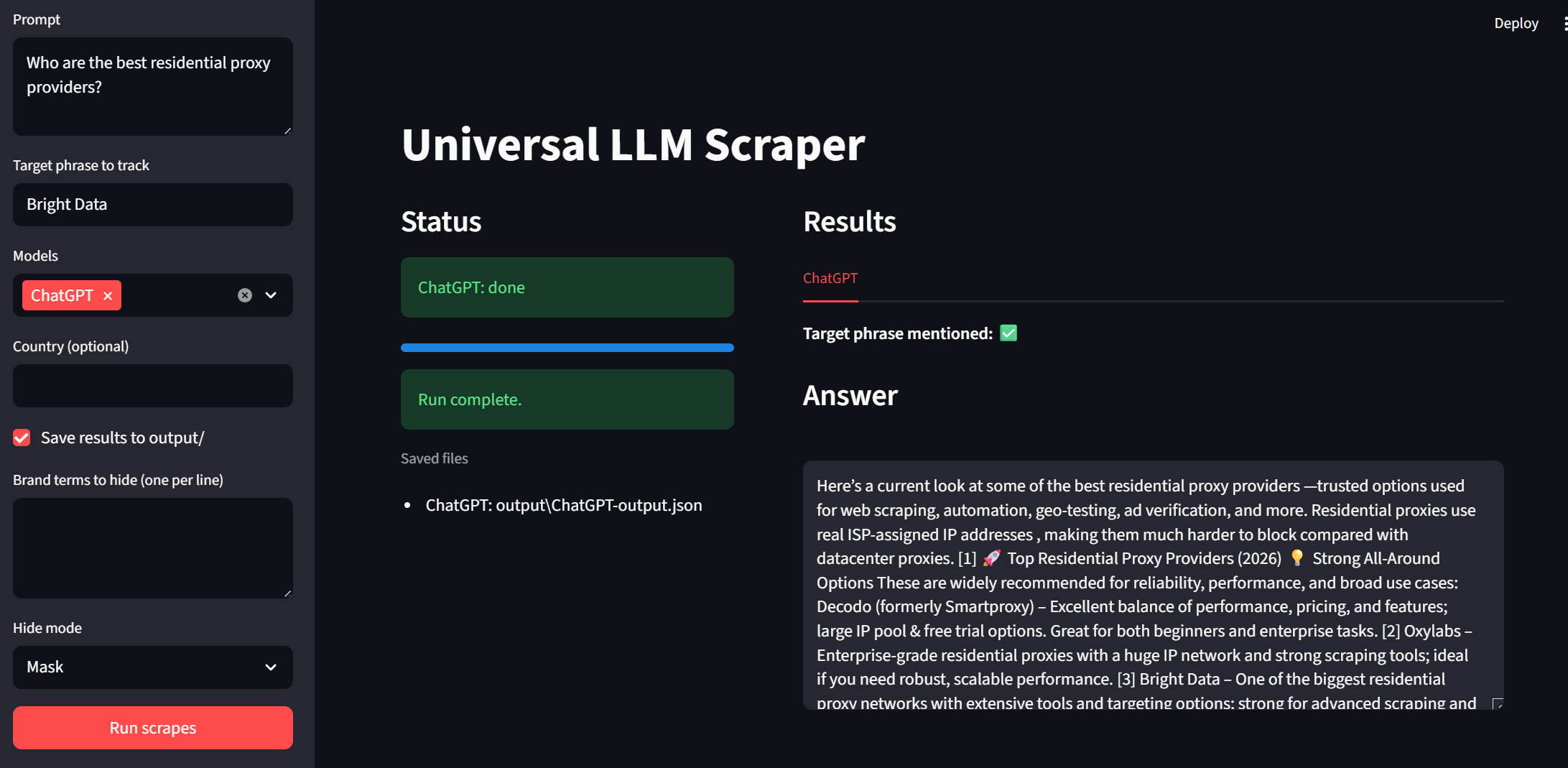
现在,是时候测试 UI 了。你可以使用下面的命令运行应用:
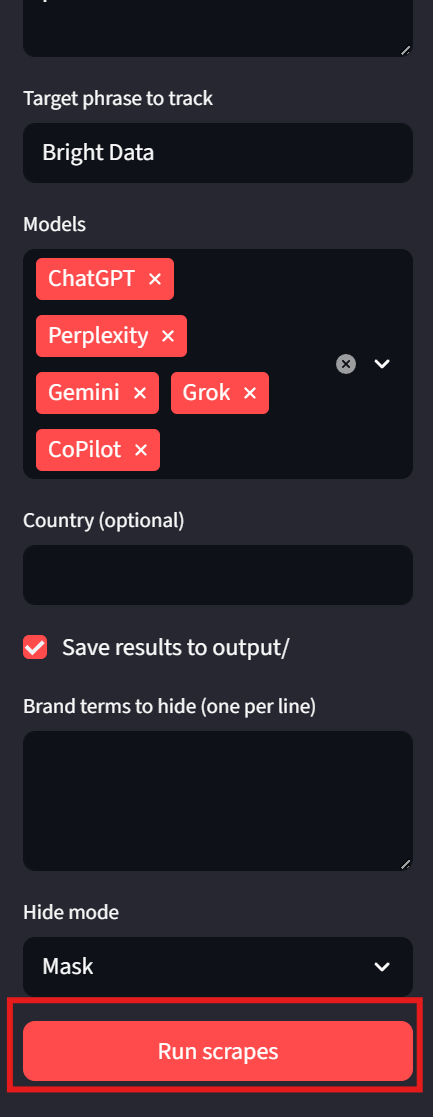
streamlit run app.py看看侧边栏:你可以输入提示词与目标短语;模型可通过下拉框选择;“Country”和“Save output”是可选项。要运行程序,只需点击底部的 “Run scrapes” 按钮。
结果
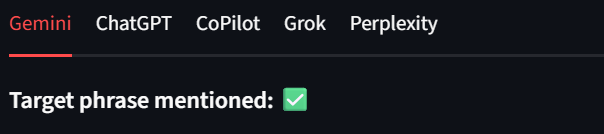
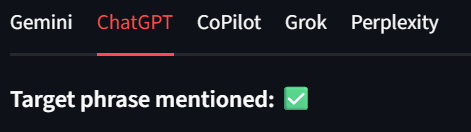
每个模型都会在结果区域以独立 Tab 的形式展示,这样我们就能快速审阅。如下图所示,Bright Data 在每个模型输出中都获得了绿色勾选标记。例如:
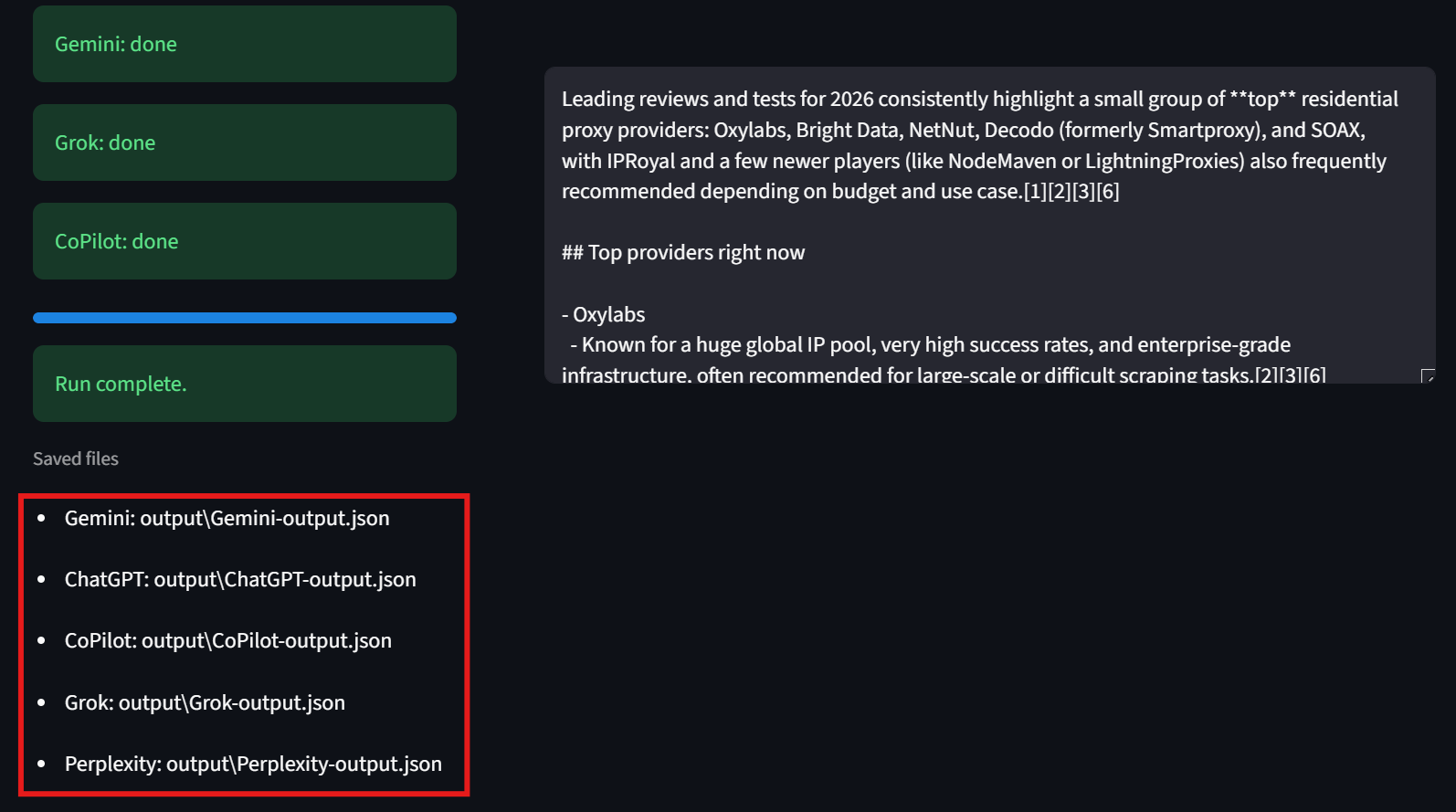
用户还应注意界面左下角:UI 会展示每个结果文件的路径,便于查看原始结果。
更进一步
首先,你需要一个 Supabase 账号。你可以访问 supabase.com 并按提示操作。Supabase 提供多种定价方案以满足需求。对本项目来说,免费套餐就足够了。不过随着数据库增长,你可能需要升级。
你还需要一个 API key。完成账号与项目设置后,在侧边栏点击 Project Settings,进入 API keys 标签页获取 API key。
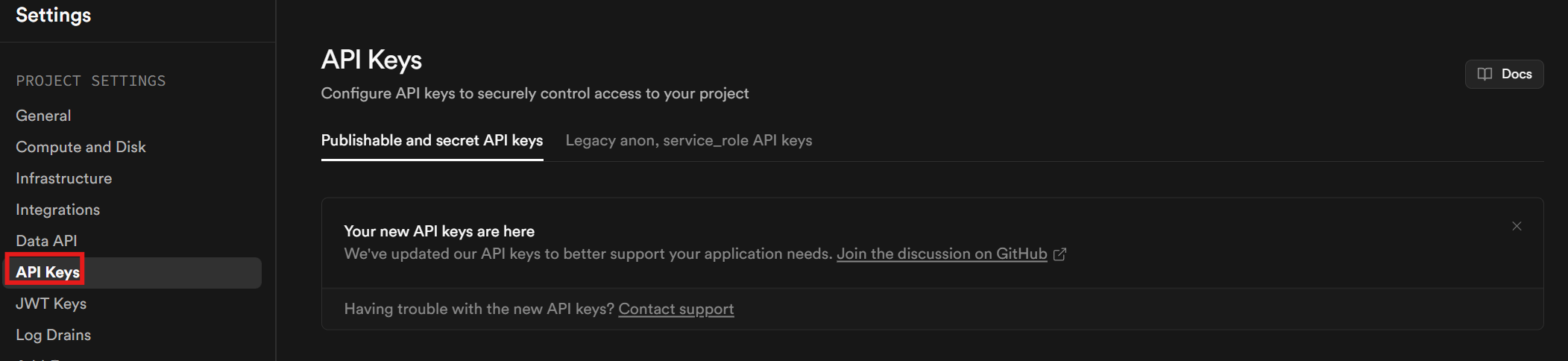
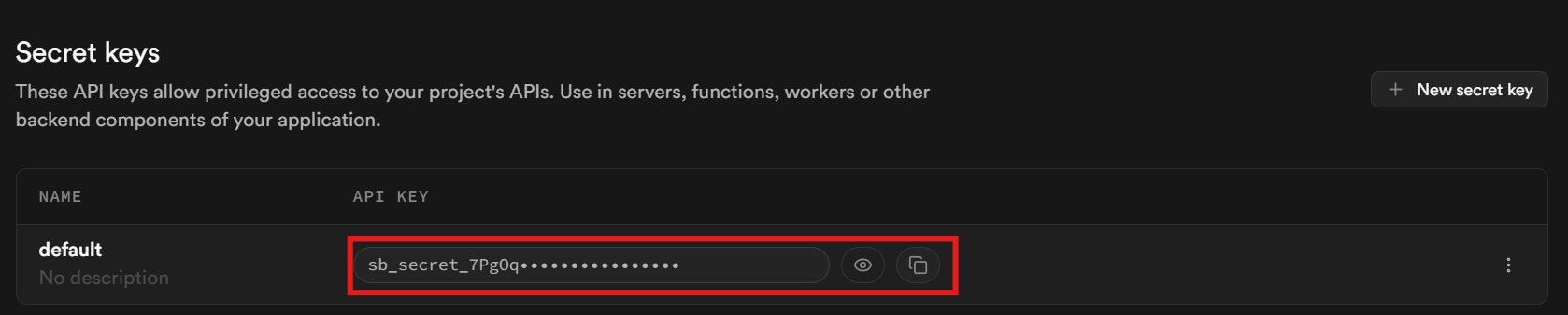
向下滚动到页面底部,你的 key 位于 “Secret keys” 区域中。
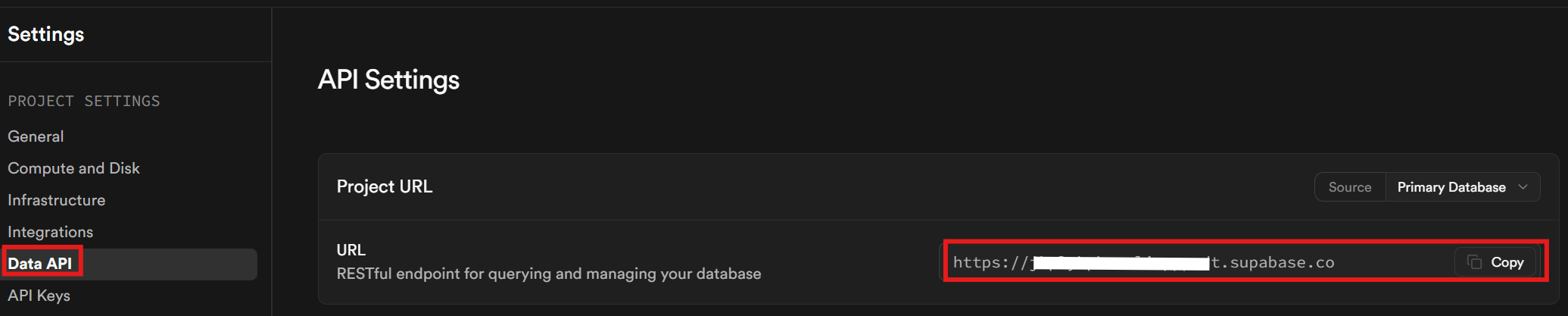
最后,在 Data API 标签页中获取 Supabase URL。该 URL 用于与你的数据库通信。
拿到这些 key 之后,我们需要更新环境文件与 requirements 文件。新的环境文件应如下所示:
BRIGHTDATA_API_TOKEN=<your-bright-data-api-key>
