

在本指南中,你将了解:
- 什么是研究智能体,以及为何传统方法会失效
- 如何配置 Bright Data 以进行可靠的数据采集
- 如何使用 Streamlit 界面构建本地 AI 驱动的研究智能体
- 如何将 Bright Data API 与本地模型集成,以获得结构化洞见
让我们开始构建你的智能研究助手。我们也建议你了解下 Deep Lookup,它是 Bright Data 的 AI 驱动搜索引擎,能像查询数据库一样搜索全网。
行业难题
- 研究人员面对来自众多来源的海量信息,人工审阅几乎不可行。
- 传统研究往往需要缓慢的人工搜索、抽取与整合。
- 结果常常不完整、彼此割裂且组织混乱。
- 简单的爬取工具只提供缺乏可信度与上下文的原始数据。
解决方案:研究智能体
深度研究智能体是一套从采集到报告全流程自动化的 AI 系统。它能够处理上下文、管理任务,并输出结构化且高质量的洞见。
核心组件:
- 规划智能体:将研究拆解为任务
- 研究子智能体:执行搜索并提取数据
- 撰写智能体:整理并编写结构化报告
- 质检智能体:检查质量,必要时触发更深入的研究
本指南演示如何使用 Bright Data 的 API、Streamlit 界面以及本地 LLM,构建一个兼顾隐私与可控性的本地研究系统。
前提条件
- 具备带有 API Key 的 Bright Data 账户。
- Python 3.10+
- 依赖:
requestsfaiss或chromadbpython-dotenvstreamlitollama(用于本地模型)
Bright Data 配置
创建 Bright Data 账户
- 在 Bright Data 注册
- 前往 API 凭证部分
- 生成你的 API Token
使用环境变量安全地存储 API 凭证。创建 .env 文件保存你的凭证,将敏感信息与代码分离。
BRIGHT_DATA_API_KEY="your_bright_data_api_token_here"环境搭建
# Create venv
python -m venv venv
source venv/bin/activate
# Install dependencies
pip install requests openai chromadb python-dotenv streamlit实现
步骤 1:研究
这是我们的研究任务。
query = "AI use cases in healthcare"步骤 2:获取数据
此步骤演示如何通过 Bright Data 的数据采集 API 以编程方式从网页抓取数据。代码会发送研究查询并检索相关数据,同时安全地处理 API 凭证。
import requests, os
from dotenv import load_dotenv
load_dotenv()
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": query, "limit": 20}
headers = {"Authorization": f"Bearer {os.getenv('BRIGHT_DATA_API_KEY')}"}
res = requests.post(url, json=payload, headers=headers)
print(res.json())步骤 3:处理与嵌入
此步骤将获取到的研究数据进行处理,并存入 ChromaDB(一个向量数据库),以实现语义搜索与相似度匹配。这样即可把研究结果构造成一个可检索的知识库,可用于医疗保健领域的 AI 用例或任何其他研究主题。
import chromadb
from chromadb.config import Settings
# Initialize ChromaDB
client = chromadb.PersistentClient(path="./research_db")
collection = client.get_or_create_collection("research_data")
# Store research results
def store_research_data(results):
documents = []
metadatas = []
ids = []
for i, item in enumerate(results):
documents.append(item.get('content', ''))
metadatas.append({
'source': item.get('source', ''),
'query': query,
'timestamp': item.get('timestamp', '')
})
ids.append(f"doc_{i}")
collection.add(
documents=documents,
metadatas=metadatas,
ids=ids
)步骤 4:本地模型摘要
此步骤展示如何通过 Ollama 调用本地运行的大语言模型(LLM),为研究内容生成简明摘要。该方式可确保数据处理在本地完成,并支持离线摘要能力。
import subprocess
import json
def summarize_with_ollama(content, model="llama2"):
"""Summarize research content using local Ollama model"""
try:
result = subprocess.run(
['ollama', 'run', model, f"Summarize this research content: {content[:2000]}"],
capture_output=True,
text=True,
timeout=120
)
return result.stdout.strip()
except Exception as e:
return f"Summarization failed: {str(e)}"
