


功能
在 src/agent/graph.py 中定义的核心逻辑编排了一个复杂的搜索工作流,能够:
- 意图分类:使用 Gemini 2.0 Flash 将查询分为四类:
general_search:新闻、事实、定义、解释product_search:购物、价格、评测、推荐web_scraping:从特定网站提取数据comparison:对多个条目或服务进行比较
- 多模态搜索:
- Google 搜索:通过 Bright Data 的 MCP 搜索引擎处理通用查询
- 网页抓取:使用 Bright Data 的 Web Unlocker 进行定向数据提取
- 智能路由:根据意图自动选择最佳搜索策略
- 结果处理:
- 对结果进行清洗与去重
- 按相关性与质量为结果打分
- 返回可配置的 Top N 结果,并提供置信度评分
- 提供查询摘要
- 错误处理:提供优雅降级与全面的错误管理
架构
该代理遵循一个复杂的、基于图(graph)的工作流:
START Intent Classifier [Google Search | Web Unlocker] Final Processing END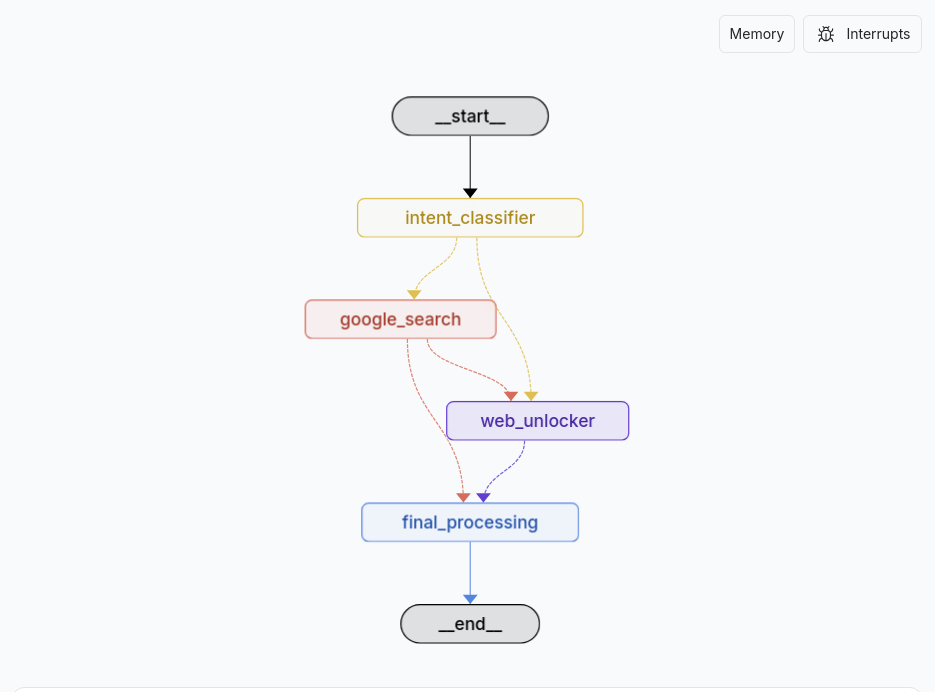
路由逻辑:
- 查询中包含 URL:直接走 Web Unlocker
general_search:仅使用 Google 搜索product_search:先 Google 搜索,再进行网页抓取web_scraping:仅使用 Web Unlockercomparison:两种搜索方式并行执行
技术栈
- LangGraph
- Gemini 2.0 Flash
- Bright Data MCP
- Pydantic
- LangGraph Studio
快速开始
- 安装依赖以及 LangGraph CLI:
cd unified-search-agent
pip install -e . "langgraph-cli[inmem]"- 设置环境变量。创建包含 API key 的
.env文件:
cp .env.example .env将你的 API key 填入 .env 文件:
# Required
GOOGLE_API_KEY=your_gemini_api_key_here
BRIGHT_DATA_API_TOKEN=your_bright_data_token_here
# Optional zones (defaults provided)
WEB_UNLOCKER_ZONE=unblocker
BROWSER_ZONE=scraping_browser
# Optional - for LangSmith tracing
LANGSMITH_API_KEY=lsv2...- 启动 LangGraph Server:
langgraph dev- 打开 LangGraph Studio,访问所提供的 URL(通常为
)https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:2024
关于 LangGraph Server 的更多入门信息,请看这里。
使用示例
基础搜索
{
"query": "Who is Or Lenchner",
"max_results": 3
}商品搜索
{
"query": "best laptops under $1000",
"max_results": 5
}网页抓取
{
"query": "extract contact info from https://example.com",
"max_results": 10
}对比查询
{
"query": "iPhone 15 vs Samsung Galaxy S24 comparison",
"max_results": 5
}配置
该代理支持多个可配置参数:
max_results:最终返回的结果数量(默认:5)- 查询级路由:查询中包含 URL 会自动触发网页抓取
- 搜索策略:由意图分类自动决定
如何自定义
- 修改意图分类:更新
src/agent/nodes.py中intent_classifier_node()的分类与示例 - 调整搜索策略:修改
src/agent/graph.py中的路由逻辑,以改变不同意图的处理方式 - 自定义结果评分:更新
final_processing_node()中的评分标准,以改变结果排序方式 - 新增搜索来源:在图中扩展额外的搜索节点,以支持其他数据源
- 配置参数:修改
graph.py中的Configuration类,以暴露更多运行时参数
开发
在 LangGraph Studio 中迭代你的图(graph)时,你可以:
- 编辑历史状态并从之前的状态重新运行,以调试特定节点
- 热重载:本地改动会自动生效
- 使用
+按钮创建新线程,以清除之前的历史记录 - 可视化调试:查看每一步的具体流程与状态
该图结构便于对以下内容进行调试:
- 意图分类准确率
- 搜索结果质量
- 路由决策
- 最终结果评分
返回结果格式
该代理返回带有完整评分的结构化结果:
{
"final_results": [
{
"title": "Result Title",
"url": "https://example.com",
"snippet": "Relevant description...",
"source": "google_search",
"relevance_score": 0.95,
"quality_score": 0.88,
"final_score": 0.92,
"metadata": {
"search_engine": "google",
"via": "bright_data_mcp",
"query": "original query"
}
}
],
"query_summary": "Found information about...",
"total_processed": 8,
"intent": "general_search",
"intent_confidence": 0.95
}高级功能
- 并行处理:对比类查询会同时执行两种搜索方式
- 智能回退:带默认响应的优雅错误处理
- 重复检测:自动对跨来源结果进行去重
- URL 校验:过滤无效或为空的 URL
- 内容清洗:清理并校验所有文本内容
更多高级功能与示例请参阅 LangGraph 文档。
LangGraph Studio 可与 LangSmith 集成,以进行更深入的追踪与团队协作,帮助你分析并优化搜索代理的性能。
依赖
langgraph>=0.2.6:核心编排框架langchain-google-genai:用于 LLM 操作的 Gemini 集成pydantic>=2.0.0:数据校验与解析mcp-use:用于 Bright Data 集成的 MCP 客户端langchain-core:LangChain 核心工具python-dotenv>=1.0.1:环境变量管理
参与贡献
- Fork 仓库
- 创建功能分支
- 完成修改
- 使用 LangGraph Studio 测试
- 提交 Pull Request
许可证
本项目基于 MIT 许可证发布——详情请参阅 LICENSE 文件。