SUPABASE_URL=<your-supabase-project-url>
SUPABASE_API_TOKEN=<your-supabase-api-key>requirements 文件现在如下:
requests==2.32.5
python-dotenv==1.2.1
streamlit==1.53.0
supabase==2.27.2创建数据表
现在,我们需要在数据库中创建表。使用侧边栏打开 SQL editor。
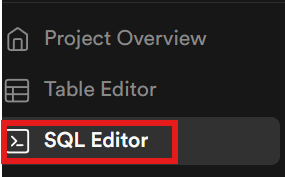
LLM runs
将以下 SQL 粘贴到脚本中并运行。这会创建名为 llm_runs 的表。每次运行采集时,我们会把结果写入这里。
create table public.llm_runs (
id bigint generated by default as identity primary key,
created_at_ts bigint not null, -- unix seconds
model_name text not null,
prompt text not null,
country text null,
target_phrase text null,
mentioned boolean not null default false,
payload jsonb not null
);
create index if not exists llm_runs_created_at_ts_idx
on public.llm_runs (created_at_ts);
create index if not exists llm_runs_model_idx
on public.llm_runs (model_name);
create index if not exists llm_runs_target_idx
on public.llm_runs (target_phrase);Prompts
我们还需要能够保存提示词。下面的代码会创建 prompts 表。
create table public.prompts (