# Example usage
research_data = res.json().get('results', [])
for item in research_data:
summary = summarize_with_ollama(item.get('content', ''))
print(f"Summary: {summary}")ollama run llama2 "Summarize AI use cases in healthcare"Streamlit 界面
最后,创建一个完整的 Web 界面,将来自 Bright Data 的数据采集与通过 Ollama 的本地 AI 摘要结合在一起。该界面允许用户配置研究参数、运行数据采集,并通过直观的仪表板生成 AI 摘要。
创建 app.py
import streamlit as st
import requests, os
from dotenv import load_dotenv
import subprocess
import json
load_dotenv()
st.set_page_config(page_title="Deep Research Agent", page_icon="🔎")
st.title("🔎 Local Deep Research Agent with Bright Data")
# Sidebar configuration
with st.sidebar:
st.header("Configuration")
api_key = st.text_input(
"Bright Data API Key",
type="password",
value=os.getenv('BRIGHT_DATA_API_KEY', '')
)
model_choice = st.selectbox(
"Ollama Model",
["llama2", "mistral", "codellama"]
)
research_depth = st.slider("Research Depth", 5, 50, 20)
# Main research interface
query = st.text_input("Enter research topic:", "AI use cases in healthcare")
col1, col2 = st.columns(2)
with col1:
if st.button("🚀 Run Research", type="primary"):
if not api_key:
st.error("Please enter your Bright Data API key")
elif not query:
st.error("Please enter a research topic")
else:
with st.spinner("Collecting research data..."):
# Fetch data from Bright Data
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": query, "limit": research_depth}
headers = {"Authorization": f"Bearer {api_key}"}
res = requests.post(url, json=payload, headers=headers)
if res.status_code == 200:
st.success(f"Successfully collected {len(res.json().get('results', []))} sources!")
st.session_state.research_data = res.json()
# Display results
for i, item in enumerate(res.json().get('results', [])):
with st.expander(f"Source {i+1}: {item.get('title', 'No title')}"):
st.write(item.get('content', 'No content available'))
else:
st.error(f"Failed to fetch data: {res.status_code}")
with col2:
if st.button("🤖 Summarize with Ollama"):
if 'research_data' in st.session_state:
with st.spinner("Generating AI summaries..."):
for i, item in enumerate(st.session_state.research_data.get('results', [])):
content = item.get('content', '')[:1500] # Limit content length
try:
result = subprocess.run(
['ollama', 'run', model_choice, f"Summarize this content: {content}"],
capture_output=True,
text=True,
timeout=60
)
summary = result.stdout.strip()
with st.expander(f"AI Summary {i+1}"):
st.write(summary)
except Exception as e:
st.error(f"Summarization failed for source {i+1}: {str(e)}")
else:
st.warning("Please run research first to collect data")
