


功能
- 聚合来自 Crunchbase、LinkedIn 和 Reddit 的公司与社交数据。
- 通过 CrewAI 代理与 Bright Data MCP 自动化网页抓取(支持 JS 渲染、代理轮换与 CAPTCHA 处理)。
- 使用 Gemini 模型进行 AI 驱动的分析与洞察生成
- 在 Streamlit 仪表盘中进行实时可视化展示
- 模块化架构,便于新增数据源或工作流
工作原理
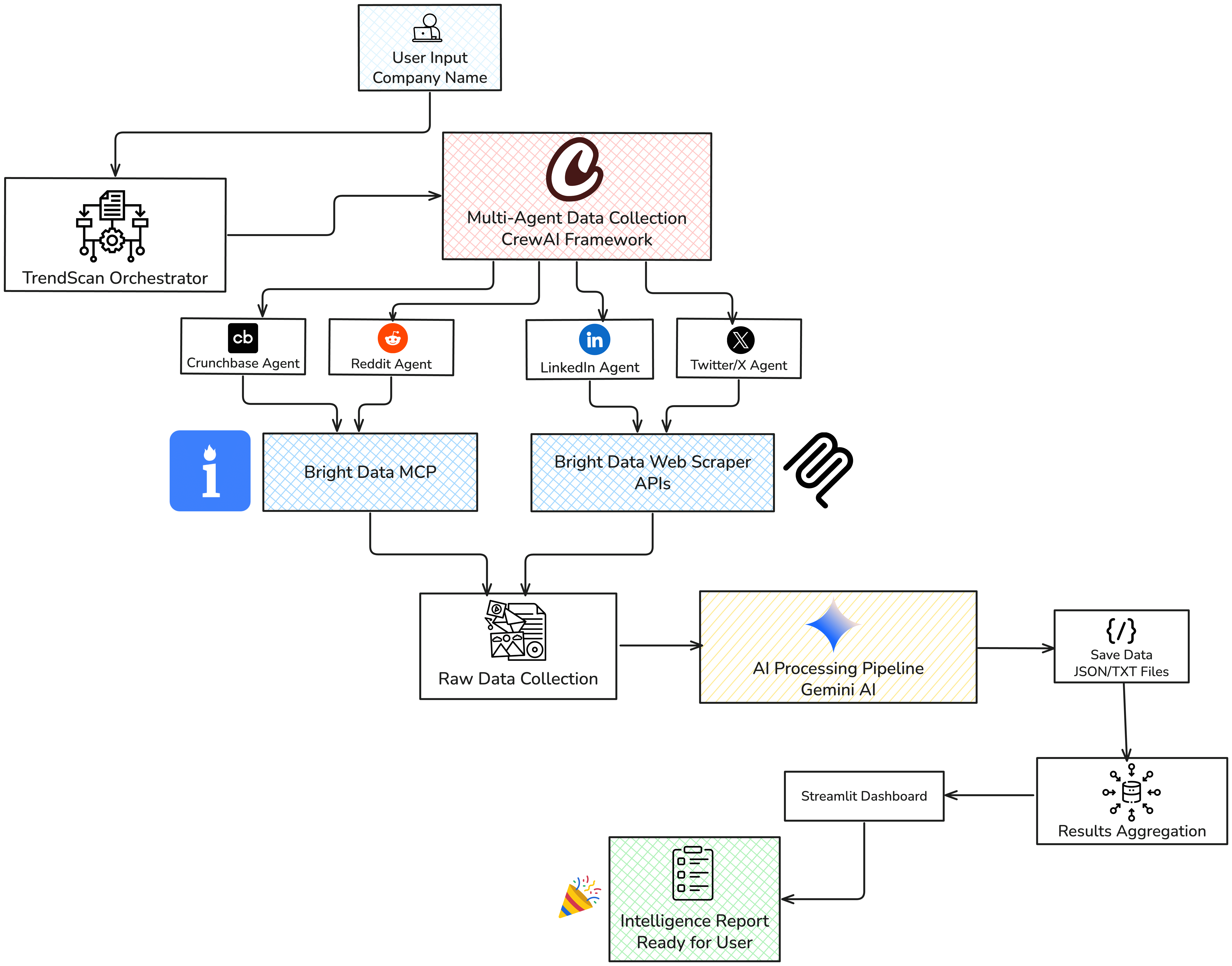
- 启动:使用专门的 CrewAI 代理进行数据获取。
- 编排:通过 Bright Data MCP 进行 API 调用与动态抓取编排,处理 JS、代理、速率限制、CAPTCHA 等。
- 规范化:存储数据并发送至 Gemini AI 进行即时分析。
- 展示:在 Streamlit 仪表盘中展示结果与可执行的洞察。
技术栈
- CrewAI:
- Bright Data MCP:
- Gemini:
- Streamlit:
数据来源
| 来源 | 数据类型 | 内容 | 集成方式 |
|---|---|---|---|
| Crunchbase | 公司资料 | 融资、团队、指标、新闻 | 100% MCP |
| 职业数据 | 职位、动态更新 | 混合(MCP+API) | |
| 公众情绪 | 讨论、观点、评价 | 100% MCP |
使用场景
- 竞争情报与公司研究
- 市场趋势分析
- 实时情绪与话题监测
- 投资/并购(M&A)标的筛选
- 面向分析师的多来源数据发现
前置条件
- Python3 & Node.js
- 拥有 API key 的 Bright Data 账号
- 另外还需要 Web Unlocker 和 Browser API 的 zone
- Gemini API 访问权限
安装
# 克隆仓库
git clone https://github.com/brightdata/trendscan.git
cd trendscan
# 创建并激活 Python 虚拟环境
uv venv
# 安装依赖
uv pip install -r requirements.txt配置
- 打开项目根目录下的
.env文件。 - 填入你的真实凭据与 API key。
- (可选)如需使用不同的 Gemini 模型,请在
.env中设置LLM_MODEL。
参见 Gemini 模型文档。
| .env 变量(示例): | 变量 | 说明 |
|---|---|---|
| BRIGHT_DATA_API_KEY | 你的 Bright Data API Key | |
| GEMINI_API_KEY | 你的 Gemini API Key | |
| … | … |
使用
使用以下命令启动 Streamlit Web 界面:
streamlit run streamlit_trendscan.py你将能够在浏览器中发起数据获取、运行整条流水线,并与仪表盘交互。
参与贡献
欢迎提交 PR、反馈与功能建议!
- 如需报告 Bug 或提出改进,请 创建 Issue。
- 如为较大规模的贡献,建议先发起讨论。
许可证
采用 MIT 许可证发布。
祝你玩得开心:扫描趋势,强化公司情报能力!