id bigint generated by default as identity primary key,
created_at_ts bigint not null,
prompt text not null,
is_active boolean not null default true
);
create index if not exists prompts_created_at_ts_idx
on public.prompts (created_at_ts desc);
create index if not exists prompts_active_idx
on public.prompts (is_active);Schedules
最后,我们需要一个表来保存定时任务。
create table public.schedules (
id bigint generated by default as identity primary key,
name text not null,
is_enabled boolean not null default true,
next_run_ts bigint not null,
last_run_ts bigint null,
models jsonb not null default '[]'::jsonb,
country text null,
target_phrase text null,
only_active_prompts boolean not null default true,
locked_until_ts bigint null,
lock_owner text null,
repeat_every_seconds bigint not null default 86400
);
create index if not exists schedules_due_idx
on public.schedules (is_enabled, next_run_ts);
create index if not exists schedules_lock_idx
on public.schedules (locked_until_ts);更新后的架构
最终代码库已经足够大,无法再放进一篇教程中。我们不会把每个文件都贴出来,而是会讲解数据库连接、无界面(headless)运行器与 Streamlit UI 背后的一些核心点。
数据库交互
我们有一系列数据库辅助函数,但整体主要围绕数据库的读取与创建操作。下面的代码用于连接整个数据库。
def get_db() -> Client:
url = os.getenv("SUPABASE_URL")
key = os.getenv("SUPABASE_API_TOKEN") # keep consistent with your .env
if not url or not key:
raise RuntimeError("Missing SUPABASE_URL or SUPABASE_API_TOKEN in environment.")
return create_client(url, key)要实际与数据库交互,我们会在 get_db() 之上调用其他方法。下一个代码片段中,get_db() 获取数据库连接;然后使用 db.table("llm_runs").insert(row).execute() 向 llm_runs 表插入新行。Prompts 与 scheduling 的辅助函数遵循同样的逻辑。
def save_run(
*,
model_name: str,
prompt: str,
country: str,
target_phrase: str,
mentioned: bool,
payload: dict,
) -> dict:
db = get_db()
row = {
"created_at_ts": int(time.time()),
"model_name": model_name,
"prompt": prompt,
"country": country or None,
"target_phrase": target_phrase or None,
"mentioned": bool(mentioned),
"payload": payload, # JSONB
}
res = db.table("llm_runs").insert(row).execute()
if not getattr(res, "data", None):
row["payload"] = {"ERROR": "FAILED RUN"}
res = db.table("llm_runs").insert(row).execute()
raise RuntimeError(f"Insert failed: {res}")
return res.data[0]无界面(Headless)运行器
在创建 Streamlit UI 之后,随着项目范围扩大,我们把 main.py 重命名为 headless_runner.py。现在不再只有一个主程序,而是两个脚本同时运行。
persist_run() 会检查 API 返回的 payload 是否为空。如果 payload 为空,我们返回 False 并在终端打印一条关于插入失败的消息。如果 payload 包含信息,则使用 save_run() 将结果插入数据库。
def persist_run(*, model_name: str, prompt: str, payload, target_phrase: str, country: str = "") -> bool:
if payload is None:
print(f"{model_name}: skipping DB insert (payload is None).")
return False
# If you want to treat empty list/dict as "don't save", keep this:
if payload == {} or payload == []:
print(f"{model_name}: skipping DB insert (empty payload). type={type(payload).__name__}")
return False
try:
json.dumps(payload, ensure_ascii=False)
except TypeError as e:
print(f"{model_name}: payload not JSON-serializable ({e}). Stringifying.")