# Display raw data if available
if 'research_data' in st.session_state:
with st.expander("View Raw Research Data"):
st.json(st.session_state.research_data)运行应用:
streamlit run app.py当你运行应用并访问 8501 端口时,界面如下:
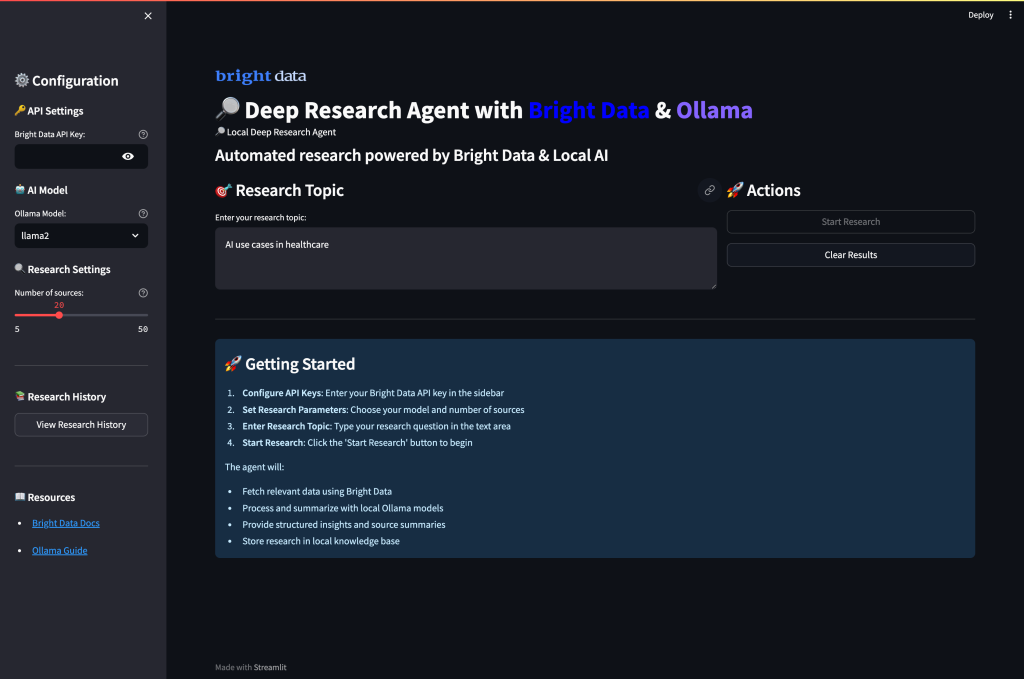
运行你的深度研究智能体
运行该应用即可开始由 AI 驱动的全面研究。在终端中打开并进入你的项目目录。
streamlit run app.py你将看到系统在处理研究请求时的多智能体工作流:
- 数据采集阶段:智能体通过 Bright Data 可靠的 API 从多元网页来源抓取全面的研究数据,并自动筛选相关性与可信度。
- 内容处理:系统对每个来源进行智能分析,抽取关键信息,识别主要主题,并基于语义理解评估内容质量。
- AI 摘要:本地 Ollama 模型处理采集到的数据,生成简明摘要,同时保留关键信息并在各来源之间保持上下文一致。
- 知识综合:系统识别重复模式、关联相关概念,并通过跨来源分析发现新兴趋势。
- 结构化报告:最终,智能体将所有发现整理为一份结构化的研究报告,包含清晰的组织结构、明确引用与专业格式,突出关键发现与洞见。
增强的研究流水线
如需更高级的研究能力,可扩展实现。
该增强流水线构建了完整的研究工作流,超越简单摘要,提供结构化分析、关键洞见与可执行结论。该流水线将 Bright Data 用于信息采集,将本地 Ollama 模型用于智能分析。
# advanced_research.py
def comprehensive_research_pipeline(query, api_key, model="llama2"):
"""Complete research pipeline with data collection and AI analysis"""
# Step 1: Fetch data from Bright Data
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": query, "limit": 20}
headers = {"Authorization": f"Bearer {api_key}"}
response = requests.post(url, json=payload, headers=headers)
if response.status_code != 200:
return {"error": "Data collection failed"}
research_data = response.json()
# Step 2: Process and analyze with Ollama
insights = []
for item in research_data.get('results', []):
content = item.get('content', '')
# Generate insights for each source
analysis_prompt = f"""
Analyze this content and provide key insights:
{content[:2000]}
Focus on:
- Main points and findings
- Key data and statistics
- Potential applications
- Limitations mentioned
"""
try:
result = subprocess.run(
['ollama', 'run', model, analysis_prompt],
capture_output=True,
text=True,
timeout=90
)
insights.append({
'source': item.get('source', ''),
'analysis': result.stdout.strip(),
'title': item.get('title', '')
})
except Exception as e:
insights.append({
'source': item.get('source', ''),
'analysis': f"Analysis failed: {str(e)}",
'title': item.get('title', '')
})
return {
'research_data': research_data,
'ai_insights': insights,
'query': query
}结论
本地深度研究智能体展示了如何将 Bright Data 可靠的网页数据采集与通过 Ollama 的本地 AI 处理相结合,构建自动化研究系统。该实现提供:
- 隐私优先:所有 AI 处理都在本地通过 Ollama 完成
- 可靠采集:Bright Data 确保高质量、结构化的网页数据
- 易用界面:Streamlit 让复杂研究一目了然
- 可定制流程:可适配不同研究领域与需求
该系统通过自动化数据采集、处理与分析,解决行业关键痛点,将数小时的人工研究转化为数分钟的自动化洞见生成。
若需进一步增强研究能力,可探索 Bright Data 的数据集解决方案以获取行业特定数据,并考虑使用 Deep Lookup 来查询和搜索全球最大规模的网页数据“数据库”。
准备好构建你自己的研究智能体了吗?创建一个免费的 Bright Data 账户,开始可靠的网页数据采集,让你的研究流程即刻升级。



AI 内容创作者
Arindam Majumder 是一名开发者推广专员、YouTube博主和技术作家,专注于将大语言模型 (LLM)、智能体工作流及 AI 内容讲解得简单易懂,拥有超过5000名关注者。