payload = {"raw": json.dumps(payload, default=str, ensure_ascii=False)}
mentioned = mentions_target(payload if isinstance(payload, dict) else {"data": payload}, target_phrase)
try:
save_run(
model_name=model_name,
prompt=prompt,
country=country,
target_phrase=target_phrase,
mentioned=mentioned,
payload=payload,
)
except Exception as db_err:
print(f"{model_name}: DB insert failed: {db_err}")
return mentioned继续之前,还有一段 headless runner 的核心逻辑需要你了解:我们提供了若干可选环境变量作为配置开关。程序的主运行逻辑放在一个简单的 while 循环中。在循环内,我们持续检查 schedule 中是否有新任务;一旦某个定时任务到期,就调用 run_schedule_once() 来执行一次运行。
# tune these without DB changes
tick_every_seconds = int(os.getenv("SCHED_TICK_SECONDS", "15")) # how often to wake up
lock_seconds = int(os.getenv("SCHED_LOCK_SECONDS", "1800")) # lock duration while a job runs
drain_all_due = os.getenv("SCHED_DRAIN_ALL_DUE", "1") == "1" # run all due jobs each tick
save_to_disk = os.getenv("SCHED_SAVE_TO_DISK", "0") == "1"
while True:
now_ts = int(time.time())
ran_any = False
# claim & run either one schedule, or drain all due schedules
while True:
try:
due = claim_due_schedule(now_ts=now_ts, lock_owner=lock_owner, lock_seconds=lock_seconds)
except Exception as e:
print(f"Failed to claim due schedule: {e}")
due = None
if not due:
break
ran_any = True
try:
run_schedule_once(
schedule_row=due,
retriever=retriever,
available_models=available_models,
model_by_name=model_by_name,
save_to_disk=save_to_disk,
)
except Exception as e:
# If something explodes mid-run, we do NOT advance the schedule.
# The lock will expire, and the schedule will be picked up later.
print(f"Schedule run crashed: {e}")
if not drain_all_due:
break
# update time for next claim
now_ts = int(time.time())
if not ran_any:
# optional: quieter logs
print(f"[{int(time.time())}] No due schedules.")
time.sleep(tick_every_seconds)要启动 headless runner,只需打开一个新终端并运行 python headless_runner.py。
Streamlit 应用
我们的 Streamlit 应用已大幅扩展。你仍可使用 streamlit run app.py 启动。它现在包含五个独立的标签页;原来的 “Run Scrapes” 页面仍会作为仪表盘首页。
在 “Prompts” 标签页中,用户可以创建新的提示词,并可选择保存以供后续使用。页面底部,用户还能配置并执行批量运行。
在 “History” 标签页中,用户可以查看详细的运行历史;页面底部也提供查看原始 JSON payload 的选项。
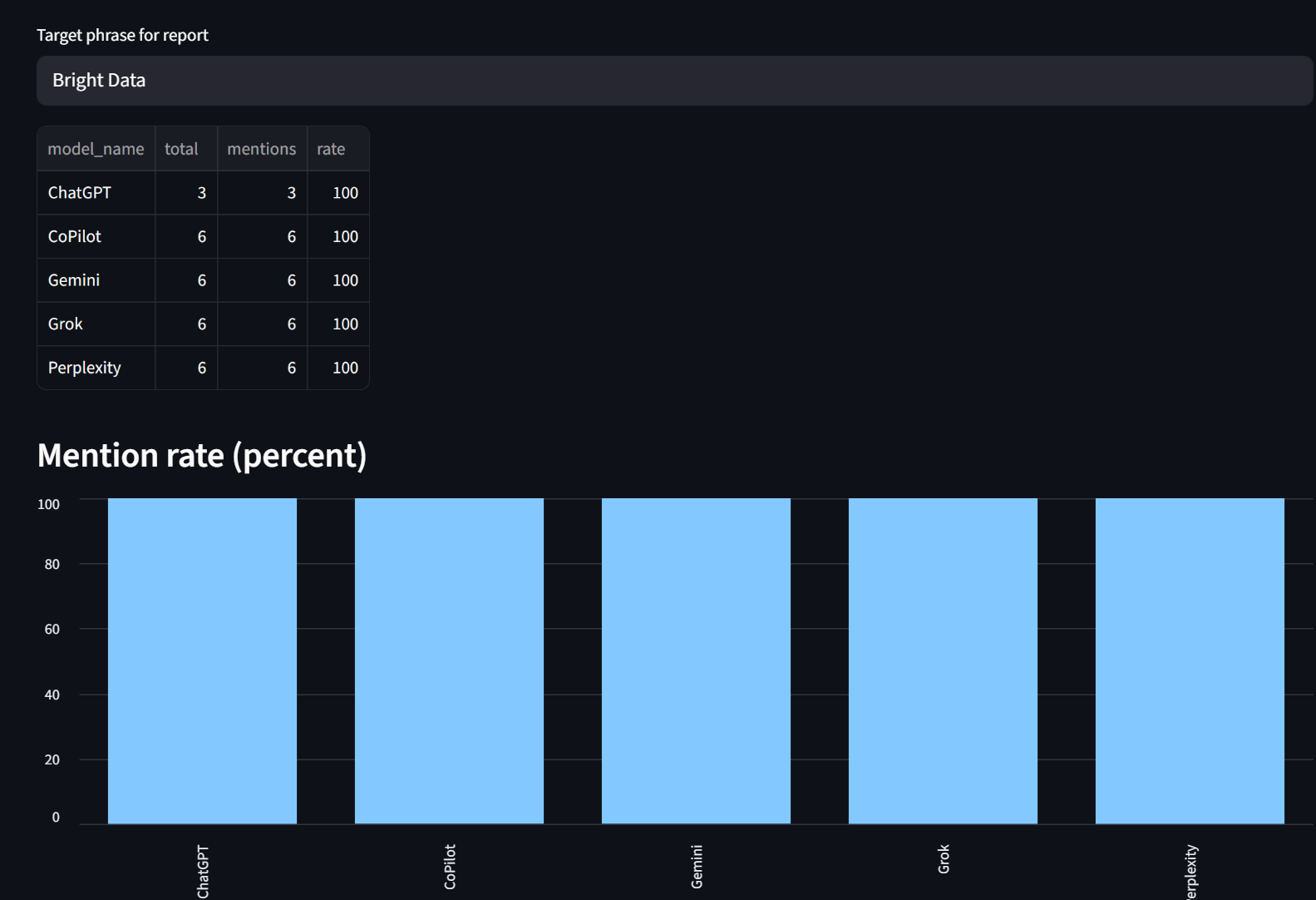
“Reports” 标签页可以按模型查看提及率报告。如下所示,Bright Data 在此处每个模型的提及率都为 100%。
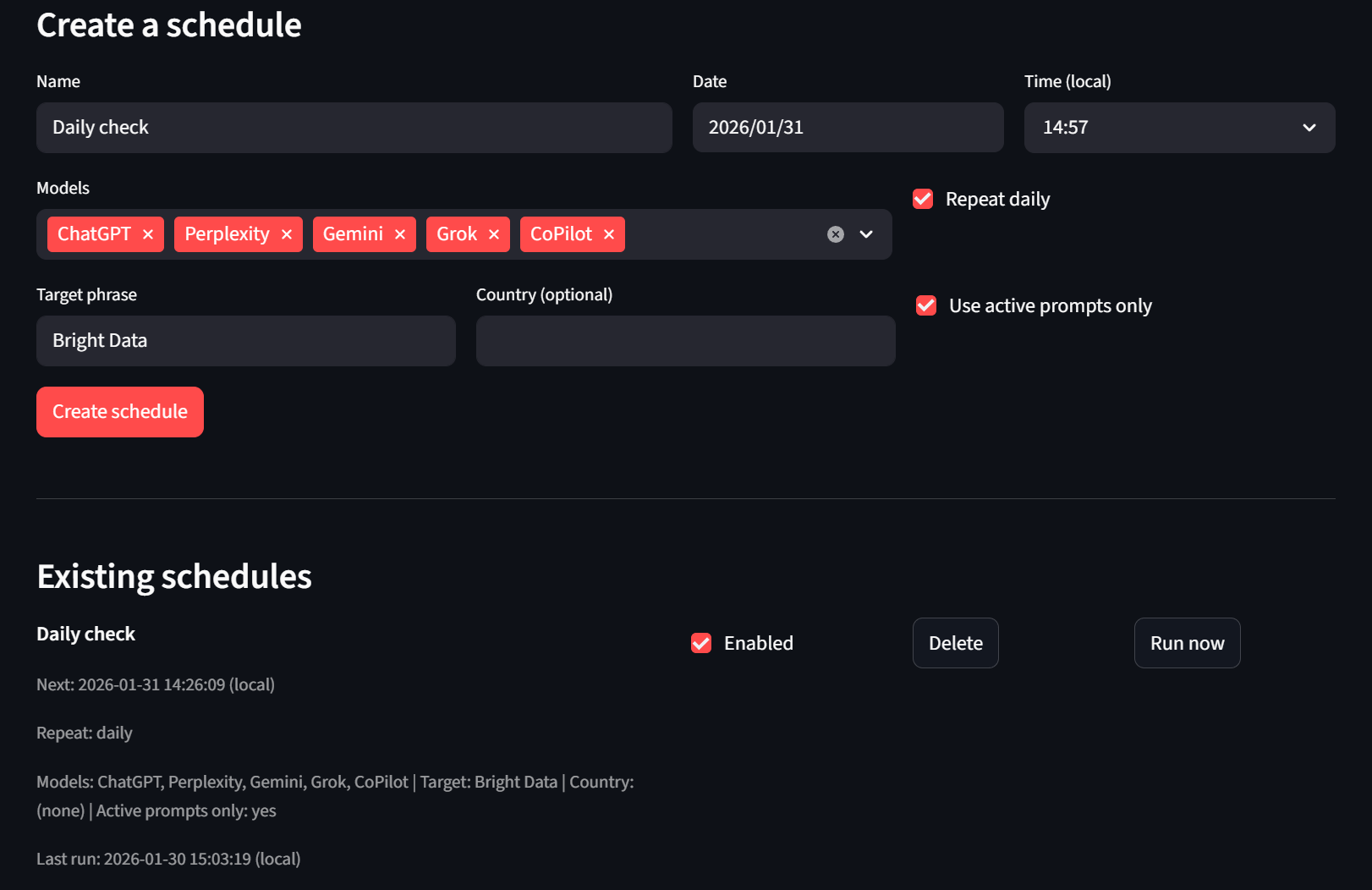
最后是 “Scheduler” 标签页:用户可以创建与删除定时计划;如果不想等待,也可以点击 “Run now” 按钮,headless runner 会在下一次 tick 时取走并执行。
结论
如果你已经在本文开头构建了原型,那么你已理解将此类工具推进到下一阶段所需的核心概念。
本指南展示的架构可以支持:
- 持久化记忆与历史追踪:将结果长期存储,用于发现 AI 模型对品牌提及方式的趋势、追踪排名变化并识别新出现的竞争对手。
- 每天监控数百条提示词:对成千上万的关键词变体、产品类别与竞品对比进行自动化定时采集。
- 自动化报表与分析:生成报告,展示品牌提及率、情绪分析、引用频率以及跨主流 LLM 的竞争定位。
- 告警系统:当品牌从推荐列表中消失或竞争对手获得更多曝光时触发通知。
- 多地区监控:追踪不同地理区域的 AI 回复差异,以指导本地化营销策略。
对于需要规模化管理品牌声誉的企业团队而言,能够针对每个主流模型、每个相关查询、每天都回答“AI 是否在推荐我的公司?”不再是可选项,而是必备基础设施。
Bright Data 的 Web Scraper API 提供经过标准化、可靠的数据流,使这种级别的监控成为可能。无论你要追踪 ChatGPT、Perplexity、Gemini、Grok 还是 Microsoft Copilot,统一的 schema 都能减少集成摩擦,让团队把精力集中在洞察而非数据清洗上。
准备构建你自己的 AI 可见性监控系统了吗?开始免费试用,看看 Bright Data 如何为你的下一代 SEO 策略提供动力。



技术写作者
 6 years experience
6 years experience
Jacob Nulty 是一位常驻底特律的软件开发者和技术写作者,探索人工智能与人类哲学,具备 Python、Rust 和区块链方面的经验。





